






作者 | 新智元 编辑 | 极市平台
点击下方卡片,关注“自动驾驶之心”公众号
戳我-> 领取自动驾驶近15个方向学习路线
本文只做学术分享,如有侵权,联系删文
导读
天才极客微调PTX,让GPU性能极致发挥。
DeepSeek 最近发布的两个模型 —— DeepSeek-V3 和 DeepSeek-R1 以很低的成本获得了比肩 OpenAI 同类模型的性能。
根据外媒的报道,他们在短短两个月时间,在 2,048 个 H800 GPU 集群上,训出 6710 亿参数的 MoE 语言模型,比顶尖AI效率高出 10 倍。
这项突破不是用 CUDA 实现的,而是通过大量细粒度优化以及使用英伟达的类汇编级别的 PTX(并行线程执行)编程。
DeepSeek 在硬件受限的条件下被逼走出了一条不同于 OpenAI 等狂堆算力的道路,用一系列技术创新来减少模型对算力的需求,同时获得性能提升。

网友的一些热评:
「在这个世界上,如果有哪群人会疯狂到说出『CUDA 太慢了!干脆直接写 PTX 吧!』这种话,绝对就是那些前量化交易员了。」


天才极客微调PTX,让GPU性能极致发挥
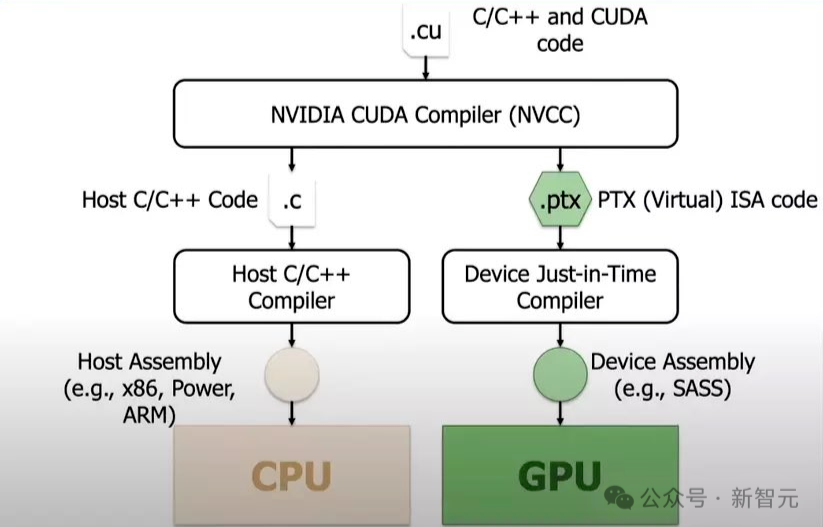
英伟达 PTX(并行线程执行)是专门为其 GPU 设计的中间指令集架构,位于高级 GPU 编程语言(如 CUDA C/C++ 或其他语言前端)和低级机器代码(流处理汇编或 SASS)之间。
PTX 是一种接近底层的指令集架构,将 GPU 呈现为数据并行计算设备,因此能够实现寄存器分配、线程/线程束级别调整等细粒度优化,这些是 CUDA C/C++ 等语言无法实现的。
当 PTX 转换为 SASS 后,就会针对特定代的英伟达 GPU 进行优化。
在训练 V3 模型时,DeepSeek 对英伟达 H800 GPU 进行了重新配置:
在 132 个流处理器多核中,划分出 20 个用于服务器间通信,主要用于数据压缩和解压缩,以突破处理器的连接限制、提升事务处理速度。
为了最大化性能,DeepSeek 还通过额外的细粒度线程/线程束级别调整,实现了先进的流水线算法。
这些优化远超常规 CUDA 开发水平,但维护难度极高。然而,这种级别的优化恰恰充分展现 DeepSeek 团队的卓越技术实力。

这是因为,在全球 GPU 短缺和美国限制的双重压力下,DeepSeek 等公司不得不寻求创新解决方案。
所幸的是,他们在这方面取得了重大突破。
有开发者认为,「底层 GPU 编程才是正确的方向。优化得越多,就越能降低成本,或在不增加额外支出的情况下,提高可用于其他方面进步的性能预算」。

这一突破对市场造成了显著冲击,部分投资者认为新模型对高性能硬件的需求将会降低,可能会影响英伟达等公司的销售业绩。
然而,包括英特尔前掌门人 Pat Gelsinger 等在内的行业资深人士认为,AI 应用能够充分利用一切可用的计算能力。
对于 DeepSeek 的这一突破,Gelsinger 将其视为在大众市场中,为各类低成本设备植入 AI 能力的新途径。

PTX与CUDA
那么,DeepSeek 的出现是否意味着前沿 LLM 的开发,不再需要大规模 GPU 集群?
谷歌、OpenAI、Meta 和 xAI 在计算资源上的巨额投资是否最终将付诸东流?AI 开发者们的普遍共识并非如此。
不过可以确定的是,在数据处理和算法优化方面仍有巨大潜力可以挖掘,未来必将涌现出更多创新的优化方法。
随着 DeepSeek 的 V3 模型开源,其技术报告中详细披露了相关细节。
该报告记录了 DeepSeek 进行的深度底层优化。简而言之,其优化程度可以概括为「他们从底层重新构建了整个系统」。
如上所述,在使用 H800 GPU 训练 V3 时,DeepSeek 对 GPU 核心计算单元(流处理器多核,简称 SM)进行了定制化改造以满足特定需求。

在全部 132 个 SM 中,他们专门划分出 20 个用于处理服务器间通信任务,而非计算任务。
这种定制化工作是在 PTX(并行线程执行)层面进行的,这是英伟达 GPU 的低级指令集。
PTX 运行在接近汇编语言的层面,能够实现寄存器分配和线程/线程束级别调整等细粒度优化。然而,这种精细的控制既复杂又难以维护。
这也是为什么开发者通常会选择使用 CUDA 这类高级编程语言,因为它们能为大多数并行编程任务提供充分的性能优化,无需进行底层优化。
但是,当需要将 GPU 资源效能发挥到极致并实现特殊优化需求时,开发者就不得不求助于 PTX。
虽然但是,技术壁垒依然还在
对此 ,网友 Ian Cutress 表示:「Deepseek 对于 PTX 的使用,并不会消除 CUDA 的技术壁垒。」

CUDA 是一种高级语言。它使代码库的开发和与英伟达 GPU 的接口变得更简单,同时还支持快速迭代开发。
CUDA 可以通过微调底层代码(即 PTX)来优化性能,而且基础库都已经完备。目前绝大多数生产级的软件都是基于 CUDA 构建的。
PTX 更类似于可以直接理解的 GPU 汇编语言。它工作在底层,允许进行微观层面的优化。
如果选择使用 PTX 编程,就意味着上文提到的那些已经建好的 CUDA 库,都不能用了。这是一项极其繁琐的任务,需要对硬件和运行问题有深厚的专业知识。
但如果开发者充分了解自己在做什么,确实可以在运行时获得更好的性能和优化效果。
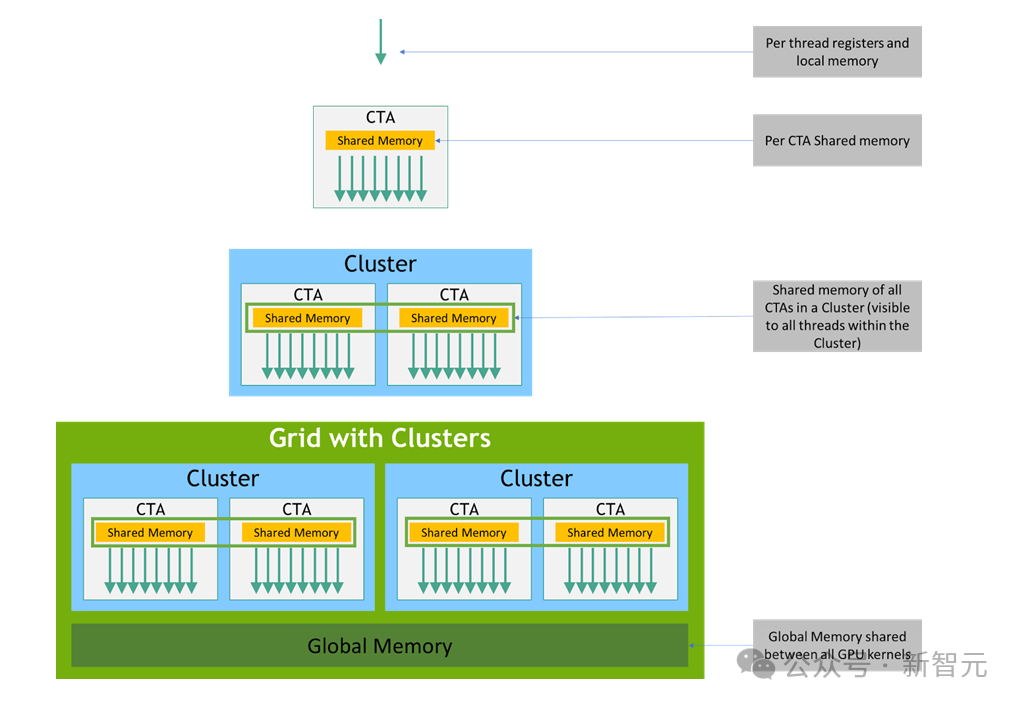
目前,英伟达生态的主流,仍然是使用 CUDA。
那些希望从计算负载中提升额外 10-20% 性能或功耗效率的开发者,比如在云端部署模型并销售 token 服务的企业,确实都已经将优化从 CUDA 层面深入到了 PTX 层面。他们愿意投入时间是因为,从长远来看这种投入是值得的。
需要注意的是,PTX 通常是针对特定硬件型号优化的,除非专门编写适配逻辑,否则很难在不同硬件间移植。
除此之外,手动调优计算内核也需要极大的毅力、勇气,还得有保持冷静的特殊能力,因为程序可能每运行 5000 个周期就会出现一次内存访问错误。
当然,对于确实需要使用 PTX 的场景,以及那些收到足够报酬来处理这些问题的开发者,我们表示充分的理解和尊重。
至于其他开发者,继续使用 CUDA 或其他基于 CUDA 的高级变体(或 MLIR)才是明智的选择。
参考资料:
https://www.tomshardware.com/tech-industry/artificial-intelligence/deepseeks-ai-breakthrough-bypasses-industry-standard-cuda-uses-assembly-like-ptx-programming-instead
https://x.com/Jukanlosreve/status/1883304958432624881
https://x.com/IanCutress/status/1884374138787357068
① 2025中国国际新能源技术展会
自动驾驶之心联合主办中国国际新能源汽车技术、零部件及服务展会。展会将于2025年2月21日至24日在北京新国展二期举行,展览面积达到2万平方米,预计吸引来自世界各地的400多家参展商和2万名专业观众。作为新能源汽车领域的专业展,它将全面展示新能源汽车行业的最新成果和发展趋势,同期围绕个各关键板块举办论坛,欢迎报名参加。

② 国内首个自动驾驶学习社区
『自动驾驶之心知识星球』近4000人的交流社区,已得到大多数自动驾驶公司的认可!涉及30+自动驾驶技术栈学习路线,从0到一带你入门自动驾驶感知(端到端自动驾驶、世界模型、仿真闭环、2D/3D检测、语义分割、车道线、BEV感知、Occupancy、多传感器融合、多传感器标定、目标跟踪)、自动驾驶定位建图(SLAM、高精地图、局部在线地图)、自动驾驶规划控制/轨迹预测等领域技术方案、大模型,更有行业动态和岗位发布!欢迎扫描加入

③全网独家视频课程
端到端自动驾驶、仿真测试、自动驾驶C++、BEV感知、BEV模型部署、BEV目标跟踪、毫米波雷达视觉融合、多传感器标定、多传感器融合、多模态3D目标检测、车道线检测、轨迹预测、在线高精地图、世界模型、点云3D目标检测、目标跟踪、Occupancy、CUDA与TensorRT模型部署、大模型与自动驾驶、NeRF、语义分割、自动驾驶仿真、传感器部署、决策规划、轨迹预测等多个方向学习视频(扫码即可学习)

④【自动驾驶之心】全平台矩阵



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









