






作者 | 团长 编辑 | 汽车人
原文链接:https://zhuanlan.zhihu.com/p/685046883
点击下方卡片,关注“自动驾驶之心”公众号
戳我-> 领取自动驾驶近15个方向学习路线
本文只做学术分享,如有侵权,联系删文
经常用stable diffusion画图的小伙伴都知道,一张好的显卡是能保证出好图的基础,如果显卡偏弱,动辄一张图几十秒都是经常的,如果加上高清修复,面部修复后一两分钟也是常态。那除了大出血换一块4090以外,有没有什么免费的解决方案呢?别说,还真有,英伟达的TensorRT!(A卡童鞋哭泣)
配置要求
TensorRT是由英伟达推出的针对N卡高性能深度学习推理SDK,这里指的是官方专门针对Stalbe Diffusion出的“加速”拓展包,号称可将画图速度提升到300%,我们先看看TensorRT的配置要求
N卡(废话)
最少16G内存
N卡,显存≥8G
显卡驱动至少更新到538.58或更高版本
良好的网络(github下载可能需要科学上网)
门槛中等,但是4G显存的小伙伴又无福消受了,下面我们先来看看实际表现有没有这么牛逼?
PS:我的显卡是3系的3070,所以“加速”效果可能不如4系
首先看看标准测试,不开启TensorRT加速的情况下,出图需要多久?
原始速度
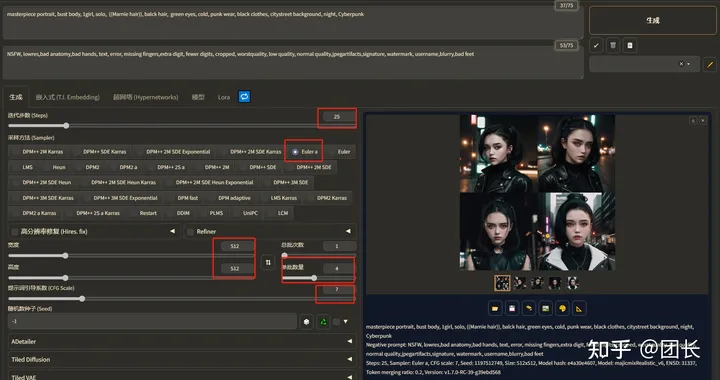
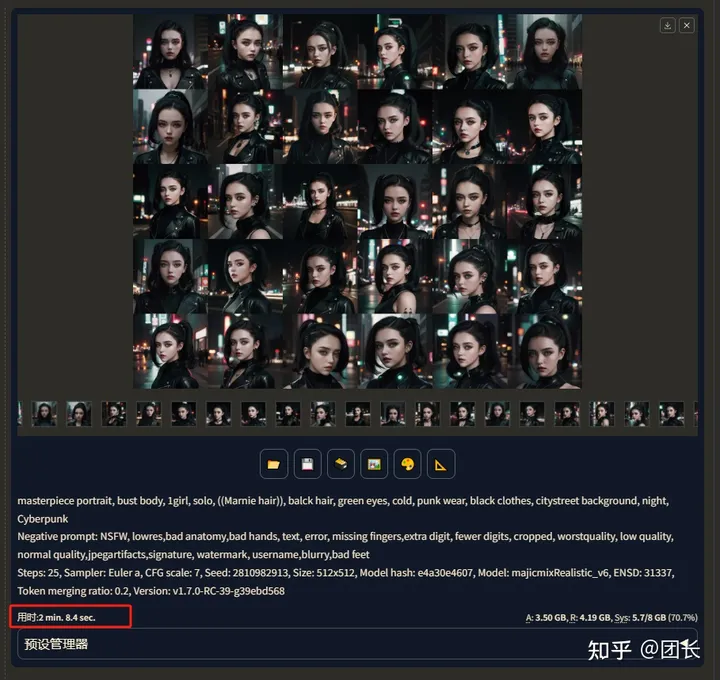
模型我这里选择了majicmixRealistic_v6,步数设置25步,采样选择euler a,长宽选择512x512,CFG选7,因为对比样本数需要大点,这里选择1次4张(不开面部重绘)
“prompt:masterpiece portrait, bust body, 1girl, solo, ((Marnie hair)), balck hair, green eyes, cold, punk wear, black clothes, citystreet background, night, Cyberpunk Negative prompt:NSFW, lowres,bad anatomy,bad hands, text, error, missing fingers,extra digit, fewer digits, cropped, worstquality, low quality, normal quality,jpegartifacts,signature, watermark, username,blurry,bad feet
我们先看看不开启TensorRT的速度(3070,8g),4张图速度(1次四张)
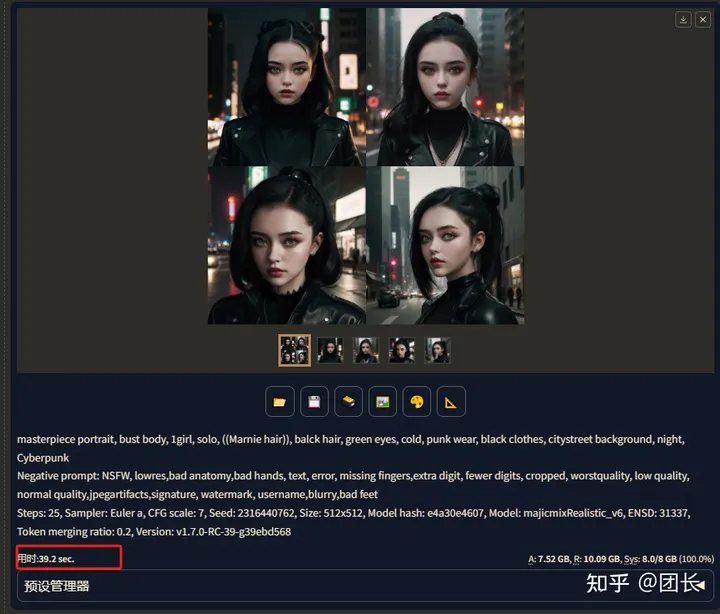
4张图用时39.2秒,我们再开启脸部修复试试(ADetailer)
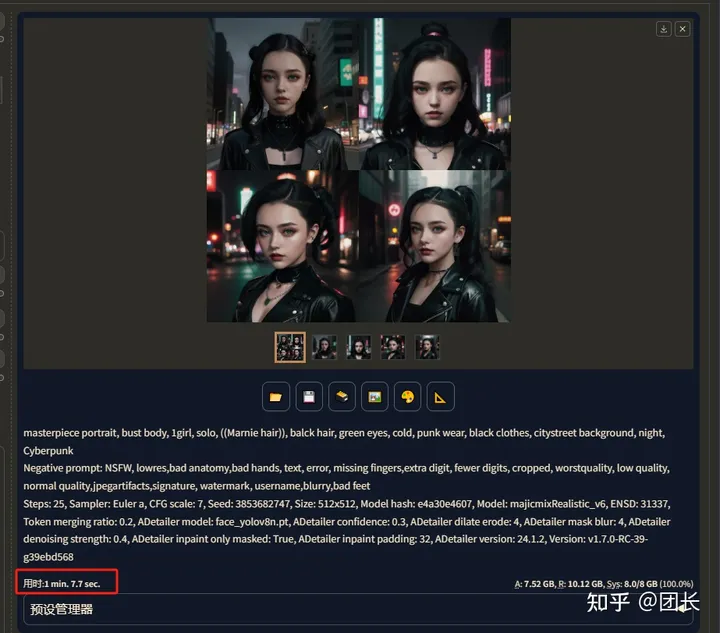
4张图用时67秒,着实挺慢的,我们打开TensorRT“加速”看看效果
开启加速后速度
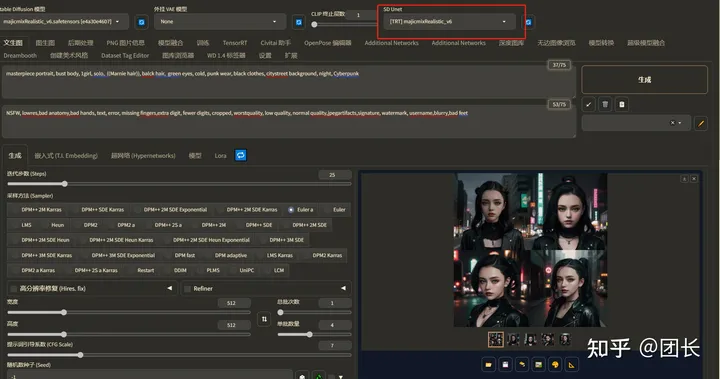
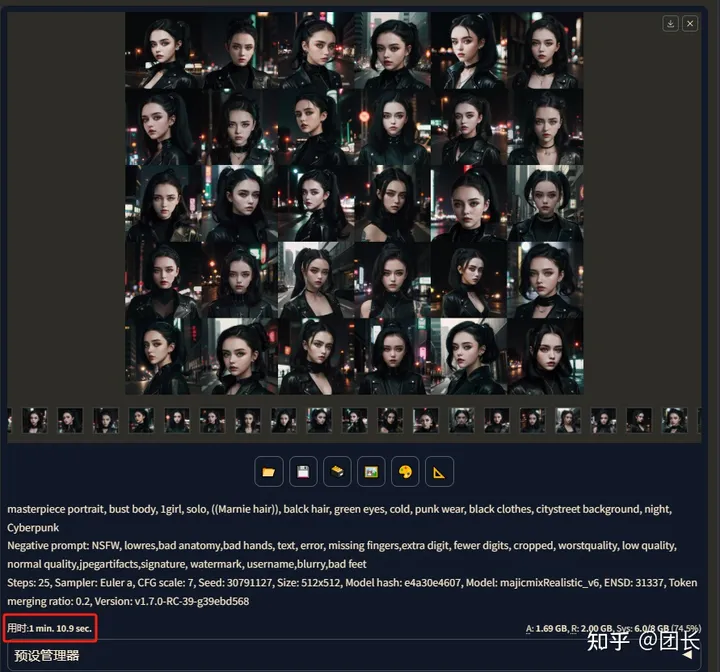
开启TensorRT加速,参数不变,先关闭ADetailer,同样出4张(1次四张)
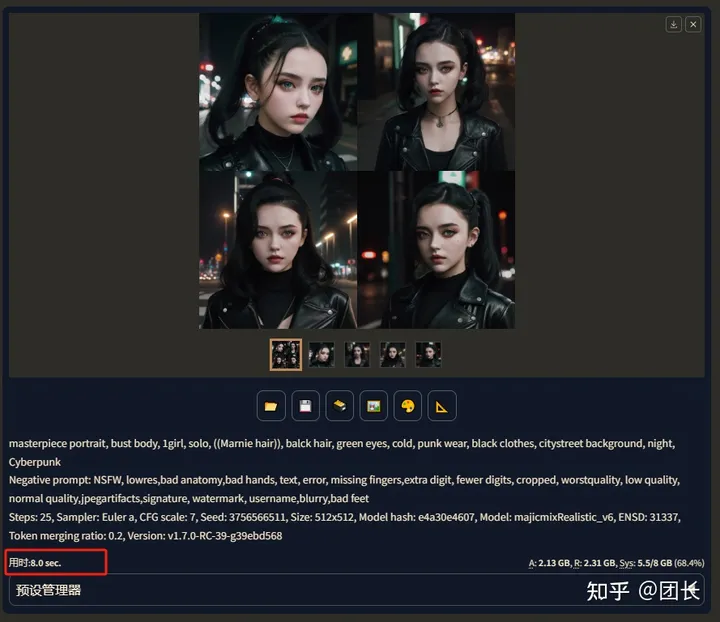
奇迹发生了!!仅仅8秒就完成了4张图的绘制!还记得我们不开之前是多少秒吗?对!39.2秒,生图速度提速至490%?是不是有点夸张?而且似乎也没怎么影响画质,这么神奇?我们再开启ADetailer试试
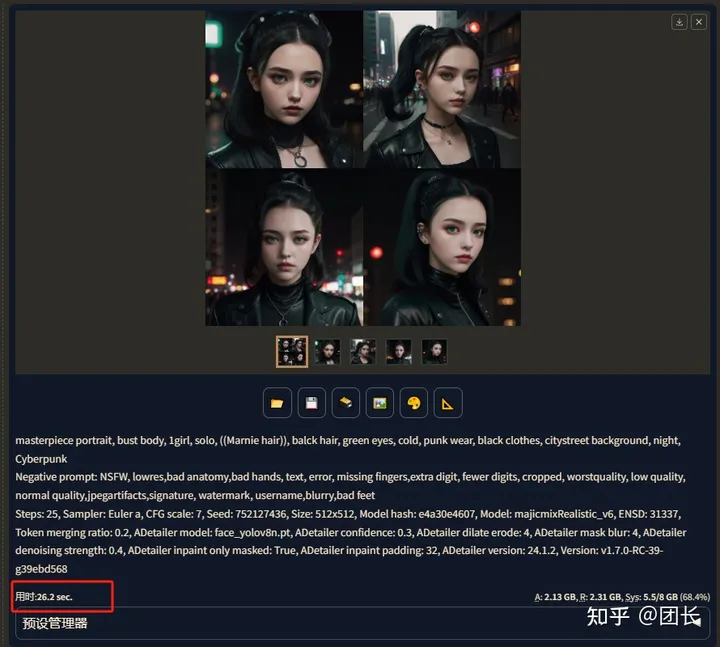
用时26.2秒,相较于没有开启TensorRT“加速”时大概提升至255%,画质也和未开启之前几乎一致。
最后为了减少概率,我们再生成一组30图的标准生图来对比下(30批次非数量)
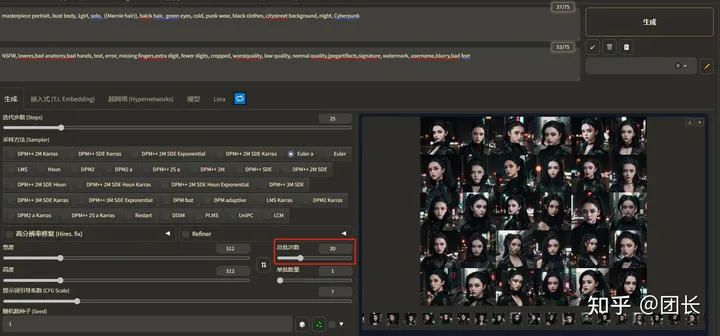
开启加速后30张图用时70.9秒
怎么有点不对劲?为啥一次4张和30批次的提速相差这么大?而且未加速状态下,为什么一次画4张图需要39.2秒?平均每张图近10秒,而30批次只需要128.4秒?每张图平均只需要4秒多呢?问题在哪里?
答案就在这里!
我们得出结论,不开加速情况下批量生产图,用“总批次数” 速度优于 “单批数量”,为了验证我们再试一组生成速度,共计28张图,不开加速的情况下,总批次数选择28,单批数量选择1, 28x1=28张
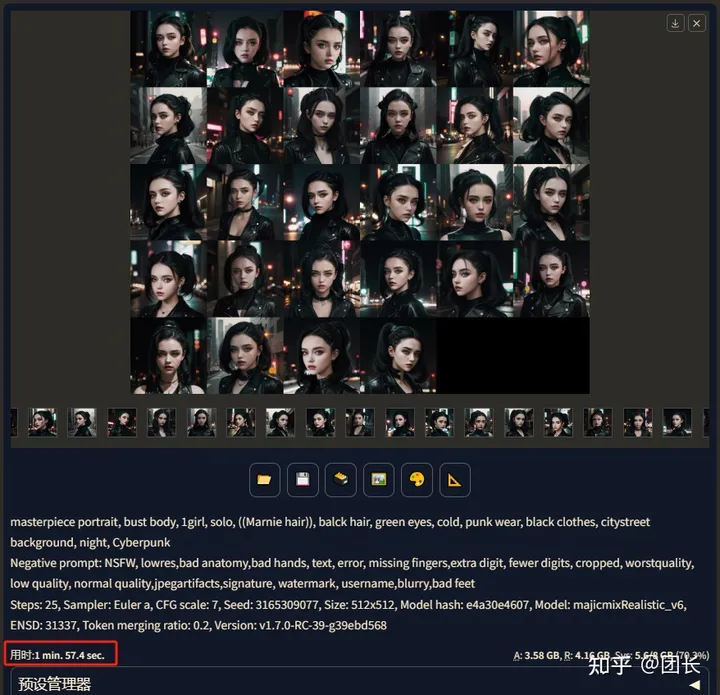
总用时117.4秒,注意看右边的显卡占用率70.3%。
再试试总批次数选择7,单批数量选择4,一共7x4=28张,试试多少秒

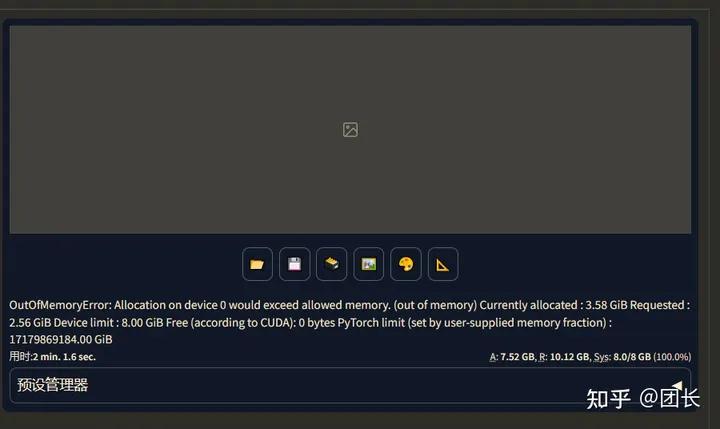
特喵的直接干爆我8g显存,也证明了单批数量4需要的显存远大于单批数量1,如果小显存还是老老实实选单批数量1
我们再开加速试试,也是一样,先测28x1的速度
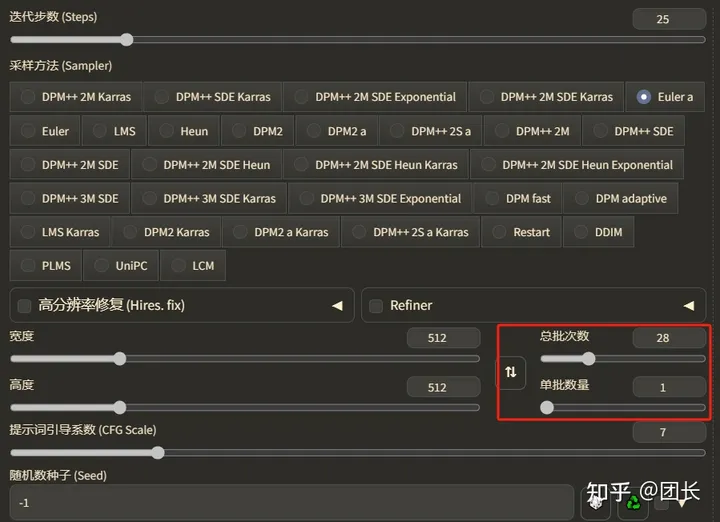
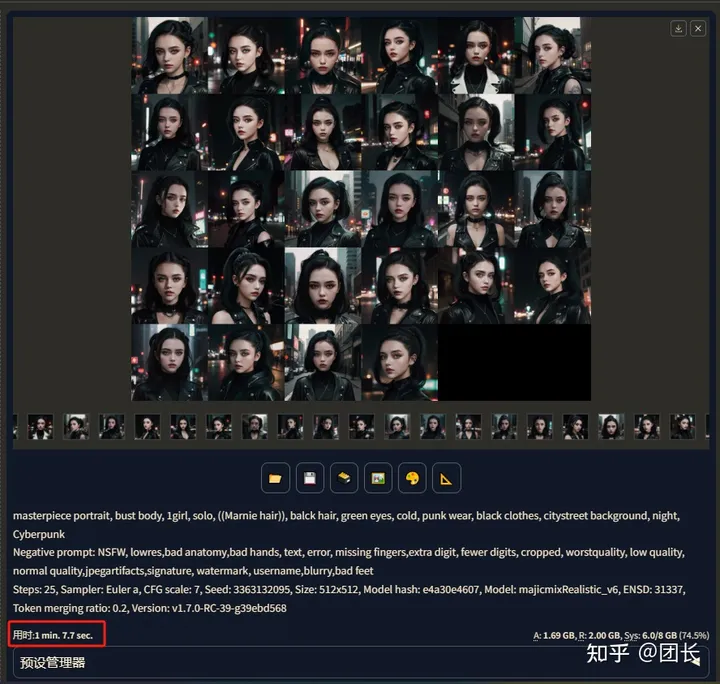
测出结果67.7秒,显卡占有率74.5%,再试试7x4加速(TensorRT最多单批数量4)

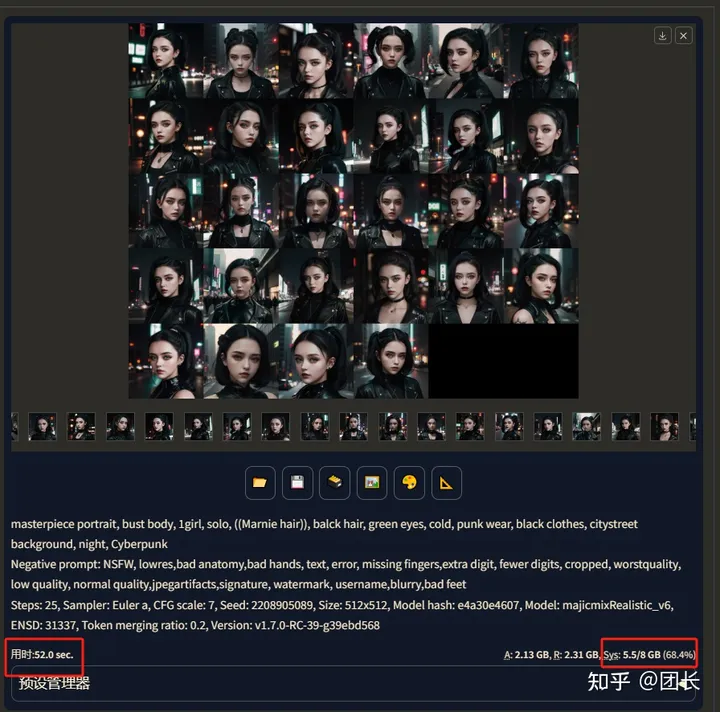
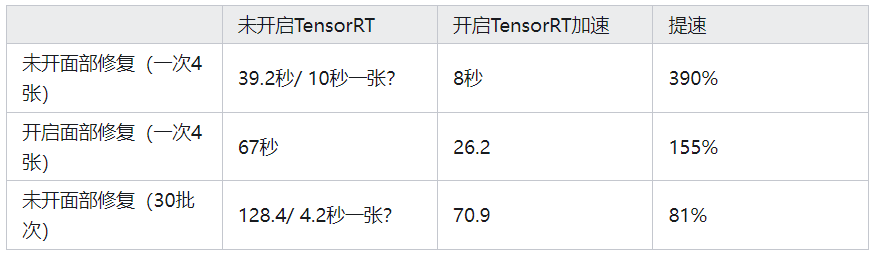
用时只需要52秒,且显卡占有率只有68.4%,统计表格如下

总结如下:
默认状态小显存不要开启“单批数量”,会严重拖累生图速度,占用大量显存资源
TensorRT对单批多图优化相当好,大幅度降低了显存占用和绘图时间
同参数下,TensorRT至少能提升100%的生图效率,着实厉害
TensorRT对生图质量几乎没影响
这么好用的工具,筒子们都迫不及待了吧?我们就看看如何安装和使用
安装和使用
NVIDIA显卡驱动更新:https://www.nvidia.cn/geforce/drivers/
GeForce Experience下载:https://www.nvidia.cn/geforce/geforce-experience/
TensorRT扩展地址:https://github.com/NVIDIA/Stable-Diffusion-WebUI-TensorRT
先更新N卡驱动,保证驱动版本是538.58或更高版本
然后打开SD,开始安装TensorRT!
方法1,从网址安装
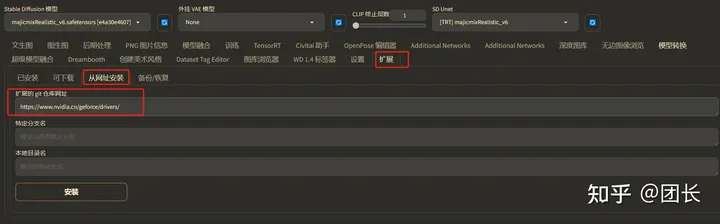
打开扩展- 从网页安装- 输入扩展地址“https://github.com/NVIDIA/Stable-Diffusion-WebUI-TensorRT.git”
点击安装完成后,重启webui和命令行,等待下载(注意,安装需要下载加速文件和相关模型,会占用1~2个GB,请检查硬盘空间和保证网速,如果无法下载请科学上网继续)
方法2,加载扩展列表安装
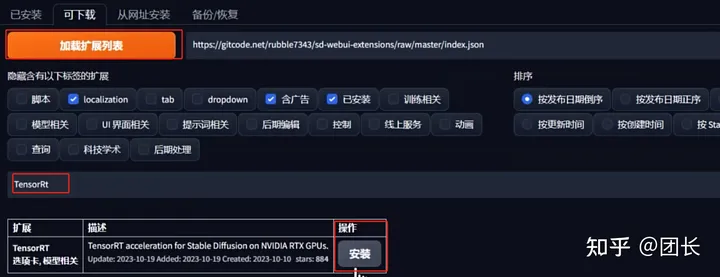
打开扩展- 可下载 -加载扩展列表,搜索TensorRT,一键安装(注意,安装需要下载加速文件和相关模型,会占用1~2个GB,请检查硬盘空间和保证网速,如果无法下载请科学上网继续)
配置TensorRT
重启命令行下载所需文件,下载完毕会打开webui,这时候我们就看到了TensorRT的选项
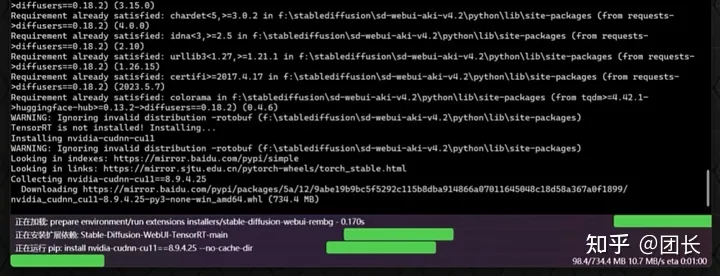
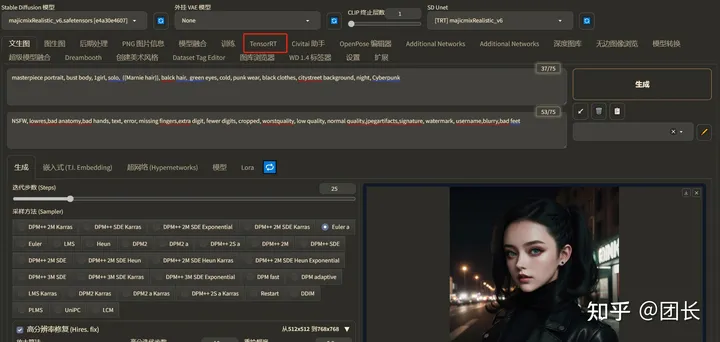
打开TensorRT发现有几种预设,我们先试试默认的预设(512x512,768x768,1024x1024),
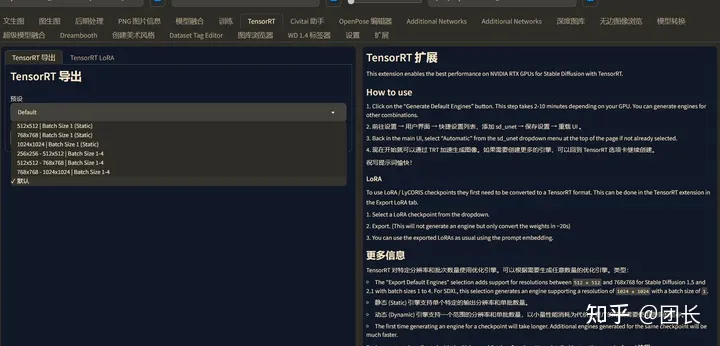
然后导出默认引擎,这时候开始生成TensorRT加速过的特定模型加速包(根据配置不等,需要2~10分钟生成)
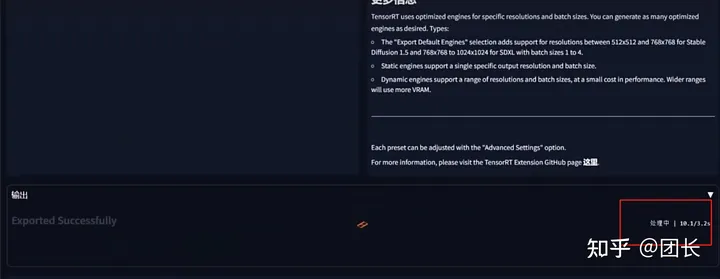
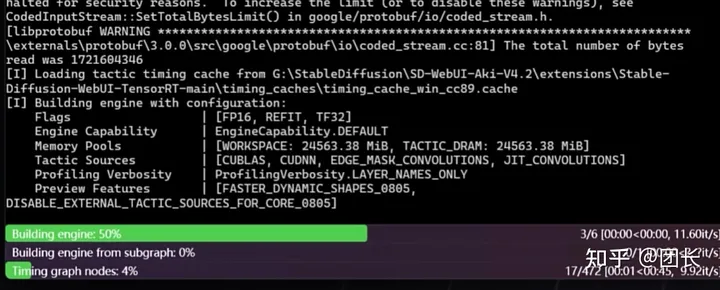
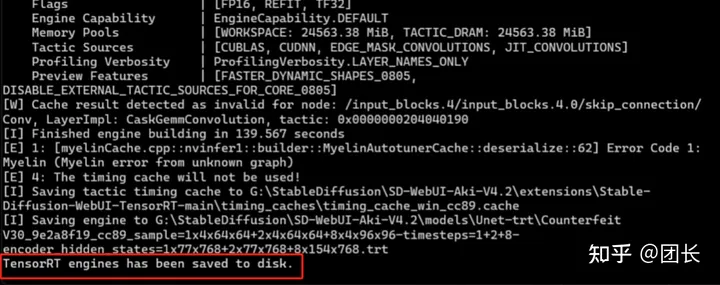
构建成功后会显示如图的内容,代表加速引擎构建成功。
然后在哪里启用这加速引擎呢?好像找不到?
其实这里需要手动操作下
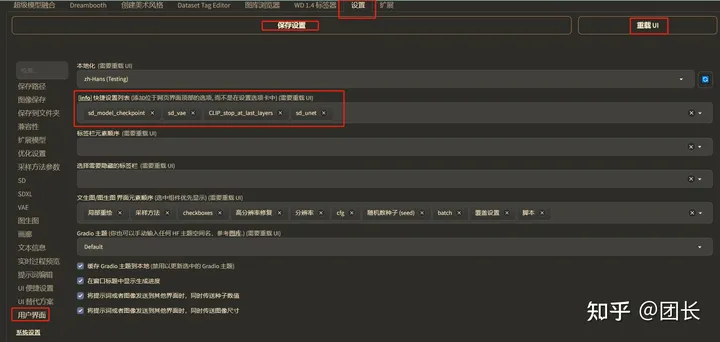
找到设置-用户界面-快捷设置,空白处点下
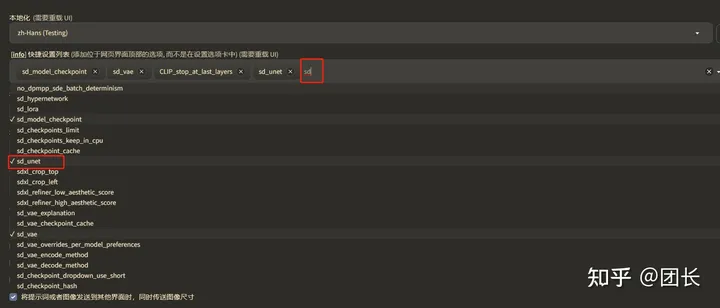
输入SD,找到sd_unet, 保存设置,然后重载UI
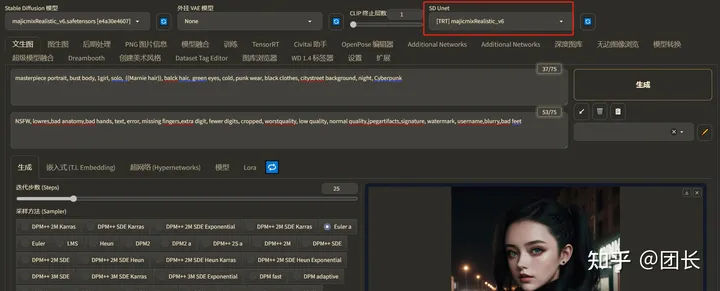
在SD Unet选择被构建的加速引擎即可,享受2系变3系,3系变4系的快感吧!

这里关于加速引擎有几点要说明:
加速引擎只针对当前被选中的模型,如果切换模型,需要重新构建新的加速引擎
模型不能有中文名,也不能放在中文目录下
加速引擎体积不小,每个占用大概在2G左右
高清绘制因为本质是两次绘图,所以需要再构建一个大分辨率的引擎(之后讲)
lora需要下载相关插件,将lora融入引擎(之后讲)
TensorRT非常合适大量抽卡&海量出图,或者总是使用一个模型或者同一分辨率的用户
现阶段TensorRT也存在一些小问题,欢迎大家讨论,下次我讲讲关于TensorRT的高级用法
祝大家赛博愉快!

投稿作者为『自动驾驶之心知识星球』特邀嘉宾,欢迎加入交流!
① 全网独家视频课程
BEV感知、毫米波雷达视觉融合、多传感器标定、多传感器融合、多模态3D目标检测、车道线检测、轨迹预测、在线高精地图、世界模型、点云3D目标检测、目标跟踪、Occupancy、cuda与TensorRT模型部署、大模型与自动驾驶、Nerf、语义分割、自动驾驶仿真、传感器部署、决策规划、轨迹预测等多个方向学习视频(扫码即可学习)

② 国内首个自动驾驶学习社区
国内最大最专业,近2700人的交流社区,已得到大多数自动驾驶公司的认可!涉及30+自动驾驶技术栈学习路线,从0到一带你入门自动驾驶感知(2D/3D检测、语义分割、车道线、BEV感知、Occupancy、多传感器融合、多传感器标定、目标跟踪)、自动驾驶定位建图(SLAM、高精地图、局部在线地图)、自动驾驶规划控制/轨迹预测等领域技术方案、大模型、端到端等,更有行业动态和岗位发布!欢迎扫描下方二维码,加入自动驾驶之心知识星球,这是一个真正有干货的地方,与领域大佬交流入门、学习、工作、跳槽上的各类难题,日常分享论文+代码+视频

③【自动驾驶之心】技术交流群
自动驾驶之心是首个自动驾驶开发者社区,聚焦2D/3D目标检测、语义分割、车道线检测、目标跟踪、BEV感知、多模态感知、Occupancy、多传感器融合、transformer、大模型、在线地图、点云处理、端到端自动驾驶、SLAM与高精地图、深度估计、轨迹预测、NeRF、Gaussian Splatting、规划控制、模型部署落地、cuda加速、自动驾驶仿真测试、产品经理、硬件配置、AI求职交流等方向。扫码添加汽车人助理微信邀请入群,备注:学校/公司+方向+昵称(快速入群方式)

④【自动驾驶之心】平台矩阵,欢迎联系我们!



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









