



作者 | 自动驾驶专栏 来源 | 自动驾驶专栏
点击下方卡片,关注“自动驾驶之心”公众号
>>点击进入→自动驾驶之心『轨迹生成』技术交流群
本文只做学术分享,如有侵权,联系删文

论文链接:https://arxiv.org/pdf/2505.09315

摘要

本文介绍了自动驾驶中基于解耦多模态表示的端到端轨迹生成。近年来,扩散模型展示了其在从视觉生成到语言建模的不同领域的潜力。将其能力转移到现代自动驾驶系统也已成为一个有前景的方向。本文提出了TransDiffuser,这是一种基于编码器-解码器的端到端自动驾驶生成轨迹规划模型。其中,模型的输入为前视相机图像、激光雷达与当前车辆的运动信息,这些多模态信息作为去噪解码器的多模态条件输入。为了进一步缓解在生成候选轨迹时模式崩溃困境,本文在训练过程中引入了一种简单而有效的多模态表示去相关优化机制,提高模型对于多模态表示信息的进一步利用。
实验结果表明,TransDiffuser在NAVSIM数据集上实现了94.85的PDMS,并且不需要任何基于锚的先验轨迹。TransDiffuser和团队今年3月提出的TrajHF技术方案位于HuggingFace NAVSIM Leaderboard的前两名,进一步体现了理想汽车在自动驾驶技术上的实力。

主要贡献

本文的贡献总结如下:
1)本文提出了一种编码器-解码器生成轨迹模型TransDiffuser。它首先编码场景感知和自车的运动,然后利用编码信息作为去噪解码器的条件输入来解码多模态多样化的可行轨迹;
2)为了进一步提高生成轨迹的多样性,本文在训练过程中引入了一种计算高效的多模态表示去相关机制;
3)本文模型在NAVSIM基准上实现了最新的PDM得分94.85,而没有任何显式的引导,例如基于锚的轨迹或者预定义的词表。

相关工作

现有方法可以基本分为自回归(AR)、评分(Scoring)与扩散生成(Diffusion)三类。以UniAD、Transfuser为代表,传统基于自回归的模型往往只预测一条规划轨迹。以VADv2、英伟达Hydra-MDP系列为代表,基于Scoring的方案往往先采样或者选出多条候选轨迹,然后结合不同的指标或者策略,从中选出一条最优轨迹。以DiffusionDrive、GoalFlow为代表,基于扩散生成的方案,往往将环境信息与自车状态进行编码,利用基于扩散策略的生成式模型来生成多个模式的候选轨迹,最后选取其中最优的轨迹。

技术方案

冻结的Transfuser模块对当前自车的图像与激光雷达采集的点云进行特征融合与编码,同时对自车的运动信息通过简单的MLP架构进行编码。所编码的多模态信息会通过去噪解码器(Denoising Decoder)完成多模态特征进一步融合,解码最终轨迹。
对于解码器模块,Transfuser模块用于编码图像与激光雷达采集的点云信息,同时通过较为简单的MLP来编码自车的运动状态。在训练部分,使用去噪扩散概率模型作为优化框架,主要训练Denoising Decoder部分,通过特定方程实现状态的逐步去噪。需要注意的是,所提出的方案并不依赖轨迹词表或者锚点信息作为先验。
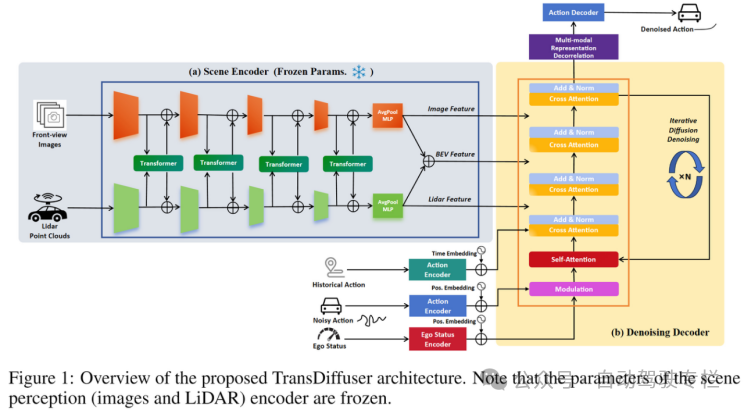
图1 | 所提出的TransDiffuser架构
相比于先前的工作,本项工作强调生成规划轨迹这一任务中潜在的模式坍塌(Mode collapse)挑战。这项挑战最初在DiffusionDrive这篇工作中被提出,具体是指生成式轨迹模型给出的多条候选轨迹的多样性受限,容易收敛到相似轨迹路线。
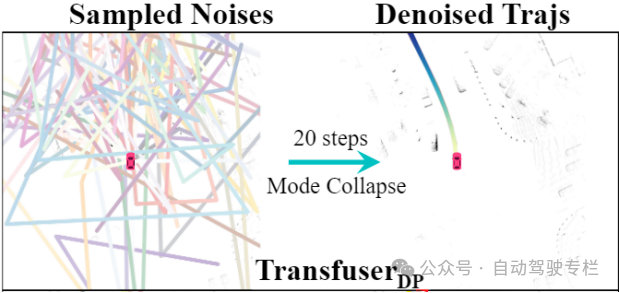
为了缓解这一问题,训练时通过约束多模态表示矩阵的相关矩阵的非对角相关系数趋近于零,降低不同模态维度间的冗余信息,从而拓展潜在表征空间的利用率。该机制在训练阶段作为附加优化目标,由权重因子平衡主要损失。具体而言,这里的多模态表示作为最终动作解码器的输入,通过提高此处的信息量,鼓励动作解码器生成更具多样性的轨迹,提高在连续动作空间中采样可行动作的效果。在图2的子图(d)中,团队对表示矩阵的奇异值谱进行可视化,可以看出优化后的多模态表示空间得到了进一步的利用。

图2 | 多模态表示去相关过程图示

实验结果

实验使用用于闭环评估的非反应式NAVSIM数据集,评价指标包含预测驾驶员模型分数(PDMS)。
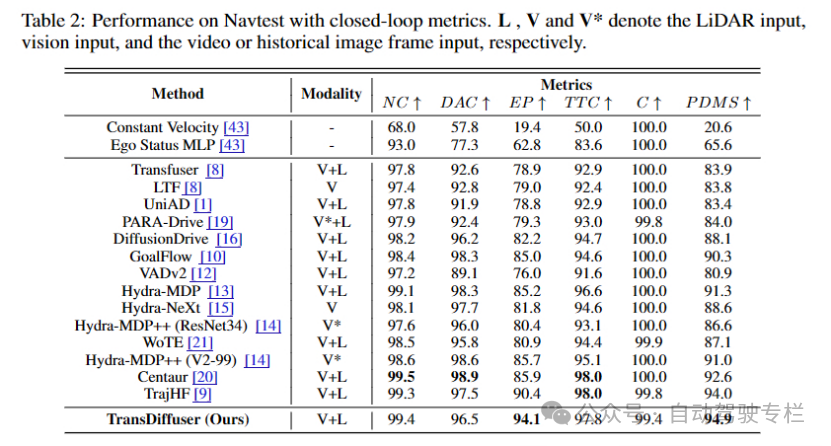
表格2 | 通过闭环指标评估在Navtest上的性能
另外,团队参考DiffusionDrive这项工作提出的多样性指标(Diversity)进行评估,从实验结果也可以体现所提出的优化策略在提高生成多模式候选轨迹的多样性方面的有效性。
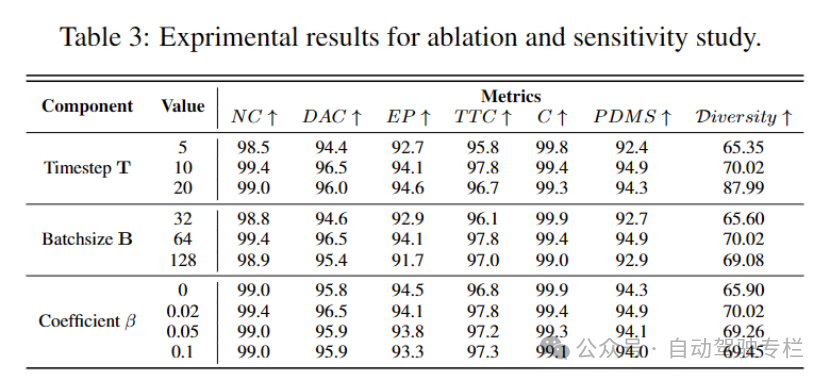
表格3 | 消融和灵敏度研究的实验结果
同时,可视化分析也表明了所提出的方案在尽可能保证安全性的同时,选取较为激进但可行的候选轨迹。
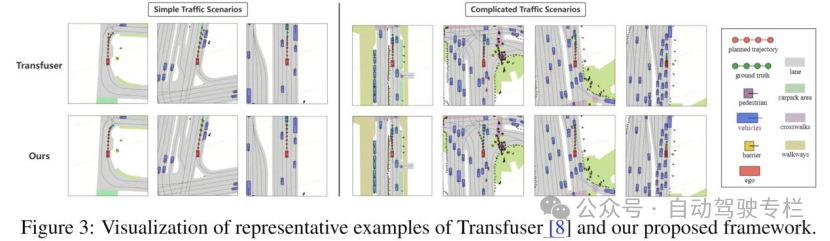
图3 | Transfuser和所提出框架的具有代表性示例的可视化结果

总结与未来工作

本项工作是团队3月的TrajHF模型的延伸工作,进一步体现了生成式端到端轨迹规划模型的性能上限。未来团队会继续聚焦于结合强化学习技术和“视觉-语言-行为”模型架构,以更好地与人类驾驶员指令或者风格对齐来生成多条规划轨迹。
自动驾驶之心
论文辅导来啦

知识星球交流社区
近4000人的交流社区,近300+自动驾驶公司与科研结构加入!涉及30+自动驾驶技术栈学习路线,从0到一带你入门自动驾驶感知(大模型、端到端自动驾驶、世界模型、仿真闭环、3D检测、车道线、BEV感知、Occupancy、多传感器融合、多传感器标定、目标跟踪)、自动驾驶定位建图(SLAM、高精地图、局部在线地图)、自动驾驶规划控制/轨迹预测等领域技术方案、大模型,更有行业动态和岗位发布!欢迎加入。

独家专业课程
端到端自动驾驶、大模型、VLA、仿真测试、自动驾驶C++、BEV感知、BEV模型部署、BEV目标跟踪、毫米波雷达视觉融合、多传感器标定、多传感器融合、多模态3D目标检测、车道线检测、轨迹预测、在线高精地图、世界模型、点云3D目标检测、目标跟踪、Occupancy、CUDA与TensorRT模型部署、大模型与自动驾驶、NeRF、语义分割、自动驾驶仿真、传感器部署、决策规划、轨迹预测等多个方向学习视频
学习官网:www.zdjszx.com


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









