






作者 | 李查德 来源 | 自动驾驶之心
原文链接:https://zhuanlan.zhihu.com/p/1900861798330107650
点击下方卡片,关注“自动驾驶之心”公众号
>>点击进入→自动驾驶之心『端到端自动驾驶』技术交流群
本文只做学术分享,如有侵权,联系删文
之前的文章主要从自动驾驶发展历程出发,讲了传统自动驾驶的架构和现在非常火的端到端自动驾驶的来龙去脉。
尽管传统派和端派还在吵的难分难解,我们这篇文章不去论证端到端自动驾驶一定比传统派强,而是讲一下现在工业界端到端自动驾驶的一些现状。至于路线之争,需要长时间的论证,重点是实践。
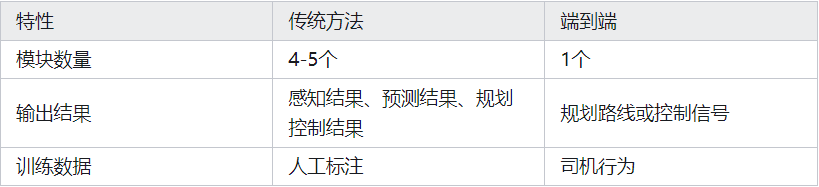
我们首先讲讲什么是端到端自动驾驶。笔者认为,端到端自动驾驶是和传统方法相对应的。传统方法把自动驾驶任务分成了感知、预测、规划控制等模块,对于每个任务,都需要一个单独的模型或者算法去解决。每个模块都需要在上车之前训练好,并且需要人工标注好的真值来作为训练的“目标”。比如感知模块,需要标注员在3D空间下标注出障碍物的定位、种类、大小。尽管每个模块彼此之间有交流,但是距离端到端还非常遥远。
而端到端(End-to-End)在机器学习领域,指的是数据输入模型 -> 模型输出结果,从模型的输入端到输出端,这中间没有人为干预。我们把数据给到模型,然后模型给我们一个最终结果,至于模型如何处理数据,人类并不关心,也不应该去纠正。在自动驾驶中,输入的数据是传感器信号(相机、激光雷达、毫米波),输出的是规划路线或者控制信号。
我们再从端到端的优势、劣势出发,讲讲为什么端到端自动驾驶容易受到现在工程师们的青睐。
端到端算法的优缺点
数据制胜
首先,端到端自动驾驶的数据来源非常广,对于主机厂(就是车厂)而言,任何一台车的所有行驶数据,都可以回流到云端,而这些数据就包括传感器(激光雷达、相机)的数据,当然也包括司机的驾驶数据(规划数据:司机的行驶轨迹;控制数据:油门开度、刹车开度、方向盘角度 )。这些数据都是人开车开出来的数据,理论情况下,不再需要人工标注了,可以直接拿来对模型进行训练,让模型去“模仿”人类如何开车。
对比下传统方法,传统方法一般分感知、预测、规划、控制等模块,以感知为例,车辆返回来的行驶数据需要标注,这在时间和金钱上都是非常大的成本。假如我们不考虑自动标注,返回的数据一般为10帧/秒,一辆车如果每天行驶2小时(以上班族为例),就会返回7w帧数据,假设每帧数据中需要标注的物体是10个(平均而言),则需要标注70w个物体,现在3D标注一般为1元左右一个物体,那么一辆车一天的数据,标注成本竟达到了70w!更别提现在主机厂面对的是几十万的用户,而特斯拉面对的是几百万的用户。而这仅仅是金钱成本,更别提时间成本了。
所以我们不难看出,端到端的优势首先体现在数据上,我们可以获得海量人驾数据,然后让模型去模仿人类的行为,避免了标注大量数据的时间和金钱成本。说个题外话,为什么数据一再为工程师所重视,23年GPT的横空出世,人们发现了力大砖飞的机器学习法则(学术界称scaling law),我只要模型够大,数据够多,效果一定会变好。而目前自动驾驶领域可回收的数据非常多,但是传统方法受限于刚才讲的标注,其实利用起来的并不是很多。而端到端正好是可以利用起来海量的人驾数据,所以被人们寄予了厚望。
模型简单
抛弃了传统方法的四到五个模块,端到端模型只需要一个模型,就可以接受输入信号,输出控制信号或者轨迹。对于工程师而言也是个福音,训练的模型数量大幅减少,节省了大量时间。此外,线上的模型由于模块数量减少,不需要模块间的信息传递(举个例子,预测需要感知结果作为输入),线上代码的复杂度也大幅下降。相对应的,算力的消耗应该变得更小。
无损的信息传递
还是举那个戴眼罩开车的例子。传统方法的规划控制模块接受感知预测的输入,也就是告诉电脑,在哪有车,车多大,速度多快等等。这相当于把主驾驶的眼镜蒙上,然后让副驾告诉主驾驶,有多少车,他们分别在哪。这样的信息传递是有损失的,即使副驾驶说的再详细,你也无法根据全部情况做出判断。
而端到端模型就实现了无损的信息传递,模型得到输入信号,再输出控制信号,这期间是没有人为的干预的,所有环境信息都可以用来做决策的依据。这就相当于把司机的眼罩取下来了,尽管没有副驾驶告诉他哪里有车,但是他可以自己进行判断,并且得到的信息更加丰富了。
难以收敛
刚才我们讲了端到端自动驾驶的优点,下面我们再来说一下端的缺点。首先是端到端模型难以收敛,不管是输出轨迹还是输出控制信号,端到端模型是一个非常高密度信息到一个低密度信息的映射,从而容易引发歧义,造成模型的困惑,因此难以收敛。我们举个例子,CV中已经证实可行的算法,比如目标检测语义分割等等,结果和输入具有很强的相关性,图中有物体,那么训练的标签就有物体,图中没有物体,训练的标签就没有物体。训练的标签和输入数据构成了非常强的映射关系。而端到端自动驾驶过程中,车前方有人,有的司机也许会急刹车,有的司机也许会采取避让措施,这些会造成映射的歧义。另外,大部分时间车不需避让,输出结果会和landmark强相关,当出现需要避让的情况的时候,模型是否会更多的相信landmark的结果?这也是信息密度从高到低映射带来的问题,端现在的问题就是标签和输入数据的映射关系太弱了。通俗点说,模型拿到的信息太丰富了,而仅仅一个控制信号能提供的信息太单薄了,模型学不到啥。
缺乏评测与仿真手段
其实评测和仿真在自驾中还是蛮重要的。首先我们评测一个算法一定要通过大量的数据去验证,而不能靠自己的主观感受,上车去跑几趟,看几个case,都不能从统计学的角度来证明算法的有效性。因此我们一定需要评测算法,在几万甚至几十万帧上做测评。目前的感知做的比较好,检测分割算法都有靠谱的指标去评估,评测也完全可以依靠计算机去自动化的进行。
问题是现在端到端就压根无法进行评测和仿真。
现有的算法无法评估车辆行为。怎么开才算好?碰到行人急刹车还是急打方向闪避?高速上碰到碎石等障碍物怎么办?路口转弯要走大半径还是小半径?这些车辆的行为都很难让人去评估,更别说是算法了。归根结底,驾驶是一个开放行为,我们要如何去评价开放行为的优劣呢?这里要打个问号。
现有的仿真环境无法还原真实世界。感知进行仿真的时候,数据都是直接从车上采集的视频。然而如果我们使用这些数据对端到端进行评测,我们发现即使我们的算法设计出了不一样的路线,视频中自车也还是按照原来的方向去走,这对于仿真而言是非常致命的。
常见的端到端应用
一段式端到端算法
一段式端到端算法,一般将环境信息整合为一个BEV特征(Bird Eye's View),然后通过对这个特征进行解码,得到我们所需要的控制信号。因为如前文所述,控制信号信息量太少,和特征之间的映射太松散,因此我们希望模型能够多学一点东西,这样模型的能力能够增强,并且多输出的信息也能够作为兜底。
所以现在的一段式端到端模型,除了输出控制信号的解码器之外,还会接一些输出感知信息、道路信息等的解码器,一个模型,通过不同的head能够实现不同的功能,这个就是目前很火的one model。
两段式
不同于一段式,两段式的人工干预风味过于明显。受益于transformer架构,信息传递通过query来传递,这样在人工干预的情况下,也能保持一些信息的无损传递。当然笔者个人认为,因为人工设计的意味相对一段式更多一些,可能现阶段两段式会表现更好,但是长远来看上限并不高
世界模型
世界模型(World Model)被认为是端到端自动驾驶训练、评测、仿真等的救命绳索。简而言之,世界模型能够根据输入信号、以及自车的运动行为,自动生成和现实世界很像的视频。通俗点讲,世界模型的出现,能够模拟一个真实的世界,这样车辆的驾驶行为就可以被评估了。此外世界模型还可以被用来作为强化训练的playground。笔者不是做aigc方向的,关于世界模型的发展、现状,大概只知道这么多。
以上。
自动驾驶之心
论文辅导来啦

知识星球交流社区
近4000人的交流社区,近300+自动驾驶公司与科研结构加入!涉及30+自动驾驶技术栈学习路线,从0到一带你入门自动驾驶感知(大模型、端到端自动驾驶、世界模型、仿真闭环、3D检测、车道线、BEV感知、Occupancy、多传感器融合、多传感器标定、目标跟踪)、自动驾驶定位建图(SLAM、高精地图、局部在线地图)、自动驾驶规划控制/轨迹预测等领域技术方案、大模型,更有行业动态和岗位发布!欢迎加入。

独家专业课程
端到端自动驾驶、大模型、VLA、仿真测试、自动驾驶C++、BEV感知、BEV模型部署、BEV目标跟踪、毫米波雷达视觉融合、多传感器标定、多传感器融合、多模态3D目标检测、车道线检测、轨迹预测、在线高精地图、世界模型、点云3D目标检测、目标跟踪、Occupancy、CUDA与TensorRT模型部署、大模型与自动驾驶、NeRF、语义分割、自动驾驶仿真、传感器部署、决策规划、轨迹预测等多个方向学习视频
学习官网:www.zdjszx.com


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









