






点击下方卡片,关注“自动驾驶之心”公众号
戳我-> 领取自动驾驶近15个方向学习路线
编辑 | 极市平台

文章链接:https://arxiv.org/pdf/2408.16768
在线Demo: https://huggingface.co/spaces/ZiyuG/SAM2Point
Code链接:https://github.com/ZiyuGuo99/SAM2Point
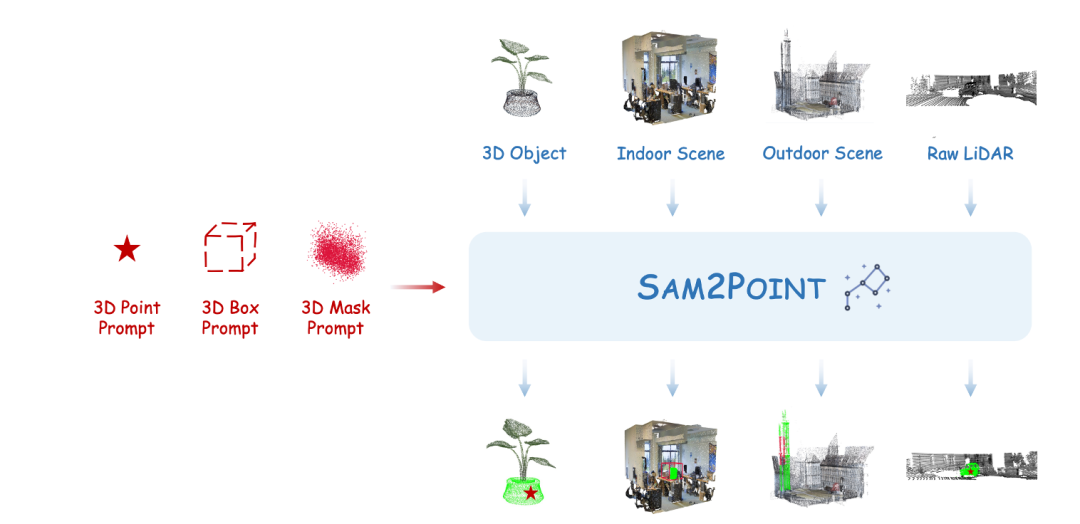
重点概述:
1.无需投影到2D的SAM 2分割方案:SAM2POINT 通过将 3D 数据体素化为视频格式,避免了复杂的 2D至3D 的投影,实现了高效的零样本 3D 分割,同时保留了丰富的空间信息。
2.支持任意用户提示(Prompt):该方法支持 3D 点、3D框和Mask三种提示类型,实现了灵活的交互式分割, 增强了 3D 分割的精确度和适应性。
3.泛化任何3D场景:SAM2POINT 在多种 3D 场景中表现出优越的泛化能力,包括单个物体、室内场景、室外场景和原始 LiDAR 数据, 显示了良好的跨领域转移能力。
SAM2POINT,是3D可提示分割领域的初步探索,将 Segment Anything Model 2(SAM 2)适配于零样本和可提示的3D分割。SAM2POINT 将任何 3D 数据解释为一系列多方向视频,并利用 SAM2 进行3D空间分割,无需进一步训练或 2D至3D 投影。SAM2POINT框架支持多种提示类型,包括 3D 点、 3D框和3D Mask,并且可以在多种不同场景中进行泛化,例如 3D 单个物体、室内场景、室外场景和原始激光雷达数据( LiDAR)。在多个3D 数据集上的演示,如 Objaverse、S3DIS、ScanNet、Semantic3D 和 KITTI,突出了 SAM2POINT 的强大泛化能力。据我们所知,这是SAM在3D中最忠实的实现,可能为未来可提示的3D分割研究提供一个起点。
SAM2Point的动机与方法创新
Segment Anything Model(SAM)已经建立了一个卓越且基础的交互式图像分割框架。基于其强大的迁移能力,后续研究将SAM扩展到多样的视觉领域,例如个性化物体、医学影像和时间序列。更近期的Segment Anything Model 2(SAM 2)提出了在视频场景中的印象深刻的分割能力,捕捉复杂的现实世界动态。
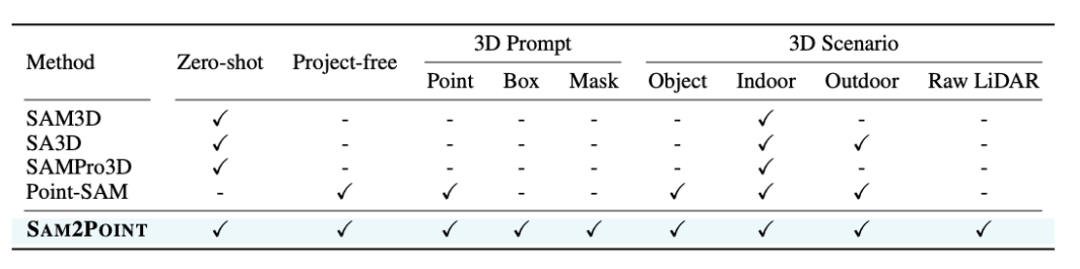
尽管如此,如何有效地将SAM适应于3D分割仍然是一个未解决的挑战。表1列举了前期工作的主要问题,这些问题阻碍了充分利用SAM的优势:
2D到3D投影的效率低。 考虑到2D和3D之间的领域差距,大多数现有工作将3D数据表示为其2D对应输入给SAM,并将分割结果反向投影到3D空间,例如使用额外的RGB图像、多视图渲染或神经辐射场。这种模态转换引入了显著的处理复杂性,阻碍了有效的实施。
3D空间信息的退化。 依赖2D投影导致了精细的3D几何形态和语义的丢失,多视图数据常常无法保留空间关系。此外,3D物体的内部结构不能被2D图像充分捕获,显著限制了分割精度。
提示灵活性的丧失。 SAM的一个引人注目的优点是通过各种提示替代品的交互能力。不幸的是,这些功能在当前方法中大多被忽视,因为用户难以使用2D表示来精确指定3D位置。因此,SAM通常用于在整个多视图图像中进行密集分割,从而牺牲了交互性。
有限的领域迁移能力。 现有的2D-3D投影技术通常是为特定的3D场景量身定制的,严重依赖于领域内的模式。这使得它们难以应用于新的环境,例如从物体到场景或从室内到室外环境。另一个研究方向旨在从头开始训练一个可提示的3D网络。虽然绕过了2D投影的需要,但它需要大量的训练和数据资源,可能仍受训练数据分布的限制。
相比之下,SAM2POINT将SAM 2适应于高效、无投影、可提示和零样本的3D分割。 作为这一方向的初步步骤,SAM2POINT的目标不在于突破性能极限,而是展示SAM在多种环境中实现强大且有效的3D分割的潜力。
效果展示
图2-图7展示了 SAM2POINT 在使用不同 3D 提示对不同数据集进行 3D 数据分割的演示,其中3D提示用红色表示,分割结果用绿色表示:



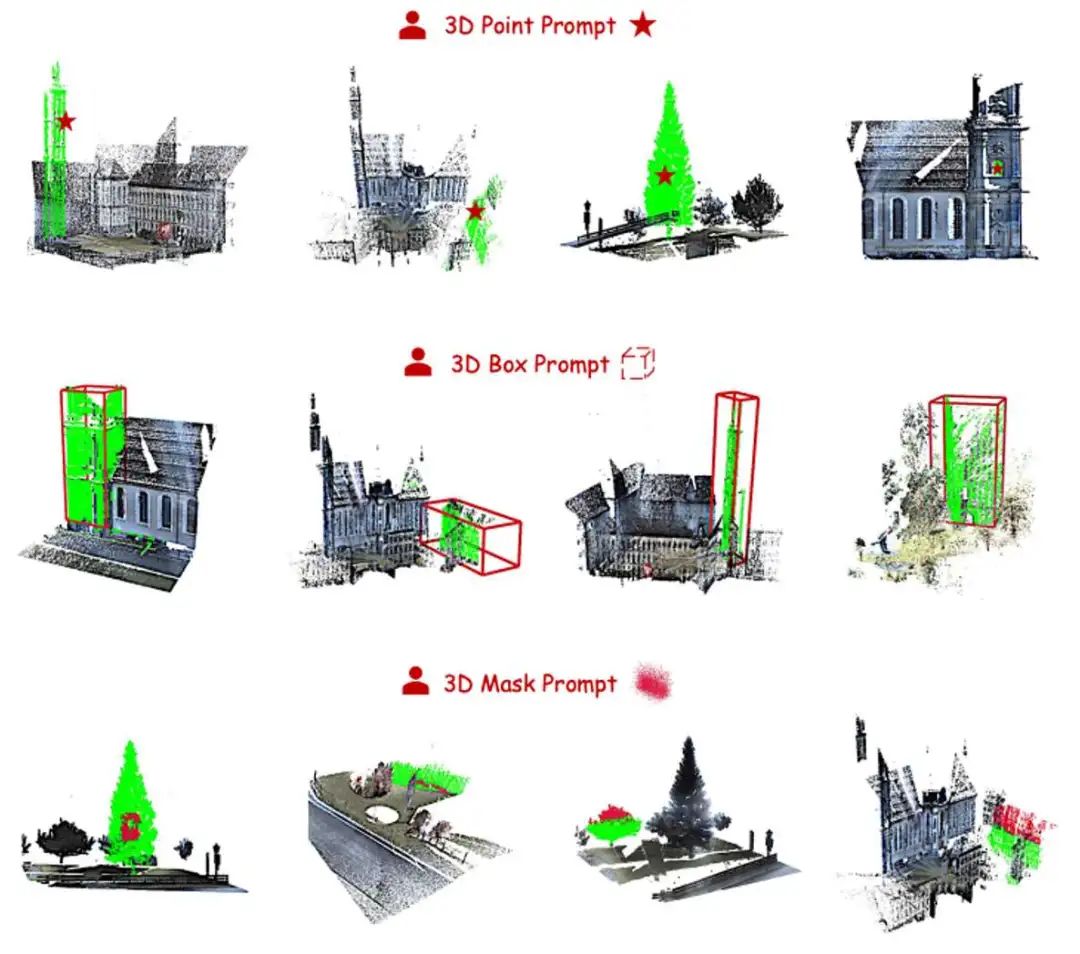

SAM2Point的3D物体的多方向视频:
SAM2Point的3D室内场景多方向视频:
SAM2Point的3D室外场景多方向视频:
SAM2Point的3D原始激光雷达的多方向视频:
SAM2POINT方法详述
SAM2POINT 的详细方法如下图所示。下面介绍了 SAM2POINT 如何高效地处理 3D 数据以适配 SAM 2, 从而避免复杂的投影过程。接下来, 以及详细说明了支持的三种 3D 提示类型及其相关的分割技术。最后, 展示了 SAM2POINT 有效解决的四种具有挑战性的 3D 场景。
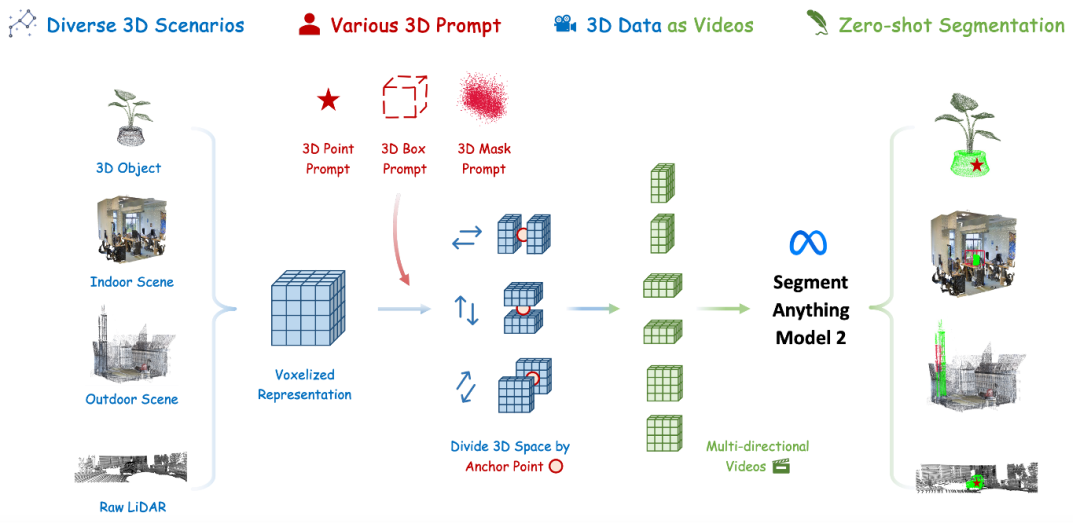
3D 数据作为视频
对于任何物体级或场景级的点云, 用 表示, 每个点为 。本文的目标是将 转换为一种数据格式, 这种格式一方面能使 SAM 2 以零样本的方式直接处理, 另一方面能够很好地保留细粒度的空间几何结构。为此, SAM2Point 采用了 3D 体素化技术。与 RGB 图像映射、多视角渲染和 和神经辐射场(NeRF)等先前工作相比,体素化在 3D 空间中的执行效率更高,且不会导致信息退化和繁琐的后处理。
通过这种方式, 获得了 3D 输入的体素化表示, 记作 , 每个体素为 。为了简化, 值根据距离体素中心最近的点设置。这种格式与形状为 的视频非常相似。主要区别在于, 视频数据包含在 t 帧之间的单向时间依赖性, 而 3D 体素在三个空间维度上是各向同性的。考虑到这一点, SAM2Point 将体素表示转换为一系列多方向的视频, 从而启发 SAM 2 以与处理视频相同的方式来分割 3D 数据。
可提示分割
为了实现灵活的交互性, SAM2POINT 支持三种类型的 3D 提示, 这些提示可以单独或联合使用。以下详细说明提示和分割细节:
3D 点提示, 记作 。首先将 视为 3D 空间中的针点, 以定义三个正交的 2D 截面。从这些截面开始, 我们沿六个空间方向将 3D 体素分为六个子部分, 即前、后、左、右、上和下。接着, 我们将它们视为六个不同的视频,其中截面作为第一帧, 被投影为 2D 点提示。应用 SAM 2 进行并行分割后,将六个视频的结果整合为最终的 3D mask 预测。
3D 框提示, 记作 ,包括 3D 中心坐标和尺寸。我们采用 的几何中心作为针点,并按照上述方法将 3D 体素表示为六个不同的视频。对于某一方向的视频, 我们将 投影到相应的 2D 截面,作为分割的框点。我们还支持具有旋转角度的 3D 框,例如 ,对于这种情况,采用投影后的 的边界矩形作为 2D 提示。
3D mask提示,记作,其中 1 或 0 表示mask区域和非mask区域。使用mask提示的质心作为锚点,同样将3D空间分为六个视频。3D mask提示与每个截面的交集被用作 2D mask提示进行分割。这种提示方式也可以作为后期精炼步骤, 以提高先前预测的 3D mask的准确性。
任意3D场景
通过简洁的框架设计,SAM2POINT在不同领域表现出卓越的零样本泛化性能,涵盖从物体到场景,从室内到室外环境。以下详细介绍四种不同的 3D 场景:
3D 单个物体, 如 Objaverse, 拥有广泛的类别, 具有不同实例的独特特征, 包括颜色、形状和几何结构。对象的相邻组件可能会重叠、遮挡或与彼此融合, 这要求模型准确识别细微差别以进行部分分割。
3D室内场景, 如 S3DIS和 ScanNet, 通常以多个物体在有限空间内(如房间)排列的特点为主。复杂的空间布局、外观相似性以及物体之间不同的方向性,为模型从背景中分割物体带来挑战。
3D 室外场景, 如 Semantic3D, 与室内场景主要不同在于物体(建筑、车辆和人)之间的明显大小对比以及点云的更大规模(从一个房间到整条街道)。这些变化使得无论是全局还是细粒度层面的物体分割都变得复杂。
原始激光雷达数据(LIDAR), 例如用于自动驾驶的KITTI(Geiger等人,2012),与典型点云不同,其特点是稀疏分布和缺乏RGB信息。稀疏性要求模型推断缺失的语义以理解场景,而缺乏颜色则强迫模型只依靠几何线索来区分物体。在SAM2POINT中,我们直接根据激光雷达的强度设置3D体素的RGB值。
讨论与洞察
基于SAM2POINT的有效性,文章深入探讨了3D领域中两个引人注目但具有挑战性的问题,并分享了作者对未来多模态学习的见解。
如何将2D基础模型适应到3D?
大规模高质量数据的可用性显著促进了语言和视觉-语言领域大型模型的发展。相比之下,3D领域长期以来一直面临数据匮乏的问题,这阻碍了大型3D模型的训练。因此,研究人员转而尝试将预训练的2D模型转移到3D中。
主要挑战在于桥接2D和3D之间的模态差距。如PointCLIP V1及其V2版本和后续方法等开创性方法,将3D数据投影成多视角图像,这遇到了实施效率低和信息丢失的问题。另一条研究线,包括ULIP系列、I2P-MAE及其他,采用了使用2D-3D配对数据的知识蒸馏。虽然这种方法由于广泛的训练通常表现更好,但在非域场景中的3D迁移能力有限。
近期的努力还探索了更复杂且成本更高的解决方案,例如联合多模态空间(例如Point-Bind & Point-LLM),大规模预训练(Uni3D)和虚拟投影技术(Any2Point)。
从SAM2POINT我们观察到,通过体素化将3D数据表示为视频可能提供了一个最佳解决方案,提供了性能和效率之间的平衡折衷。这种方法不仅以简单的转换保留了3D空间中固有的空间几何形状,还呈现了一种2D模型可以直接处理的基于网格的数据格式。尽管如此,仍需要进一步的实验来验证并加强这一观察。
SAM2POINT在3D领域的潜力是什么?
SAM2POINT展示了SAM在3D中最准确和全面的实现,成功继承了其实施效率、可提示的灵活性和泛化能力。虽然之前基于SAM的方法已经实现了3D分割,但它们在可扩展性和迁移到其他3D任务的能力方面往往表现不足。相比之下,受到2D领域SAM的启发,SAM2POINT展现了推进各种3D应用的重大潜力。
对于基本的3D理解,SAM2POINT可以作为一个统一的初始化主干,进一步微调,同时为3D物体、室内场景、室外场景和原始激光雷达提供强大的3D表示。在训练大型3D模型的背景下,SAM2POINT可以作为自动数据标注工具,通过在不同场景中生成大规模分割标签来缓解数据稀缺问题。对于3D和语言视觉学习,SAM2POINT天生提供了一个跨2D、3D和视频领域的联合嵌入空间,由于其零样本能力,这可能进一步增强模型的效果,如Point-Bind。此外,在开发3D大语言模型(LLMs)的过程中,SAM2POINT可以作为一个强大的3D编码器,为LLMs提供3D Tokens,并利用其可提示的特征为LLMs装备可提示的指令遵循能力。
总结
SAM2Point, 利用 Segment Anything 2 (SAM 2) 实现了零样本和可提示的3D分割框架。通过将 3D 数据表示为多方向视频, SAM2POINT 支持多种类型的用户提供的提示 (3D 点、3D框和3D mask), 并在多种 3D 场景(3D 单个物体、室内场景、室外场景和原始稀疏激光雷达)中展现出强大的泛化能力。作为一项初步探索,SAM2POINT为有效和高效地适应SAM 2以理解3D提供了独特的见解。希望SAM2Point能成为可提示3D分割的基础基准,鼓励进一步的研究,以充分利用SAM 2在3D领域的潜力。
参考文献
[1] SAM2Point: Segment Any 3D as Videos in Zero-shot and Promptable Manners.
投稿作者为『自动驾驶之心知识星球』特邀嘉宾,欢迎加入交流!重磅,自动驾驶之心科研论文辅导来啦,申博、CCF系列、SCI、EI、毕业论文、比赛辅导等多个方向,欢迎联系我们!

① 全网独家视频课程
BEV感知、BEV模型部署、BEV目标跟踪、毫米波雷达视觉融合、多传感器标定、多传感器融合、多模态3D目标检测、车道线检测、轨迹预测、在线高精地图、世界模型、点云3D目标检测、目标跟踪、Occupancy、cuda与TensorRT模型部署、大模型与自动驾驶、Nerf、语义分割、自动驾驶仿真、传感器部署、决策规划、轨迹预测等多个方向学习视频(扫码即可学习)
 网页端官网:www.zdjszx.com
网页端官网:www.zdjszx.com
② 国内首个自动驾驶学习社区
国内最大最专业,近3000人的交流社区,已得到大多数自动驾驶公司的认可!涉及30+自动驾驶技术栈学习路线,从0到一带你入门自动驾驶感知(2D/3D检测、语义分割、车道线、BEV感知、Occupancy、多传感器融合、多传感器标定、目标跟踪)、自动驾驶定位建图(SLAM、高精地图、局部在线地图)、自动驾驶规划控制/轨迹预测等领域技术方案、大模型、端到端等,更有行业动态和岗位发布!欢迎扫描下方二维码,加入自动驾驶之心知识星球,这是一个真正有干货的地方,与领域大佬交流入门、学习、工作、跳槽上的各类难题,日常分享论文+代码+视频

③【自动驾驶之心】技术交流群
自动驾驶之心是首个自动驾驶开发者社区,聚焦感知、定位、融合、规控、标定、端到端、仿真、产品经理、自动驾驶开发、自动标注与数据闭环多个方向,目前近60+技术交流群,欢迎加入!扫码添加汽车人助理微信邀请入群,备注:学校/公司+方向+昵称(快速入群方式)

④【自动驾驶之心】全平台矩阵


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









