






作者 | Jarden 编辑 | 自动驾驶之心
原文链接:https://www.zhihu.com/question/10949909331/answer/90585960028
点击下方卡片,关注“自动驾驶之心”公众号
戳我-> 领取自动驾驶近15个方向学习路线
本文只做学术分享,如有侵权,联系删文
你以为的:DeepSeek 绕过 CUDA 使用 PTX。
实际上的:DeepSeek 通过在 CUDA 代码里塞入一堆 PTX 代码来优化 CUDA 性能,然后和其他现成 CUDA 工具链结合,在可接收的开发时间内完成了开发,换成别的 GPU 还是做不到。
英伟达的护城河是 CUDA 的生态,而不是 CUDA 本身,而 PTX 是 CUDA 生态的一环
CUDA 生态包括高级 API 和丰富的工具链,庞大的库和框架支持,而这些在其他显卡生态上都还不够完善。
PTX 是 CUDA 的汇编,你可以理解为 CUDA 是一步一步翻译到显卡能照着执行的代码的,PTX 是 CUDA 的下一步。
现阶段的用 PTX 开发,是指把 PTX 插入到 CUDA 代码里,比如
// CUDA 内核函数,用于向量相加
__global__ void vectorAdd(const float* A, const float* B, float* C, int N) {
int idx = blockIdx.x * blockDim.x + threadIdx.x;
if (idx < N) {
float a = A[idx];
float b = B[idx];
float c;
// 插入 PTX 汇编代码
asm volatile(
"add.f32 %0, %1, %2;" // PTX 汇编指令:将 %1 和 %2 相加,结果存入 %0
: "=f"(c) // 输出操作数:c
: "f"(a), "f"(b) // 输入操作数:a 和 b
);
C[idx] = c;
}
}常见的误区
PTX 编程是整个代码用 PTX 写
PTX 的开发效率特别低,PTX 现在只被用来优化某些关键部分,是以镶嵌在 CUDA 里的形式存在的。
PTX 是跨芯片的
PTX 肯定不是跨芯片的,AMD 上与之对应的概念是 GCN ISA。
兼容 PTX 是分分钟的事
CUDA 编译后的结果是 PTX,要是兼容 PTX 简单,显卡厂商早拿着 CUDA 编译出来的中间结果到自己显卡上跑了,事实上,兼容 PTX 比兼容 CUDA 更难。
误解护城河的含义
我们现在说的英伟达的护城河一直是他做得更快(包括开发更快以及跑得更快),而不是其他显卡不能做。
CUDA 生态的东西太多了,其他生态的东西相比之下又太贫瘠了,DeepSeek 这个事件不仅没有说明 CUDA 护城河的消失,反而是在证明 CUDA 护城河仍然坚固。
只有当以下事件发生时,才是大众理解的护城河消失的征兆
其他显卡的理论性能超过英伟达
发生类似华为制裁导致的生态大迁徙(比如完全禁用 N 卡,被迫开始重复造轮子),丰富了其他生态
CUDA 护城河会破吗
其实,从业者一直是相信 CUDA 不会永远一家独大的,近几年越来越多的业务开始用 AMD 的显卡,尤其是推理侧。过往是迁移到其他显卡的成本太大,但是随着英伟达吃相越来越难看,N 卡越来越不划算,这个迁移是肉眼可见的。
但是,我最想吐槽的点就是,DeepSeek 用 PTX 这件事,和打破 CUDA 护城河是一点关系都没有,甚至这个事情应该是 CUDA 护城河的体现。
硬要扯上关系,就是未来其他显卡的生态需要一群高水平的从业者来开发,DeepSeek 如果愿意的话,他们有这个能力来完成这个事情,但到底能不能实现,还要看包括 DeepSeek 在内的高级开发者是否愿意为爱发电做迁移,或者是其他显卡展现出足够的潜力。
但是,CUDA 地位动摇这件事早已有之,和 DeepSeek 真是一点关系都没有,用 PTX 来优化 CUDA 至少三年前就开始大规模在干了,而且仍然是 CUDA 护城河内部的事情,现在突然被拿出来东拼西凑了一个故事。
这个问题火了,而且评论区吵得厉害,我觉得有争议的点不是护城河,而是城本身,也就是训练用的显卡的需求会变少吗,这是一般认为 Nvidia 股价下跌的主要原因
DeepSeek 推出后 Nvidia 的股价下跌意味着什么
DeepSeek 提出了一个新颖的算法,用 1/10 的成本在 N 卡上完成了训练,证明训练大模型不需要那么多显卡,又因为训练大模型一直是用 N 卡,所以 Nvidia 的股票跌的厉害。
也就是
N 卡仍然是训练时的主流(目前大模型竞赛需要的领域)
但是未来训练端需要的显卡可能会变少
所以以今天的情况来看,N 卡的总需求可能会因为训练端需要的显卡变少而减少。
可能减少是因为微软 CEO 在第二天提出了一个有意思的观点
杰文斯悖论:蒸汽机发明了,煤炭就少用了吗?提高资源使用效率反而可能增加其总消耗量。
这个观点认为技术进步提高了资源使用效率,效率提高降低了资源使用成本,成本下降刺激了资源需求的增长,需求增长可能超过效率提升带来的节约,最终导致资源总消耗增加。
举一些例子就是:
蒸汽机发明提高了煤炭的利用效率,但是每年煤炭的需求反而在提高
LED 照明技术比传统更节能,全球照明用电需求仍在上升
家电能效提升,但家庭总用电量仍在增长
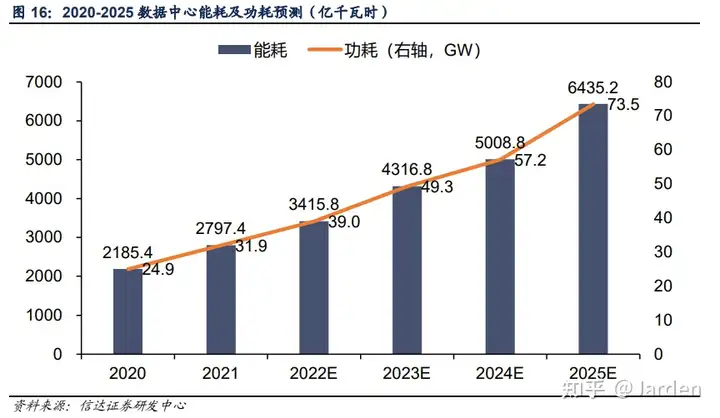
数据中心的能效提高,数据中心能耗仍在上升
数据来源:2020-2025 电力电量分析与展望
但这个观点对于显卡来说会不会成立,我们以目前的眼光是看不到的。当然 Nvidia 股票下跌还受到中国科技实力上升对美国科技企业产生冲击之类的影响,不能完全反应美股市场对显卡数量问题的看法。
① 自动驾驶论文辅导来啦

② 国内首个自动驾驶学习社区
『自动驾驶之心知识星球』近4000人的交流社区,已得到大多数自动驾驶公司的认可!涉及30+自动驾驶技术栈学习路线,从0到一带你入门自动驾驶感知(端到端自动驾驶、世界模型、仿真闭环、2D/3D检测、语义分割、车道线、BEV感知、Occupancy、多传感器融合、多传感器标定、目标跟踪)、自动驾驶定位建图(SLAM、高精地图、局部在线地图)、自动驾驶规划控制/轨迹预测等领域技术方案、大模型,更有行业动态和岗位发布!欢迎扫描加入

③全网独家视频课程
端到端自动驾驶、仿真测试、自动驾驶C++、BEV感知、BEV模型部署、BEV目标跟踪、毫米波雷达视觉融合、多传感器标定、多传感器融合、多模态3D目标检测、车道线检测、轨迹预测、在线高精地图、世界模型、点云3D目标检测、目标跟踪、Occupancy、CUDA与TensorRT模型部署、大模型与自动驾驶、NeRF、语义分割、自动驾驶仿真、传感器部署、决策规划、轨迹预测等多个方向学习视频(扫码即可学习)

④【自动驾驶之心】全平台矩阵



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









