






编辑 | 自动驾驶专栏
点击下方卡片,关注“自动驾驶之心”公众号
>>点击进入→自动驾驶之心『世界模型』技术交流群
本文只做学术分享,如有侵权,联系删文

论文链接:https://arxiv.org/pdf/2503.22231

摘要

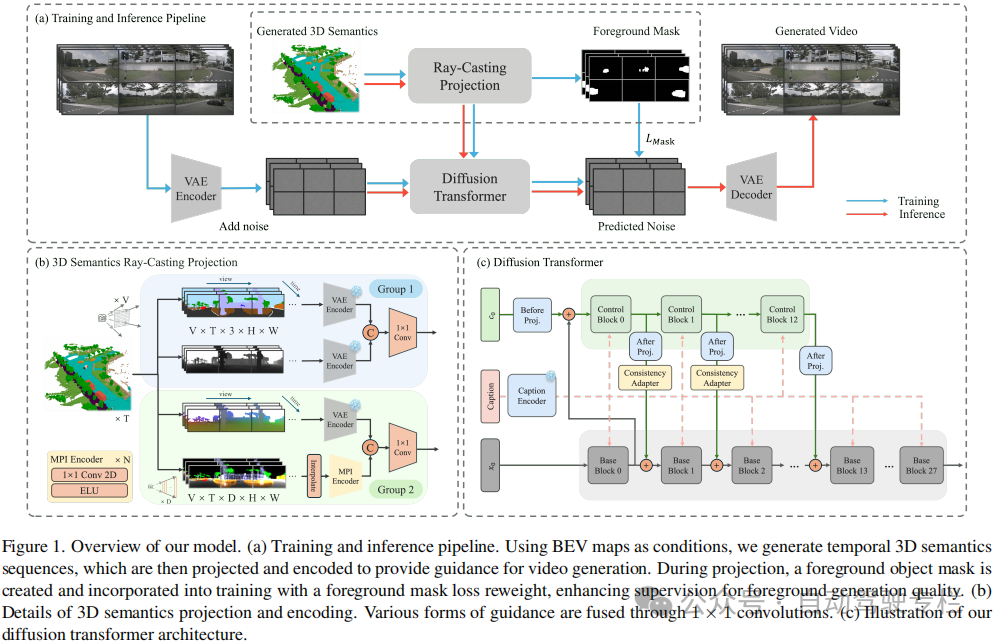
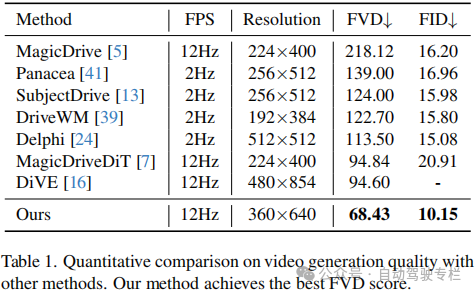
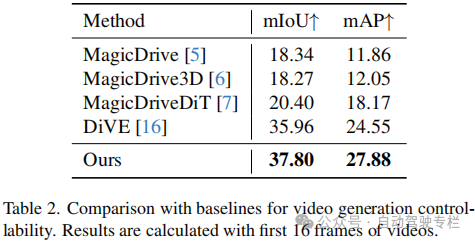
本文介绍了CoGen:自动驾驶中基于自适应调节的3D一致视频生成。驾驶视频生成的最新进展表明,通过提供可扩展且可控的训练数据来增强自动驾驶系统具有巨大的潜力。尽管由2D布局条件(例如高精地图和边界框)引导的预训练生成模型可以生成逼真的驾驶视频,但是实现具有高度3D一致性的可控多视图视频仍然是一项主要挑战。为了解决这个问题,本文引入了一种新的空间自适应生成框架CoGen,它利用了3D生成的当前进展来提高两个关键方面的性能:(i)为了确保3D一致性,本文首先生成高质量、可控的3D条件,以捕获驾驶场景的几何结构。本文方法通过使用这些细粒度的3D表示来替换粗略的2D条件,显著提高了生成视频的空间一致性;(ii)此外,本文引入了一致性适配器模块,以增强模型对多条件控制的鲁棒性。结果表明,该方法在保持几何保真度和视觉真实性方面表现出色,从而为自动驾驶提供了一种可靠的视频生成解决方案。

主要贡献

本文的贡献总结如下:
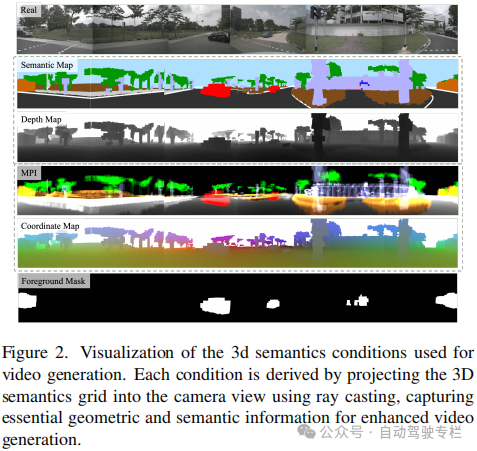
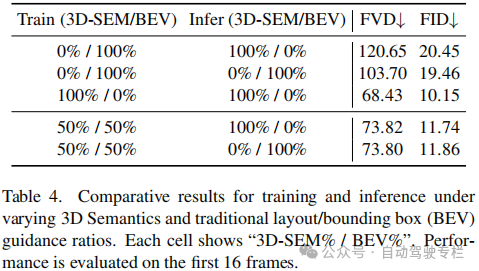
1)本文系统性地研究了四种基于3D语义的引导投影,验证了它们在视频生成中增强几何保真度和视觉真实性的能力;
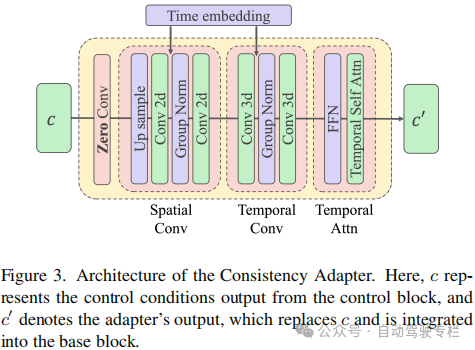
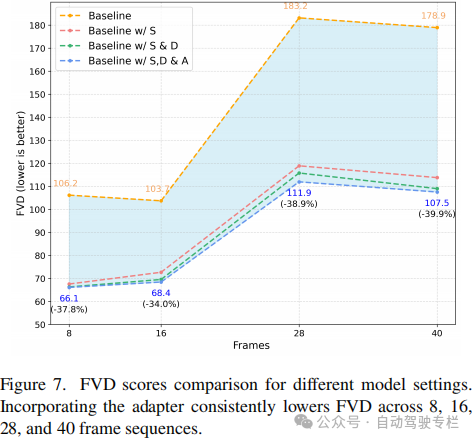
2)本文引入了一种一致性适配器,以提高模型对多种条件的适应性,显著增强了跨帧的运动一致性;
3)在基准数据集和指标上的实验表明,本文方法在驾驶视频生成方面实现了最先进的性能。

论文图片和表格





总结

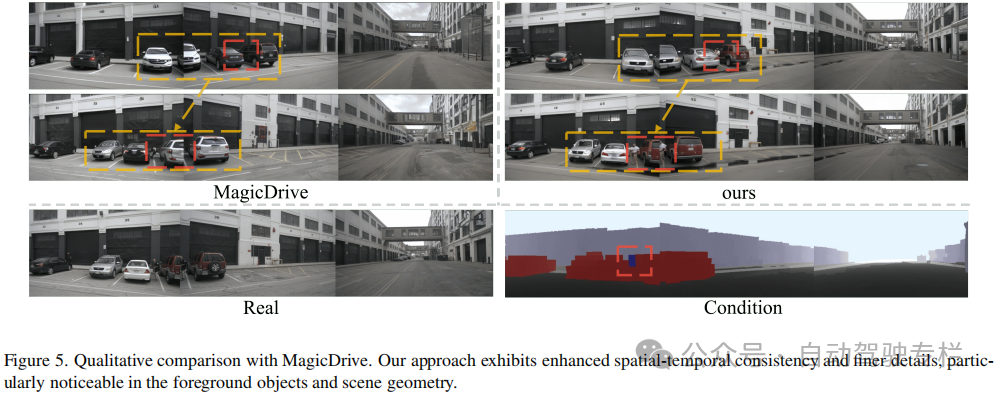
本文引入了CoGen,这是一种新的框架,它利用详细的3D语义信息来生成具有增强的逼真性和3D一致性的高质量驾驶视频。通过结合多种形式的语义引导、前景感知掩膜损失训练和一致性适配器模块,CoGen进一步提高了视频质量和3D一致性。在nuScenes数据集上的实验结果证明了CoGen实现了最先进的性能,其FVD为68.43,超越了基于2D布局和语义引导的现有方法。此外,本文方法生成的视频在下游感知任务中展现出卓越的实用性。这些结果证明了本文方法在生成自动驾驶合成数据、维持几何保真度和视觉真实性方面的实用价值。
自动驾驶之心
论文辅导来啦

知识星球交流社区
近4000人的交流社区,近300+自动驾驶公司与科研结构加入!涉及30+自动驾驶技术栈学习路线,从0到一带你入门自动驾驶感知(大模型、端到端自动驾驶、世界模型、仿真闭环、3D检测、车道线、BEV感知、Occupancy、多传感器融合、多传感器标定、目标跟踪)、自动驾驶定位建图(SLAM、高精地图、局部在线地图)、自动驾驶规划控制/轨迹预测等领域技术方案、大模型,更有行业动态和岗位发布!欢迎加入。

独家专业课程
端到端自动驾驶、大模型、VLA、仿真测试、自动驾驶C++、BEV感知、BEV模型部署、BEV目标跟踪、毫米波雷达视觉融合、多传感器标定、多传感器融合、多模态3D目标检测、车道线检测、轨迹预测、在线高精地图、世界模型、点云3D目标检测、目标跟踪、Occupancy、CUDA与TensorRT模型部署、大模型与自动驾驶、NeRF、语义分割、自动驾驶仿真、传感器部署、决策规划、轨迹预测等多个方向学习视频
学习官网:www.zdjszx.com


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









