






作者 | 郑宇鹏等 编辑 | 深蓝AI
点击下方卡片,关注“自动驾驶之心”公众号
戳我-> 领取自动驾驶近15个方向学习路线
本文只做学术分享,如有侵权,联系删文
端到端自动驾驶范式因为其可扩展性而受到广泛关注。然而,现有方法受限于真实世界数据规模,阻碍了对端到端自动驾驶相关规模化定律的全面探索。针对这一问题,中国科学院自动化所赵冬斌研究员团队与理想汽车“端到端”量产部门夏中谱团队进行了合作探索,团队收集了各类真实驾驶场景和行为数据,对现有基于模仿学习的端到端自动驾驶范式的规模化定律进行了深入研究。具体而言,该团队共收集了23种不同场景,约400万次演示,总计超过3万小时的驾驶视频。在严格的评估条件下,通过共计1,400次不同的驾驶演示(开环1,300次,闭环100次)进行开环评测和闭环仿真评测。通过实验分析发现:(1)轨迹拟合的开环性能与训练数据量呈幂律关系,闭环性能在200万次数据量时出现性能拐点;(2)长尾数据量的少量增加可以显著提高相应场景的性能;(3)适当的数据规模化可以为模型带来新场景组合泛化的能力。团队的研究结果首次通过大规模真实场景数据和实验,展现了数据规模化为端到端模型在不同驾驶场景中的泛化的关键作用,为端到端在开放世界的量产部署提供了支撑。
论文信息
论文题目:Preliminary Investigation into Data Scaling Laws for Imitation Learning-Based End-to-End Autonomous Driving
论文发表单位:中科院自动化所深度强化学习团队,理想汽车
论文地址:https://arxiv.org/pdf/2412.02689
项目仓库:https://github.com/ucaszyp/Driving-Scaling-Law

1 引言
端到端自动驾驶算法将自动驾驶中的感知、预测、规划等任务纳入一个完全可微的框架中。它将原始传感器数据作为输入,输出可能的规划轨迹,这种方法可以数据驱动的方式优化整个系统,因而受到了学界和业界广泛的关注。
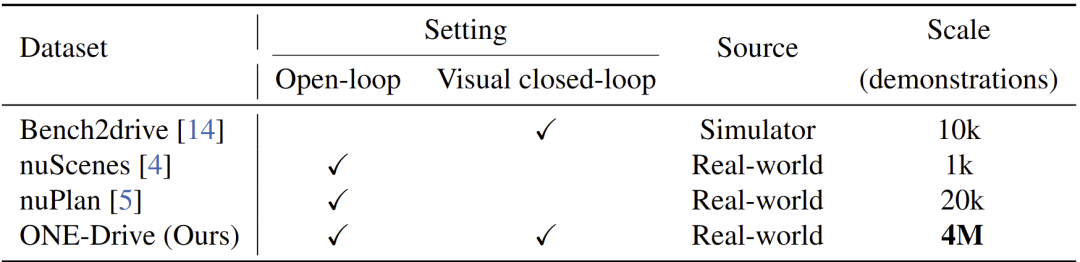
然而,当前的自动驾驶社区面临一个巨大的挑战:现实世界数据的匮乏,使得端到端自动驾驶中的数据规模化定律尚未得到充分研究。如表1所示,现有的开源真实数据集规模通常在千级,远小于语言模型或生成模型中动辄百万甚至十亿级的视觉-语言数据。
表1 ONE-Drive和现有的开源数据集的对比
对于端到端自动驾驶的安全落地,在数据规模化定律三个关键问题值得被探索:
端到端自动驾驶领域是否存在数据规模化定律?
在数据规模化的过程中,数据数量如何影响模型性能?
数据规模化能否赋予自动驾驶算法在新场景中的泛化能力?

图1 数据采集车7个摄像头的位置
2 研究工作
2.1 数据准备
为了解答这三个问题,团队收集并标注了一个名为ONE-Drive的百万级数据集,其中包含超过400万次驾驶演示(约30,000小时)的现实世界数据,数据源自多个城市的多样道路环境。图1展示了ONE-Drive的采集配置,它包括7个摄像头和一个128线的激光雷达。图2展示了ONE-Drive与现有的开源数据集nuScenes和nuPlan的对比,(a)、(b)两部分展示了它有更丰富的场景和动作。(c)对比了它与其他两个开源数据集的轨迹热力图,展现了ONE-Drive规划轨迹的多样性和挑战性。

图2 ONE-Drive数据集与nuScenes和nuPlan的对比
在此数据集的基础上。团队依据交通条件和智能体的动作将场景分为23种类型。数据集中场景类型的分布如图3所示。
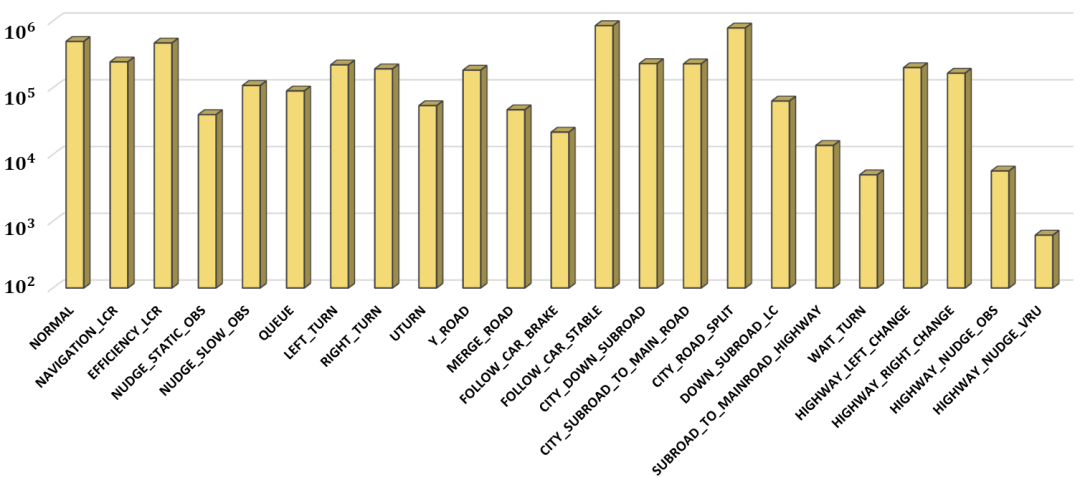
图3 ONE-Drive数据集中23种场景类型及分布
2.2 模型准备
基于PARA-Drive[1],团队提出了一种易于扩展的端到端自动驾驶网络。它的结构如图4展示。它分别提取多视角图像的特征和点云特征,随后利用前投影的方法将两种模态的信息在鸟瞰图(BEV)空间融合。随后它按照时序提取过去的BEV特征和相对位姿并进行时序融合以增强历史信息。随后,BEV特征通过并行的解码器通过Online Map、4D Occupancy、Static Object Detection、Prediction和Planning等5个任务进行训练。在自车规划中,利用多层感知器将从导航中获取的红绿灯、道路级别的路线(为了应对真实世界规划对贴合导航的需求)等导航信息和自车运动状态编码作为规划的上下文信息,最终输出多模态的规划轨迹和对应的分数。在评测中,分数最高的轨迹将被采取作为最后的规划执行。
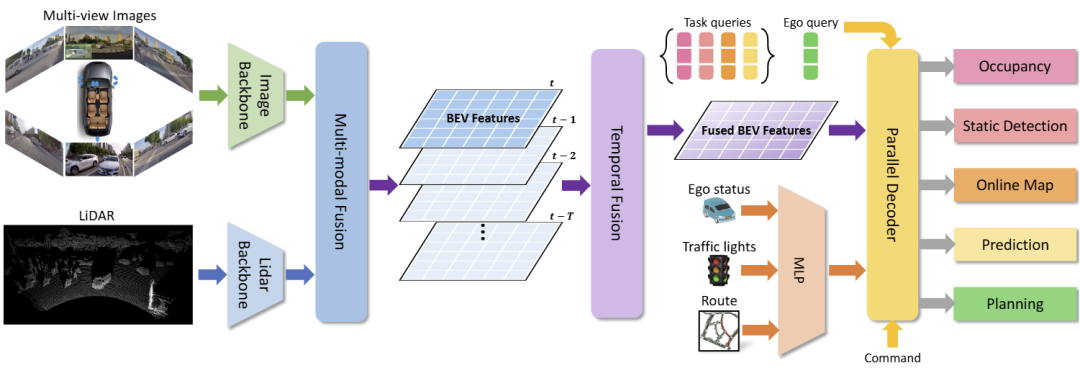
图4 模型结构图
2.3 评测准备
团队采取开环和闭环两种评测方式,开环评测旨在评估预测轨迹与专家轨迹的距离。闭环评测采用基于3D-GS场景重建的仿真器。具体来说,对每个测试场景进行3条不同轨迹的数据采集,轨迹间隔3米。利用这些采集数据,团队基于算法StreetGaussians[2]重建了测试场景,它可以10Hz的频率进行图像渲染仿真。闭环仿真中计算和实车部署密切相关的安全、效率、导航、规则、舒适度五个指标,并按照如下方式加权计算驾驶分数:
![]()
值得注意的是,由于重建场景的限制,开环评测与闭环评测的场景不完全相同。开环评测有约1300个驾驶演示组成,而闭环评测仅重建约100个场景。后续的工作中团队会将评测对齐,更公平地探索不同评测方式下的规模化定律。
2.4 实验准备
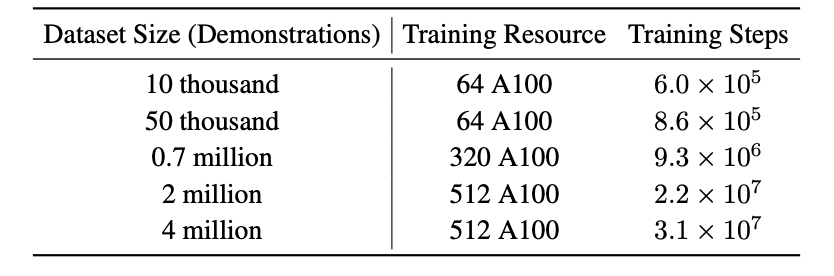
基于ONE-Drive数据集,团队进行均匀下采样得到数据量为200万、70万、5万、1万的子集作为实验数据准备。不同数据量的模型进行训练直到收敛,训练模型及资源如表2所示。
表2 不同数据量模型及训练资源
3 实验与结果
本文在大规模真实场景的闭环规划平台进行闭环规划实验,以评估性能,实验结果如下。
3.1 开闭环性能的差异
如图5所示,团队进行了开环闭环两种评测,并绘制了评测指标和训练数据量的关系图。其中5(a)是开环评测的关系图,横纵坐标均为对数坐标。5(b)和5(c)是闭环评测图,横坐标为对数坐标,纵坐标为线性坐标。如图5(a)的线性拟合,团队发现在开环评测中,模型拟合专家轨迹的性能与训练数据大致呈现幂律关系。如图5(c)所示,在闭环评测中,数据规模化定律不再是幂律关系。驾驶分数首先快速增长,随后增长放缓。在200万数据量时形成一个拐点。图5(b)中展示了闭环中每一项的评分。
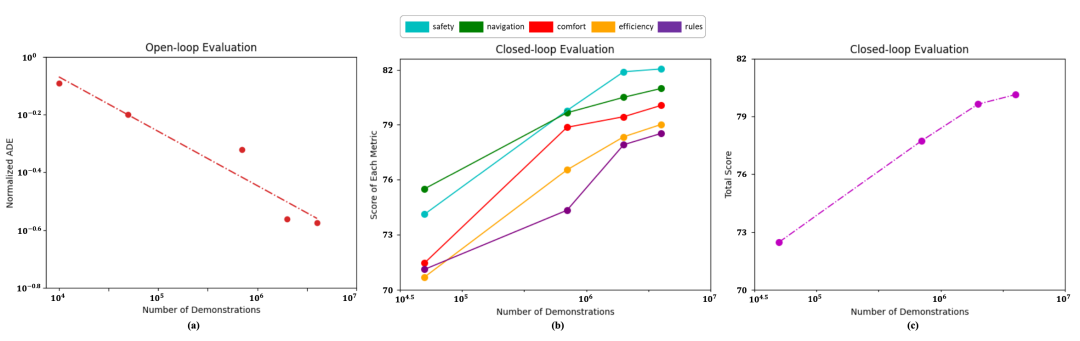
图5 数据规模化定律
3.2 数据数量增长对模型性能的影响
团队进一步探讨在数据规模化的过程中,数据量增加如何影响模型的性能以及如何利用这一规律扩增场景数据。为了研究这个问题,团队依照2.1节数据准备中的方法将数据集划分为23种类型,并选择了两种数据量少、模型表现差的长尾场景作为研究对象,开环评测模型的在两种场景中的轨迹拟合能力。在研究中保持数据总量不变,逐步增加这两种场景的数据数量。如表3所示,随着长尾数据量扩增至约4倍时,模型在该场景的性能提升约20%至30%。即通过百或千级别的长尾场景数据扩增,即可在该场景有较大的性能提升。
表3 数据量扩增实验表格
![]()
3.3 场景的组合泛化
最后,团队探讨数据规模化与端到端驾驶泛化性的关系。泛化能力被认为是自动驾驶技术于真实世界安全部署的关键。为此,团队将数据集中23种场景中的2种:高速绕行HIGHWAY_NUDGE_OBS和路口待转WAIT_TURN作为测试场景,利用剩下的21种作为训练数据。团队在5万、70万、200万数量的数据上进行了实验。值得注意的是,在选择这两个类别的测试数据时采用了严格的筛选策略,以确保每个场景与其他场景类型不重叠。图6展示了组合泛化的定量结果并展示了与这两种场景相似的场景以便比较。比如对于高速绕行HIGHWAY_NUDGE_OBS,类似的对比场景为高速行驶(左右换道)、城区绕行(障碍物、低速智能体)。通过实验结果观察到:(1)在5万个示例上训练的模型在两个测试场景中与专家轨迹的位移误差比类似场景更大,表明小规模训练数据的模型泛化能力不足。(2)随着训练数据增加到200万(绿色示例数量),两个测试场景的轨迹与其他场景之间的轨迹误差迅速缩小。在高速场景上的表现甚至超过了参与训练的其他场景。(3)通过分别从训练数据中学习高速行驶和低速绕行,模型获得了泛化到高速绕行场景的能力;通过学习转弯和红灯排队,模型发展出了泛化到路口待转场景的能力。
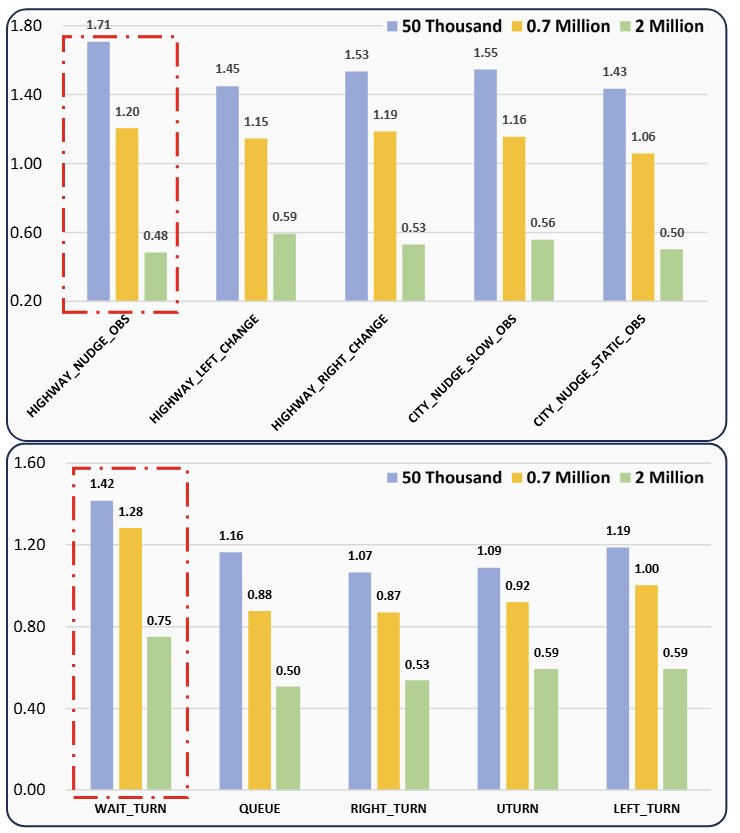
图6组合泛化定量实验
更进一步,图7中展示了模型预测轨迹的可视化。绿色框中的鸟瞰图代表使用5万个示例训练的模型的规划结果,这些示例在训练时不包含高速绕行HIGHWAY_NUDGE_OBS和路口待转WAIT_TURN场景(图例中的"50K + Unseen")。蓝色框中的鸟瞰图代表使用200万个示例训练的模型的规划结果,这些示例同样在训练时不包含高速绕行HIGHWAY_NUDGE_OBS和路口待转WAIT_TURN场景(图例中的"2M + Unseen")。橙色框中的鸟瞰图代表使用200万个示例训练的模型的规划结果,这些示例包含HIGHWAY_NUDGE_OBS和WAIT_TURN场景(图例中的"2M + Seen")。可视化的分析揭示了适当增加训练数据的规模使模型能够实现对新场景的组合泛化。这种增强的泛化能力使模型在这些新场景中的表现可以与专门训练的对应模型相媲美。团队的发现强调了数据规模在提高模型在多种自动驾驶环境中的适应性和鲁棒性方面的关键作用。

图7 组合泛化定性实验
3.4 可视化分析
本节中展示了仿真场景的可视化,两个对比场景展现了数据扩增的效果。第三个视频展示了多种天气、道路环境下的仿真效果,体现了基于3D-GS仿真的有效性。
闭环仿真测试--对比场景1:无效变道

闭环仿真测试--对比场景2:红灯路口停车区域错误
多环境的闭环仿真展示
实车部署
在实际部署中,团队评估每个模型的每次干预里程(MPI),这表示在需要人工干预之前平均行驶的距离。更高的MPI表示更好的性能。值得注意的是,在实际应用中采用了一个安全检查模块用于确保安全,它基于并行解码器生成的感知结果选择最合理的轨迹。通过对400万个示例的训练,该模型在道路测试中实现了平均约24.41公里的MPI。
4 结论
在本文中,团队深入探讨了基于模仿学习的端到端自动驾驶框架中的数据规模化定律。进一步的研究揭示了以下有趣的发现:
(1) 随着数据量指数增加,开环的轨迹拟合性能与训练数据量呈幂律关系。
(2) 对于闭环性能,团队发现200万演示数据是闭环性能的拐点,之后随着数据量指数增加,闭环性能提升变慢,这意味着基于模仿学习的端到端框架可能出现“反规模化”效应,即随着数据量指数增加,闭环性能的收益提升会逐步放缓。
(3)长尾数据量的少量增加可以显著提高相应场景的性能;
(4)适当的数据规模化可以为模型带来新场景组合泛化的能力。
在未来,团队将会更聚焦于端到端模型的闭环能力,探索更广泛的场景表征(BEV 和稀疏)、模型架构(级联和并行)和监督范式(监督和自监督)下的模型表现,旨在为自动驾驶系统在不同场景和模型范式中的可扩展性和通用性提供见解。
参考文献
[1]Xinshuo Weng, Boris Ivanovic, Yan Wang, Yue Wang, and Marco Pavone. Para-drive: Parallelized Architecture for Real-time Autonomous Driving. CVPR, 2024.
[2] Yunzhi Yan, Haotong Lin, Chenxu Zhou, Weijie Wang, Haiyang Sun, Kun Zhan, Xianpeng Lang, Xiaowei Zhou, and Sida Peng, et al. Street Gaussians for modeling dynamic urban scenes. ECCV 2024.
① 2025中国国际新能源技术展会
自动驾驶之心联合主办中国国际新能源汽车技术、零部件及服务展会。展会将于2025年2月21日至24日在北京新国展二期举行,展览面积达到2万平方米,预计吸引来自世界各地的400多家参展商和2万名专业观众。作为新能源汽车领域的专业展,它将全面展示新能源汽车行业的最新成果和发展趋势,同期围绕个各关键板块举办论坛,欢迎报名参加。

② 国内首个自动驾驶学习社区
『自动驾驶之心知识星球』近4000人的交流社区,已得到大多数自动驾驶公司的认可!涉及30+自动驾驶技术栈学习路线,从0到一带你入门自动驾驶感知(端到端自动驾驶、世界模型、仿真闭环、2D/3D检测、语义分割、车道线、BEV感知、Occupancy、多传感器融合、多传感器标定、目标跟踪)、自动驾驶定位建图(SLAM、高精地图、局部在线地图)、自动驾驶规划控制/轨迹预测等领域技术方案、大模型,更有行业动态和岗位发布!欢迎扫描加入

③全网独家视频课程
端到端自动驾驶、仿真测试、自动驾驶C++、BEV感知、BEV模型部署、BEV目标跟踪、毫米波雷达视觉融合、多传感器标定、多传感器融合、多模态3D目标检测、车道线检测、轨迹预测、在线高精地图、世界模型、点云3D目标检测、目标跟踪、Occupancy、CUDA与TensorRT模型部署、大模型与自动驾驶、NeRF、语义分割、自动驾驶仿真、传感器部署、决策规划、轨迹预测等多个方向学习视频(扫码即可学习)

④【自动驾驶之心】全平台矩阵



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









