






作者 | 黄哲威 hzwer 编辑 | 自动驾驶之心
原文链接:https://zhuanlan.zhihu.com/p/9140786426
点击下方卡片,关注“自动驾驶之心”公众号
戳我-> 领取自动驾驶近15个方向学习路线
本文只做学术分享,如有侵权,联系删文
本文希望先跳过很多不熟悉的名词和定理,找出我认为适合初学者理解的部分,下一篇文章 [生成模型 2] 整流流 Rectified Flow 理论简介
有个完整理解后,再看 ewrfcas:由浅入深了解Diffusion Model 就不会觉得害怕
本文大量参考了网上文献和使用 跃问 辅助,如有纰漏求指正
主要参考的是苏神的 生成扩散模型漫谈(一):DDPM = 拆楼 + 建楼 和 生成扩散模型漫谈(二):DDPM = 自回归式VAE,DDPM 论文
假设读者记得一些概率论的基本知识,如果忘了可以移步 Deja vu:一文带你看懂DDPM和DDIM(含原理简易推导,pytorch代码) 看前置知识
核心价值 以能量模型为抓手,将得分匹配下沉到朗之万方程的动态轨迹,打通马尔可夫链底层逻辑,发力变分推断引爆点,形成去噪过程递归闭环,拉通前向-反向全链路,卡位生成模型赛道,造势图像生成风口,布局多模态蓝海,沉淀噪声调度护城河,赋能潜在空间表征,倒逼模型优化,输出高质量样本反馈,升华生成建模格局,重塑数据生成认知矩阵,击穿传统生成模型研究员心智,打出一套组合拳。
生成扩散模型介绍
从 2019 BigGAN 可以生成 ImageNet 某一类别的 128p 图片,2022-2023 的 DALLE-2/3 又是新的里程碑

用卷积神经网络做图像任务,模型性能随着模型参数 / 训练数据量增加,其实经常是边际收益递减的
我理解 transformer 流行的一个原因是在模型放大时能有不错的边际收益,而生成扩散模型则找到了一种可以在推理时使用非常大算力来提升效果的范式,这两者实现它们和卷积神经网络的差异化
分步扩散和生成
我们的目标是一个生成模型,它从随机噪声 z 变成数据样本 x

如果我们能把中间扩散的每一步的逆过程 生成 建模出来,得到一个生成函数:=()(2)
然后从随机噪声 z 开始,生成 T 步就得到了 x
CV+DL 白话:训练的时候,随机采样数据 x 和步数 t,学到的变换模型,推理的时候,从一个随机高斯噪声递归调用 T 步学出来的模型得到生成结果
具体来说,DDPM 的扩散过程是
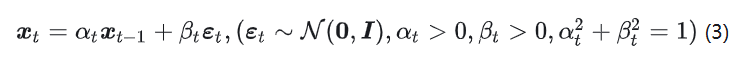
其一般形式来自 Variational Diffusion ModelsVariational Diffusion Models

之后推导中可以把系数看作是我们选的常数项

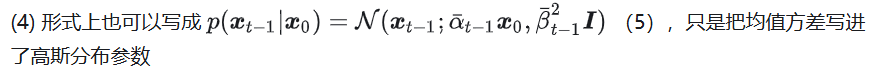


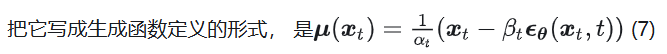
这里可以看到可训练参数是噪声项的下标,表示我们实际上是在预测第 t 步添加到数据样本中的噪声(实现上就是一个输入 xt 和 t 的神经网络)
代入损失函数有
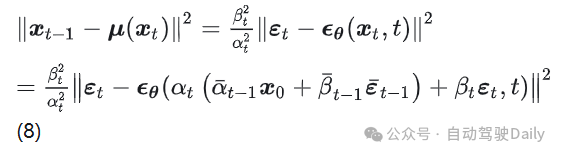
推导中把 xt 变成了 x0 的加噪形式 (4)
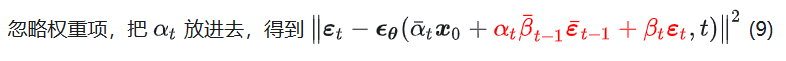
小结:到这里我们已经了解很多了,我们知道了一个单步的具体优化过程,其中只有一个关键步骤是高斯噪声叠加过程的理解
接下来这个小节是为了把两个通过一些技巧变成一个,使得我们采样时方差变小,优化更简单
损失函数优化(可以跳过)
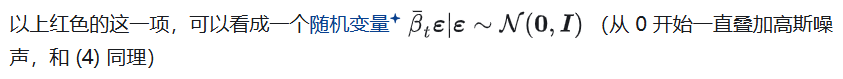
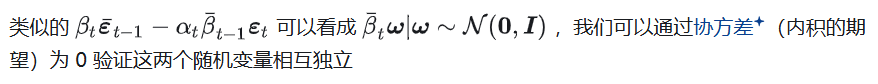
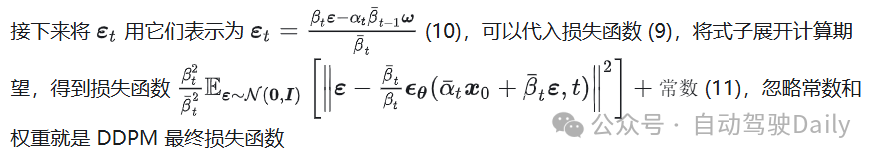
参数选取

在实践中,DDPM 设置生成步数 T=1000,后续有很多工作讨论加速和优化
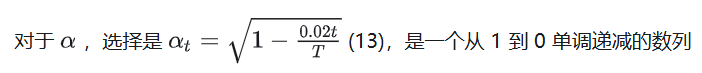

另一方面据苏神解释,在图像上用欧式距离时,当两张图片非常接近时才好度量,所以不管是选取大的 T,还是单调递减的,都是希望在靠近图片一侧的扩散过程的每一步都走的不太远,而在靠近噪声一侧走得远一点也无妨
我感觉就算选取了更好的度量,我们仍然会希望把更多的推理开销花在靠近图片的一侧而不是最初叠加噪声的过程
小结:以上其实就是完整推导,后面是从 VAE 的角度再解释一遍,大部分推导技巧是一致的
VAE 角度理解
稍微介绍几句 VAE,做过一段神经网络的朋友应该都知道编解码结构,z = g(x), x' = f(z)
用一张图 x 和 f(g(x)) 计算欧式距离就可以训练这样一对网络
如果我们抛弃掉 g,随便采样一个 z,解码 f(z) 出来会发现基本上是噪声
这是因为 z 的先验分布 q(z) 没有建模,f 对随机的 z 是不鲁棒的
VAE 会将条件分布 p(z|x)(编码)和 q(x|z)(解码)以及 q(z) 建模为高斯分布
但是这种一步到位的做法并不能提供足够强的表达能力

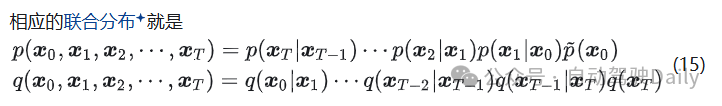

做生成模型的目标是希望生成模型的联合分布 q 尽可能接近真实数据的联合分布 p,可以通过最小化 KL 散度实现
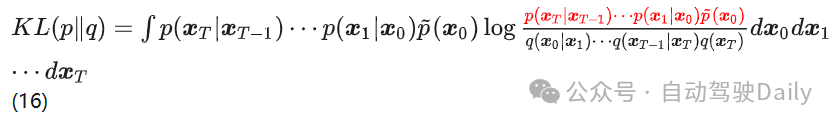
联系到 DDPM
在 DDPM 中,模型每一步的编码过程 p (3),是不含可训练参数的,所以标红的 p 是常数项
所以 (16) 就是
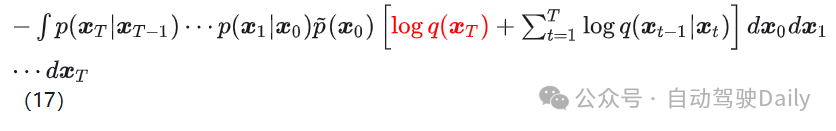
对比一下就是把 log 下面的分母变出前面负号,然后写成求和形式
这里的先验分布q()一般取标准高斯分布, 所以取 log 是常数项
看求和中的第 t 步
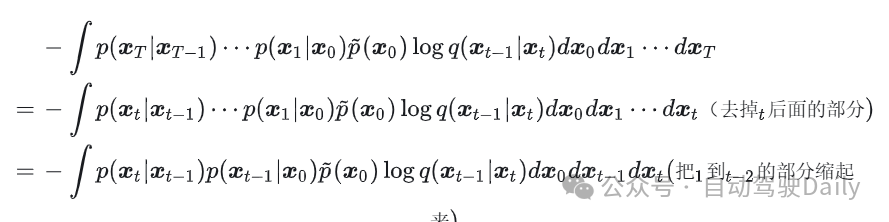
(18)
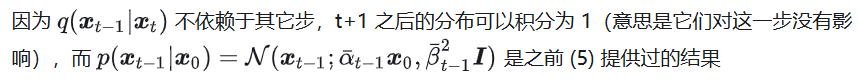
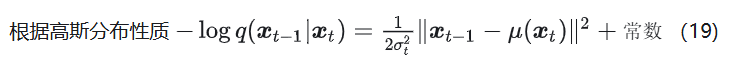
其实就是 (8) 多了权重和常数项,往后推的结果和 (11) 也只是有权重系数区别
这个系列为了督促自己补齐相关知识,希望能持续写一段时间
① 2025中国国际新能源技术展会
自动驾驶之心联合主办中国国际新能源汽车技术、零部件及服务展会。展会将于2025年2月21日至24日在北京新国展二期举行,展览面积达到2万平方米,预计吸引来自世界各地的400多家参展商和2万名专业观众。作为新能源汽车领域的专业展,它将全面展示新能源汽车行业的最新成果和发展趋势,同期围绕个各关键板块举办论坛,欢迎报名参加。

② 国内首个自动驾驶学习社区
『自动驾驶之心知识星球』近4000人的交流社区,已得到大多数自动驾驶公司的认可!涉及30+自动驾驶技术栈学习路线,从0到一带你入门自动驾驶感知(端到端自动驾驶、世界模型、仿真闭环、2D/3D检测、语义分割、车道线、BEV感知、Occupancy、多传感器融合、多传感器标定、目标跟踪)、自动驾驶定位建图(SLAM、高精地图、局部在线地图)、自动驾驶规划控制/轨迹预测等领域技术方案、大模型,更有行业动态和岗位发布!欢迎扫描加入

③全网独家视频课程
端到端自动驾驶、仿真测试、自动驾驶C++、BEV感知、BEV模型部署、BEV目标跟踪、毫米波雷达视觉融合、多传感器标定、多传感器融合、多模态3D目标检测、车道线检测、轨迹预测、在线高精地图、世界模型、点云3D目标检测、目标跟踪、Occupancy、CUDA与TensorRT模型部署、大模型与自动驾驶、NeRF、语义分割、自动驾驶仿真、传感器部署、决策规划、轨迹预测等多个方向学习视频(扫码即可学习)

④【自动驾驶之心】全平台矩阵



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









