






作者 | Patrick Liu 编辑 | 自动驾驶之心
原文链接:https://zhuanlan.zhihu.com/p/706193528
点击下方卡片,关注“自动驾驶之心”公众号
戳我-> 领取自动驾驶近15个方向学习路线
本文只做学术分享,如有侵权,联系删文
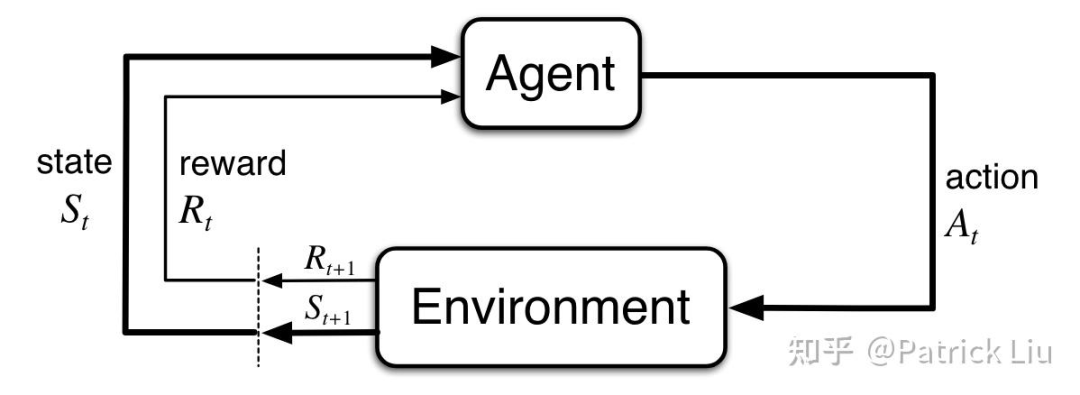
在我们熟知的模块化自动驾驶系统中,通常包含感知、预测、规划和控制等几个部分。截至2023年,机器学习带来的巨大影响主要发生在感知部分,但对下游组件尚没有产生太大的变革。有趣的是,虽然规划栈中AI的渗透率较低,但端到端的感知系统(比如鸟瞰图BEV感知)已经大规模在量产车上得到应用。
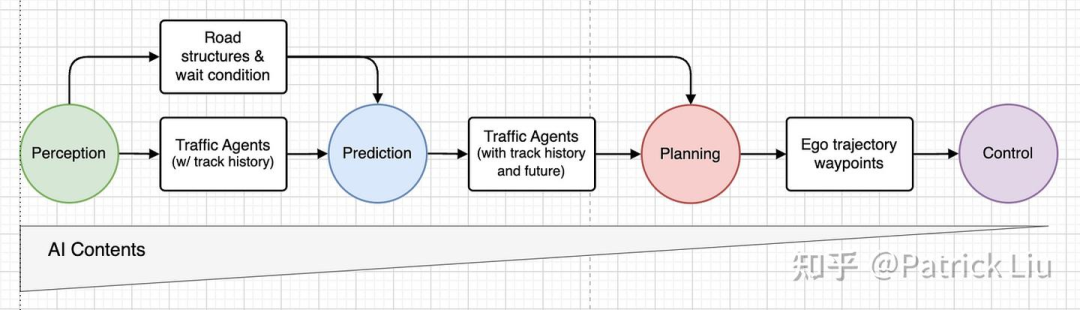
为什么会这样呢?因为传统的基于人工设计的系统更加容易解释,而且一旦在现场测试中发现问题,可以在几个小时内快速调整。而机器学习驱动的功能可能需要几天甚至几周的时间才能解决问题。尽管面临这些挑战,让大量现成的人类驾驶数据闲置不用,显然是不可取的。此外,增加计算能力比扩充工程团队要更具可扩展性。因此,机器学习在下游模块的使用是非常必要的。
幸运的是,无论是学术界还是工业界,都在积极推动这一状况的改变。首先,下游模块变得越来越数据驱动,并且可以通过可微(differentiable)的接口进行集成,代表作是CVPR 2023最佳论文UniAD。接口的可微保证各个模块可以进行联合训练或者微调,最下游规划端的反馈信号可以传递到最上游感知模块。更重要的是,随着生成式AI的不断进步,集成视觉-语言-动作(VLA)多模态的大模型在处理复杂机器人任务(如学术界的RT-2、工业界的TeslaBot和1X)以及自动驾驶(如学术界的GAIA-1、DriveVLM和工业界的Wayve AI driver、Tesla FSD)方面显示出巨大的潜力。这些工作将AI和数据驱动开发的工作模式从感知模块带到了规划模块。
作为一名感知工程师,我在过去的几周里抽出时间系统地学习了传统的规划模块。这篇文章是我想和大家分享的学习心得,旨在为感知工程师提供一个速成课程,介绍规划模块的问题设置、现有方法和挑战。我还会从AI工程师的角度,讨论AI应该如何在规划中发挥作用。
这篇文章的目标读者是从事自动驾驶领域的AI从业者,尤其是感知工程师。文章内容较长(22200字),下面的目录可能会对那些希望通过关键词快速查找内容的同学有所帮助。
英文版内容也发在Towards Data Science的互动博客。
medium.com/towards-data-science/a-crash-course-of-planning-for-perception-engineers-in-autonomous-driving-ede324d78717?sk=85715972175f3584e7c5382be1eb991f
为什么要学习规划?
那么,为什么在AI时代还要学习规划,特别是传统的规划模块呢?
从问题解决的角度来说,深入理解客户的需求,可以让我们更好地服务下游客户。机器学习只是一个工具,而不是解决方案的全部。而最有效的解决问题方法往往是将新工具与领域知识相结合,尤其是那些有扎实数学基础的领域知识,因为基于领域知识的学习方法通常更高效。当规划从基于规则的系统转变为基于机器学习的系统时,传统方法和学习方法可能会共存相当长一段时间,在此过程中两种方法的比例可能逐渐从8:2转变为2:8。因此,尽管现在端到端系统的早期原型和产品已经开始应用,一个好的工程师仍需对规划和机器学习两种方法的基础都有所涉猎。
从价值驱动开发(value-driven development)的角度来说,了解传统方法的局限性也非常重要。这些知识可以帮助我们更有效地利用新的ML工具来解决当前最棘手的问题,或者提高解决方案的上限,从而带来立竿见影的效果。
此外,规划是所有自主代理(automonous agent)的重要组成部分。它的应用不仅仅局限在自动驾驶领域,还有例如电子游戏AI选手,AI围棋手,通用机器人等领域有着重要的应用。因此理解规划是什么,以及规划是如何工作的,可以让更多的机器学习人才参与到这个快速发展的领域中来,为真正的自主代理技术的发展做出贡献。
什么是规划?
问题的定义
作为自动驾驶车辆的“头脑”,规划系统对于车辆的安全和高效驾驶至关重要。规划系统的目标是生成一条安全、舒适、高效的行驶轨迹。换句话说,安全性、舒适性和效率是规划的三个关键目标。
为了给规划系统提供输入,系统需要所有感知输出,包括静态的道路结构、动态的道路参与者、占用网生成的占用空间(occupancy network)以及交通等待情况等。规划系统还必须通过监控加速度(acceleration)和加加速度(jerk)来确保车辆的舒适性,从而生成平滑的轨迹,同时考虑与其他交通参与者的互动和礼让。
规划系统以路径点(waypoint)序列的形式生成轨迹,来表示车辆在一系列固定时间点上的未来位置,供车辆的低级控制器跟踪。例如,在8秒的规划视野内,每间隔0.4秒生成一个点,总共生成20个路径点。
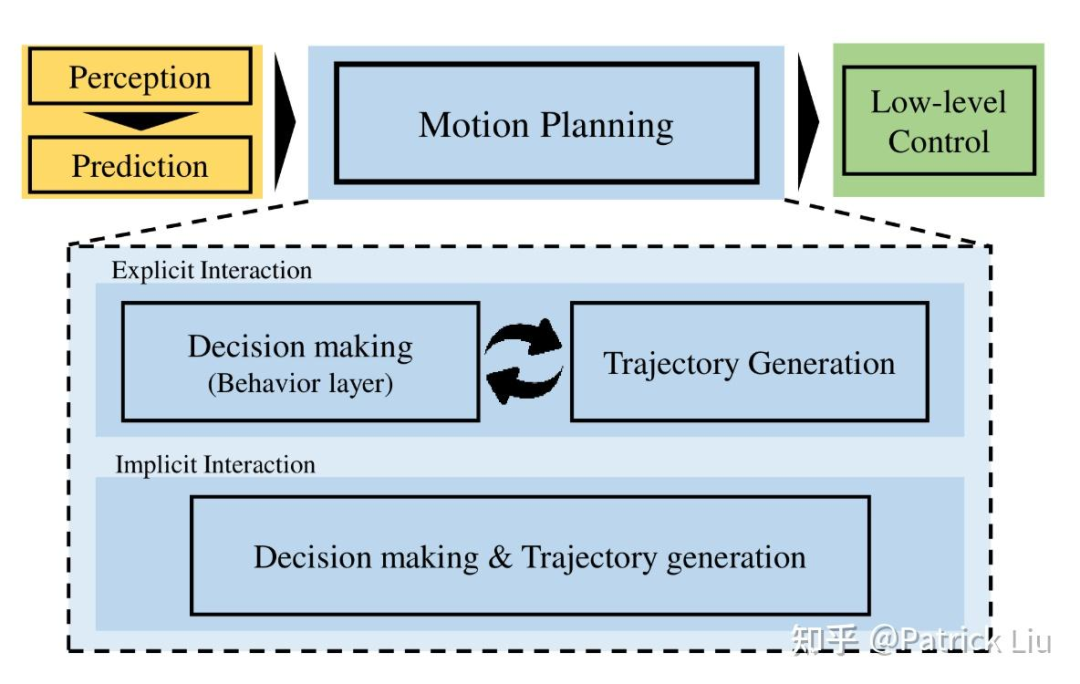
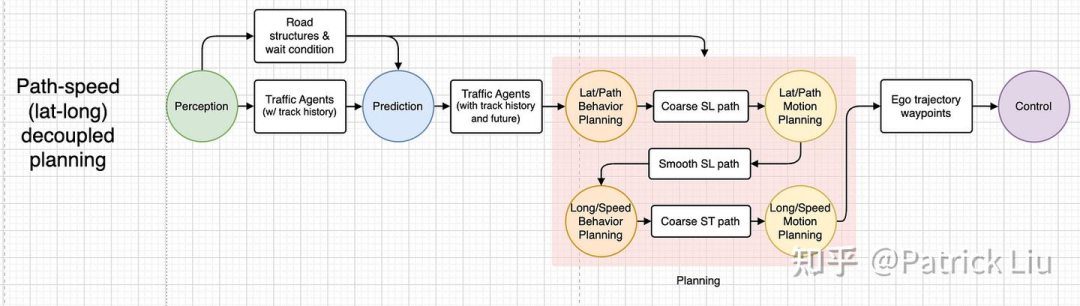
一个传统的规划模块大致包括全局路径规划(route planning)、行为规划(behavior planning)和轨迹规划(trajectory planning)。全局路径规划提供从起点到终点在全局地图上的道路级路径。行为规划决定未来几秒内的语义动作类型(例如跟车、绕行、侧向通过、礼让和超车等)。根据行为规划模块给出的行为类型,轨迹规划生成短期的行驶轨迹。全局路径规划通常在设置导航后由地图服务提供,不在本文讨论范围内。我们在本文中将重点放在行为规划和轨迹规划上。
行为规划和轨迹规划可以协同工作或合并为一个过程。在显式方法中,行为规划和轨迹规划是两个独立的过程,在分层框架中以不同的频率运行。通常行为规划以1-5 Hz的频率运行,而轨迹规划以10-20 Hz的频率运行。这种方法大多数情况下非常高效,但缺点是有可能需要大量的修改和微调来适配不同的场景。更先进的规划系统将两者合并为一个单一的优化问题,这种方法可以确保可行性和最优性的最佳平衡。
规划术语表
目前规划技术栈的一个问题是没有一个公认的标准术语表。在学术界和工业界,人们往往使用不同的名称来指代相同的概念,或者使用相同的名称来指代不同的概念。这也说明自动驾驶中的规划技术栈仍在发展,还没有完全收敛。
以下是本文中使用的术语及简要解释,并介绍了文献中可能会出现的其他近义概念。
规划(planning):一个顶层概念,平行于控制。生成轨迹路径点。规划和控制往往一起被统称为PnC(planning and control)。
控制(control):一个顶层概念,接收轨迹路径点,并生成高频率的转向、油门和刹车命令,由执行器执行。与其他领域相比,控制相对成熟,因此尽管有PnC这个常见概念,控制超出了本文讨论的范围。
预测(prediction):一个顶层概念,预测除了自车以外的交通参与者的未来轨迹。预测可以被视为其他交通参与者的轻量级规划器,也被称为运动预测(motion prediction)。
语义动作(semantic action):带有人类意图的高层抽象动作(例如跟车、绕行、侧向通过、礼让、超车),也称为行为(behavior),意图(intention)、策略(policy)、操作(maneuver)或基本运动(primitive motion)。
动作(action):没有固定含义的术语。它可以指控制的输出(高频率的转向、油门和刹车命令,由执行器执行),也可以指规划的输出(轨迹路径点)。语义动作指行为预测的输出。
行为规划(behavior planning):一个生成高层语义动作(例如变道、超车)的模块,通常生成粗略的轨迹,还有与自车动作有潜在交互的物体标签(例如避让或者抢行)。在交互情境中,它也被称为任务规划或决策。
运动规划(motion planning):一个接收语义动作,并生成平滑且可行的轨迹路径点的模块。也称为轨迹规划。
轨迹规划(trajectory planning):运动规划的另一个术语,因为一般运动规划的输出是轨迹。
决策(decision making):专注于交互的行为规划。如果没有自车与其他参与者的交互,它仅被称为行为规划,也被称为战术决策。
路径规划(route planning):在道路网络上寻找首选路径,也被称为任务规划。
基于模型的方法(model-based method):在规划中,这指的是传统规划模块中手工制作的框架,与神经网络模型相对。基于模型的方法与基于学习的方法形成对比。这个说法文献里面不太多。
传统规划(traditional planning):与基于神经网络的数据驱动的规划相对。也称为经典规划(classical planning)。
多模态性(multimodality):在规划的上下文中,这通常指的是有不确定的多重意图,例如一辆车未来的轨迹可以是直行也可以是右拐。注意这与感知中的多模态传感器输入或多模态大语言模型(如VLM或VLA)的多模态不是一个概念,尽管在英文和中文里,这两个概念都是同一个词。
参考线(reference line):基于全局路径信息和自车当前状态生成的本地(几百米)粗略路径。
Frenet坐标系:基于参考线的坐标系。Frenet坐标系将笛卡尔坐标系(直角坐标系)中的曲线路径简化为直线隧道模型。详细介绍请见下文。
轨迹(trajectory):一个三维时空曲线,在笛卡尔坐标系中表示为(x, y, t)或在Frenet坐标系中表示为(s, l, t)。轨迹由路径和速度组成。
路径(path):一个二维空间曲线,在笛卡尔坐标系中表示为(x, y)或在Frenet坐标系中表示为(s, l)。
不同文献也可能使用不同的符号和概念。以下是一些示例:
决策系统:有时是顶层概念,包括规划和控制。
运动规划:有时是顶层概念,相当于上面所说的规划,包括行为规划和轨迹规划。
规划:有时包括行为规划、运动规划和路径规划。
行为规划
目前行为规划模块通常是一个高度人为定义的中间模块,其输出的确切形式和内容,目前从业者并没有共识。具体来说,行为规划的输出可以是参考路径或与自车动作有潜在交互的物体标签(例如,从左侧或右侧通过、通过或礼让)。
将行为规划和运动规划分离增加了在解决自动驾驶车辆的高维动作空间时的效率。自动驾驶车辆的动作需要以通常10 Hz或更高的频率进行推理(路径点的时间分辨率),其中大多数动作相对简单,比如直行。分离后,行为规划层只需要以相对粗糙的分辨率对未来场景进行推理,而运动规划层则在基于行为规划决策的本地解空间中运行。行为规划的另一个好处是将非凸优化问题转换为凸优化问题,我们将在下面进一步讨论。
行为规划模块最大的短板在于没有统一且完备的行为(“语义动作”)划分方案。大部分的语义动作也都是基于结构化道路(例如高速路)来定义的。
Frenet vs 笛卡尔坐标系
Frenet坐标系是一个被广泛采用的系统,值得单独介绍。Frenet框架通过独立管理相对于参考路径的横向和纵向运动,简化了轨迹规划。s坐标表示纵向位移(沿道路的距离),而l(或d)坐标表示横向位移(相对于参考路径的侧面位置)。
Frenet坐标系将笛卡尔坐标系(Cartesian,也就是直角坐标系)中的曲线路径简化为直线隧道模型。这种转换将曲线路径上的非线性道路边界约束转换为线性约束,大大简化了随后的优化问题。此外,人类对纵向和横向运动的感知是不同的,Frenet框架允许分别且更灵活地优化这些运动。
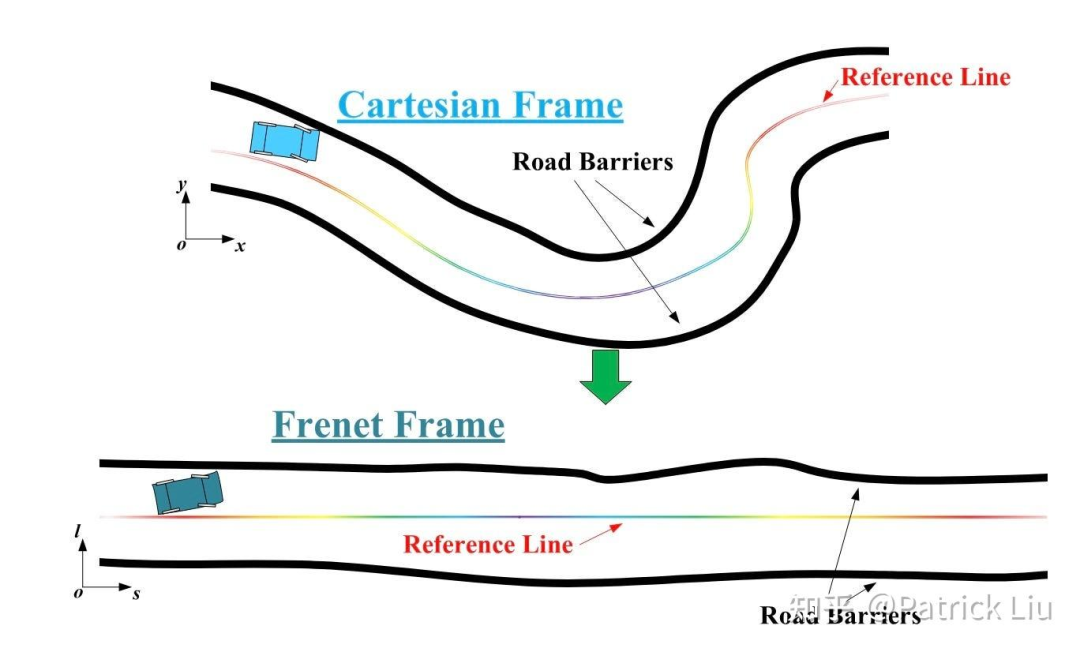
Frenet坐标系需要干净、结构化的低曲率车道图。在实践中,它更适合用于低曲率的结构化道路,如高速公路或城市快速路。然而,随着参考线曲率的增加,Frenet坐标系的问题会被放大,因此在高曲率的结构化道路(如带导向线的城市交叉路口)上应谨慎使用。
对于非结构化道路,如港口、矿区、停车场或无导向线的交叉路口,推荐使用更灵活的笛卡尔坐标系。
经典工具——规划的三板斧
在自动驾驶中,规划涉及从初始的高维状态(包括位置、时间、速度、加速度和加加速度)计算轨迹到目标子空间,确保满足所有约束。搜索、采样和优化是规划中最广泛使用的三种工具。
搜索(search)
经典的图搜索方法在规划中很受欢迎,用于结构化道路上的路径/任务规划,或者直接在运动规划中寻找在非结构化环境(如停车场或城市交叉路口,尤其是无地图场景)中的最佳路径。从Dijkstra算法到A * (读作A-star,A星),再到混合A* (hybrid A*),有一个明确的进化路径。
Dijkstra算法探索所有可能的路径以找到最短路径,使其成为一种盲目(无信息)搜索算法。这是一种系统性的方法,可以保证找到最优路径,但其部署效率较低。正如下面的图表所示,它几乎探索了所有方向。本质上,Dijkstra算法是加权移动成本的广度优先搜索(BFS)。为了提高效率,我们可以利用目标位置的信息来修剪搜索空间。
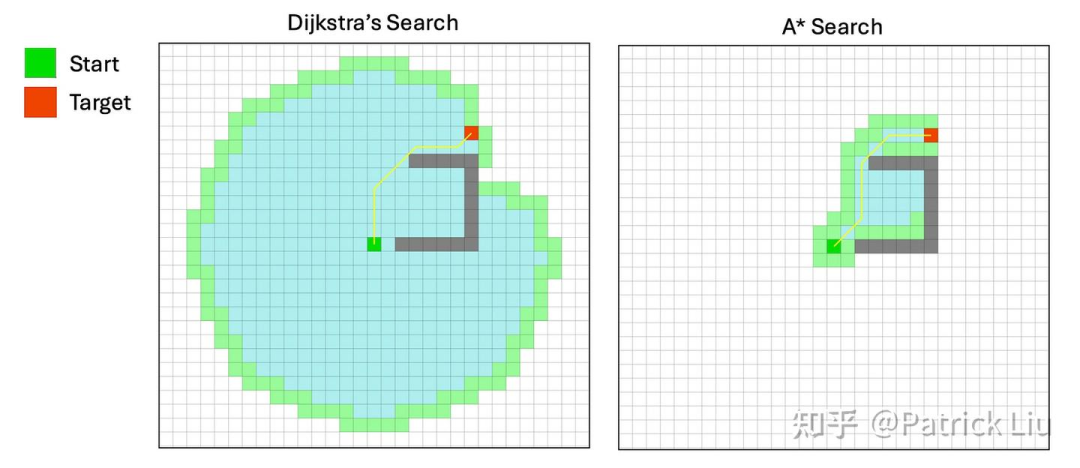
A* 算法使用启发式方法优先考虑看似更接近目标的路径,从而更高效。它结合了到目前为止的成本(Dijkstra算法中原有的成本)和到目标的成本(启发式,本质上是贪婪的最佳优先)。A* 只有在启发式是可接受(admissible)且一致的情况下才能保证最短路径。如果启发式较差,A*的性能可能比Dijkstra基准更差,甚至可能退化为贪婪的最佳优先搜索。
在自动驾驶的具体应用中,混合A* 算法通过考虑车辆运动学进一步改进了A。A求出的解可能并不满足运动学约束,导致车辆无法进行准确执行(例如,车辆的转向角通常限制在40度以内)。虽然A在网格空间中对状态和动作进行操作,但混合A*将它们分离,保持状态在网格中(discrete state),但允许根据运动学进行连续动作(continuous action)。
混合A* 的另一个关键创新是解析扩展(analytical expansion, or shot to goal)。对A* 算法的一种较为自然的改进方法是使用一条不碰撞的直线将最近探索的节点连接到目标。如果这是可能的,我们就找到了解。在混合A*中,这条直线被Dubins和Reeds-Shepp(RS)曲线所取代,这些曲线符合车辆的运动学。这种提前停止方法通过更多地关注可行性,在最优性和可行性之间取得了平衡。
混合A* 广泛用于停车场和无地图的城市交叉路口等场景。以下图像和视频展示了它在停车场场景中的工作原理。
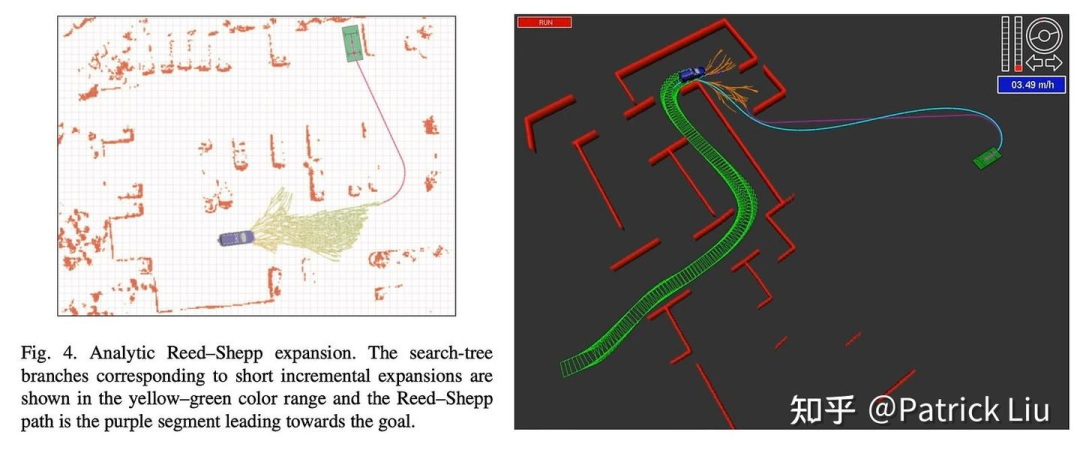
采样(sampling)
另一种流行的规划方法是采样。众所周知的蒙特卡罗(Monte Carlo)方法是一种随机采样方法。采样的方法一般涉及随机或根据先验选择许多候选者,然后根据事先定义的成本选择最佳一个。对于采样方法,快速评估众多选项是关键,因为这直接影响自动驾驶系统的实时性能。
大语言模型(LLM)本质上提供了采样,并且需要一个评估器,定义的成本与人类偏好一致。这种评估过程确保所选输出满足所需的标准和质量。这个过程也就是所谓对齐(alignment)。
如果我们已经知道给定问题或子问题的解析解,就可以在参数化解空间中进行采样。例如,我们通常希望最小化加加速度(位置p(t)的三阶导数,jerk)的平方时间积分,表示为p上面有三个点(每个点代表一个相对于时间的一阶导数)。这个目标函数(cost)可以表示为:
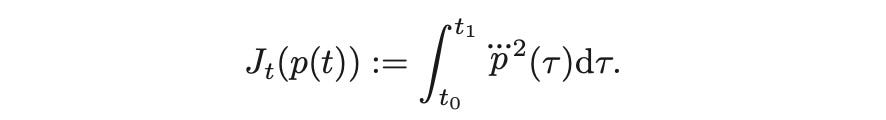
可以证明,五次多项式(quintic polynomial)在位置-速度-加速度空间中提供了两个状态之间加加速度最优的连接,即使考虑任意附加的目标函数。通过在这些五次多项式的参数空间中进行采样,我们可以找到具有最小成本的近似解。目标函数考虑了速度、加速度、加加速度限制和碰撞检查等因素。这种方法本质上通过采样解决了优化问题。
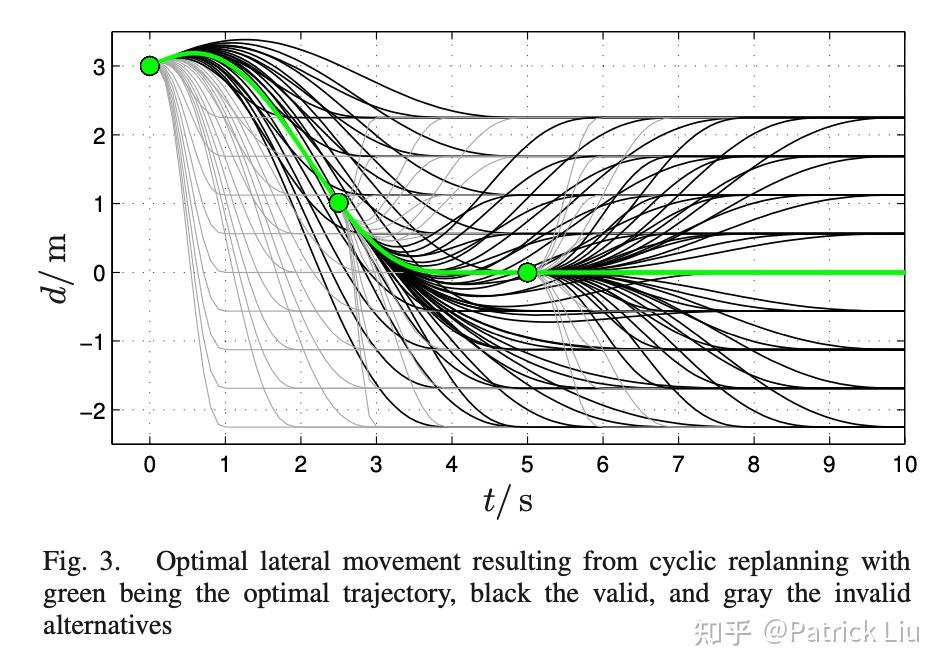
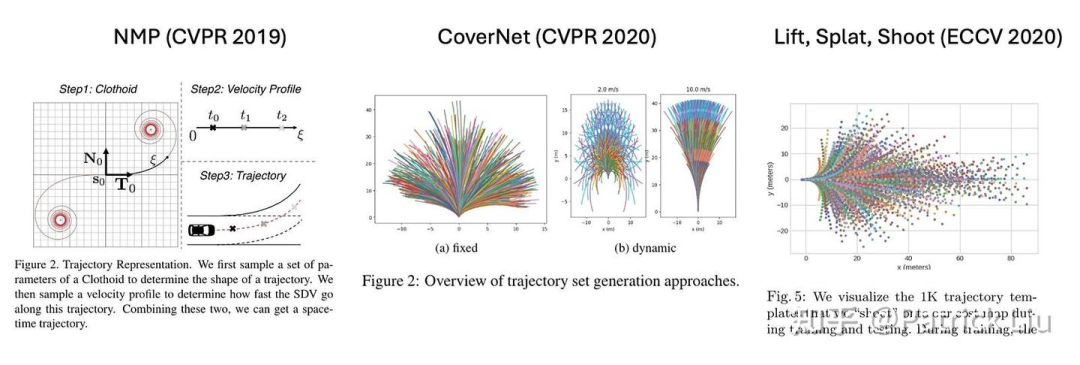
采样方法启发了许多利用机器学习来进行规划的论文,包括CoverNet、Lift-Splat-Shoot、NMP和MP3。这些方法用人类驾驶行为的大型数据库取代了数学上合理的五次多项式。轨迹的评估可以很容易地并行化,这进一步支持了采样方法的使用。这种方法有效地利用了大量专家示范来模仿人类驾驶行为,同时避免了随机采样加速度和转向角。
优化(optimization)
优化通过在给定约束下最大化或最小化特定目标函数来找到问题的最佳解决方案。在神经网络训练中,类似的原则通过梯度下降和反向传播来调整网络的权重。然而,在神经网络之外的优化任务中,模型通常不那么复杂,通常采用比梯度下降更有效的方法。(虽然梯度下降可以应用于二次规划,但它通常不是最有效的方法。)
在自动驾驶中,规划的优化目标函数通常考虑动态物体的避障、静态道路结构的跟踪车道、导航信息以确保正确路线,以及自车状态以评估平滑度。
优化可以分为凸优化和非凸优化。关键区别在于,在凸优化场景中,只有一个全局最优解,也就是局部最优解。这一特性使其不受初始解决方案的影响。在非凸优化中,初始解决方案非常重要,如下图所示。
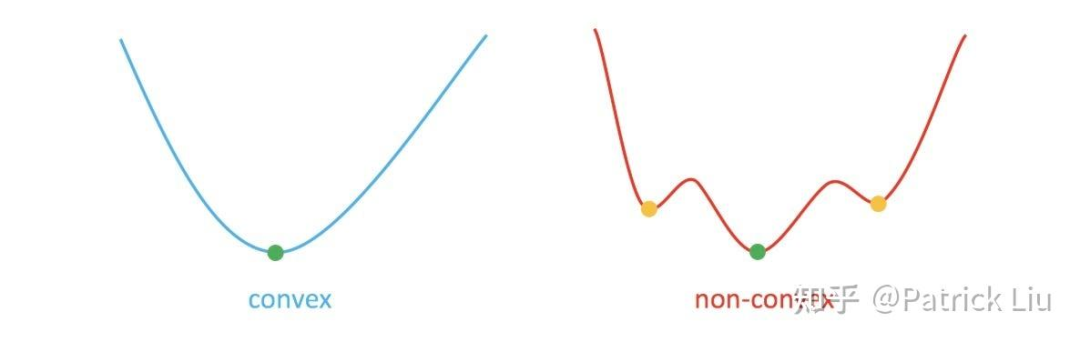
由于规划涉及高度非凸优化,存在许多局部最优解,所以规划很大程度上依赖于初始解决方案。此外,凸优化通常运行得更快,因此在自动驾驶这样的车载实时应用中更受欢迎。一个典型的方法是将凸优化与其他方法结合使用,首先勾勒出一个凸解空间,在进行凸优化。这其实就是把行为规划和运动规划进行分离的数学基础:行为规划来负责找到一个好的初始解决方案,运动规划再进行精细的凸优化。
以避障为例,一般来讲这是一个非凸问题。但如果我们知道绕行的方向,那么它就变成了一个凸优化问题,障碍物的位置作为优化问题的下界或上界约束。如果我们不知道绕行的方向,我们需要首先决定绕行的方向,使问题成为运动规划可以解决的凸问题。这个绕行方向的决策就属于行为规划的范畴。
当然,我们也可以使用投影梯度下降、交替最小化、粒子群优化(PSO,Particle Swarm Optimization)和遗传算法等工具直接优化非凸问题。但这超出了本文的讨论范围,就不详细展开了。
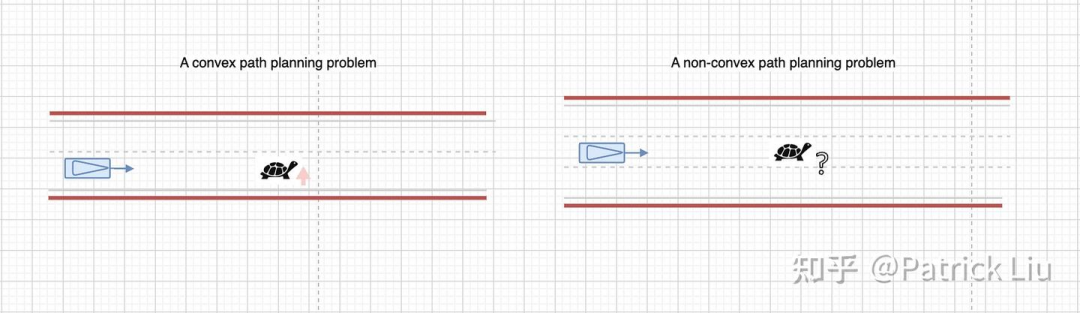
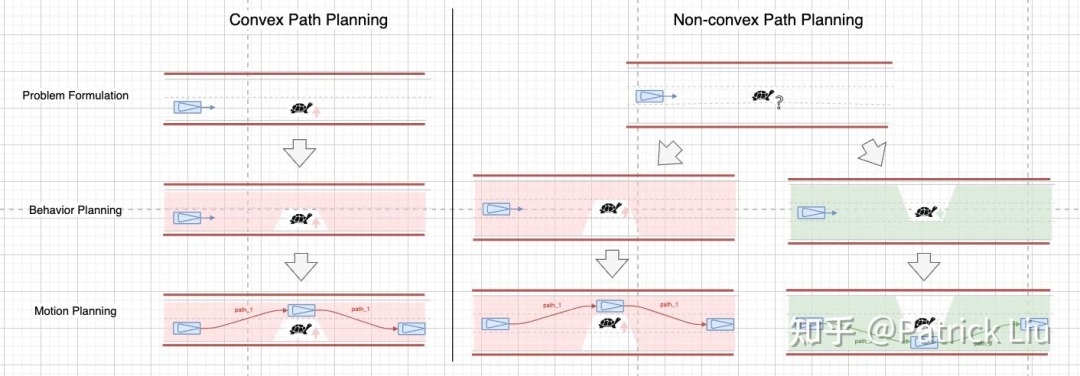
我们可以使用前面提到的搜索或采样方法来解决非凸问题。采样方法在参数空间中散布许多选项,就像是进行一次并行大搜索,也可以有效地处理非凸问题。
你可能会问,为什么只要确定往哪个方向推动就能保证问题空间是凸的呢?为了解释这个,我们需要用到一点拓扑学(topology)。在路径空间中,相似的可行路径可以在没有障碍物干扰的情况下相互连续变换。这些相似路径在拓扑学的正式语言中叫做“同伦类”(homotopy classes)。我们可以用一个与这些路径同伦的(homotopic)初始解决方案来探索所有这些路径。所有这些同伦路径形成了一个驾驶走廊,就像上图中的红色或绿色阴影区域那样。对于三维时空情况,原理类似,请参考这篇QCraft的技术博客。
我们可以利用广义Voronoi图来枚举所有的同胚类,这大致对应于我们可用的不同决策路径。不过,这个话题涉及到的高级数学概念有点超纲,本文就不细说了。
要高效解决优化问题,关键在于优化求解器的能力。通常,求解器需要大约10毫秒来规划一条轨迹。如果我们能把这个效率提高十倍,将会引发算法设计的变革,从量变到质变。特斯拉AI Day 2022年展示了这一改进,利用神经网络对轨迹生成加速超过10倍。在感知系统中也有类似的故事,例如从2D感知过渡到鸟瞰图(BEV),也是随着计算能力提高十倍而实现(例如,Nvidia Xavier的32 TOPS到Orin的275TOPS)。更高效的优化器能够计算和评估更多选项,从而降低决策过程的重要性。不过,创造一个高效的优化求解器需要投入大量的工程资源。
“每当计算能力提高十倍,算法就会进化到下一代。” —— 算法进化的定律(待验证)

工业界的规划实践
不同规划系统的一个关键区别在于它们是否是时空解耦的。具体来说,时空解耦的方法先在空间维度上规划路径,然后在这条路径上规划速度。这种方法也被称为路径-速度解耦。
路径-速度解耦(path-speed decoupling)通常又被称为横纵解耦(lat-long decoupling),其中横向(lat,lateral)规划对应路径规划,纵向(long,longitudinal)规划对应速度规划。这个术语起源于Frenet坐标系。
解耦的解决方案更容易实现,而且可以解决大约95%的问题。相比之下,耦合的解决方案理论上性能更高,但实现起来更具挑战性。它们涉及更多的参数调整,需要更有章法地进行。
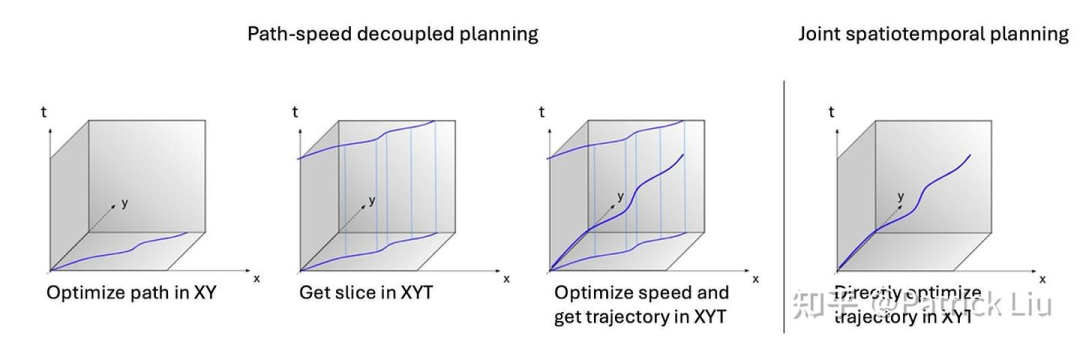

路径-速度解耦规划
我们可以以百度Apollo EM规划器为例,来看看路径-速度解耦规划的应用。
EM规划器通过将三维的纵向-横向-速度问题转化为两个二维问题:纵向-横向问题和纵向-速度问题,大大减少了计算复杂度。Apollo的EM规划器的核心是一个迭代的期望最大化(EM)步骤,包括路径优化和速度优化。每个步骤分为E步(在二维状态空间中的投影和公式化)和M步(在二维状态空间中的优化)。E步涉及将三维问题投影到Frenet SL框架或ST速度跟踪框架。
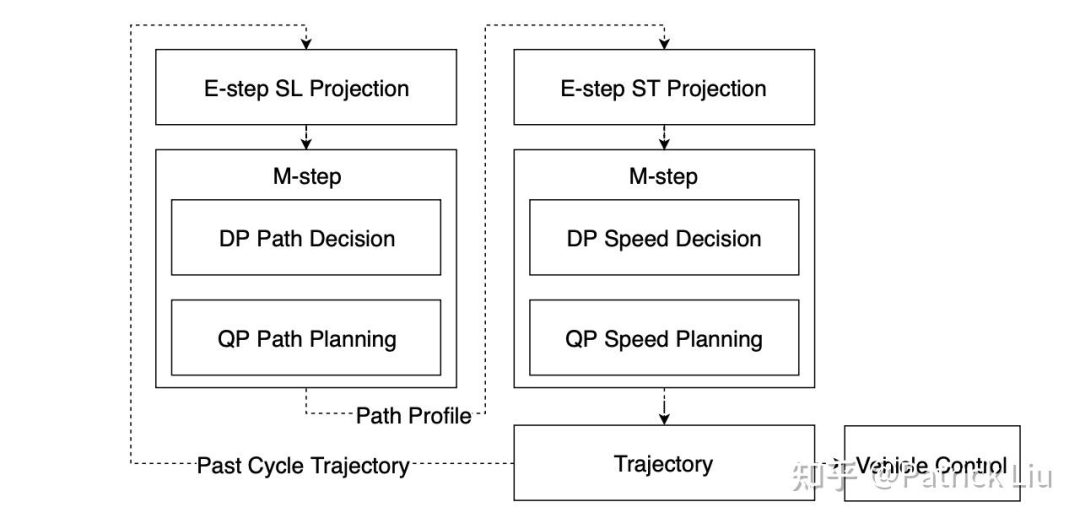
M步(最大化步骤)在路径和速度优化中都涉及解决非凸优化问题。对于路径优化,这意味着决定是从物体的左侧还是右侧绕行,而速度优化则涉及决定是超车还是礼让一个动态物体。Apollo EM规划器通过两步过程解决这些非凸优化挑战:动态规划(Dynamic Programming,DP)和二次规划(Quadratic Planning,QP)。
DP使用采样或搜索算法生成粗略的初始解决方案,有效地将非凸空间修剪为凸空间。然后,QP将粗略的DP结果作为输入,并在DP提供的凸约束内进行优化。本质上,DP关注可行性,而QP在凸约束内精细调整以实现最优性。
在我们定义的术语中,路径DP对应横向行为规划,路径QP对应横向运动规划,速度DP对应纵向行为规划,速度QP对应纵向运动规划。换句话说,这个过程包括在路径和速度步骤中分别进行行为规划(BP)和运动规划(MP)。
时空联合规划
尽管解耦规划可以解决自动驾驶中的大部分情况,但剩下的5%涉及复杂的动态交互,其中解耦解决方案通常会导致次优轨迹。在这些复杂场景中,联合优化往往可以展示出类人的智能行为,因此这是现在自动驾驶领域的热门话题。
例如,在狭窄空间内通过时,最佳行为可能是减速礼让或加速通过。这种行为在解耦解空间中是无法实现的,需要联合优化。联合优化允许更集成的方法,同时考虑路径和速度,以有效处理复杂的动态交互。

然而,联合时空规划存在明显的难点。首先,直接在高维状态空间中解决非凸问题比使用解耦解决方案更具挑战性且耗时。其次,在时空联合规划中考虑交互更加复杂。我们将在讨论决策时更详细地介绍这一主题。
这里介绍两种解决方法:暴力搜索和构建时空走廊进行优化。
暴力搜索直接在三维时空空间(二维空间和一维时间)中进行,可以在XYT(笛卡尔)或SLT(Frenet)坐标中进行。我们以SLT为例。SLT空间长而扁,类似于一个像巧克力威化的能量棒。在暴力搜索中,我们可以使用混合A-star,成本是进度成本和到达成本的组合。在优化过程中,我们必须遵守防止在s和t维度中逆行的搜索约束。
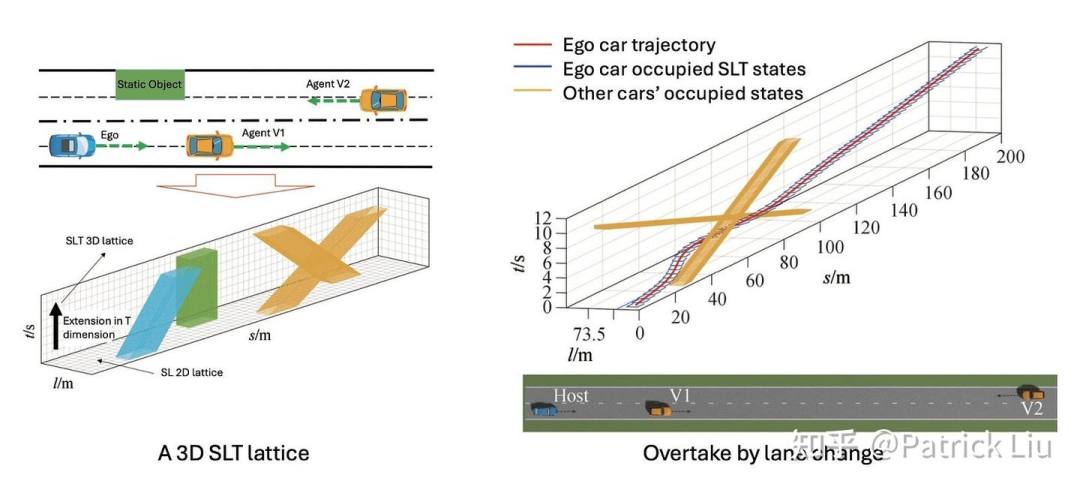
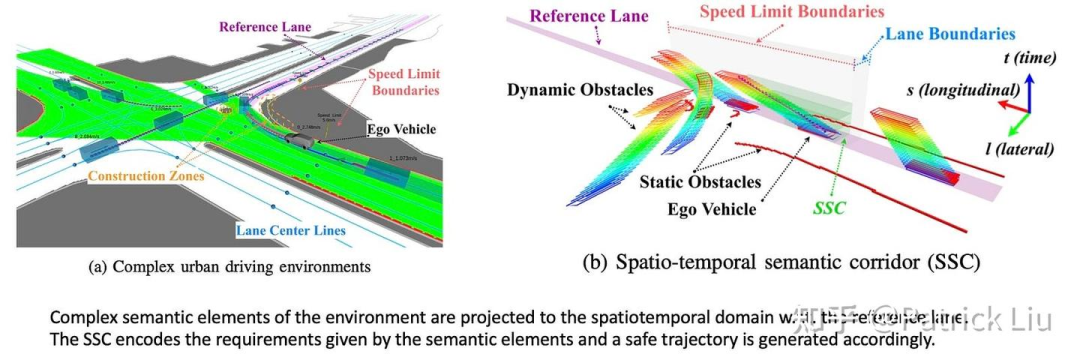
另一种方法是构建时空走廊,本质上是一条在三维时空状态空间(例如SLT)中带有车辆足迹的曲线。时空语义走廊(SSC,2019年RAL)将语义元素的要求编码为语义走廊,生成相应的安全轨迹。语义走廊由一系列相互连接的无碰撞立方体组成,由时空域中的语义元素提出的动态约束。在每个立方体内,它成为一个可以使用二次规划(QP)解决的凸优化问题。
SSC仍然需要一个行为规划(BP)模块提供一个粗略的驾驶轨迹,来作为SSC的输入。环境的复杂语义元素投影到参考车道的时空域中。EPSILON(2021年TRO)展示了一个系统,其中SSC作为运动规划器与行为规划器协同工作。在下一节中,我们将讨论行为规划,特别是交互方面。在这种强交互的情况下,行为规划通常被称为决策。
决策
什么是决策?为什么要做决策?
在自动驾驶中,决策本质上是行为规划,但更注重与其他交通参与者的交互。我们的假设是其他道路参与者大多数是理性的(rational),并且会以可预测的方式回应我们的行为。或者最起码也是“带噪理性人”(noisily rational)。
可能有人会问,当我们已经有先进的规划工具时,为什么还需要决策?关键在于两个方面——不确定性和交互。由于动态物体的存在,环境具有概率性特征。交互是自动驾驶中最具挑战的部分,使其区别于一般机器人。
在一个确定的(纯几何的)没有交互的世界中,决策是多余的,规划通过搜索、采样和优化即可解决问题。暴力搜索3D XYT空间可以作为一种通用解决方案。
在大多数传统的自动驾驶模块中,采用”预测然后规划“(predict-then-plan)的方式,假设自车与其他车辆之间的交互为零阶。这种方法将预测输出视为确定性,要求自车做出相应反应。这会导致过于保守的行为,也就是经典的“冻结机器人”问题(freezing robot)。在大量的运动物体自由运动的场合,预测会填满整个时空空间,具体行为就表现为,车辆在拥挤条件下就无法完成变道——而人类则能更有效地处理这些情况。
为了应对随机策略,马尔可夫决策过程(MDP,Markov Decision Process)或部分可观马尔可夫决策过程(POMDP,Partially Observable Markov Decision Process)框架是必不可少的。这些方法将重点从几何转向概率,应对混乱的不确定性。假设交通参与者表现理性或至少噪声理性,决策可以帮助在混乱的时空空间中创建一个安全的驾驶走廊。
MDP和POMDP
接下来我会先介绍马尔可夫决策过程(MDP)和部分可观马尔可夫决策过程(POMDP),然后是它们的系统解决方案,如价值迭代和策略迭代。
马尔可夫过程(MP,Markov Process)是一种处理动态随机现象的随机过程,不同于静态概率。在马尔可夫过程中,未来状态仅依赖于当前状态,使得它足以进行预测。对于自动驾驶来说,所有相关状态可以用一个较长的时间窗口的位置信息来描述。这感觉并不满足MDP的条件。但是,如果我们扩展一下状态空间,例如除了位置信息我们也可以使用速度,加速度,加加速度等信息。这样我们可以使用在更高维度下的更短的历史窗口来刻画自车的当前状态,更加满足MDP的条件。
马尔可夫决策过程(MDP)通过引入行动将马尔可夫过程扩展到决策。MDP模拟了决策过程,其中结果一部分是随机的,另一部分是由决策者或代理控制的。MDP可以用五个因素建模:
状态(S):环境的状态(state)。
行动(A):代理可以采取的影响环境的行动(action)。
奖励(R):环境作为行动的结果提供给代理的奖励(reward)。
转移概率(P):代理的行动导致从旧状态转移到新状态的概率(transition probability)。
Gamma(γ):未来奖励的折扣因子(discount factor)。
这也是强化学习(RL)使用的通用框架,本质上是一个MDP。MDP或RL的目标是最大化长期累积奖励(cumulative reward)。这要求代理根据环境中的状态,依据策略做出良好的策略(policy)。
策略,π,是一种从每个状态s ∈ S和行动a ∈ A(s)到在状态s时采取行动a的概率π(a|s)的映射。MDP和RL都是研究如何导出最优策略的问题。
部分可观马尔可夫决策过程(POMDP)相比MDP,在状态(state)这个变量的基础之上又引入了观测量(observation)。在POMDP里,状态没有办法直接得到,而是通过观测量来推断的。在POMDP中,代理会保持一个”信念状态“(belief state),也就是可能状态的概率分布,以估计环境的状态。由于内在的不确定性和部分可观性,自动驾驶场景更适合用POMDP表示。MDP可以被视为POMDP的一种特殊情况,在这种情况下,观察完全揭示了状态。
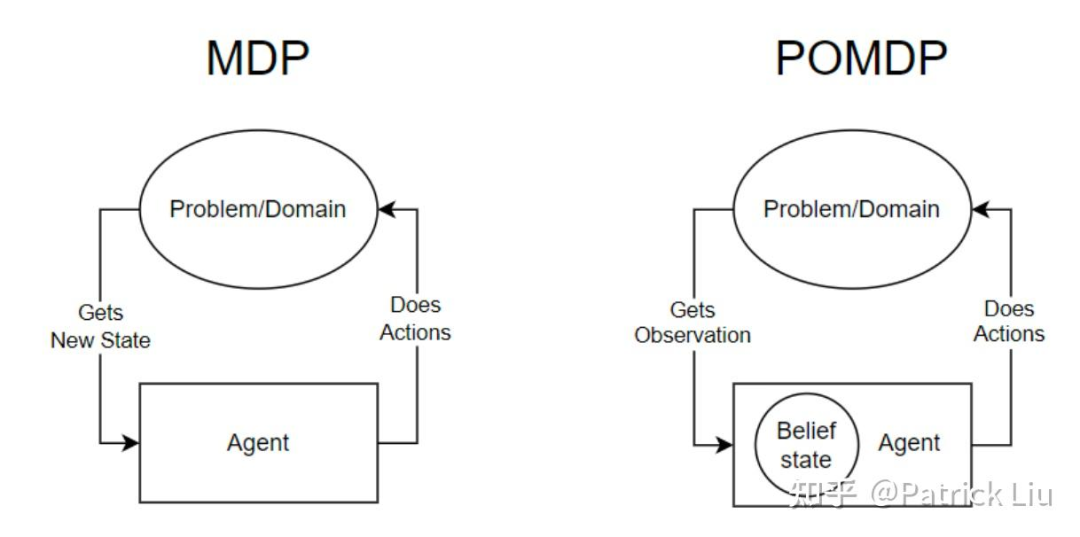
POMDP能够通过主动收集信息来获取必要的数据,这其实是某种智能行为。这种能力在等候交叉路口时尤其有用,例如收集其他车辆意图和交通信号灯状态的信息,以便做出安全高效的决策。
价值迭代和策略迭代
价值迭代和策略迭代是解决MDP或POMDP问题的系统方法。由于这些方法较为复杂,在现实应用中并不常见,但我们仍可以了解这些方法以及如何在实践中简化它们,比如在AlphaGo中使用的MCTS或在自动驾驶中的MPDM。
为了在MDP中找到最佳策略,我们必须评估一个状态的潜在或预期奖励,或者更具体地说,评估该状态下采取某个行动的奖励(reward)。这不仅包括当下的奖励,还包括所有未来的奖励,通常被称为回报(return)或累积折扣奖励(cumulative discounted reward)。(如果想了解更多,请参考《强化学习:导论》。这本书被认为强化学习的”圣经“。)
价值函数(V)通过求和预期回报来表征状态的质量。动作-价值函数(Q)评估给定状态下行动的质量。两个函数都强依赖于某个给定的策略才有定义。贝尔曼最优方程(Bellman Optimality Equation)指出,最优策略将选择最大化即时奖励加上由此产生的新状态预期未来奖励的行动。简而言之,贝尔曼最优方程建议在考虑行动的即时奖励和未来后果的基础上做决策。就如同当你考虑换工作时,不仅要考虑眼前的加薪(R),还要考虑新职位未来的价值(S’)。
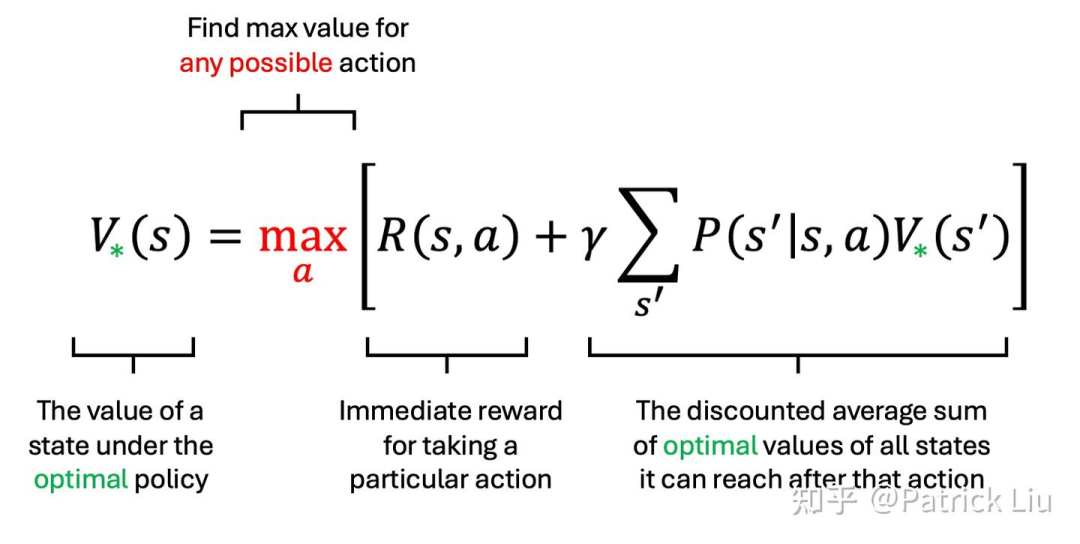
从贝尔曼最优方程中提取最优策略相对简单,一旦我们获得了最优价值函数。但如何找到这个最优价值函数呢?这就是价值迭代的用武之地。
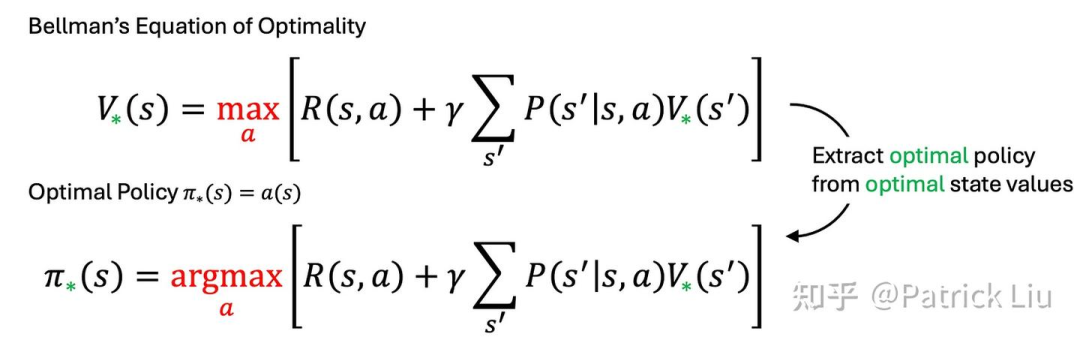
价值迭代通过不断更新每个状态的价值,直到稳定来找到最佳策略。这个过程通过将贝尔曼最优方程转化为更新规则得出。我们相当于用最优未来的“愿景”来指导迭代走向最优。老话说的好,这是榜样的力量,在英文中就是“Fake it until you make it” (先演再成真)。
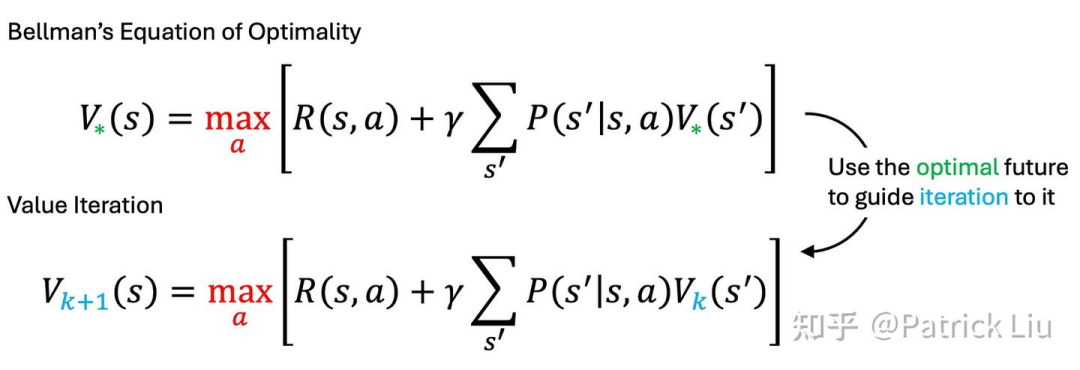
价值迭代对有限状态空间保证收敛,无论状态的初始值如何(详细证明请参考RL的圣经)。如果折扣因子γ设置为0,意味着我们只考虑即时奖励,价值迭代将在一次迭代后收敛。较小的γ会导致更快的收敛,因为考虑的范围更短,尽管这不一定总是解决具体问题的最佳选择。在工程实践中平衡折扣因子是一个关键方面。
有人可能会问,如果所有状态都初始化为零,不就没有办法打破这个僵局么?贝尔曼方程中的即时奖励(reward)对于引入额外信息和打破初始对称性至关重要。想象一下,直接通向目标状态的状态,它们的价值会像病毒一样在状态空间中传播。通俗地说,就是要取得频繁的小胜利(make small wins frequently)。
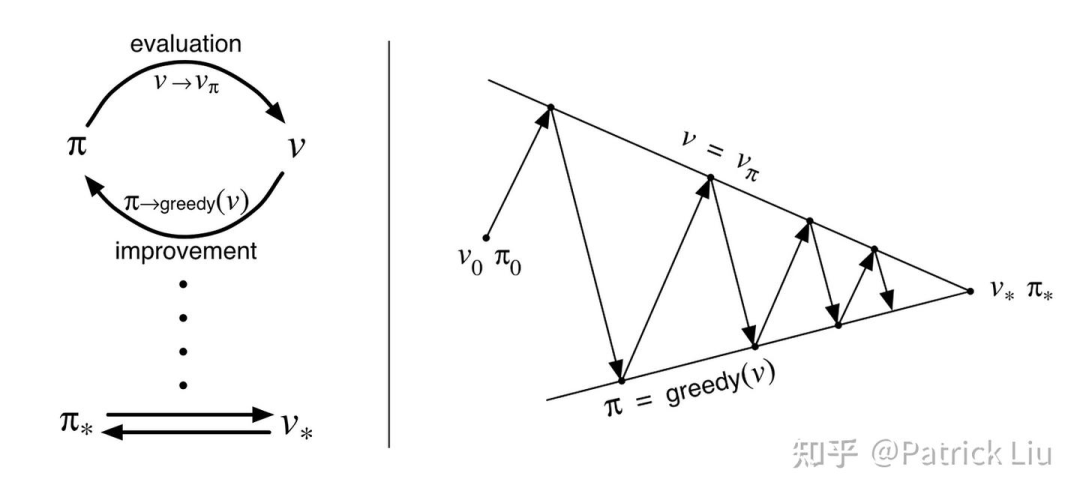
然而,价值迭代也存在效率低下的问题。它需要在每次迭代中通过考虑所有可能的行动来采取最优行动,类似于Dijkstra算法。虽然它展示了作为基本方法的可行性,但通常不适用于现实应用。策略迭代通过根据当前策略采取行动,并根据贝尔曼方程(注意:不是贝尔曼最优方程!)进行价值函数更新。
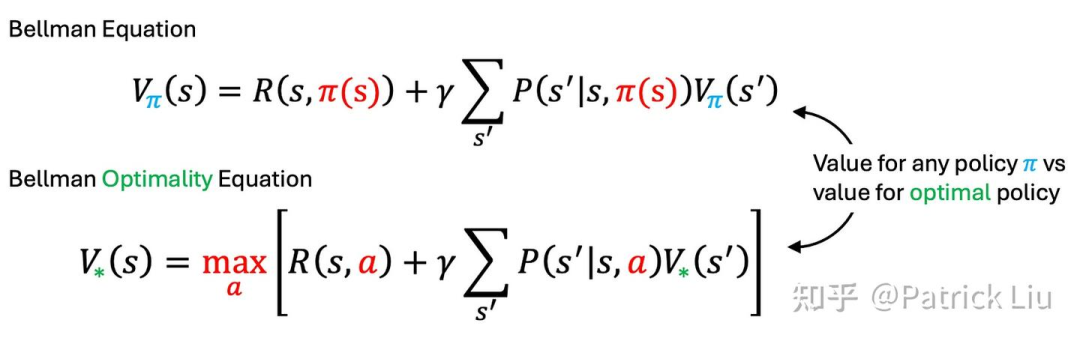
策略迭代将策略评估与策略改进分离,使其成为更快的解决方案。每一步都基于当下的策略,而不是探索所有可能的行动以找到最大化目标的行动。尽管策略迭代的每次迭代可能由于策略评估步骤而计算量更大,但总体上结果是更快的收敛。通俗地说,如果你只能完全评估某一个(而不是多个)行动的后果,那就最好依靠自己的判断,尽你当前所能做到最好。
AlphaGo和MCTS——当网遇到树
我们都听过2016年AlphaGo击败顶级围棋棋手李世乭的传奇故事。AlphaGo将围棋的玩法公式化为一个马尔可夫决策过程(MDP),并用蒙特卡罗树搜索(Monte Carlo Tree Search, MCTS)来解决MDP。但是,为什么AlphaGo没有使用价值迭代或策略迭代呢?

价值迭代和策略迭代是系统化解决MDP问题的方法。然而,即使是改进的策略迭代,仍然需要进行耗时的操作来更新每个状态的价值。标准19x19围棋盘大约有2e170个可能的状态。要探索这么多的状态,使用用传统的价值迭代或策略迭代技术不可行的。
AlphaGo及其后继者使用MCTS算法来搜索棋步,并由经过人类和计算机对局训练的价值网络和策略网络对搜索进行指导。让我们先看看基本的MCTS。
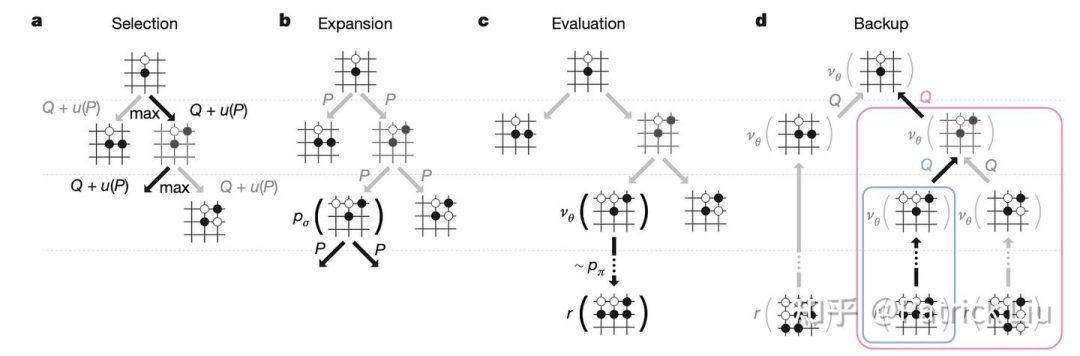
蒙特卡罗树搜索(MCTS)是一种专注于从当前状态进行决策的策略估计方法。一次迭代涉及四个步骤:选择、扩展、模拟(或评估)和回溯。
选择(selection):算法根据之前的模拟,沿着最有希望的路径前进,直到到达一个叶节点,一个尚未完全探索的位置。
扩展(expansion):添加一个或多个子节点,表示从叶节点可能进行的下一步动作。
模拟(simulation,又称,评估evalution):算法从新节点开始进行随机对局,直到结束,称为“rollout”。这一步通过模拟随机动作直到达到终局来评估扩展节点的潜在结果。
回溯(backup):算法根据对局的结果更新所走路径上的节点值。如果结果是胜利,节点值增加;如果是失败,节点值减少。这个过程将rollout的结果向上传播,基于模拟结果优化策略。
经过一定次数的迭代,MCTS提供了在模拟过程中从根节点选择的即刻动作的频率百分比。在推理过程中,选择访问次数最多的动作。以下是一个关于井字棋游戏的MCTS交互式示例,作为围棋的简化版,便于理解。
vgarciasc.github.io/mcts-viz/
AlphaGo使用了两个神经网络来对MCTS进行增强。价值网络评估给定状态(棋盘配置)的胜率。策略网络评估所有可能动作的动作分布。这些神经网络通过减少搜索树的有效深度和广度来提高MCTS的性能。策略网络有助于动作采样,将搜索集中在有前途的移动上,而价值网络提供更准确的位置评估,减少了大量rollout的需求。这种结合使得AlphaGo能够在围棋的广阔状态空间中进行高效而有效的搜索。
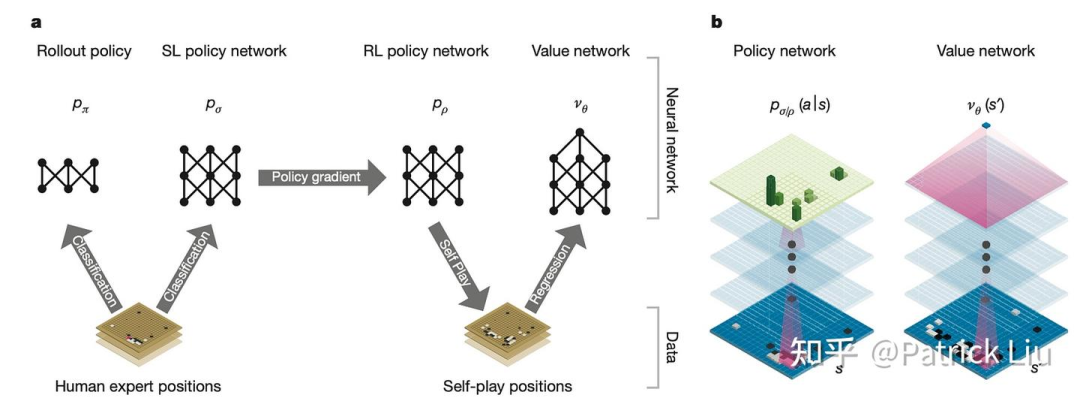
在扩展步骤中,策略网络对最可能的位置进行采样,有效地修剪了搜索空间的广度。在评估步骤中,价值网络提供对位置的直观评分,而一个更快、更轻量级的策略网络则执行rollout直到对局结束以收集奖励。MCTS随后使用两个网络评估的加权和来进行最终判断。
需要注意的是,价值网络的一次前向评估就接近使用策略网络进行蒙特卡罗rollout的准确性,但计算量减少了15000倍。这个对比类似于快速对比慢速系统设计,像直觉对比推理,或者诺贝尔奖得主Daniel Kahneman描述的系统1对比系统2。类似的设计也可以在更近期的作品中看到,如DriveVLM。
确切地说,AlphaGo在不同层面上结合了两个快慢系统。在宏观层面,策略网络选择走子,而更快速的rollout策略网络评估这些走子。在微观层面,更快速的rollout策略网络可以通过一个直接预测棋盘位置胜率的价值网络来近似。
我们可以从AlphaGo中学到什么应用于自动驾驶?AlphaGo展示了通过一个强大的世界模型(模拟)提取优秀策略的重要性。同样,自动驾驶需要一个高度准确的模拟,以有效利用类似于AlphaGo的算法。
MPDM和自动驾驶
在围棋中,所有状态对双方棋手都是即时可见的,使得这成为一个完美信息游戏(perfect information game),其中观察等同于状态。这允许游戏用MDP过程描述。相比之下,自动驾驶是一个POMDP过程,因为状态只能通过观察来估计。
POMDPs以有原则的方式连接感知和规划。POMDP的典型解决方案类似于MDP,但带有有限的预见。然而,主要挑战在于维度诅咒(状态空间的爆炸)和与其他代理的复杂交互。为了使实时进展变得可行,通常会做出领域特定的假设以简化POMDP问题。
MPDM(Multi-policy Decision Making,及其两项后续的研究,以及白皮书)是这一方向的开创性研究。MPDM通过对有限的离散语义级策略(也就是前文所说的语义动作,semantic actions)集合进行闭环前向模拟,而不是评估每个车辆的每一个可能控制输入,从而简化了POMDP问题。此方法通过专注于少量有意义的语义动作来应对维度诅咒,从而使在自动驾驶场景中进行有效的实时决策成为可能。
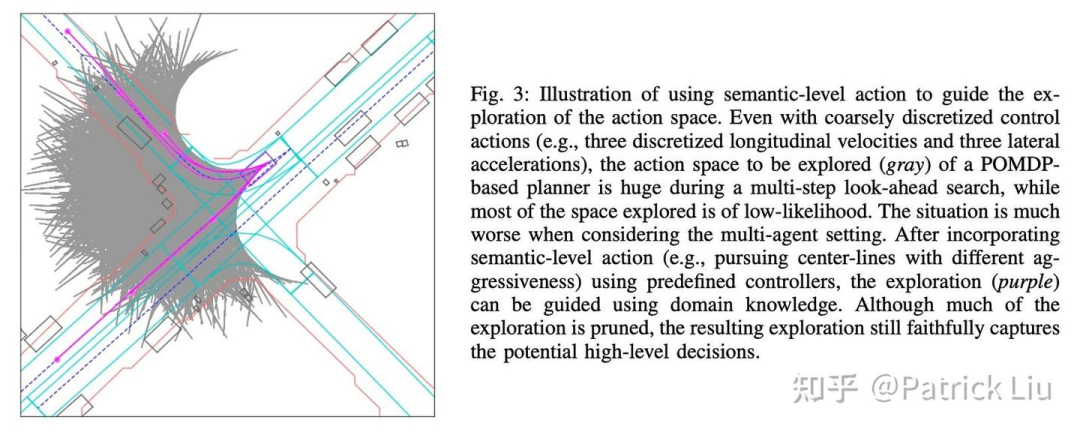
MPDM的假设有两个。首先,大多数人类驾驶决策涉及离散的高层语义动作(例如减速、加速、变道、停车)。在这种情况下,这些动作被称为策略。第二个隐含假设是其他车辆会做出合理安全的决策。一旦确定了一辆车的策略,其行动(轨迹)也就基本确定了。
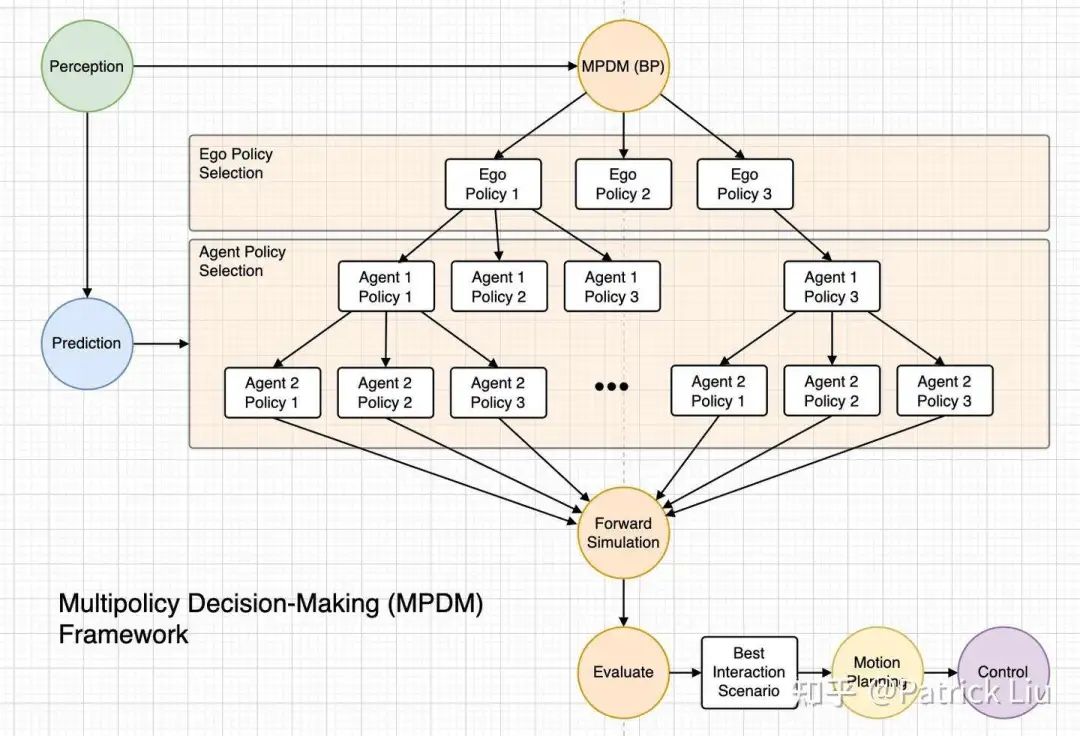
MPDM首先从众多选项中为自车选择一个策略(这就是其名称中“多策略”的来源),并根据它们各自的预测为每个附近的车辆选择一个策略。然后进行前向模拟(类似于MCTS中的快速rollout)。评估后选择最佳交互场景,然后传递给运动规划,例如在联合时空规划部分提到的时空语义走廊(SSC)。
MPDM使得智能和人性化的行为成为可能,例如在没有足够间隙的情况下主动切入密集交通流。这在预测-然后-规划(predict-then-plan)管道中是无法实现的,因为它没有明确考虑交互。MPDM中的预测模块通过前向模拟与行为规划模型紧密集成。
MPDM假设在整个决策视野(10秒)内只使用一种策略。这基本上就是采用了一种非常宽而浅的MCTS方法,考虑了所有可能的代理行为预测。这就给改进留下了空间,也激发了许多后续研究,比如EUDM、EPSILON和MARC。例如,EUDM考虑了更加灵活的自车策略,并使用了一个深度为4的策略树,每个策略覆盖2秒的时间跨度,总共覆盖8秒的决策视野。为了抵消增加的树深度所带来的额外计算负担,EUDM通过指导分支进行更高效的宽度修剪,识别关键场景和关键车辆。这种方法探索了一个更为平衡的策略树。
在MPDM和EUDM中,前向模拟使用了非常简化的驾驶员模型(纵向模拟使用IDM,横向模拟使用纯追踪)。MPDM指出,只要策略级别的决策不受低级别动作执行不准确的影响,高保真度的现实性并不如闭环性质本身那么重要。
在自动驾驶的背景下,应急规划(Contingency Planning)涉及生成多条潜在轨迹,以应对各种可能的未来情景。一个关键的例子是,有经验的司机会预见多个未来场景,并始终计划一个安全的备选方案。这种预见性的策略即使在遇到突然切入车道的车辆时,也能带来更平顺的驾驶体验。
应急规划的一个重要方面是延迟决策分叉点。也就是说,延迟不同潜在轨迹分离的时间点,让自车有更多时间收集信息并对不同的结果做出反应。通过这样做,车辆可以做出更明智的决策,从而实现更平稳和更有信心的驾驶行为,类似于有经验的司机。
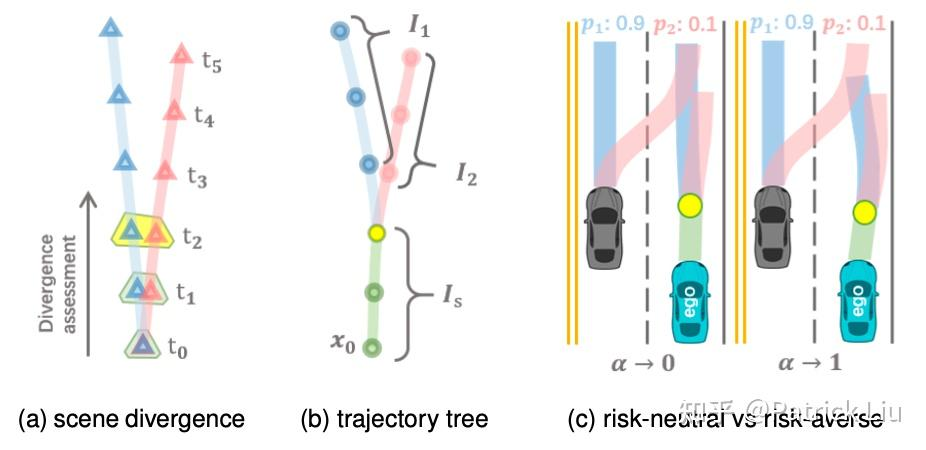
MARC 把行为规划和运动规划巧妙地结合在了一起,让前向模拟更强大、更实用。简单来说,MPDM 和 EUDM 使用策略树来进行高层次的行为规划,然后依赖其他运动规划管道,比如语义时空走廊(SSC)。因为在策略树中,自车的运动仍然是用高度量化的语义行动来描述的。而 MARC 进一步提升了这一点,对自车之外的其他代理保持量化行为,但在前向展开时直接使用更精细的运动规划。可以说,MARC 是一种混合方法,就像混合 A*,是离散和连续两种方法的混合体。这种方法不仅保留了量化行为的优点,还融合了更精细的运动规划,让我们的前向模拟更加智能和灵活。
MPDM及其所有后续工作的一个可能缺陷是,它们依赖于为类似高速公路结构的环境(如保持车道和换道)设计的简单策略。这种依赖可能会限制前向模拟处理复杂交互的能力。为了解决这个问题,遵循MPDM的示例,关键在于通过增长高级策略树来简化动作和状态空间。比如,可以通过对所有相对物体枚举时空相对位置标签,然后进行指导分支,来创建一个更灵活的策略树。
工业界的决策实践
决策仍然是当前研究的热门话题。即使是传统的优化方法也还没有被完全探索。机器学习方法尤其是大语言模型(LLM)在链式推理(CoT)或蒙特卡罗树搜索(MCTS)等技术的支持下,可能会带来颠覆性的影响。
使用搜索树
树结构是执行决策的系统方式。特斯拉在2021年和2022年的AI日展示了他们的决策能力,这些能力深受AlphaGo及其后继者MuZero的影响,用于解决高度复杂的交互。
根据2021年的分享,特斯拉的方法遵循行为规划(决策)然后是运动规划。首先搜索一个凸走廊,然后将其输入连续优化,使用时空联合规划。这种方法有效地解决了如狭窄通行这样的场景,这是路径-速度解耦规划的典型瓶颈。
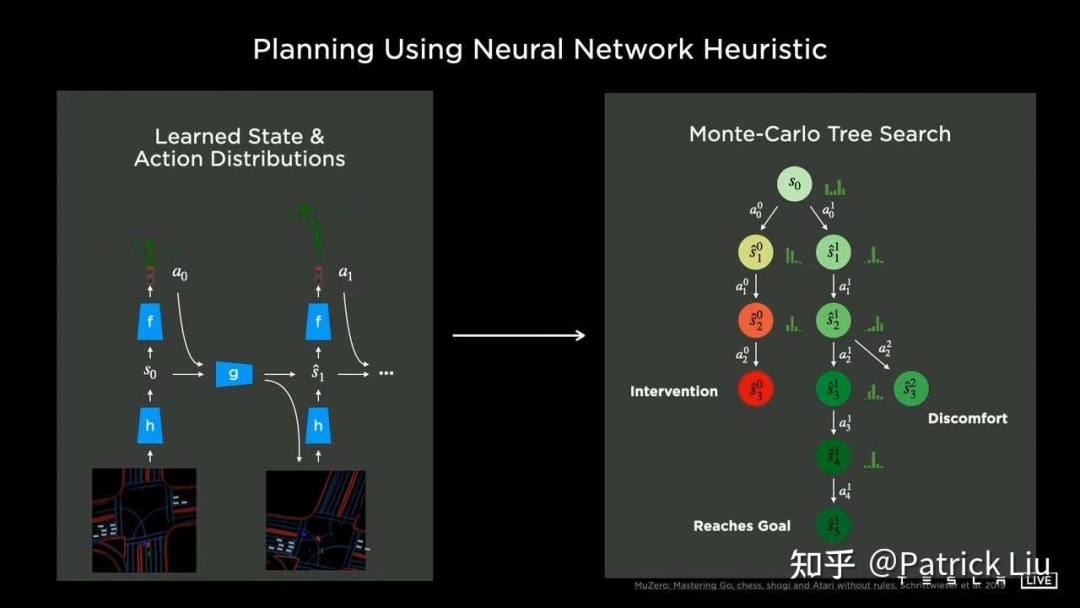
特斯拉还采用了一种结合数据驱动和物理检查的混合系统。特斯拉的系统从定义目标开始,生成种子轨迹并评估关键场景。然后,它会分支创建更多的场景变体,例如对其他交通参与者的抢断或礼让。
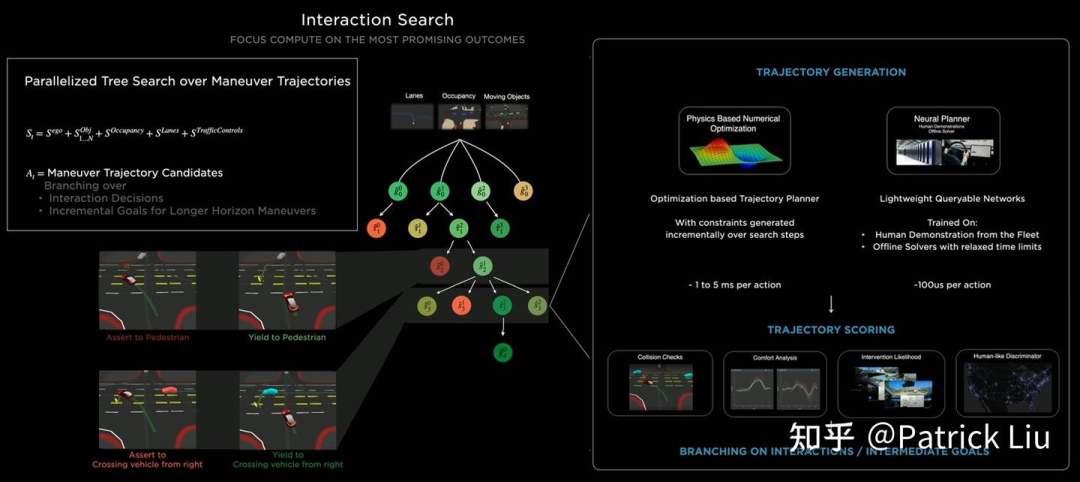
特斯拉使用机器学习的一个亮点是通过轨迹优化加速树搜索。对于每个节点,特斯拉使用基于物理的优化和神经规划器,实现了10毫秒对比100微秒的时间框架——结果是10倍到100倍的改进。神经网络通过专家演示和离线优化器进行训练。
轨迹评分通过结合传统的基于物理的检查(如碰撞检查和舒适度分析)与神经网络评估器来进行。特斯拉使用了两个神经网络评估器,一个预测接管(takeover)可能性另一个预测和人类的相似度。这种评分有助于修剪搜索空间,将计算集中在最有前途的结果上。
虽然很多人认为机器学习应该应用于高层次的决策,但特斯拉基本上在利用ML来做最底层的优化加速,从而加速树搜索。
蒙特卡罗树搜索(MCTS)方法似乎是决策的终极工具。有趣的是,研究大语言模型(LLM)的人正在尝试将MCTS集成到LLM中,而从事自动驾驶的人则试图用LLM取代MCTS。
大约两年前,特斯拉的技术采用了这种方法。然而,自2024年3月以来,特斯拉的全自动驾驶(FSD)已经转向了一种更端到端的方法,与之前的方法显著不同。
不使用搜索树
我们仍然可以在不显式增长树的情况下考虑交互。可以实施特设逻辑,实现在预测和规划之间进行一次交互。即使是一次交互也能产生良好的行为(图森未来曾在AI Day中提及了这个设计,但不清楚是否上了实车)。MPDM在其原始形式中,本质上是一次交互,但以更有原则和可扩展的方式执行。
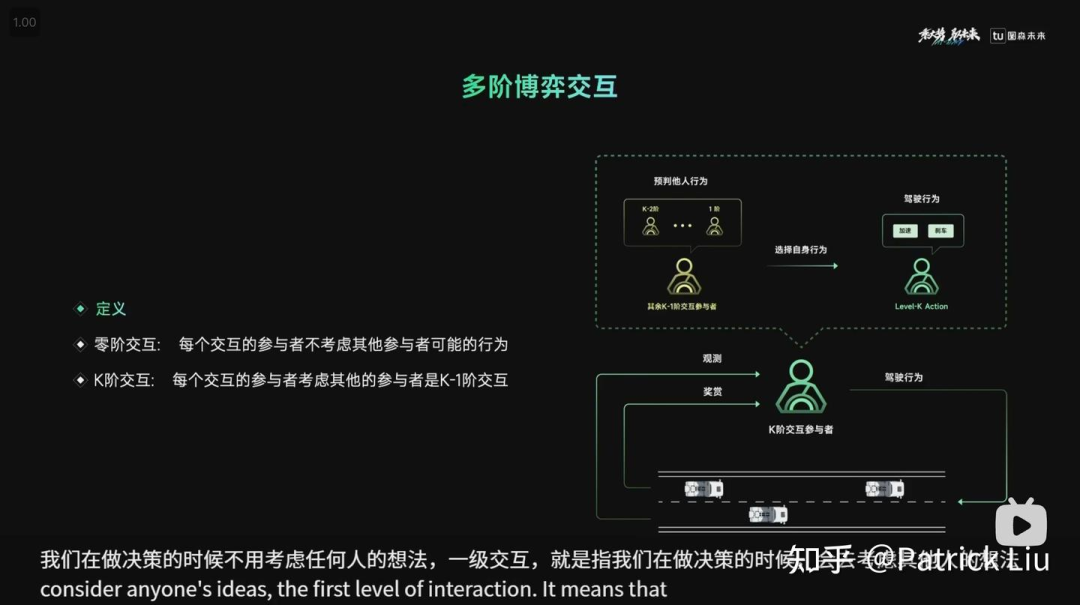
图森未来还展示了执行应急规划的能力,类似于MARC中提出的方法(不过MARC还可以适应定制的风险偏好)。

自我思考
学习了传统规划系统的基本构建模块,包括行为规划、运动规划以及通过决策处理交互的原则方法后,我一直在思考系统中的潜在瓶颈以及机器学习(ML)和神经网络(NN)如何帮助解决这些问题。我在此记录我的思考过程,以备将来参考,并希望对有类似问题的人有所帮助。需要注意的是,这部分信息包含我个人偏见和推测。
为什么在规划中使用神经网络?
让我们从现有的模块化管道、端到端(e2e)神经网络规划器或端到端自动驾驶系统三个不同的角度来看这个问题。
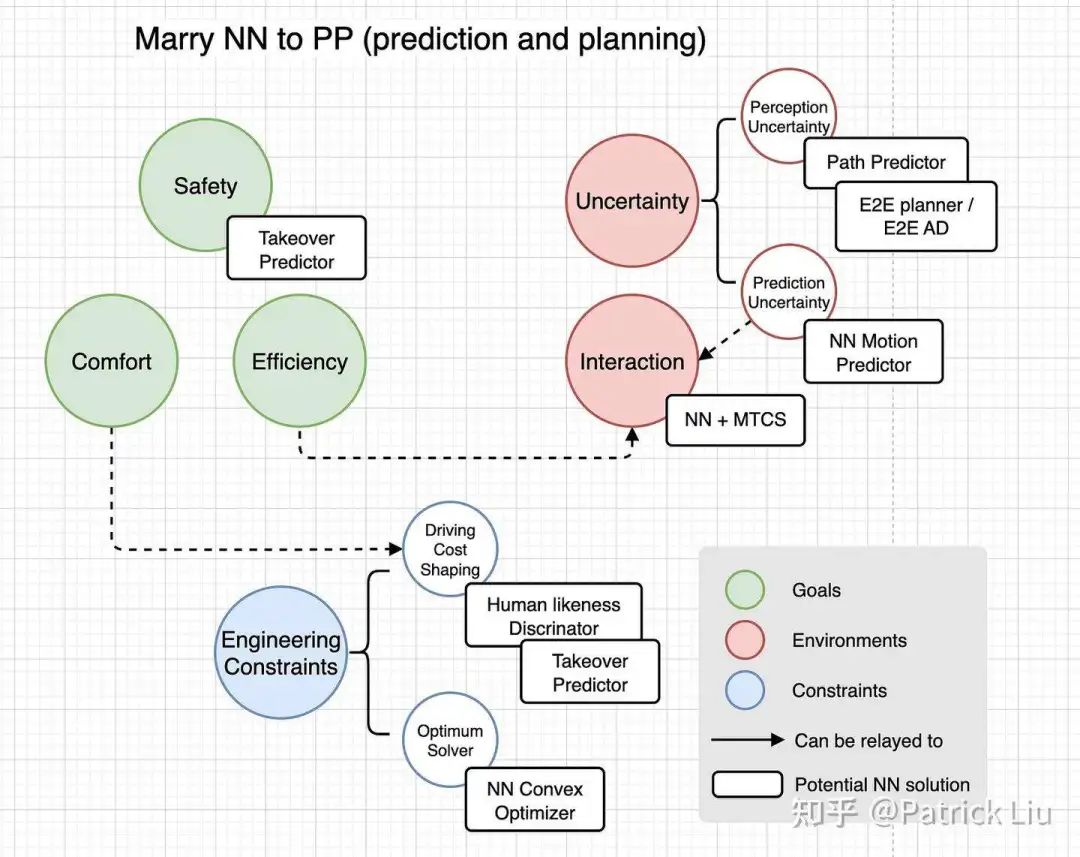
让我们回顾一下自动驾驶中规划系统的问题定义。目标是在高度不确定和交互的环境中,在遵守车载实时工程约束的情况下,获得一个确保安全、舒适和高效的轨迹。这些因素在上图中总结为目标、环境和约束。
自动驾驶中的不确定性可以指感知(观察)中的不确定性以及预测其他代理行为未来轨迹的不确定性。规划系统还必须处理其他代理未来轨迹预测中的不确定性。正如前面讨论的,有原则的决策系统是处理这些问题的有效方法。
此外,在当前以视觉为中心和无高清地图的驾驶时代,规划必须有能力承接感知结果的不确定性、不完美和不完整。集成一个标精地图(SD Map)有助于减轻这种不确定性,但对一个高度手动的规划器系统来说,仍然有较大难度。L4自动驾驶公司通过大量使用激光雷达和高清地图,认为感知不确定性已得到解决。然而,随着行业大规模量产自动驾驶解决方案迈进,这个问题再次出现。一个NN规划器更具鲁棒性,能够处理不完美和不完整感知结果,这对于大规模生产以视觉为中心和无高清地图的高级驾驶辅助系统(ADAS)至关重要。
交互应该使用有严谨数学基础的决策系统来处理,例如蒙特卡罗树搜索(MCTS)或简化版本的MPDM。主要挑战在于如何利用自动驾驶领域的知识,智能地修剪策略树,以应对维度诅咒(组合爆炸)。学术界的MPDM和工业界的特斯拉都展示了如何平衡地生长策略树。
神经网络还可以通过加速运动规划优化来增强规划器的实时性能。这可以将计算负荷从CPU转移到GPU,实现数量级的加速。如果优化速度提高十倍,就可以从根本上影响高级算法设计,如MCTS。
轨迹规划需要更具人性化。可以使用大量的真实驾驶数据进行训练,以开发人性化和接管预测器。扩大计算资源池比维持不断增加的工程团队更具可持续性。
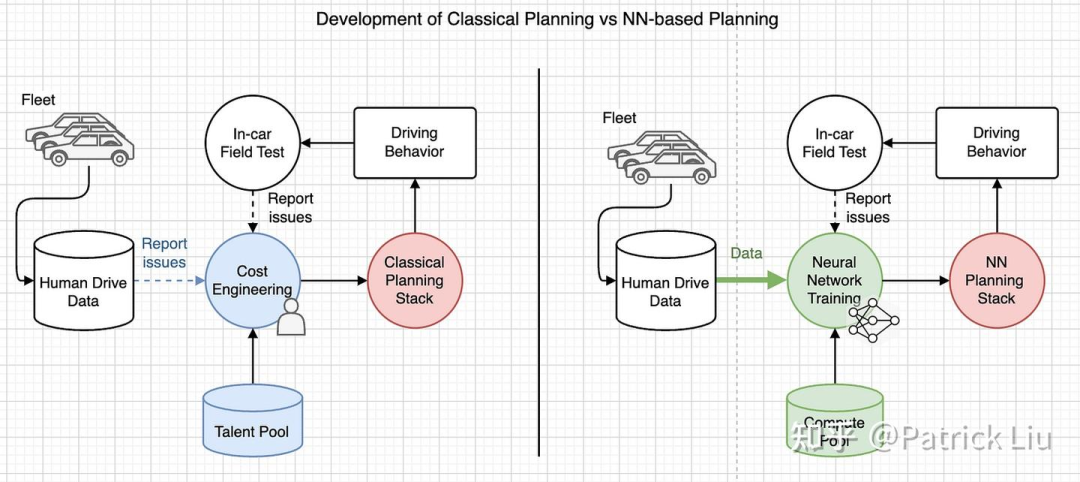
端到端神经网络规划器怎么做?
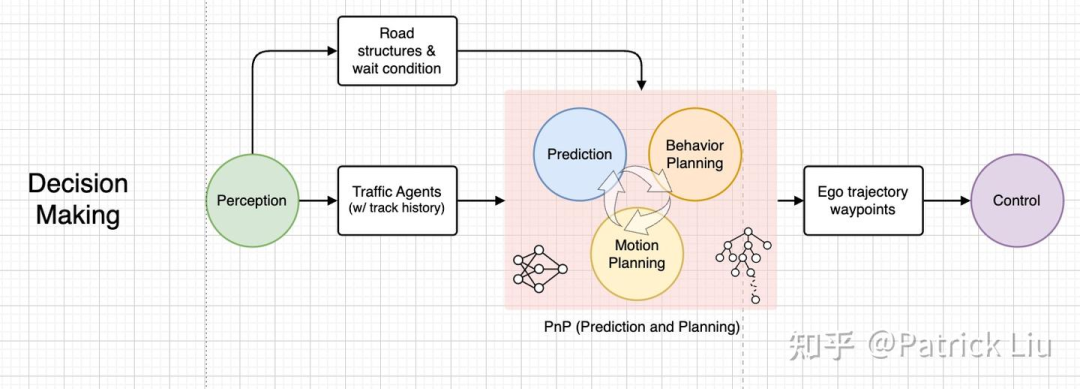
端到端(e2e)神经网络(NN)规划器仍然是模块化自动驾驶设计的一部分,接收结构化感知结果(和潜在的潜在特征)作为输入。这种方法将预测、决策和规划结合成一个单一的网络。一些公司,如DeepRoute(2022)和华为(2024)都声称采用了这种方法。注意,这里省略了相关的原始传感器输入,如导航和自车信息。
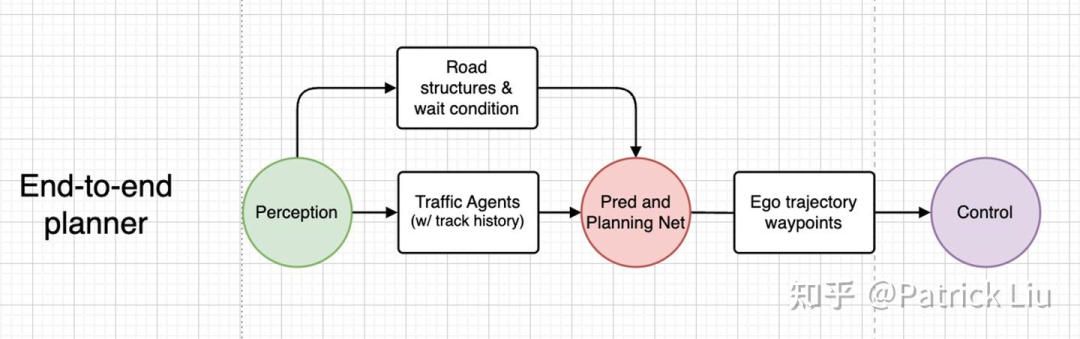
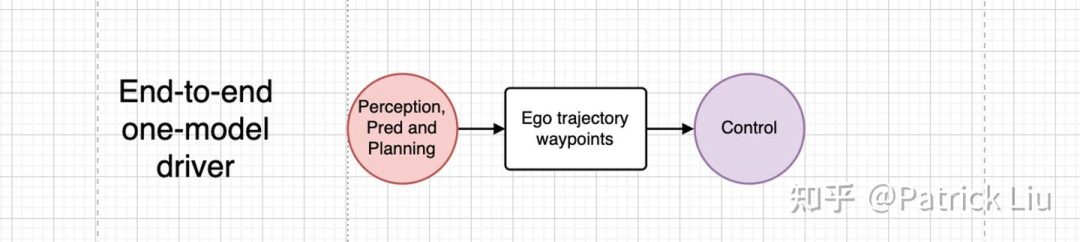
端到端(e2e)规划器可以进一步发展为一种结合感知与规划的端到端自动驾驶系统。这正是Wayve的LINGO-2(2024)和特斯拉的FSDv12(2024)想要实现的目标。
这种方法有两大好处。首先,它解决了感知问题。驾驶中有许多方面我们无法通过常用的感知接口显式建模。例如,要手工制作一个绕过水坑或在遇到凹陷或坑洞时减速的驾驶系统是相当困难的。虽然传递中间感知特征可能有所帮助,但它可能无法从根本上解决问题。
此外,涌现行为可能有助于更系统地解决corner case(边缘情况)。例如上述示例的智能处理corner case,很可能就是大型模型涌现行为的结果。
我推测,在其最终形式中,假设没有计算限制,端到端驾驶员将是一个由蒙特卡洛树搜索(MCTS)增强的原生多模态(native multimodal)大模型。截至2024年,文献中大家比较有共识的自动驾驶世界模型通常是一个覆盖至少视觉和行动模式的多模态模型(Vision-Action或者VA模型)。虽然语言可以加速训练、增加可控性并提供可解释性,但它并不是必需的。在其完全开发的形式中,一个世界模型将是一个视觉-语言-行动(Vision-Language-Action,VLA)模型。
开发世界模型至少有两种方法:
视频原生模型:训练一个模型来预测未来的视频帧,这些帧是以伴随的行动为条件或输出的,如GAIA-1等模型所示。
多模态适配器:从预训练的大型语言模型(LLM)开始,添加多模态适配器,如LINGO-2、RT2或ApolloFM等模型。这些多模态LLM不是原生的视觉或行动模型,但需要显著更少的训练资源。
一个世界模型可以通过行动输出本身产生策略,从而直接驾驶车辆。或者,MCTS可以查询世界模型并使用其策略输出来指导搜索。尽管这种世界模型-MCTS方法在计算上要密集得多,但它在处理边缘情况方面可能具有更高的上限,因为它具有显式的推理逻辑。
我们能否不进行预测?
大多数当前的运动预测模块将自车以外的代理的未来轨迹表示为一个或多个离散轨迹。预测-规划接口是否足够或必要,仍然是一个问题。
在传统的模块化流程中,预测仍然是需要的。然而,如在决策环节中讨论的那样,预测-然后-规划流程确实限制了自动驾驶系统的上限。一个更为关键的问题是如何更有效地将这个预测模块整合到整体的自动驾驶模块中。预测应当辅助决策,一个在整体决策框架中可被调用的预测模块,如MPDM及其变体,是首选。只要具体轨迹预测被正确整合,例如通过策略树回滚,就不会有严重问题。
预测的另一个问题是,开放回路关键性能指标(open-loop KPIs),例如平均位移误差(ADE)和最终位移误差(FDE),不是有效的度量标准,因为它们未能反映对规划的影响。相反,应考虑意图层面的召回率和精准度等指标。
在端到端系统中,显式的预测模块可能不是必须的,但隐式监督——以及来自传统模块的其他领域知识——无疑可以帮助或至少提升学习系统的数据效率。评估预测行为,无论是显式的还是隐式的,也将有助于调试这样的端到端系统。
我们能否只用网而不用树?
首先说结论。对于助手而言,神经网络(nets)可以实现非常高,甚至是超人的表现。而对于代理,我认为使用树结构(trees)仍然是有益的(尽管不一定是必须的)。
首先,树结构可以增强神经网络。以MCTS为例,MCTS提升了给定网络的性能,无论其是否基于神经网络。在AlphaGo中,即使使用通过监督学习和强化学习训练的策略网络,整体性能上,仍然比基于MCTS的AlphaGo要低。AlphaGo中将策略网络作为一个组件整合在内。
其次,神经网络可以从树结构中提取知识。在AlphaGo中,MCTS使用了价值网络和来自快速回滚策略网络的奖励来评估树中的节点(状态或棋盘位置)。AlphaGo论文还提到,虽然可以单独使用价值函数,但结合两者的结果才能达到最佳效果。价值网络本质上是通过直接学习状态-价值对,从策略回滚中提炼知识。这类似于人类将缓慢的系统2的逻辑思维提炼为快速、直觉反应的系统1。丹尼尔·卡尼曼在他的书《思考,快与慢》中描述了一个象棋大师如何在多年的练习后快速识别模式并做出迅速决策,而一个新手则需要付出大量努力才能达到类似的结果。同样地,AlphaGo中的价值网络可以通过训练能快速评估给定的棋盘位置。
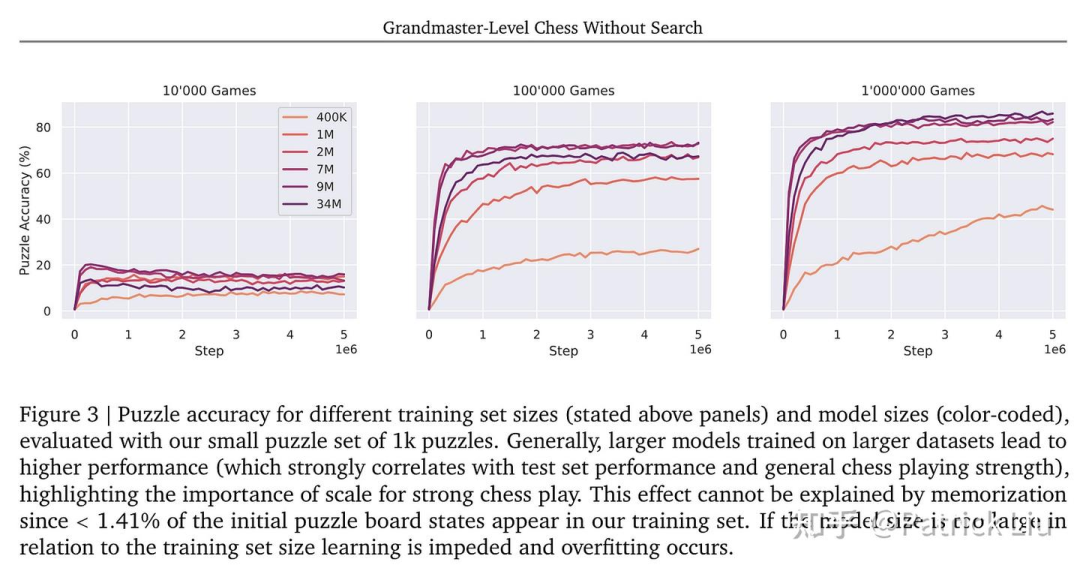
最近的论文探索了这种快速系统在神经网络方面的上限。"无需搜索的象棋"论文展示了在有足够数据(来源于传统算法的树搜索)的情况下,有可能达到大师级的水平。存在一个明确的scaling law与数据量和模型规模相关,表明随着数据量和模型复杂性的增加,系统的熟练度也会提高。
因此,我们有一个强力组合:树结构可以提升神经网络的性能,而神经网络也可以从树结构中提取知识。这个正反馈循环基本上就是AlphaZero用来在多个游戏中自举到超人表现的方法。
同样的原则也适用于大型语言模型(LLMs)的发展。对于游戏,由于我们有明确的胜负奖励,我们可以使用前向回滚来确定某个动作或状态的价值。对于LLMs,奖励不像围棋那样明确,因此我们依靠人类偏好通过人类反馈强化学习(RLHF)来评估模型。然而,我们可以使用监督微调(SFT),本质上是模仿学习,从ChatGPT这样的模型中蒸馏出较小但仍然强大的模型,而无需RLHF。
回到最初的问题,神经网络在大量高质量数据的支持下可以达到非常高的性能。这对于助手来说可能已经足够,取决于对错误的容忍度,但对于自动代理可能还不够。对于目标是驾驶辅助系统(ADAS,也是一种助手)的系统,神经网络通过模仿学习可能已经足够了。
树结构通过显式推理循环显著提升了神经网络的性能,使它们可能更适合于完全自主的代理。树结构或推理循环的广度取决于工程资源的投入回报。例如,正如在TuSimple AI Day中所倡导的那样,即使是一次交互也能带来显著的好处。
我们能否使用LLM来做决策?
从以下对热门AI代表产品的总结中可以看出,LLM并不是为决策制定而设计的。实际上,LLM的训练目标是用来完成文档,甚至那些经过监督微调(SFT)对话助手例如ChatGPT,也是将对话视为一种特殊类型的文档(完成对话记录)。
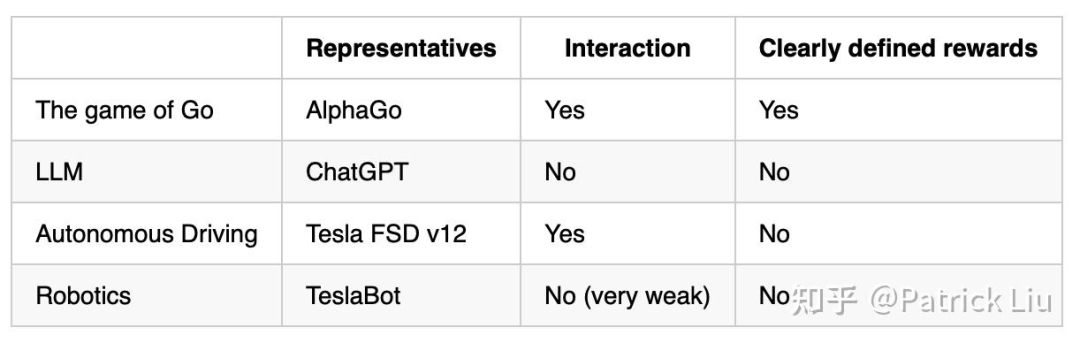
目前有一种观点认为LLM是慢速系统(系统2)。对此我并不完全同意。由于硬件限制,LLM的推理过程确实较传统网络架构慢,但在其原始形式中,LLM无法执行反事实检查,所以它们还是快系统。提示技术如思维链(CoT)或思维树(ToT)实际上是蒙特卡洛树搜索(MCTS)的简化形式,使LLM更像是慢速系统。
目前有大量研究试图将完整的MCTS与LLM结合起来。具体来说,LLM-MCTS(NeurIPS 2023)将LLM视为常识“世界模型”,并使用LLM诱导的策略动作作为指导搜索的启发式。LLM-MCTS在复杂、新颖的任务上大幅超越了仅使用MCTS和LLM诱导的策略。OpenAI被广泛猜测的Q-star似乎也遵循同样的方法,通过MCTS提升LLM性能。
规划的演进趋势
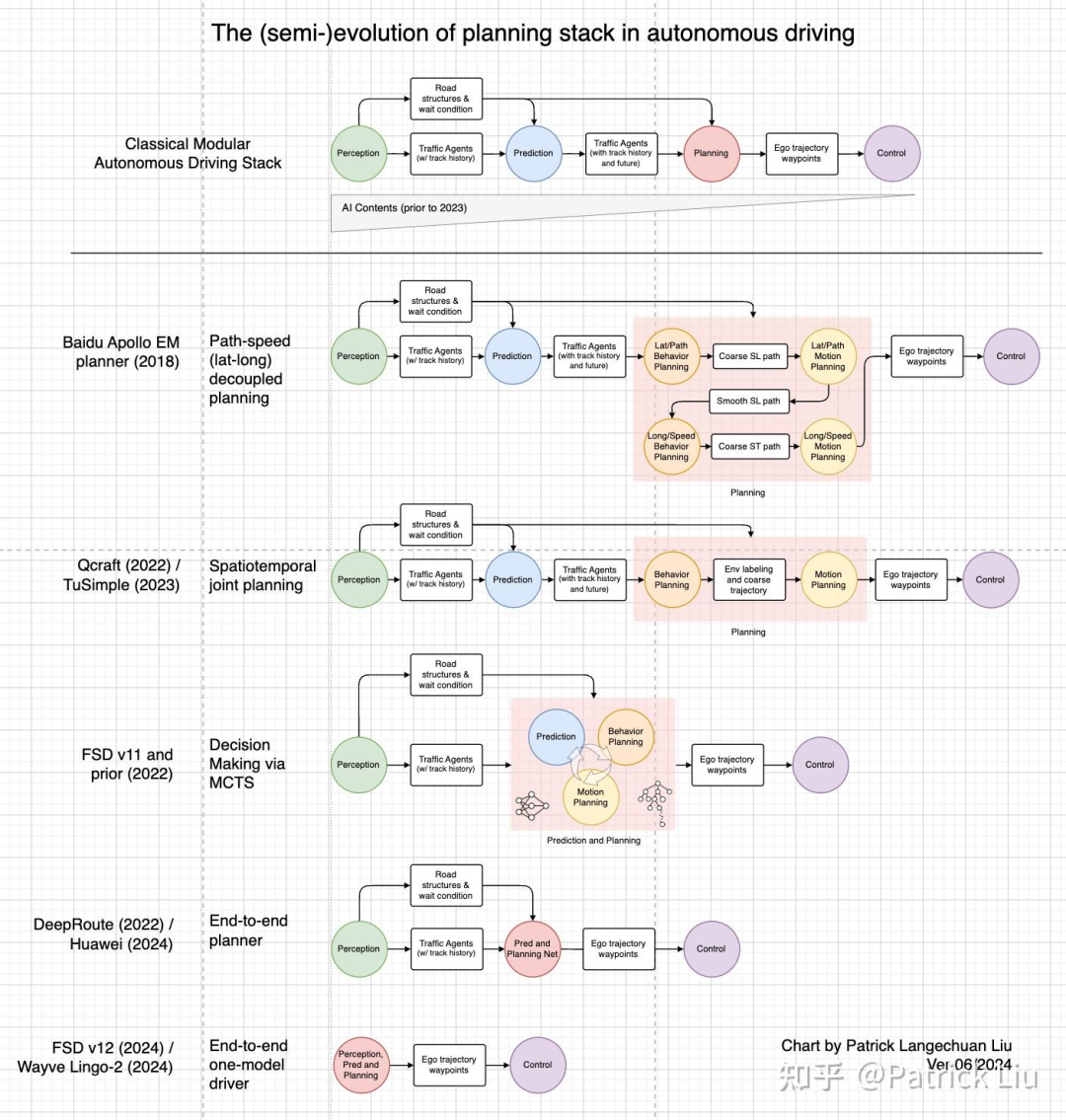
以下是自动驾驶规划模块的一个大致的演进历史。之所以称之为“大致”,是因为并不是每个方案都一定比它前面的更先进,并且它们的问世时间也不一定是确切的。但是我们可以观察到一些总体趋势。需要注意的是,所列出的行业代表性解决方案都是基于我对各种新闻稿的理解,可能存在误差。
首先,可以看到规划模块的架构变得越来越“端到端“,即更多的模块被整合到一个系统中。我们可以看到模块从路径-速度解耦规划演变为联合时空规划,并从”预测-然后-规划“系统演变为联合预测和规划系统。其次,可以看到规划模块越来越多地采用基于机器学习的组件,特别是在最后三个阶段。这两个趋势趋向于一个端到端的神经网络规划器(不包括感知)甚至是一个端到端的单一模型的神经网络驾驶员(包括感知)。
要点总结
机器学习作为工具:机器学习是一种工具,而不是单独的解决方案。即使在当前的模块化设计中,它也可以辅助规划。
完整问题表述:从完整的问题表述开始,然后做出合理假设以平衡性能和资源。这有助于为未来的系统设计制定明确的方向,并在资源增加时进行改进。回顾从POMDP的表述到AlphaGo的MCTS和MPDM等工程解决方案的过渡。
算法适应:理论上美妙的算法(如Dijkstra和Value Iteration)对于理解概念非常有用,但需要为实际工程进行适应(Value Iteration到MCTS,如Dijkstra算法到Hybrid A-star)。
确定性 vs. 随机性:规划在解决确定性(不一定是静态的)场景方面表现出色。在随机性场景中的决策制定是实现完全自主最具挑战的任务。
应急规划:这可以帮助将多个未来合并为一个共同的行动。应急规划的积极程度应使你始终可以依赖备选计划。
端到端模型:端到端模型是否能解决完全自主驾驶仍不明确。它可能仍需要经典方法如MCTS。神经网络可以处理助手任务,而树结构可以管理代理任务。
致谢
本博客文章深受丁文超博士在深蓝学院(Shenlan Xueyuan)规划课程的启发。
感谢和王乃岩和赵京伟的深刻而启发性的讨论。感谢论文推土机, Invictus, XF, PF和JL对初稿提出的关键反馈。感谢与伯克利的战威教授就学术界趋势进行的讨论。
① 自动驾驶论文辅导来啦

② 国内首个自动驾驶学习社区
『自动驾驶之心知识星球』近4000人的交流社区,已得到大多数自动驾驶公司的认可!涉及30+自动驾驶技术栈学习路线,从0到一带你入门自动驾驶感知(端到端自动驾驶、世界模型、仿真闭环、2D/3D检测、语义分割、车道线、BEV感知、Occupancy、多传感器融合、多传感器标定、目标跟踪)、自动驾驶定位建图(SLAM、高精地图、局部在线地图)、自动驾驶规划控制/轨迹预测等领域技术方案、大模型,更有行业动态和岗位发布!欢迎扫描加入

③全网独家视频课程
端到端自动驾驶、仿真测试、自动驾驶C++、BEV感知、BEV模型部署、BEV目标跟踪、毫米波雷达视觉融合、多传感器标定、多传感器融合、多模态3D目标检测、车道线检测、轨迹预测、在线高精地图、世界模型、点云3D目标检测、目标跟踪、Occupancy、CUDA与TensorRT模型部署、大模型与自动驾驶、NeRF、语义分割、自动驾驶仿真、传感器部署、决策规划、轨迹预测等多个方向学习视频(扫码即可学习)

④【自动驾驶之心】全平台矩阵



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









