






作者 | william 编辑 | 自动驾驶之心
原文链接:https://zhuanlan.zhihu.com/p/14282858208
点击下方卡片,关注“自动驾驶之心”公众号
戳我-> 领取自动驾驶近15个方向学习路线
本文只做学术分享,如有侵权,联系删文
文章是24年11月上传到arxiv的,https://arxiv.org/pdf/2410.23262v2
背景
EMMA是waymo最新发布的基于MLLM的端到端自动驾驶模型架构,全称是End-to-End Multimodal Model for Autonomous Driving,它是把自动驾驶任务当成一个visual question answering (VQA)问题,基于MLLM把输入和输出都用自然语言文本来表述。
之前的自动驾驶架构都是模块化的,分为Perception,Mapping,Prediction,以及Planning。模块化架构的优点是更易于调试和单模块优化,缺点也很明显,就是模块间的累积误差和模块间的有限通信导致scalability受限;而且对于新场景的适应性差。为了解决模块化架构的缺陷,端到端架构被提出来,能够从sensor data学习生成驾驶行为;但当前的端到端系统是为特定driving task训练的,而且训练数据有限,对于rare or novel场景处理不好。因此,MLLM是自动驾驶领域的新范式,它可以(1)训练数据足够大,有world knowledge,(2)可以加上Chain-of-Thought reasoning,(3)可以用task-specific prompts基于driving logs做微调。
EMMA的模型架构
EMMA的架构如下图所示。
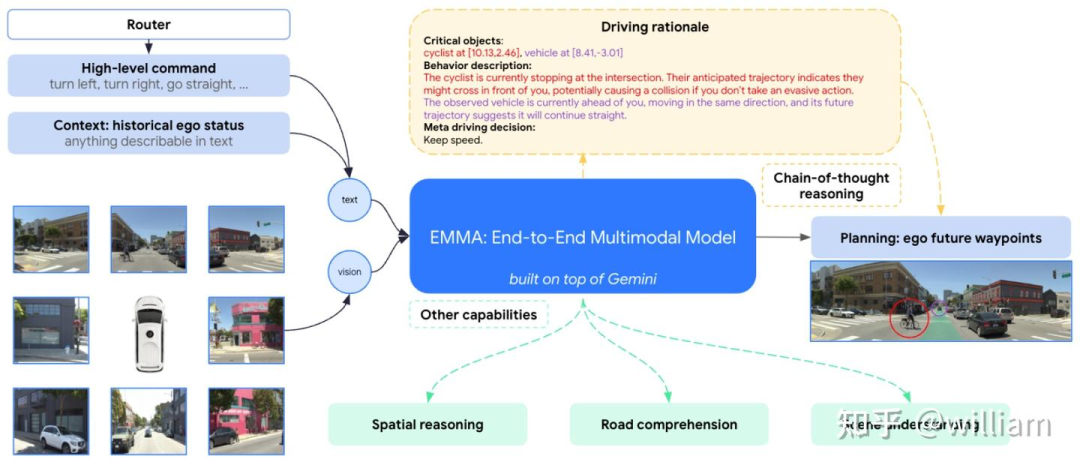
EMMA输入:
camera images (图像)
来自的router的high-level driving commands,即左转、右转、直行等 (是plain text),
historical context 以及ego vehicle status (也是plain text).
EMMA输出:
planning的自车未来trajectories (way points),
rationale的解释(用CoT提升了模型的performance和explainability)
perception objects (3D或是BEV location),
road graph elements
EMMA的优点:
端到端motion planning表现较好,在nuScenes上sota,在WOMD上获得competitive results;
在感知任务比如3D OD、road graph estimation和scene understanding,在WOD上表现sota;
EMMA可以作为自动驾驶领域的通才模型generalist model;
EMMA能够在复杂常委的驾驶场景中reason and make decisions.
EMMA的不足:
3D空间推理能力较弱,仅仅能处理图片帧,并没有考虑精准的3D感知模态比如LiDAR or radar;
需要实际的且计算量大的sensor simulation来加强closed-loop evaluation;
比传统范式的模型计算量大。
EMMA的组成部分
1.端到端Motion Planning
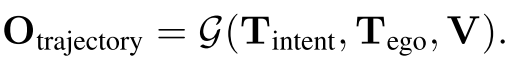
其中g是Gemini模型,V是周边的Images,是自然语言形式的自车历史状态,
表示自车过去时刻在BEV空间下的waypoint坐标,是router给的方向左转、右转、直行等,={(,)}是未来时刻的waypoint坐标点,也是自然语言形式。
这个公式的3个特点是:(1)自监督,(2)sensor input只有cameras,(3)不需要HD map,只需要high-level的router方向。
2.基于CoT推理的Planning
在Gemini模型中使用MLLM的有用工具CoT prompting,CoT的工作方式是asking模型明确表达决策的逻辑依据。本文将driving rationale分层结构化,具体处理包括以下四类信息(由于非常重要,直接截图便于理解):

注意,以上rationale的文本描述是自动生成的,不需要人工标注;此外R2 Critical objects也是用现成的感知预测模型。最终得到的端到端模型公式如下图。
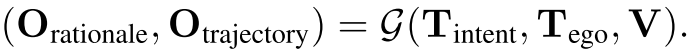
3. EMMA通才模型训练
本文基于Gemini做了一些instruction tuning,用task-specific的prompts联合训练所有的任务,具体包括三类任务:spatial reasoning,road graph estimation,以及scene understanding,整个通才范式示意如下图。
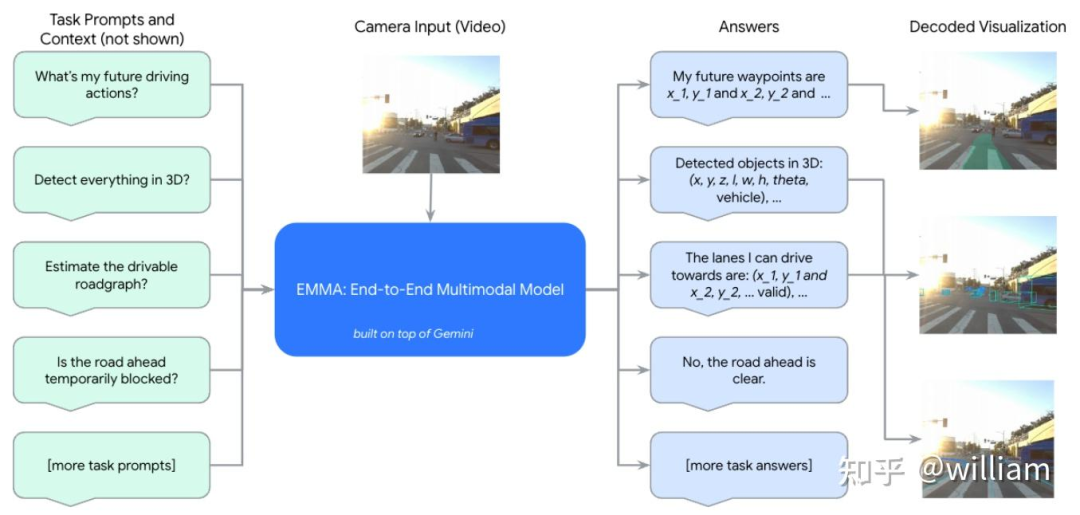
Spatial reasoning
这个任务就是3D目标检测,用的是Pix2Seq,将输入图片转化为文本表示的3D bbox,即=g(,V)。其中是detection task的固定prompt,比如上图左侧的"detect every object in 3D";的表示形式是即set{text(x,y,z,l,w,h,,cls)}
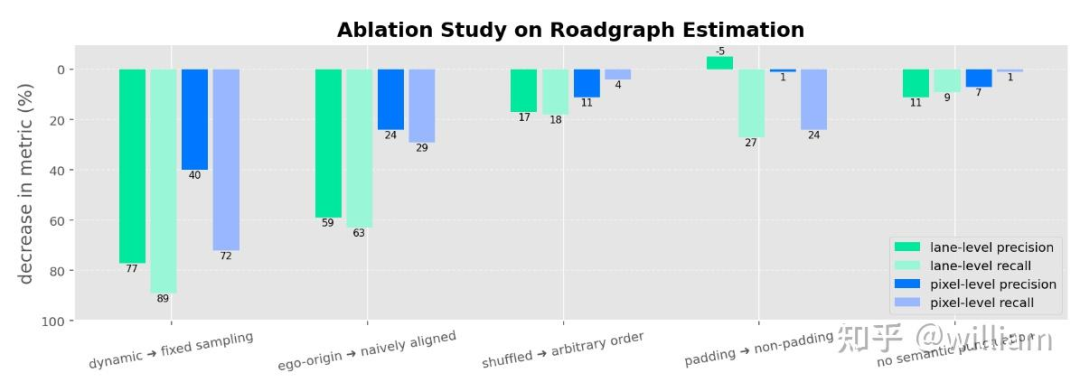
Road graph estimation
这个任务是识别出道路元素包括语义元素(比如lane markings, signs)和物理属性(比如lane curvature)。Road-graph是由许多polyline segments组成的,计算polyline也有很多现有的模型,比如StreamMapnet。用EMMA表示任务就是=g(
´íÎó
,V)。 是文本形式的waypoints来表示road graph,并且这个点是有顺序的,即{( , and...and , );(( , and...and , );...}。prompt是"estimate the drivable roadgraph".Scene understanding
类似前述任务,这里不展开了,prompts可以是"is the road ahead temporarily blocked".
4. 通才模型Generalist训练
本文用一个通才模型同时训练多个任务,训练后通才模型超过专用模型,而且能够应对长尾场景。
实验过程
模型用的是最小size的Gemini 1.0 Nano-1
任务1:公开数据集上的motion planning轨迹生成
数据集用的是nuScenes和Waymo Open Motion Dataset (WOMD),用的是前一节的端到端模型,输入camera images, ego vehicle history以及driving intent,模型预测未来的ego waypoints。
WOMD数据集有10.3万个城市驾驶场景片段,每个片段20s;这些驾驶场景被划分为110多万个样本,每个是9s是时间窗口,其中1s用作输入,剩余8s用作预测。数据集中包括了详细的地图要素(map feature),比如信号灯状态、车道特征,以及周围agent状态比如位置、速度、加速度和bbox。
在预测轨迹中,baseline方法MotionLM和Wayformer会生成192条轨迹,通过k-means聚类得到6条代表轨迹,最终根据概率挑选最优轨迹。用ADE(average distance error)指标来度量,最终的指标如下表。

在nuScenes数据集上的测试过程就不展开了,结果见下表。
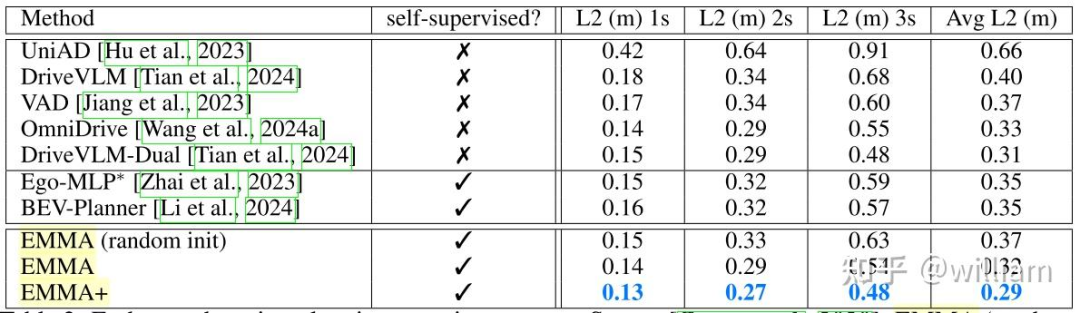
任务2:在自有数据集上的带CoT推理的E2E运动规划
waymo的自有内部数据集包括百万条场景数据,比目前开源数据集都要大,模型是用过去3s预测未来5s。
通过对比CoT中间推理过程对效果的提升,可以看出meta decision和critical object比较重要,详细数据见下表。

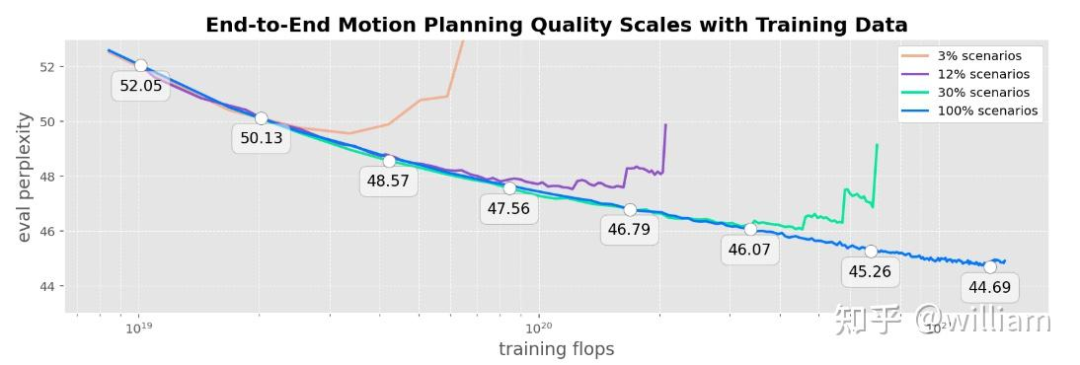
本文还验证了data scaling,通过在更大的数据集训练,发现在overfitting前得到了更低的eval perplexity,EMMA在最大的数据集上依然没有趋于平稳,因此EMMA的潜力是很大。
任务3:感知任务
本文测试了3个感知任务:3D目标检测、道路图(road graph)估计、场景理解。
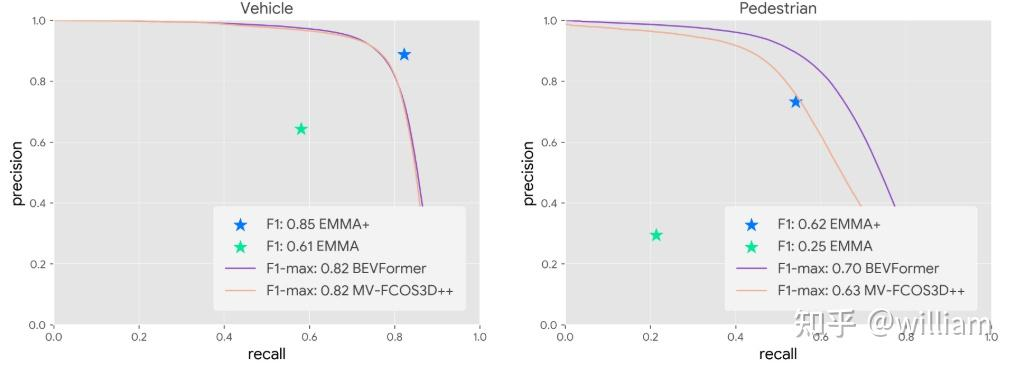
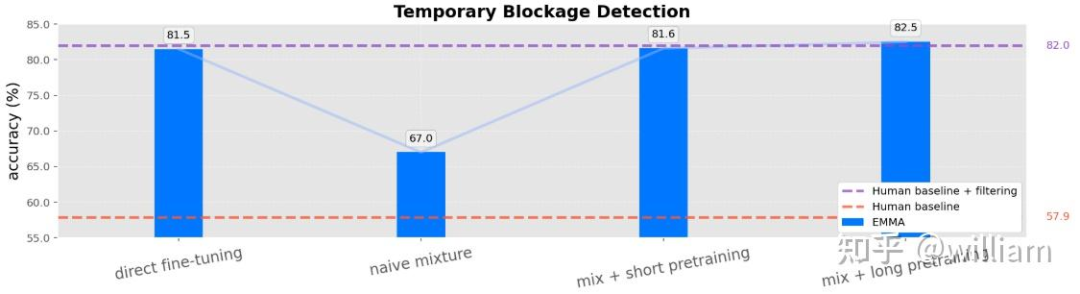
任务4:通才模型
本文聚焦3个核心任务:end-to-end planning, 3D目标检测, road graph estimation。这三个任务是互补的。多任务co-training后的效果有提升,这个发现表明通才模型是多任务合力提升、效果优化上很好的未来研究方向。

此外,实验结果发现EMMA能够(1)识别避让unseen objects或动物,(2)避让通过施工区域,(3)遵循交通灯,(4)避让VRU比如摩托车。总结EMMA的优点有:
通用性:能处理真实世界场景,即时松鼠这类没有定义过的物体也能搞定;
预见式驾驶:针对于其他道路参与者的行为积极调整,实现安全平顺驾驶;
障碍物避让:障碍物、杂物、封锁的道路都可以避让;
适应性行为:安全处理复杂场景比如施工区域、遵从信号灯;
精准的3D检测:有效识别road agents如车、自行车、摩托车、行人;
可靠的road graph估计:精准捕获道路layouts,整合成安全轨迹规划。
总结
EMMA是一个端到端多模态自动驾驶模型,是首个基于MLLM的将AD视为一个视觉问答问题,能够用camera数据得到规划轨迹、感知目标、道路元素。所有的输出都是以plain text的形式表征,用task-specific prompts设计得到。EMMA在轨迹规划、3D OD和road graph估计上获得了sota or competitive的结果;并且通过多任务joint training发现co-trained EMMA效果比单一任务训练效果要好。
本文的不足和未来研究方向:
增加long-term memory实现long-term推理;
增加pre-trained的Lidar encoder从而将Lidar数据作为输入;
验证driving signals的有效性:本文直接预测了driving signals,并不依赖中间产出的OD和road graph,但是二者并不一定是完全一致的;
需要做closed-loop验证;
实车部署挑战:大模型导致的推理延迟。
关联较大的文章(有时间再仔细看下):
Chen, O. Sinavski, J. Hünermann, A. Karnsund, A. J. Willmott, D. Birch, D. Maund, and J. Shotton. Driving with llms: Fusing object-level vector modality for explainable autonomous driving. In ICRA, 2024b.
X. Tian, J. Gu, B. Li, Y. Liu, C. Hu, Y. Wang, K. Zhan, P. Jia, X. Lang, and H. Zhao. Drivevlm: The convergence of autonomous driving and large vision-language models. In CoRL, 2024.
Z. Li, Z. Yu, S. Lan, J. Li, J. Kautz, T. Lu, and J. M. Alvarez. Is ego status all you need for open-loop end-to-end autonomous driving? In CVPR, 2024.
Chen, S. Saxena, L. Li, D. J. Fleet, and G. Hinton. Pix2seq: A language modeling framework for object detection. In ICLR, 2022a.
S. Huang, L. Dong, W. Wang, Y. Hao, S. Singhal, S. Ma, T. Lv, L. Cui, O. K. Mohammed, B. Patra, et al. Language is not all you need: Aligning perception with language models. In NeurIPS, 2023.
① 2025中国国际新能源技术展会
自动驾驶之心联合主办中国国际新能源汽车技术、零部件及服务展会。展会将于2025年2月21日至24日在北京新国展二期举行,展览面积达到2万平方米,预计吸引来自世界各地的400多家参展商和2万名专业观众。作为新能源汽车领域的专业展,它将全面展示新能源汽车行业的最新成果和发展趋势,同期围绕个各关键板块举办论坛,欢迎报名参加。

② 国内首个自动驾驶学习社区
『自动驾驶之心知识星球』近4000人的交流社区,已得到大多数自动驾驶公司的认可!涉及30+自动驾驶技术栈学习路线,从0到一带你入门自动驾驶感知(端到端自动驾驶、世界模型、仿真闭环、2D/3D检测、语义分割、车道线、BEV感知、Occupancy、多传感器融合、多传感器标定、目标跟踪)、自动驾驶定位建图(SLAM、高精地图、局部在线地图)、自动驾驶规划控制/轨迹预测等领域技术方案、大模型,更有行业动态和岗位发布!欢迎扫描加入

③全网独家视频课程
端到端自动驾驶、仿真测试、自动驾驶C++、BEV感知、BEV模型部署、BEV目标跟踪、毫米波雷达视觉融合、多传感器标定、多传感器融合、多模态3D目标检测、车道线检测、轨迹预测、在线高精地图、世界模型、点云3D目标检测、目标跟踪、Occupancy、CUDA与TensorRT模型部署、大模型与自动驾驶、NeRF、语义分割、自动驾驶仿真、传感器部署、决策规划、轨迹预测等多个方向学习视频(扫码即可学习)

④【自动驾驶之心】全平台矩阵



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









