







本文停更,新篇发布于:https://www.jianshu.com/u/90c2509fcc3e
开篇序
真实原因是上一篇字数超上限不给写了,虽然我也确实很想重写新的…
目测上半年剩余时间会以更新运筹优化,数值计算以及随机分析的内容为主,等到下半年可能会重归本业做些有趣的事情。
今日凌晨VAE发布了新曲MV《乌鸦》,感觉VAE的创作风格真的是越来越剑走偏锋,与前三张专辑的风格迥异,但是多听几遍总是可以产生共情的。
所以有时候会想人和人的喜怒真的是不相通么?也许只是难以同乐,单论共悲或许要容易得多。
由于诸多的偏差,往往我们多数时候只能看到别人光鲜面,却发现自己大部分时候都是在平淡地活着,甚至是颓唐地活着,因此一旦觉察倒世上也有与我一样的人,难免就会触而生情。
但是我想到了这个年纪,并没有几个人真的可以做到无忧无虑,各式各样的烦恼总是会有。
人到底血肉之躯,脆弱的时候至刚易折,偶然有烛火照亮我,就会下意识地去追求这团微弱的光芒,渴求还能找到春天。
假若有缘,或许时间并不是问题,谁知道呢。确实是很久了,有时候觉得可能还是像这次决绝一点好罢。
宴尔新昏,如兄如弟。宴尔新昏,不我屑矣。品荼苦而故作乐,大约是会有一点这种感觉的罢。
May 2021
05-08
- 午休起来看到W已在801,克制,虽然看到了还是觉得有点遗憾,
定义【可达常数】:若存在常数 m m m,使得 ∀ n ≥ m \forall n\ge m ∀n≥m,图 G G G中任意两个顶点之间都存在一条长度为 n n n的路径,则称 m m m为可达常数。(简单也可以理解为 C n 2 C_n^2 Cn2对顶点之间最短距离的最大值,其实这个定义不是很严谨);
昨晚测试了一下随机生成的强连通图 G = ( V , E ) G=(V,E) G=(V,E),其中 ∣ E ∣ = 2 ∣ V ∣ |E|=2|V| ∣E∣=2∣V∣的一个可达常数(reachability constant)的情况,从 ∣ V ∣ = 2 4 |V|=2^4 ∣V∣=24测试到 ∣ V ∣ = 2 16 |V|=2^{16} ∣V∣=216,发现可达常数刚好是 4 4 4~ 16 16 16,也就是 log 2 ∣ V ∣ \log_2 |V| log2∣V∣的水平,这个确实是一件很巧的事情。
具体的随机生成方法就是每个顶点都有两个出度,然后确保每个顶点都有入度即可。
上面的测试结论虽然还是比较容易接受的(因为如果做BFS可以近似的认为遍历的顶点数会呈 2 n 2^n 2n的速度增长,因此至少这个量级还是比较容易被接受的),但是严格证明起来并不是很容易。
不过我们也不会太关注证明,类推地,可以想到如果每个顶点有 k k k个出度,那么可达常数可以用 log k ∣ V ∣ \log_k|V| logk∣V∣来估计。
一个现实的案例即为六度空间,即世界上任意两个人通过六个人即可联系到,以目前 70 70 70亿人口来计算的话,这大约是假设每个人的出度(即人脉数)为 6 7 × 1 0 9 ≈ 43 ^6\sqrt{7\times 10^9}\approx 43 67×109≈43,还算是合理罢。
05-09
- 真的狼灭啊,三点不睡发邮件,当日还得早起有事。话说这反射弧也太长了,不回也没啥其实,好在这样事件算是正式画上句号,明天最后一课我也不会太尴尬了,如释重负。
- 31℃,4km,17’03",这么好的状态也破不了16’56"的pb,接下来要刷新pb越来越难,下周二周四比较凉快,争取再试一次。
- 被迫参加月底研学代会,其实现在我倒是不太抗拒这些无聊的琐事,就算是我本科四年欠下的经历给补上罢。
机器学习×数值分析,就决定做这个方向了,lh想做迭代算法做那我就一个人搞这个,还是有点意思的,至少我现在看了这么多ACL EMNLP的顶会paper从来没有人用过这些最传统的统计方法,以及对优化算法的底层进行改进,现在想想确实如此,有那么多ill-conditioned的问题,凭什么你会觉得在你找到的训练集上模型的损失函数真的可以被优化算法(如SGD,ADAM)优化得很好。
现在的问题是在DL年代,我们并不关心训练数据长什么样子,反正一股脑儿输进去就完事了,但是我觉得至少输入数据的条件数还是非常有参考意义的(即输入矩阵的最大奇异值除以最小奇异值),尤其是在NLP领域,很多外部知识(如词袋模型,tfidf矩阵,乃至知识图谱?)都是可以转换为矩阵形式输入到模型中去的。只是这里面有个trick,就是现在的输入数据越来越复杂,可能大多数时候已经不是矩阵,而是至少三维的张量,这个条件数以及预条件子矩阵怎么从二维推广到三维确实是个问题,另一个问题是输入的广度也是复杂的,可能有时候需要综合多个不同类型的输入(比如还有其他特征)。我想对于前者可能切片处理,这也许是一个解决方案,给每个切片找个预条件子矩阵,现在不是确实也有人在研究用CNN自动生成预条件子矩阵的事情嘛。对于后者的话,我倾向于建立子模型来处理,我还是挺反对把所有能用的东西全部输入到模型训练,应当将不同的输入分别训练,这可能需要设计更加合理的结构,还得实践才能知道该怎么做。
总之我越来越觉得邓琪的研究方向很有趣,这学期虽然这门课没有怎么听(因为太难听不懂,而且不考试),但是确实是非常有帮助的知识,对我之后的进展大概率会有思路上的开拓,总之人还是不能太局限于代码上的能力,理论知识,无论紧密与否,选择走这条路就得博采众长,包括计量那边的一些研究方法,也是很值得借鉴的,现在毕业真TM难,我可不想被延毕。
05-10
- 《散去的时候》我听到了,一个人比较好,尽力在躲避,行吧,还是这样的歌词比较适合你的风格。
- 再见很早就已经说过,多说还是太过于矫揉造作。最后一课,我是有想说点什么作为告别,毕竟那晚回来后就再也没有见过了,再次看到时总还是会有点在意,实话说我还真是容易被这种假小子的装扮给惊艳到…
- 好在以后不太可能再见了,无声的告别也许确实更好,让一切都淡去吧。总之还是多谢了,各种意义上,前路安好。
- 我发誓这是最后一个颓废的晚上了,以后绝对要足够自律起来了,再不自律真的凉了。
GPR的scipy实现:其实我之前就很奇怪,这种根据一条样本曲线去拟合整个样本空间分布的做法实在是很胃疼,虽然看起来是很有道理,但是有道理的事情一般都不太行得通。
from scipy.optimize import minimize
import numpy as np
from matplotlib import pyplot as plt
class GPR:
def __init__(self, optimize=True):
self.is_fit = False
self.train_X, self.train_y = None, None
self.params = {"l": 0.5, "sigma_f": 0.2}
self.optimize = optimize
def fit(self, X, y):
# store train data
self.train_X = np.asarray(X)
self.train_y = np.asarray(y)
self.is_fit = True
def predict(self, X):
if not self.is_fit:
print("GPR Model not fit yet.")
return
X = np.asarray(X)
Kff = self.kernel(self.train_X, self.train_X) # (N, N)
Kyy = self.kernel(X, X) # (k, k)
Kfy = self.kernel(self.train_X, X) # (N, k)
Kff_inv = np.linalg.inv(Kff + 1e-8 * np.eye(len(self.train_X))) # (N, N)
mu = Kfy.T.dot(Kff_inv).dot(self.train_y)
cov = Kyy - Kfy.T.dot(Kff_inv).dot(Kfy)
return mu, cov
def kernel(self, x1, x2):
dist_matrix = np.sum(x1**2, 1).reshape(-1, 1) + np.sum(x2**2, 1) - 2 * np.dot(x1, x2.T)
return self.params["sigma_f"] ** 2 * np.exp(-0.5 / self.params["l"] ** 2 * dist_matrix)
def y(x, noise_sigma=0.0):
x = np.asarray(x)
y = np.cos(x) + np.random.normal(0, noise_sigma, size=x.shape)
return y.tolist()
train_X = np.array([3, 1, 4, 5, 9]).reshape(-1, 1)
train_y = y(train_X, noise_sigma=1e-4)
test_X = np.arange(0, 10, 0.1).reshape(-1, 1)
gpr = GPR()
gpr.fit(train_X, train_y)
mu, cov = gpr.predict(test_X)
test_y = mu.ravel()
uncertainty = 1.96 * np.sqrt(np.diag(cov))
plt.figure()
plt.title("l=%.2f sigma_f=%.2f" % (gpr.params["l"], gpr.params["sigma_f"]))
plt.fill_between(test_X.ravel(), test_y + uncertainty, test_y - uncertainty, alpha=0.1)
plt.plot(test_X, test_y, label="predict")
plt.scatter(train_X, train_y, label="train", c="red", marker="x")
plt.legend()
plt.show()
05-11
- 还可以,计量终于不会布置作业了,剩下的作业应该就只有随机模型和运筹优化两门课的了。不过一下子就已经跳到考试月,来得还挺突然,只剩四周时间,有两门期末项目要赶,没能抱到lth的大腿,要自己动手,那就跟我来分个高下呗。
- 冒雨冲了五圈,均配3’55",很久没有这样在大雨中狂奔,难得畅快。
- 童安格的干燥花,和折翼蝶还挺搭。本打算晚上下课去一趟511的,可惜gjj拖太久,而且似乎也没什么理由去,作罢。
更新预告:我越来越觉得这块内容很有用了。
-
参考文献 [ 19 ] [19] [19]:对四维卷积核张量的分解研究。如张量秩分解(CPD),可以将四维卷积核直接分解为四个低秩的卷积层。
- 备注:CPD这个词我第一次是在RE2RNN那篇paper里碰到的,在那篇博客里有关于CPD的详细说明,对于三维张量的CPD应该是会分解成三个二维矩阵,但是对于四维张量的话,分解得到的矩阵数量可能会非常多。
05-12
- 好天气,手环到手,计划试跑一次半马。
- 刚跑就出太阳,跑完就下山,真就针对我呗。最终4’40"的配跑了12km,测了一下发现心率基本维持在175左右,很离谱,看到别人4分配以内心率都不会超过170,差距还真是有够大。
- still not so easy,果然还是对自己的适应的水平太高估。
介绍一种SVD训练:
-
对于神经网络而言,这相当于是将权重矩阵 W W W分解为两个连续的层: W 1 = U diag ( s ) W_1=U\text{diag}(\sqrt{s}) W1=Udiag(s)与 W 2 = diag ( s ) V ⊤ W_2=\text{diag}(\sqrt{s})V^\top W2=diag(s)V⊤
-
对于卷积层而言,卷积核 K ∈ R n × c × w × h \mathcal{K}\in\R^{n\times c\times w\times h} K∈Rn×c×w×h可以表示为一个四维张量,其中 n , c , w , h n,c,w,h n,c,w,h分别代表过滤器(filters)的数量,输入管道(channels)的数量,过滤器的宽和高,本文只要使用空间级(spatial-wise,参考文献 [ 15 ] [15] [15])或者管道级(channel-wise,参考文献 [ 39 ] [39] [39])分解的方法来对卷积层进行分解(因为前人用下来效果很好):
-
首先将 K \mathcal{K} K重构(reshape)成二维矩阵 K ^ ∈ R n × c w h \hat K\in\R^{n\times cwh} K^∈Rn×cwh;
-
然后 K ^ \hat K K^通过SVD得到 U ∈ R n × r , V ∈ R c w h × r , s ∈ R r U\in\R^{n\times r},V\in\R^{cwh\times r},s\in\R^r U∈Rn×r,V∈Rcwh×r,s∈Rr,其中 U U U和 V V V是正交矩阵, r = min ( n , c w h ) r=\min(n,cwh) r=min(n,cwh);
-
此时原始的卷积测出那个被分解为两个连续的子卷积层: K 1 ∈ R r × c × w × h \mathcal{K}_1\in\R^{r\times c\times w\times h} K1∈Rr×c×w×h(从 diag ( s ) V ⊤ \text{diag}(\sqrt{s})V^\top diag(s)V⊤重构回)与 K 2 ∈ R n × r × 1 × 1 \mathcal{K}_2\in\R^{n\times r\times1\times1} K2∈Rn×r×1×1(从 U diag ( s ) ) U\text{diag}(\sqrt{s})) Udiag(s))重构回);
-
05-13
- 休整,月头12天跑了3次10km以上,感觉这个状态其实还行,不算糟糕。晚上进场恰好看到了那个叫WXY的大佬,跟三圈实在是跟不住,回来刷keep看到他3’46"的配跑了5公里多,离谱。下半年一定要把5km练进20分钟,跟这种顶尖的业余跑者比还是差得挺远。
- 写proposal时突然感觉邓琪做的事情真的好有趣,我担心wyl指导不了我这方面的东西,我有直觉这些方法是比较可能发paper的。
- 回翻了一下近一个月的日记,每天都能写满至少一页纸,想休假在家两三天才能写满一页。事多有事多的紧凑,事少也有事少的清闲,以前回翻自己初高中的日记,那种狂妄自大的气息扑面而来,不知道多年以后我再回翻自己某些时期的日记还会作何感想,人嘛,总得成长。
-
关于bibtex的使用方法:
- 编写.bib文件(如proposal.bib),内容如下:
@article{2020Convolutional, title={Convolutional neural nets for estimating the run time and energy consumption of the sparse matrix-vector product}, author={ Barreda, M. and Dolz, M. F. and Castao, M. A. }, journal={International Journal of High Performance Computing Applications}, number={1}, year={2020}, } - 编写.tex文件(如proposal.tex):
\documentclass{article} \usepackage[utf8]{inputenc} \usepackage[margin=1in]{geometry} \usepackage{cite} \usepackage{graphicx} \usepackage{caption2} \usepackage{subfigure} \begin{document} \begin{center} \LARGE{\textbf{Proposal}}\\ \vspace{1em} \normalsize\textbf{Hao Li, Yang Cao}\\ \end{center} \begin{normalsize} \section{Research Questions and Objectives} \section{Objectives} \section{Significance/Contributions} \section{Research Plan} \nocite{1} %只加入到参考文献列表中,不在文中引用(显示[id]) \nocite{*} %显示所有文献 \bibliography{proposal.bib} \bibliographystyle{plain} \end{normalsize} \end{document} - 接下来就是先用pdflatex编译,然后bibtex编译,再pdflatex编译即可。上述
\bibliographystyle{plain}是默认的plain,可自定义,但比较麻烦。
- 编写.bib文件(如proposal.bib),内容如下:
05-14
- MD,proposal硬是拖到下午才写完,最近真废,恨铁不成钢,周末得把这周欠下的都给补上,时隔近一年终于可以开始好好写代码了。
- 刚发现明月姐7号发了一篇ACL,组里都给点赞了,就我没点… 关了朋友圈信息就总是特别滞后。博二第一篇顶会paper,我也得加把劲才行,争取要硕士阶段能整点东西。
- 麦当劳有这么好吃么… 如果健身锻炼不是为了畅所欲食,那就毫无意义。
- 晚课lth居然把zsj带过来了,虽然是带的口罩,我还是一眼就认出了,没好意思去打招呼,老妈说我贼没礼貌,害。课下雷暴,怕被雷击,三圈走人,预报上周末闷热带雨,实在是让人很颓败的天气,不过下周一倒是很凉快,计划再试一次半马,弥补寒假未能完成20km的遗憾。
最近要开始写代码了,实话说还有点小兴奋。
关于python中的稀疏矩阵:from scipy import sparse
scipy中封装了七种常用的稀疏矩阵存储结构,最常用的还是coo:
import numpy as np
from scipy.sparse import coo_matrix
_row = np.array([0, 3, 1, 0])
_col = np.array([0, 3, 1, 2])
_data = np.array([4, 5, 7, 9])
coo = coo_matrix((_data, (_row, _col)), shape=(4, 4), dtype=np.int)
coo.todense() # 通过todense方法转化成密集矩阵(numpy.matrix)
coo.toarray() # 通过toarray方法转化成密集矩阵(numpy.ndarray)
其他像csc与csr的存储方式也有用,但是我觉得理解起来相对会比较复杂,至少matlab中默认存储稀疏矩阵的方式仍然是coo。
稀疏矩阵的稀疏存储结构可以大大加快科学计算中矩阵乘法运算的速度,如果能够在特定问题环境下找到合适的预条件子,还能够使得很多迭代求解算法的收敛速度大大提升。
目前在做这方面的工作,很有趣,因为以前没做过,我发现人总是对新事物会很好奇的,但是真正坚持走下去的确实很少。不思进取,人之常情,也不必多虑,虽然我现在也不太喜欢和别人再争什么,但是至少也别让过去的自己瞧不起现在的自己,最终活成自己讨厌的样子。
05-15
- 鬼天气,又热又闷,四圈就给报废了。凡事还是得慢慢来,欲速不达,本来三月份已经可以达到4分配坚持3km的水平了,最近自从认识了那个5km跑进18分半的大佬后,开始对自己的配速特别不满,急躁了。
- 其实pytorch也有稀疏训练的方法,似乎并没有什么人注意到过,值得好好学习一下。
E2006数据集转稀疏矩阵方法:
# -*- coding: utf-8 -*-
# @author: caoyang
# @email: caoyang@163.sufe.edu.cn
import numpy as np
import scipy as sp
from scipy.sparse import coo_matrix, csr_matrix, save_npz, load_npz, hstack, vstack
from scipy.sparse.linalg import cg, gmres
def load_dataset(filepath, format_='csr', add_constant=False, export_path_matrix=None, export_path_vector=None):
format_ = format_.lower()
if format_ == 'coo':
print('coo')
coo_rows = []
coo_columns = []
coo_values = []
vector = []
row = -1
with open(filepath, 'r') as f:
while True:
line = f.readline()
if not line:
break
row += 1
blocks = line.split()
vector.append(blocks[0])
for block in blocks[1:]:
column, value = block.split(':')
coo_rows.append(row)
coo_columns.append(int(column) - 1)
coo_values.append(float(value))
vector_array = np.array(vector, dtype=np.float64)
sparse_matrix = coo_matrix((coo_values, (coo_rows, coo_columns)), dtype=np.float64)
elif format_ == 'csr':
print('csr')
csr_index_pointers = [0]
csr_indices = []
csr_values = []
vector = []
with open(filepath, 'r') as f:
while True:
line = f.readline()
if not line:
break
blocks = line.split()
vector.append(blocks[0])
index_pointer = csr_index_pointers[-1] + len(blocks) - 1
csr_index_pointers.append(index_pointer)
for block in blocks[1:]:
column, value = block.split(':')
csr_indices.append(int(column) - 1)
csr_values.append(float(value))
vector_array = np.array(vector, dtype=np.float64)
sparse_matrix = csr_matrix((csr_values, csr_indices, csr_index_pointers), dtype=np.float64)
else:
raise Exception('Unknown keyword augment `format_`: {}'.format(format_))
if add_constant:
sparse_matrix = hstack([np.ones((sparse_matrix.shape[0], 1)), sparse_matrix])
if export_path_matrix is not None:
print(type(sparse_matrix))
save_npz(open(export_path_matrix, 'wb'), sparse_matrix)
if export_path_vector is not None:
np.save(export_path_vector, vector_array)
return sparse_matrix, vector_array
05-16
- 萎靡了四天,天气确实也不太好,但是明天一定无论如何要试一次半马的了。
scipy.sparse.linalg下若干线性系统求解迭代方法的评测(以E2006数据集为例):(API见https://docs.scipy.org/doc/scipy/reference/sparse.linalg.html#module-scipy.sparse.linalg):
| 求解方法 | 运行时间 | 是否需要计算 A ⊤ A A^\top A A⊤A | 测试集误差 ∥ A x − b ∥ 2 \|Ax-b\|_2 ∥Ax−b∥2 |
|---|---|---|---|
spsolve(稀疏系统求解) | O O M \rm OOM OOM | Y e s \rm Yes Yes | N a N \rm NaN NaN |
bicg(
BiConjugate Gradient
\text{BiConjugate Gradient}
BiConjugate Gradient) | 56min \text{56min} 56min | Y e s \rm Yes Yes | 22.247769608108694 22.247769608108694 22.247769608108694 |
cg(共轭梯度法) | 1min9s \text{1min9s} 1min9s | Y e s \rm Yes Yes | 22.498612313964742 22.498612313964742 22.498612313964742 |
gmres(广义最小残差法) | 54s \text{54s} 54s | Y e s \rm Yes Yes | 21.30442357345542 21.30442357345542 21.30442357345542 |
minres(最小残差法) | 44 s 44\rm s 44s | Y e s \rm Yes Yes | 21.526024247327364 21.526024247327364 21.526024247327364 |
gcrotmk(
G
C
R
O
T
(
m
,
k
)
{\rm GCROT}(m,k)
GCROT(m,k)方法) | 1min26s \text{1min26s} 1min26s | Y e s \rm Yes Yes | 29.943797879916882 29.943797879916882 29.943797879916882 |
lsqr(求稀疏最小二乘的函数) | 45.8 s 45.8\rm s 45.8s | N o \rm No No | 26.741176979699944 26.741176979699944 26.741176979699944 |
lsmr(求稀疏最小二乘的迭代方法) | 7.31 s \rm 7.31s 7.31s | N o \rm No No | 21.30442357345681 21.30442357345681 21.30442357345681 |
总结:lsmr永远的神,真就又快又好。
05-17
- 时隔近四个月,我终于完成了年前未能跑完20km的夙愿,配速4’45",用时1小时35分,继续下去有望半马进100分钟。昨晚补糖早睡,今早早起继续补糖,就怕自己中途体力不支,结果16km处还是力竭休息了两三分钟。还有必须吐槽坑爹的天气预报,说好早上小雨,结果八点就来这种太阳,还不如抛硬币来得靠谱。
- 偶然看到又不吃午饭就去图书馆的人,罢了。累,回去睡午觉。
- 下午起来感觉无恙,进场看有没有认识的大佬在跑,准备跟两三圈练练速度,结果打开keep发现sxy在跑,但是并不能找到,也许只是我根本认不出来…
搞了一天稀疏矩阵和稀疏张量的处理,目前几个坑点记录一下:
pytorch更新到1.6.0后开始出现torch.sparse模块,可惜这个模块做得太垃圾了,且不说只有COO格式的存储(不支持CSR格式的存储),导致无法做稀疏张量切片,而且也不能直接用torch.nn.utils.DataLoader去包装(原因很简单,dataloader是可以做批生成的,但是本来这个稀疏矩阵就不能切片,怎么做批生成?),但是我测试下来直接把整个稀疏张量拿进去训练是可行的,但是显然这个代价相比于批训练要大得多。如果放弃稀疏存储而用.to_dense()方法转为普通的张量,显存就直接炸了。scipy中coo稀疏格式和csr稀疏格式的转换的时间代价很小,即便矩阵很大(本质上运行时间只和非零元nnz的数量有关,所以很快),因此无需存下来多个不同格式的稀疏矩阵,一般存csr格式的就行了,这个是最常用的,转成其他格式的也快。- 巨型坑点:
torch中稀疏矩阵乘法问题- 目前这个坑在于不同版本的
torch稀疏矩阵乘法是有不同结论的,笔者目前用的是1.7.0gpu版本,torch已经更新到1.8.0,不知是否有更新,目前的情况似乎是支持稀疏乘稀疏,支持稀疏乘普通,但是不支持普通乘稀疏,这就很tricky了,所以很多时候如果要普通乘稀疏,还得反过来写然后再转置,真的是蠢到不行…
- 目前这个坑在于不同版本的
- 总之要用稀疏矩阵做训练,估计得自己改写底层代码了,建议直接手写DNN
05-18
- keep的路线主任从3月2日做到4月5日,然后驾崩(四月中途零碎了做了十天左右),现在从5月4日一直做到现在,这个时间点还真是够敏感的,显然这并不是什么巧合,很直观的因果关系…
- 双腿严重残废,我早在5月1日刷新10km pb后就做好残废的准备了,没想到这个月还能跑4次10km+的里程,最后完成半马,血赚,只是我那路线主任的位置…
收到CSDN定制的nova7的手机壳,看起来还不错,反正我也从来不会买这玩意儿,都是用烂原装的之后就开始“裸机”。
关于稀疏矩阵求奇异值的问题:
-
问题来源于求解矩阵条件数(最大奇异值/最小奇异值),常规做法源自于
numpy.linalg中的svd与eig方法,这两种方法是精确求解的方法,算法应该是通过求解线性系统得出所有奇异值和特征值,以及对应的奇异向量与特征向量,缺点是慢。 -
注意到
scipy.sparse.linalg中提供了svds和eigs两种方法,都是迭代方法,所以会非常快,这里值得注意的是svds方法的调用(https://docs.scipy.org/doc/scipy/reference/generated/scipy.sparse.linalg.svds.html#scipy.sparse.linalg.svds):- 注意到参数
which,取值为'LM'(求最大奇异值)或'SM'(求最小奇异值); - 另外还有一个
k指找出最大的几个奇异值; - 有兴趣的朋友可以去看看求 k > 1 k>1 k>1的情况下迭代算法是如何运行的,因为 k = 1 k=1 k=1时(即只找到一个)的算法是比较浅显的,我记得找多个其实就是初始化时找若干线性不相关的初始向量去迭代,好像还可能涉及需要QR分解的内容
- 但是我实际想说的是这个迭代算法求最大特征值确实非常快(实测100k维的稀疏矩阵只需要不到1秒钟就能找到最大奇异值,而且相当精准),但是找最小奇异值算法是很难迭代收敛(一小时无法收敛),某次测试花了93分钟后报错:
这意味着矩阵奇异得厉害,最小奇异值非常小,导致条件数很大,即矩阵是ill-conditionedArpackNoConvergence: ARPACK error -1: No convergence (33081 iterations, 0/1 eigenvectors converged)
- 这里想做的事情是去找预条件子矩阵 M − 1 M^{-1} M−1来修复 A A A,使得 M − 1 A M^{-1}A M−1A的条件数变小,要求是 M M M也是一个稀疏矩阵,其实如果盲目地去寻找是非常困难的,所以可能还是偏向于物理降维… 不过还是得试试的,万一运气好找到一个预条件子那不血赚。
- 注意到参数
05-19
- wyl又找了好活,这次的明显靠谱得多,还是跟科大讯飞合作的,大约是问答这块的东西。虽然最近忙得离谱,但是我还是跟wyl说了一句“多少事我都能做”。怎么说呢,多点事儿好,省得我瞎TM乱想别的东西,五月以来一直没有好好做事,该给我点颜色看看了。
- 吃苦耐劳能致富,emmm…
- 昨晚熬夜搞掉gjj的作业,下午复习完算法,准备开始正事。饭后冒中雨干了3km,很明显感觉跑姿越来越自然,很畅快地跑,有迫切去参加一次半马的渴望。
今日痛点:LaTeX参考文献.bib文件编译失败的一个原因
有些期刊名称里包含特殊字符,比如&,关键是好多paper提供的BibTex里都不注意这些小问题,然后编译的时候就会出问题。比如下面这个:
\bibitem{2009A}
T.~Strohmer and R.~Vershynin.
\newblock A randomized kaczmarz algorithm with exponential convergence.
\newblock {\em Journal of Fourier Analysis & Applications}, 15(2):262, 2009.
解决方案要么加反斜杠\&,要么直接把&换成and拉倒。
还有一个问题,就是你按照pdflatex
→
\rightarrow
→bibtex
→
\rightarrow
→pdflatex的顺序编译后如果发现引用部分(\cite{...})显示出来的还是[?],那就紧接着再用pdflatex编译一次,实话说这玩意儿很玄学,有时候三步走能好,有时候就得四步。这年头LaTeX还是硬技能,只是这玩意儿老是犯病,有时候还就很难找到问题在哪。
05-20
- 520果然还是图书馆更适合单身狗。这年头还有人热心地在食堂门口放一束应急玫瑰,唉,需要的人不缺,不需要的人有了也没用…
- 今年11月21日,杨浦新江湾国际半程马拉松,目标首马破100分钟。
牛顿法小结:
-
本质上就是在该点附近根据一阶导,二阶导来用一个二次函数近似,然后将二次函数的最低点作为下一个迭代点
-
δ x n t = − ∇ 2 f ( x ) − 1 ∇ f ( x ) \delta x_{\rm nt}=-\nabla^2f(x)^{-1}\nabla f(x) δxnt=−∇2f(x)−1∇f(x)
-
推论:
-
x
+
δ
x
n
t
x+\delta x_{\rm nt}
x+δxnt最小化(二次近似速度):
f ^ ( x + v ) = f ( x ) + ∇ f ( x ) ⊤ v + 1 2 v ⊤ ∇ 2 f ( x ) v \hat f(x+v)=f(x)+\nabla f(x)^\top v+\frac12v^\top\nabla^2f(x)v f^(x+v)=f(x)+∇f(x)⊤v+21v⊤∇2f(x)v
-
x
+
δ
x
n
t
x+\delta x_{\rm nt}
x+δxnt最小化(二次近似速度):
05-21
- 520看《情书》,属实雅兴,终于拉黑,解脱…
- 好天气,可惜睡晚了,加上几天不午睡,状态不算很好。膝盖偶尔还是有点刺痛的,还真以为自己练成钢铁膝盖了,休息一两天回口血,事情也比较多暂时。有空也去科技园一趟,这年头汉堡真有这么好吃?
- ITCS来了些玩飞盘的访问学者,准备陪他们耍耍,看起来还挺好玩的,主要是跑步、跳跃与投掷,权当锻炼身体,培养一些额外的兴趣~
关于连续时间马尔科夫链的转移概率矩阵的计算(实例中的技巧):
-
我们知道可以用下面的ODE来解 P ( t ) P(t) P(t)矩阵的表达式:
{ P ˙ ( t ) = d P ( t ) d t = P ( t ) ⋅ Q P ( 0 ) = I (3.1) \left\{\begin{aligned} &\dot P(t)=\frac{\text{d}P(t)}{\text{d}t}=P(t)\cdot Q\\ &P(0)=I \end{aligned}\right.\tag{3.1} ⎩⎨⎧P˙(t)=dtdP(t)=P(t)⋅QP(0)=I(3.1)
具体解为:
P ( t ) = e t Q = ∑ i = 0 + ∞ 1 i ! t i Q i = I + t Q + 1 2 ! t 2 Q 2 + 1 3 ! t 3 Q 3 + . . . (3.2) P(t)=e^{tQ}=\sum_{i=0}^{+\infty}\frac{1}{i!}t^iQ^i=I+tQ+\frac1{2!}t^2Q^2+\frac1{3!}t^3Q^3+...\tag{3.2} P(t)=etQ=i=0∑+∞i!1tiQi=I+tQ+2!1t2Q2+3!1t3Q3+...(3.2)
这个无穷级数很多时候在 Q Q Q没有特殊形式时是很难求解的,不过有一种更简洁的表达:设对称矩阵 Q Q Q具有正交对角化的形式 Q = S D S ⊤ Q=SDS^\top Q=SDS⊤,则有 P ( t ) = S e t D S ⊤ P(t)=Se^{tD}S^\top P(t)=SetDS⊤
e t D e^{tD} etD非常好求(直接对角元求指数即可),因此只要能给出 Q Q Q对角化的形式,即可直接求出结果。
问题在于很多时候我们甚至连 S S S都给不出显示表达,比如下面这个 Q Q Q矩阵:
Q = [ 1 − m 1 1 . . . 1 1 1 − m 1 . . . 1 1 1 1 − m . . . 1 . . . . . . . . . . . . . . . 1 1 1 . . . 1 − m ] m × m (3.3) Q=\left[\begin{matrix}1-m&1&1&...&1\\1&1-m&1&...&1\\1&1&1-m&...&1\\...&...&...&...&...\\1&1&1&...&1-m\end{matrix}\right]_{m\times m}\tag{3.3} Q=⎣⎢⎢⎢⎢⎡1−m11...111−m1...1111−m...1...............111...1−m⎦⎥⎥⎥⎥⎤m×m(3.3)
虽然通过观察容易发现特征值,但是特征向量并不好求。
因此这里需要一些别的技巧。通过观察可以发现 P ( t ) P(t) P(t)一定是对角元取同一个值,非对角元取另一个值所以我们立刻给出ODE的具体表达:
P ( t ) = [ f ′ ( t ) g ′ ( t ) . . . g ′ ( t ) g ′ ( t ) f ′ ( t ) . . . g ′ ( t ) . . . . . . . . . . . . g ′ ( t ) g ′ ( t ) . . . f ′ ( t ) ] = [ f ( t ) g ( t ) . . . g ( t ) g ( t ) f ( t ) . . . g ( t ) . . . . . . . . . . . . g ( t ) g ( t ) . . . f ( t ) ] [ 1 − m 1 . . . 1 1 1 − m . . . 1 . . . . . . . . . . . . 1 1 . . . 1 − m ] = P ( t ) ⋅ Q P(t)=\left[\begin{matrix}f'(t)&g'(t)&...&g'(t)\\g'(t)&f'(t)&...&g'(t)\\...&...&...&...\\g'(t)&g'(t)&...&f'(t)\end{matrix}\right]=\left[\begin{matrix}f(t)&g(t)&...&g(t)\\g(t)&f(t)&...&g(t)\\...&...&...&...\\g(t)&g(t)&...&f(t)\end{matrix}\right]\left[\begin{matrix}1-m&1&...&1\\1&1-m&...&1\\...&...&...&...\\1&1&...&1-m\end{matrix}\right]=P(t)\cdot Q P(t)=⎣⎢⎢⎡f′(t)g′(t)...g′(t)g′(t)f′(t)...g′(t)............g′(t)g′(t)...f′(t)⎦⎥⎥⎤=⎣⎢⎢⎡f(t)g(t)...g(t)g(t)f(t)...g(t)............g(t)g(t)...f(t)⎦⎥⎥⎤⎣⎢⎢⎡1−m1...111−m...1............11...1−m⎦⎥⎥⎤=P(t)⋅Q
即:
{ f ′ ( t ) = ( 1 − m ) f ( t ) + ( m − 1 ) g ( t ) g ′ ( t ) = f ( t ) + ( 1 − m ) g ( t ) + ( m − 2 ) g ( t ) = f ( t ) − g ( t ) (3.6) \left\{\begin{aligned} &f'(t)=(1-m)f(t)+(m-1)g(t)\\ &g'(t)=f(t)+(1-m)g(t)+(m-2)g(t)=f(t)-g(t) \end{aligned}\right.\tag{3.6} {f′(t)=(1−m)f(t)+(m−1)g(t)g′(t)=f(t)+(1−m)g(t)+(m−2)g(t)=f(t)−g(t)(3.6)
这个ODE很好解,结论是:
P i j ( t ) = { 1 m + m − 1 m e − m t ( i = j ) 1 m − 1 m e − m t ( i ≠ j ) (3.11) P_{ij}(t)=\left\{\begin{aligned} &\frac1m+\frac{m-1}me^{-mt}\quad&(i=j)\\ &\frac1m-\frac1me^{-mt}\quad&(i\neq j) \end{aligned}\right.\tag{3.11} Pij(t)=⎩⎪⎨⎪⎧m1+mm−1e−mtm1−m1e−mt(i=j)(i=j)(3.11)
我看别人多是死磕无穷级数,这个方法似乎并没有太多人想到。
05-22
- 好天气,可惜身体还没有完全回满,中长跑到不了一个月前的水平,周一之后都还是2-4公里的量在恢复,四分配不是那么容易练到的,明天倒很凉快,看状态。
- hdm的期末pre致命了,不到两周,还跟组里事情的节点重叠,Eviews还是半吊子水平,接下来半个月怕要拼命了,聒噪得很,到底得先应付掉后天的考试。
- 感觉s每天都在吃麦当劳,建议撤了二教旁边的缤纷谷,直接把店开在那儿,百分百创收[笑]…
最近一些没搞清楚的混淆点(优化理论):
-
牛顿法的下降方向到底是 − f ( x ) / f ′ ( x ) -f(x)/f'(x) −f(x)/f′(x),还是 − ∇ 2 f ( x ) − 1 ∇ f ( x ) -\nabla^2 f(x)^{-1} \nabla f(x) −∇2f(x)−1∇f(x)
-
拟牛顿法的初始海森矩阵究竟是取初始点的海森矩阵,还是用单位矩阵,还是随机取一个正定矩阵就行了?
-
回溯线搜索(backtracking line search)的算法终止条件,到底是 f ( x ( k ) − α ∇ f ( x ( k ) ) ) > f ( x ( k ) ) − c 1 α k ∥ ∇ f ( x ( k ) ) ∥ 2 2 f(x^{(k)}-\alpha \nabla f(x^{(k)}))\gt f(x^{(k)})-c_1\alpha_k\|\nabla f(x^{(k)})\|_2^2 f(x(k)−α∇f(x(k)))>f(x(k))−c1αk∥∇f(x(k))∥22还是 f ( x ( k ) + α k Δ x k ) > f ( x ( k ) ) + α ∇ f ( x ( k ) ) ⊤ Δ x k f(x^{(k)}+\alpha_k\Delta x_k)\gt f(x^{(k)})+\alpha\nabla f(x^{(k)})^{\top} \Delta x_k f(x(k)+αkΔxk)>f(x(k))+α∇f(x(k))⊤Δxk,感觉两种都可以
-
为什么steepest descent method有的说法是在方向上取下降最多的那个步长: t = argmin t f ( x + t Δ x ) t = \text{argmin}_t f(x+t\Delta x) t=argmintf(x+tΔx),还有一种说法则是针对下降方向: Δ x = argmin v : ∥ v ∥ = 1 ∇ f ( x ) ⊤ v \Delta x = \text{argmin}_{v:\|v\|=1}\nabla f(x)^\top v Δx=argminv:∥v∥=1∇f(x)⊤v
注意这里的 ∥ v ∥ \|v\| ∥v∥如果是二模则等价于梯度下降法,但是这里有多种不同模的选择,比如可以选一模,还能选二次模: ∥ x ∥ P = x ⊤ P x \|x\|_P=\sqrt{x^\top Px} ∥x∥P=x⊤Px,其中 P P P是一个正定矩阵,结果就完全不同了。
这里很迷的就是前一个steepest descent method是用来确定步长,后一个steepest descent method其实是用来确定下降方向的。[黑人问号脸]
05-23
- 状态好偏逢连夜雨,难受。晚饭后小雨17’20“跑了10圈,说起来已经很久不跑4km这个距离了。想到甘肃越野21个精英跑者丧生,所以真的别太高估自己的身体素质,人是有极限的。现在我淋雨跑完(虽然现在是很享受雨中跑步的快感)第一件事就是洗澡,就怕闷长得伤寒,在这种持续一天一夜的越野中低温淋湿,真的是会丢了小命的。
- 花了半个下午终于找到了一篇数据源全部accessible的paper,看起来可实现性比较高。离谱的是问sxy给我搞了一批百八十页的英文paper,上午硬着头皮看完了一篇实证的introduction,然后彻底放弃。这也太看得起我了,我本专的paper都没看过这么长的…
SVDtraining的模型与损失函数定义:
-
这是个最平凡的测试demo,因为我遇到一个很头疼的问题,就是torch好像不能给网络层命名(首先像
torch.nn.Linear这些函数的参数里就没有name,然后即便你初始化好之后手动修改,比如self.orthogonal_linear1.name = 'ABC',在输出模型参数时的name也还是它原先的默认名称),所以我只好给变量命名的时候就带上前缀orthogonal_和diag_,然后才好在损失函数里确定正则项对应的张量(是不是很蠢?到底有没有不蠢的办法?) -
这事情确实挺恶心,明明
torch里的张量都是可以命名的,但是好像就不能命名网络层,还是我没找到怎么改名字的方法?
# -*- coding: utf-8- *-
# @author: caoyang
# @email: caoyang@163.sufe.edu.cn
import torch as th
class DotProduct(th.nn.Module):
def __init__(self, in_features, bias=False):
super(DotProduct, self).__init__()
self.bias_flag = bias
self.weight = th.nn.Parameter(th.rand(in_features, ))
if bias:
self.bias = th.nn.Parameter(th.rand(in_features, ))
def forward(self, x):
x = self.weight * x
if self.bias_flag:
x = x + self.bias
return x
class SVDNet(th.nn.Module):
def __init__(self, input_dim, output_dim):
super(SVDNet, self).__init__()
self.orthogonal_linear1 = th.nn.Linear(input_dim, output_dim, bias=False)
self.diag_dotproduct1 = DotProduct(output_dim, bias=False)
self.orthogonal_linear2 = th.nn.Linear(output_dim, output_dim, bias=False)
def forward(self, x):
x = self.orthogonal_linear1(x)
x = self.diag_dotproduct1(x)
x = self.orthogonal_linear2(x)
return x
class SVDLoss(th.nn.Module):
def __init__(self) -> None:
super(MRRLoss, self).__init__()
def forward(self, y_pred, y_true, model, regularizer_weights=[1, 1]) -> th.FloatTensor:
regularizer = 0
for name, param in model.named_parameters():
if name.startswith('orthogonal_'):
regularizer += self.singular_vectors_orthogonality_regularizer(param) * regularizer_weights[0]
if name.startswith('diag_'):
regularizer += self.singular_values_sparsity_inducing_regularizer(param) * regularizer_weights[1]
error = y_pred - y_true
loss = error * error + regularizer
return loss
def singular_vectors_orthogonality_regularizer(self, x):
return th.norm(th.mm(x.t(), x) - th.eye(x.shape[1]), p='fro') / x.shape[1] / x.shape[1]
def singular_values_sparsity_inducing_regularizer(self, x):
# return th.norm(x, 1)
return th.norm(x, 1) / th.norm(x, 2)
然后我还有一个问题,就是我想写一个函数把任意模型重构成SVD形式的模型,但是我发现这必须先定义一个函数,返回值是一个class,这事情还真从来没做过,突然就触及到经验盲区了,直觉上是可行的。
05-24
- 中午莫名其妙又吃不下饭,实话说这个月胃口还没坏过。一直暗示自己要开心些,却不那么容易,只有跑步时才能让大脑进入暂时的空白。
- 下午算法考试写完第一个交掉,其实以我的性格是不会去提前交卷的,一定是严谨地检查到最后一秒。但就是有那么幼稚,就是想在最后的最后在某人面前装一次B。
- 这次写得很顺,四道大题全部想出来,有高中考数学竞赛的那种感觉,其实也是想秀一下lth,让他知道我也宝刀不老,不是看我数分考了60几分就以为我真的是菜了,数竞人的血统是不会这么快衰败的,你是如此,我也不会逊色于你,术业有专攻罢了,四年后鹿死谁手尚未知。
- 考完试一改颓势,状态振奋,顶着烈日跑了五圈,对我来说这是个可以接受的状态。接下来真的真的别让我再遇见你哪怕一次了,逃避虽然可耻,但是对忘记过去来说也许确实是有效的。
昨晚小熬夜把中国统计图鉴和中国金融图鉴(from中国知网)的爬虫给做了,有空水一篇blog,数据暂时得到保障,虽然我大概率还是复现不了全部[菜B]。但愿下午考试别翻车,真是一生之敌了。
# -*- coding: utf-8 -*-
# @author: caoyang
# @email: caoyang@163.sufe.edu.cn
import re
import requests
from bs4 import BeautifulSoup
def download_chinese_statistical_yearbook(ybcode='N2020100004', is_initial=True):
headers = {'User-Agent': 'User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:82.0) Gecko/20100101 Firefox/82.0'}
query_url = 'https://data.cnki.net/Yearbook/PartialGetCatalogResult'
excel_url = 'https://data.cnki.net/{}'.format
caj_url = 'https://data.cnki.net/download/GetCajUrl'
regex = r'<[^>]+>'
compiler = re.compile(regex, re.S)
formdata = {
'ybcode': ybcode,
'entrycode': '',
'page': '1',
'pagerow': '20'
}
response = requests.post(query_url, data=formdata, headers=headers)
html = response.text
soup = BeautifulSoup(html, 'lxml')
span = soup.find('span', class_='s_p_listl')
for link in span.find_all('a'):
page = str(link.string)
print('第{}页..'.format(page))
if not page == '1':
formdata = {
'ybcode': ybcode,
'entrycode': '',
'page': page,
'pagerow': '20'
}
response = requests.post(query_url, data=formdata, headers=headers)
html = response.text
soup = BeautifulSoup(html, 'lxml')
table = soup.find('table')
for tr in table.find_all('tr'):
tds = tr.find_all('td')
assert len(tds) == 3
title = compiler.sub('', str(tds[0])).replace('\n', '').replace('\t', '').replace(' ', '')
page_range = compiler.sub('', str(tds[1])).replace('\n', '').replace('\t', '').replace(' ', '')
for _link in tds[2].find_all('a'):
href = _link.attrs['href']
if href.startswith('/download/excel'): # excel
filecode = href[href.find('=')+1:]
response = requests.get(excel_url(href), headers=headers)
with open('{}.xls'.format(filecode), 'wb') as f:
f.write(response.content)
with open('log.txt', 'a') as f:
f.write('{}\t{}\t{}.xls\n'.format(title, page_range, filecode))
else: # caj
filecode = _link.attrs['fn']
pagerange = _link.attrs['pg']
disk = _link.attrs['disk']
_formdata = {
'filecode': filecode,
'pagerange': pagerange,
'disk': disk,
}
response = requests.post(caj_url, headers=headers, data=_formdata)
resource_url = response.json()['url']
print(resource_url)
input()
response = requests.get(resource_url, headers=headers)
with open('{}.caj'.format(filecode), 'wb') as f:
f.write(response.content)
with open('log.txt', 'a') as f:
f.write('{}\t{}\t{}.xls\n'.format(title, page_range, filecode))
# Find urls of year
if is_initial is True:
url = 'https://data.cnki.net/trade/Yearbook/Single/{}?z=Z016'.format(ybcode)
response = requests.get(url, headers=headers)
html = response.text
soup = BeautifulSoup(html, 'lxml')
div = soup.find('div', class_='s_year clearfix')
links = []
ybcodes = []
for link in div.find_all('a'):
class_ = link.attrs.get('class')
if class_ is not None: # not current
href = link.attrs.get('href')
ybcode = href.split('/')[-1].split('?')[0]
links.append(href)
ybcodes.append(href)
for ybcode in ybcodes:
download_chinese_statistical_yearbook(ybcode=ybcode, is_initial=False)
if __name__ == '__main__':
download_chinese_statistical_yearbook()
05-25
- 组会开始前十分钟wyl问今天要不让我来讲,好在我早有准备。讲得还不错,就像是聊天一样,轻松且享受,如果与别人聊天也能这么简单就好了。
- 晚饭后直接进场五圈,状态挺不错,果然睡好比啥都强,明天下雨凉快,计划再试一次10k+的距离,没什么明确的目标,一切看状态。
- 晚上课上突然发现自己wx也被删了好友,我最近可真的是什么事都没做,结果也这么绝么。不过这下一点儿痕迹都无了,已经所有社交平台都被拉黑,然而可笑的是三教806窗外一瞥就发现20号楼正对着。彼时彼刻,恰如此时此刻,唉,宁可她真的是从未来过,可是为什么还这么容易地能看得到呢,就不该在自己这么多课的一个学期动这种心思,到头来落得一事无成的下场。
最近在看自动解题,认知推理这方面的东西,限于时间并没有给每篇paper做详细的笔注,只做了速读的笔注,推荐下面这篇很有帮助:
论文标题:Differentiable Learning of Logic Rules for Knowledge Base Reasoning
中文标题:基于知识推理的逻辑规则可微学习
下载链接:arxiv@1702.08367
项目地址:GitHub@ProPPR
上面这篇是基于外部知识的推理,下面这篇则是单纯的模板方法解决代数问题,不过也用到了概率模型,方法值得借鉴:
论文标题:Learning to Automatically Solve Algebra Word Problems
中文标题:学习自动求解代数语言问题
下载链接:Citeseer
项目地址:wordsprobs
目前我只看了后面这篇,也是今天汇报掉的,虽然任务相对简单,不过方法很值得借鉴。
05-26
- 七点已经在下雨,进不了场,索性回笼觉,似乎将是要下一天的雨[胃疼]。
- 下午趁雨小了一些进场10圈,可惜越跑下得越大,10圈悻悻而归。
我最近发现一种自动更新爬虫cookie的方法,需要更新cookie的时候直接用selenium去请求一下,再提取driver.get_cookies()即可,返回的值是一个字典的列表,然后只需要取每个字典中的name和value字段,按照'{}={}; '.format(name, value)的格式将它们拼接起来即可。
其实据我所知,cookiejar还有一些别的包或许也可以来存储cookie,不过我记得以前用过不是很好用,最近发现的这个办法可以快速更新cookie,避免爬虫失效。
05-27
- 《致陌生的你》,河图少有的现代歌,旋律好,演唱难度也很低。只是一直以为歌词是一首写挚友的歌曲,今天重新再听,又不是那样,似乎怎么理解都合理,只是我的心境不同罢了。
- 毒热的太阳,起了10km的状态,最终只跑出5km历史最好成绩21’09"。实际上并没有专门测过自己5km,从6km的最好成绩来看,之前的5km pb大约是21’40"上下,这次算是相当高的提升,不过即便是6km也是2个多月之前跑的了,算意料之中。最终目标是5km破20分。
- sxy的麦当劳探店连续剧已经升级成自带下集预告的版本了… 自由自在的吃也是一种不错的生活方式,也不该把自己逼太紧。不过从定位上来看感觉是要吃遍五角场附近所有的连锁店么…
现在关于最速梯度下降就更迷了,下课我问了一次郭加熠,得到的答复和江波截然不同,郭认为最速梯度下降就是在找方向,所谓在方向上找下降最多的步长那是Exact line search,不叫最速梯度下降,然后郭还说江的slide上是把最速梯度下降的标题给写错了,但是我也学了好多遍最速梯度下降了,都没有听说过郭这种说法,网上搜下来也都是与Exact line search一样的定义,但是Boyd的教材上还真是这种跟郭说的一样,到底谁是对的…
计划再CIFAR-10上面做SVD training的测试,过几天给些结果。torch自己给了一个直接下载CIFAR10数据集的接口,不过也可以自己到http://www.cs.toronto.edu/~kriz/cifar.html自取:
import torchvision as tv #里面含有许多数据集
import torch
import torchvision.transforms as transforms #实现图片变换处理的包
from torchvision.transforms import ToPILImage
#使用torchvision加载并预处理CIFAR10数据集
show = ToPILImage() #可以把Tensor转成Image,方便进行可视化
transform = transforms.Compose([transforms.ToTensor(),transforms.Normalize(mean = (0.5,0.5,0.5),std = (0.5,0.5,0.5))])#把数据变为tensor并且归一化range [0, 255] -> [0.0,1.0]
trainset = tv.datasets.CIFAR10(root='data1/',train = True,download=True,transform=transform)
trainloader = torch.utils.data.DataLoader(trainset,batch_size=4,shuffle=True,num_workers=0)
testset = tv.datasets.CIFAR10('data1/',train=False,download=True,transform=transform)
testloader = torch.utils.data.DataLoader(testset,batch_size=4,shuffle=True,num_workers=0)
classes = ('plane','car','bird','cat','deer','dog','frog','horse','ship','truck')
(data,label) = trainset[100]
print(classes[label])#输出ship
show((data+1)/2).resize((100,100))
dataiter = iter(trainloader)
images, labels = dataiter.next()
print(' '.join('%11s'%classes[labels[j]] for j in range(4)))
show(tv.utils.make_grid((images+1)/2)).resize((400,100))#make_grid的作用是将若干幅图像拼成一幅图像
05-28
- 似乎有人总是半夜一两点来这儿,劝你们早点睡觉,年纪大了有你们后悔的。
- wyl并不打算放过我,即便我还有五门专业课要上到16周,外加两个期末项目和三四次专业作业。
- 最近状态非常不错,吃得好睡得好,可惜今天太闷,晚饭后试了两圈就脱力了,等晚课下再去试试。
- 哈哈哈,晚课提前溜去跑步,居然在电梯里遇到方慧和史钞老师,听sc说也要去跑步,于是偷偷跟着去偷拍了几张他做准备活动和跑步的雅照。感觉抄男神似乎也是那种不太会跟女老师聊天的人。不过yysy,钞男神的腿真的是一绝,看了男默女泪…
眼下在实现卷积层的分解,重拾一下卷积层,发现把卷积层转为全连接层还是有点意思的,计划会有一篇不错的博客,预告下一篇博客SVD训练的实现,相信我这会是个很有趣的东西。
事实上在E:\Anaconda3\Lib\site-packages\torchvision\models下面有不少流行模型的开源代码,随着torchvision的升级会不断更新新的研究结果进来,包括老牌的alexnet,resnet,imagenet,以及现在一些新的googlenet等,而且这些代码可以其实直接复制过来就能用,都不需要做什么修改,然后就可以在巨人肩膀上试着去重构模型了。
05-29
- 呆在520半天,反锁大门,感觉可以把520当成自己的工位用了,没人来,门也不锁,一个人一个教室岂不美哉。
- 晚上状态极好,进场看到WXY和两个认识的大爷,热身跟了他们一两圈,本来还是奔着10km去的,可惜第5个1000米起快了,第6个1000米减不下来只得提速冲刺,最后成功把6km的pb突破到26’10",非常不错(这次应该是被WXY注意到了,他肯定很惊讶学校里除了他还有这么能跑的哈哈),尘封两个多月的6km个人最好被刷新了(其实只是很久不跑6km了… 感觉现在认真跑6km有机会跑进26分,可惜好状态不常有唉)。
全连接层转卷积层很简单(FCN即可),反过来呢?
卷积层的分解已经写完了,再凑点内容准备水博客了(假如王英林不来烦我的话)。
# -*- coding: utf-8 -*-
# @author: caoyang
# @email: caoyang@163.sufe.edu.cn
import torch
from torch import nn
# 将给定的二维卷积层转换为线性层
def conv2d_to_linear(conv2d, input_height, input_width):
# 卷积层输出维度的计算公式:$O=\frac{W-K+2P}{S}+1$
def _clac_output_size(_input_size, _kernel_size, _stride_size, _padding_size=0):
_output_size = (_input_size - _kernel_size + _padding_size * 2) / _stride_size + 1
return int(_output_size) # 一般来说,padding的目的是使得
# 将三维索引转成一维索引
def _index3d_to_index1d(_channel, _height, _width, _height_dim, _width_dim):
return _channel * _height_dim * _width_dim + _height * _width_dim + _width
# 将一维索引转回三维索引
def _index1d_to_index3d(_index, _height_dim, _width_dim):
_size = _height_dim * _width_dim
_channel = _index // _size
_height = (_index - _channel * _size) // _width_dim
_width = _index - _channel * _size - _height * _width_dim
return _channel, _height, _width
conv_weight = conv2d.weight # 卷积层的权重矩阵
out_channels, in_channels, kernel_height, kernel_width = conv_weight.shape # 卷积层权重张量的形状:[输出管道数,输入管道数,卷积核高度,卷积核宽度]
stride_height, stride_width = conv2d.stride # 高度与宽度方向上卷积核每次移动的步长
padding_height, padding_width = conv2d.padding # 高度与宽度方向上输入矩阵
output_height = _clac_output_size(input_height, kernel_height, stride_height, padding_height) # 每个管道上的输出高度
output_width = _clac_output_size(input_width, kernel_width, stride_width, padding_width) # 每个管道上的输出宽度
input_dim = in_channels * input_height * input_width # 输入的总维度数(将输入张量拉平为向量)
output_dim = out_channels * output_height * output_width # 输出的总维度数(将输入张量拉平为向量)
linear_weight = torch.zeros((output_dim, input_dim)) # 初始化线性层的权重矩阵全零
for output_index in range(output_dim): # 遍历每一个输出维度(一维索引)
_output_channel, _output_height, _output_width = _index1d_to_index3d(output_index,
output_height,
output_width) # 将对应的一维索引转回成三维索引
# 因为有stride的存在,输出点对应的起始坐标未必和输入点对应的起始坐标一致
start_height = _output_height * stride_height # 对应_output_height的输入高度方向的起始坐标
start_width = _output_width * stride_width # 对应_output_width的输入宽度方向的起始坐标
for _input_height in range(start_height, start_height + kernel_height): # 遍历此时卷积核对应的所有输入高度方向上的坐标
for _input_width in range(start_width, start_width + kernel_width): # 遍历此时卷积核对应的所有输入宽度方向上的坐标
for in_channel in range(in_channels): # 遍历所有的管道
input_index = _index3d_to_index1d(in_channel,
_input_height,
_input_width,
input_height,
input_width) # 找到对应的输出维度上的一维索引
linear_weight[output_index, input_index] = conv_weight[_output_channel,
in_channel,
_input_height - start_height,
_input_width - start_width] # 修正线性层的权重矩阵
return linear_weight
if __name__ == '__main__':
conv2d = nn.Conv2d(in_channels=2, out_channels=3, kernel_size=2, stride=1)
image_height = 5
image_width = 5
linear = conv2d_to_linear(conv2d, image_height, image_width)
print(conv2d.weight)
print(linear)
print(linear.shape)
05-30
- 凌晨熬夜把之前看的一篇paper实现完,水了一篇以SVD的分解形式进行深度神经网络的训练,算是一次热身吧,可能是一个月熬得最晚的一次。人一到很晚就会想些乱七八糟的东西,文章结束写了几行废话,深夜还是适合睡觉。
- 最后两天,能否有机会10km破44分?感觉这个月的水平有显著提升,这两日状态OK,可惜前天弄丢了跑步用的三分裤,有点心疼…
- 傍晚4.05km用时17’14",逼近4km的pb(16’56"),没有尽全力。至此,4~6km全部恢复到巅峰水平,等一个好天气,准备冲新的10km pb。
信用规模是不是就是负债规模???我要疯了。
二维卷积层转全连接层的实现(卷积核–>权重矩阵):
# -*- coding: utf-8 -*-
# @author: caoyang
# @email: caoyang@163.sufe.edu.cn
import torch
from torch import nn
# 将给定的二维卷积层转换为线性层
def conv2d_to_linear(conv2d, input_height, input_width):
# 卷积层输出维度的计算公式:$O=\frac{W-K+2P}{S}+1$
def _clac_output_size(_input_size, _kernel_size, _stride_size, _padding_size=0):
_output_size = (_input_size - _kernel_size + _padding_size * 2) / _stride_size + 1
return int(_output_size) # 一般来说,padding的目的是使得
# 将三维索引转成一维索引
def _index3d_to_index1d(_channel, _height, _width, _height_dim, _width_dim):
return _channel * _height_dim * _width_dim + _height * _width_dim + _width
# 将一维索引转回三维索引
def _index1d_to_index3d(_index, _height_dim, _width_dim):
_size = _height_dim * _width_dim
_channel = _index // _size
_height = (_index - _channel * _size) // _width_dim
_width = _index - _channel * _size - _height * _width_dim
return _channel, _height, _width
conv_weight = conv2d.weight # 卷积层的权重矩阵
out_channels, in_channels, kernel_height, kernel_width = conv_weight.shape # 卷积层权重张量的形状:[输出管道数,输入管道数,卷积核高度,卷积核宽度]
stride_height, stride_width = conv2d.stride # 高度与宽度方向上卷积核每次移动的步长
padding_height, padding_width = conv2d.padding # 高度与宽度方向上输入矩阵
output_height = _clac_output_size(input_height, kernel_height, stride_height, padding_height) # 每个管道上的输出高度
output_width = _clac_output_size(input_width, kernel_width, stride_width, padding_width) # 每个管道上的输出宽度
input_dim = in_channels * input_height * input_width # 输入的总维度数(将输入张量拉平为向量)
output_dim = out_channels * output_height * output_width # 输出的总维度数(将输入张量拉平为向量)
linear_weight = torch.zeros((output_dim, input_dim)) # 初始化线性层的权重矩阵全零
for output_index in range(output_dim): # 遍历每一个输出维度(一维索引)
_output_channel, _output_height, _output_width = _index1d_to_index3d(output_index,
output_height,
output_width) # 将对应的一维索引转回成三维索引
# 因为有stride的存在,输出点对应的起始坐标未必和输入点对应的起始坐标一致
start_height = _output_height * stride_height # 对应_output_height的输入高度方向的起始坐标
start_width = _output_width * stride_width # 对应_output_width的输入宽度方向的起始坐标
for _input_height in range(start_height, start_height + kernel_height): # 遍历此时卷积核对应的所有输入高度方向上的坐标
for _input_width in range(start_width, start_width + kernel_width): # 遍历此时卷积核对应的所有输入宽度方向上的坐标
for in_channel in range(in_channels): # 遍历所有的管道
input_index = _index3d_to_index1d(in_channel,
_input_height,
_input_width,
input_height,
input_width) # 找到对应的输出维度上的一维索引
linear_weight[output_index, input_index] = conv_weight[_output_channel,
in_channel,
_input_height - start_height,
_input_width - start_width] # 修正线性层的权重矩阵
return linear_weight
05-31
- 偶然发现研代会群里有认识的人。
- 午饭后即兴测了一次400米,果然在短跑上还是个fw,75秒都跑不进。
- 晚上lh临时通知我ITCS要玩飞盘,于是取消了今天冲10km pb的计划,我的天,来了四五个清华北大,还有姚班的学生,剩下的都是交大浙大计算机的同好,那个北大飞盘协会的会长听lh说我能跑半马,全程盯着我一个人防,玩了一个多小时,差点没把我的心肺跑炸掉。临走时我看到WXY在跑,似乎已经跑了很久了,于是我顶着爆炸的心肺跟了他五圈,他是4’09"的配速,显然不是他最好的状态(他5km能跑进18分半),我猜可能是在跑20km,五圈后我实在是心肺承受不了了,只得退场,下次看到他一定加个wx,每天跟他练练速度。
带正交正则项与稀疏正则项的交叉熵损失:
# -*- coding: utf-8 -*-
# @author: caoyang
# @email: caoyang@163.sufe.edu.cn
import torch
from torch.nn import functional as F
class CrossEntropyLossSVD(torch.nn.CrossEntropyLoss):
def __init__(self, weight=None, size_average=None, ignore_index=-100, reduce=None, reduction='mean'):
super(CrossEntropyLossSVD, self).__init__(
weight=weight,
size_average=size_average,
ignore_index=ignore_index,
reduce=reduce,
reduction=reduction,
)
def forward(self, input, target, model=None, regularizer_weights=[1, 1], orthogonal_suffix='svd_weight_matrix', sparse_suffix='svd_weight_vector', mode='lh') -> torch.FloatTensor:
cross_entropy_loss = F.cross_entropy(input, target, weight=self.weight, ignore_index=self.ignore_index, reduction=self.reduction)
if model is None:
return cross_entropy_loss
# 正交正则器
def _orthogonality_regularizer(x): # x应当是一个2D张量(矩阵)且高大于宽
return torch.norm(torch.mm(x.t(), x) - torch.eye(x.shape[1]).cuda(), p='fro') / x.shape[1] / x.shape[1]
# 稀疏导出正则器
def _sparsity_inducing_regularizer(x, mode='lh'): # x应当是一个1D张量(向量)
mode = mode.lower()
if mode == 'lh':
return torch.norm(x, 1) / torch.norm(x, 2)
elif model == 'l1':
return torch.norm(x, 1)
raise Exception(f'Unknown mode: {mode}')
regularizer = torch.zeros(1, ).cuda()
for name, parameter in model.named_parameters():
lastname = name.split('.')[-1]
if lastname.startswith(orthogonal_suffix): # 奇异向量矩阵参数:添加正交正则项
regularizer += _orthogonality_regularizer(parameter) * regularizer_weights[0]
elif lastname.startswith(sparse_suffix): # 奇异值向量参数:添加稀疏导出正则项
regularizer += _sparsity_inducing_regularizer(parameter, mode) * regularizer_weights[1]
return cross_entropy_loss + regularizer
June 2021
06-01
- 早起腰酸背痛,都快挺不起来了,上半身锻炼太少… 昨天手环测下来一共跑了11km多,刨去本来就跑了6圈,玩飞盘差不多跑了有9km,有两只脚趾的关节处磨破,很久脚上不受伤了。不过实话对抗性强一点的极限飞盘还是确实很有意思,多接触点人也开心些,玩爽了就只得熬夜写了一晚上作业…
- 有很不好的感觉,我好像又被人拉黑了…
- 晚上试跑了四圈,从躯干疼到大腿到脚尖,全身上下除了脑袋,全部都酸胀得厉害,昨天就不该在那么累得情况下还跟WXY跑五圈,怕真伤到了。
M / M / ∞ M/M/∞ M/M/∞排队系统性质:
-
设 Δ t \Delta t Δt是一个充分小的正数,对于每台服务器(server),若在时刻 t t t观察到该服务器处于繁忙,则定义如下两个事件:
- 事件 A A A:在该条件下,接下来 Δ t \Delta t Δt时间内该服务器仍然保持繁忙状态。
- 事件 B B B:在该条件下,接下来 Δ t \Delta t Δt时间内该服务器服务终止。
则根据指数分布的无记忆性,可得:
Pr ( A ) = Pr ( Z ≥ t + Δ t ∣ Z ≥ t ) = Pr ( Z ≥ Δ t ) = e − μ Δ t ≈ 1 − μ Δ t + o ( Δ t ) Pr ( B ) = Pr ( Z ≤ t + Δ t ∣ Z ≥ t ) = Pr ( Z ≥ Δ t ) = 1 − e − μ Δ t ≈ μ Δ t + o ( Δ t ) (1.1) \Pr(A)=\Pr\left(Z\ge t+\Delta t|Z\ge t\right)=\Pr\left(Z\ge\Delta t\right)=e^{-\mu\Delta t}\approx1-\mu\Delta t+o(\Delta t)\\ \Pr(B)=\Pr\left(Z\le t+\Delta t|Z\ge t\right)=\Pr\left(Z\ge\Delta t\right)=1-e^{-\mu\Delta t}\approx\mu\Delta t+o(\Delta t)\tag{1.1} Pr(A)=Pr(Z≥t+Δt∣Z≥t)=Pr(Z≥Δt)=e−μΔt≈1−μΔt+o(Δt)Pr(B)=Pr(Z≤t+Δt∣Z≥t)=Pr(Z≥Δt)=1−e−μΔt≈μΔt+o(Δt)(1.1)
设 N ( t ) N(t) N(t)是直到时刻 t t t时所有来访客户的总数,根据泊松过程的性质,可得:
Pr ( N ( t + Δ t ) − N ( t ) = 0 ) = 1 − λ Δ t + o ( Δ t ) Pr ( N ( t + Δ t ) − N ( t ) = 1 ) = 1 − e − λ Δ t = λ Δ t + o ( Δ t ) Pr ( N ( t + Δ t ) − N ( t ) ≥ 2 ) = o ( Δ t ) (1.2) \begin{aligned} \Pr(N(t+\Delta t)-N(t)=0)&=1-\lambda\Delta t+o(\Delta t)\\ \Pr(N(t+\Delta t)-N(t)=1)&=1-e^{-\lambda\Delta t}=\lambda\Delta t+o(\Delta t)\\ \Pr(N(t+\Delta t)-N(t)\ge2)&=o(\Delta t) \end{aligned}\tag{1.2} Pr(N(t+Δt)−N(t)=0)Pr(N(t+Δt)−N(t)=1)Pr(N(t+Δt)−N(t)≥2)=1−λΔt+o(Δt)=1−e−λΔt=λΔt+o(Δt)=o(Δt)(1.2)
根据式 ( 1.1 ) (1.1) (1.1)与式 ( 1.2 ) (1.2) (1.2)的结论,可知在 Δ t \Delta t Δt时间内同时有不低于 2 2 2个服务器服务终止或不低于 2 2 2个客户到来的概率都是 o ( Δ t ) o(\Delta t) o(Δt),则有:
Pr ( X ( t + Δ t ) = i + 1 ∣ X ( t ) = i ) = ∑ k = 0 i [ Pr ( Exactly k services are finished , N ( t + Δ t ) − N ( t ) = k + 1 ∣ X ( t = i ) ) ] = Pr ( No service is finished , N ( t + Δ t ) − N ( t ) = 1 ∣ X ( t ) = i ) + o ( Δ t ) = Pr ( No service is finished ∣ X ( t ) = i ) ⋅ Pr ( N ( t + Δ t ) − N ( t ) = 1 ) + o ( Δ t ) = [ Pr ( A ) ] i ⋅ ( λ Δ t + o ( Δ t ) ) + o ( Δ t ) = ( 1 − μ Δ t + o ( Δ t ) ) i ( λ Δ t + o ( Δ t ) ) + o ( Δ t ) = ( 1 − i μ Δ t + o ( Δ t ) ) ( λ Δ t + o ( Δ t ) ) + o ( Δ t ) = λ Δ t + o ( Δ t ) ( i = 0 , 1 , 2 , . . . ) (1.3) \begin{aligned} \Pr\left(X(t+\Delta t)=i+1|X(t)=i\right)&=\sum_{k=0}^i\left[\Pr\left(\text{Exactly }k\text{ services are finished},N(t+\Delta t)-N(t)=k+1|X(t=i)\right)\right]\\ &=\Pr(\text{No service is finished},N(t+\Delta t)-N(t)=1|X(t)=i)+o(\Delta t)\\ &=\Pr(\text{No service is finished}|X(t)=i)\cdot\Pr(N(t+\Delta t)-N(t)=1)+o(\Delta t)\\ &=\left[\Pr(A)\right]^i\cdot(\lambda\Delta t+o(\Delta t))+o(\Delta t)\\ &=(1-\mu\Delta t+o(\Delta t))^i(\lambda\Delta t+o(\Delta t))+o(\Delta t)\\ &=(1-i\mu\Delta t+o(\Delta t))(\lambda\Delta t+o(\Delta t))+o(\Delta t)\\ &=\lambda \Delta t+o(\Delta t)\quad(i=0,1,2,...) \end{aligned}\tag{1.3} Pr(X(t+Δt)=i+1∣X(t)=i)=k=0∑i[Pr(Exactly k services are finished,N(t+Δt)−N(t)=k+1∣X(t=i))]=Pr(No service is finished,N(t+Δt)−N(t)=1∣X(t)=i)+o(Δt)=Pr(No service is finished∣X(t)=i)⋅Pr(N(t+Δt)−N(t)=1)+o(Δt)=[Pr(A)]i⋅(λΔt+o(Δt))+o(Δt)=(1−μΔt+o(Δt))i(λΔt+o(Δt))+o(Δt)=(1−iμΔt+o(Δt))(λΔt+o(Δt))+o(Δt)=λΔt+o(Δt)(i=0,1,2,...)(1.3)Pr ( X ( t + Δ t ) = i − 1 ∣ X ( t ) = i ) = ∑ k = 1 i [ Pr ( Exactly k services are finished , N ( t + Δ t ) − N ( t ) = k − 1 ∣ X ( t = i ) ) ] = Pr ( Exactly 1 service is finished , N ( t + Δ t ) − N ( t ) = 0 ∣ X ( t ) = i ) + o ( Δ t ) = Pr ( Exactly 1 service is finished ∣ X ( t ) = i ) ⋅ Pr ( N ( t + Δ t ) − N ( t ) = 0 ) + o ( Δ t ) = i ⋅ [ Pr ( A ) ] i − 1 ⋅ Pr ( B ) ⋅ ( 1 − λ Δ t + o ( Δ t ) ) + o ( Δ t ) = i ⋅ ( 1 − μ Δ t + o ( Δ t ) ) i − 1 ⋅ ( μ Δ t + o ( Δ t ) ) ⋅ ( 1 − λ Δ t + o ( Δ t ) ) + o ( Δ t ) = i ⋅ ( 1 − ( i − 1 ) μ Δ t + o ( Δ t ) ) ⋅ ( μ Δ t + o ( Δ t ) ) ⋅ ( 1 − λ Δ t + o ( Δ t ) ) + o ( Δ t ) = i μ Δ t + o ( Δ t ) ( i = 1 , 2 , 3 , . . . ) (1.4) \begin{aligned} \Pr\left(X(t+\Delta t)=i-1|X(t)=i\right)&=\sum_{k=1}^i\left[\Pr\left(\text{Exactly }k\text{ services are finished},N(t+\Delta t)-N(t)=k-1|X(t=i)\right)\right]\\ &=\Pr(\text{Exactly 1 service is finished},N(t+\Delta t)-N(t)=0|X(t)=i)+o(\Delta t)\\ &=\Pr(\text{Exactly 1 service is finished}|X(t)=i)\cdot\Pr(N(t+\Delta t)-N(t)=0)+o(\Delta t)\\ &=i\cdot\left[\Pr(A)\right]^{i-1}\cdot\Pr(B)\cdot(1-\lambda\Delta t+o(\Delta t))+o(\Delta t)\\ &=i\cdot(1-\mu\Delta t+o(\Delta t))^{i-1}\cdot(\mu\Delta t+o(\Delta t))\cdot(1-\lambda\Delta t+o(\Delta t))+o(\Delta t)\\ &=i\cdot(1-(i-1)\mu\Delta t+o(\Delta t))\cdot(\mu\Delta t+o(\Delta t))\cdot(1-\lambda\Delta t+o(\Delta t))+o(\Delta t)\\ &=i\mu\Delta t+o(\Delta t)\quad(i=1,2,3,...) \end{aligned}\tag{1.4} Pr(X(t+Δt)=i−1∣X(t)=i)=k=1∑i[Pr(Exactly k services are finished,N(t+Δt)−N(t)=k−1∣X(t=i))]=Pr(Exactly 1 service is finished,N(t+Δt)−N(t)=0∣X(t)=i)+o(Δt)=Pr(Exactly 1 service is finished∣X(t)=i)⋅Pr(N(t+Δt)−N(t)=0)+o(Δt)=i⋅[Pr(A)]i−1⋅Pr(B)⋅(1−λΔt+o(Δt))+o(Δt)=i⋅(1−μΔt+o(Δt))i−1⋅(μΔt+o(Δt))⋅(1−λΔt+o(Δt))+o(Δt)=i⋅(1−(i−1)μΔt+o(Δt))⋅(μΔt+o(Δt))⋅(1−λΔt+o(Δt))+o(Δt)=iμΔt+o(Δt)(i=1,2,3,...)(1.4)
Pr ( X ( t + Δ t ) = i ∣ X ( t ) = i ) = ∑ k = 0 i [ Pr ( Exactly k services are finished , N ( t + Δ t ) − N ( t ) = k ∣ X ( t = i ) ) ] = Pr ( No service is finished , N ( t + Δ t ) − N ( t ) = 0 ∣ X ( t ) = i ) + Pr ( Exactly 1 service is finished , N ( t + Δ t ) − N ( t ) = 1 ∣ X ( t ) = i ) + o ( Δ t ) = Pr ( No service is finished ∣ X ( t ) = i ) ⋅ Pr ( N ( t + Δ t ) − N ( t ) = 0 ) + Pr ( Exactly 1 service is finished ∣ X ( t ) = i ) ⋅ Pr ( N ( t + Δ t ) − N ( t ) = 1 ) + o ( Δ t ) = [ Pr ( A ) ] i ⋅ ( 1 − λ Δ t + o ( Δ t ) ) + i ⋅ [ Pr ( A ) ] i − 1 ⋅ Pr ( B ) ⋅ ( λ Δ t + o ( Δ t ) ) + o ( Δ t ) = ( 1 − μ Δ t + o ( Δ t ) ) i ( 1 − λ Δ t + o ( Δ t ) ) + i ( 1 − μ Δ t + o ( Δ t ) ) i − 1 ( μ Δ t + o ( Δ t ) ) ( λ Δ t + o ( Δ t ) ) + o ( Δ t ) = 1 − i μ Δ t − λ Δ t + o ( Δ t ) = 1 − ( i μ + λ ) Δ t + o ( Δ t ) ( i = 0 , 1 , 2 , . . . ) (1.5) \begin{aligned} \Pr\left(X(t+\Delta t)=i|X(t)=i\right)&=\sum_{k=0}^i\left[\Pr\left(\text{Exactly }k\text{ services are finished},N(t+\Delta t)-N(t)=k|X(t=i)\right)\right]\\ &=\Pr(\text{No service is finished},N(t+\Delta t)-N(t)=0|X(t)=i)\\ &\quad+\Pr(\text{Exactly 1 service is finished},N(t+\Delta t)-N(t)=1|X(t)=i)+o(\Delta t)\\ &=\Pr(\text{No service is finished}|X(t)=i)\cdot\Pr(N(t+\Delta t)-N(t)=0)\\ &\quad+\Pr(\text{Exactly 1 service is finished}|X(t)=i)\cdot\Pr(N(t+\Delta t)-N(t)=1)+o(\Delta t)\\ &=\left[\Pr(A)\right]^i\cdot(1-\lambda\Delta t+o(\Delta t))+i\cdot\left[\Pr(A)\right]^{i-1}\cdot\Pr(B)\cdot(\lambda\Delta t+o(\Delta t))+o(\Delta t)\\ &=(1-\mu\Delta t+o(\Delta t))^i(1-\lambda\Delta t+o(\Delta t))\\ &\quad+i(1-\mu\Delta t+o(\Delta t))^{i-1}(\mu\Delta t+o(\Delta t))(\lambda\Delta t+o(\Delta t))+o(\Delta t)\\ &=1-i\mu\Delta t-\lambda\Delta t+o(\Delta t)\\ &=1-(i\mu+\lambda)\Delta t+o(\Delta t)\quad(i=0,1,2,...) \end{aligned}\tag{1.5} Pr(X(t+Δt)=i∣X(t)=i)=k=0∑i[Pr(Exactly k services are finished,N(t+Δt)−N(t)=k∣X(t=i))]=Pr(No service is finished,N(t+Δt)−N(t)=0∣X(t)=i)+Pr(Exactly 1 service is finished,N(t+Δt)−N(t)=1∣X(t)=i)+o(Δt)=Pr(No service is finished∣X(t)=i)⋅Pr(N(t+Δt)−N(t)=0)+Pr(Exactly 1 service is finished∣X(t)=i)⋅Pr(N(t+Δt)−N(t)=1)+o(Δt)=[Pr(A)]i⋅(1−λΔt+o(Δt))+i⋅[Pr(A)]i−1⋅Pr(B)⋅(λΔt+o(Δt))+o(Δt)=(1−μΔt+o(Δt))i(1−λΔt+o(Δt))+i(1−μΔt+o(Δt))i−1(μΔt+o(Δt))(λΔt+o(Δt))+o(Δt)=1−iμΔt−λΔt+o(Δt)=1−(iμ+λ)Δt+o(Δt)(i=0,1,2,...)(1.5)
知 M / M / ∞ M/M/\infty M/M/∞排队系统对应生灭过程的状态空间为 X = N = { 0 , 1 , 2 , . . . } \mathcal{X}=\N=\{0,1,2,...\} X=N={0,1,2,...}
根据式 ( 1.3 ) ( 1.4 ) ( 1.5 ) (1.3)(1.4)(1.5) (1.3)(1.4)(1.5),状态转移率矩阵 Q = { q i j } Q=\{q_{ij}\} Q={qij}具有如下的显式表达:
q i j = { 0 if j > i + 1 or j < i − 1 λ if j = i + 1 i μ if j = i − 1 − λ − i μ if j = i (1.6) q_{ij}=\left\{\begin{aligned} &0&&\text{if }j>i+1\text{ or }j<i-1\\ &\lambda&&\text{if }j=i+1\\ &i\mu&&\text{if }j=i-1\\ &-\lambda-i\mu&&\text{if }j=i \end{aligned}\right.\tag{1.6} qij=⎩⎪⎪⎪⎪⎨⎪⎪⎪⎪⎧0λiμ−λ−iμif j>i+1 or j<i−1if j=i+1if j=i−1if j=i(1.6)
对应的状态转移率示意图如下所示(省略状态转移到自身的负转移率):
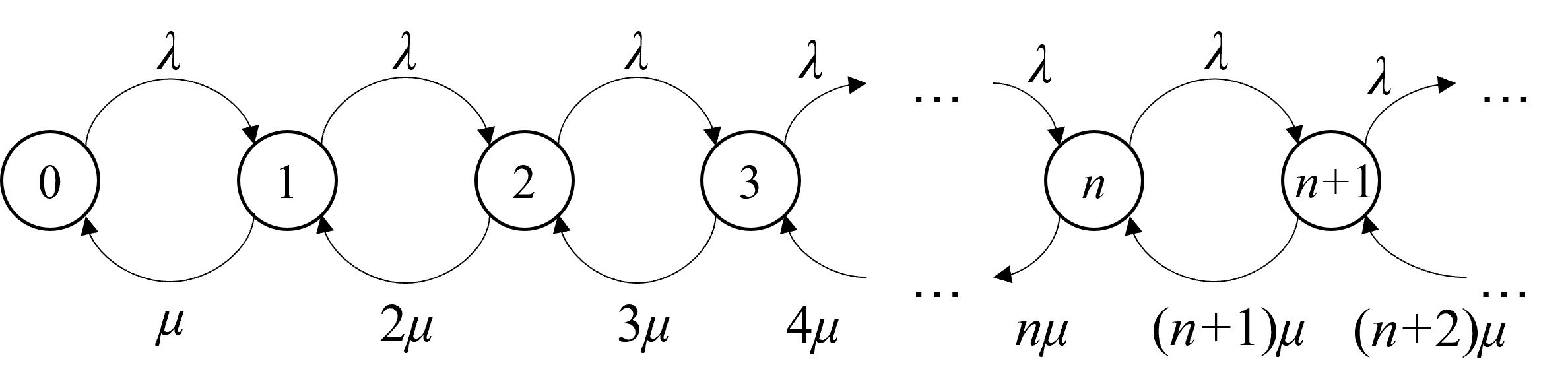
综上所述,式 ( 1.6 ) (1.6) (1.6)与上图即为所求。 ■ \blacksquare ■
-
根据 Slide \text{Slide} Slide中的对应内容,可得一般形式下生灭过程的稳定状态概率(steady state probability)为:
{ π 0 = [ 1 + ∑ n = 1 ∞ ( ∏ k = 0 n − 1 λ k ∏ k = 1 n μ k ) ] − 1 π t = ( ∏ k = 0 t − 1 λ k ∏ k = 1 t μ k ) π 0 ( t = 1 , 2 , . . . ) (1.7) \left\{\begin{aligned} &\pi_0=\left[{1+\sum_{n=1}^\infty\left(\frac{\prod_{k=0}^{n-1}\lambda_k}{\prod_{k=1}^n\mu_k}\right)}\right]^{-1}\\ &\pi_t=\left(\frac{\prod_{k=0}^{t-1}\lambda_k}{\prod_{k=1}^t\mu_k}\right)\pi_0\quad(t=1,2,...) \end{aligned}\right.\tag{1.7} ⎩⎪⎪⎪⎪⎪⎨⎪⎪⎪⎪⎪⎧π0=[1+n=1∑∞(∏k=1nμk∏k=0n−1λk)]−1πt=(∏k=1tμk∏k=0t−1λk)π0(t=1,2,...)(1.7)
其中对应本题的生灭过程,可得具体的 λ i \lambda_i λi与 μ i \mu_i μi的表达式:
{ λ i = λ i = 0 , 1 , 2 , . . . μ i = i μ i = 1 , 2 , 3 , . . . (1.8) \left\{\begin{aligned} &\lambda_i=\lambda&&i=0,1,2,...\\ &\mu_i=i\mu&&i=1,2,3,... \end{aligned}\right.\tag{1.8} {λi=λμi=iμi=0,1,2,...i=1,2,3,...(1.8)
将式 ( 1.8 ) (1.8) (1.8)代入式 ( 1.7 ) (1.7) (1.7)即可得到 M / M / ∞ M/M/\infty M/M/∞排队系统对应生灭过程的稳定状态概率(steady state probability),设 ρ = λ μ \rho=\frac\lambda\mu ρ=μλ:
{ π 0 = [ 1 + ∑ n = 1 ∞ 1 n ! ( λ μ ) n ] − 1 = e − ρ π i = 1 i ! ( λ μ ) i π 0 = 1 i ! ρ i e − ρ i = 1 , 2 , 3 , . . . (1.9) \left\{\begin{aligned} &\pi_0=\left[1+\sum_{n=1}^\infty\frac1{n!}\left(\frac{\lambda}{\mu}\right)^n\right]^{-1}&&=e^{-\rho}&\\ &\pi_i=\frac1{i!}\left(\frac\lambda\mu\right)^i\pi_0&&=\frac1{i!}\rho^ie^{-\rho}&&i=1,2,3,... \end{aligned}\right.\tag{1.9} ⎩⎪⎪⎪⎪⎨⎪⎪⎪⎪⎧π0=[1+n=1∑∞n!1(μλ)n]−1πi=i!1(μλ)iπ0=e−ρ=i!1ρie−ρi=1,2,3,...(1.9)
综上所述,式 ( 1.9 ) (1.9) (1.9)即为所求。 ■ \blacksquare ■ -
效用(utilization)为处于繁忙状态的服务器的期望数量,在 M / M / ∞ M/M/\infty M/M/∞的排队系统中即平均队长(average queue length):
Utilization = ∑ i = 1 ∞ i π i = e − ρ ∑ i = 1 ∞ 1 ( i − 1 ) ! ρ i = ρ e − ρ ∑ t = 0 ∞ 1 t ! ρ t = ρ e − ρ ⋅ e ρ = ρ (1.10) \text{Utilization}=\sum_{i=1}^\infty i\pi_i=e^{-\rho}\sum_{i=1}^\infty \frac1{(i-1)!}\rho^i=\rho e^{-\rho}\sum_{t=0}^\infty \frac1{t!}\rho^{t}=\rho e^{-\rho}\cdot e^\rho=\rho\tag{1.10} Utilization=i=1∑∞iπi=e−ρi=1∑∞(i−1)!1ρi=ρe−ρt=0∑∞t!1ρt=ρe−ρ⋅eρ=ρ(1.10)
吞吐量(throughput)为客户离开排队系统的速率,根据式 ( 1.9 ) (1.9) (1.9),可得:
Throughput = ∑ i = 1 ∞ i μ ⋅ π i = μ ∑ i = 1 ∞ i π i = μ ⋅ Utilization = μ ρ (1.11) \text{Throughput}=\sum_{i=1}^\infty i\mu\cdot\pi_i=\mu\sum_{i=1}^{\infty}i\pi_i=\mu\cdot\text{Utilization}=\mu\rho\tag{1.11} Throughput=i=1∑∞iμ⋅πi=μi=1∑∞iπi=μ⋅Utilization=μρ(1.11)
综上所述,式 ( 1.10 ) (1.10) (1.10)与式 ( 1.11 ) (1.11) (1.11)即为所求。 ■ \blacksquare ■ -
平均队长(average queue length)可以根据式 ( 1.9 ) (1.9) (1.9)计算得出:
E [ X ] = ∑ i = 1 ∞ i π i = e − ρ ∑ i = 1 ∞ 1 ( i − 1 ) ! ρ i = ρ e − ρ ∑ t = 0 ∞ 1 t ! ρ t = ρ e − ρ ⋅ e ρ = ρ (1.12) E[X]=\sum_{i=1}^\infty i\pi_i=e^{-\rho}\sum_{i=1}^\infty \frac1{(i-1)!}\rho^i=\rho e^{-\rho}\sum_{t=0}^\infty \frac1{t!}\rho^{t}=\rho e^{-\rho}\cdot e^\rho=\rho\tag{1.12} E[X]=i=1∑∞iπi=e−ρi=1∑∞(i−1)!1ρi=ρe−ρt=0∑∞t!1ρt=ρe−ρ⋅eρ=ρ(1.12)
平均系统时间(average system time),在 M / M / ∞ M/M/\infty M/M/∞的排队系统中即为每台服务器的平均服务时间:
E [ S ] = 1 μ (1.13) E[S]=\frac1\mu\tag{1.13} E[S]=μ1(1.13)
综上所述,式 ( 1.12 ) (1.12) (1.12)与式 ( 1.13 ) (1.13) (1.13)即为所求。 ■ \blacksquare ■
06-02
- 三天两夜,准备创造一个奇迹(感觉已经被ddl逼上绝路)。今天身体更疼,又要错过一个凉快的天气了,唉。
- 但是晚上还是不甘心浪费这么好的天气,强行起跑,结果5圈就报销。右膝疼,左脚踝也疼,感觉腰还有点扭了,肩膀也不行,整就一废人。五圈之后练了三组400米间歇,基本上还是在1分30左右的水平,状态差就只能跑间歇练速耐了,至于10km,有的是机会去破。权且休整数日罢。
06-03
- 最终我决定靠想象力凑齐数据,要我看500多张excel表一个个找,那是不可能的。
- 研代会还要正装,烦,不想去了都,搞这么复杂。
- 本来晚饭后去热了两圈身,步伐很沉,完全提不起状态。晚课下之后看确实很凉快,觉得浪费这么好的天气也很可惜,轻装上阵,结果35分18秒跑完8.02km,平均配速4’23"!其实我还是本着44分10km去跑的,可惜第8个1000米提速太早,最后200米我感觉心脏都要跳出来了,整个人都要变形了。至此,近半年历史最佳成绩汇总(基本上都是近两个月内):
| 里程 | 平均配速 | 总用时 | 日期 |
|---|---|---|---|
| 1 k m \rm 1km 1km | 3 ′ 3 4 ′ ′ 3'34'' 3′34′′ | 3 ′ 3 4 ′ ′ 3'34'' 3′34′′ | 2021 / 5 / 3 2021/5/3 2021/5/3 |
| 2 k m \rm 2km 2km | 3 ′ 5 4 ′ ′ 3'54'' 3′54′′ | 7 ′ 4 9 ′ ′ 7'49'' 7′49′′ | 2021 / 5 / 7 2021/5/7 2021/5/7 |
| 3 k m \rm 3km 3km | 4 ′ 0 2 ′ ′ 4'02'' 4′02′′ | 1 2 ′ 0 7 ′ ′ 12'07'' 12′07′′ | 2021 / 4 / 18 2021/4/18 2021/4/18 |
| 4 k m \rm 4km 4km | 4 ′ 1 3 ′ ′ 4'13'' 4′13′′ | 1 6 ′ 5 5 ′ ′ 16'55'' 16′55′′ | 2021 / 4 / 22 2021/4/22 2021/4/22 |
| 5 k m \rm 5km 5km | 4 ′ 1 3 ′ ′ 4'13'' 4′13′′ | 2 1 ′ 0 8 ′ ′ 21'08'' 21′08′′ | 2021 / 5 / 27 2021/5/27 2021/5/27 |
| 6 k m \rm 6km 6km | 4 ′ 2 1 ′ ′ 4'21'' 4′21′′ | 2 6 ′ 0 9 ′ ′ 26'09'' 26′09′′ | 2021 / 5 / 29 2021/5/29 2021/5/29 |
| 8 k m \rm 8km 8km | 4 ′ 2 3 ′ ′ 4'23'' 4′23′′ | 3 5 ′ 1 0 ′ ′ 35'10'' 35′10′′ | 2021 / 6 / 3 2021/6/3 2021/6/3 |
| 10 k m \rm 10km 10km | 4 ′ 2 5 ′ ′ 4'25'' 4′25′′ | 4 4 ′ 0 8 ′ ′ 44'08'' 44′08′′ | 2021 / 5 / 1 2021/5/1 2021/5/1 |
| 12 k m \rm 12km 12km | 4 ′ 4 0 ′ ′ 4'40'' 4′40′′ | 5 6 ′ 0 9 ′ ′ 56'09'' 56′09′′ | 2021 / 5 / 12 2021/5/12 2021/5/12 |
| 15 k m \rm 15km 15km | 4 ′ 4 4 ′ ′ 4'44'' 4′44′′ | 7 1 ′ 0 5 ′ ′ 71'05'' 71′05′′ | 2020 / 12 / 31 2020/12/31 2020/12/31 |
| 20 k m \rm 20km 20km | 4 ′ 4 5 ′ ′ 4'45'' 4′45′′ | 9 5 ′ 0 8 ′ ′ 95'08'' 95′08′′ | 2021 / 5 / 17 2021/5/17 2021/5/17 |
06-04
- 我能理解hdm的不满的心情,因为我也是只用了一周不到糊了一篇汇报出来。但是你指望我们这些到了16周还有五门专业课要上,三门专业课还在布置纸面作业,一学期上了六门专业课外带一两门选修的硕博和博士花一两个月乃至一学期时间做一个以后永远用不到的实证分析研究,这太难了。
- 整整五年没有这种被老师训话的经历了,还是当着全班近40个硕博和博士。本来计划晚上讲8组,结果只讲了四组,其中三组全被hdm劝退。能理解hdm也是好心,可惜院里这些老一辈做的研究真的跟不上年轻一辈的节奏了,现在院里的主流还是OR,OM和ML这块。不过跟hdm也算是有些情分,我尽力而为,下周汇报不会让她太尴尬。
- 研路难,且自勉以共进。周末休养生息,吃些好的。研代会可以跟yy见面,等他去阿里总部就没机会了,运气好兴许还能碰到熟人,不过也无碍了。
排队网络(QN)的仿真代码,其实我发现这类随机问题的仿真还挺难,内存耗用特别大,尤其如果你把时间间隔划得非常小(1e-6)左右的水平,16G内存的PC机都很容易卡死。这可能需要在代码上做一些内存占用的优化,比较费脑子,害。其实有一种思想就是时间间隔划大一些,然后做二阶近似(即单位时间间隔内会发生两次转移事件),这样倒也行,就是也有点费脑子。
# -*- coding: utf-8 -*-
# @author: caoyang
# @email: caoyang@163.sufe.edu.cn
import random
import numpy as np
from multiprocessing import Process, Pool, Manager
def simulate_queue_network(r, p, mu, T=100, delta=1e-4):
timestamps = np.linspace(0, T, int(T/delta) + 1)
system_state_series = {
'link_states': [], # 链接上的packet数量记录(dict)
'packet_states': [], # 每个packet的正在位于的link记录
}
nodes = list(range(len(r)))
node_state = [[] for _ in range(len(nodes))] # 记录每个节点的packet到来情况
current_link_state = {} # 当前的链接状态:每个链接上存在的所有packets
current_packet_state = {} # 当前每个packet所处的链接位置:(None表示已经离开系统)
current_packet_time = {} # 当前每个packet已经在系统中停留的时间
num_packets = 0 # packet计数值
for i in range(len(p)): # 初始化current_link_state:每个链接上都没有packet
for j in range(len(p[i])):
if p[i][j] > 0 and i != j:
current_link_state[(i,j)] = []
for timestamp in timestamps:
# 0 期初更新所有时间序列
system_state_series['link_states'].append(current_link_state.copy())
system_state_series['packet_states'].append(current_packet_state.copy())
# 外部输入情况
for i in range(len(nodes)): # 遍历每个节点
if random.random() <= r[i] * delta: # 到来一个packet
packet_id = num_packets # 给packet编号
current_packet_time[packet_id] = 0
node_state[i].append(packet_id) # 将packet记录到node_state中
num_packets += 1 # packet计数值+1
# 遍历每个链接:将链接上的东西传到节点中
for (i, j) in current_link_state.keys():
if random.random() <= mu[i][j] * delta and current_link_state[(i, j)]:
packet_id = current_link_state[(i, j)].pop(0) # 这个要求当前链接上有packet,且触发了转移
node_state[j].append(packet_id) # 将这个packet添加到节点中记录
# 遍历每个节点,将其中所有的packet输送到各个link上,总之期末的时候node中一定不存在任何packet
for i in range(len(nodes)): # 遍历每个节点
for packet_id in node_state[i][:]: # 遍历每个节点上的packet
j = np.random.choice(a=nodes, size=1, p=p[i])[0]
if j == i: # 离开系统
current_packet_state[packet_id] = None # 将该packet的状态置为None
else:
current_packet_state[packet_id] = (i, j) # 更新packet状态
current_link_state[(i, j)].append(packet_id) # 更新link状态
node_state[i].pop(0)
# 更新每个packet的停留时间
for packet_id in current_packet_state:
if current_packet_state[packet_id] is not None:
current_packet_time[packet_id] += 1
print('共计: {}个packet'.format(num_packets))
# 计算packet的平均停留时间
print(delta * np.mean(list(current_packet_time.values())))
# 计算link的效用
link_busy_time = {link: 0 for link in current_link_state}
for packet_state in system_state_series['packet_states']:
for packet_id in packet_state:
if packet_state[packet_id] is not None:
link_busy_time[packet_state[packet_id]] += 1
for link in link_busy_time:
print(link, link_busy_time[link], link_busy_time[link] / len(timestamps))
if __name__ == '__main__':
r = [1, 3, 0, 0, 0] # 各个节点外部输入的速率
p = [
[.0, .5, .0, .5, .0],
[.0, .0, .6, .2, .2],
[.0, .0, .5, .0, .5],
[.0, .0, .0, .5, .5],
[.0, .0, .0, .0, 1.],
] # 节点转移概率矩阵(节点转移到自身的概率为其离开排队网络的速率)
mu = [
[0., 6., 0., 6., 0.],
[0., 0., 6., 6., 6.],
[0., 0., 0., 0., 6.],
[0., 0., 0., 0., 6.],
[0., 0., 0., 0., 0.],
]
simulate_queue_network(r, p, mu, T=100, delta=1e-4)
06-05
- 凌晨肝到近三点秒了所有作业,这是我第几遍自学内点法和整数规划了?后悔不好好听课…
- 大补了一顿甲鱼,外加午睡两小时,满血满蓝复活。可能还是书包太重一路走回学校太疲劳了,晚八点半一回校就马不停蹄地开始按4分配跑圈,5圈过后明显感觉坚持不到3km,休息了一会儿跑了三组90秒的400间歇,总之追求4分配以内必须练间歇跑了,虽然间歇跑真的太吃力了。
我最近遇到一个很棘手的问题,就是从中国统计年鉴以及中国金融年鉴上下载得到的excel表是受保护的,但是其实可以打开,只是不能编辑,在excel中的审阅里点击取消保护是需要输入密码的。但是如果我用xlrd库去读取或者pandas的read_excel去读取都会报错:
xlrd.biffh.XLRDError: Workbook is encrypted
即连读取都做不到,显示工作表被加密,但是其实正常还是可以打开的。
然后我发现这种受保护的工作表依然可以导出成csv(这个其实可以写个按键精灵的脚本去一个个手动导出),这样就可以读取了,但是很蠢,而且费时费力,目前有几种可能的处理方案,一个是使用openpyxl库来读取,这个库似乎要比xlrd更高级一些,另一个方案是from win32com.client import DispatchEx,然后excel = DispatchEx('Excel.Application'),我记得以前批量把word转成pdf的脚本也是用到这个底层库,希望能行得通吧,要不然真的要人工看遍500多张excel表了。
06-06
- 晚上看到sxy,感觉印象和记忆种的很不同了,人总是在变。最后唱国际歌还在低头忙事情,实习真的是太忙了。临走让颜烨认识了一下,便是如此。
- 跟颜烨确实有段时间不见了,他已经入职阿里,明晚就要去杭州了,日薪400想必并不会轻松,祝他好运罢,希望多年后彼此都成家立业后还能亦如此。听他说杉数的同事很多都跳到阿里美团字节。杉数确实不是长久之计,但确然也是个不错的跳板,人生浮沉哪。
- 总的来说我们院还是莫得牌面,代表人数跟数院人文一个规模,我们好歹本科也是大院。颜烨最后只吃到了52票,半数都没过,亏我就只给他投了一票。
昨天的问题解决,用DispatchEx可解,附关于python处理Excel的若干方法:
- 使用
xlrd:data = xlrd.open_workbook() - 使用
openpyxl:data = openpyxl.load_workbook() - 使用
pandas:data = pd.read_excel() - 使用
win32com:
from win32com.client import DispatchEx
excel = DispatchEx('Excel.Application')
demo = excel.Workbooks.Open(os.path.join(target_path, xls_filename))
sheet = demo.WorkSheets(1)
print(sheet.Cells(1,1).Value)
demo.Close(True)
06-07
- 最近关注了钞男神微博,才发现到他原来已经35岁,仍单身。从去年11月份就失恋,到今年5月还是郁郁寡欢,怪不得今年随机模型课上的没有去年金融工程那种激情了。想想同龄的常诚都已经是两个孩子的母亲了。北大数学博士也不得志,猛然意识到自己和史钞有好多共通点,跑步、怀旧、古风、民乐、关键都喜欢钻牛角尖,总感觉自己十年后也会是这幅光景… 害怕。
- 晚饭后4分配跑了5圈,然后开始跟ITCS那边玩飞盘。中途看到WXY来了,于是跟跑了一会儿,只跟了600米,配速3’45",本来自己就已经有点疲乏,完全跟不住。隔了10分钟又跟了他800米,刚好是他的冲刺圈,速度太快。很难想象昨天那么热,他居然用3’57"的配速跑了10km,人和人的体质果然不能一概而论,长距离配速上跟他有将近30秒的差距,争取转博前能练到他这种有氧水平。
磁链解析python脚本:利用aria2解析(不要问我是用来做什么的,我只是好奇而已,关于aria2的配置使用,在我上半年的log里有提到)
from http.client import HTTPConnection
import json
SAVE_PATH = "torrents"
STOP_TIMEOUT = 60
MAX_CONCURRENT = 16
MAX_MAGNETS = 256
ARIA2RPC_ADDR = "127.0.0.1"
ARIA2RPC_PORT = 6800
def exec_rpc(magnet):
"""
使用 rpc,减少线程资源占用,关于这部分的详细信息科参考
https://aria2.github.io/manual/en/html/aria2c.html?highlight=enable%20rpc#aria2.addUri
"""
conn = HTTPConnection(ARIA2RPC_ADDR, ARIA2RPC_PORT)
req = {
"jsonrpc": "2.0",
"id": "magnet",
"method": "aria2.addUri",
"params": [
[magnet],
{
"bt-stop-timeout": str(STOP_TIMEOUT),
"max-concurrent-downloads": str(MAX_CONCURRENT),
"listen-port": "6881",
"dir": SAVE_PATH,
},
],
}
conn.request(
"POST", "/jsonrpc", json.dumps(req), {"Content-Type": "application/json"}
)
res = json.loads(conn.getresponse().read())
if "error" in res:
print("Aria2c replied with an error:", res["error"])
exec_rpc('magnet:?xt=urn:btih:F6F7A767CFC964D24E05A0F50B04559B45021941')
06-08
- good,身体完全没有疼,第二次飞盘就完全适应强度了。昨晚回来之后忙里偷闲水了一篇爬虫,好久不做爬虫了,偶尔搞点老本行也挺好。
- 早上yy突然发消息来提wyy学术论文写作的pre做得稀碎,被老师怼得很惨。与我无瓜,无能为力,另外真的不能再提了,饶了我吧。
- 看得出来每个人期末都不是很好过,想不到经院也要学运筹和随机模型,早上高级计量结课的我一下子就平衡了哈哈。
我醉了,脑子里只有浆糊,肚子里只有酒水,一点墨水也倒不出来了。
06-09
- 昨晚课下,颜烨突然跟我提快要分手了,差不多才两个多月,这已经是他第四任了。本来自己状态很好,计划下课要去冲10km pb,临时应邀去陪颜烨喝酒。赌牌,畅饮,诉心肠,直至飘飘然,二人同饮,无需大醉,点到为止,甚是快哉。颜烨今早七点启程去杭州阿里总部,作为践行,昨晚回来十一点绕校跑了4km(均配4’27"),没有尽兴,还能接着跑,一来醒酒,二来且为友人践行。作业,pre,跟纵欲一场又能算得了什么呢?男人的快乐,约莫这么一回事吧。
- 结果酒精上头,三点多都睡不着,早上八点就起来,强行写作业到下午三点多,整个人都快散架了,太伤。
几何布朗运动(Geometrical Brownish Motion,GBM)仿真代码:
# -*- coding: utf-8 -*-
# @author: caoyang
# @email: caoyang@163.sufe.edu.cn
import time
import numpy as np
from scipy.stats import norm
from multiprocessing import Pool, Manager
from matplotlib import pyplot as plt
# 求解标准正态分布的累计密度函数值
def norm_dist(x, loc=0, scale=1):
return norm.cdf(x, loc=loc, scale=scale)
# 计算几何布朗运动的期望(理论值)
def calc_theoritical_expectation_for_geometrical_brownian_motion(t, mu, sigma, s0):
return s0 * np.exp(mu * t)
# 计算几何布朗运动的方差(理论值)
def calc_theoritical_variance_for_geometrical_brownian_motion(t, mu, sigma, s0):
return s0 * s0 * np.exp(2 * mu * t) * (np.exp(sigma * sigma * t) - 1)
# 计算几何布朗运动的期望(仿真值)
def calc_simulated_expectation_for_geometrical_brownian_motion(sample_paths):
return np.mean(sample_paths, axis=0)
# 计算几何布朗运动的方差(仿真值)
def calc_simulated_variance_for_geometrical_brownian_motion(sample_paths):
std = np.std(sample_paths, axis=0)
return std * std
# 生成一条标准布朗运动的样本路径
def generate_sample_path_for_standard_brownian_motion(T, delta=1e-6, timestamps=None):
if timestamps is None:
timestamps = np.linspace(0, T, int(T / delta) + 1)
current_state = 0
sample_path = []
for timestamp in timestamps:
sample_path.append(current_state)
current_state += np.random.normal(0, np.sqrt(delta))
return np.array(sample_path, dtype=np.float64)
# 根据标准布朗运动生成几何布朗运动
def geometrical_brownian_motion(t, mu, sigma, s0, bm):
return s0 * np.exp((mu - 0.5 * sigma * sigma) * t + sigma * bm)
# 仿真模拟几何布朗运动
def simulate_geometrical_brownian_motion(mu, sigma, r, k, s0, T, sample_capacity, delta=1e-6):
sample_paths = []
timestamps = np.linspace(0, T, int(T / delta) + 1)
for _ in range(sample_capacity):
print(_)
standard_brownian_motion_sample_path = generate_sample_path_for_standard_brownian_motion(T, delta, timestamps)
sample_path = geometrical_brownian_motion(timestamps, mu, sigma, s0, standard_brownian_motion_sample_path)
sample_paths.append(sample_path)
return np.array(sample_paths, dtype=np.float64)
# 仿真模拟几何布朗运动(多进程目标函数)
def f(sample_paths, mu, sigma, r, k, s0, T, delta=1e-6):
timestamps = np.linspace(0, T, int(T / delta) + 1)
standard_brownian_motion_sample_path = generate_sample_path_for_standard_brownian_motion(T, delta, timestamps)
sample_path = geometrical_brownian_motion(timestamps, mu, sigma, s0, standard_brownian_motion_sample_path)
sample_paths.append(sample_path)
if __name__ == '__main__':
mu, sigma, r, k, s0, T, sample_capacity, delta = .12, .12, .005, 105, 100, 1, 5000, 1e-4
use_multiprocess = False
_timestamps = np.linspace(0, T, int(T / delta) + 1)
theoritical_expectation = calc_theoritical_expectation_for_geometrical_brownian_motion(_timestamps, mu, sigma, s0)
theoritical_variance = calc_theoritical_variance_for_geometrical_brownian_motion(_timestamps, mu, sigma, s0)
print(f'Theoritical expectation: {theoritical_expectation.shape}')
print(f'Theoritical variance: {theoritical_variance.shape}')
if use_multiprocess:
manager = Manager()
sample_paths = manager.list()
params = {
'sample_paths' : sample_paths,
'mu' : mu,
'sigma' : sigma,
'r' : r,
'k' : k,
's0' : s0,
'T' : T,
'delta' : delta,
}
start_time = time.time()
pool = Pool(processes=16)
for i in range(sample_capacity):
pool.apply(f, kwds=params)
pool.close()
pool.join()
sample_paths = np.array(sample_paths, dtype=np.float64)
end_time = time.time()
print(f' - Time consumption: {end_time - start_time}')
else:
sample_paths = simulate_geometrical_brownian_motion(mu, sigma, r, k, s0, T, sample_capacity, delta)
simulated_expectation = calc_simulated_expectation_for_geometrical_brownian_motion(sample_paths)
simulated_variance = calc_simulated_variance_for_geometrical_brownian_motion(sample_paths)
print(f'Simulated expectation: {simulated_expectation.shape}')
print(f'Simulated variance: {simulated_variance.shape}')
plt.plot(_timestamps, theoritical_expectation)
plt.plot(_timestamps, simulated_expectation)
plt.title('Expectation')
plt.xlabel('$t$')
plt.ylabel('$E[S(t)]$')
plt.legend(['Theoritical', 'Simulated'])
plt.savefig('expectation.png')
plt.close()
plt.plot(_timestamps, theoritical_variance)
plt.plot(_timestamps, simulated_variance)
plt.title('Variance')
plt.xlabel('$t$')
plt.ylabel('$Var[S(t)]$')
plt.legend(['Theoritical', 'Simulated'])
plt.savefig('variance.png')
plt.close()
print(np.sum(sample_paths[:, -1] > k) / sample_capacity)
06-10
- 昨晚11时金言突然来电说周五要来沪,两年不见了,每次来办签证都还记得找我。可惜我跟朱光耀真的是有五年不见了,这次时间比较紧也不能叫朱光耀从交大赶来,不过可以考虑叫上刘天浩。“金(言)—(曹)阳—(朱)光(耀)”同寝三年,从开始走到结束,只可惜我太拉胯,财大还是不能跟科大交大相提并论。想我们高三(1)班以天招班自居,如今随便提几个人都是直博硕博在读,在北京的第一梯队只会更加恐怖。估摸着有一半人都会读到博士,以后真有聚会怕真是会很没面子…
- 入梅,持续一个月,沉闷至极,很不快,只能在中长距离上的速耐练习,这种天强行10km以上真的会脱水到休克。
- 端午王凯重回杨浦,也是很期待与他会面,一周内与三个最好的挚友约见,对我来说实在是太奢侈了。
关于Black-Scholez模型期权定价的仿真代码:
这里其实有点问题,就是本质上我只能对一条价格曲线做仿真,如果真的先仿真出多个S(t)的样本路径后,计算对应价格曲线的均值,这个仿真量就太大了,但是题目中是说要仿真5000条样本路径,我就不是很能搞得明白。
# -*- coding: utf-8 -*-
# @author: caoyang
# @email: caoyang@163.sufe.edu.cn
import time
import numpy as np
from scipy.stats import norm
from multiprocessing import Pool, Manager
from matplotlib import pyplot as plt
# 生成一条标准布朗运动的样本路径
def generate_sample_path_for_standard_brownian_motion(T, delta=1e-6, timestamps=None):
if timestamps is None:
timestamps = np.linspace(0, T, int(T / delta) + 1)
current_state = 0
sample_path = []
for timestamp in timestamps:
sample_path.append(current_state)
current_state += np.random.normal(0, np.sqrt(delta))
return np.array(sample_path, dtype=np.float64)
# 根据标准布朗运动生成几何布朗运动
def geometrical_brownian_motion(t, sigma, r, s0, bm):
return s0 * np.exp((r - 0.5 * sigma * sigma) * t + sigma * bm)
# 随机生成计算某个瞬时几何布朗运动的状态值(根据当前状态s_t与时刻t)
def generate_final_state_of_gbm(t, sigma, r, s_t, T):
tau = T - t
return s_t * np.exp((r - 0.5 * sigma * sigma) * tau + sigma * np.random.normal(0, np.sqrt(tau)))
# 期权价格的理论值
def theoritical_price(t, s_t, sigma, r, k, T):
tau = T - t
d_1 = (np.log(s_t / k) + (r + sigma * sigma / 2) * tau) / (sigma * np.sqrt(tau))
d_2 = d_1 - sigma * np.sqrt(tau)
return s_t * norm.cdf(d_1) - k * np.exp(-r * tau) * norm.cdf(d_2)
# 期权价格的仿真值
def simulate_price(t, s_t, sigma, r, k, T, n_sample=100):
tau = T - t
ST_minus_K = [max(generate_final_state_of_gbm(t, sigma, r, s_t, T) - k, 0) for _ in range(n_sample)]
return np.exp(-r * tau) * np.mean(ST_minus_K)
# 仿真代码
def simulate_black_scholes(sigma, r, k, s0, T, delta, sample_capacity):
timestamps = np.linspace(0, T, int(T / delta) + 1)
standard_brownian_motion_sample_path = generate_sample_path_for_standard_brownian_motion(T, delta, timestamps)
geometrical_brownian_motion_sample_path = geometrical_brownian_motion(timestamps, sigma, r, s0, standard_brownian_motion_sample_path)
theoritical_price_sample_path = theoritical_price(timestamps, geometrical_brownian_motion_sample_path, sigma, r, k, T)
# simulated_price_paths = []
# for _ in range(sample_capacity):
# print(_)
# standard_brownian_motion_sample_path = generate_sample_path_for_standard_brownian_motion(T, delta, timestamps)
# geometrical_brownian_motion_sample_path = geometrical_brownian_motion(timestamps, sigma, r, s0, standard_brownian_motion_sample_path)
# simulated_price_path = []
# for timestamp, state in zip(timestamps, geometrical_brownian_motion_sample_path):
# simulated_price = simulate_price(timestamp, state, sigma, r, k, T)
# simulated_price_path.append(simulated_price)
# simulated_price_paths.append(simulated_price_path)
# expected_simulated_price_path = np.mean(simulated_price_paths, axis=0)
expected_simulated_price_path = []
for timestamp, state in zip(timestamps, geometrical_brownian_motion_sample_path):
simulated_price = simulate_price(timestamp, state, sigma, r, k, T, sample_capacity)
expected_simulated_price_path.append(simulated_price)
plt.plot(timestamps, expected_simulated_price_path)
plt.plot(timestamps, theoritical_price_sample_path)
plt.xlabel('t')
plt.ylabel('price')
plt.legend(['Simulated', 'Theoritical'])
plt.savefig('price.png')
plt.close()
if __name__ == '__main__':
sigma, r, k, s0, T, sample_capacity, delta = .12, .005, 105, 100, 1, 5000, 1e-4
simulate_black_scholes(sigma, r, k, s0, T, delta, sample_capacity)
06-11
- 金言居然早上七点半点就到了,还好我醒得早。老言子最近小日子过得很滋润,国内国外两头拿津贴,直接月入过万,整个人都发福了,比上次重了10kg,我刚好是瘦了10kg,然而我还是比他重一点哈哈。
- 跟老言子交流就会发现自己真的是弱小得很,他已经有一篇一作,还有一篇挂名,都是SCI一区的paper,与我这种菜B已经不可同日而语了。
- 到了这个年纪,老言子似乎也有点急,看上了小师妹可惜自己要出国,眼看着身边少年班的天才21岁就和女友拍了婚纱照,自己却还是孑然一身远赴他国,前途未卜,受身边环境的影响的了,人之常情,本来“浓厚的学术氛围”,一下子变成了单身狗座谈会,朱光耀跟管思思很早也分了,我们仨还是我们仨,唉。
几何布朗运动的期望方差计算(很离谱,我看到现在只有百度百科里有结论,就没一个人具体讲讲GBM的推导,关于 E [ X 2 ( t ) ] \mathbb{E}[X^2(t)] E[X2(t)]的值使用的是矩母函数的结论):
-
( 2 a ) (\rm 2a) (2a) 即已知 G B M \rm GBM GBM的表达式为:
{ d S ( t ) = μ S ( t ) d t + σ S ( t ) d W ( t ) S ( 0 ) = s 0 ⟹ S ( t ) = s 0 exp { ( μ − 1 2 σ 2 ) t + σ W ( t ) } (2.1) \left\{\begin{aligned} &\text{d}S(t)=\mu S(t)\text{d}t+\sigma S(t)\text{d}W(t)\\ &S(0)=s_0 \end{aligned}\right.\\ \Longrightarrow S(t)=s_0\exp\left\{\left(\mu-\frac12\sigma^2\right)t+\sigma W(t)\right\}\tag{2.1} {dS(t)=μS(t)dt+σS(t)dW(t)S(0)=s0⟹S(t)=s0exp{(μ−21σ2)t+σW(t)}(2.1)
其中 W ( t ) W(t) W(t)是布朗运动, μ \mu μ表示漂移率, σ \sigma σ表示波动率。设 X ( t ) = exp { ( μ − 1 2 σ 2 ) t + σ W ( t ) } X(t)=\exp\left\{\left(\mu-\frac12\sigma^2\right)t+\sigma W(t)\right\} X(t)=exp{(μ−21σ2)t+σW(t)},根据 S l i d e \rm Slide Slide中定理 7.1 7.1 7.1,可知 X ( t ) X(t) X(t)是鞅,则可得:
E [ X ( t ) ] = E [ X ( 0 ) ] = 1 Var [ X ( t ) ] = E [ X 2 ( t ) ] − ( E [ X ( t ) ] ) 2 = e σ 2 t − 1 (2.2) \begin{aligned} &\mathbb{E}[X(t)]=\mathbb{E}[X(0)]=1\\ &\text{Var}[X(t)]=\mathbb{E}\left[X^2(t)\right]-(\mathbb{E}[X(t)])^2=e^{\sigma^2t}-1 \end{aligned}\tag{2.2} E[X(t)]=E[X(0)]=1Var[X(t)]=E[X2(t)]−(E[X(t)])2=eσ2t−1(2.2)
利用 X ( t ) X(t) X(t),可以将 S ( t ) S(t) S(t)改写为:
S ( t ) = s 0 e μ t X ( t ) (2.3) S(t)=s_0e^{\mu t}X(t)\tag{2.3} S(t)=s0eμtX(t)(2.3)
根据式 ( 2.2 ) (2.2) (2.2),可以计算 S ( t ) S(t) S(t)的期望与方差:
E [ S ( t ) ] = E [ s 0 exp { ( μ − 1 2 σ 2 ) t + σ W ( t ) } ] = s 0 e μ t E [ X ( t ) ] = s 0 e μ t Var [ S ( t ) ] = E [ S 2 ( t ) ] − ( E [ S ( t ) ] ) 2 = E [ s 0 2 exp { 2 ( μ − 1 2 σ 2 ) t + 2 σ W ( t ) } ] − s 0 2 e 2 μ t = s 0 2 e 2 μ t E [ X 2 ( t ) ] − s 0 2 e 2 μ t = s 0 2 e 2 μ t ( Var [ X ( t ) ] + ( E [ X ( t ) ] ) 2 − 1 ) = s 0 2 e 2 μ t ( e σ 2 t − 1 ) (2.4) \begin{aligned} \mathbb{E}[S(t)]&=\mathbb{E}\left[s_0\exp\left\{\left(\mu-\frac12\sigma^2\right)t+\sigma W(t)\right\}\right]\\ &=s_0e^{\mu t}\mathbb{E}\left[X(t)\right]\\ &=s_0e^{\mu t}\\ \text{Var}[S(t)]&=\mathbb{E}[S^2(t)]-\left(\mathbb{E}[S(t)]\right)^2\\ &=\mathbb{E}\left[s_0^2\exp\left\{2\left(\mu-\frac12\sigma^2\right)t+2\sigma W(t)\right\}\right]-s_0^2e^{2\mu t}\\ &=s_0^2e^{2\mu t}\mathbb{E}\left[X^2(t)\right]-s_0^2e^{2\mu t}\\ &=s_0^2e^{2\mu t}\left(\text{Var}\left[X(t)\right]+\left(\mathbb{E}[X(t)]\right)^2-1\right)\\ &=s_0^2e^{2\mu t}\left(e^{\sigma^2t}-1\right) \end{aligned}\tag{2.4} E[S(t)]Var[S(t)]=E[s0exp{(μ−21σ2)t+σW(t)}]=s0eμtE[X(t)]=s0eμt=E[S2(t)]−(E[S(t)])2=E[s02exp{2(μ−21σ2)t+2σW(t)}]−s02e2μt=s02e2μtE[X2(t)]−s02e2μt=s02e2μt(Var[X(t)]+(E[X(t)])2−1)=s02e2μt(eσ2t−1)(2.4)
综上所述,式 ( 2.4 ) (2.4) (2.4)即为所求。 ■ \blacksquare ■
06-12
- 现在让我们来看看hdm昨晚到底有多离谱,课前5分钟提示今晚考试,还要把剩下10各组的pre做完。时间显然很紧,于是她给出了70分钟讲10个组,90分钟考试的计划,也就是到8点40能下课。用脚趾头都能想出来怎么可能一个组7分钟,还组里每个人都必须讲。结果大部分组都讲到了双倍时间,直到八点才结束。本以为她放弃考试了,结果强行起考,还问我们谁不想考就举手(被自愿),然后考试形式也是离谱到家——论文精读,我被分到一篇40页的英文paper,只给两个小时看,然后按章节写提纲,最后还要总结论文的创新、优点和不足,花半小时过了一遍,剩下90分钟拼死拼活勉强写完。我就想知道碳基生物能想得出这种活?真就从头离谱到尾呗。
- 本来昨天见金言还没睡午觉又累又困,下课后我一肚子怒气无处泄,4’21"的配速出门随意乱跑,3km多莫名奇妙跑进了大学路,稍微平复了一些,可惜还要被人虐一条街,真的是艹了。
- 时隔半年,CSDN又开始征水文了,恰好可以把昨天跟老言子的事情拿来说说《纸短情长叹朝夕》。
DOS(常用汇总)
cmd命令大全(第一部分)
winver---------检查Windows版本
wmimgmt.msc----打开windows管理体系结构(WMI)
wupdmgr--------windows更新程序
wscript--------windows脚本宿主设置
write----------写字板
winmsd---------系统信息
wiaacmgr-------扫描仪和照相机向导
winchat--------XP自带局域网聊天
2
cmd命令大全(第二部分)
mem.exe--------显示内存使用情况
Msconfig.exe---系统配置实用程序
mplayer2-------简易widnows media player
mspaint--------画图板
mstsc----------远程桌面连接
mplayer2-------媒体播放机
magnify--------放大镜实用程序
mmc------------打开控制台
mobsync--------同步命令
3
cmd命令大全(第三部分)
dxdiag---------检查DirectX信息
drwtsn32------ 系统医生
devmgmt.msc--- 设备管理器
dfrg.msc-------磁盘碎片整理程序
diskmgmt.msc---磁盘管理实用程序
dcomcnfg-------打开系统组件服务
ddeshare-------打开DDE共享设置
dvdplay--------DVD播放器
4
cmd命令大全(第四部分)
net stop messenger-----停止信使服务
net start messenger----开始信使服务
notepad--------打开记事本
nslookup-------网络管理的工具向导
ntbackup-------系统备份和还原
narrator-------屏幕“讲述人”
ntmsmgr.msc----移动存储管理器
ntmsoprq.msc---移动存储管理员操作请求
netstat -an----(TC)命令检查接口
5
cmd命令大全(第五部分)
syncapp--------创建一个公文包
sysedit--------系统配置编辑器
sigverif-------文件签名验证程序
sndrec32-------录音机
shrpubw--------创建共享文件夹
secpol.m转载自电脑十万个为什么http://www.qq880.com,请保留此标记sc-----本地安全策略
syskey---------系统加密,一旦加密就不能解开,保护windows xp系统的双重密码
services.msc---本地服务设置
Sndvol32-------音量控制程序
sfc.exe--------系统文件检查器
sfc /scannow---windows文件保护
6
cmd命令大全(第六部分)
tsshutdn-------60秒倒计时关机命令
tourstart------xp简介(安装完成后出现的漫游xp程序)
taskmgr--------任务管理器
eventvwr-------事件查看器
eudcedit-------造字程序
explorer-------打开资源管理器
packager-------对象包装程序
perfmon.msc----计算机性能监测程序
progman--------程序管理器
regedit.exe----注册表
rsop.msc-------组策略结果集
regedt32-------注册表编辑器
rononce -p ----15秒关机
regsvr32 /u *.dll----停止dll文件运行
regsvr32 /u zipfldr.dll------取消ZIP支持
7
cmd命令大全(第七部分)
cmd.exe--------CMD命令提示符
chkdsk.exe-----Chkdsk磁盘检查
certmgr.msc----证书管理实用程序
calc-----------启动计算器
charmap--------启动字符映射表
cliconfg-------SQL SERVER 客户端网络实用程序
Clipbrd--------剪贴板查看器
conf-----------启动netmeeting
compmgmt.msc---计算机管理
cleanmgr-------垃圾整理
ciadv.msc------索引服务程序
osk------------打开屏幕键盘
odbcad32-------ODBC数据源管理器
oobe/msoobe /a----检查XP是否激活
lusrmgr.msc----本机用户和组
logoff---------注销命令
iexpress-------木马捆绑工具,系统自带
Nslookup-------IP地址侦测器
fsmgmt.msc-----共享文件夹管理器
utilman--------辅助工具管理器
gpedit.msc-----组策略
06-13
- 感冒加重了,隐隐还有点发烧,特别糟糕的情况。山楂树?
- 怎么还能碰得到?而且,时隔一阵子,怎么又取消拉黑我了呢?胃疼,矛盾,无厘头。
- 从5月1日开始没有断过的跑步,被迫要停一天了,状态掉落到冰点,咳嗽带着头也开始疼,感觉学校里有不少人感冒,可能是有流感了。
- 晚上看到那个体育生在光着上身在裸奔,我跟了1km实在是状态太差,感觉自己有快两年没感冒发烧过了,真是倒大霉了。
- 明天王凯来沪,吃个饭正好晚上一起去外滩看个点灯,这么多年我还一次没去看过。
抓取PDF中图片的小脚本:
# -*- coding: UTF-8 -*-
# @author: caoyang
# @email: caoyang@163.sufe.edu.cn
import cv2
import numpy
from PyPDF2 import PdfFileReader, PdfFileWriter
def parse_pdf_images(import_path: str) -> None:
with open(import_path, 'rb') as pdf:
reader = PdfFileReader(pdf)
for number in range(reader.getNumPages()):
page = reader.getPage(number)
print('Page {}:'.format(number))
x_object = page['/Resources'].get('/XObject')
if x_object is None:
continue
for key in x_object:
if x_object[key]['/Subtype'] == '/Image':
size = (x_object[key]['/Width'], x_object[key]['/Height'])
data = x_object[key].getData()
if x_object[key]['/ColorSpace'] == '/DeviceRGB':
mode = 'RGB'
else:
mode = 'P'
image = numpy.frombuffer(data, numpy.uint8)
print(x_object[key]['/Filter'])
if x_object[key]['/Filter'] == '/FlateDecode':
print(size)
print(image.shape)
image = image.reshape(size[1], size[0], 3)
cv2.imwrite('page' + '%05ui' % number + 'key' + key[1:] + '.png', image)
elif x_object[key]['/Filter'] == '/DCTDecode':
cv2.imwrite(key[1:] + '.jpg', image)
elif xObject[obj]['/Filter'] == '/JPXDecode':
cv2.imwrite(key[1:] + '.jpg', image)
06-14
- 想做就去做呗,反正某人现在不也没课没考试了,想谈恋爱又嫌麻烦。现在我觉得所有的胡思乱想都可以归结于太闲(虽然我现在也没资格这么评判别人)。
- 星巴克约了下午茶后,晚上请王凯去悦荟吃了个烤肉(其实就是我自己想吃了,我都好久没出去吃了),顺道去外滩看了个亮灯。颜烨,金言,王凯三人的处事风格相异甚远,但是都已经取得了阶段性的成功(入职阿里,赴美留学,考取复旦),事实上我与他们任何一人的处事风格都不相同,所以我又能走到哪里呢?
- 中午找到了救命的头孢克肟,不然我可能真的是要不行了。一天走了将近两万步,晚归疲累到极致,但还是进场跑了五圈,4’34"的配速,近一年多以来可能是最差的状态了。等感冒痊愈,再从头开始练罢。
gpytorch的一个小demo(原谅我最近啥有意义的事情也没做,周末赶完hdm8000字的paper,今天又出去晃了半天,只能拿以前的存货来顶了)
import os
import math
from matplotlib import pyplot as plt
import torch
import gpytorch
from gpytorch import kernels, means, models, mlls, settings
from gpytorch import distributions as distr
from IPython.display import Markdown, display
def printmd(string):
display(Markdown(string))
train_x = torch.linspace(0, 1, 100)
train_y = torch.sin(train_x * (2 * math.pi)) + torch.randn(train_x.size()) * 0.2
# We will use the simplest form of GP model, exact inference
class ExactGPModel(gpytorch.models.ExactGP):
def __init__(self, train_x, train_y, likelihood):
super(ExactGPModel, self).__init__(train_x, train_y, likelihood)
self.mean_module = gpytorch.means.ConstantMean()
self.covar_module = gpytorch.kernels.ScaleKernel(gpytorch.kernels.RBFKernel())
def forward(self, x):
mean_x = self.mean_module(x)
covar_x = self.covar_module(x)
return gpytorch.distributions.MultivariateNormal(mean_x, covar_x)
# initialize likelihood and model
likelihood = gpytorch.likelihoods.GaussianLikelihood()
model = ExactGPModel(train_x, train_y, likelihood)
for param_name, param in model.named_parameters():
print(f'Parameter name: {param_name:42} value = {param.item()}')
raw_outputscale = model.covar_module.raw_outputscale
print('raw_outputscale, ', raw_outputscale)
# Three ways of accessing the raw outputscale constraint
print('\nraw_outputscale_constraint1', model.covar_module.raw_outputscale_constraint)
printmd('\n\n**Printing all model constraints...**\n')
for constraint_name, constraint in model.named_constraints():
print(f'Constraint name: {constraint_name:55} constraint = {constraint}')
printmd('\n**Getting raw outputscale constraint from model...**')
print(model.constraint_for_parameter_name("covar_module.raw_outputscale"))
printmd('\n**Getting raw outputscale constraint from model.covar_module...**')
print(model.covar_module.constraint_for_parameter_name("raw_outputscale"))
raw_outputscale = model.covar_module.raw_outputscale
constraint = model.covar_module.raw_outputscale_constraint
print('Transformed outputscale', constraint.transform(raw_outputscale))
print(constraint.inverse_transform(constraint.transform(raw_outputscale)))
print(torch.equal(constraint.inverse_transform(constraint.transform(raw_outputscale)), raw_outputscale))
print('Transform a bunch of negative tensors: ', constraint.transform(torch.tensor([-1., -2., -3.])))
# Recreate model to reset outputscale
model = ExactGPModel(train_x, train_y, likelihood)
# Inconvenient way of getting true outputscale
raw_outputscale = model.covar_module.raw_outputscale
constraint = model.covar_module.raw_outputscale_constraint
outputscale = constraint.transform(raw_outputscale)
print(f'Actual outputscale: {outputscale.item()}')
# Inconvenient way of setting true outputscale
model.covar_module.raw_outputscale.data.fill_(constraint.inverse_transform(torch.tensor(2.)))
raw_outputscale = model.covar_module.raw_outputscale
outputscale = constraint.transform(raw_outputscale)
print(f'Actual outputscale after setting: {outputscale.item()}')
# Recreate model to reset outputscale
model = ExactGPModel(train_x, train_y, likelihood)
# Convenient way of getting true outputscale
print(f'Actual outputscale: {model.covar_module.outputscale}')
# Convenient way of setting true outputscale
model.covar_module.outputscale = 2.
print(f'Actual outputscale after setting: {model.covar_module.outputscale}')
print(f'Actual noise value: {likelihood.noise}')
print(f'Noise constraint: {likelihood.noise_covar.raw_noise_constraint}')
likelihood = gpytorch.likelihoods.GaussianLikelihood(noise_constraint=gpytorch.constraints.GreaterThan(1e-3))
print(f'Noise constraint: {likelihood.noise_covar.raw_noise_constraint}')
## Changing the constraint after the module has been created
likelihood.noise_covar.register_constraint("raw_noise", gpytorch.constraints.Positive())
print(f'Noise constraint: {likelihood.noise_covar.raw_noise_constraint}')
# Registers a prior on the sqrt of the noise parameter
# (e.g., a prior for the noise standard deviation instead of variance)
likelihood.noise_covar.register_prior(
"noise_std_prior",
gpytorch.priors.NormalPrior(0, 1),
lambda module: module.noise.sqrt()
)
# Create a GaussianLikelihood with a normal prior for the noise
likelihood = gpytorch.likelihoods.GaussianLikelihood(
noise_constraint=gpytorch.constraints.GreaterThan(1e-3),
noise_prior=gpytorch.priors.NormalPrior(0, 1)
)
# We will use the simplest form of GP model, exact inference
class FancyGPWithPriors(gpytorch.models.ExactGP):
def __init__(self, train_x, train_y, likelihood):
super(FancyGPWithPriors, self).__init__(train_x, train_y, likelihood)
self.mean_module = gpytorch.means.ConstantMean()
lengthscale_prior = gpytorch.priors.GammaPrior(3.0, 6.0)
outputscale_prior = gpytorch.priors.GammaPrior(2.0, 0.15)
self.covar_module = gpytorch.kernels.ScaleKernel(
gpytorch.kernels.RBFKernel(
lengthscale_prior=lengthscale_prior,
),
outputscale_prior=outputscale_prior
)
# Initialize lengthscale and outputscale to mean of priors
self.covar_module.base_kernel.lengthscale = lengthscale_prior.mean
self.covar_module.outputscale = outputscale_prior.mean
def forward(self, x):
mean_x = self.mean_module(x)
covar_x = self.covar_module(x)
return gpytorch.distributions.MultivariateNormal(mean_x, covar_x)
likelihood = gpytorch.likelihoods.GaussianLikelihood(
noise_constraint=gpytorch.constraints.GreaterThan(1e-2),
)
model = FancyGPWithPriors(train_x, train_y, likelihood)
hypers = {
'likelihood.noise_covar.noise': torch.tensor(1.),
'covar_module.base_kernel.lengthscale': torch.tensor(0.5),
'covar_module.outputscale': torch.tensor(2.),
}
model.initialize(**hypers)
print(
model.likelihood.noise_covar.noise.item(),
model.covar_module.base_kernel.lengthscale.item(),
model.covar_module.outputscale.item()
)
06-15
- 看来我昨天还是应该再外滩多留一会儿的,后来确实是有认识的人来的,可惜阿凯要赶火车,而且自己有点脱力,一个人留下不是很明智,关键是今天要考试…
- 既然躲不掉,那还是欣然接受罢,取个快递也能碰到。
- 卷子发下来,七道大题考了五条半的原题,以为稳了。笑死,根本写(抄)不完,出来问刘天浩情况如何(我其实从来不考完问人题目,但是这次是真的被恶心了),都一样,第一题抄了半小时,结果就开始发慌,后面越做(抄)越急,多出来的那题动态规划,我就不信有人能在4张答题纸上写完所有步骤,到目前为止考得最让我反胃的一门。本来下午复习完胸有成竹,感觉全都弄明白了,考试,考个屁。
重要的几个矩母函数结论(我感觉晚上会用到…)
-
设 M X ( t ) = E [ e t X ] M_X(t)=E\left[e^{tX}\right] MX(t)=E[etX],则:
-
若 X ∼ Γ ( α , β ) X\sim \Gamma(\alpha,\beta) X∼Γ(α,β),有 M X ( t ) = 1 ( 1 − β t ) α M_X(t)=\frac1{(1-\beta t)^\alpha} MX(t)=(1−βt)α1,其中 t < 1 β t<\frac1\beta t<β1
-
若 X ∼ X 2 ( n ) X\sim \mathcal{X}^2(n) X∼X2(n),有 M X ( t ) = 1 ( 1 − 2 t ) n 2 M_X(t)=\frac1{(1-2t)^\frac n2} MX(t)=(1−2t)2n1,其中 t < 1 2 t<\frac12 t<21
-
若 X ∼ N ( μ , σ 2 ) X\sim N(\mu,\sigma^2) X∼N(μ,σ2),有 M X ( t ) = e μ t + σ 2 2 t 2 M_X(t)=e^{\mu t+\frac{\sigma^2}2t^2} MX(t)=eμt+2σ2t2
-
若 X ∼ Exp ( λ ) X\sim \text{Exp}(\lambda) X∼Exp(λ),有 M X ( t ) = 1 1 − λ t M_X(t)=\frac1{1-\lambda t} MX(t)=1−λt1,其中 t < 1 λ t<\frac1\lambda t<λ1
-
对于CTMC(连续时间马尔可夫链)的仿真,之前的做法似乎有点不妥,之前一直是选择划分很小的时间间隔,然后等于化解成离散的MC来做,但是其实应该是以每个下一状态的转移率每次去生成指数分布的变量,然后看哪个变量最小就转移到哪个状态,然后时间递增这个指数分布的变量即可。这样就大大地减少了仿真地复杂度,尤其是时间间隔取得太小容易导致内存溢出。怎么以前这么蠢呢,见鬼地 LTH \text{LTH} LTH也没想过可以这么做,每次傻兮兮地取个1e-6的时间间隔,要跑上几个小时。
06-16
- 早起外面好凉快,但是明天的运筹闭卷,是要拼命的一天… 明早考完再跑了。搞了条三分紧身运动裤,昨晚穿上试跑了一下,挺不错,可惜感冒没好状态还是不行,希望明天感冒能好,能有个好天气罢。
- 午饭后感觉实在是太凉快了,不忍错过。进场冲了3km,均配4’01",破了之前3km的最好成绩,涅槃重生,满血复活,痛快!明天如果还能这么凉快,就去冲10km pb吧,
- 闭关一日。昨晚考完难得孙蜀和颜烨都在学校,之后一个去北京,一个去杭州,其实应该跟他们出去喝一杯的,可惜感冒没好,而且要复习,越来越难以两全。天佑明天运筹考的全会(写得全对我就不指望了,反正会就够了,这学期懒得看成绩了,随缘,真的争不动了,考原题真的一点意思没有)。
介绍一个很有趣的概念: totally unimodular matrix \text{totally unimodular matrix} totally unimodular matrix
什么样的矩阵可以称为 totally unimodular matrix \text{totally unimodular matrix} totally unimodular matrix呢?即这个矩阵(不要求必须方阵)的所有子方阵(即任取 k k k行 k k k列构成的阵,取的行列不必连续)的行列式为 0 0 0或 ± 1 \pm1 ±1。
根据上面的定义,容易看出 totally unimodular matrix \text{totally unimodular matrix} totally unimodular matrix的必要条件是矩阵中所有元素的取值为 0 0 0或 ± 1 \pm1 ±1,因为单取一个元素也是一个子方阵。
看起来判定一个矩阵是否属于 totally unimodular matrix \text{totally unimodular matrix} totally unimodular matrix还是很麻烦的,因为子方阵的数量非常多,以 n n n阶方阵为例,子方阵的数量为 1 + 4 + 9 + . . . + n 2 = 1 6 n ( n + 1 ) ( 2 n + 1 ) 1+4+9+...+n^2=\frac16n(n+1)(2n+1) 1+4+9+...+n2=61n(n+1)(2n+1)个,每个都检查一遍显然是太慢了,不过我们有下面的定理:
定理:一个仅由 0 , ± 1 0,\pm1 0,±1构成的矩阵是 totally unimodular matrix \text{totally unimodular matrix} totally unimodular matrix,当且仅当它的每一列(行)至多包含一个 1 1 1,且每一列(行)至多包含一个 − 1 -1 −1。
反向的证明非常容易,可以用数学归纳法,然后用行列式的主子式展开即可。正向相对麻烦一些,但是你可以相信它是正确的。
为什么要提 totally unimodular matrix \text{totally unimodular matrix} totally unimodular matrix的概念,因为它具有一个非常良好的性质:
定理:若矩阵 A ∈ R m × n A\in\R^{m\times n} A∈Rm×n是 totally unimodular matrix \text{totally unimodular matrix} totally unimodular matrix且 b ∈ R m b\in\R^{m} b∈Rm为一个整数向量,则集合 { x ∣ A x = b , x ≥ 0 } \{x|Ax=b,x\ge0\} {x∣Ax=b,x≥0}中每一个向量都是整数向量。
这个性质意味着 totally unimodular matrix \text{totally unimodular matrix} totally unimodular matrix对于整数规划意义重大,因为形如 A x = b , x ≥ 0 Ax=b,x\ge0 Ax=b,x≥0的线性约束下,总是可以得到整数解。
一个非常经典的应用案例就是最大流(
M
A
X
F
L
O
W
\rm MAXFLOW
MAXFLOW)问题,定义矩阵
A
=
R
∣
V
∣
×
∣
E
∣
A=\R^{|V|\times|E|}
A=R∣V∣×∣E∣:
A
=
{
a
i
j
}
=
{
1
if edge
j
starts from node
i
−
1
if edge
j
ends to node
i
0
otherwise
A=\{a_{ij}\}=\left\{\begin{aligned} &1&&\text{if edge }j\text{ starts from node }i\\ &-1&&\text{if edge }j\text{ ends to node }i\\ &0&&\text{otherwise}\\ \end{aligned}\right.
A={aij}=⎩⎪⎨⎪⎧1−10if edge j starts from node iif edge j ends to node iotherwise
则最大流问题可以用线性规划建模:
maximize
∑
j
:
(
s
,
j
)
∈
E
x
s
j
−
∑
i
:
(
i
,
s
)
∈
E
x
i
s
subject to
A
ˉ
x
=
0
0
≤
x
i
j
≤
c
i
j
∀
i
,
j
\text{maximize}\quad\sum_{j:(s,j)\in E}x_{sj}-\sum_{i:(i,s)\in E}x_{is}\\ \text{subject to}\quad \bar Ax=0\\ \quad 0\le x_{ij}\le c_{ij}\quad \forall i,j
maximizej:(s,j)∈E∑xsj−i:(i,s)∈E∑xissubject toAˉx=00≤xij≤cij∀i,j
其中 A ˉ \bar A Aˉ是在矩阵 A A A中删除 s , t s,t s,t两个节点所在行后的结果。
显然 A ˉ \bar A Aˉ是一个 totally unimodular matrix \text{totally unimodular matrix} totally unimodular matrix,关键是下面还有个 0 ≤ x i j ≤ c i j ∀ i , j 0\le x_{ij}\le c_{ij}\quad \forall i,j 0≤xij≤cij∀i,j的约束,这个其实可以添加松弛变量 s i j s_{ij} sij来解决,最终的标准形式就是:
maximize ∑ j : ( s , j ) ∈ E x s j − ∑ i : ( i , s ) ∈ E x i s subject to [ A ˉ 0 I I ] [ X S ] = [ 0 C ] x i j ≥ 0 ∀ i , j \text{maximize}\quad\sum_{j:(s,j)\in E}x_{sj}-\sum_{i:(i,s)\in E}x_{is}\\ \text{subject to}\quad \left[\begin{matrix}\bar A&0\\I&I\end{matrix}\right]\left[\begin{matrix}X\\S\end{matrix}\right]=\left[\begin{matrix}0\\C\end{matrix}\right]\\ \quad x_{ij}\ge0 \quad \forall i,j maximizej:(s,j)∈E∑xsj−i:(i,s)∈E∑xissubject to[AˉI0I][XS]=[0C]xij≥0∀i,j
显然 [ A ˉ 0 I I ] \left[\begin{matrix}\bar A&0\\I&I\end{matrix}\right] [AˉI0I]仍然是一个 totally unimodular matrix \text{totally unimodular matrix} totally unimodular matrix,所以就可以套用上面的性质了,这也就是为什么如果 C C C是整数向量(即网络流中的所有边的容量都为整数),则一定有一个整数的最大流解。
06-17
- 运筹感觉考得一般,没有达到预期,但也算差强人意。最后一门考试还有很久,可以休息一阵子了。
- 午饭看到sxy,结果我不是那么确信(总感觉头发没那么短…),怕认错就没打个招呼,最近眼神不行,还菜得真实。
- 5月1日跑出44’08"的10km后,今天是第二次冲击44分以内(上一次6月3日冲到8km熄火,不过跑出了8km的pb)还是失败了,主要4~6km时突然下大雨,节奏乱了,T恤湿透贴着特别难受。自己也确实很久不练长距离了,水平掉太多,最后跑到45分出头,还需努力,这种状态下半年是跑不了半马的。
关于凸函数的一个等价定义(比较有趣的表达形式,今天考到了):
函数
f
:
R
→
R
f:\R\rightarrow\R
f:R→R的定义域
dom
(
f
)
\textbf{dom}(f)
dom(f)是一个凸集,则
f
f
f是凸函数当且仅当
∀
x
,
y
,
z
∈
dom
(
f
)
\forall x,y,z\in\textbf{dom}(f)
∀x,y,z∈dom(f)(其中
x
<
y
<
z
x<y<z
x<y<z),有下式成立:
∣
1
1
1
x
y
z
f
(
x
)
f
(
y
)
f
(
z
)
∣
≥
0
\left|\begin{matrix} 1&1&1\\ x&y&z\\ f(x)&f(y)&f(z)\\ \end{matrix}\right|\ge0
∣∣∣∣∣∣1xf(x)1yf(y)1zf(z)∣∣∣∣∣∣≥0
这个的证明不是特别难,有兴趣的可以试一试,不过这个局限性是只针对一元函数才能用。
06-18
- 左膝报销,有两个多月膝盖没疼过了。
- 先把preconditioner整明白,有空水一文,计量的复习先缓一缓。
- 晚饭后3+5+2间歇,最后2圈最大心率超过190,快到终点时有种可怕的窒息感。明后计划再冲一次10km
下午给考场电脑装QT,本以为要一台台装,所以写了一个监测键盘及鼠标操作的脚本,根据脚本的记录内容可以复原键盘及鼠标的操作,这是我想出来的自动化在WINDOWS系统上安装软件的笨办法(Linux自然可以直接写bash脚本安装),结果我兴致勃勃写完这个脚本,他们告诉我只要在母机上装好,然后把模板上传下载到各个子机上就完事了。真是蠢得真实…
监测鼠标键盘操作的脚本:
# -*- coding: utf-8 -*-
# @author: caoyang
# @email: caoyang@163.sufe.edu.cn
import time
import logging
from pynput import mouse, keyboard
logging.basicConfig(
level= logging.DEBUG,
format='%(asctime)s %(filename)s : %(levelname)s %(message)s',
datefmt='%Y-%m-%d %H:%M:%S',
filename='logging.log',
filemode='w',
)
console = logging.StreamHandler()
console.setLevel(logging.INFO)
formatter = logging.Formatter('%(asctime)s %(filename)s : %(levelname)s %(message)s')
console.setFormatter(formatter)
logging.getLogger().addHandler(console)
def keyboard_listener():
def _on_press(key):
info = f'press key {key}'
logging.info(info)
def _on_release(key):
info = f'release key {key}'
logging.info(info)
with keyboard.Listener(on_press=_on_press, on_release=_on_release) as listener:
listener.join()
def mouse_listener():
def _on_move(x, y):
info = f'move to ({x}, {y})'
logging.info(info)
def _on_click(x, y, button, pressed):
info = f'{"click" if pressed else "released"} {button} at ({x}, {y})'
logging.info(info)
def _on_scroll(x, y, dx, dy):
info = f'scrolled at ({x}, {y}) by ({dx}, {dy})'
logging.info(info)
with mouse.Listener(on_move=_on_move, on_click=_on_click, on_scroll=_on_scroll) as listener:
listener.join()
if __name__ == '__main__':
# keyboard_listener()
mouse_listener()
根据鼠标操作记录复原(键盘暂时没写,稍微麻烦一点,要把所有键位跟id对上,比较费事,以后用到再写)
# -*- coding: utf-8 -*-
# @author: caoyang
# @email: caoyang@163.sufe.edu.cn
import time
from pynput import mouse, keyboard
def mouse_script(logging_path):
def _find_coordinate(_string):
index_1 = _string.find('(')
index_2 = _string.find(',', index_1)
index_3 = _string.find(')', index_2)
return int(_string[index_1+1: index_2]), int(_string[index_2+1: index_3])
with open(logging_path, 'r') as f:
lines = f.read().splitlines()
mouse_controller = mouse.Controller()
last_timestamp = None
for line in lines:
x, y = _find_coordinate(line)
timestring = line[:19]
timestamp = time.mktime(time.strptime(timestring, '%Y-%m-%d %H:%M:%S'))
if last_timestamp is None:
last_timestamp = timestamp
else:
time.sleep(timestamp - last_timestamp)
last_timestamp = timestamp
print(timestamp)
if 'move' in line:
mouse_controller.move(x, y)
elif 'click' in line:
mouse_controller.move(x, y)
if 'Button.left' in line:
mouse_controller.press(mouse.Button.left)
elif 'Button.right' in line:
mouse_controller.press(mouse.Button.right)
else:
assert False
elif 'release' in line:
mouse_controller.move(x, y)
if 'Button.left' in line:
mouse_controller.release(mouse.Button.left)
elif 'Button.right' in line:
mouse_controller.release(mouse.Button.right)
else:
assert False
elif 'scroll' in line:
mouse_controller.move(x, y)
x1, y1 = _find_coordinate(line[line.find(' by '):])
mouse_controller.scroll(x1, y1)
else:
assert False
if __name__ == '__main__':
mouse_script('logging.log')
06-19
- 巨大突破!得益于前日雨中10k与昨天间歇的训练,10.05km用时42’48",均配4’15",刷新pb整整95秒。
- 早起就觉得今天是不可错过的好天气,只有20℃,下午雨歇,是突破44分的绝佳机会。起手第一个1000米失误跑到4’09",4km用时17’06",比4km的pb只慢了10秒,但是尚有余力,6km用时25’44"(破前pb 26’09"),8km用时34’10"(破前pb 35’12"),当时就有种无所不能的超脱感,只是最后2km明显力竭,已经完成不了加速冲刺。
- 可能算是近两三个月最畅快的一次长跑了,计量也复习得差不多(觉得还是把硬性任务先做了,反正早晚要复习),极致的尽兴!这个成绩可能是整个夏天都遥不可及的了。
计量复习里遇到的困惑点:
- 为什么一元线性回归的随机误差项方差的最小二乘估计量是无偏的?(事实上我想知道到底是怎么用 O L S \rm OLS OLS来估计 Var ( μ ) \text{Var}(\mu) Var(μ)的,即 σ ^ O L S 2 = ∑ i e i 2 n − 2 \hat \sigma_{\rm OLS}^2=\frac{\sum_{i}e_i^2}{n-2} σ^OLS2=n−2∑iei2到底是怎么推出来的)。
- 其实我还是没有看明白一元线性回归的情况下,变量显著性检验和方程显著性检验等价性的推导,即
F
=
t
2
F=t^2
F=t2,我怎么感觉推导过程那么奇怪…(针对
H
0
:
β
1
=
0
H_0:\beta_1=0
H0:β1=0的检验过程,为什么第一个等号就把
β
^
0
\hat \beta_0
β^0给丢掉了…)
F = ∑ y ^ i 2 ∑ e i 2 / ( n − 2 ) = β ^ 1 2 ∑ x i 2 ∑ e i 2 / ( n − 2 ) = β ^ 1 2 ∑ e i 2 / ( n − 2 ) ∑ x i 2 = [ β ^ 1 ∑ e i 2 / ( n − 2 ) ∑ x i 2 ] 2 = [ β ^ 1 ∑ e i 2 n − 2 ⋅ 1 ∑ x i 2 ] 2 = t 2 F=\frac{\sum\hat y_i^2}{\sum e_i^2/(n-2)}=\frac{\hat\beta_1^2\sum x_i^2}{\sum e_i^2/(n-2)}=\frac{\hat\beta_1^2}{\sum e_i^2/(n-2)\sum x_i^2}=\left[\frac{\hat\beta_1}{\sqrt{\sum e_i^2/(n-2)\sum x_i^2}}\right]^2=\left[\frac{\hat\beta_1}{\sqrt{\frac{\sum e_i^2}{n-2}\cdot\frac1{\sum x_i^2}}}\right]^2=t^2 F=∑ei2/(n−2)∑y^i2=∑ei2/(n−2)β^12∑xi2=∑ei2/(n−2)∑xi2β^12=[∑ei2/(n−2)∑xi2β^1]2=⎣⎡n−2∑ei2⋅∑xi21β^1⎦⎤2=t2 - 关于
D
u
r
b
i
n
\rm Durbin
Durbin两步法估计带有序列相关性模型的方法:
Y i = ( ∑ k = 1 l ρ k Y i − k ) + β 0 ( 1 − ∑ k = 1 l ρ k ) + β 1 ( X i − ∑ k = 1 l ρ k X i − k ) Y_i=\left(\sum_{k=1}^l\rho_kY_{i-k}\right)+\beta_0\left(1-\sum_{k=1}^l\rho_k\right)+\beta_1\left(X_i-\sum_{k=1}^l\rho_kX_{i-k}\right) Yi=(k=1∑lρkYi−k)+β0(1−k=1∑lρk)+β1(Xi−k=1∑lρkXi−k)- 第一步只是在估计 Y i − k Y_{i-k} Yi−k前面的系数 ρ k \rho_k ρk,估计完了代入再估计后面两项,所以第一步只估计 Y i − k Y_{i-k} Yi−k前面的系数 ρ k \rho_k ρk,后面两项怎么办呢( ρ k \rho_k ρk又观测不到,所以后面两项都不知道怎么做回归…)?
- 相对来说 Cochrane-Orcutt \text{Cochrane-Orcutt} Cochrane-Orcutt迭代法倒是比较明白,就先正常估计 Y i = β 0 + β 1 X i + μ i Y_i=\beta_0+\beta_1X_i+\mu_i Yi=β0+β1Xi+μi,然后对得到的 μ i \mu_i μi做 l l l阶自相关回归 μ i = ϵ i + ∑ k = 1 l ρ k μ i − k \mu_i=\epsilon_i+\sum_{k=1}^l\rho_k\mu_{i-k} μi=ϵi+∑k=1lρkμi−k,将估计得到的结果 ρ ^ k \hat \rho_k ρ^k代回到广义差分模型 Y i = ( ∑ k = 1 l ρ k Y i − k ) + β 0 ( 1 − ∑ k = 1 l ρ k ) + β 1 ( X i − ∑ k = 1 l ρ k X i − k ) Y_i=\left(\sum_{k=1}^l\rho_kY_{i-k}\right)+\beta_0\left(1-\sum_{k=1}^l\rho_k\right)+\beta_1\left(X_i-\sum_{k=1}^l\rho_kX_{i-k}\right) Yi=(∑k=1lρkYi−k)+β0(1−∑k=1lρk)+β1(Xi−∑k=1lρkXi−k)中把 β ^ i \hat\beta_i β^i估计出来,再代回到原模型 Y i = β 0 + β 1 X i + μ i Y_i=\beta_0+\beta_1X_i+\mu_i Yi=β0+β1Xi+μi中去,得到新的 μ i \mu_i μi观测值后继续做 l l l阶自相关回归,重复上述流程即可。
06-20
- WXY昨天刚好在我退场后也进场跑了一次10km,用时40’25",均配4’02"。太强了,我拼半条命(最后两圈心脏有刺痛感)才跑成这样,差距好大。不过去年认识的那个大爷现在是跑不过我了哈哈。
- 复习计量到午夜0:40,全部看完,少一件破事。然后刚好刷到就看到了两点。确实很久不看球了(连番剧也很久不追不补了,真的好多东西都丢了,羡慕这么大岁数还熬夜看球的人),恰好是葡萄牙对阵德国,可惜结局还是莫得悬念…
- 出门称重只剩66kg,努力三餐吃饱,可还是止不住体重在掉。晚归随性跑了1km,3’40",跑完看到裸奔狂人在跑,笑死,他跑一圈,我跟一圈,他再跑一圈,我就休一圈,成功造成我一直跟着他的假象。接下来会经常性练间歇跑,夏天不指望能破6km-10km的成绩,主要练5km内的速度的和10km以上的耐力,我希望能在自己第一个半马上跑出不错的成绩。
- 话说娃娃机真能抓到这么大的公仔么… 有个能带着出去玩的室友是真好,大约所谓近朱者赤罢,可能我真的会一直黑到底。其实也不坏,路是自己选的,也容不得后悔。
关于【论文实现】以SVD的分解形式进行深度神经网络的训练(PyTorch)的代码有一点小问题,忘了对重写的卷积层和线性层的权重矩阵参数初始化,导致网络输出中有大量的 N a N \rm NaN NaN,损失函数计算出问题。
其实源码看得还是不仔细,torch里对所有权重矩阵参数都做了kaiming_uniform_的初始化,不做初始化权重就都是零,所以会出一点问题。不过我也懒得改原博客了,反正也不会有人真的会去细究,修正后的cifar_layers.py如下(构造函数中添加初始化,cifar_init模块即E:\Anaconda3\Lib\site-packages\torch\nn\init.py中的源码,直接复制过来用即可):
现在有新的问题,就是似乎跑得很慢,按道理SVDTraining应该很快才对,不知道是哪里理解的不对。
# -*- coding: utf-8 -*-
# @author: caoyang
# @email: caoyang@163.sufe.edu.cn
import math
import torch
import cifar_init as init
from torch.nn import functional as F
class Conv2dSVD(torch.nn.Conv2d):
"""二维卷积层的SVD形式"""
def __init__(self, in_channels, out_channels, kernel_size, stride=1, padding=0, dilation=1, groups=1, bias=True, padding_mode='zeros', decomposition_mode='channel'):
super(Conv2dSVD, self).__init__(
in_channels=in_channels,
out_channels=out_channels,
kernel_size=kernel_size,
stride=stride,
padding=padding,
dilation=dilation,
groups=groups,
bias=bias,
padding_mode=padding_mode,
)
kernel_height, kernel_width = self.kernel_size
self.decomposition_mode = decomposition_mode
if self.decomposition_mode == 'channel': # 管道级的分解
rank = min(out_channels, in_channels * kernel_height * kernel_width) # r = min(n, cwh)
self.svd_weight_matrix_u = torch.nn.Parameter(torch.Tensor(out_channels, rank)) # 左奇异向量矩阵,形状为n×r
self.svd_weight_matrix_v = torch.nn.Parameter(torch.Tensor(in_channels * kernel_width * kernel_height, rank)) # 右奇异向量矩阵,形状为cwh×r
self.svd_weight_vector_s = torch.nn.Parameter(torch.Tensor(rank, )) # 奇异值向量
elif self.decomposition_mode == 'spatial': # 空间级的分解
rank = min(out_channels * kernel_width, in_channels * kernel_height) # r = min(nw, ch)
self.svd_weight_matrix_u = torch.nn.Parameter(torch.Tensor(out_channels * kernel_width, rank)) # 左奇异向量矩阵,形状为nw×r
self.svd_weight_matrix_v = torch.nn.Parameter(torch.Tensor(in_channels * kernel_height, rank)) # 右奇异向量矩阵,形状为ch×r
self.svd_weight_vector_s = torch.nn.Parameter(torch.Tensor(rank, )) # 奇异值向量
else:
raise Exception(f'Unknown decomposition mode: {decomposition_mode}')
# 参数初始化:注意源码中构造函数中有self.reset_parameters
init.kaiming_uniform_(self.svd_weight_matrix_u, a=math.sqrt(5))
init.kaiming_uniform_(self.svd_weight_matrix_v, a=math.sqrt(5))
init.uniform_(self.svd_weight_vector_s, -1, 1)
def forward(self, input):
kernel_height, kernel_width = self.kernel_size
if self.decomposition_mode == 'channel': # 管道级的分解
weight = torch.mm(torch.mm(self.svd_weight_matrix_u, torch.diag(self.svd_weight_vector_s)), self.svd_weight_matrix_v.t()) # (out_channels, in_channels * kernel_width * kernel_height)
weight = weight.reshape(self.out_channels, self.in_channels, kernel_height, kernel_width) # (out_channels, in_channels , kernel_height, kernel_width)
elif self.decomposition_mode == 'spatial': # 空间级的分解
weight = torch.mm(torch.mm(self.svd_weight_matrix_u, torch.diag(self.svd_weight_vector_s)), self.svd_weight_matrix_v.t()) # (out_channels * kernel_width, in_channels * kernel_height)
weight = weight.reshape(self.out_channels, kernel_width, self.in_channels, kernel_height) # (out_channels, kernel_width, in_channels , kernel_height)
weight = weight.permute((0, 2, 3, 1)) # 这里我觉得可能直接reshape成(out_channels, in_channels , kernel_height, kernel_width)也可以,但是从矩阵的形状上来看可能还是按顺序reshape更合理一些,最后再多做一个维度置换即可
# 用法: torch.nn.functional.conv2d(input, weight, bias=None, stride=1, padding=0, dilation=1, groups=1)
if not self.padding_mode == 'zeros': # 这部分似乎源码中是未完成状态,内容稍微有点乱,不过一般来说padding都是零填充,所以用不到这边的内容
from torch._six import container_abcs
from itertools import repeat
def _reverse_repeat_tuple(t, n):
return tuple(x for x in reversed(t) for _ in range(n))
def _ntuple(n):
def parse(x):
if isinstance(x, container_abcs.Iterable):
return x
return tuple(repeat(x, n))
return parse
_pair = _ntuple(2)
return F.conv2d(F.pad(input, _reverse_repeat_tuple(self.padding, 2), mode=self.padding_mode), weight, self.bias, self.stride, _pair(0), self.dilation, self.groups)
return F.conv2d(input, weight, self.bias, self.stride, self.padding, self.dilation, self.groups)
class LinearSVD(torch.nn.Linear):
"""线性层的SVD形式"""
def __init__(self, in_features, out_features, bias=True):
super(LinearSVD, self).__init__(in_features, out_features, bias)
rank = min(in_features, out_features)
self.svd_weight_matrix_u = torch.nn.Parameter(torch.Tensor(out_features, rank))
self.svd_weight_matrix_v = torch.nn.Parameter(torch.Tensor(in_features, rank))
self.svd_weight_vector_s = torch.nn.Parameter(torch.Tensor(rank, ))
# 参数初始化:注意源码中构造函数中有self.reset_parameters
init.kaiming_uniform_(self.svd_weight_matrix_u, a=math.sqrt(5))
init.kaiming_uniform_(self.svd_weight_matrix_v, a=math.sqrt(5))
init.uniform_(self.svd_weight_vector_s, -1, 1)
def forward(self, input):
weight = torch.mm(torch.mm(self.svd_weight_matrix_u, torch.diag(self.svd_weight_vector_s)), self.svd_weight_matrix_v.t())
return F.linear(input, weight, self.bias)
06-21
- 《不见长安》,理想与现实的差距。每个人都有自己纸上的长安,可是真的抵达却茫然失措,最终怀恨诀别。不属于你的长安,你永远无法拥有,然而长安也许并不存在,因此既要怀揣理想,也要学会走出理想,奈何偶尔看到真的是很美好(齐刘海+口罩确实是上照神器)。
- 晚饭后4km慢跑,刚好WXY也在,自己状态不太行没敢跟上去,怕被拉爆。10圈快到终点时被他套了一圈,提速想反超却做不到,害,无能狂怒。
- 对于多元线性回归模型,何谓“内生性”?它有什么危害?怎么来判断一个模型中是否具有“内生性”?对此问题,请你进行详细论证。
- 估计多元线性回归模型,其目标函数是残差的偶数次方和最小,这种做法是否正确?为什么?这一目标函数的结果与采用极大似然法的结果有何不同?
- 有一研究者欲分析我国股票市场
S
\rm S
S与
G
D
P
\rm GDP
GDP的关系,采用
2000
-
2017
2000\text{-}2017
2000-2017年上证指数和我国
31
31
31个省级单位的面板数据对各省工业生产总值
I
N
D
\rm IND
IND建立了模型并进行实证检验:
ln IND = β 0 + β 1 ln S + μ 1 \ln\text{IND}=\beta_0+\beta_1\ln\text{S}+\mu_1 lnIND=β0+β1lnS+μ1
通过采用 O L S \rm OLS OLS估计模型参数,得到 β 1 = 3.47 \beta_1=3.47 β1=3.47,于是得出结论:我国股票市场 S \rm S S对 G D P \rm GDP GDP的影响弹性为 3.47 3.47 3.47。请从计量经济学模型理论和方法角度指出以上做法的错误之处。 - 现研究城市化
u
r
b
\rm urb
urb对城乡收入差距
g
a
p
\rm gap
gap的影响,有人设立模型:
ln gap i = β 0 + β 1 ln urb i + μ i i = 1 , 2 , . . . , n \ln\text{gap}_i=\beta_0+\beta_1\ln\text{urb}_i+\mu_i\quad i=1,2,...,n lngapi=β0+β1lnurbi+μii=1,2,...,n-
( 1 ) (1) (1) 以上模型可能存在什么问题?这些问题有什么后果?为什么?
-
( 2 ) (2) (2) 如果以上模型中存在随机解释变量问题(内生性问题),请你从经济学理论上出发,为 u r b \rm urb urb找出至少两个工具变量( I V \rm IV IV),并充分论证你所选择的工具变量的合理性。
-
( 3 ) (3) (3) 在以上 ( 2 ) (2) (2)的基础上,能否采用狭义的工具变量法估计模型参数?为什么?
-
( 4 ) (4) (4) 如果采用两阶段最小二乘法( 2 S L S \rm 2SLS 2SLS)估计模型参数,请写出估计过程。并详细说明它与狭义的工具变量法有什么区别。
-
- 现在需要研究目前中国以下经济社会问题,请从计量经济学模型设定理论出发详细说明如何建立模型进行实证分析。
- ( 1 ) (1) (1) 2021 2021 2021年中国新基建投资规模。
- ( 2 ) (2) (2) 2020 2020 2020年中国地摊经济就业人数总量预测。
- 对我国
1990
-
2019
1990\text{-}2019
1990-2019年
GDP
\text{GDP}
GDP和劳动力就业人数
L
a
b
\rm Lab
Lab的时间序列进行分析:
- ( 1 ) (1) (1) 以上两个序列是否同阶单整?如何检验?请写出详细的检验步骤。
- ( 2 ) (2) (2) 经过检验,如果发现 G D P \rm GDP GDP和 L a b \rm Lab Lab单整阶数不同,它们是否可能存在协整关系?在此条件下对二者进行回归分析,会造成什么结果?
- ( 3 ) (3) (3) 如果 G D P \rm GDP GDP和 L a b \rm Lab Lab的短期波动具有误差修正模型( E C M \rm ECM ECM),这是否意味着它们之间一定具有协整关系?为什么
- ( 4 ) (4) (4) 对 G D P \rm GDP GDP和 L a b \rm Lab Lab进行时间序列分析,“协整关系与误差修正模型( E C M \rm ECM ECM)没有本质区别”,这种说法是否正确?为什么?如果不正确,那么请问它们的本质区别是什么?请详细说明。
06-22
- 计量考完,比去年多两道大题,勉强全部写完(跟写马哲一样,密密麻麻写满四张纸,绝了)。感觉一般,等最终成绩,希望别让我太失望(这学期最后也许还是未能挽救自己,虽然期末感觉自己已经比以往都更尽力了,只是自己这么多年偶尔想要争一回成绩的时候却不得,很失落)。
- 刚考完就收到导师的“亲切的问候”,赶紧中午回去休息了一会儿就出门到图书馆干活,紧凑一些好。虽然并非完全出于本意,但还是无可奈何地碰到了wyy,学校就这么大,想躲确实很难(关键自己还跑回去确认一眼也太犯贱了),既来之则安之罢。
- 晚归间歇3km+2km+0.5km,均配4’09"+4’13"+3’53",状态尚可。最后一个500米是跟着裸奔狂人跑的,本来是想要跟完1km,结果他跑得太快,自己刚完成5km已是强弩之末,无奈又被拉爆。有机会满状态跟一次,或许能顺势破3km和4km的pb。
还是憋去图书馆了… 都有一个多月没去过了,真是自找不痛快。
下午花了一些功夫看了使用CNN进行雅可比预条件子的生成的项目代码,发现这个项目代码写得也太离谱了,README没有也就算了,关键还跑不通,改了好久才通,提供的伪造数据跟代码完全不匹配,还得自己根据paper重写了一份伪造逻辑。不过我看下来似乎只是做有雅可比块和无雅可比块的二分类预测,并不是确切地找到雅可比块的构成,这就有点令人失望了,到底还是确实地把雅可比块找出来比较切实际。眼下硬任务是把邓琪的项目搞掉,大约如此。
#!/usr/bin/env python
import argparse
import pickle
import h5py
from keras import optimizers
from keras.callbacks import ModelCheckpoint
from keras.layers import Activation, add, BatchNormalization, Conv2D, Dense, Dropout, Flatten, Input, ZeroPadding2D
from keras.models import load_model, Model
from keras.regularizers import l2
from keras.utils import plot_model
import numpy as np
def positive_int(value):
try:
parsed = int(value)
if not parsed > 0:
raise ValueError()
return parsed
except ValueError:
raise argparse.ArgumentTypeError('value must be an positive integer')
# def parse_cli():
# parser = argparse.ArgumentParser()
# parser.add_argument(
# '-e', '--epochs',
# nargs='?',
# type=positive_int,
# action='store',
# default=10,
# help='number of training epochs'
# )
# parser.add_argument(
# metavar='TRAIN',
# type=str,
# dest='train',
# help='path to the HDF5 file with the training data'
# )
# parser.add_argument(
# metavar='MODEL',
# type=str,
# dest='model',
# help='path where to store the model'
# )
# return parser.parse_args()
def load_data(path):
with h5py.File(path, 'r') as handle:
# data = np.array(handle['diagonalset'])
data = np.array(handle['matrixset'])
labels = np.array(handle['vectorset'])
return data, labels
def preprocess(data, labels):
# simply add an additional dimension for the channels for data
# swap axis of the label set
return np.moveaxis(np.expand_dims(data, axis=3), 2, 0), np.moveaxis(labels, 0, -1)
# return np.expand_dims(data, axis=3), np.moveaxis(labels, 0, -1)
def build_model(input_shape):
input_img = Input(shape=input_shape)
# first bottleneck unit
bn_1 = BatchNormalization()(input_img)
activation_1 = Activation('selu')(bn_1)
conv_1 = Conv2D(32, kernel_size=(5, 5,), padding='same', kernel_regularizer=l2(0.02))(activation_1)
bn_2 = BatchNormalization()(conv_1)
activation_2 = Activation('selu')(bn_2)
# conv_2 = Conv2D(128, kernel_size=(3, 3,), padding='same', kernel_regularizer=l2(0.02))(activation_2)
conv_2 = Conv2D(32, kernel_size=(3, 3,), padding='same', kernel_regularizer=l2(0.02))(activation_2)
merged = add([input_img, conv_2])
# corner detection
bn_3 = BatchNormalization()(merged)
padding = ZeroPadding2D(padding=(0, 3))(bn_3)
conv_3 = Conv2D(32, kernel_size=(21, 7,), padding='valid', activation='tanh')(padding)
# conv_4 = Conv2D(128, kernel_size=( 1, 3,), padding='same', activation='tanh')(conv_3)
conv_4 = Conv2D(32, kernel_size=( 1, 3,), padding='same', activation='tanh')(conv_3)
# fully-connected predictor
flat = Flatten()(conv_4)
# classify = Dense(512, activation='sigmoid')(flat)
classify = Dense(128, activation='sigmoid')(flat)
dropout = Dropout(0.1)(classify)
result = Dense(input_shape[1], activation='sigmoid')(dropout)
model = Model(inputs=input_img, outputs=result)
model.compile(optimizer=optimizers.Nadam(lr=1e-4), loss='binary_crossentropy', metrics=['accuracy'])
return model
def train_network(model, data, labels, model_file, epochs):
plot_model(model, to_file='{}.png'.format(model_file), show_shapes=True)
checkpoint = ModelCheckpoint(model_file, monitor='val_loss', verbose=True, save_best_only=True, save_weights_only=False, mode='auto')
training = model.fit(data, labels, epochs=epochs, batch_size=8, validation_split=1.0/5.0, class_weight={0: 0.1, 1: 0.9}, callbacks=[checkpoint])
with open('{}.history'.format(model_file), 'wb') as handle:
pickle.dump(training.history, handle)
if __name__ == '__main__':
# arguments = parse_cli()
# data, labels = preprocess(*load_data(arguments.train))
# model = build_model(input_shape=data.shape[1:])
# train_network(model, data, labels, arguments.model, arguments.epochs)
n_epochs = 10
trainset_path = 'artificial.h5'
model_path = 'model.h5'
data, labels = preprocess(*load_data(trainset_path))
model = build_model(input_shape=data.shape[1:])
model.summary()
train_network(model, data, labels, model_path, n_epochs)
06-23
- 稀疏训练这块还有不少人开发了模块,似乎速度就是会很慢,本质是节约空间么?不科学啊,先再看几篇弄清楚。感觉只剩最后六天想要给邓琪搞点名堂出来比较有挑战性,试试看咯,颜烨那边也在糊报告,不过他们不用汇报倒是容易。搞完邓琪的汇报想先回去休养一阵子了(但愿wyl那边没急事),明明上学期也是每天在跑,却也没像这学期瘦掉将近20多斤,真的太伤了。
- 罪过,下午上了个分,国战排位打到枭雄35星…
- 晚上每周一次的飞盘活动,上半场40分钟后,轻度疲劳状态下测了一次1000米,3分36秒,算是一个不错的成绩了,下半场打完慢跑了五圈收尾,北大的极限飞盘社社长ljw过一阵子要离开了,拍了一张合照留念(这学期玩了四五吧差不多),以后SUFE要真的有极限飞盘社,我们也算是社团的前身了哈哈。
- 这几天很热,想把1000米练进3分半,等28号下雨凉快下来之后跑一次10km以上的长距离耐力,然后回家之前计划再完成一次场地20km,上半年即完满。
吐了,原来使用CNN进行雅可比预条件子的生成的项目代码里是有伪造数据生成的逻辑的额,不写README是真的坑,我以为直接从train开始跑,原来有extract_diagonals.py的… 还是颜烨眼神好[Facepalm]
#!/usr/bin/env python
import argparse
import h5py
import numpy as np
DATA_DATASET = 'matrixset'
DIAGONALS_DATASET = 'diagonalset'
WINDOW = 10
def parse_cli():
parser = argparse.ArgumentParser()
parser.add_argument(
metavar='DATA',
type=str,
dest='data',
help='path to the HDF5 file that stores the matrices'
)
return parser.parse_args()
def extract_diagonals(path):
handle = h5py.File(path, 'r+')
# load the data and move the sample axis to the front
data = np.moveaxis(np.array(handle[DATA_DATASET]), -1, 0)
width = data.shape[1]
samples = data.shape[0]
diagonalset = np.zeros((samples, 2 * WINDOW + 1, width), dtype=np.float32)
for j in range(samples):
image = data[j, :, :]
# always reallocate the diagonals image here to fill the left triangle with ones
out = np.ones((2 * WINDOW + 1, width), dtype=np.float32)
for i in range(-WINDOW, WINDOW + 1):
diagonal = np.diagonal(image, i)
out[i + WINDOW, abs(i):] = diagonal
out = ((out - out.min()) / out.max() * 2) - 1
diagonalset[j] = out
# remove the previous diagonals set if present
if DIAGONALS_DATASET in list(handle.keys()):
del handle[DIAGONALS_DATASET]
handle[DIAGONALS_DATASET] = diagonalset
# release the handle
handle.close()
if __name__ == '__main__':
# arguments = parse_cli()
# extract_diagonals(arguments.data)
06-24
- 高级运筹与优化理论还是挣扎回来了,卡位90分,卷面略差,好在七次作业分数还行。
- 老妈来沪办事,下午见了一面,真的是肉眼可见的变老了。这学期中途没有回家,所以四个月不见了,虽然每天都会通电话,但是一看到她越发苍老的脸,自己却正是年富力强,真的很不是滋味。一想到等我博士毕业妈妈可能已经快要六十岁,已经是可以叫奶奶的年纪了,真的好快好快,多想能慢一点,多给我一些时间罢。
- 晚4km跑,均配4’20",太热,两圈心率就飙到160,状态也不太行。不过被WXY跟了5圈,我一看影子的摆臂动作就知道是他,想让他带我,结果直接把我给带崩了。
- PS:我有点好奇到底是谁最近突然把我卖了,明明我断更上一篇log之后已经没有什么访问量了,为什么这两天每天有数十的访问,这个数量和监测到的访问频率应该不是脚本在刷,我想过要删了那篇log,奈何要扣分,而且博客数据也要掉,有点不忍心,这事情有点诡异,奈何现在CSDN更新之后查不到主要访问IP来源了,看且看罢。
lh开始展露他锋锐的一面,邓琪的汇报可能要借他六分力了,总归不能什么事情都是我来主导做。我目前在看一篇新的CNN稀疏训练paper,很有深度,争取今晚把笔注发出来,来不及了,接下来几天我要去院里做助管,这次给的比较多,半天100元,想必破事会很多,赚点外快吧。五体不勤整整一年了,做个人吧cy。
下面是lh对随机karzman算法并行实现一个matlab脚本,lh在原文基础上想到了一些创新型的改进,确实加快了算法速度。我暂时没空看随机算法的paper,等我把我这边想做的东西的思路理清,再去学习一下,邓琪的汇报嘛,主要是内容质量,形式倒是次要的,说不定跟他聊半小时就算过了,所以得动点脑子。
function x=randKacz_Parrall(A,b,x1)
[w,l]=size(A);
funtol = 100*eps; xtol = 100*eps; maxiter = 20;
x = x1;
%y = A*x-b;
dx = Inf; % for initial pass below
k = 1;
p=0;
for i=1:w
p(i)=norm(A(i,:));
end
p=p./sum(p);
c = parcluster();
dx=[];
while (k < maxiter)
% r=rand();
% for j=1:w
% if r<sum(p(1:j))
% i=j;
% break;
% end
% end
% a=A(i,:);
% dx=(b(i)-dot(a,x(:,k)))/norm(a)^2*a;
%size(x)
%size(dx')
% parpool(8)
parfor j=1:500
dx(j,:)=iter(A,b,x(:,k),p,w);
end
% dx=load(job(1),'dx')
step=sum(dx)/500;
x(:,k+1) = x(:,k) + step';
%y(:,k)=norm(A*x(:,k)-b);
k=k+1;
% y=A*x(k)-b;
end
if k==maxiter, warning('Maximum number of iterations reached.'), end
end
06-25
- 树欲静而风不止。早上碰到林振炜,得知叉院那边的硕博也有在看我的blog,看来把鬼子引到这里来的要么是刘天浩和刘宏瑞,要么是颜烨。
- 午饭留在院里跟几个不认识的老师打了会儿乒乓球,都有三年不碰乒乓球了,好在手感没有掉太多,反拧反拉都还能上得去,正手确实是生疏了。想想确实找个能日常一起打球的真的是不容易,年纪越大,人越忙,所以只能跑跑步。
- 确认了WXY的身份,金院大三的武新宇,也是江苏人。其实他去年这个时候差不多跟我现在的配速相仿,然后一年从4’20"提升到3’50"以内,10km的pb37分半,tql。晚上操场封闭,绕五角场跑了10km,均配4’40",路况很差,天气也很闷,算是差强人意的一次路跑练习。也许我再练上一年也可以达到WXY的水平,期待自己5km与10km突破4分配的那一天,Fight!
我发现今天搭档的另一个助管杨静月居然也是个硕博,一起上了一学期的六门专业课,我居然一点印象也没有…
李浩证明了随机Karzman算法的一些收敛性质,目前来看比较缓慢,算是伪一次收敛,不过收敛速度还是跟每次选取的矩阵行有关。我目前在学习自定义写优化器,但是可能还是很难把李浩那边的工作给融入进来,实在不行到时候我们各讲各的,反正都算是有一些成果,实在融合不起来也无能为力了。
Karzman迭代算法用于解大规模线性系统
A
x
=
b
Ax=b
Ax=b:
x
k
+
1
=
x
k
−
A
r
(
i
)
x
k
−
b
r
(
i
)
∥
A
r
(
i
)
∥
2
A
r
(
i
)
⊤
x^{k+1}=x^k-\frac{A_{r(i)}x^k-b_{r(i)}}{\|A_{r(i)}\|^2}A_{r(i)}^\top
xk+1=xk−∥Ar(i)∥2Ar(i)xk−br(i)Ar(i)⊤
这里本质是随机挑选若干行 r ( i ) r(i) r(i)出来做迭代,有点类似 S G D \rm SGD SGD,但是步长并不完全相同。
我们实现了该算法的并行,并证明了这个算法的收敛速度为 1 q \frac1q q1, q q q为每次提取的行的数量,需要在收敛速度与运行速度之间做一个 t r a d e o f f \rm tradeoff tradeoff,者需要一些实验结果的支撑。
06-26
- 早起发现sxy昨天怎么像打了鸡血,运动时长上到300多分钟… 我记得前天才70分钟,也太夸张了…(难以置信,晚上看到已经快500分钟了…)
- 这个周末要最后挣扎一下了,这几天跟yy交流了一下那篇CNN预测块雅可比预条件子的代码实现还是有所得的,不至于肚子里倒不出墨水。
- 晚上操场又封,不知道搞什么飞机。
我找到了之前SVD training的问题,是因为没有做剪枝,这个感觉实现起来不是那么容易,但是现在的情况是即便不剪枝,效果也不太行,剪了肯定更不行,而且具体要怎么在训练中剪枝,还不是很能透析,头疼,得动动脑子了。
I get. 我知道怎么做了。
06-27
- 黄昏是我一天中状态最好的时候。我又是否算见到过真实的样子呢?总之别做让自己后悔的事情罢。
- 下午睡到昏天黑地,这几天莫名其妙晚上睡不着,乱我心者,皆称烦忧,又下不了决心再去拉黑。起来两个芒果补热量,进场破了1km的pb,3分28秒,完成了跑进3分半的夙愿。真的很感慨,从小体育无能,初中体测1km跑了4分50秒,本科6次体测最快的一次也就4分08秒。
- 碰到一个妈妈带着她5岁的儿子,跑了17圈,他妈妈说这孩子在家里搞得一团糟,出来让他跑到没力气,回去就不闹了。羡慕这种从小就热爱跑步的人,以后我要是也有个儿子,我每周一定抽空带他去跑步,人活着需要有信仰,否则跟机器有何区别?
- 开始动笔写report,实验该做的都做完了,现在的问题就是做的东西稍微有点零散,最后得找个主题把我和李浩做的给连结起来。
pdflatex+bibtex+pdflatex如果编译不通的话,试试xelatex+bibtex+xelatex,明明我之前都没问题的,过了一个月就编译不通了?
后来想办法测试了剪枝,目前是直接定的SVD的秩数,发现即便定到个位数的水平,还是比原模型ResNet18要慢,差不多是要双倍的时间,真的是醉了,算下来明明模型参数少了好多,怎么还能更慢呢?
还有一种策略是每隔若干轮后对模型剪枝,这在实现上要动点脑子,但是应该不难,只是这样应该只会更慢吧…
P
y
T
o
r
c
h
\rm PyTorch
PyTorch中统计模型参数(可以手动统计,也可以调包torchsummary),以及统计模型的每秒浮点数运算次数(FLOPs)值的方法:
# 计算深度模型的FLOPs
def evaluate_flops(model, input):
from thop import clever_format, profile
flops, params = profile(model, inputs=(input, ))
print(flops)
print(params)
print('-' * 64)
flops, params = clever_format([flops, params], "%.3f")
print(flops)
print(params)
# 计算模型的参数数量
def count_params(model):
# 定义总参数量、可训练参数量及非可训练参数量变量
Total_params = 0
Trainable_params = 0
NonTrainable_params = 0
# 遍历model.parameters()返回的全局参数列表
for param in model.parameters():
mulValue = np.prod(param.size()) # 使用numpy prod接口计算参数数组所有元素之积
Total_params += mulValue # 总参数量
if param.requires_grad:
Trainable_params += mulValue # 可训练参数量
else:
NonTrainable_params += mulValue # 非可训练参数量
print(f'Total params: {Total_params}')
print(f'Trainable params: {Trainable_params}')
print(f'Non-trainable params: {NonTrainable_params}')
# 模型总结
def torch_summary(model, ch, h, w):
pip install torchsummary
from torchsummary import summary
summary(model, input_size=(ch, h, w), batch_size=-1)
06-28
- 又是在食堂碰到一次,欲言又止,就看着人急着下楼去全家了。
- 计量也挣扎回来了,91分,还不错,这确是意料之外,毕竟课上从没答对过问题,平时分拉胯,期中也只有89。也许最后期末写满四张纸真的感动到周建老师了哈哈。不过周建为人确实很好,颇有大师风骨,又完全看不出大师架子(亲和力MAX)。
- 一天助管下来很累,五点后跑了5圈就不行了(TMD跑了五圈书包都给保安大哥没收了)。以后如果真的是996,很难每天维持一定强度的锻炼,因为工作完全会剥夺所有的精力。如果人从小到大一辈子都是在被逼着走,实在是太悲哀了,无可避免的话,那我宁可选择平庸。
- 明早九点是邓琪汇报的ddl,晚上得挑灯夜战了,思路还是比较清晰的,就是要控制一下时间,天佑。
- 某人最近又受啥刺激了… 发些莫名其妙的话。
最后理清了SVD training的所有思路,本质上其实就是先分解,再剪枝,这看起来很抽象,简单的说,对于一个 Linear ( m , n ) \text{Linear}(m,n) Linear(m,n)层,不算 b i a s \rm bias bias的话,一共是 m × n m\times n m×n个参数,现在相当于是把它分解成了 Linear ( m , r ) \text{Linear}(m,r) Linear(m,r)和 Linear ( r , n ) \text{Linear}(r,n) Linear(r,n)两个层(如果看作是 W = U D V ⊤ W=UDV^\top W=UDV⊤的分解,则前一个层 W 1 = U D W_1=U\sqrt{D} W1=UD,后一个层就是 W 2 = D V ⊤ W_2=\sqrt{D}V^\top W2=DV⊤,当然说到这里其实可能有其他分解的形式,至少 S V D \rm SVD SVD目前最浅显),这样的话参数数量就从 m n mn mn变成了 m r + r n = r ( m + n ) mr+rn=r(m+n) mr+rn=r(m+n),如果是满秩分解,那么 r = min ( m , n ) r=\min(m,n) r=min(m,n),则参数数量没有减少,反而增多,但是我们可以通过剪枝把 r r r变得很小,那么就可以得到远小于 m n mn mn的参数量。
其实看起来还是很浅然的,都不需要做别的事情,但是其实因为选择了 S V D \rm SVD SVD,所以 U , D U,D U,D需要满足正交矩阵的条件,强制要求正交是很难的,所以需要添加一些正则项来控制 U , D U,D U,D的正交程度,一般可以通过 ∥ U ⊤ U − I ∥ F \|U^\top U-I\|_F ∥U⊤U−I∥F作为惩罚项,如果 U U U是正交的,那么显然惩罚项为零。至于为什么选择 F F F范数,因为算起来简单,求导容易,反向传播方便。
其实笔者做了一些测试,发现SVD training并不比原模型快,以为是 r r r取得太大,后来发现是因为损失函数太难算所以很慢,去掉损失函数里的正则项一下子就变快了,真的是醉了,可能需要一些运算上技巧,按道理算 F F F范数确实计算量有点大,但是比普通的矩阵二范数肯定是容易多了。
06-29
- 凌晨肝到将近两点搞完report和pptslide,早上自信给邓琪汇报,尚可,邓琪灵魂拷问为什么李浩跟我不分下来做,明明都做了很多工作,合在一起根本讲不完,我就纳闷了,明明你布置大作业的时候说要做得有深度一些,别做无聊的事情,现在李浩和我既做了理论证明,又搞定实现上的工作,你又嫌长,真TM难伺候。无妨,report写得够很详实了。
- 这学期彻底结束,曹某人又有何作为?可惜今天又闷又热,但是我还是想要赶在上半年最后两天再试一次20km的,下午补觉回状态,晚上拼拼看了。
- 唉,困到死午觉还睡不着,头疼,最近思想有问题。
- 晚上太扫兴了,八点临时被导师叫去办事,九点多才放人,20km计划泡汤,最后跑了3组2km的间歇,第一组均配3’59",第二组均配4’08"(这组是裸奔狂带着跑的),第三组均配4’24",间隔休息150秒,算是近期强度比较高的一次间歇训练。明天看情况吧,状态不行就不勉强自己了。
今天汇报时跟邓琪探讨了SVD training的细节(论文摘要和代码实现),刚好他对这篇paper比较熟悉。我提到说其实SVD training并不会加快训练速度,这似乎很反常识,直觉上降秩的模型应该会更快,但是其实如果选择满秩训练,则参数将会由 m n mn mn变为 r ( m + n + 1 ) r(m+n+1) r(m+n+1),其中 r = min { m , n } r=\min\{m,n\} r=min{m,n},显然参数量变多了,自然会慢。而且就本人的实际测试结果来看,损失函数里计算正则项的时间是不容忽视的,甚至会占到60%以上的训练时间,当然这有可能是因为实现的不太好导致算的太慢。
值得一提的是邓琪指出,SVD training的侧重点是加快了模型预测的速度,或者说是模型部署的速度。我提出一种可能的改进手段,因为如果选择满秩训练真的是太慢了,所以可以借鉴学习率(learning rate)的weight decay方法,我们隔一段时间手动对模型的秩进行降低(通过对奇异值向量剪枝即可),这个的难度在于如何代码实现,因为直觉上如果隔若干epoch后人工调整模型中权重参数的形状,是否是一件不太容易实现的事情?本质上似乎是要重新构建一个新的模型,然后把参数全部记录进去才行。可能需要实际尝试一下才能有定论。
总之很可惜今天邓琪时间给的太少,其实我还有很多其他想法想要分享,包括之前看的哪个spconv包,这些确实是比较有趣的理论性内容,值得深究,比瞎几把调参有趣多了。
06-30
- 浑身酸痛,看来昨天的间歇还是太累。骑车左膝下面髌骨突然疼了一会儿,有点后怕,恐怕是没有机会再试一次半马了。只能晚上去跟ITCS的朋友玩会儿飞盘了。六月总跑量130多km,跟五月差不多的量,虽然很不情愿,但可能又要进一段休整期了。
- 批改本科生的期末卷子,本来老师说前面客观题都是送分的,现在看起来只有后面的程序题才是能送分的。客观题错了就是错了,都没有调和的余地,一堆人全错,只能给零分,救都救不了。程序题只要你写了东西总归可以友情给点儿分[Facepalm]
- 又是突然就多了100多分钟的运动时长,好厉害,之前我还想S续了一年多的会员怎么突然就不练了,原来是在憋大招呢。
- 晚上还是很想跑的,10km后浑身乏力。有点像发烧的那种乏力感,但是显然没有生病。精神状态特别差最近,有点想回家了养好身体再回来了。
添加正交正则项和稀疏导出正则项的交叉熵损失:
# -*- coding: utf-8 -*-
# @author: caoyang
# @email: caoyang@163.sufe.edu.cn
import torch
from torch.nn import functional as F
class CrossEntropyLossSVD(torch.nn.CrossEntropyLoss):
def __init__(self, weight=None, size_average=None, ignore_index=-100, reduce=None, reduction='mean'):
super(CrossEntropyLossSVD, self).__init__(
weight=weight,
size_average=size_average,
ignore_index=ignore_index,
reduce=reduce,
reduction=reduction,
)
def forward(self, input, target, model=None, regularizer_weights=[1, 1], orthogonal_suffix='svd_weight_matrix', sparse_suffix='svd_weight_vector', mode='lh') -> torch.FloatTensor:
cross_entropy_loss = F.cross_entropy(input, target, weight=self.weight, ignore_index=self.ignore_index, reduction=self.reduction)
if model is None:
return cross_entropy_loss
# 正交正则器
def _orthogonality_regularizer(x): # x应当是一个2D张量(矩阵)且高大于宽
return torch.norm(torch.mm(x.t(), x) - torch.eye(x.shape[1]).cuda(), p='fro') / x.shape[1] / x.shape[1]
# 稀疏导出正则器
def _sparsity_inducing_regularizer(x, mode='lh'): # x应当是一个1D张量(向量)
mode = mode.lower()
if mode == 'lh':
return torch.norm(x, 1) / torch.norm(x, 2)
elif model == 'l1':
return torch.norm(x, 1)
raise Exception(f'Unknown mode: {mode}')
regularizer = torch.zeros(1, ).cuda()
for name, parameter in model.named_parameters():
lastname = name.split('.')[-1]
if lastname.startswith(orthogonal_suffix): # 奇异向量矩阵参数:添加正交正则项
regularizer += _orthogonality_regularizer(parameter) * regularizer_weights[0]
elif lastname.startswith(sparse_suffix): # 奇异值向量参数:添加稀疏导出正则项
regularizer += _sparsity_inducing_regularizer(parameter, mode) * regularizer_weights[1]
return cross_entropy_loss + regularizer
July 2021
07-01
- 六月总跑量140km,昨晚强行起跑的后果就是连右膝一起废了。自从寒假伤痛之后再没有伤成这样过,真的是贱骨头,一点记性都不长。接下来开始做些自重(正好体重掉了很多,说不定能拉得上引体),核心练稳,才能维持住高配速跑姿。晚上可能还是会去玩一下飞盘,昨天好多叉院的博士也慕名来玩,渐渐就热闹起来了。
- 缺觉极致疲乏,终于是睡了一个美美的午觉,要不是外面突然军训喊口号,我觉得能一觉睡到傍晚… 状态总算恢复,膝盖还是伤。
- 好久不去新园,结果晚饭去吃又碰见一次,应该是从图书馆过来的。自己是否还会有感觉?罢了。
- 在GitHub上开了个项目,计划深入svdtraining,在更多其他主流模型上的进行测试,包括对一些稀疏运算的研究,我觉得与其盲目建模,不如深耕一些理论性的内容,也许wyl并不能指导我这些内容,不过也不需要人来教我做事。
看看facebook的sparseconvnet里的池化是怎么写的:
其实我有点好奇,就是目前大部分的稀疏DNN模块都是写的CNN,为什么没有人去做RNN的稀疏改进呢,我RNN不要面子的吗?
class AveragePooling(Module):
"""
Average Pooling for SparseConvNetTensors.
Parameters:
dimension i.e. 3
pool_size i.e. 3 or [3,3,3]
pool_stride i.e. 2 or [2,2,2]
"""
def __init__(self, dimension, pool_size, pool_stride, nFeaturesToDrop=0):
super(AveragePooling, self).__init__()
self.dimension = dimension
self.pool_size = toLongTensor(dimension, pool_size)
self.pool_stride = toLongTensor(dimension, pool_stride)
self.nFeaturesToDrop = nFeaturesToDrop
def forward(self, input):
output = SparseConvNetTensor()
output.metadata = input.metadata
output.spatial_size = (
input.spatial_size - self.pool_size) // self.pool_stride + 1
assert ((output.spatial_size - 1) * self.pool_stride +
self.pool_size == input.spatial_size).all()
output.features = AveragePoolingFunction.apply(
input.features,
input.metadata,
input.spatial_size,
output.spatial_size,
self.dimension,
self.pool_size,
self.pool_stride,
self.nFeaturesToDrop)
return output
def input_spatial_size(self, out_size):
return (out_size - 1) * self.pool_stride + self.pool_size
def __repr__(self):
s = 'AveragePooling'
if self.pool_size.max().item() == self.pool_size.min().item() and\
self.pool_stride.max().item() == self.pool_stride.min().item():
s = s + str(self.pool_size[0].item()) + \
'/' + str(self.pool_stride[0].item())
else:
s = s + '(' + str(self.pool_size[0].item())
for i in self.pool_size[1:]:
s = s + ',' + str(i.item())
s = s + ')/(' + str(self.pool_stride[0].item())
for i in self.pool_stride[1:]:
s = s + ',' + str(i.item())
s = s + ')'
if self.nFeaturesToDrop > 0:
s = s + ' nFeaturesToDrop = ' + self.nFeaturesToDrop
return s
07-02
- 钱逢胜之后又一个极品,查了一下本科不是本校的,稍微宽慰了一些。林子大了什么鸟都有,永远别把学校拿来说事,看看你能为学校做出过什么贡献,不是拿着学校的名头出去坑蒙拐骗,自己几斤几两心里要有数。
- 昨晚玩完飞盘感觉又满血复活了,连续的抢断长传,满场跑完全感觉不到累,总归是件幸事。
- 鬼天气,早上醒得早索性去图书馆待了一天。午休深睡,梦醒浑身无力,状态恢复了八九成,奈何外头像蒸馒头似的,暴雨、然后高温蒸煮,以此往复,闷得人透不过气。但愿暑假回家前能找到机会练次半马,这是醉后的倔强。
- 想就这么朝九晚十闭关两个月做出点东西来,可惜不愿放弃跑步,学习或许已非一切,可若抛弃,恐怕就一无是处了。
今天学会了些东西,很满足。但不想写太多,给之后写博客留点素材,总之深入研究了一下 PyTorch \text{PyTorch} PyTorch里的损失函数和优化器的一些进阶性的用法,主要在优化svdtraining的代码时遇到一些问题。
提一个比较小的问题,最近旧机上的jupyter突然不可用,装的Anaconda自带jupyter,应该是不会有问题的。无奈只能去重装了一遍:
pip install jupyter notebook -i https://pypi.tuna.tsinghua.edu.cn/simple
但是发生报错:
Cannot uninstall 'terminado'. It is a distutils installed project and thus we cannot accurately determine which files belong to it which would lead to only a partial uninstall.
其实这个报错目前网上还真没有人给出正确的解决方案,我试了别人提供的解决方案都是不可行的(加--user参数?)。这个问题的本质是因为site-packages里的安装信息与其他包发生冲突,导致pip不知道如何正确卸载terminado包。
好在之前碰到过类似的问题,我记不清具体是卸载哪个包了,好像是Anaconda自带的一个原装包,然后其实只要在pip命令上添加参数----ignore-installed即可:
pip install terminado --upgrade --ignore-installed -i https://pypi.tuna.tsinghua.edu.cn/simple
07-03
- 练一次半马就回扬州,想留下点什么再走,总不能全是遗憾。
- 一段很长的悲伤过去了么?这怕不是又动情了。
- 下午雷暴,总算消些暑气。屯香蕉和巧克力,今日休整早睡,计划明早五点开练半马,天佑能够成功。
第一版挂到GitHub@svdtraining,有点奇怪,这次我改写的是torchvision.models.resnet里的源码,之前别人写的ResNets18好像比torchvision里自带的源码要快好多,不知道是不是实现上有区别。目前遇到的一个非常困难的点,就是如何在训练过程中手动去修改模型参数,简单地说我想手动在训练过程中对模型剪枝,看似很容易,但是实现起来好像真的很复杂,如果直接改模型里的参数,这就意味着要把模型里每个层的参数都改一遍,这个其实是很麻烦的事情,而且改完之后我发现再训练它就不变了,即便我设置了require_grad=true,还有一种思路就是重写一个ResNets类,然后里面所有层的权重参数的初始化都要重写(因为要换成已经训练好的参数),总之就是很复杂,甚至都不能很好地表述清楚我想说什么… 算了,等我搞完再说了。
07-04
- 早5:45起,面包+香蕉+燕麦+奶粉+士力架,五神装6:45起跑,结果先是极闷,10圈后实在太难受脱掉上衣,20圈又被保安大哥勒令穿回去(TMD裸奔狂天天晚上跑,操场那么多人都不管,我赶个大早路上都没几个人,真就针对呗), 25圈结束开始下大雨,27圈右腹岔气,硬撑了1圈只得退场。最终是53分整完成11.30km,其实10圈之后慢慢状态已经起来了,后程基本已经可以维持得住4’40"以内的配速(主要有一个水平相仿的大爷跟我一起跑,比较激励),只能说天时不利,遗憾透顶。
- 姨父被下病危通知,罹患肺癌已经十个月,如果真的出事,妈妈也得过来。服役的表哥今天紧急赶回,对我来说这可能是第一个即将要离世的父辈近亲,虽然也不算特别亲近(其实儿子跟父亲一般倒不是太亲近,但是真的失去父亲一定还是会特别难受,而且这对妈妈也是很大的打击),但是也很感慨,毕竟表哥的年纪与我只差了八天,转眼我们这一辈也不再年轻。
- 晚上探病,午睡至三点,睡到昏天黑地,整个人都快睡死了。想以后就每天晨跑5km,难度也不大,这样就可以在图书馆待一整天不用出来了,就是一天得洗两次澡,又怕早上起不来,回家后倒可以试试。总之受天气影响,最近长距离水平明显掉了很多,要尽快调整起来,至于半马练习,一定会再试,直到能够成功在最恶劣的天气。
- 这几天总是能在新食堂或者图书馆遇见某些人,可是我也不太想去实验室或者院楼,天气闷热在寝室也待不住,也便就这么过罢,心态放正。
最终我实现了隔一段epoch对模型进行SVD剪枝的操作,其实也不太难,就是需要多测试几种写法,因为torch的loss和optimizer其实功能是很强大的,执行逻辑跟想象的有区别(PS:GitHub真香,我要另辟战场)
# -*- coding: utf-8 -*-
# @author : caoyang
# @email: caoyang@163.sufe.edu.cn
if __name__ == '__main__':
import sys
sys.path.append('../')
import time
import torch
import logging
from torch import nn
from torch import optim
from torch.nn import functional as F
from torchvision.models import resnet
from config import ModelConfig
from src.data import load_cifar
from src.models import svd_resnet
from src.svd_loss import CrossEntropyLossSVD
from src.svd_layer import Conv2dSVD, LinearSVD
from src.utils import summary_detail, initialize_logging, load_args, svd_layer_prune
def train(args):
if __name__ == '__main__':
ckpt_root = '../ckpt/' # model checkpoint path
logging_root = '../logging/' # logging saving path
data_root = '../data/' # dataset saving path
else:
ckpt_root = 'ckpt/' # model checkpoint path
logging_root = 'logging/' # logging saving path
data_root = 'data/' # dataset saving path
# Load model
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
model, model_name = svd_resnet.resnet18()
model = model.to(device)
# Initialize logging
initialize_logging(filename=f'{logging_root}{model_name}.log', filemode='w')
# Group model parameters
orthogonal_params = []
sparse_params = []
for name, parameter in model.named_parameters():
lastname = name.split('.')[-1]
if lastname == 'left_singular_matrix' or lastname == 'right_singular_matrix':
orthogonal_params.append(parameter)
elif lastname == 'singular_value_vector':
sparse_params.append(parameter)
# Group modules
svd_module_names = []
svd_module_expressions = []
for name, modules in model.named_modules():
if isinstance(modules, Conv2dSVD) or isinstance(modules, LinearSVD):
svd_module_names.append(name)
expression = 'model'
for character in name.split('.'):
if character.isdigit():
expression += f'[{character}]'
else:
expression += f'.{character}'
svd_module_expressions.append(expression)
# Define loss function and optimizer
loss = CrossEntropyLossSVD()
optimizer = optim.SGD(model.parameters(), lr=args.learning_rate, momentum=args.momentum, weight_decay=args.weight_decay)
optimizer = optim.SGD([{'params': orthogonal_params, 'lr': args.orthogonal_learning_rate, 'momentum': args.orthogonal_momentum, 'weight_decay': args.orthogonal_weight_decay},
{'params': sparse_params, 'lr': args.sparse_learning_rate, 'momentum': args.sparse_momentum, 'weight_decay': args.sparse_weight_decay}],
lr=args.learning_rate,
momentum=args.momentum,
weight_decay=args.weight_decay)
# Load dataset
trainloader, testloader = load_cifar(root=data_root, download=False, batch_size=args.batch_size)
num_batches = len(trainloader)
if args.summary:
for i, data in enumerate(trainloader, 0):
input_size = data[0].shape
summary_detail(model, input_size=input_size)
break
for epoch in range(args.max_epoch):
# Train
epoch_start_time = time.time()
model.train()
total_losses = 0.
correct_count = 0
total_count = 0
for i, data in enumerate(trainloader, 0):
X_train, y_train = data[0].to(device), data[1].to(device)
optimizer.zero_grad()
y_prob = model(X_train)
loss_value = loss(y_prob, y_train, orthogonal_params, sparse_params)
loss_value.backward()
optimizer.step()
total_losses += loss_value.item()
_, y_pred = torch.max(y_prob.data, 1)
total_count += y_train.size(0)
correct_count += (y_pred == y_train).sum()
train_accuracy = 100. * correct_count / total_count
logging.debug('[Epoch:%d, Iteration:%d] Loss: %.03f | Train accuarcy: %.3f%%' % (epoch + 1,
i + 1 + epoch * num_batches,
total_losses / (i + 1), train_accuracy))
epoch_end_time = time.time()
# Prune
if args.svd_prune and ((epoch + 1) % args.svd_prune_cycle == 0):
for expression in svd_module_expressions:
svd_layer_prune(eval(expression), threshold=args.svd_prune_threshold, reduce_by=args.svd_prune_decay, min_rank=args.svd_prune_min_rank)
# Test
logging.info('Waiting Test ...')
model.eval()
with torch.no_grad():
correct_count = 0
total_count = 0
for data in testloader:
X_test, y_test = data[0].to(device), data[1].to(device)
y_prob = model(X_test)
_, y_pred = torch.max(y_prob.data, 1)
total_count = y_test.size(0)
correct_count += (y_pred == y_test).sum()
test_accuracy = 100. * correct_count / total_count
logging.info('EPOCH=%03d | Accuracy= %.3f%%, Time=%.3f' % (epoch + 1, test_accuracy, epoch_end_time - epoch_start_time))
# Save model to checkpoints
if (epoch + 1) % args.ckpt_cycle == 0:
logging.info('Saving model ...')
torch.save(model.state_dict(), ckpt_root + model_name + '_%03d.pth' % (epoch + 1))
if __name__ == '__main__':
args = load_args(ModelConfig)
train(args)
07-05
- 昨晚回程被个地痞追了一路,实话说很喜欢这种竞逐的刺激,虽然是有些危险,难得享受一下,无碍,毕竟在围墙内憋太久了。以后有机会可以试试长距离的公路车骑行,感觉以现在的耐力应该能坚持得到百八十公里。
- 新生军训今晚在操场联欢,教官和学生轮流着在表演节目,十分欢快。当然我也并没什么不高兴的事,只是有些不相通罢了。晚饭又在食堂看到,话说我还真有够脸盲,扎了辫子就认不出来了,还是看到手环才能确认,话说真的是吃了好久…
- 晚31℃,按4’05"的均配去练了5圈+3圈的间歇,心率爆炸,很难在这种天气坚持很久,夏天彻底来了。等新生军训完再抽个清晨去试一次半马,还是很固执唉,真是一点没变。
这两天进度稍缓,但是也算是更新了很多内容。其实很想把这几天做得事情写成博客,但是感觉内容特别多,而且条理有些混乱,自己又不是那么空闲,看情况吧,有兴致就写点东西,可能真的是年纪越大,做事越没激情了。年轻真好呵(开始练自重,菜得真实,俯卧撑都做不来,果然自重跟体重一点关系都没有,菜就是菜)。
提一个比较小的问题,
P
y
T
o
r
c
h
\rm PyTorch
PyTorch中我们要导出argparser中的参数时,可以用json导出,具体像这个样子:
import json
import time
import argparser
def load_args(Config):
config = Config()
parser = config.parser
return parser.parse_args()
def save_args(args, save_path=None):
if save_path is None:
save_path = f'../logging/config_{time.strftime("%Y%m%d%H%M%S")}.json'
with open(save_path, 'w') as f:
f.write(json.dumps(vars(args)))
比如需要保存的Config参数是ModelConfig像这样的配置类:
# -*- coding: utf-8 -*-
# @author : caoyang
# @email: caoyang@163.sufe.edu.cn
import argparse
from torch import optim
class ModelConfig:
parser = argparse.ArgumentParser("--")
parser.add_argument('--summary', default=True, type=bool)
parser.add_argument('--ckpt_cycle', default=4, type=int)
parser.add_argument('--max_epoch', default=128, type=int)
parser.add_argument('--batch_size', default=16, type=int)
parser.add_argument('--learning_rate', default=1e-2, type=float)
parser.add_argument('--orthogonal_regularizer_weight', default=1., type=float)
parser.add_argument('--sparsity_regularizer_weight', default=1., type=float)
parser.add_argument('--orthogonal_learning_rate', default=1e-3, type=float)
parser.add_argument('--sparsity_learning_rate', default=1e-3, type=float)
parser.add_argument('--momentum', default=.9, type=float)
parser.add_argument('--orthogonal_momentum', default=.9, type=float)
parser.add_argument('--sparsity_momentum', default=.9, type=float)
parser.add_argument('--weight_decay', default=0., type=float)
parser.add_argument('--orthogonal_weight_decay', default=0., type=float)
parser.add_argument('--sparsity_weight_decay', default=0., type=float)
parser.add_argument('--optimizer', default=optim.SGD, type=type)
parser.add_argument('--svd_prune', default=True, type=bool)
parser.add_argument('--svd_prune_cycle', default=4, type=int)
parser.add_argument('--svd_prune_rank_each_time', default=2, type=float)
parser.add_argument('--svd_prune_threshold', default=None, type=float)
parser.add_argument('--svd_prune_decay', default=None, type=float)
parser.add_argument('--svd_prune_min_rank', default=4, type=int)
parser.add_argument('--svd_prune_min_decay', default=.1, type=int)
if __name__ == "__main__":
config= ModelConfig()
parser = config.parser
args= parser.parse_args()
但是你会发现是无法导出为json的,因为配置类中有一个无法序列化的参数:
parser.add_argument('--optimizer', default=optim.SGD, type=type)
那么此时就需要自定义序列化方式,我们修改save_args函数如下所示即可:
def save_args(args, save_path=None):
class _MyEncoder(json.JSONEncoder):
def default(self, obj):
if isinstance(obj, type):
return str(obj)
return json.JSONEncoder.default(self, obj)
if save_path is None:
save_path = f'../logging/config_{time.strftime("%Y%m%d%H%M%S")}.json'
with open(save_path, 'w') as f:
f.write(json.dumps(vars(args), cls=_MyEncoder))
07-06
- 到晚才更,一个原因是白天啥事都没有,闭关把最近的工作整理成文【项目总结】SVD Training(终焉),个人觉得算是近期比较满意的一篇博客,最后写些后记缓释一下心情。接下来重启其他工作,SVD training告一段落。
- 可能是写完博客比较满足,状态还不错,进场冲3km,追平pb(12’04"),上一个3km的pb是在20℃的阴天跑的,今天最高气温35℃,算是非常不错的进步,而且难得被裸奔狂跟了一圈半。2km用时8’08",以为稳破4km的pb(16’56"),但是6圈后感觉不如提速冲击一下3km12分的梦想,结果还是差了几秒,感觉血亏。下一个好状态何时能来?
- 后来休息了5分钟又冲了一个1km,跑完喝水到反胃,难受了将近半个小时,楼梯都爬不动,以前跑20km都没这么难受过,天热还是伤。
- 老妈天天催我回去,唉,或许回去也是一个不错的选择罢,只是可能就再也没有机会了(啪!你以为留下来就会有机会了?——人总是要有梦想的嘛~)
python的日志初始化:
def initialize_logging(filename, filemode='w'):
logging.basicConfig(
level=logging.DEBUG,
format='%(asctime)s | %(filename)s | %(levelname)s | %(message)s',
datefmt='%Y-%m-%d %H:%M:%S',
filename=filename,
filemode=filemode,
)
console = logging.StreamHandler()
console.setLevel(logging.DEBUG)
formatter = logging.Formatter('%(asctime)s | %(filename)s | %(levelname)s | %(message)s')
console.setFormatter(formatter)
logging.getLogger().addHandler(console)
07-07
- EMNLP2020上找了几十篇跟逻辑推理相关的paper,准备做一个论文合集整理,总归还是要回到wyl门下,感觉推理可以作为一个长久的课题。
- 看了半天强化学习,很久不做原理都忘了,然后意外发现一个做物理引擎和机器人的包pybullet,不过好像比较难装,看起来会很有趣。
- 晚上暴雨,进程赤膊跑了10km,真TMD爽,要是穿着衣服肯定湿透难受地不得了,赤膊上阵,雨下得越大跑得越舒服,那种全场只有自己一个人,极好的状态下在暴雨中狂奔的快感,真的是无法用言语表达。只可惜最后两双鞋灌水湿透,步伐节奏全乱了,要不然至少感觉30圈是可以坚持得到的。
- 今晚本意仍是冲半马,但就近日的情况来看,夏天要零补给地跑完一次半马,难度非常大,今晚【暴雨清凉 + 状态高昂】,天时地利人和占尽,还是失败。接下来操场只在17:00-22:00开放,赶早起跑不再可能。军训结束后,食堂很快就要大面积关闭,连伙食都得不到保障。还是趁早回家算了,只是那路线主任… 下学期再来争罢,反正我还要待至少四年,毕业前早晚成为田径场上的一个传说[笑]。
- 我现在才意识到党妹好像是个B站UP,之前看到还以为是那个叫呆妹的主播… 反正每年百大UP总有几个要出事,之前那个叫啥槐安遗梦的,不过也秽土转生了。今年LEXBURNER也暴毙,到现在都没复活;回形针纯属内鬼,立场不同就不谈了。所以说像泛式、散人、毕导这些高学历出身的UP,总归三观要正得多,虽说人红是非多,但是最起码的底线得有,娱乐性质的UP还是少点为好,奶嘴太多的环境,早晚会出事的。
关于WIN10上pybullet的安装,一般需要跟gym库一起装,我是选择先装gym包,这个一般直接用pip安装就可以,不会有什么问题。
但是pybullet的安装确实比较麻烦,pip带清华镜像总是提示没有兼容的包,不带镜像这个包太大也很难下得完,其实直接去https://pypi.tuna.tsinghua.edu.cn/simple/pybullet/里找最新的(目前是pybullet-3.1.7.tar.gz)即可。
然后可以手动安装这把tar.gz包,解压后分别执行
python setup.py build
python setup.py install
即可。但是如果没有VS环境会报错
error: Microsoft Visual C++ 14.0 is required.
这个问题遇到过无数次,但是自己一直懒得装VS。安装VS可参考https://zhuanlan.zhihu.com/p/165008313,主要很多前人提供的安装包都有损坏,还是要去官网拿最新的VS2019社区版(免费),然后按照链接里的教程勾选几个扩展即可,还是比较便捷的。
在旧机上装好pybullet可用,接下来边读paper,边做些有意思的事情吧,上手了再在新机上做,要真有趣就买个带物理引擎的机器人回来捣鼓捣鼓,感觉pybullet是个有趣的玩意儿,可惜跟我的方向不太搭。唉,我还是应该去读个工科。
07-08
- 武东田径场和篮球场翻新,从本月10日到开学,似乎已经没有理由留下了,唉,终究还是如此遗憾的结束了,各种意义上。
- 早上发现图书馆四五楼的台灯区都封闭了,五楼空间又满座,不知道从哪儿冒出这么多人来。只得回院里开个空房间呆上半天。三点雷雨大作,似乎将要下到午夜,又是沉郁的一天。
- 裸奔一时爽,一直裸奔一直爽。可惜今晚状态很差,5km报销。明天是田径场开放的最后一天,估摸着冲上半马的机会渺茫,整个跑步历史上从未连续两天跑过10km以上的距离(跑步机除外),这几天身体感觉已经完全耗尽,而且食堂是越来越吃不下去。
- 回家吧cy,别在这挣扎了,不会有什么结果,而且,你也不会去主动争取些什么,不是么?
- 悉实而慎论,还是少些戾气为好。片弟这次撞上枪口,连陈睿也受波及,有心人总是要搞些噱头带带节奏,不过就目前的情况看B站公关做得还行,没搞出什么爆炸热搜。讥笑别人为富不仁,又有多少人能追逐最初的梦想呢?也许会有吧,但可能大都已经被洪水猛兽所吞噬了,屠龙勇士终成恶魔,就是如今社会的悲剧。
抄了一段pybullet的Helloworld脚本,没怎么看懂,但是好有意思啊,这玩意儿其实是做机器人的强化学习的,所以现在改行学做自动驾驶还来得及嘛~
# -*- coding: utf-8 -*-
# @author: caoyang
# @email: caoyang@163.sufe.edu.cn
import pybullet as p
from time import sleep
physicsClient = p.connect(p.GUI)
p.setGravity(0, 0, -10)
planeId = p.loadURDF("plane.urdf")
cubeStartPos = [0, 0, 1]
cubeStartOrientation = p.getQuaternionFromEuler([0, 0, 0])
boxId = p.loadURDF("r2d2.urdf", cubeStartPos, cubeStartOrientation)
cubePos, cubeOrn = p.getBasePositionAndOrientation(boxId)
useRealTimeSimulation = 0
if (useRealTimeSimulation):
p.setRealTimeSimulation(1)
while 1:
print(useRealTimeSimulation)
if (useRealTimeSimulation):
p.setGravity(0, 0, -10)
sleep(0.01) # Time in seconds.
else:
p.stepSimulation()
07-09
- 有点难受,就在眼前,还是犹豫了要不要前去吃饭聊一会儿,总觉得还是太唐突了。真实的无力。
- 看了一篇关于多级推理的文,很有趣,居然还用到了最大流的整数规划,真是强行高端,不过确实值得借鉴,计划读个十来篇做个合集,前几篇先详读,后面开始略读,主要还有代码要一起看,精读论文真的很麻烦。
- 晚上强行冲半马。至少在跑步上还不想留下遗憾。第一个10km用时45分13秒,休息15分钟开始第二段10km,这可能是我一年半来最艰辛的一次跑步了,38圈结束小腿已经完全软了;45圈结束心肺大腿全部到极限,完全迈不开步子;19km看到胡总和林总来跑,我已经完全没有力气再跟他们打招呼了,20km结束,一共喝光四瓶水,最终20km用时1小时32分半,虽然比5月17日的要快上不少,但是由于还是分段,不过天气也要热得多,所以勉强算是半斤八两。明日操场翻新,这就是我的最后之作了,下学期来时,希望自己能够脱胎换骨,在各种层面上。
推一篇多级推理的文,个人觉得比较有创新,看得差不多了,但是不准备更新,屯点货,发个长文。
论文标题:PRover: Proof Generation for Interpretable Reasoning over Rules
中文标题:证明器:通过在规则上进行可解释的推理生成证明过程
论文下载地址: 2020.emnlp-main.9 \text{2020.emnlp-main.9} 2020.emnlp-main.9
论文引用:
@inproceedings{saha2020prover, title={{PR}over: Proof Generation for Interpretable Reasoning over Rules}, author={Saha, Swarnadeep and Ghosh, Sayan and Srivastava, Shashank and Bansal, Mohit}, booktitle={EMNLP}, year={2020} }
07-10
- 壹夜
关于自然语言推断中的证明表示:
证明(proof)
P
=
(
N
,
E
)
\mathcal{P}=(\mathcal{N},\mathcal{E})
P=(N,E)是一个有向图,其中:
N
⊆
R
∪
F
∪
NAF
E
⊆
N
×
N
\begin{aligned} \mathcal{N}&\subseteq R\cup F\cup \text{NAF}\\ \mathcal{E}&\subseteq\mathcal{N}\times\mathcal{N} \end{aligned}
NE⊆R∪F∪NAF⊆N×N
具体而言:
-
每个节点 n ∈ N n\in\mathcal{N} n∈N表示以下三种对象之一:
- 一个事实 f ∈ F f\in F f∈F;
- 一条规则 r ∈ R r\in R r∈R;
- 一个特殊的负面节点(negation as failure node,下简称为 N A F \rm NAF NAF节点);
N A F \rm NAF NAF节点指代那些无法被规则集证明的陈述对立面的真实性,其实就是额外添加的一些默认条件,这在 F i g u r e 2 \rm Figure 2 Figure2中比较容易看得明白。
-
每条边 e ∈ E e\in\mathcal{E} e∈E的指向情形为以下两种之一:
- 从一个事实 f f f(或一个 N A F \rm NAF NAF节点)指向一条规则 r r r,这代表事实 f f f(或 N A F \rm NAF NAF节点)被规则 r r r所消耗(consumed);
- 从一条规则 r 1 r_1 r1指向另一条规则 r 2 r_2 r2,这代表规则 r 1 r_1 r1的输出被规则 r 2 r_2 r2所消耗(consumed);
07-11
- 贰夜
07-12
- 葬歌。
- 气急败坏,还是控制不好情绪,太幼稚了。
- 死人的事情办完之后,就是活人的事情。实话说人生走一遭真是不容易,到死也要被殡葬业榨得干干净净,遗产搞不好还要纷争,唉,真的没意思。这几天太累,好好补觉了。
今天突然有了很多有趣的idea,一个是目前看完的PRover的代码准备深究一下,笔注写完但不想发,等代码吃透再一起,主要里面一个用于解整数规划的PuLP包很值得在意。
另外我突然想做三个小游戏的强化学习测试,推箱子(莫名其妙看到了推箱子就想做,因为觉得推箱子真的很难,发现居然有人还专门开发了一个用于搞推箱子的包,tql),2048(这个是今天刷B站看到有个人做的,很有意思,他用的是蒙特卡洛模拟后三步然后取得分最高的走法,效果拔群,搞到4096不是问题),搞怪碰碰球(这个知道的人肯定很少,因为这个游戏是很老很老的,我很小的时候老妈天天在医院电脑上玩,然后科室里另一个同事特别厉害,每次都能打到一万多分,老妈菜的从几百分慢慢搞,最后也没打穿过7000分,这个游戏我还挺看重,因为它每一步的决策实在是太多了,而且带有随机性,前两个都有人做过,这个想自己设计个算法试试,主要回家精神振奋,就想搞点有的没的东西)。
07-13
- 养猪计划 v.s. 晨跑计划,晨跑5km,配速4’27",吃太撑,节奏不太稳,慢慢来吧,有几天不跑了。
- 三伏天跑步机反而比路跑要难,无风,1km多一点就湿透了。
- 2048的算法还是挺有趣的,准备在它的基础上做些有趣的事情,一个是迁移到搞怪碰碰球上,另一个是用现有的策略生成若干episode去做个强化学习看看效果如何,目前直观上的Q函数已经可以做到90%的成功率到2048了,不知道能不能学出更优的策略,总之蒙特卡洛永远嘀神。
pygame版本的2048:
# -*- coding: utf-8 -*-
# @author : caoyang
# @email: caoyang@163.sufe.edu.cn
import random
import pygame
import numpy as np
nmap = {0: 'U', 1: 'R', 2: 'D', 3: 'L'}
fmap = dict([val, key] for key, val in nmap.items())
class Button(pygame.sprite.Sprite):
def __init__(self, name, text, location, size=(100, 50)):
pygame.sprite.Sprite.__init__(self)
self.name = name
self.text = text
self.x, self.y = location
self.w, self.h = size
self.is_show = True
def is_click(self, location):
return self.is_show and self.x <= location[0] <= self.x + self.w and self.y <= location[1] <= self.y + self.h
class Grid:
size = 4
tiles = []
max_tile = 0
def __init__(self, size=4):
self.size = size
self.score = 0
self.tiles = np.zeros((size, size)).astype(np.int32)
def is_zero(self, x, y):
return self.tiles[y][x] == 0
def is_full(self):
return 0 not in self.tiles
def set_tiles(self, location, number):
self.tiles[location[1]][location[0]] = number
def get_random_location(self):
if not self.is_full():
while 1:
x, y = random.randint(0, self.size - 1), random.randint(0, self.size - 1)
if self.is_zero(x, y):
return x, y
return -1, -1
def add_tile_init(self):
self.add_random_tile()
self.add_random_tile()
def add_random_tile(self):
if not self.is_full():
value = 2 if random.random() < 0.9 else 4
self.set_tiles(self.get_random_location(), value)
def run(self, direction, is_fake=False):
if isinstance(direction, int):
direction = nmap[direction]
self.score = 0
if is_fake:
t = self.tiles.copy()
else:
t = self.tiles
if direction == 'U':
for i in range(self.size):
self.move_hl(t[:, i])
elif direction == 'D':
for i in range(self.size):
self.move_hl(t[::-1, i])
elif direction == 'L':
for i in range(self.size):
self.move_hl(t[i, :])
elif direction == 'R':
for i in range(self.size):
self.move_hl(t[i, ::-1])
return self.score
def move_hl(self, hl):
len_hl = len(hl)
for i in range(len_hl - 1):
if hl[i] == 0:
for j in range(i + 1, len_hl):
if hl[j] != 0:
hl[i] = hl[j]
hl[j] = 0
self.score += 1
break
if hl[i] == 0:
break
for j in range(i + 1, len_hl):
if hl[j] == hl[i]:
hl[i] += hl[j]
self.score += hl[j]
hl[j] = 0
break
if hl[j] != 0:
break
return hl
def is_over(self):
if not self.is_full():
return False
for y in range(self.size - 1):
for x in range(self.size - 1):
if self.tiles[y][x] == self.tiles[y][x + 1] or self.tiles[y][x] == self.tiles[y + 1][x]:
return False
return True
def is_win(self):
if self.max_tile > 0:
return self.max_tile in self.tiles
else:
return False
def __str__(self):
str_ = '====================\n'
for row in self.tiles:
str_ += '-' * (5 * self.size + 1) + '\n'
for i in row:
str_ += '|{:4d}'.format(int(i))
str_ += '|\n'
str_ += '-' * (5 * self.size + 1) + '\n'
str_ += '==================\n'
return str_
class Game:
score = 0
env = 'testing'
state = 'start'
grid = None
def __init__(self, grid_size=4, env='production'):
self.env = env
self.grid_size = grid_size
self.start()
def start(self):
self.grid = Grid(self.grid_size)
if self.env == 'production':
self.grid.add_tile_init()
self.state = 'run'
def run(self, direction):
if self.state in ['over', 'win']:
return None
if isinstance(direction, int):
direction = nmap[direction]
self.grid.run(direction)
self.score += self.grid.score
if self.grid.is_over():
self.state = 'over'
if self.grid.is_win():
self.state = 'win'
if self.env == 'production':
self.grid.add_random_tile()
return self.grid
def printf(self):
print(self.grid)
07-14
- 晨跑5km,穿了件背心,没好意思再裸奔… 均配4’32",比昨天慢一些。发现晨跑的问题就是需要一段时间进状态,一开始总是找不到节奏,3km之后才有感觉。计划养猪30天,争取做到每天晨跑5km加晚饭后跑步机3km。实话说现在体能比去年同期确实长太多了。
- 在生成2048的episode,随机策略很快,1w个差不多一分钟就好了,准备加十分之一的标准策略,五六分钟才能有一个,这个如果效果好就准备写搞搞怪了,做出来可以给老妈秀一下。
- 照这种吃法,不出半个月必过70kg,一个月后怕不再也跑不动了,这个鬼天气也跑不了长距离,供过于求了,算了,好好养一个月,既来之则安之。
2048生成episode的脚本:
# -*- coding: UTF-8 -*-
# @author: caoyang
# @email: caoyang@163.sufe.edu.cn
import os
import time
import pygame
import pandas as pd
from pygame.locals import (QUIT,
KEYDOWN,
K_ESCAPE,
K_LEFT,
K_RIGHT,
K_DOWN,
K_UP,
K_w,
K_a,
K_s,
K_d,
K_k,
K_l,
MOUSEBUTTONDOWN)
from config import GameConfig
from src.utils import load_args, save_args, draw_text
from src.game import Game, Button
from src.ai import AI
def run(args, episode_path=None):
# Initialize game
# pygame.init()
# Set window
# os.environ['SDL_VIDEO_WINDOW_POS'] = '%d,%d' % args.window_pos
# raw_screen = pygame.display.set_mode((args.window_width, args.window_height), pygame.DOUBLEBUF, 32)
# screen = raw_screen.convert_alpha()
# pygame.display.set_caption(args.window_title)
interval = args.interval
state = 'start'
# clock = pygame.time.Clock()
game = Game(args.grid_dim)
ai = AI(args)
next_direction = ''
last_time = time.time()
buttons = [
Button('start', 'Restart', (args.grid_size + 50, 150)),
Button('ai', 'Autorun', (args.grid_size + 50, 250)),
]
episode_dict = {
'action': [],
'tiles': [],
'score': [],
'reward': [],
}
while not state == 'exit':
if game.state in ['over', 'win']:
state = game.state
# Start game
if state == 'start':
game.start()
state = 'ai'
if state == 'ai' and next_direction == '':
next_direction, reward = ai.get_next(game.grid.tiles, random_strategy=args.random_strategy)
current_direction = next_direction
# Logging Episode
tiles = []
for y in range(args.grid_dim):
for x in range(args.grid_dim):
tiles.append(game.grid.tiles[y][x])
episode_dict['tiles'].append(tuple(tiles))
episode_dict['action'].append(current_direction)
episode_dict['score'].append(game.score)
episode_dict['reward'].append(reward)
# Direction
if next_direction and (state == 'run' or state == 'ai' and time.time() - last_time > interval):
game.run(next_direction)
next_direction = ''
# last_time = time.time()
# Fill background color
# screen.fill((101, 194, 148))
# Draw text
# draw_text(screen, f'Score: {game.score}', (args.grid_size + 100, 40), args.fontface)
# if state == 'ai':
# draw_text(screen, f'Interval: {interval}', (args.grid_size + 100, 60), args.fontface)
# draw_text(screen, f'Reward:{round(reward, 3)}', (args.grid_size + 100, 80), args.fontface)
# Draw button
# for button in buttons:
# if button.is_show:
# pygame.draw.rect(screen, (180, 180, 200), (button.x, button.y, button.w, button.h))
# draw_text(screen, button.text, (button.x + button.w / 2, button.y + 9), args.fontface, size=18, center='center')
# Draw map
# for y in range(args.grid_dim):
# for x in range(args.grid_dim):
# # Draw block
# number = game.grid.tiles[y][x]
# size = args.grid_size / args.grid_dim
# dx = size * 0.05
# x_size, y_size = x * size, y * size
# color = args.colors[str(int(number))] if number <= args.max_number else (0, 0, 255)
# pygame.draw.rect(screen, color, (x_size + dx, y_size + dx, size - 2 * dx, size - 2 * dx))
# color = (20, 20, 20) if number <= 4 else (255, 255, 255)
# if number:
# length = len(str(number))
# if length == 1:
# text_size = size * 1.2 / 2
# elif length <= 3:
# text_size = size * 1.2 / length
# else:
# text_size = size * 1.5 / length
# draw_text(screen, str(int(number)), (x_size + size * 0.5, y_size + size * 0.5 - text_size / 2), args.fontface, color=color, size=args.fontsize, center='center')
if state == 'over':
# pygame.draw.rect(screen, (0, 0, 0, 0.5), (0, 0, args.grid_size, args.grid_size))
# draw_text(screen, 'Game over!', (args.grid_size / 2, args.grid_size / 2), args.fontface, size=25, center='center')
break
elif state == 'win':
# pygame.draw.rect(screen, (0, 0, 0, 0.5), (0, 0, args.grid_size, args.grid_size))
# self.draw_text('Win!', (args.grid_size / 2, args.grid_size / 2), args.fontface, size=25, center='center')
break
# Update
# raw_screen.blit(screen, (0, 0))
# pygame.display.flip()
# clock.tick(args.FPS)
df = pd.DataFrame(episode_dict, columns=list(episode_dict.keys()))
if episode_path is not None:
df.to_csv(episode_path, index=False, header=True, sep='\t')
return df
if __name__ == '__main__':
N = 10000
args = load_args(GameConfig)
dfs = []
args.random_strategy = True
for i in range(N):
print(i)
df = run(args, None)
df['episode'] = i
dfs.append(df)
pd.concat(dfs).to_csv('episode/random.csv', sep='\t', header=True, index=False)
args.random_strategy = False
N = 10000
for i in range(N):
print(i)
df = run(args, 'episode/ai_%04d.csv' % (i))
# df.loc[:, 'episode'] = i
# dfs.append(df)
# pd.concat(dfs).to_csv('episode/random.csv', sep='\t', header=True, index=False)
07-15
- 路跑5km跑进22分,跑完膝盖有点疼。专攻5km,争取坚持住一个月。其实有点想试试公路车,家里这边倒是有很不错的路段,对膝盖也友好些。
- 好像大家都回家了,喝酒是约不到了。卸掉weibo,之前一年多不用,就不知道这学期怎么会想到再把这玩意儿给装上。清静三十日,搞点名堂出来。
- 下午暴雨导致大面积断电,雨下到起雾,从三点停到八点,扫兴。晚上做空中蹬腿时感觉右腿确实疼,恐怕真的不能这么跑了。于是试了试punk的动作发现完全跟不住,又想起了小学时被班主任留下来练广播体操的童年阴影,手脚协调性是真的差,这辈子改不了了…
关于强化学习github上有人给出了一个非常好的用pytorch实现的各种算法的仓库GitHub@Deep-Reinforcement-Learning-Algorithms-with-PyTorch,很奇怪为什么对于强化学习目前没有什么比较好的框架能用,其实还是跟普通的监督学习有点区别的。
有点问题,因为episode差不多已经凑齐了,随机的10000个加带策略的1000个,目标函数就用off policy的DQN版本,似乎应该不会有太大问题。
其实毕竟对强化学习这块做得很少,还是有一些问题,比如如果一个状态下的决策空间很大该怎么办,2048只有4种action,自然可以每个遍历一遍看 max a ′ Q ( s ′ , a ′ ) \max_{a'}Q(s',a') maxa′Q(s′,a′)的取值,但是如果有非常多的action,是否有其他扩展改进的算法?似乎并不那么容易。
07-16
- 这次真的伤痛了,又跟寒假那会儿一样,本来早上不想跑了,但是觉得才三天就断也太差劲了。
- 刷国际课程学分,这个暑假暂时没有什么硬事,趁早刷掉15场,省得后面几个暑假费事。
- 昨晚刷了10集巨人第四季,下午把剩下六集补了,有大半年没有这么补番了,巨人还是值得画时间补掉的,虽然动画没有画到结局,但是大致的后续基本还是知道的。总体来看第四季还不错,可惜了jsc搞出那种离谱的结局,唉。贾碧没那么坏,还有吉克是真惨,被兵长砍从头砍到尾,完事被弟弟洗脑了还帮着数钱。冤冤相报何时能了,各退一步也许就没那么多悲剧了。
关于今天的讲座做了些笔注:
-
Computational不代表是Computer Science
Computational指使用计算方法与算法来解决某些其他问题,如Computational social science, Systems biology.
-
Computational design science research is concerned with solving business and societal problems by developing computational models and algorithms
-
Computational data science research是Computational design science research的一类,目前仍然是MIS受欢迎的投稿类型,因为这些Editorial里都强调了会接收这些期刊
-
Computational data science research的特点:
- Problem-oriented:需要解决商业或社会上的具体问题
- Interdisciplinary:扩展多个不同的disciplines,如机器学习,优化,社会学,经济学等
- Data-driven:数据启动
- Methodological Contribution
- Empirically sound
- Demonstrate economic value and managerial insights
与相关研究的区别:
-
与CS中的机器学习的区别:Problem to Algorithm v.s. Algorithm to Algorithm
要对问题做具体描述(如Fintech的问题可能需要做经济学对该问题的看法,文献综述要有这部分的问题),CS会侧重算法
-
一些其他领域用机器学习的(如Fintech),一般只是用现成的算法,而我们则更注重方法论的创新。
-
如何进行Computational data science research:
- 定义需要解决的问题
- 需要对相关领域的文献进行review(如Finance)
- 综述先进的模型
- 确认问题的挑战性,以及提出的方法的新颖性
-
Computational data science research一些研究点:
-
Fundamental Business Problem, e.g. Industry Classfication System
-
Grand Chanllege in Society
-
Methodological Contribution:这是Computational data science research的主要贡献
这是比较主观的一个点,如果论文中能够论述方法与先进模型的比较,一般认为是有方法论贡献的,如果只是对已有方法的应用,一般是No significant contribution,介于这两者中间,成为Nontrival extension(非平凡的扩展),是有可能构成significant contribution
-
Evaluation:
研究与baseline方法的比较,研究理论分析,消融测试,实验,经济价值等
-
-
Reviews Pitfalls:
-
缺乏理论性
-
Fit(不太懂)
-
07-17
- 临睡刷keep笑死,不是说再喝茶百道是狗么,果然没有人能逃得过真香定律。
- 准备练公路车,这腿是没法再跑了,逃得过初一,逃不过十五,应该是6月30号和7月9号两次长距离跑给伤了,否则5km的量不至于三四天就再起不能。
- 下周四场讲座好像还可以,感觉要比第一场靠谱点儿,第一场想记些东西,可是也没啥有意义的内容。我一直觉得做ML还是要注重理论性的东西,至少不能完全抛弃,第一场方晓给人的感觉就是那种结果论者,很不看重理论性的创新,认为是可有可无的。最好笑的是他连自己论文的方法都说不清楚,还宣称论文写了四五年。其实大部分搞ML这块的人基本都这个德行,虽然也没什么可解释性,所以我还是很喜欢邓琪的风格,本科对他还是了解得太少。
给下周的四场讲座打个宣传,前两场看起来质量高一些,第一场应该是理论计算机中心请的,模糊决策了解一下;中间两场都是X院老本行了:
- 讲座标题:On Fuzzy and Linguistic Decision-Makings: Scenarios and Challenges
- 中文标题:模糊和语言决策:情景与挑战
- 讲座时间: 2020/07/19 14:30-16:30(GMT+8) \text{2020/07/19 14:30-16:30(GMT+8)} 2020/07/19 14:30-16:30(GMT+8)
- 讲授者: Enrique Herrera-Viedma \text{Enrique Herrera-Viedma} Enrique Herrera-Viedma
- 讲授者介绍:Enrique Herrera-Viedma (IEEE Fellow) received the M.Sc. and Ph.D. degrees in computer science from the University of Granada, Granada, Spain, in 1993 and 1996, respectively. He is currently a Professor of computer science and AI, and the Vice-President of Research and Knowledge Transfer, University of Granada. His H-index is 69, with more than 17 000 citations received in the Web of Science and 85 in Google Scholar, with more than 29 000 cites received. He has been identified as one of the World’s most influential researchers by the Shanghai Centre and Thomson Reuters/Clarivate Analytics in both the scientific categories of computer science and engineering, from 2014 to 2018. His current research interests include group decision making, consensus models, linguistic modeling, aggregation of information, information retrieval, bibliometric, digital libraries, Web quality evaluation, recommender systems, block chain, smart cities, and social media. He is the Vice-President of Publications of the SMC Society and an Associate Editor of several JCR journals, such as IEEE Transactions on Fuzzy Systems, IEEE Transactions on Systems, Man, and Cybernetics: Systems, Information Sciences, Applied Soft Computing, Soft Computing, Fuzzy Optimization and Decision Making, Journal of Intelligent and Fuzzy Systems, International Journal of Fuzzy Systems, Engineering Applications of Artificial Intelligence, Journal of Ambient Intelligence and Humanized Computing, International Journal of Machine Learning and Cybernetics, and Knowledge-Based Systems. He is also the Editor-in-Chief of the Journal Frontiers in Artificial Intelligence (Section Fuzzy Systems).
- Z O O M \rm ZOOM ZOOM会议室 I D \rm ID ID: 89845472509 89845472509 89845472509(密码: 647299 647299 647299)
This talk takes a brief tour through the main trends, studies, methodologies and models developed around the field of fuzzy decision-making in the last decades. Fuzzy decision making approaches allow to deal with real-world decision problems of varying complexity where humans exhibit vagueness and imprecision to assess information about decision alternatives, criteria, etc. Specifically, we address a triple goal in this talk. Firstly, we introduce the main representation paradigms that have arisen from fuzzy set theory to model assessment information at different levels of expressive richness and complexity. Secondly, we examine three core scenarios around which fuzzy decision-making methods have been developed: multi-criteria decision-making, group (and consensus-driven) decision-making, and multi-person multi-criteria decision-making. Lastly, we discuss new complex decision-making scenarios that emerged in recent years where decisions should be guided by the “wisdom of the crowd”, highlighting their challenges and reflecting on much needed key guidelines for future research in the field.
- 讲座标题:Designing Maximum Matchings in Sparse Random Graphs (with an Application in Alibaba Cainiao’s Logistics Network)
- 中文标题:稀疏随机图中的最大匹配设计(在阿里巴巴菜鸟物流网络中的应用)
- 讲座时间: 2020/07/20 09:30-11:30(GMT+8) \text{2020/07/20 09:30-11:30(GMT+8)} 2020/07/20 09:30-11:30(GMT+8)
- 讲授者:辛林威
- 讲授者介绍:辛林威博士是美国芝加哥大学Booth商学院助理教授(运营管理方向)。他的主要研究方向是库存和供应链管理:为公司/政府/非营利性组织在各种不确定的情况下设计模型和算法以有效的达到 “供需平衡”。他利用渐进分析对随机库存模型的研究获得了多个 INFORMS \text{INFORMS} INFORMS(运筹学和管理科学研究协会)论文奖项,包括应用概率学会颁发的最佳论文奖( 2019 2019 2019)、 George E. Nicholson \text{George E. Nicholson} George E. Nicholson最佳学生论文奖( 2015 2015 2015)、最佳青年学者论文奖第二名( 2015 2015 2015),以及生产与服务运作管理最佳学生论文入围奖( 2014 2014 2014)。他采取产学研相结合,与业界的广泛研究合作包括京东物流,阿里巴巴菜鸟,阿里巴巴达摩院,沃尔玛全球电子商务。他与京东物流在无人仓库机器人调度算法方面的工作被素有运筹和管理科学界“诺贝尔奖”之称的 INFORMS Franz Edelman \text{INFORMS Franz Edelman} INFORMS Franz Edelman奖所认可( 2021 2021 2021),累计可为公司节省数十亿美元。他以沃尔玛线上超市的结账推荐系统为背景的研究获得了 2017 2017 2017年 CSAMSE \text{CSAMSE} CSAMSE(中国管理科学与工程学者协会)最佳论文奖。他与美国阿贡国家实验室对动态线路额定值的研究获得了 2020 2020 2020年 IEEE Transactions on Power Systems \text{IEEE Transactions on Power Systems} IEEE Transactions on Power Systems最佳论文奖。他的其他荣誉包括曾获得过美国国家自然科学基金资助。他的研究成果发表在《 Operations Research \text{Operations Research} Operations Research》和《 Management Science \text{Management Science} Management Science》等学术期刊上。他目前在芝加哥大学教授 MBA \text{MBA} MBA以及博士生课程。
- 腾讯会议 I D \rm ID ID: 843214421 843214421 843214421(密码: 123456 123456 123456)
本讲座是基于一项由阿里巴巴菜鸟研究基金支持的研究。我们研究的问题是如何设计一个稀疏图,能够支持随机节点中断的大型匹配。这是基于实践中电子商务平台的"中间一公里"运输问题。我们研究了三种图网络,并刻画了它们的理论性能。我们的理论结果表明,它们的性能可以接近于完整图的性能。我们并且通过菜鸟的真实数据评估了它们在"中间一公里"上的经验性能。文章的合作者包括 Yifan Feng \text{Yifan Feng} Yifan Feng(新加坡国立大学)、 Ren e ˊ Caldentey \text{René Caldentey} Reneˊ Caldentey(芝加哥大学)、 Yuan Zhong \text{Yuan Zhong} Yuan Zhong(芝加哥大学), Haoyuan Hu \text{Haoyuan Hu} Haoyuan Hu(阿里巴巴菜鸟), Bing Wang \text{Bing Wang} Bing Wang(阿里巴巴菜鸟)。
- 讲座标题:Data-Driven Hospital Management
- 中文标题:数据驱动的医院运营管理
- 讲座时间: 2020/07/21 09:30-11:30(GMT+8) \text{2020/07/21 09:30-11:30(GMT+8)} 2020/07/21 09:30-11:30(GMT+8)
- 讲授者: Yichuan Ding \text{Yichuan Ding} Yichuan Ding
- 讲授者介绍:Yichuan Ding’s research interests include optimization, queueing, and statistics, as well as their applications in public sectors, including cadaver kidney exchange and allocation policies, affordable housing management, emergency department operations, outpatient and surgical scheduling, etc.
- 腾讯会议 I D \rm ID ID: 895588024 895588024 895588024(密码: 123456 123456 123456)
We will cover a few topics in hospital management, including the management of the outpatient department, the operation room, and the emergent department. We will introduce the cutting-edge techniques in improving the efficiency of the care delivery system, including queueing theory, optimization, and empirical methods. This seminar talk does not require much technical background, and is suitable for students at all levels with an interest in operations research and management sciences.
- 讲座标题:Recent Development in Data Privacy
- 中文标题:近期数据隐私性的发展
- 讲座时间: 2020/07/23 09:00-11:00(GMT+8) \text{2020/07/23 09:00-11:00(GMT+8)} 2020/07/23 09:00-11:00(GMT+8)
- 讲授者: Xuan Bi \text{Xuan Bi} Xuan Bi
- 讲授者介绍:Xuan Bi is an Assistant Professor of Information and Decision Sciences in the Carlson School of Management, at the University of Minnesota. His general research goal is to design data-driven solutions and provide decision support to benefit organizations and individuals. His research mainly focuses on the interface of Statistics, Machine Learning, and Information Systems, which aims at creating and applying data-driven methodologies to address real-world, large-scale, business and scientific problems. Specifically, his works revolve around personalization, with a special interest in recommender systems and differential privacy.
- Z O O M \rm ZOOM ZOOM会议室 I D \rm ID ID: 88260819472 88260819472 88260819472(密码: 123456 123456 123456)
Limited access to large-scale, high-quality, or multi-source data is one of the key obstacles to deploying modern machine learning models, which is partly due to the reluctance of information exchange out of privacy concerns. Recent studies have found that data privacy has the potential to grow into a 10+ billion industry, because of the increasing demand of data sharing, fast development of AI software and platforms, and the vast adoption of data-related regulations and policies. We will provide a broad overview of the state-of-the-art data protection techniques, including some of the key methods such as differential privacy and federated learning, as well as our recent works in these areas.
07-18
- WXY去跑六盘水马拉松了,目标是破三,相当可怕的实力。才知道六盘水就在贵州,家门口的就有赛事也太舒服了。似乎受甘肃马拉松事故的影响,下半年的赛事很多都取消了,实在是很扫兴,现在还能期待一下的应该是南京、杭州这两场,上海的只能听着点消息。相对近一些,要不然就只能等到明年了唉。
- 这两天转练腰腹和深蹲,这次不敢硬犟,跑休个四五天也认。希望练稳核心和膝盖后能有提升,总归还是想把5k跑进20分的。
- 头疼,事情做不进去。
torch.sort用法:
import numpy
import torch
tensor = torch.FloatTensor(numpy.array([[.3, .2, .1, .4], [.3, .2, .1, .4]], dtype=numpy.float64))
sorted_tensor, index = torch.sort(tensor, descending=True)
print(sorted_tensor, type(tensor))
print(index, type(index))
# Output:
"""
tensor([[0.4000, 0.3000, 0.2000, 0.1000],
[0.4000, 0.3000, 0.2000, 0.1000]]) <class 'torch.Tensor'>
tensor([[3, 0, 1, 2],
[3, 0, 1, 2]]) <class 'torch.Tensor'>
"""
07-19
- 姑婆婆昨天上厕所时断气,93岁寿终正寝,一大早家里嘈杂得不行,还好昨晚睡得特别早(困死)。醒来下意识一弯腿,右小腿腹猛地一抽,疼好久,都两天没跑了还能抽筋。老舅就很郁闷,上周一送完姨父刚飞走,这周又得飞回来,大热天丧事成双。
- 小腿抽筋也要被老妈训斥。五月之后在校都没有大伤,这次回来没几天跑伤是给她到把柄了,再加上连续有人去世心情也不好,惹不起。反正我已经决定从明天开始接着晨跑,换条直的路线,休息三天状态基本也恢复得差不多了, 不过这几天感觉练了些新的动作也挺有趣,只是跑步确实还是太单调了。
- 下午讲的是语言模糊决策模型,其实算是NLP的一个非常重要的理论基础,所以是wyl来主持的,可惜这个西班牙人的口音实在是一言难尽,wyj还要我来写讲座回顾。
- sxy最近好猛,每天都运动一两个小时,自律的人类真可怕。
模糊数评估(Fuzzy number assessments):
定义 1 1 1:
设 A : R → [ 0 , 1 ] A:\R\rightarrow[0,1] A:R→[0,1]是实数轴上的一个模糊集,称 A A A是一个模糊数(fuzzy number),若满足一下性质:
- A A A是正态的(normal),即 ∃ x ∈ R \exist x\in\R ∃x∈R,使得 A ( x ) = 1 A(x)=1 A(x)=1成立;
- A A A是模糊凸的(fuzzy convex),即 ∀ t ∈ [ 0 , 1 ] , x ∈ R , y ∈ R \forall t\in [0,1],x\in\R,y\in\R ∀t∈[0,1],x∈R,y∈R,使得 A ( t x + ( 1 − t ) y ) ≥ min { A ( x ) , A ( y ) } A(tx+(1-t)y)\ge\min\{A(x),A(y)\} A(tx+(1−t)y)≥min{A(x),A(y)}成立;
- A A A是上半连续的(upper semicontinuous),即 ∀ ϵ > 0 , x 0 ∈ R \forall\epsilon>0,x_0\in\R ∀ϵ>0,x0∈R, ∃ δ > 0 \exist\delta>0 ∃δ>0,使得 ∀ x ∈ { x : ∣ x − x 0 ∣ < δ } \forall x\in\{x:|x-x_0|<\delta\} ∀x∈{x:∣x−x0∣<δ},有 A ( x ) − A ( x 0 ) < ϵ A(x)-A(x_0)<\epsilon A(x)−A(x0)<ϵ成立;
- A A A是紧支的(compactly supported),即 cl { x ∈ R : A ( x ) > 0 } \text{cl}\{x\in\R:A(x)>0\} cl{x∈R:A(x)>0}是紧集,其中 cl \text{cl} cl是闭包;
利用模糊数,专家无需提供精确的评估值,而是提供类似 ≈ 0.6 \approx 0.6 ≈0.6这样的表达式来近似表达一个实数值(这往往是更实际的做法)。
07-20
- 早起先在跑步机上试了2km,身体很轻盈,感觉最好的状态回来了,特别高兴,或许每天坚持未必是最好的,适当的跑休是必要的。忽然发现家里的器材还挺全,哑铃,健腹轮,俯卧撑支架,跑步机,拉力弹簧都有,就是好多都上灰了… 中午参加完葬礼顶着最毒的太阳在S237省道上全力跑了2km,左髌骨还疼,其余没有异样,good。
- 早上的讲座是杨超林的老朋友的汇报,又是库存专题,自从离开杉数后,感觉做库存没前途,客户总是会有各种莫名其妙的规则,内部提供的dp也不准,搞不好还有各种版本,需求永远在变,各种蝴蝶效应导致最后实际效益会很差。而且这位老朋友贼糊弄,2小时的讲座用了不到1小时就讲完,超林看起来也没精神,总感觉院里的教授都太没精气神了,或者说对学生的事情很不上心,反而是刚来的年轻老师课讲得好,对学生也负责。唉,这就是社会的现状,既得利益者不思进取,底端卷成麻花。
livebot里的一些模块:
'''
@Date : 8/10/2018
@Author: Shuming Ma
@mail : shumingma@pku.edu.cn
@homepage: shumingma.com
'''
'''
Originally from http://nlp.seas.harvard.edu/2018/04/03/attention.html
'''
import numpy as np
import torch
import torch.nn as nn
import torch.nn.functional as F
import math, copy, time
from torch.autograd import Variable
BOS = 1
class luong_attention(nn.Module):
def __init__(self, hidden_size):
super(luong_attention, self).__init__()
self.hidden_size = hidden_size
self.linear_in = nn.Linear(hidden_size, hidden_size)
self.linear_out = nn.Sequential(nn.Linear(2*hidden_size, hidden_size), nn.Tanh())
self.softmax = nn.Softmax(dim=-1)
def init_context(self, context):
self.context = context # batch * seq1 * size
def forward(self, h): # batch * seq2 * size
gamma_h = self.linear_in(h) # batch * seq2 * size
weights = torch.bmm(gamma_h, self.context.transpose(1,2)) # batch * seq2 * seq1
weights = self.softmax(weights) # batch * seq2 * seq1
c_t = torch.bmm(weights, self.context) # batch * seq2 * size
output = self.linear_out(torch.cat([c_t, h], -1)) # batch * seq2 * size
return output
class Generator(nn.Module):
"Define standard linear + softmax generation step."
def __init__(self, d_model, vocab):
super(Generator, self).__init__()
self.proj = nn.Linear(d_model, vocab)
def forward(self, x):
return self.proj(x)
class VideoEncoder(nn.Module):
def __init__(self, d_model, d_ff, n_head, dropout, n_block):
super(VideoEncoder, self).__init__()
self.layers = nn.ModuleList([VideoBlock(d_model, d_ff, n_head, dropout) for _ in range(n_block)])
self.norm = LayerNorm(d_model)
def forward(self, x):
for layer in self.layers:
x = layer(x)
return self.norm(x)
class TextEncoder(nn.Module):
def __init__(self, d_model, d_ff, n_head, dropout, n_block):
super(TextEncoder, self).__init__()
self.layers = nn.ModuleList([TextBlock(d_model, d_ff, n_head, dropout) for _ in range(n_block)])
self.norm = LayerNorm(d_model)
def forward(self, x, m):
for layer in self.layers:
x = layer(x, m)
return self.norm(x)
class CommentDecoder(nn.Module):
def __init__(self, d_model, d_ff, n_head, dropout, n_block):
super(CommentDecoder, self).__init__()
self.layers = nn.ModuleList([DecoderBlock(d_model, d_ff, n_head, dropout) for _ in range(n_block)])
self.norm = LayerNorm(d_model)
def forward(self, x, m1, m2, mask):
for layer in self.layers:
x = layer(x, m1, m2, mask)
return self.norm(x)
class VideoBlock(nn.Module):
def __init__(self, d_model, d_ff, n_head, dropout):
super(VideoBlock, self).__init__()
self.self_attn = MultiHeadedAttention(n_head, d_model)
self.feed_forward = PositionwiseFeedForward(d_model, d_ff, dropout)
self.sublayer = nn.ModuleList([SublayerConnection(d_model, dropout) for _ in range(2)])
def forward(self, x):
x = self.sublayer[0](x, lambda x: self.self_attn(x, x, x))
return self.sublayer[1](x, self.feed_forward)
class TextBlock(nn.Module):
def __init__(self, d_model, d_ff, n_head, dropout):
super(TextBlock, self).__init__()
self.self_attn = MultiHeadedAttention(n_head, d_model)
self.video_attn = MultiHeadedAttention(n_head, d_model)
self.feed_forward = PositionwiseFeedForward(d_model, d_ff, dropout)
self.sublayer = nn.ModuleList([SublayerConnection(d_model, dropout) for _ in range(3)])
def forward(self, x, m):
x = self.sublayer[0](x, lambda x: self.self_attn(x, x, x))
x = self.sublayer[1](x, lambda x: self.video_attn(x, m, m))
return self.sublayer[2](x, self.feed_forward)
class DecoderBlock(nn.Module):
def __init__(self, d_model, d_ff, n_head, dropout):
super(DecoderBlock, self).__init__()
self.self_attn = MultiHeadedAttention(n_head, d_model)
self.video_attn = MultiHeadedAttention(n_head, d_model)
self.text_attn = MultiHeadedAttention(n_head, d_model)
self.feed_forward = PositionwiseFeedForward(d_model, d_ff, dropout)
self.sublayer = nn.ModuleList([SublayerConnection(d_model, dropout) for _ in range(4)])
def forward(self, x, m1, m2, mask):
x = self.sublayer[0](x, lambda x: self.self_attn(x, x, x, mask))
x = self.sublayer[1](x, lambda x: self.video_attn(x, m1, m1))
x = self.sublayer[2](x, lambda x: self.text_attn(x, m2, m2))
return self.sublayer[3](x, self.feed_forward)
class LayerNorm(nn.Module):
def __init__(self, features, eps=1e-6):
super(LayerNorm, self).__init__()
self.a_2 = nn.Parameter(torch.ones(features))
self.b_2 = nn.Parameter(torch.zeros(features))
self.eps = eps
def forward(self, x):
mean = x.mean(-1, keepdim=True)
std = x.std(-1, keepdim=True)
return self.a_2 * (x - mean) / (std + self.eps) + self.b_2
class SublayerConnection(nn.Module):
"""
A residual connection followed by a layer norm.
Note for code simplicity the norm is first as opposed to last.
"""
def __init__(self, size, dropout):
super(SublayerConnection, self).__init__()
self.norm = LayerNorm(size)
self.dropout = nn.Dropout(dropout)
def forward(self, x, sublayer):
return x + self.dropout(sublayer(self.norm(x)))
class MultiHeadedAttention(nn.Module):
def __init__(self, h, d_model, dropout=0.1):
"Take in model size and number of heads."
super(MultiHeadedAttention, self).__init__()
assert d_model % h == 0
# We assume d_v always equals d_k
self.d_k = d_model // h
self.h = h
self.linears = nn.ModuleList([nn.Linear(d_model, d_model) for _ in range(4)])
self.attn = None
self.dropout = nn.Dropout(p=dropout)
def attention(self, query, key, value, mask=None, dropout=None):
"Compute 'Scaled Dot Product Attention'"
d_k = query.size(-1)
scores = torch.matmul(query, key.transpose(-2, -1)) / math.sqrt(d_k)
if mask is not None:
scores = scores.masked_fill(mask == 0, -1e9)
p_attn = F.softmax(scores, dim=-1)
if dropout is not None:
p_attn = dropout(p_attn)
return torch.matmul(p_attn, value), p_attn
def forward(self, query, key, value, mask=None):
if mask is not None:
# Same mask applied to all h heads.
mask = mask.unsqueeze(1)
nbatches = query.size(0)
# 1) Do all the linear projections in batch from d_model => h x d_k
query, key, value = \
[l(x).view(nbatches, -1, self.h, self.d_k).transpose(1, 2)
for l, x in zip(self.linears, (query, key, value))]
# 2) Apply attention on all the projected vectors in batch.
x, self.attn = self.attention(query, key, value, mask=mask,
dropout=self.dropout)
# 3) "Concat" using a view and apply a final linear.
x = x.transpose(1, 2).contiguous() \
.view(nbatches, -1, self.h * self.d_k)
return self.linears[-1](x)
class Embeddings(nn.Module):
def __init__(self, d_model, vocab):
super(Embeddings, self).__init__()
self.lut = nn.Embedding(vocab, d_model)
self.d_model = d_model
def forward(self, x):
return self.lut(x)
class PositionalEncoding(nn.Module):
"Implement the PE function."
def __init__(self, d_model, dropout, max_len=5000):
super(PositionalEncoding, self).__init__()
self.dropout = nn.Dropout(p=dropout)
# Compute the positional encodings once in log space.
pe = torch.zeros(max_len, d_model)
position = torch.arange(0., max_len).unsqueeze(1)
div_term = torch.exp(torch.arange(0., d_model, 2) *
-(math.log(10000.0) / d_model))
pe[:, 0::2] = torch.sin(position * div_term)
pe[:, 1::2] = torch.cos(position * div_term)
pe = pe.unsqueeze(0)
self.register_buffer('pe', pe)
def forward(self, x):
x = x + Variable(self.pe[:, :x.size(1)],requires_grad=False).cuda()
return self.dropout(x)
class PositionalEmb(nn.Module):
"Implement the PE function."
def __init__(self, d_model, dropout, max_len=5000):
super(PositionalEmb, self).__init__()
self.dropout = nn.Dropout(p=dropout)
# Compute the positional encodings once in log space.
self.pe = torch.nn.Embedding(max_len, d_model)
def forward(self, x):
x = x + self.pe(Variable(torch.range(1,x.size(1))).long().cuda()).unsqueeze(0)
return self.dropout(x)
class PositionwiseFeedForward(nn.Module):
"Implements FFN equation."
def __init__(self, d_model, d_ff, dropout=0.1):
super(PositionwiseFeedForward, self).__init__()
self.w_1 = nn.Linear(d_model, d_ff)
self.w_2 = nn.Linear(d_ff, d_model)
self.dropout = nn.Dropout(dropout)
def forward(self, x):
return self.w_2(self.dropout(F.relu(self.w_1(x))))
def subsequent_mask(batch, size):
"Mask out subsequent positions."
attn_shape = (batch, size, size)
subsequent_mask = np.triu(np.ones(attn_shape), k=1).astype('uint8')
return torch.from_numpy(subsequent_mask) == 0
07-21
- 河南这次发大水好像真的麻烦了,郑州都淹成这样,其他地级市可能更难… 唉,对我来说洪涝还只是停留在书本上的东西,但愿这水能尽快退去,太难了。
- WXY腰伤,看他最近拉胯得很,只能在4分半以上的配速在恢复。中午宴席结束继续在烈日下练抗乳酸跑,其实太阳很晒倒是不太影响,习惯了还挺舒服,只是喉咙干得太难受。
- 前天把进巨漫画从120话刷到139话完,其实我后来想想最终话也没那么糟糕,我觉得最后艾伦的那些看起来反差很大的话可能也算是与整个故事的开头呼应,返璞归真,临死前总归还是对最初和三笠、阿明纯情的友谊不舍的。至于为什么得出是艾伦操纵弑母的结论,我觉得jsc在设定上出现BUG了,仔细想想进巨的能力真的是预知未来么?难道不是操纵过去么?后任继承者会对前任造成影响,这意味着无穷远的未来的人能够对当前时间点产生影响,这本身就很BUG,因为颠倒了因果,会导致很多逻辑说不通,剧情设定上就无法自圆其说了。总之我觉得并不是那么一无是处吧,只是这个结局可能并不是最好的,但仍然是一个情理之中的结局(PS:很希望第五季是以剧场版的形式把120话之后的内容呈现出来,结尾稍加改编,最终始祖巨上的大战如果能画出来就太好了,望有生之年能看到真正的结局)
rar和zip的解压压缩解密操作记录:
from unrar import rarfile
path1 = "d:\\1.rar"
path2 = "d:\\1"
rf = rarfile.RarFile(path1 , pwd = "123")
rf.extractall(path = path2, pwd = "123")
'''
第一步:安装unrar模块,直接pip install unrar可能会找不到库,需要下载unrar library,也就是UnRAR.dll,下载地址为:http://www.rarlab.com/rar/UnRARDLL.exe;
第二步:将unrar安装路径添加到系统环境变量,64位操作系统的路径为C:\Program Files (x86)\UnrarDLL\x64,然后还需要将x64文件下的UnRAR64.lib和UnRAR64.dall重命名为unrar.lib和unrar.dall,因为unrar模块识别的文件是unrar.dll和unrar.lib;
'''
import zipfile
zip_file = zipfile.ZipFile('./cache/.zip')#文件的路径与文件名
zip_list = zip_file.namelist() # 得到压缩包里所有文件
for f in zip_list:
zip_file.extract(f, './cache_F/',pwd="".encode("utf-8")) # 循环解压文件到指定目录
zip_file.close() # 关闭文件,必须有,释放内存
zip_file = zipfile.ZipFile('./cache_F/.zip')#文件的路径与文件名
zip_list = zip_file.namelist() # 得到压缩包里所有文件
for f in zip_list:
zip_file.extract(f, './cache/',pwd="mima".encode("utf-8")) # 循环解压文件到指定目录
zip_file.close() # 关闭文件,必须有,释放内存
07-22
- 灾情并不见好转,甚至蔓延到河北。有时就是如此无力,明明已经尽力,但是只能眼睁睁看着局势恶化,在郑州地铁中遇难的12人该是多么绝望。院里同级在河南的特别多,认识的就有三个,还都算是有过一些交集,困在郑州、许昌和安阳,住在高层的暂时还算安全,倒霉的yjy刚好坐车回家困在郑州站。总之千万别有致命的决堤溃坝,一切都会慢慢好起来的。
- 还是要学游泳,保命,也为了可以去参加铁三。感觉完赛个小铁(800m游泳+20km自行车+5km跑步)还是轻而易举的,标铁和大铁那真的反人类。前几天大铁(3.8km游泳+180km自行车+全马)世界纪录刷新到7小时27分(游泳44分钟,自行车时速46km,最后的全马仅用了2小时44分,中间没有休息,这是人能做到的…),太恐怖了,我记得去年在B站刷到一个去跑连云港大铁的上海大学学生,用了整整12小时,已经是男子组前30的精英选手。如果我去跑大铁,肯定已经淹死在第一段游泳的河里了…
- 看了一些龙胖蟒的集锦,又重燃去打乒乓球的热情,可惜球拍没带回来。这种酷暑天跑不动路,就该去文体中心吹着空调陪老大爷过两招。24号东奥乒赛开始,关注一下。
- 晚饭后2km(均配4’12")+2.5km(均配4’23")路跑间歇,为什么不晨跑了?因为真的起不来,这两天都七点多起,唉,自律真难。
下周三、四、五(7月28~30日)的短期课程非常有趣,是宾州沃顿商学院的Dr. Zongming Ma副教授来讲,主题是网络数据分析,主要是高维统计以及各种随机模型的高阶应用,我觉得会非常吸引人,跟邓琪教的内容会有交叉,值得关注,因为受中美关系影响,Dr. Zongming Ma不希望在公众号传播该课程,那我就“勉为其难”宣传一下啦
时间表:
 课程大纲:
课程大纲:
- Introduction to network data
(a) Examples of typical network data
(b) Important characteristics
(c) Main challenges: modeling, algorithm, theory
(d) This course: exchangeable network models, SBM / DCBM / latent space models - A short introduction to statistical decision theory
(a) Model, parameter, action space, loss, risk
(b) Statistical optimality: Cramer–Rao, Bayes, minimax, rate minimax
(c) Why the rate minimax viewpoint makes sense for complex decision problems
(d) Neyman-Pearson lemma
(e) Statistical optimality vs. computational efficiency - Stochastic block models (1)
(a) Data, model and parametrization
(b) Likelihood and mean structure
(c) To start with: planted partition model (balanced 2-block model) - Stochastic block models (2): Performance guarantee of spectral clustering
(a) Prelude: three different regimes for community detection
(b) l2 loss function
(c) l∞ loss function
(d) From spectral clustering to rate minimaxity
07-24
- 早上的讲座本来是这周最不看好的一场,没想到Bi Xuan这么激情,讲得让人很振奋,关于数据安全这块院里老师做得很少,可能吕晨那边是有做,主要今天讲得内容跟去年吕晨课上我做得汇报很相关,听了很有启发,要学的东西太多了。
- 从说唱事件,到发布大碗宽面单曲,最后这次通报,wyf的风评人设多度反转,可是电鳗还是那条电鳗。每个人都在伪装,但非要立牌坊就恶心了,总归得有些自知之明。所以在这满是蟑螂的屋内,又有几人能保持清醒的记忆呢?都是随波逐流罢了。
- M24,烂。望早日完结,免得晚节不保。虽然已经不怎么懂物理,但是八百里外能一枪命中犯人,还强行瞄准不打中要害,TM… 即便理论可行,答应别再这么秀了好么…
- 养精蓄锐,期待后天的暴雨。
各类浏览器Cookie保存路径:(PS:Firefox真的屏蔽掉了Flash,怎么也恢复不了支持了,哎,想回味童年已经不能了)
在Windows系统上(这里以Win7为例)浏览器的Cookie
IE浏览器Cookie数据位于:%APPDATA%\Microsoft\Windows\Cookies\ 目录中的xxx.txt文件 (里面可能有很多个.txt Cookie文件)
如:C:\Users\yren9\AppData\Roaming\Microsoft\Windows\Cookies\0WQ6YROK.txt
在IE浏览器中,IE将各个站点的Cookie分别保存为一个XXX.txt这样的纯文本文件(文件个数可能很多,但文件大小都较小);而Firefox和Chrome是将所有的Cookie都保存在一个文件中(文件大小较大),该文件的格式为SQLite3数据库格式的文件。
Firefox的Cookie数据位于:%APPDATA%\Mozilla\Firefox\Profiles\ 目录中的xxx.default目录,名为cookies.sqlite的文件。
如:C:\Users\jay\AppData\Roaming\Mozilla\Firefox\Profiles\ji4grfex.default\cookies.sqlite
在Firefox中查看cookie, 可以选择”工具 > 选项 >” “隐私 > 显示cookie”。
Chrome的Cookie数据位于:%LOCALAPPDATA%\Google\Chrome\User Data\Default\ 目录中,名为Cookies的文件。
如:C:\Users\jay\AppData\Local\Google\Chrome\User Data\Default\Cookies
在Linux系统上(以Ubuntu 12.04 和 RHEL6.x 为例)浏览器的Cookie
Firefox的Cookie路径为:$HOME$/.mozilla/firefox/xxxx.default/目录下的cookie.sqlite文件。
View Code BASH
1234master@jay-linux:~/.mozilla/firefox/tffagwsn.default$ ll cookies.sqlite-rw-r–r-- 1 master master 1572864 Apr 21 16:54 cookies.sqlitemaster@jay-linux:~/.mozilla/firefox/tffagwsn.default$ pwd/home/master/.mozilla/firefox/tffagwsn.default
07-24
- 女子十米气步枪最后一枪太刺激了,高压之下两个人都是大失误,还好对方失误得更离谱…
- 混双毫无悬念,常规让一追四。明晚可以打到半决赛,左半区应该不会有什么问题,不出意外肯定还是决赛打日本队。
- 举重绝对碾压,hzh抓举成绩就比大部分选手的挺举成绩还高,唯一的竞争对手也没有产生威胁,确实是赢得太轻松了。值得注意的是那个36岁的japan选手,真的特别悲情,挺举全部失败,抓举也只成功了第一次74kg(hzh抓举94kg),作为老将退役落幕之战实在是让人唏嘘不已。还有那个19岁的比利时小将,挺举99kg好不容易成功却被吹了两个红灯成绩作废,然后红着眼睛跪在台上,很让人触动。竞技体育真实残酷。
ϵ \epsilon ϵ贪婪策略实现:
from exploration_strategies.Base_Exploration_Strategy import Base_Exploration_Strategy
import numpy as np
import random
import torch
class Epsilon_Greedy_Exploration(Base_Exploration_Strategy):
"""Implements an epsilon greedy exploration strategy"""
def __init__(self, config):
super().__init__(config)
self.notified_that_exploration_turned_off = False
if "exploration_cycle_episodes_length" in self.config.hyperparameters.keys():
print("Using a cyclical exploration strategy")
self.exploration_cycle_episodes_length = self.config.hyperparameters["exploration_cycle_episodes_length"]
else:
self.exploration_cycle_episodes_length = None
if "random_episodes_to_run" in self.config.hyperparameters.keys():
self.random_episodes_to_run = self.config.hyperparameters["random_episodes_to_run"]
print("Running {} random episodes".format(self.random_episodes_to_run))
else:
self.random_episodes_to_run = 0
def perturb_action_for_exploration_purposes(self, action_info):
"""Perturbs the action of the agent to encourage exploration"""
action_values = action_info["action_values"]
turn_off_exploration = action_info["turn_off_exploration"]
episode_number = action_info["episode_number"]
if turn_off_exploration and not self.notified_that_exploration_turned_off:
print(" ")
print("Exploration has been turned OFF")
print(" ")
self.notified_that_exploration_turned_off = True
epsilon = self.get_updated_epsilon_exploration(action_info)
if (random.random() > epsilon or turn_off_exploration) and (episode_number >= self.random_episodes_to_run):
return torch.argmax(action_values).item()
return np.random.randint(0, action_values.shape[1])
def get_updated_epsilon_exploration(self, action_info, epsilon=1.0):
"""Gets the probability that we just pick a random action. This probability decays the more episodes we have seen"""
episode_number = action_info["episode_number"]
epsilon_decay_denominator = self.config.hyperparameters["epsilon_decay_rate_denominator"]
if self.exploration_cycle_episodes_length is None:
epsilon = epsilon / (1.0 + (episode_number / epsilon_decay_denominator))
else:
epsilon = self.calculate_epsilon_with_cyclical_strategy(episode_number)
return epsilon
def calculate_epsilon_with_cyclical_strategy(self, episode_number):
"""Calculates epsilon according to a cyclical strategy"""
max_epsilon = 0.5
min_epsilon = 0.001
increment = (max_epsilon - min_epsilon) / float(self.exploration_cycle_episodes_length / 2)
cycle = [ix for ix in range(int(self.exploration_cycle_episodes_length / 2))] + [ix for ix in range(
int(self.exploration_cycle_episodes_length / 2), 0, -1)]
cycle_ix = episode_number % self.exploration_cycle_episodes_length
epsilon = max_epsilon - cycle[cycle_ix] * increment
return epsilon
def add_exploration_rewards(self, reward_info):
"""Actions intrinsic rewards to encourage exploration"""
return reward_info["reward"]
def reset(self):
"""Resets the noise process"""
pass
07-25
- 混双还是太碾压了,昨天4:1,今天两场4:0,昕雯毫无悬念进决赛。日本的水谷伊藤组合就特别搞笑,居然差点跪在1/4决赛,若不是抢七局奇迹般地从2:9反追到16:14,两人连半决赛都进不了。
- 膝痛未愈,雨中慢跑了五六公里,很惬意,最后冲刺了一段1km的直线,水平保持在3’40"左右。现在就是半养半练,一直回不到最好的状态。
policy gradient 学习
import copy
import sys
import torch
import numpy as np
from torch import optim
from agents.Base_Agent import Base_Agent
from exploration_strategies.Epsilon_Greedy_Exploration import Epsilon_Greedy_Exploration
from utilities.Parallel_Experience_Generator import Parallel_Experience_Generator
from utilities.Utility_Functions import normalise_rewards, create_actor_distribution
class PPO(Base_Agent):
"""Proximal Policy Optimization agent"""
agent_name = "PPO"
def __init__(self, config):
Base_Agent.__init__(self, config)
self.policy_output_size = self.calculate_policy_output_size()
self.policy_new = self.create_NN(input_dim=self.state_size, output_dim=self.policy_output_size)
self.policy_old = self.create_NN(input_dim=self.state_size, output_dim=self.policy_output_size)
self.policy_old.load_state_dict(copy.deepcopy(self.policy_new.state_dict()))
self.policy_new_optimizer = optim.Adam(self.policy_new.parameters(), lr=self.hyperparameters["learning_rate"], eps=1e-4)
self.episode_number = 0
self.many_episode_states = []
self.many_episode_actions = []
self.many_episode_rewards = []
self.experience_generator = Parallel_Experience_Generator(self.environment, self.policy_new, self.config.seed,
self.hyperparameters, self.action_size)
self.exploration_strategy = Epsilon_Greedy_Exploration(self.config)
def calculate_policy_output_size(self):
"""Initialises the policies"""
if self.action_types == "DISCRETE":
return self.action_size
elif self.action_types == "CONTINUOUS":
return self.action_size * 2 #Because we need 1 parameter for mean and 1 for std of distribution
def step(self):
"""Runs a step for the PPO agent"""
exploration_epsilon = self.exploration_strategy.get_updated_epsilon_exploration({"episode_number": self.episode_number})
self.many_episode_states, self.many_episode_actions, self.many_episode_rewards = self.experience_generator.play_n_episodes(
self.hyperparameters["episodes_per_learning_round"], exploration_epsilon)
self.episode_number += self.hyperparameters["episodes_per_learning_round"]
self.policy_learn()
self.update_learning_rate(self.hyperparameters["learning_rate"], self.policy_new_optimizer)
self.equalise_policies()
def policy_learn(self):
"""A learning iteration for the policy"""
all_discounted_returns = self.calculate_all_discounted_returns()
if self.hyperparameters["normalise_rewards"]:
all_discounted_returns = normalise_rewards(all_discounted_returns)
for _ in range(self.hyperparameters["learning_iterations_per_round"]):
all_ratio_of_policy_probabilities = self.calculate_all_ratio_of_policy_probabilities()
loss = self.calculate_loss([all_ratio_of_policy_probabilities], all_discounted_returns)
self.take_policy_new_optimisation_step(loss)
def calculate_all_discounted_returns(self):
"""Calculates the cumulative discounted return for each episode which we will then use in a learning iteration"""
all_discounted_returns = []
for episode in range(len(self.many_episode_states)):
discounted_returns = [0]
for ix in range(len(self.many_episode_states[episode])):
return_value = self.many_episode_rewards[episode][-(ix + 1)] + self.hyperparameters["discount_rate"]*discounted_returns[-1]
discounted_returns.append(return_value)
discounted_returns = discounted_returns[1:]
all_discounted_returns.extend(discounted_returns[::-1])
return all_discounted_returns
def calculate_all_ratio_of_policy_probabilities(self):
"""For each action calculates the ratio of the probability that the new policy would have picked the action vs.
the probability the old policy would have picked it. This will then be used to inform the loss"""
all_states = [state for states in self.many_episode_states for state in states]
all_actions = [[action] if self.action_types == "DISCRETE" else action for actions in self.many_episode_actions for action in actions ]
all_states = torch.stack([torch.Tensor(states).float().to(self.device) for states in all_states])
all_actions = torch.stack([torch.Tensor(actions).float().to(self.device) for actions in all_actions])
all_actions = all_actions.view(-1, len(all_states))
new_policy_distribution_log_prob = self.calculate_log_probability_of_actions(self.policy_new, all_states, all_actions)
old_policy_distribution_log_prob = self.calculate_log_probability_of_actions(self.policy_old, all_states, all_actions)
ratio_of_policy_probabilities = torch.exp(new_policy_distribution_log_prob) / (torch.exp(old_policy_distribution_log_prob) + 1e-8)
return ratio_of_policy_probabilities
def calculate_log_probability_of_actions(self, policy, states, actions):
"""Calculates the log probability of an action occuring given a policy and starting state"""
policy_output = policy.forward(states).to(self.device)
policy_distribution = create_actor_distribution(self.action_types, policy_output, self.action_size)
policy_distribution_log_prob = policy_distribution.log_prob(actions)
return policy_distribution_log_prob
def calculate_loss(self, all_ratio_of_policy_probabilities, all_discounted_returns):
"""Calculates the PPO loss"""
all_ratio_of_policy_probabilities = torch.squeeze(torch.stack(all_ratio_of_policy_probabilities))
all_ratio_of_policy_probabilities = torch.clamp(input=all_ratio_of_policy_probabilities,
min = -sys.maxsize,
max = sys.maxsize)
all_discounted_returns = torch.tensor(all_discounted_returns).to(all_ratio_of_policy_probabilities)
potential_loss_value_1 = all_discounted_returns * all_ratio_of_policy_probabilities
potential_loss_value_2 = all_discounted_returns * self.clamp_probability_ratio(all_ratio_of_policy_probabilities)
loss = torch.min(potential_loss_value_1, potential_loss_value_2)
loss = -torch.mean(loss)
return loss
def clamp_probability_ratio(self, value):
"""Clamps a value between a certain range determined by hyperparameter clip epsilon"""
return torch.clamp(input=value, min=1.0 - self.hyperparameters["clip_epsilon"],
max=1.0 + self.hyperparameters["clip_epsilon"])
def take_policy_new_optimisation_step(self, loss):
"""Takes an optimisation step for the new policy"""
self.policy_new_optimizer.zero_grad() # reset gradients to 0
loss.backward() # this calculates the gradients
torch.nn.utils.clip_grad_norm_(self.policy_new.parameters(), self.hyperparameters[
"gradient_clipping_norm"]) # clip gradients to help stabilise training
self.policy_new_optimizer.step() # this applies the gradients
def equalise_policies(self):
"""Sets the old policy's parameters equal to the new policy's parameters"""
for old_param, new_param in zip(self.policy_old.parameters(), self.policy_new.parameters()):
old_param.data.copy_(new_param.data)
def save_result(self):
"""Save the results seen by the agent in the most recent experiences"""
for ep in range(len(self.many_episode_rewards)):
total_reward = np.sum(self.many_episode_rewards[ep])
self.game_full_episode_scores.append(total_reward)
self.rolling_results.append(np.mean(self.game_full_episode_scores[-1 * self.rolling_score_window:]))
self.save_max_result_seen()
07-26
- 张本对林兆恒,林连续三局赛点被翻,太可惜了,没能看到精彩的爆冷。观赛感觉张本速度有余,力量不足,期待小胖拉爆他。
- 1/4赛水谷伊藤抢七局2:9死里逃生,昕雯却未能在抢七0:7,2:8的颓势下实现逆转,真的是越来越玄学了,这几天看下来rb队总是越战越勇,频频实现逆转,混双丢金,单打和团体一定要挺住啊。
混双输了,很难过,没心情写东西。
不写不让过审,我可太难了。
关于使用numba加速代码运行的一些装饰器写法:
from numba import jit
import random
import time
@jit(nopython=True)
def monte_carlo_pi(nsamples):
acc = 0
for i in range(nsamples):
x = random.random()
y = random.random()
if (x*x+y*y)<1.0: acc += 1
return 4.0*acc/nsamples
@numba.jit(nopython=True,parallel=True)
def logistic_regression(Y,X,w,iterations):
for i in range(iterations):
w -= np.dot(((1.0/(1.0+np.exp(-Y*np.dot(X,w)))-1.0)*Y),X)
return w
def logistic_regression_(Y,X,w,iterations):
for i in range(iterations):
w -= np.dot(((1.0/(1.0+np.exp(-Y*np.dot(X,w)))-1.0)*Y),X)
return w
07-27
- 回顾昨天的决赛,一方面昕雯前三场淘汰赛赢得太轻松,决赛先大比分赢了两局后有些轻敌了,另一方面前两局明显伊藤接不住许昕的反拉弧圈,许昕得分非常稳定,后来伊藤慢慢适应了许昕的力量后,许昕一板盖不死她。反观刘诗雯接伊藤发球稍显吃力,此消彼长,感觉就不对了。不管怎么说太遗憾,这应该是昕雯的退役之战,未能完满。客观地说,这次rb队的晋级夺冠之路真如小说情节般传奇,无论是对德国的死里逃生,还是决赛在2:0落后的情况下连扳三局逆转,真的是很精彩的表现。
单纯型法的简易实现:
from numpy import *
#标准型线性规划的单纯型tableu迭代算法实现
#函数:计算差额成本
def calc_reduced_cost(c,c_B,B,A):
return c.T - c_B.T * B.I * A
#函数:计算目标函数值
def calc_object_value(c_B,B,b):
return -c_B.T * B.I * b
#函数:计算基解
def calc_BFS(B,b):
return B.I * b
#函数:计算基阵
def calc_Aex(B,A):
return B.I * A
tableau = []
#函数:创建迭代表
def create_tableau(c,c_B,B,A,b):
C = calc_reduced_cost(c,c_B,B,A)
V = calc_object_value(c_B,B,b)
X = calc_BFS(B,b)
A_= calc_Aex(B,A)
table_1 = hstack((V,C))#第一行
table_2 = hstack((X,A_))#其余行
table = vstack((table_1,table_2))
return table
#函数:输出迭代表
def output_tableau(tableau,B_,m,n):
#输出第一行x_1~x_n
print(" "+'\t'+" ",end='\t')
for i in range(n):
print("x_"+str(i+1),end='\t')
#输出第二行V+C(对应tableau的第二行)
print("\n ",end='\t')
for i in range(n+1):
print(tableau[0,i],end='\t')
#输出3~(m+2)行X+A_
for i in range(m):
print("\nx_"+str(B_[i]+1),end='\t')
for j in range(n+1):
print(tableau[i+1,j],end='\t')
print('\n',end="")
return
#simplex method算法实现(Bland选取法)
def simplex_method_algorithm(tableau,B_,m,n):
flag_1 = False#控制reduced cost
flag_2 = False#控制负reduced cost下的元素是否全负
pivot_col_list = []#储存可行的列数
pivot_row_list = []#储存可行的行数
index = -1#pivot_col的下标
min = 999999
output_tableau(tableau,B_,m,n)
for i in range(1,n+1):
if(tableau[0,i]<0):
pivot_col_list.append(i)
flag_1 = True
while flag_1:
Q = mat(zeros((m+1,m+1)))#初等行变换的矩阵初始化
while (not flag_2)and(index<(len(pivot_col_list)-1)):
index += 1
pivot_col = pivot_col_list[index]
for i in range(1,m+1):
if tableau[i,pivot_col]>0:
pivot_row_list.append(i)
flag_2 = True
for i in pivot_row_list:
if tableau[i,0]/tableau[i,pivot_col]<min:
min = tableau[i,0]/tableau[i,pivot_col]
pivot_row = i
B_[pivot_row-1] = pivot_col-1#修改基变量组
for i in range(m+1):
if i==(pivot_row):
Q[i,i] = 1/tableau[pivot_row,pivot_col]
else:
Q[i,i] = 1
Q[i,pivot_row] = -tableau[i,pivot_col]/tableau[pivot_row,pivot_col]
tableau = Q * tableau#对tablau初等行变换
#对tableau元素保留2位小数
tableau1 = mat([[round(tableau[i,j],2) for j in range(n+1)] for i in range(m+1)])
flag_1 = False
flag_2 = False
pivot_col_list = []
pivot_row_list = []
index = -1
min = 999999
output_tableau(tableau1,B_,m,n)
for i in range(1,n+1):
if(tableau[0,i]<0):
pivot_col_list.append(i)
flag_1 = True
return tableau
#获取问题规模
n = int(input("请输入变量数目:"))#列数
m = int(input("请输入约束条件数目:"))#行数
#获取目标函数系数矩阵c
tmp_list = input("请输入目标函数系数矩阵:\n").split()
c = [float(element) for element in tmp_list]
c_mat = mat(c)
print(c_mat)
#获取线性等式约束系数矩阵A
tmp_list = input("请输入线性约束系数矩阵:\n").split(";")
A = [[float(element) for element in tmp_list[i].split()] for i in range(m)]
A_mat = mat(A)
print(A_mat)
#获取RHS矩阵b
tmp_list = input("请输入右值系数矩阵:\n").split()
b = [float(element) for element in tmp_list]
b_mat = mat(b)
print(b_mat)
#获取初始BFS基可行解x_0基变量的下标B_,初始基阵B,初始基目标函数阵c_B
tmp_list = input("请输入基可行解的下标:").split()
B_ = [int(element)-1 for element in tmp_list]
print(B_)
B = [[A[i][j] for j in B_] for i in range(m)]
B_mat = mat(B)
print(B_mat)
c_B = [c[i] for i in B_]
c_B_mat = mat(c_B)
#主程序
tableau = create_tableau(c_mat.T,c_B_mat.T,B_mat,A_mat,b_mat.T)
tableau = simplex_method_algorithm(tableau,B_,m,n)
07-28
- 连日下雨导致马路上开始积水,而且邗江区出现病例,我们这边也要全员核酸,养个老日子都过得不安稳,烦得很。
- 早上的课很好,关于网络图的统计分析,值得关注。笔记见最新发布的博客。
-
行为空间,损失函数与风险函数
( 1 ) (1) (1) 理论框架:给定数据 X X X,模型 F θ F_\theta Fθ,需要制定决策,如估计、检验以及预测。
( 2 ) (2) (2) 行为空间:决策可以采取的所有值构成行为空间,记为 A \mathcal{A} A,我们需要得出某个映射 X → A X\rightarrow\mathcal{A} X→A。
- 在检验中, A = { 0 , 1 } \mathcal{A}=\{0,1\} A={0,1}或 A = [ 0 , 1 ] A=[0,1] A=[0,1]表示是否拒绝零假设或表示随机检验中拒绝零假设的概率。
( 3 ) (3) (3) 损失函数:给定一个行动 a ∈ A a\in A a∈A,损失函数 l ( a , θ ) l(a,\theta) l(a,θ)用于衡量该行为有多坏。
- 确定检验中,一种合理的损失函数: l ( a , θ ) = 1 a = 1 ⋅ 1 θ ∈ H 0 + 1 a = 0 ⋅ 1 θ ∈ H 1 l(a,\theta)=\textbf{1}_{a=1}\cdot\textbf{1}_{\theta\in H_0}+\textbf{1}_{a=0}\cdot\textbf{1}_{\theta\in H_1} l(a,θ)=1a=1⋅1θ∈H0+1a=0⋅1θ∈H1
- 随机检验中,一种合理的损失函数: l ( a , θ ) = a ⋅ 1 θ ∈ H 0 + ( 1 − a ) ⋅ 1 θ ∈ H 1 l(a,\theta)=a\cdot\textbf{1}_{\theta\in H_0}+(1-a)\cdot\textbf{1}_{\theta\in H_1} l(a,θ)=a⋅1θ∈H0+(1−a)⋅1θ∈H1
07-29
- 屋漏偏逢连夜雨,积水更深,淹没电箱导致片区停电,一两天是修不好了。早上强撑着开热点听了3个小时,笔记更新。
- 七月跑量目前112km,下旬跑得很不规律。昨天试了跑步机5km,感觉稍有吃力,明早晨跑找状态。
DQN_HER的一个pytest测试脚本:
import random
from collections import Counter
import pytest
from agents.DQN_agents.DQN_HER import DQN_HER
from agents.DQN_agents.DDQN import DDQN
from agents.DQN_agents.DDQN_With_Prioritised_Experience_Replay import DDQN_With_Prioritised_Experience_Replay
from agents.DQN_agents.DQN_With_Fixed_Q_Targets import DQN_With_Fixed_Q_Targets
from environments.Bit_Flipping_Environment import Bit_Flipping_Environment
from agents.policy_gradient_agents.PPO import PPO
from agents.Trainer import Trainer
from utilities.data_structures.Config import Config
from agents.DQN_agents.DQN import DQN
import numpy as np
import torch
random.seed(1)
np.random.seed(1)
torch.manual_seed(1)
config = Config()
config.seed = 1
config.environment = Bit_Flipping_Environment(4)
config.num_episodes_to_run = 1
config.file_to_save_data_results = None
config.file_to_save_results_graph = None
config.visualise_individual_results = False
config.visualise_overall_agent_results = False
config.randomise_random_seed = False
config.runs_per_agent = 1
config.use_GPU = False
config.hyperparameters = {
"DQN_Agents": {
"learning_rate": 0.005,
"batch_size": 3,
"buffer_size": 40000,
"epsilon": 0.1,
"epsilon_decay_rate_denominator": 200,
"discount_rate": 0.99,
"tau": 0.1,
"alpha_prioritised_replay": 0.6,
"beta_prioritised_replay": 0.4,
"incremental_td_error": 1e-8,
"update_every_n_steps": 3,
"linear_hidden_units": [20, 20, 20],
"final_layer_activation": "None",
"batch_norm": False,
"gradient_clipping_norm": 5,
"HER_sample_proportion": 0.8,
"clip_rewards": False
}
}
trainer = Trainer(config, [DQN_HER])
config.hyperparameters = config.hyperparameters["DQN_Agents"]
agent = DQN_HER(config)
agent.reset_game()
def test_initiation():
"""Tests whether DQN_HER initiates correctly"""
config.hyperparameters["batch_size"] = 64
agent = DQN_HER(config)
agent.reset_game()
assert agent.ordinary_buffer_batch_size == int(0.2 * 64)
assert agent.HER_buffer_batch_size == 64 - int(0.2 * 64)
assert agent.q_network_local.input_dim == 8
assert agent.q_network_local.output_layers[0].out_features == 4
assert isinstance(agent.state_dict, dict)
assert agent.observation.shape[0] == 4
assert agent.desired_goal.shape[0] == 4
assert agent.achieved_goal.shape[0] == 4
assert agent.state.shape[0] == 8
assert not agent.done
assert agent.next_state is None
assert agent.reward is None
config.hyperparameters["batch_size"] = 3
def test_action():
"""Tests whether DQN_HER picks and conducts actions correctly"""
num_tries = 1000
actions = []
for _ in range(num_tries):
action = agent.pick_action()
actions.append(action)
actions_count = Counter(actions)
assert actions_count[0] > num_tries*0.1
assert actions_count[1] > num_tries*0.1
assert actions_count[2] > num_tries*0.1
assert actions_count[3] > num_tries*0.1
assert actions_count[0] + actions_count[1] + actions_count[2] + actions_count[3] == num_tries
assert agent.next_state is None
def test_tracks_changes_from_one_action():
"""Tests that it tracks the changes as a result of actions correctly"""
previous_obs = agent.observation
previous_desired_goal = agent.desired_goal
previous_achieved_goal = agent.achieved_goal
agent.action = 0
agent.conduct_action_in_changeable_goal_envs(agent.action)
assert agent.next_state.shape[0] == 8
assert isinstance(agent.next_state_dict, dict)
assert not all (agent.observation == previous_obs)
assert not all(agent.achieved_goal == previous_achieved_goal)
assert all (agent.desired_goal == previous_desired_goal)
agent.track_changeable_goal_episodes_data()
with pytest.raises(Exception):
agent.HER_memory.sample(1)
agent.save_alternative_experience()
sample = agent.HER_memory.sample(1)
assert sample[1].item() == agent.action
assert sample[2].item() == 4
def test_tracks_changes_from_multiple_actions():
"""Tests that it tracks the changes as a result of actions correctly"""
agent = DQN_HER(config)
agent.reset_game()
for ix in range(4):
previous_obs = agent.observation
previous_desired_goal = agent.desired_goal
previous_achieved_goal = agent.achieved_goal
agent.action = ix
agent.conduct_action_in_changeable_goal_envs(agent.action)
assert agent.next_state.shape[0] == 8
assert isinstance(agent.next_state_dict, dict)
assert not all(agent.observation == previous_obs)
assert not all(agent.achieved_goal == previous_achieved_goal)
assert all(agent.desired_goal == previous_desired_goal)
agent.track_changeable_goal_episodes_data()
agent.save_experience()
if agent.done: agent.save_alternative_experience()
agent.state_dict = agent.next_state_dict # this is to set the state for the next iteration
agent.state = agent.next_state
states, actions, rewards, next_states, dones = agent.HER_memory.sample(4)
07-30
- 在医院值班室过了一夜,早起晨跑发现医院门口已经开始排队查核酸。扬州四例确诊,到处都开始紧张起来,这个老太确实很坑,瞒报行程还到处乱跑偷绿码。有点担心开学回不了校,好在水已经退去,电也修好了。
- WXY还是强,已经恢复到接近4分配的水平了。不过照这个态势,国内的马拉松估计又要受挫,至少南京马拉松肯定是没戏了,今年如果跑不了也是好事,多一些时间准备,上半年的比赛相对多一些,到时候争取练到能跑进一小时半,。其实跑步就是在不断受伤中寻求更好的跑法,从艰难到享受,跑得越久,体悟越深。
- 国乒无敌!
曹冲称象(给定若干石块及重量,给出称出大象重量所需的最少石块,有点类似集合划分问题)动态规划写法,感觉应该是要比穷举快不少的,这是前天有个同学来问我,不知道有没有更好的写法:
# -*- coding: utf-8 -*-
# @author: caoyang
# @email: caoyang@163.sufe.edu.cn
import random
N = 10
stones = set([str(i) for i in range(N)])
stone_weight = {stone: random.randint(1, 9) for stone in stones}
elephant_weight = 25
memory = {
0: [(set(), stones)]
}
max_weight = max(stone_weight.values())
for weight in range(1, elephant_weight + 1):
memory[weight] = []
for _weight in range(max(weight - max_weight, 0), weight):
for (_used_stones, _unused_stones) in memory[_weight]:
for _unused_stone in _unused_stones:
if _weight + stone_weight[_unused_stone] == weight:
used_stones = _used_stones.union({_unused_stone})
unused_stones = stones - used_stones
memory[weight].append((used_stones, unused_stones))
result = min(map(lambda x: len(x[0]), memory[elephant_weight]))
print(result)
07-31
- 新增10例,成功晋级中风险地区,艹。
- 晚上老爸从邗江区没敢开车回家,试图骑共享电动车抄小路躲开封锁,结果半路上没电… 正在步行十公里回公司。江都公交停运,高速口封闭,怕是返校无望了,安心刷完暑期课的分罢。
- 七月跑量123.75km,运动总时长1511分钟,眼看着要练出腹肌了哈哈,这两天状态还不错。
PRover逻辑推理模型模块(一):
from pytorch_transformers import BertPreTrainedModel, RobertaConfig, \
ROBERTA_PRETRAINED_MODEL_ARCHIVE_MAP, RobertaModel
from pytorch_transformers.modeling_roberta import RobertaClassificationHead
from torch.nn import CrossEntropyLoss, BCEWithLogitsLoss
import torch
import torch.nn as nn
from torch.nn.utils.rnn import pad_sequence
class RobertaForRR(BertPreTrainedModel):
config_class = RobertaConfig
pretrained_model_archive_map = ROBERTA_PRETRAINED_MODEL_ARCHIVE_MAP
base_model_prefix = "roberta"
def __init__(self, config):
super(RobertaForRR, self).__init__(config)
self.num_labels = config.num_labels
self.roberta = RobertaModel(config)
self.classifier = RobertaClassificationHead(config)
self.apply(self.init_weights)
def forward(self, input_ids, token_type_ids=None, attention_mask=None, labels=None, position_ids=None,
head_mask=None):
outputs = self.roberta(input_ids, position_ids=position_ids, token_type_ids=token_type_ids,
attention_mask=attention_mask, head_mask=head_mask)
sequence_output = outputs[0]
logits = self.classifier(sequence_output)
outputs = (logits,) + outputs[2:]
if labels is not None:
loss_fct = CrossEntropyLoss()
qa_loss = loss_fct(logits.view(-1, self.num_labels), labels.view(-1))
outputs = (qa_loss,) + outputs
return outputs # qa_loss, logits, (hidden_states), (attentions)
August 2021
08-01
- 扬州围城。邗江区已经高风险了,目前所在的江都区通往主城(邗江区、广陵区)的通道是只出不进的,市场似乎有那么点恐慌,听说连鸡蛋都买不到了… 不过全国各地的情况都不是很好,几乎遍地开花,南京禄口这次难辞其咎,秋后算账罢。
- 下周抽空沿S237省道往高邮方向试一次长距离的公路越野,估摸着路上的车会越来越少。其实也是一件好事,想去年二三月份也是如此,清静的地方跑着最舒服了。
PRover逻辑推理模型模块(二):
class RobertaForRRWithNodeLoss(BertPreTrainedModel):
config_class = RobertaConfig
pretrained_model_archive_map = ROBERTA_PRETRAINED_MODEL_ARCHIVE_MAP
base_model_prefix = "roberta"
def __init__(self, config):
super(RobertaForRRWithNodeLoss, self).__init__(config)
self.num_labels = config.num_labels
self.roberta = RobertaModel(config)
self.classifier = RobertaClassificationHead(config)
self.naf_layer = nn.Linear(config.hidden_size, config.hidden_size)
self.classifier_node = NodeClassificationHead(config)
self.apply(self.init_weights)
def forward(self, input_ids, token_type_ids=None, attention_mask=None, proof_offset=None, node_label=None, labels=None,
position_ids=None, head_mask=None):
outputs = self.roberta(input_ids, position_ids=position_ids, token_type_ids=token_type_ids,
attention_mask=attention_mask, head_mask=head_mask)
sequence_output = outputs[0]
cls_output = sequence_output[:, 0, :]
naf_output = self.naf_layer(cls_output)
logits = self.classifier(sequence_output)
max_node_length = node_label.shape[1]
batch_size = node_label.shape[0]
embedding_dim = sequence_output.shape[2]
batch_node_embedding = torch.zeros((batch_size, max_node_length, embedding_dim)).to("cuda")
for batch_index in range(batch_size):
prev_index = 1
sample_node_embedding = None
count = 0
for offset in proof_offset[batch_index]:
if offset == 0:
break
else:
rf_embedding = torch.mean(sequence_output[batch_index, prev_index:(offset+1), :], dim=0).unsqueeze(0)
prev_index = offset+1
count += 1
if sample_node_embedding is None:
sample_node_embedding = rf_embedding
else:
sample_node_embedding = torch.cat((sample_node_embedding, rf_embedding), dim=0)
# Add the NAF output at the end
sample_node_embedding = torch.cat((sample_node_embedding, naf_output[batch_index].unsqueeze(0)), dim=0)
# Append 0s at the end (these will be ignored for loss)
sample_node_embedding = torch.cat((sample_node_embedding, torch.zeros((max_node_length-count-1, embedding_dim)).to("cuda")), dim=0)
batch_node_embedding[batch_index, :, :] = sample_node_embedding
node_logits = self.classifier_node(batch_node_embedding)
outputs = (logits, node_logits) + outputs[2:]
if labels is not None:
loss_fct = CrossEntropyLoss()
qa_loss = loss_fct(logits.view(-1, self.num_labels), labels.view(-1))
node_loss = loss_fct(node_logits.view(-1, self.num_labels), node_label.view(-1))
total_loss = qa_loss + node_loss
outputs = (total_loss, qa_loss, node_loss) + outputs
return outputs # (total_loss), qa_loss, node_loss, logits, node_logits, (hidden_states), (attentions)
08-02
- 邵伯镇进江都区主城的路也用泥土堵死了,高速关口两道板加特警把守,以前最严重的时候也没有这么紧张过。明天老妈开始去高速口轮值测核酸,城区全面停工停产。
- 老爸困在家里上不了班,不过好在前天还是连夜抄小路走回来,要不然现在困在邗江区就更糟糕了。
- 其实除了扬州城区,下辖的江都区、高邮市、仪征市、宝应县,目前都还没有确诊病例,这几天一直没有出门,也不知道外面情况怎么样,老妈也不让出去跑步。这次扬州棋牌室真的是全国出名了,真是好事不出门,糗事传千里。
DQN的HER版本:
from agents.DQN_agents.DQN import DQN
from agents.HER_Base import HER_Base
class DQN_HER(HER_Base, DQN):
"""DQN algorithm with hindsight experience replay"""
agent_name = "DQN-HER"
def __init__(self, config):
DQN.__init__(self, config)
HER_Base.__init__(self, self.hyperparameters["buffer_size"], self.hyperparameters["batch_size"],
self.hyperparameters["HER_sample_proportion"])
def step(self):
"""Runs a step within a game including a learning step if required"""
while not self.done:
self.action = self.pick_action()
self.conduct_action_in_changeable_goal_envs(self.action)
if self.time_for_q_network_to_learn():
for _ in range(self.hyperparameters["learning_iterations"]):
self.learn(experiences=self.sample_from_HER_and_Ordinary_Buffer())
self.track_changeable_goal_episodes_data()
self.save_experience()
if self.done: self.save_alternative_experience()
self.state_dict = self.next_state_dict # this is to set the state for the next iteration
self.state = self.next_state
self.global_step_number += 1
self.episode_number += 1
def enough_experiences_to_learn_from(self):
"""Returns booleans indicating whether there are enough experiences in the two replay buffers to learn from"""
return len(self.memory) > self.ordinary_buffer_batch_size and len(self.HER_memory) > self.HER_buffer_batch_size
08-03
- 全民核检第一天,老妈早上六点多就出门,中午回来了一个小时,然后要今天值班一个通宵不回来,真的累死。下午出去边走边跑了十几公里,热得不行,不带补给想跑高邮公路线还是太勉强。
- 全镇三个核检点,队伍长度加起来得有一公里多,在户外又热又闷,这毛老太真的是太可恶了,全扬州人跟着她一起倒霉,今天终于给抓起来了。
PRover逻辑推理模型模块(三):
class RobertaForRRWithNodeEdgeLoss(BertPreTrainedModel):
config_class = RobertaConfig
pretrained_model_archive_map = ROBERTA_PRETRAINED_MODEL_ARCHIVE_MAP
base_model_prefix = "roberta"
def __init__(self, config):
super(RobertaForRRWithNodeEdgeLoss, self).__init__(config)
self.num_labels = config.num_labels
self.num_labels_edge = 2
self.roberta = RobertaModel(config)
self.naf_layer = nn.Linear(config.hidden_size, config.hidden_size)
self.classifier = RobertaClassificationHead(config)
self.classifier_node = NodeClassificationHead(config)
self.classifier_edge = EdgeClassificationHead(config)
self.apply(self.init_weights)
def forward(self, input_ids, token_type_ids=None, attention_mask=None, proof_offset=None, node_label=None,
edge_label=None, labels=None, position_ids=None, head_mask=None):
outputs = self.roberta(input_ids, position_ids=position_ids, token_type_ids=token_type_ids,
attention_mask=attention_mask, head_mask=head_mask)
sequence_output = outputs[0]
cls_output = sequence_output[:, 0, :]
naf_output = self.naf_layer(cls_output)
logits = self.classifier(sequence_output)
max_node_length = node_label.shape[1]
max_edge_length = edge_label.shape[1]
batch_size = node_label.shape[0]
embedding_dim = sequence_output.shape[2]
batch_node_embedding = torch.zeros((batch_size, max_node_length, embedding_dim)).to("cuda")
batch_edge_embedding = torch.zeros((batch_size, max_edge_length, 3*embedding_dim)).to("cuda")
for batch_index in range(batch_size):
prev_index = 1
sample_node_embedding = None
count = 0
for offset in proof_offset[batch_index]:
if offset == 0:
break
else:
rf_embedding = torch.mean(sequence_output[batch_index, prev_index:(offset+1), :], dim=0).unsqueeze(0)
prev_index = offset+1
count += 1
if sample_node_embedding is None:
sample_node_embedding = rf_embedding
else:
sample_node_embedding = torch.cat((sample_node_embedding, rf_embedding), dim=0)
# Add the NAF output at the end
sample_node_embedding = torch.cat((sample_node_embedding, naf_output[batch_index].unsqueeze(0)), dim=0)
repeat1 = sample_node_embedding.unsqueeze(0).repeat(len(sample_node_embedding), 1, 1)
repeat2 = sample_node_embedding.unsqueeze(1).repeat(1, len(sample_node_embedding), 1)
sample_edge_embedding = torch.cat((repeat1, repeat2, (repeat1-repeat2)), dim=2)
sample_edge_embedding = sample_edge_embedding.view(-1, sample_edge_embedding.shape[-1])
# Append 0s at the end (these will be ignored for loss)
sample_node_embedding = torch.cat((sample_node_embedding,
torch.zeros((max_node_length-count-1, embedding_dim)).to("cuda")), dim=0)
sample_edge_embedding = torch.cat((sample_edge_embedding,
torch.zeros((max_edge_length-len(sample_edge_embedding), 3*embedding_dim)).to("cuda")), dim=0)
batch_node_embedding[batch_index, :, :] = sample_node_embedding
batch_edge_embedding[batch_index, :, :] = sample_edge_embedding
node_logits = self.classifier_node(batch_node_embedding)
edge_logits = self.classifier_edge(batch_edge_embedding)
outputs = (logits, node_logits, edge_logits) + outputs[2:]
if labels is not None:
loss_fct = CrossEntropyLoss()
qa_loss = loss_fct(logits.view(-1, self.num_labels), labels.view(-1))
node_loss = loss_fct(node_logits.view(-1, self.num_labels), node_label.view(-1))
edge_loss = loss_fct(edge_logits.view(-1, self.num_labels_edge), edge_label.view(-1))
total_loss = qa_loss + node_loss + edge_loss
outputs = (total_loss, qa_loss, node_loss, edge_loss) + outputs
return outputs # (total_loss), qa_loss, node_loss, edge_loss, logits, node_logits, edge_logits, (hidden_states), (attentions)
08-04
- 早上听讲座看到韩冬梅又是一激灵,想到期末作业还是没交,笑死我了,她不想要,我们也不想交,绝了。
PRover逻辑推理模型模块(四):
class EdgeClassificationHead(nn.Module):
"""Head for sentence-level classification tasks."""
def __init__(self, config):
super(EdgeClassificationHead, self).__init__()
self.dense = nn.Linear(3*config.hidden_size, config.hidden_size)
self.dropout = nn.Dropout(config.hidden_dropout_prob)
self.out_proj = nn.Linear(config.hidden_size, config.num_labels)
def forward(self, features, **kwargs):
x = self.dropout(features)
x = self.dense(x)
x = torch.tanh(x)
x = self.dropout(x)
x = self.out_proj(x)
return x
08-05
- 跑休,女团轻松夺冠。
PRover逻辑推理模型模块(五):
class RRProcessorQA(DataProcessor):
def get_train_examples(self, data_dir):
return self._create_examples(
self._read_jsonl(os.path.join(data_dir, "train.jsonl")),
self._read_jsonl(os.path.join(data_dir, "meta-train.jsonl")))
def get_dev_examples(self, data_dir):
# Change these to test paths for test results
return self._create_examples(
self._read_jsonl(os.path.join(data_dir, "dev.jsonl")),
self._read_jsonl(os.path.join(data_dir, "meta-dev.jsonl")))
'''
return self._create_examples_leave_one_out(
self._read_jsonl(os.path.join(data_dir, "leave-one-out.jsonl"))
)
'''
def get_test_examples(self, data_dir):
return self._create_examples(
self._read_jsonl(os.path.join(data_dir, "test.jsonl")),
self._read_jsonl(os.path.join(data_dir, "meta-test.jsonl")))
def get_labels(self):
return [True, False]
def _create_examples(self, records, meta_records):
examples = []
for (i, (record, meta_record)) in enumerate(zip(records, meta_records)):
print(i)
assert record["id"] == meta_record["id"]
context = record["context"]
for (j, question) in enumerate(record["questions"]):
id = question["id"]
label = question["label"]
meta_data = meta_record["questions"]["Q" + str(j + 1)]
proofs = meta_data["proofs"]
#if "CWA" in proofs:
# continue
#if question["meta"]["QDep"] != 3:
# continue
question = question["text"]
examples.append(RRInputExampleQA(id, context, question, label))
return examples
def _create_examples_leave_one_out(self, records):
examples = []
for record in records:
examples.append(RRInputExampleQA(record["id"], record["context"], record["question"], record["label"]))
return examples
完篇记
差不多只有三个月时间就写到上限字数了,看来这三个月我的话是有些多。作为一个阶段性的结束,写些东西免得虎头蛇尾。
最近状态不是很好,外婆好像突然生病了。老妈今晚又是将近十一点才回来,不过江都区的核检应该快要结束了,因为没有出大问题。我和老爸已经在家里关了快两周的禁闭,每天除了吃饭睡觉,就是跑步和码字,实在是没有什么事情可写。事实上也不太做得进去东西,连想静下心看点番的耐性都没有,前一阵子还能认真听完了前15场讲座,今天中午就直接挂机睡觉了,起来再看自己已经是会议室的主持人了[Facepalm]。不过最近还是有些灵感,在做一些有趣的工作,或许有空会再写点博客。
这里先分享一个python写得截屏小脚本(因为最近把C盘WindowsApp文件夹清空掉之后,所有WIN10自带的软件都用不了了,包括计算器和截屏之类的。而且新机连微信都没装,只能手动写个截屏的凑合,要不然还得printscreen再到word里裁剪,实在是太蠢,这个脚本只要点一下需要截屏部分的左上角和右下角即可实现截屏,用的是pynput的鼠标事件监听来实现的):
import cv2
import time
import numpy
import pyautogui
from pynput.mouse import Controller
from pynput import mouse
def screenshot():
with open('temp/screenshot.log', 'w') as f:
pass
global count, image
print('Prepare for Screenshot ...')
time.sleep(2)
image = pyautogui.screenshot()
image = cv2.cvtColor(numpy.asarray(image), cv2.COLOR_RGB2BGR)
count = 0
def _on_move(x, y):
return True
def _on_click(x, y, button, pressed):
global count, image
if pressed:
return True
count += 1
with open('temp/screenshot.log', 'a') as f:
f.write(f'{x}\t{y}\n')
if count < 2:
return True
with open('temp/screenshot.log', 'r') as f:
lines = f.read().splitlines()
x1, x2 = list(map(int, lines[0].split('\t')))
y1, y2 = list(map(int, lines[1].split('\t')))
image = image[x2: y2, x1: y1, :]
cv2.imwrite(f'temp/image-{time.strftime("%Y%m%d%H%M%S")}.png', image)
return False
def _on_scroll(x, y, dx, dy):
return True
with mouse.Listener(on_move=_on_move, on_click=_on_click, on_scroll=_on_scroll) as listener:
listener.join()
然后顺便汇总一下python里截屏的所有方法,大概有三四种,截屏图片的channel次序稍有区别,用之前先确认一下。
# 方法一
import pyautogui
import cv2
img = pyautogui.screenshot(region=[0,0,100,100]) # x,y,w,h
# img.save('screenshot.png')
img = cv2.cvtColor(np.asarray(img),cv2.COLOR_RGB2BGR)
# 方法二
from PyQt5.QtWidgets import QApplication
from PyQt5.QtGui import *
import win32gui
import sys
hwnd = win32gui.FindWindow(None, 'C:\Windows\system32\cmd.exe')
app = QApplication(sys.argv)
screen = QApplication.primaryScreen()
img = screen.grabWindow(hwnd).toImage()
img.save("screenshot.jpg")
# 方法三
import win32gui
hwnd_title = dict()
def get_all_hwnd(hwnd,mouse):
if win32gui.IsWindow(hwnd) and win32gui.IsWindowEnabled(hwnd) and win32gui.IsWindowVisible(hwnd):
hwnd_title.update({hwnd:win32gui.GetWindowText(hwnd)})
win32gui.EnumWindows(get_all_hwnd, 0)
for h,t in hwnd_title.items():
if t is not "":
print(h, t)
# 方法四
import time
import numpy as np
from PIL import ImageGrab
img = ImageGrab.grab(bbox=(100, 161, 1141, 610))
img = np.array(img.getdata(), np.uint8).reshape(img.size[1], img.size[0], 3)
总是想出去走走,憋坏了。每天跑步机五公里,跑三休一,跑前跑后坚持拉伸,慢慢地腿已经恢复得很好了,看着外面空旷的街道心里总是痒痒的,自从回家后就再没有跑过10km以上的里程,今年的半马八成也泡汤了。也不知道这该死的疫情啥时候能过去,好像刘天浩也在扬州,不过他那儿是重灾区,估计比我的处境要惨,返校我们肯定都是逃不了要隔离的。
虽然但是,还是说了很多废话,因为也不知道该写一些什么作为结束。总之在家还是有好处的,至少不需要想什么破事,就这样慢慢地生活,没有人来叨扰。生活本该如此,不温不火是日常,但应当保持内心始终在炽热,也许跑不到那么远,但是至少应当燃烧到最后一刻。
—— 永远奔跑,无论是否年轻。
2021年8月12日 0:34 囚生
[本文完]
新篇发布于:https://www.jianshu.com/p/a1623d2c757b


















 59万+
59万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









