






编辑 | 机器之心
点击下方卡片,关注“自动驾驶之心”公众号
戳我-> 领取自动驾驶近15个方向学习路线
本文只做学术分享,如有侵权,联系删文
2024 年 5 月,DreamTech 官宣了其高质量 3D 生成大模型 Direct3D,并公开了相关学术论文 Direct3D: Scalable Image-to-3D Generation via 3D Latent Diffusion Transformer。

链接:https://arxiv.org/abs/2405.14832
这是首个公开发布的原生三维生成路线的 3D 大模型,通过采用 3D Diffusion Transformer (3D-DiT),解决了长期以来困扰行业的高质量三维内容生成难题。

坚持原生 3D 技术路线并取得突破
此前,3D AIGC 通常采用的技术路线是 2D-to-3D lifting,即通过 2D 图像模型升维得到 3D 模型,代表性方案包括早期以 Google 公司提出的 DreamFusion 为代表的 Score Distillation Sampling (SDS) ,以及以 Adobe 公司提出的 Instant3D 为代表的 Large Reconstruction Model (LRM)。虽然 3D 数据被逐步引入模型训练过程以提升质量,但 2D 升维技术存在多头多面、空腔、遮挡等固有问题,现有解决方案难以满足商业应用对通用三维生成的要求。
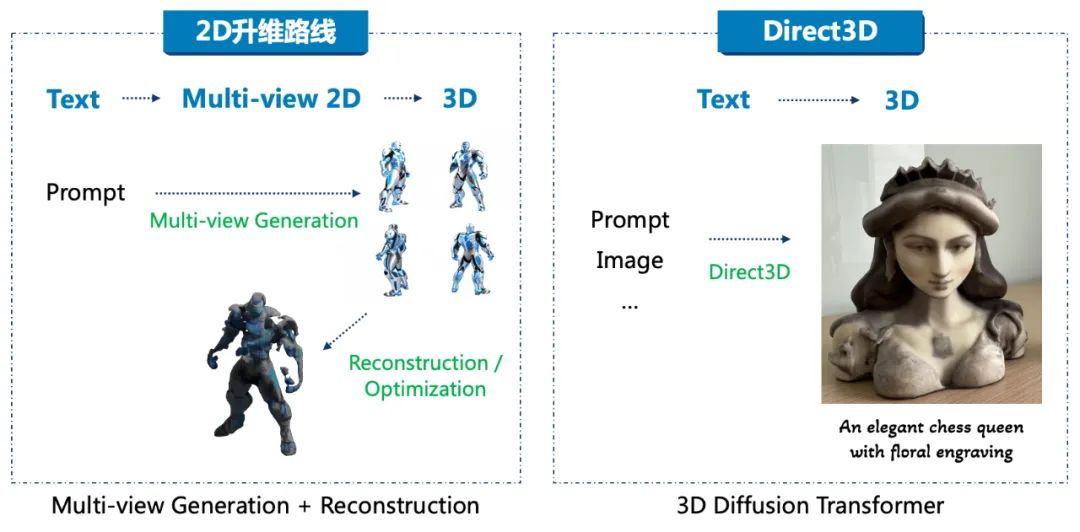
去年初,业内部分人员开始尝试原生 3D 路线,即不经过中间的多视角 2D 图片或者多视角迭代优化直接获得 3D 模型,这条技术路线可以避开 2D 升维的缺陷,展现了获取高质量、无畸形、无残缺、可商用 3D 内容的潜力。原生 3D 路线在原理上相较 2D 升维方法具有显著的优势,然而,其模型训练及算法开发一直存在诸多挑战,其中最关键的问题有:
高效的 3D 模型表征:图像和视频可以直接通过 2D/2.5D 的矩阵表征压缩获得 latent feature,相比之下, 3D 数据拓扑复杂、表征维度更高。如何对三维数据进行高效压缩,进而对 3D latent space 进行三维数据分布的分析与学习,是一直困扰行业人员的难题。
高效的 3D 训练架构: DiT 架构最先应用在图像生成领域并取得了巨大成功,包括 Stable Diffusion 3 (SD3)、Hunyuan-DiT 都采用了 DiT 架构;在视频生成领域,OpenAI SORA 采用 DiT 架构成功实现远超 Runway 和 Pika 的视频生成效果;而在 3D 生成领域,受限于复杂拓扑与三维表征方法,原始的 DiT 架构无法直接应用于 3D mesh 生成。
高质量大规模 3D 训练数据: 3D 训练数据的质量和规模直接决定了生成模型的质量及泛化能力,行业内普遍认为至少需要千万规模的高质量 3D 训练数据才可以达到 3D 大模型的训练要求。然而 3D 数据在全世界范围内都极其缺乏,尽管有诸如 ObjaverseXL 这样千万规模级别的 3D 训练数据集,但其中绝大多数都是低质量的简单结构,可用的高质量 3D 数据占比不足 5%。如何获得足够数量的高质量的 3D 数据是一个世界性的难题。
针对以上核心难题,DreamTech 提出了全球首个原生 3D-DiT 大模型 Direct3D。通过广泛的实验验证,Direct3D 的三维模型生成质量显著超越了目前主流的 2D 升维方法,这主要得益于以下三点:
D3D-VAE: Direct3D 提出了类似 OpenAI SORA 的 3D VAE (Variational Auto-Encoder) 来提取 3D 数据的 latent feature,将 3D 数据的表征复杂度从原本的 N^3 降低到了 n^2 (n<<N) 的紧凑 3D latent space,并通过 decoder 网络实现了对原始 3D mesh 近乎无损的恢复。通过使用 3D latent feature,Direct3D 将原本训练 3D-DiT 的运算和内存需求量降低了超过两个数量级,使得大规模 3D-DiT 模型训练成为了可能。
D3D-DiT: Direct3D 采用了 DiT 架构并对原始 DiT 进行了改进优化,引入了针对输入图像的语义级与像素级对齐模块,可实现输出模型与任意输入图像的高度对齐。
DreamTech 3D 数据引擎: Direct3D 在训练中使用了大量高质量 3D 数据,这些数据绝大部分由 DreamTech 自研的数据合成引擎制作而成。DreamTech 合成引擎建立了数据清洗、标注等全自动数据处理流程,已积累生产了超过 2000 万的高质量 3D 数据,补全了原生 3D 算法落地的最后一块拼图。值得一提的是,OpenAI 在 2023 年 Shap-E 和 Point-E 的训练过程中尝试使用了百万规模的 3D 合成数据,而对比 OpenAI 的数据合成方案,DreamTech 合成的 3D 数据规模更大,且质量更高。
采用 DiT 架构
3D 领域再次验证 Scaling Law
技术架构上,Direct3D 采用与 OpenAI SORA 相似的 Diffusion Transformer (DiT)。DiT 架构是当前最先进的 AIGC 大模型架构,结合了 Diffusion 与 Transformer 两大架构的优势,满足可扩展(Scalable)的要求,即提供给模型更多的数据量及更多的大模型参数量,DiT 可达到甚至超越人类的生成质量。目前 DiT 技术的实践项目包括图像生成方向上的 Stable Diffusion 3 (Stablility AI,2024 年 2 月)、Hunyuan-DiT (腾讯,2024 年 5 月),视频生成方向上的 SORA (OpenAI, 2024 年 2 月),DreamTech 的 Direct3D 则是全球首个公开的 3D 内容生成方向上的 DiT 实践。
DiT 架构符合并多次验证了 Scaling Law。
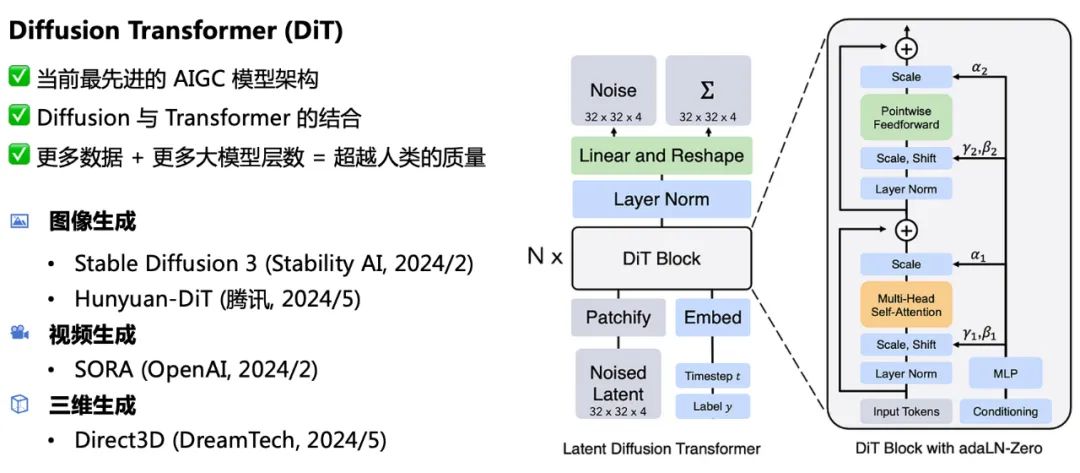
在大语言模型上,Scaling Law 已经充分证明了有效性,随着参数量和训练数据的增加,大模型的智能程度将极大提高;在图像生成领域上,从 SD1 的参数量 0.8B 到 SD3 的 8B, Dall-E 3 参数量 12B,都展示了 Scaling Law 的有效性;在视频生成领域,SORA 相比 Runway、Pika 等,据推测其技术实现上主要是将模型架构换成了 DiT,以及在模型参数量与训练数据上都提升了一个数量级,展示了震惊世界的生成效果,无论是视频分辨率、视频时长还是视频生成质量都得到了极大提升。
3D 领域也是如此,Direct3D-1B 向行业展示了首个可行的原生 3D-DiT 架构,利用自研的高质量数据合成引擎,增加训练数据量及增大模型参数量,生成结果稳步提升,未来 3D 生成领域将由 Direct3D (或其衍生架构) 完全取代现有的 LRM 或 SDS 方案。目前,DreamTech 团队正在稳步推进 Direct3D 的 scale up,计划年底前推出 15B 参数的 Direct3D-XL,同时将训练模型的高质量 3D 数据增加 5 倍以上,3D 生成届时将迎来里程碑时刻。
3D 内容生成质量达到商用级别
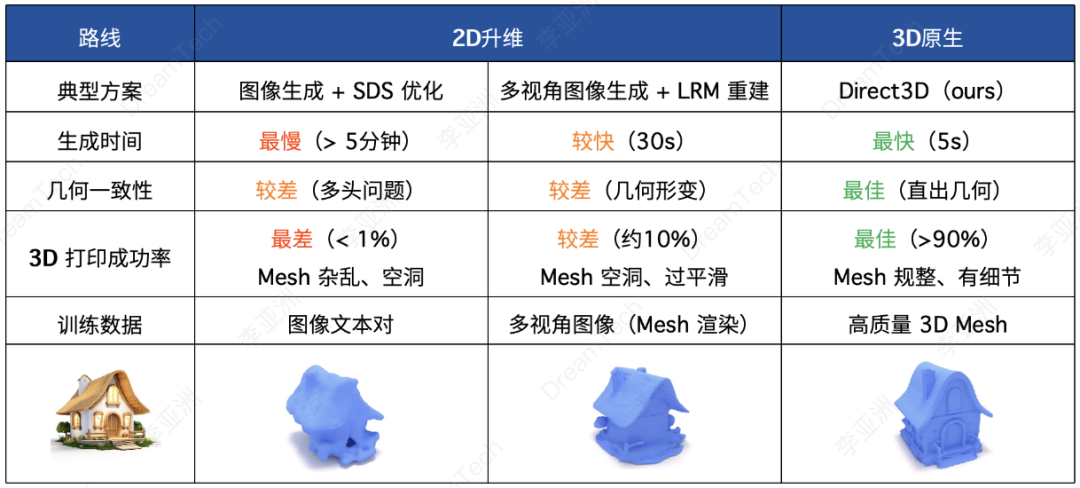
随着 Direct3D 的推出,3D 生成领域大步跨越进入了商用时代。以 3D 打印为例,使用 SDS、LRM 等技术方案生成的模型都会存在如下问题:
模型几何结构扭曲,容易出现多头多尾;
模型存在很多尖锐的毛刺;
表面过度平滑,缺少细节;
mesh 面片数少,精细结构无法保证。
这些问题的存在导致此前各类方案生成的模型无法在 3D 打印机中正常打印,还需要人工进行调整修补。Direct3D 因为采取的是原生 3D 技术路线,训练集中仅使用 3D 数据,其所生成的 3D 模型质量也更接近原始质量,完美解决了几何结构、模型精度、表面细节、mesh 面片数量等核心问题。Direct3D 所生成的模型质量已经超出了家用打印机的精度上限,只有更高规格的商用及工业打印机才能充分还原所生成模型的精细度。

此前, SDS、LRM 等技术方案受限于 3D 模型特征表达形式,一般生成的模型 mesh 面片数都在 5-20 万左右,且很难再提高,然而在商业使用中,3D 模型的 mesh 面片数量往往需要达到 100-500 万以上。Direct3D 提出了更精细的 3D 特征表达范式,使得所生成的模型 mesh 面片数没有上限,可以达到并超过 1000 万,满足各类商业场景需要。
随着 Direct3D 模型参数量及训练数据量的增加,3D 生成可以应用到的行业会越来越多,包括万亿级别的游戏、动漫行业,预计在 2025 年底之前,3D 生成将实现大部分游戏、动画、影视建模的替代工作,在各行业大规模投入使用。
Direct3D 实践
基于 Direct3D 大模型,DreamTech 推出了两款尝鲜产品,目前已经开放申请测试(点击阅读原文,跳转:www.neural4d.com)。
其一是面向 C 端用户的 Animeit!,Animeit! 可将用户输入的任意图片 / 文字对象转换为二次元风格的高质量 3D 人物形象,并且 3D 人物具备骨骼节点以用于动作绑定,在 Animeit! 上用户可以与个性化的 3D AI 伙伴直接对话并进行动作交互。
Animeit! 所生成的二次元角色精细度极高,脸部轮廓细节清晰可辨,手部细节凸显、手指粒粒分明,这是此前的 3D 生成技术路线无法达到的质量水平,已可用于二次元社区 MMD 制作。
另一款产品则为面向创作者的 3D 内容创作平台,用户可以像使用 Midjourney 这类平台一样,通过文本描述在 1 分钟之内获得高质量 3D 模型,不需要等待长时间的 refinement;用户也可以仅上传单张图片,稍作等待即可获得高质量且还原精准的 3D 模型。
关于 DreamTech
DreamTech 深耕于 3D AI 技术领域,致力于用创新的产品和服务提升全球 AIGC 创作者及消费者的使用体验,公司的愿景是利用先进的 AI 技术打造与真实世界无缝对接、实时互动的 4D 时空体验,并通过模拟真实世界的复杂性和多样性实现通用人工智能 (AGI)。
DreamTech 汇集了全球顶尖的 AI 人才,其创始团队由英国两院院士、国家级青年人才以及多位深圳市高层次人才组成。公司的核心成员毕业于牛津大学、香港中文大学、香港科技大学等世界知名学府,并曾在苹果、腾讯、百度等行业领先企业任职,创始团队成员曾成功创立多家成为 3D 领域标杆的公司,这些公司后被苹果、谷歌、博世等业界巨头收购。
投稿作者为『自动驾驶之心知识星球』特邀嘉宾,欢迎加入交流!
① 全网独家视频课程
BEV感知、BEV模型部署、BEV目标跟踪、毫米波雷达视觉融合、多传感器标定、多传感器融合、多模态3D目标检测、车道线检测、轨迹预测、在线高精地图、世界模型、点云3D目标检测、目标跟踪、Occupancy、cuda与TensorRT模型部署、大模型与自动驾驶、Nerf、语义分割、自动驾驶仿真、传感器部署、决策规划、轨迹预测等多个方向学习视频(扫码即可学习)

② 国内首个自动驾驶学习社区
国内最大最专业,近3000人的交流社区,已得到大多数自动驾驶公司的认可!涉及30+自动驾驶技术栈学习路线,从0到一带你入门自动驾驶感知(2D/3D检测、语义分割、车道线、BEV感知、Occupancy、多传感器融合、多传感器标定、目标跟踪)、自动驾驶定位建图(SLAM、高精地图、局部在线地图)、自动驾驶规划控制/轨迹预测等领域技术方案、大模型、端到端等,更有行业动态和岗位发布!欢迎扫描下方二维码,加入自动驾驶之心知识星球,这是一个真正有干货的地方,与领域大佬交流入门、学习、工作、跳槽上的各类难题,日常分享论文+代码+视频

③【自动驾驶之心】技术交流群
自动驾驶之心是首个自动驾驶开发者社区,聚焦感知、定位、融合、规控、标定、端到端、仿真、产品经理、自动驾驶开发、自动标注与数据闭环多个方向,目前近60+技术交流群,欢迎加入!扫码添加汽车人助理微信邀请入群,备注:学校/公司+方向+昵称(快速入群方式)

④【自动驾驶之心】全平台矩阵















 637
637











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









