






作者 | 自动驾驶专栏 编辑 | 自动驾驶专栏
点击下方卡片,关注“自动驾驶之心”公众号
>>点击进入→自动驾驶之心『端到端自动驾驶』技术交流群
本文只做学术分享,如有侵权,联系删文

论文链接:https://arxiv.org/pdf/2503.19755
项目主页:https://xiaomi-mlab.github.io/Orion/

摘要

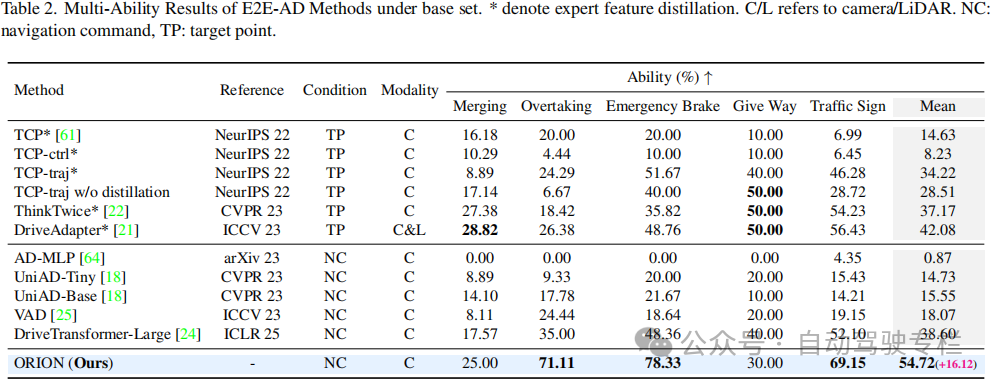
本文介绍了ORION:基于视觉语言引导行为生成的整体端到端自动驾驶框架。由于端到端(E2E)自动驾驶方法的因果推理能力有限,它在交互式闭环评估中仍然难以做出正确决策。当前的方法试图利用视觉语言模型(VLMs)的强大理解和推理能力来解决这一困境。然而,由于语义推理空间和行为空间中的纯数值轨迹输出之间存在差距,很少有用于E2E方法的VLMs在闭环评估中表现良好。为了解决这个问题,本文提出了ORION,这是一种基于视觉语言引导行为生成的全面E2E自动驾驶框架。ORION独特地结合了聚合长期历史上下文的QT-Former、用于驾驶场景推理的大型语言模型(LLM)和用于精确轨迹预测的生成规划器。ORION进一步对齐了推理空间和行为空间,为视觉问答(VQA)和规划任务实现统一的E2E优化。本文方法在具有挑战性的Bench2Drive数据集上实现了令人印象深刻的闭环性能,驾驶得分(DS)为77.74和成功率(SR)为54.62%,这比最先进的(SOTA)方法高出14.28的DS和19.61%的SR。

主要贡献

本文的贡献为如下三方面:
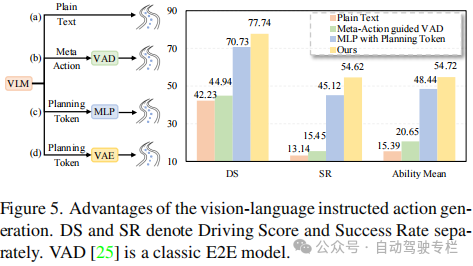
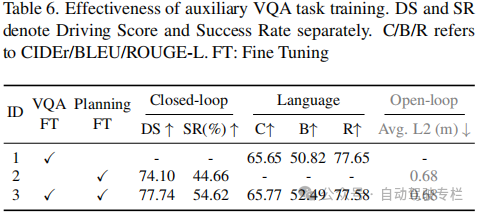
1)本文提出了ORION,这是一种基于视觉语言引导行为生成的全面E2E自动驾驶框架。得益于生成模型能够表征数据的潜在分布,本文通过生成规划器弥补了VLM的推理空间和轨迹的行为空间之间的差距,使VLM能够理解场景并且引导轨迹生成;
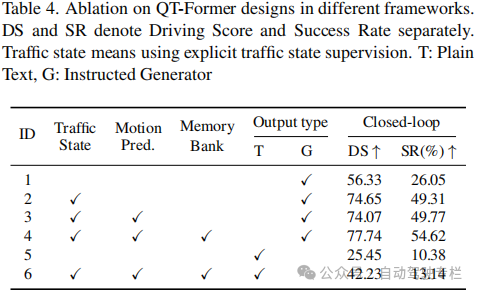
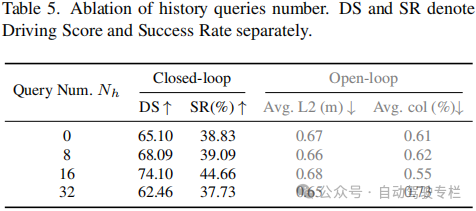
2)ORION中的QT-former有效地捕获了长期时间依赖性,使得模型能够将时间视觉上下文集成到推理和行为空间中;
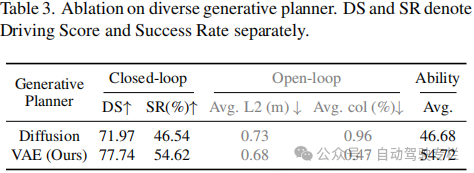
3)ORION在Bench2Drive闭环基准上表现出色。实验结果还表明,ORION与各种生成模型兼容,这进一步证明了所提出框架的灵活性。

论文图片和表格

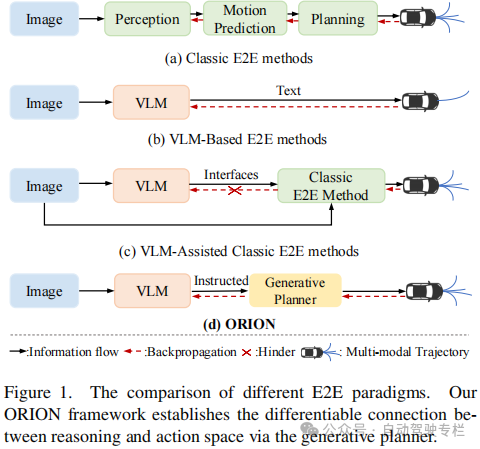
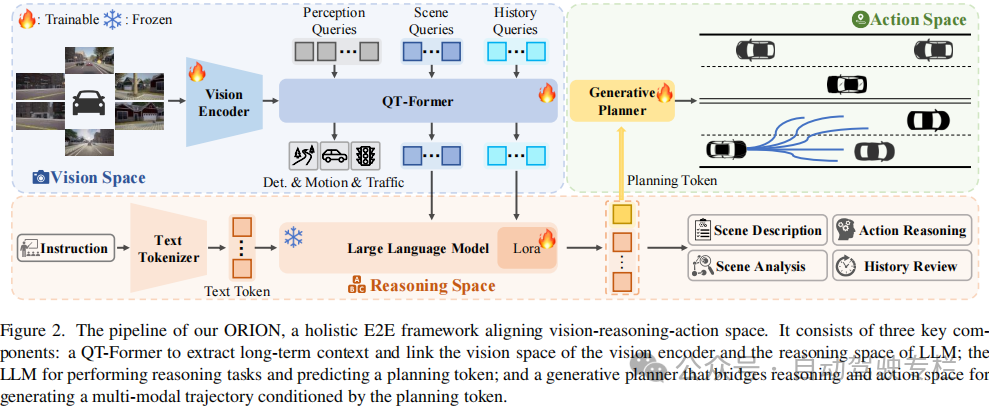
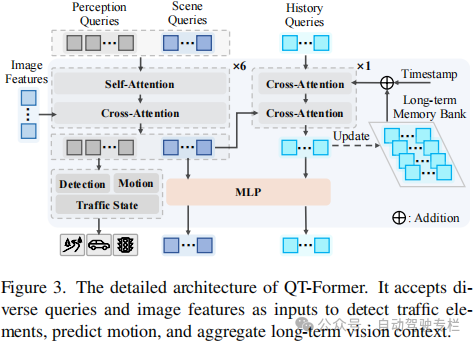
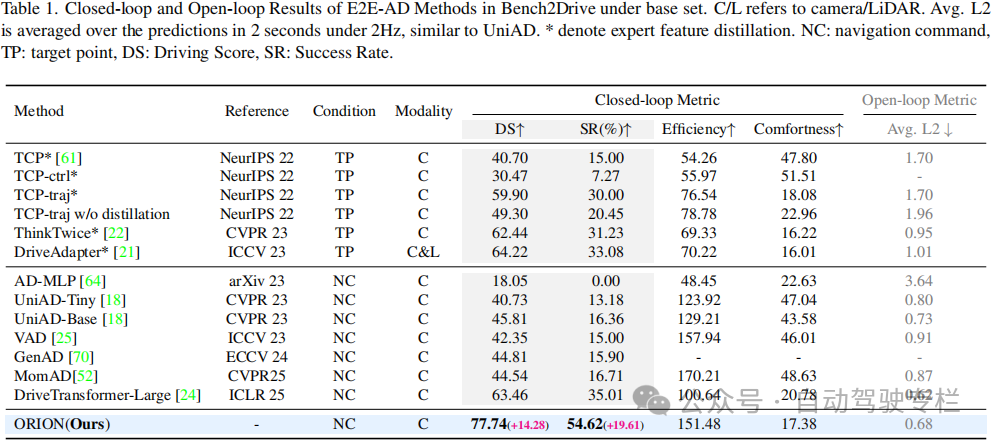

总结

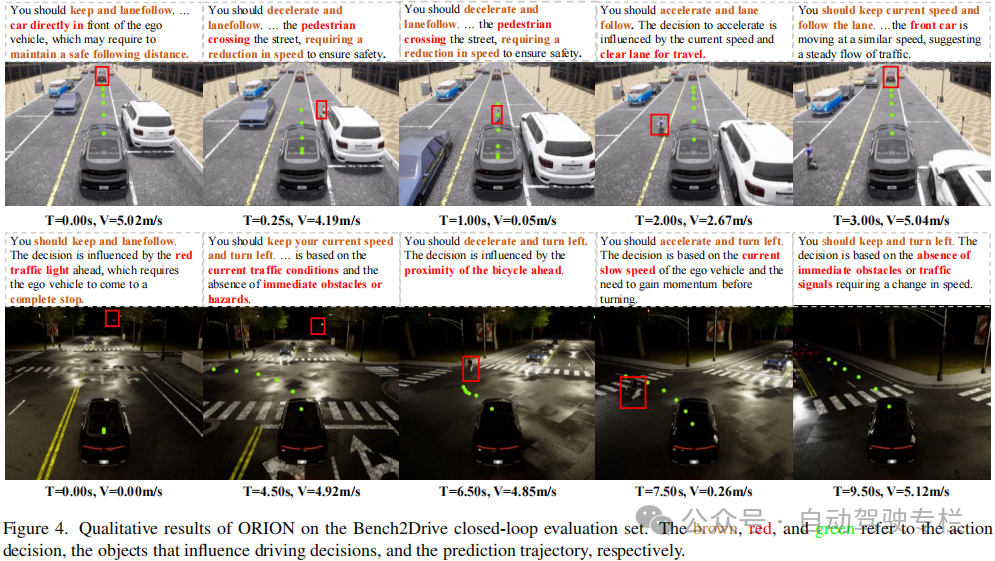
本文主要着重于端到端自动驾驶的VLM方法在将VLM的推理空间与用于规划的纯数值行为空间对齐方面所面临的挑战。因此,现有方法同时分析驾驶场景并且输出高质量多模态预测轨迹并非易事。为了解决这个问题,本文提出了ORION,这是一种通过视觉语言引导行为生成的整体端到端自动驾驶框架。本文通过利用生成规划器并且结合长期视觉上下文,有效地连接了视觉-推理-行为空间。大量实验验证了所提出框架的灵活性和优越性,结果表明,ORION在闭环规划评估方面取得了显著改进,其超越了SOTA方法。
局限性:尽管ORION在Bench2Drive的闭环仿真环境中表现良好,但是它受到实时驾驶场景中可扩展VLM的高计算复杂度限制。未来,本文将通过模型压缩和剪枝等技术来降低ORION的复杂度,从而使得模型能够实现实时自动驾驶。
自动驾驶之心
论文辅导来啦

知识星球交流社区
近4000人的交流社区,近300+自动驾驶公司与科研结构加入!涉及30+自动驾驶技术栈学习路线,从0到一带你入门自动驾驶感知(大模型、端到端自动驾驶、世界模型、仿真闭环、3D检测、车道线、BEV感知、Occupancy、多传感器融合、多传感器标定、目标跟踪)、自动驾驶定位建图(SLAM、高精地图、局部在线地图)、自动驾驶规划控制/轨迹预测等领域技术方案、大模型,更有行业动态和岗位发布!欢迎加入。

独家专业课程
端到端自动驾驶、大模型、VLA、仿真测试、自动驾驶C++、BEV感知、BEV模型部署、BEV目标跟踪、毫米波雷达视觉融合、多传感器标定、多传感器融合、多模态3D目标检测、车道线检测、轨迹预测、在线高精地图、世界模型、点云3D目标检测、目标跟踪、Occupancy、CUDA与TensorRT模型部署、大模型与自动驾驶、NeRF、语义分割、自动驾驶仿真、传感器部署、决策规划、轨迹预测等多个方向学习视频
学习官网:www.zdjszx.com


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









