







文章目录
- 20240401(首马20日)
- 20240402(首马19日)
- 20240403(首马18日)
- 20240404(首马17日)
- 20240405(首马16日)
- 20240406(首马15日)
- 20240407(首马14日)
- 20240408(首马13日)
- 20240409(首马12日)
- 20240410(首马11日)
- 20240411(首马10日)
- 20240412(首马9日)
- 20240413~20240414(首马7日,完结?)
- 20240415(首马6日)
- 20240416(首马5日)
- 20240417(首马4日)
- 20240418(~~首马3日~~)
- 20240419(~~首马2日~~)
- 20240420(~~首马1日~~)
- 20240421(完篇)
20240401(首马20日)
- 整体来说,今年扬州办得不错,物资丰富,观众热情,加之天气锦上添花,极大扭转去年不利的印象。今天下肢酸痛,集中在大腿前侧和右脚踝,遂休整一日,明日返沪。因为昨天拉伸是在接驳车上进行,不够充分,交通管制,老爹懒得绕路来终点接我,我也是服了。
- 中国马拉松官方网站上可以查成绩,LXY芜湖10K,净时间48’58",枪声49’36",前半程24’50",后半程24’08",全程负配速,不说是竭尽全力,也算是养老慢跑。或许是状态不好,也可能是生理原因,至少我觉得她全力一定是能跑进45分钟。
- 手头还有一份2018级以前的本科生身份信息文件,顺手查了几个人的PB:
- AK:20场比赛,恐怖如斯,半马1:13:56(2019新江湾城,他来过两次扬州,分别跑出125和120),全马2:41:05(2019哈尔滨)
- WXY:半马1:24:24(2021南京仙林),全马3:23:46(2023成都)
- MK(前队):半马1:30:18(2018扬州),全马3:20:15(2019无锡)
- 五年前的AK和MK,三年前的WXY和WBJ,如今的嘉伟和我,可以算是现役中长双子星。我的群昵称一直是陈嘉伟老粉,嘉伟前两年飞速的进步,我却停滞不前,他的有氧域配速一度比我快近30秒,鸿沟般的差距,一年多来依然愿意带着我训练。去年夏训,4’05"的配速,我气喘吁吁说不上话,他却和GZY谈笑风生,让我汗颜。如今,我终于能跟他掰一下手腕。希望在一次比赛中,正面击败嘉伟,将是我对他最大的敬意。
顺手写个爬虫,从中国马拉松官网上抓一下看看目前上财历届校友的马拉松成绩,暂缺滑动验证的模拟,可以使用ActionChains实现,如:
from selenium import webdriver
from selenium.webdriver.common.action_chains import ActionChains
driver = webdriver.Chrome() # 启动浏览器驱动
driver.get("http://example.com") # 打开网页
element = driver.find_element_by_id("element_id") # 定位元素
ActionChains(driver).move_to_element(element).perform() # 使用ActionChains模拟鼠标移动到元素上
driver.quit()
关键的方法:
click(on_element=None) ——单击鼠标左键
click_and_hold(on_element=None) ——点击鼠标左键,不松开
context_click(on_element=None) ——点击鼠标右键
double_click(on_element=None) ——双击鼠标左键
drag_and_drop(source, target) ——拖拽到某个元素然后松开
drag_and_drop_by_offset(source, xoffset, yoffset) ——拖拽到某个坐标然后松开
key_down(value, element=None) ——按下某个键盘上的键
key_up(value, element=None) ——松开某个键
move_by_offset(xoffset, yoffset) ——鼠标从当前位置移动到某个坐标
move_to_element(to_element) ——鼠标移动到某个元素
move_to_element_with_offset(to_element, xoffset, yoffset) ——移动到距某个元素(左上角坐标)多少距离的位置
perform() ——执行链中的所有动作
release(on_element=None) ——在某个元素位置松开鼠标左键
send_keys(*keys_to_send) ——发送某个键到当前焦点的元素
send_keys_to_element(element, *keys_to_send) ——发送某个键到指定元素
模拟代码:
# -*- coding: utf-8 -*-
# @author: caoyang
# @email: caoyang@stu.sufe.edu.cn
import re
import time
from bs4 import BeautifulSoup
from selenium import webdriver
from selenium.webdriver.support.ui import WebDriverWait
url_host = "https://www.runchina.org.cn/"
def initialize_driver():
# 初始化浏览器驱动
driver = webdriver.Chrome(chrome_options=chrome_options)
driver.set_page_load_timeout(15)
driver.maximize_window()
return driver
# 姓名和身份证号的生成器
def generate_name_and_id():
regex = re.compile("身份证,\d{17}[\dX]")
data_path = r"D:\$old\studentInfo.csv"
with open(data_path, 'r', encoding="utf8") as f:
while True:
line = f.readline()
if not line:
break
name = line.split(',', 2)[1]
matched_results = regex.findall(line)
if matched_results:
id_ = matched_results[0][-18: ]
else:
id_ = None
yield name, id_
def score_query():
url_score_query = url_host + "#/data/data-mgt/score-query"
xpath_input_box_name = "//div[@placeholder=\"请填写您的证件姓名\"]"
xpath_input_box_id = "//div[@placeholder=\"请填写您的证件号码\"]"
xpath_scroll_button = "//div[@class=\"icon nc-iconfont icon-slide-arrow\"]" # 用于验证的按钮
xpath_send_button = "//p[@class=\"search_button\"]" # 提交按钮
# TODO: 拖动滑动验证的按钮并右移松开
def _click_and_move(_driver):
NotImplemented
for name, id_ in generate_name_and_id():
driver = initialize_driver()
driver.get(url_score_query)
driver.find_element_by_xpath(xpath_input_box_name).send_keys(name)
driver.find_element_by_xpath(xpath_input_box_id).send_keys(id_)
_click_and_move(driver)
driver.find_element_by_xpath(xpath_send_button).send_keys(id_)
results = is_achievement_container_existed()
with open("grade.txt", 'a', encoding="utf8") as f:
f.write(f"{id_}\t{results}\n")
driver.quit()
# 判断是否有成绩
# TODO: 有成绩的条件下,寻找PB成绩,或返回所有成绩
def is_achievement_container_existed(driver):
xpath_1 = "//div[@class=\"achievement_container\"]"
if driver.find_element_by_xpath(xpath_1) is not None:
return True
else:
return False
if __name__ == "__main__":
score_query()
20240402(首马19日)
- 最近两天状态非常低落,无关人和事,单纯因为精力耗尽,以及作息饮食紊乱:
- 31号本来就没睡多久,赛后又马不停蹄地开车带老爹回乡下把清明的事提前办了,下午到家已经快三点,时间太晚不想补觉,一直挨到晚上十一点才睡,手表显示身体电量只剩3%,困乏到了极致。
- 但昨天又不到七点就醒了,脚踝疼痛,一天没出门,这人一懒就容易贪食,吃了一堆零食(甜食是真的毒品,吃了整整一包山楂卷和四块巧克力糖,我忌口了三个月,只在饭点猛吃,昨天一破戒就停不下来了),晚上做了些核心训练才让负罪感稍减了些,但今天明显身体就有笨重感,吃饭都不香了。
- 今天右脚踝依然疼痛,只能用后跟跑,前掌跑完全支撑不住。组会前去操场,嘉伟27圈@3’40",我就顺便带着XR做力量训练(正好已两周没有力量训练),负重箭步30个×8组(+20kg),XR因为是第一次做,给他拿了块10kg的片先试试,看起来歪歪扭扭特别吃力,跟我刚进队时一模一样(那时也觉得10kg很重,现在20kg都没啥感觉了),没有人生而强大,都是从弱小慢慢成长起来,不过他这小子野心倒挺大,想今年就把5000米跑进18分半,这个成绩对我来说都不算容易(不过,假如有嘉伟带我跑,我有把握全盛状态下破开18分大关)。
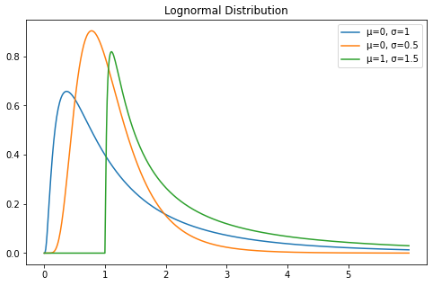
对数正态分布:
X = np.linspace(0, 6, 500)
std = 1
mean = 0
lognorm_distribution = stats.lognorm([std], loc=mean)
lognorm_distribution_pdf = lognorm_distribution.pdf(X)
fig, ax = plt.subplots(figsize=(8, 5))
plt.plot(X, lognorm_distribution_pdf, label="μ=0, σ=1")
ax.set_xticks(np.arange(min(X), max(X)))
std = 0.5
mean = 0
lognorm_distribution = stats.lognorm([std], loc=mean)
lognorm_distribution_pdf = lognorm_distribution.pdf(X)
plt.plot(X, lognorm_distribution_pdf, label="μ=0, σ=0.5")
std = 1.5
mean = 1
lognorm_distribution = stats.lognorm([std], loc=mean)
lognorm_distribution_pdf = lognorm_distribution.pdf(X)
plt.plot(X, lognorm_distribution_pdf, label="μ=1, σ=1.5")
plt.title("Lognormal Distribution")
plt.legend()
plt.show()
20240403(首马18日)
- 脚踝走路已经无碍,感觉自己又行了。下午四点去操场想试着前掌跑会儿,还是疼得厉害,脚踝依然无法承重。正好韬哥在冲3000米,配速3’50",气喘吁吁,他可是1500米能跑到4’45"以内的,这学期忙着实习,是真的虚了唉。
- 拉了几组单杠,陪韬哥摇了两圈就撤了。晚上NRC在跑百巷有活动,由于上周六开营仪式没去参加,我想着还是不能翘得太狠,正好去把衣服鞋子拿一下,骑车来回25km也算是恢复训练(主要是坐地铁还没骑车快,杨浦到静安这条线确实不方便)。AK晚上下班回来带着四五个小朋友一起跑,跟我讲这样挺好,其实学校里能跑的人还是有的,而且女生也有,下次去捞几个来平衡一下群里的男女比例。
- 首马临近,伤痛迟迟未愈,有些不顺心。4月14日的江阴半马大概还是要去的,就当是首马前的一次长距离拉练,也确实没去过江阴,也便是去游玩两日。依然没有人陪我一起,江阴这场我可以给别人当一回私兔,或许遇到有缘人,带ta跑一程吧。
其他几个常用分布:
# 泊松分布
from scipy import stats
print(stats.poisson.pmf(k=9, mu=3))
X = stats.poisson.rvs(mu=3, size=500)
plt.subplots(figsize=(8, 5))
plt.hist(X, density=True, edgecolor="black")
plt.title("Poisson Distribution")
plt.show()
# 指数分布
X = np.linspace(0, 5, 5000)
exponetial_distribtuion = stats.expon.pdf(X, loc=0, scale=1)
plt.subplots(figsize=(8,5))
plt.plot(X, exponetial_distribtuion)
plt.title("Exponential Distribution")
plt.show()
# 二项分布
X = np.random.binomial(n=1, p=0.5, size=1000)
plt.subplots(figsize=(8, 5))
plt.hist(X)
plt.title("Binomial Distribution")
plt.show()
# t分布
import seaborn as sns
from scipy import stats
X1 = stats.t.rvs(df=1, size=4)
X2 = stats.t.rvs(df=3, size=4)
X3 = stats.t.rvs(df=9, size=4)
plt.subplots(figsize=(8,5))
sns.kdeplot(X1, label = "1 d.o.f")
sns.kdeplot(X2, label = "3 d.o.f")
sns.kdeplot(X3, label = "6 d.o.f")
plt.title("Student's t distribution")
plt.legend()
plt.show()
# 卡方分布
X = np.arange(0, 6, 0.25)
plt.subplots(figsize=(8, 5))
plt.plot(X, stats.chi2.pdf(X, df=1), label="1 d.o.f")
plt.plot(X, stats.chi2.pdf(X, df=2), label="2 d.o.f")
plt.plot(X, stats.chi2.pdf(X, df=3), label="3 d.o.f")
plt.title("Chi-squared Distribution")
plt.legend()
plt.show()
20240404(首马17日)
- 停跑4天,本来计划清明节是要跑一个30-35K,这样看至少要停跑一周,只用不到两周时间能恢复到破三的能力么,感觉真的很困难。
- 最近几天的活动消耗低得可怕,今天好不容易才上到800C以上。下午找嘉伟练了会儿球,感觉体力都变差了。年后其实还没跟嘉伟打过,虽然依然不是对手,但是明显要比之前好多了。
- 巅峰之后总是低谷,慢慢来吧,也不必太焦虑,总会跑得起来的。
审稿人通常会有以下几类问题针对不同问题我们可以有不同的回答模板。
切记:一定展现出诚意,虚心回答,point by point,不要刻意回避某些问题。
补充实验/仿真模拟类:
这类问题通常都很复杂,切忌回避问题。真的要做到点到点回答。你所要回避的问题审稿人都能发现。所以即使我们现有条件解决不了,我们也要向审稿人承认。不要自欺欺人。
我感觉对面一些
Thank you for suggesting the addition of experimental data. We have conducted the experiments as advised, and the results indeed align with the theoretical expectations.
Thank you for............We appreciate your recommendation to include supplementary experiments. The results obtained are in line with the theoretical predictions, confirming our initial hypothesis.
Thank you for............Following your suggestion, we have carried out additional experiments. The results obtained are consistent with the theoretical framework, supporting our conclusions.
Thank you for............We have conducted the recommended experiments, and the results obtained confirm the anticipated outcomes based on the theoretical assumptions. Thank you for guiding us in this direction.
Thank you for............Upon conducting the supplementary experiments as suggested, we found that the results align closely with the theoretical expectations. Your advice proved to be invaluable in strengthening our research.
Thank you for emphasizing the importance of additional experiments. The results obtained are in accordance with the theoretical predictions, further solidifying the validity of our findings.
Thank you for............We have taken your feedback into consideration and conducted the recommended experiments. The results obtained match the theoretical expectations outlined in the paper, providing robust support for our arguments.
Thank you for............The additional experiments performed as per your suggestion have yielded results that are in line with the theoretical predictions. Thank you for prompting us to further validate our findings through experimentation.
Thank you for............Based on your recommendation, we have carried out supplementary experiments. The results obtained are consistent with the theoretical framework proposed in the paper, reinforcing the validity of our research.
Thank you for............We have followed your advice and conducted the supplementary experiments. The results obtained support the theoretical expectations outlined in our study. Your guidance has been instrumental in enhancing the rigor of our research.
20240405(首马16日)
- 这两天高强度打球,下午两点又陪王京练一小时球,我本以为现在打得勉强能看,但真特么随便来个人都能虐我,计分四把,全是大比分输,绷不住一点。
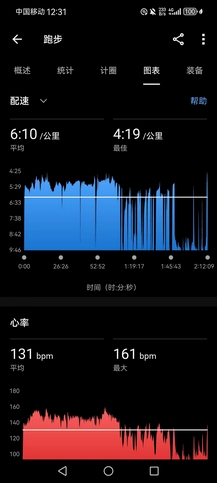
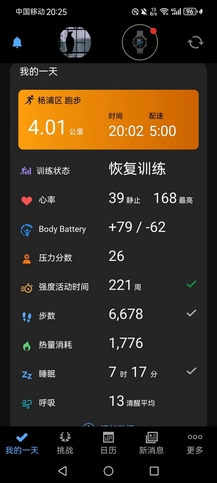
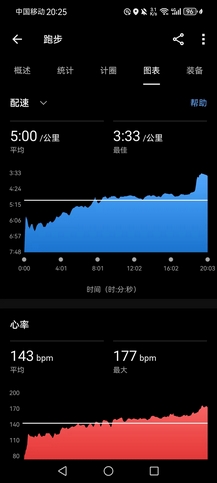
- 好消息是今天终于能跑起来了,右脚可以单脚踮起。午饭后去操场小憩,阳光明媚,气温也不是很高,今年清明节确实是出行的好天气。起来慢跑,配速4’19",但是六圈后,右脚踝还是明显疼痛,还是不勉强。拉了几组单杠,坐两组提踵结束,
- 晚上火车头体育场NRC训练,精英组400米@1’20"(间歇60秒),大概有10个人全程跟完课表(精英组基本上是全马245到300水平的)。我原计划签个完,量力而行,跟个几组就提前溜,毕竟白天消耗已经挺大,而且脚伤尚不明确,但是跟高手一起跑就明显兴奋得很,课表圈速是1’22"-1’28",但是众所周知一群人是没有诚信可言的,前面几个带队的很快就把圈速拉到1’20"以内,神奇的是,我居然并不吃力(已经停跑四天)。
- 10组之后,我确信自己一定可以顶完20组,此时教练提醒再这么快就要给你们加量了,一个个老实了点。最后五组,我觉得自己有余力,开始跟着第一集团猛冲,分别跑出1’17",1’13"(从最后一位超到第一位),1’17",1’20"(这一组收着了,留给最后一组冲刺),1’13"的圈速,一位大哥在我后面喊,最前面那位是谁,这么猛?步伐真大,冲过来我都害怕,给诸位一点小小的震撼。(要是嘉伟能来,指定降维打击。嘉伟这次锡马真是越想越可惜,能进245真就圆满了)。
- 今日活动消耗1700C+,持平31号扬马那日的活动消耗,极大地扭转了前四日不振的状态。400米间歇确是极好的恢复训练(进入状态后越跑越轻松,以前下班回来就算再累,12组400米变速也能轻松跑完),我确信已基本恢复到全盛状态。接下来就是无伤坚持到首马开赛,我已做好付出代价的准备(这次半马确实顶到极限,脚踝应该是肌肉疲劳,损伤多少也有,可想而知全马如果顶到极限,肯定不会是无伤),哪怕最后只能跪着爬回来。
GaLore在本地GPU进行LLM调优:
安装依赖
pip install galore-torch
datasets==2.18.0
transformers==4.39.1
trl==0.8.1
accelerate==0.28.0
torch==2.2.1
调度优化器类:
from typing import Optional
import torch
# Approach taken from Hugging Face transformers https://github.com/huggingface/transformers/blob/main/src/transformers/optimization.py
class LayerWiseDummyOptimizer(torch.optim.Optimizer):
def __init__(self, optimizer_dict=None, *args, **kwargs):
dummy_tensor = torch.randn(1, 1)
self.optimizer_dict = optimizer_dict
super().__init__([dummy_tensor], {"lr": 1e-03})
def zero_grad(self, set_to_none: bool = True) -> None:
pass
def step(self, closure=None) -> Optional[float]:
pass
class LayerWiseDummyScheduler(torch.optim.lr_scheduler.LRScheduler):
def __init__(self, *args, **kwargs):
optimizer = LayerWiseDummyOptimizer()
last_epoch = -1
verbose = False
super().__init__(optimizer, last_epoch, verbose)
def get_lr(self):
return [group["lr"] for group in self.optimizer.param_groups]
def _get_closed_form_lr(self):
return self.base_lrs
加载GaLore优化器对象
from transformers import get_constant_schedule
from functools import partial
import torch.nn
import bitsandbytes as bnb
from galore_torch import GaLoreAdamW8bit
def load_galore_optimizer(model, lr, galore_config):
# function to hook optimizer and scheduler to a given parameter
def optimizer_hook(p, optimizer, scheduler):
if p.grad is not None:
optimizer.step()
optimizer.zero_grad()
scheduler.step()
# Parameters to optimize with Galore
galore_params = [
(module.weight, module_name) for module_name, module in model.named_modules()
if isinstance(module, nn.Linear) and any(target_key in module_name for target_key in galore_config["target_modules_list"])
]
id_galore_params = {id(p) for p, _ in galore_params}
# Hook Galore optim to all target params, Adam8bit to all others
for p in model.parameters():
if p.requires_grad:
if id(p) in id_galore_params:
optimizer = GaLoreAdamW8bit([dict(params=[p], **galore_config)], lr=lr)
else:
optimizer = bnb.optim.Adam8bit([p], lr = lr)
scheduler = get_constant_schedule(optimizer)
p.register_post_accumulate_grad_hook(partial(optimizer_hook, optimizer=optimizer, scheduler=scheduler))
# return dummies, stepping is done with hooks
return LayerWiseDummyOptimizer(), LayerWiseDummyScheduler()
20240406(首马15日)
- 昨晚练完就很奇怪,为什么中午慢跑6圈就觉得右脚踝酸得受不了,但是到晚上,明明消耗更大,骑到火车头时,身体感觉很疲劳,不像是能上得了强度的状态,但20组400米间歇就是硬顶了下来,右脚踝一点事都没有。今天想趁热打铁,跑个30K,感觉昨天休息得很好,首马前也急缺长距离拉练。
- 但只跑了4K,脚踝就有些受不了,大失所望,后面去操场冲了三组400米间歇,反而很轻松,我想可能是触地时间的区别,脚踝耐受也确实不行了,不知还要多久才能恢复到之前的状态。
- 晚饭后补了8组×30箭步(+20kg),也明显比4月2日那天做得吃力,这两天越来越吃不准状态。回楼想要再跳会儿绳,试图小强度恢复脚踝力量,跳了几十个后,决心还是放弃。
- 真的止于三月了,吗?
- 我不甘心

HF Trainer
from transformers import AutoTokenizer, AutoModelForCausalLM, TrainingArguments, set_seed, get_constant_schedule
from trl import SFTTrainer, setup_chat_format, DataCollatorForCompletionOnlyLM
from datasets import load_dataset
import torch, torch.nn as nn, uuid, wandb
lr = 1e-5
# GaLore optimizer hyperparameters
galore_config = dict(
target_modules_list = ["attn", "mlp"],
rank = 1024,
update_proj_gap = 200,
scale = 2,
proj_type="std"
)
modelpath = "meta-llama/Llama-2-7b"
model = AutoModelForCausalLM.from_pretrained(
modelpath,
torch_dtype=torch.bfloat16,
attn_implementation = "flash_attention_2",
device_map = "auto",
use_cache = False,
)
tokenizer = AutoTokenizer.from_pretrained(modelpath, use_fast = False)
# Setup for ChatML
model, tokenizer = setup_chat_format(model, tokenizer)
if tokenizer.pad_token in [None, tokenizer.eos_token]:
tokenizer.pad_token = tokenizer.unk_token
# subset of the Open Assistant 2 dataset, 4000 of the top ranking conversations
dataset = load_dataset("g-ronimo/oasst2_top4k_en")
training_arguments = TrainingArguments(
output_dir = f"out_{run_id}",
evaluation_strategy = "steps",
label_names = ["labels"],
per_device_train_batch_size = 16,
gradient_accumulation_steps = 1,
save_steps = 250,
eval_steps = 250,
logging_steps = 1,
learning_rate = lr,
num_train_epochs = 3,
lr_scheduler_type = "constant",
gradient_checkpointing = True,
group_by_length = False,
)
optimizers = load_galore_optimizer(model, lr, galore_config)
trainer = SFTTrainer(
model = model,
tokenizer = tokenizer,
train_dataset = dataset["train"],
eval_dataset = dataset['test'],
data_collator = DataCollatorForCompletionOnlyLM(
instruction_template = "<|im_start|>user",
response_template = "<|im_start|>assistant",
tokenizer = tokenizer,
mlm = False),
max_seq_length = 256,
dataset_kwargs = dict(add_special_tokens = False),
optimizers = optimizers,
args = training_arguments,
)
trainer.train()
20240407(首马14日)
- 一日细雨,似是清明大好天气的代价,好像给了我偷懒的理由。
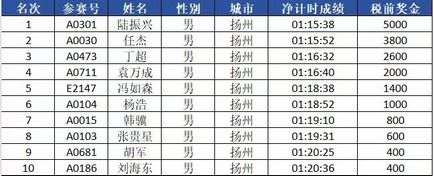
- 扬马市民前十出炉,瞋目结舌,除E区杀出个程咬金,其余九位全是A区大佬,第一1:15:38,第十1:20:36,往年120已是市民第一的水平,今年竟然连前十都悬,这两年大众水平进步太大,之前还以为稳进前十,沾沾自喜,到头来小丑竟是我自己🤡。
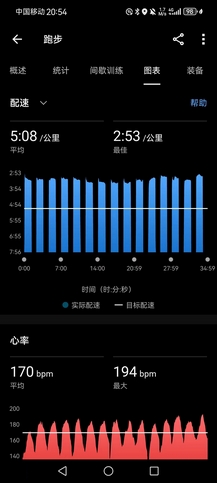
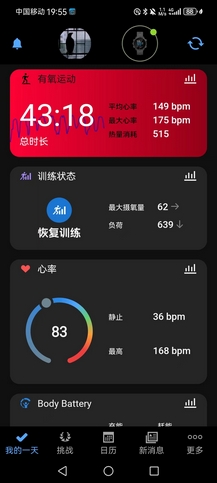
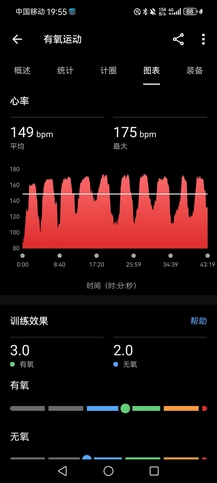
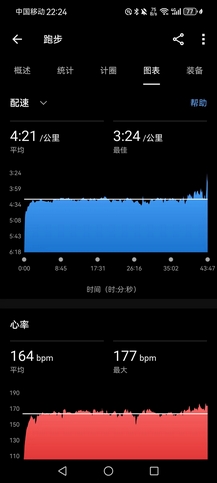
- 晚上室内训练,爬楼10组(B1~15F),用时43’18",平均一组上下楼4’20",平均心率149bpm,最大心率175bpm,去年每组一般在4’40",但心率不会超过160bpm。结束补1000×单摇+200×双摇,以及平地提踵(台阶上提踵针对的是小腿,平地提踵则针对脚踝),旨在恢复脚踝力量,现在的情况应该不算太坏,就是右脚踮起承重整个身体,15分钟左右就会有酸痛感。
- 很多时候我们无法既要、又要。伤痛在所难免,最近因为加入NRC,第一次开始用小红书,发现嘉伟也经常发些帖子,他三月跑量230km,平均配速4’10",跟我差不太多,最近也是受锡马的伤痛困扰,他也并没有完全恢复,就开始上大强度。AK去年柴古唐斯越野赛回来,休整近两个月,却依然保持极好的竞技状态。总觉得自己前路无多,今年不破,这辈子就没机会再破三了。或许到底是走得太少。AK长我两岁有余,大大小小的比赛参加了不下三四十场,经验和心态都比我俩要好不少。
- PS:4月21日安阳马拉松,全马2000人,半马3000人,都报不满,实际参赛人数可能会更少,给各高校机构发请帖,倒贴请人来参赛,质量属实令人担忧。说起来WYY就是安阳人,虽已分道扬镳,但这种规模倒确实适合刷成绩,但我实在不想舟车劳顿。首马定于南通,就像考试从来不会提前交卷一样,这次无论状态如何,我都会坚持训练,严阵以待,直到最后一天的到来。
LlamaIndex构建RAG应用:
from llama_index.llms import ChatMessage, OpenAILike
llm = OpenAILike(
api_base="http://localhost:1234/v1",
timeout=600, # secs
api_key="loremIpsum",
is_chat_model=True,
context_window=32768,
)
chat_history = [
ChatMessage(role="system", content="You are a bartender."),
ChatMessage(role="user", content="What do I enjoy drinking?"),
]
output = llm.chat(chat_history)
print(output)
对比LangChain:
from langchain.schema import HumanMessage, SystemMessage
from langchain_openai import ChatOpenAI
llm = ChatOpenAI(
openai_api_base="http://localhost:1234/v1",
request_timeout=600, # secs, I guess.
openai_api_key="loremIpsum",
max_tokens=32768,
)
chat_history = [
SystemMessage(content="You are a bartender."),
HumanMessage(content="What do I enjoy drinking?"),
]
print(llm(chat_history))
LangChain区分了聊天llm(ChatOpenAI)和llm(OpenAI),而LlamaIndex在构造函数中使用is_chat_model参数来进行区分。
LlamaIndex区分官方OpenAI端点和openaillike端点,而LangChain通过openai_api_base参数决定向何处发送请求。
LlamaIndex用role参数标记聊天消息,而LangChain使用单独的类。
20240408(首马13日)
- 昨夜失眠,难以置信,三月上旬离职回校后,保持了一个月的规律作息彻底破戒。6点起来先把早饭吃了,再补觉到中午11点起来吃午饭,还是得按点吃饭,勉强把饮食给控制住。其实真没啥心事,这次就是情绪控制太差,之前太顺,稍遇些挫折就变得急躁。下午头疼,感觉状态一落千丈。
- 晚饭后慢跑10圈,配速4’08",感觉特别疲累,但比前天情况好,右脚踝并没有疼痛。又看到寒假冬训时见过两三次的那个矮个女生,群里现在男女比例失调,准备捞些学妹来平衡一下,毕竟女性高手在上财还是太稀缺,本想等她跑完再去加,结果她一路出操场直接跑回去,下次得直接在门口逮人。
- 上财在校生的长跑水平明显提升许多,2021年参加完高百后,我就很想能组织一支全部由在校生组成的队伍再征战一回高百,那时全队破40分的选手一个都没有。如今,AK可破35分,嘉伟可破36分,我,宋某、小崔都已具备38分以内的水平,安迪、胡哥冲一冲肯定也能开40分,唯独缺少2名女性高手。这个夏天跟AK和嘉伟再组织一次夏训,头部几个选手的水平有望再拔高一个档次。其实我也不知道自己还能否参加,但是我很希望有一天,上财也能在高百拿到前十的席位,就像《强风吹拂》里那样,上财也有自己的竹青庄。
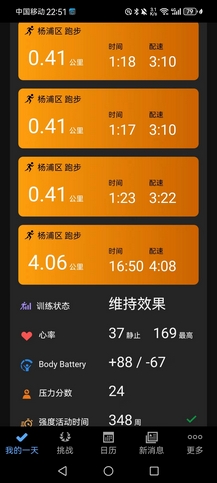
- 今晚带XR,YY,LZR跑万米,配速4’21"。后面嘉伟和AK到场,配速3’50"~4’00"带队,他们仨还能跟着我们仨再跑上两三圈,估摸着这三人5000米都是能跑进20分钟的。我其实带完万米后,感觉状态好转许多,觉得再来一个40分钟的万米也不在话下,原来宋某是对的,通宵熬夜真的有用(大雾),但是跟着嘉伟3’51"配速跑到3000米后,右脚踝终于还是顶不住,不再勉强。
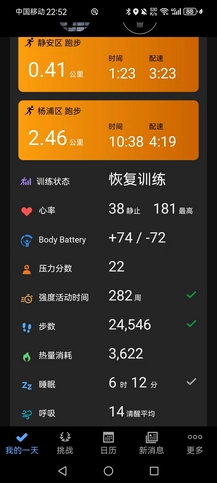
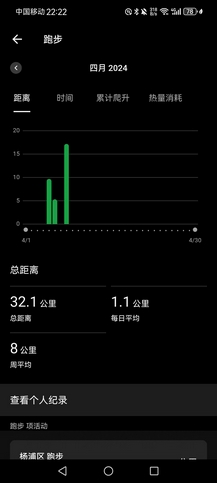
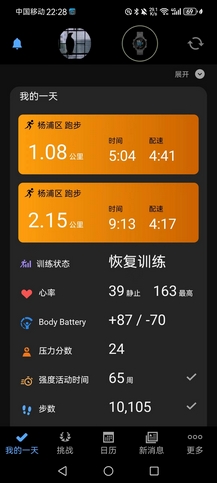
- PS:四月目前总跑量32.1km,今天17.1km,比前七天加起来都多,伤痛,荒废得太久。晚上这个万米我带得还是很稳的,最后两圈加到4分配,他们三个都还能顶得住,全部PB,真的很不错,尤其LZR和YY都还是大一新生,后继有人。
从本地文件夹读取文本:
from llama_index import ServiceContext, SimpleDirectoryReader, VectorStoreIndex
service_context = ServiceContext.from_defaults(
embed_model="local",
llm=llm, # This should be the LLM initialized in the task above.
)
documents = SimpleDirectoryReader(
input_dir="mock_notebook/",
).load_data()
index = VectorStoreIndex.from_documents(
documents=documents,
service_context=service_context,
)
engine = index.as_query_engine(
service_context=service_context,
)
output = engine.query("What do I like to drink?")
print(output)
对比LangChain:
from langchain_community.document_loaders import DirectoryLoader
# pip install "unstructured[md]"
loader = DirectoryLoader("mock_notebook/", glob="*.md")
docs = loader.load()
from langchain.text_splitter import RecursiveCharacterTextSplitter
text_splitter = RecursiveCharacterTextSplitter(chunk_size=1000, chunk_overlap=200)
splits = text_splitter.split_documents(docs)
from langchain_community.embeddings.fastembed import FastEmbedEmbeddings
from langchain_community.vectorstores import Chroma
vectorstore = Chroma.from_documents(documents=splits, embedding=FastEmbedEmbeddings())
retriever = vectorstore.as_retriever()
from langchain import hub
# pip install langchainhub
prompt = hub.pull("rlm/rag-prompt")
def format_docs(docs):
return "\n\n".join(doc.page_content for doc in docs)
from langchain_core.runnables import RunnablePassthrough
rag_chain = (
{"context": retriever | format_docs, "question": RunnablePassthrough()}
| prompt
| llm # This should be the LLM initialized in the task above.
)
print(rag_chain.invoke("What do I like to drink?"))
这些代码片段清楚地说明了这两个框架的不同抽象级别。LlamaIndex用一个名为“query engines”的方法封装了RAG管道,而LangChain则需要更多的内部组件:包括用于检索文档的连接器、表示“基于X,请回答Y”的提示模板,以及他所谓的“chain”(如上面的LCEL所示)。
当使用LangChain构建时,必须确切地知道想要什么。比如调用from_documents的位置,这使得对于初学者来说是一个非常麻烦的事情,需要更多的学习曲线。
LlamaIndex可以无需显式选择矢量存储后端直接使用,而LangChain则需要显示指定这也需要更多的信息,因为我们不确定在选择数据库时是否做出了明智的决定。
虽然LangChain和LlamaIndex都提供类似于Hugging Face的云服务(即LangSmith Hub和LlamaHub),但是LangChain把它集成到了几乎所有的功能,我们使用pull只下载一个简短的文本模板,内容如下:
You are an assistant for question-answering tasks. Use the following pieces of retrieved context to answer the question. If you don’t know the answer, just say that you don’t know. Use three sentences maximum and keep the answer concise.Question: {question}Context: {context}Answer:**
这绝对是一种过度的做法。虽然这确实鼓励在社区中分享提示,但是这有必要吗。
20240409(首马12日)
- 天晴,热了许多。下午顶着太阳训练,配速4’11"跑到3000米,右脚跟腱一圈疼痛发作,无奈放弃。右跟腱的疼痛自冬训时就已经有过,年后回来好了许多,直到赛前基本上都是无伤训练,状态极好。如今右侧伤痛太多,脚踝才差不多好转,跟腱又复发,唉。
- 后拉了会儿单杠,慢跑2000米,跑得一瘸一拐,补30箭步×8组(+20kg),队里的训练也是箭步,估计只做了三四组就摸了,用的5kg和10kg的片,但是LXY做得确实很标准,我感觉虽然自己每周都练箭步,但也做不到她这么标准。
- 下午宋某自测场地万米,38分57秒,天气太热,给他递了两波水,就算我今天右脚没有伤,这种天气跑进39分也绝非易事,这小子绝对在黑练。虽然宋某有些怠惰,但不可否认他意志的强大,不管多快都能跟得下来,而且具备极好的冲刺能力。直到冬训结束,我都没有绝对把握在场地5000米和10000米上战胜宋某。尽管目前我的各项PB都要比他好不少,然而在所有正式测试和比赛中,我从未击败过宋某,每次都是被他跟住,直到最后两圈被反超。
- 晚饭后去操场消食,想着能不能逮到昨天那个女生拉进群,结果只逮到嘉伟在黑练,1200米间歇,跟我讲现在跑强度跟腱不会疼,但是慢跑就会疼,这正是跟我之前的感觉一样,我前两天也是觉得跑强度间歇右脚踝不会疼,但是慢跑就很难忍受得了疼痛。我不是很能理解嘉伟为什么这学期一直不参加队内例训,只顾黑练,我问他是不是不想见到某个人(CML?LJY?),他不置可否。就像他去年校运会一整日都没有现身,可能也是想躲着YPY。
- PS:我就知道,宋某不会甘心输给我的,跑者不会输在起跑线,只会倒在冲刺的路上。走るのは好きですか?



将前两天的功能整合起来,可以获得一个可以和本地文件对话的真正的可用的简单应用。
使用LlamaIndex,就像将as_query_engine与as_chat_engine交换一样简单:
engine = index.as_chat_engine()
output = engine.chat("What do I like to drink?")
print(output) # "You enjoy drinking coffee."
output = engine.chat("How do I brew it?")
print(output) # "You brew coffee with a Aeropress."
使用LangChain时,按照官方教程,让我们首先定义memory(负责管理聊天记录):
# Everything above this line is the same as that of the last task.
from langchain_core.runnables import RunnablePassthrough, RunnableLambda
from langchain_core.messages import get_buffer_string
from langchain_core.output_parsers import StrOutputParser
from operator import itemgetter
from langchain.memory import ConversationBufferMemory
from langchain.prompts.prompt import PromptTemplate
from langchain.schema import format_document
from langchain_core.prompts import ChatPromptTemplate
memory = ConversationBufferMemory(
return_messages=True, output_key="answer", input_key="question"
)
在LLM开始时,我们需要从memory中加载聊天历史记录。
load_history_from_memory = RunnableLambda(memory.load_memory_variables) | itemgetter(
"history"
)
load_history_from_memory_and_carry_along = RunnablePassthrough.assign(
chat_history=load_history_from_memory
)
然后要求LLM用上下文来丰富我们的提问:
rephrase_the_question = (
{
"question": itemgetter("question"),
"chat_history": lambda x: get_buffer_string(x["chat_history"]),
}
| PromptTemplate.from_template(
"""You're a personal assistant to the user.
Here's your conversation with the user so far:
{chat_history}
Now the user asked: {question}
To answer this question, you need to look up from their notes about """
)
| llm
| StrOutputParser()
)
但是我们不能只是将两者连接起来,因为话题可能在谈话过程中发生了变化,这使得聊天记录中的大多数语义信息无关紧要。
然后就是运行RAG。
retrieve_documents = {
"docs": itemgetter("standalone_question") | retriever,
"question": itemgetter("standalone_question"),
}
对提问进行回答:
rephrase_the_question = (
{
"question": itemgetter("question"),
"chat_history": lambda x: get_buffer_string(x["chat_history"]),
}
| PromptTemplate.from_template(
"""You're a personal assistant to the user.
Here's your conversation with the user so far:
{chat_history}
Now the user asked: {question}
To answer this question, you need to look up from their notes about """
)
| llm
| StrOutputParser()
)
得到最终响应后将其附加到聊天历史记录。
final_chain = (
load_history_from_memory_and_carry_along
| {"standalone_question": rephrase_the_question}
| retrieve_documents
| compose_the_final_answer
)
# Demo.
inputs = {"question": "What do I like to drink?"}
output = final_chain.invoke(inputs)
memory.save_context(inputs, {"answer": output.content})
print(output) # "You enjoy drinking coffee."
inputs = {"question": "How do I brew it?"}
output = final_chain.invoke(inputs)
memory.save_context(inputs, {"answer": output.content})
print(output) # "You brew coffee with a Aeropress."
这是一个非常复杂的过程,我们通过这个过程可以了解了很多关于llm驱动的应用程是如何构建的。特别是调用了LLM几次,让它假设不同的角色:查询生成器、总结检索到的文档的人,对话的参与者。这对于学习来说是非常有帮助的,但是对于应用是不是有些复杂了。
20240410(首马11日)
- 今天右跟腱疼了一天,用护腕打了个封闭,老老实实休息了大半天。真的好无语,好不容易把右脚踝的伤养好,跟腱旧伤又复发。白天一直想试着慢跑两步,但始终做不到,心灰意冷,很失落,加上前天熬夜的后劲,这两天到下午之后头都有点疼。去年9到11月,因为睡眠不足经常头疼,从12月开始按时熄灯起床,已经很久没有这种头疼感了,今晚必须零点前熄灯,再不能熬夜。
- 晚上陪AK跑800米间歇,黑马课表是12-15组,间歇休息90秒,我俩状态都不是很好,最后一共跑了8组,间歇两分半,质量勉强说得过去,8组全部跑进2’45",平均每组约2’40"出头些,去年9月,AK、嘉伟、宋某带2’50"一组的800米间歇我都跟不了一点,如今中短距离的水平也有所长进(去年800米全力可能也就勉强2’40",现在我觉得自己应该有机会跑到接近2’30"的水平,今晚穿的是从NRC白嫖的NIKE鞋,虽然不是碳板,但穿起来还挺好跑的,作为日常训练的口粮鞋也还不错)。
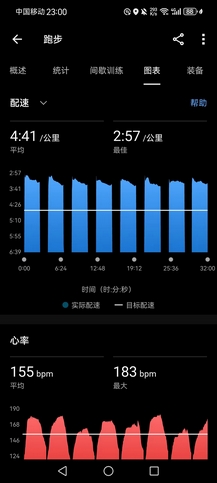
- 本周日江阴半马90分钟以内的选手可当场领取破九鲥鱼一条,然而现在我甚至连半马跑进90分钟可能都要拼尽全力,如果是这周末跑全马,破三的希望极其渺茫,好消息是我还有十天的备赛时间,最后真的会有奇迹发生吗?
RAG管道可以被认为是一个工具。而LLM可以访问多个工具,比如给它提供搜索、百科查询、天气预报等。通过这种方式聊天机器人可以回答关于它直接知识之外的问题。
工具也不一定要提供信息,还可以进行其他操作,例如下购物订单,回复电子邮件等。
LLM有了这些工具,就需要决定使用哪些工具,以及以什么顺序使用。而使用这些工具LLM角色被称为“代理”。
有多种方式可以为LLM提供代理。最具模型泛型的方法是ReAct范式。
在LlamaIndex中使用方法如下:
from llama_index.tools import ToolMetadata
from llama_index.tools.query_engine import QueryEngineTool
notes_query_engine_tool = QueryEngineTool(
query_engine=notes_query_engine,
metadata=ToolMetadata(
name="look_up_notes",
description="Gives information about the user.",
),
)
from llama_index.agent import ReActAgent
agent = ReActAgent.from_tools(
tools=[notes_query_engine_tool],
llm=llm,
service_context=service_context,
)
output = agent.chat("What do I like to drink?")
print(output) # "You enjoy drinking coffee."
output = agent.chat("How do I brew it?")
print(output) # "You can use a drip coffee maker, French press, pour-over, or espresso machine."
对于我们的后续问题“how do I brew coffee”,代理的回答与它仅仅是一个查询引擎时不同。这是因为代理可以自己决定是否查看我们本地笔记。如果他们有足够的信心来回答这个问题,代理可能会选择不使用任何工具。如果LLM发现他无法回答这个问题,则会使用RAG搜索我们本地的文件(我们的查询引擎的其职责是从索引中查找文档,所以他肯定会选择这个)。
代理是LangChain高级API:
from langchain.agents import AgentExecutor, Tool, create_react_agent
tools = [
Tool(
name="look_up_notes",
func=rag_chain.invoke,
description="Gives information about the user.",
),
]
react_prompt = hub.pull("hwchase17/react-chat")
agent = create_react_agent(llm, tools, react_prompt)
agent_executor = AgentExecutor.from_agent_and_tools(agent=agent, tools=tools)
result = agent_executor.invoke(
{"input": "What do I like to drink?", "chat_history": ""}
)
print(result) # "You enjoy drinking coffee."
result = agent_executor.invoke(
{
"input": "How do I brew it?",
"chat_history": "Human: What do I like to drink?\nAI: You enjoy drinking coffee.",
}
)
print(result) # "You can use a drip coffee maker, French press, pour-over, or espresso machine."
尽管我们仍然需要手动管理聊天记录,但与创建RAG相比,创建代理要容易得多。create_react_agent和AgentExecutor整合了底层的大部分工作。
总结,LlamaIndex和LangChain是构建LLM应用程序的两个框架。LlamaIndex专注于RAG用例,LangChain得到了更广泛的应用。我们可以看到,如果是和RAG相关的用例,LlamaIndex会方便很多,可以说是首选。
但是如果你的应用需要一些非RAG的功能,可能LangChain是一个更好的选择。
20240411(首马10日)
- SXY情感受挫,果然任何人逃不过真香定律,之前嘴上说着不谈,心动了还是想试试的。周末这家伙也要去跑四分马,我发现很多人都是失恋之后开始跑步,其实真没必要。昨晚她就在滨江大道试跑了个10km,六分多的配速,估计是好好释放了一下。春天就是这么一个萌动的季节,估计她是最近太闲了,周周都出去玩,我也不太想去问,不过我猜对象会是L🤫。
- 中午陪王京打了三局计分,终于赢了他一把,我觉得现在球感已经好了不少,反手颠球可以颠上一百多个,反正慢慢练呗,球技总是熟能生巧,不像跑步总是起起落落。
- 晚上训练,断断续续跑了六七公里,右跟腱是真顶不住,有两段跑了五六百米就疼得受不了了,而且因为右跟腱的疼痛,右膝会不自主的内扣,导致我左脚经常踢到右膝盖,给膝盖内侧都踢肿了,是真的有些绝望,不知如何是好。我有点担心周末江阴重蹈去年扬马的覆辙,准确地说,并不是右跟腱,就是右跟腱一圈内侧的一个点在阵痛,并不是后侧跟腱部位,胡哥觉得可能是炎症,或许吃些头孢会有用,我是真的有些绝望了。虽然训练质量很差,但是保证了1200C+的消耗,我真的已经不知道该怎么训练了,或许休息才是最好的方法。
- PS:晚上又看到之前那个经常跑步的女生LY,这次终于没放过她,直接逮到拉进群里,居然是NIKE黑马的成员,这周末将去参加苏州全马(此前已经跑了很多场半马,这是首马),太可怕了,这可能是上财在校生里第一个跑全马的女生。虽然她平时都是5’30"配速慢摇,但是真实水平估计很高,LXY一姐地位恐怕不保[Facepalm]。
Mixtral-8x7B(16G显存微调,转载)
全量模型内存占用96.8G内存,使用QLoRA可以将内存占用降低到1/4,仍然不足够。
更优地压缩方法是使用AQLM将模型量化为2位(INT2),仅需12.6GB内存。
首先安装AQLM和最新版本地PEFT,Transformers,Accelerate和TRL,以及bitsandbytes来使用分页AdamW8位算法,可进一步减少微调中的内存消耗。
pip install git+https://github.com/huggingface/transformers.git
pip install git+https://github.com/huggingface/peft
pip install git+https://github.com/huggingface/trl.git
pip install git+https://github.com/huggingface/accelerate.git
pip install aqlm[gpu,cpu]
加载模型:
model = AutoModelForCausalLM.from_pretrained(
"ISTA-DASLab/Mixtral-8x7b-AQLM-2Bit-1x16-hf",
trust_remote_code=True, torch_dtype="auto", device_map="cuda", low_cpu_mem_usage=True
)
tokenizer
tokenizer = AutoTokenizer.from_pretrained("ISTA-DASLab/Mixtral-8x7b-AQLM-2Bit-1x16-hf")
tokenizer.pad_token = tokenizer.eos_token
这里使用了prepare_model_for_kbit_training为微调准备模型,它与AQLM一起工作得很好:
model = prepare_model_for_kbit_training(model)
通过微调,我们将把Mixtral-8x7B变成一个指示/聊天模型。我使用了timdettmers/openassistant-guanaco,因为它小而好,适合本教程。由于它有一个名为“text”的列,因此它的格式也可以使用TRL进行微调。
dataset = load_dataset("timdettmers/openassistant-guanaco")
Lora配置如下:
peft_config = LoraConfig(
lora_alpha=16,
lora_dropout=0.05,
r=16,
bias="none",
task_type="CAUSAL_LM",
target_modules= ['k_proj', 'q_proj', 'v_proj', 'o_proj', "gate", "w1", "w2", "w3"]
)
我们的配置会产生一个242M参数的巨大适配器。这是因为我的目标是模块w1、w2和w3。这些模块都在Mixtral的8位专家内部,总共24个模块。其他模块(自注意力和门控模块)由8位专家共享。它们对可训练参数总数的影响可以忽略不计。
对于训练超参数,我选择如下:
training_arguments = TrainingArguments(
output_dir="./fine-tuned_MixtralAQLM_2bit/",
evaluation_strategy="steps",
do_eval=True,
optim="paged_adamw_8bit",
per_device_train_batch_size=4,
gradient_accumulation_steps=4,
per_device_eval_batch_size=4,
log_level="debug",
logging_steps=25,
learning_rate=1e-4,
eval_steps=25,
save_strategy='steps',
max_steps=100,
warmup_steps=25,
lr_scheduler_type="linear",
)
这里重要的超参数是:
per_device_train_batch_size和gradient_accumulation_steps设置为4和4,这将产生总批大小为16(4*4)。
learning_rate设置为1e-4,因为它看起来很好用。这绝对不是最好的值。
lr_scheduler_type:我将其设置为linear。
optim: paged_adamw_8bit性能良好,同时比原始AdamW实现消耗的内存少得多。缺点是它减慢了微调速度,特别是如果你有一个旧的CPU。如果您有足够的内存,比如24G,可以将其替换为adamw_torch或adamw_8bit。
我们将max_steps设置为100。来证实模型在学习,但是这还不足以训练出一个好的模型。因为至少训练1到2个epoch,才能获得一个相当好的适配器。
使用TRL的SFTTrainer进行训练:
trainer = SFTTrainer(
model=model,
train_dataset=dataset['train'],
eval_dataset=dataset['test'],
peft_config=peft_config,
dataset_text_field="text",
max_seq_length=256,
tokenizer=tokenizer,
args=training_arguments,
)
trainer.train()
根据任务,可以增加max_seq_length,我将其设置为256。这是一个较低的值,但它有助于消耗更少的内存。
根据训练和验证损失,微调进展顺利:
整个过程耗时2小时41分钟。我用的是Google Colab的A100。如果使用RTX GPU,预计训练时间类似。如果你使用较旧的GPU,例如T4或RTX 20xx,它可能会慢2到4倍。
对AQLM模型进行微调的效果出奇地好。当我尝试使用标准QLoRA对Mixtral进行微调时,在相同的数据集上,它消耗了32 GB的VRAM,并且困惑并没有减少得那么好。
如何减少内存消耗
如果你只有一个带有16gb VRAM的GPU,微调Mixtral仍然是可能的。
减少per_device_train_batch_size并按比例增加gradient_accumulation_steps。训练批大小的最小值为1。如果您将其从4减少到1(小4倍),那么应该将gradient_accumulation_steps从4增加到16(大4倍)。
通过从LoraConfig中删除w1、w2、w3和可能的gate,只针对自注意力模块。
将LoRA rank (LoraConfig中的r参数)降低到8或4。
AQLM已经被PEFT和Transformers很好地支持。正如我们在本文中看到的,对AQLM模型进行微调既快速又节省内存。由于我只对几个训练步骤进行了微调,所以我没有使用基准测试来评估经过微调的适配器,但是查看在100个微调步骤之后所达到的困惑(或验证损失)是有很不错的。
这种方法的一个缺点是,由于模型已经量子化了,所以不能合并微调的适配器。并且由于使用AQLM量化llm的成本非常高,因此AQLM模型并不是很多。
20240412(首马9日)
- 伤痛加剧,今天连走路都觉得有些疼,无可奈何。什么都想要,到头来只会一无所得,理智一些,与自己和解,放弃后天的比赛,至少,还有希望在下周末前恢复到健康状态。
- …
希尔排序,也称递减增量排序算法,是插入排序的一种更高效的改进版本。但希尔排序是非稳定排序算法。
希尔排序是基于插入排序的以下两点性质而提出改进方法的:
插入排序在对几乎已经排好序的数据操作时,效率高,即可以达到线性排序的效率;
但插入排序一般来说是低效的,因为插入排序每次只能将数据移动一位。
希尔排序的基本思想是:先将整个待排序的记录序列分割成为若干子序列分别进行直接插入排序,待整个序列中的记录“基本有序”时,再对全体记录进行依次直接插入排序。
- 算法步骤
选择一个增量序列 t1,t2,……,tk,其中 ti > tj, tk = 1;
按增量序列个数 k,对序列进行 k 趟排序;
每趟排序,根据对应的增量 ti,将待排序列分割成若干长度为 m 的子序列,分别对各子表进行直接插入排序。仅增量因子为 1 时,整个序列作为一个表来处理,表长度即为整个序列的长度。 - Python 代码
def shellSort(arr):
import math
gap=1
while(gap < len(arr)/3):
gap = gap*3+1
while gap > 0:
for i in range(gap,len(arr)):
temp = arr[i]
j = i-gap
while j >=0 and arr[j] > temp:
arr[j+gap]=arr[j]
j-=gap
arr[j+gap] = temp
gap = math.floor(gap/3)
return arr
}
堆排序(Heapsort)是指利用堆这种数据结构所设计的一种排序算法。堆积是一个近似完全二叉树的结构,并同时满足堆积的性质:即子结点的键值或索引总是小于(或者大于)它的父节点。堆排序可以说是一种利用堆的概念来排序的选择排序。分为两种方法:
大顶堆:每个节点的值都大于或等于其子节点的值,在堆排序算法中用于升序排列;
小顶堆:每个节点的值都小于或等于其子节点的值,在堆排序算法中用于降序排列。
堆排序的平均时间复杂度为 Ο(nlogn)。
- 算法步骤
创建一个堆 H[0……n-1];
把堆首(最大值)和堆尾互换;
把堆的尺寸缩小 1,并调用 shift_down(0),目的是把新的数组顶端数据调整到相应位置;
重复步骤 2,直到堆的尺寸为 1。 - 动图演示
动图封面 - Python 代码
def buildMaxHeap(arr):
import math
for i in range(math.floor(len(arr)/2),-1,-1):
heapify(arr,i)
def heapify(arr, i):
left = 2*i+1
right = 2*i+2
largest = i
if left < arrLen and arr[left] > arr[largest]:
largest = left
if right < arrLen and arr[right] > arr[largest]:
largest = right
if largest != i:
swap(arr, i, largest)
heapify(arr, largest)
def swap(arr, i, j):
arr[i], arr[j] = arr[j], arr[i]
def heapSort(arr):
global arrLen
arrLen = len(arr)
buildMaxHeap(arr)
for i in range(len(arr)-1,0,-1):
swap(arr,0,i)
arrLen -=1
heapify(arr, 0)
return arr
20240413~20240414(首马7日,完结?)
下午四点,回到上海站,一路蹒跚走到3号线站台,我到底还是哭了。我知道巅峰之后会是低谷,但没想到低谷来得是如此猝不及防。


理智地说,为了下周末的南通全马,我应该弃赛江阴半马。但是,我依然想要去走一遭。一方面,从未造访过江阴,给自己浅薄的阅历添上一笔,未尝不可,倘若这趟旅行能再遇到些人或事呢?另一方面,赛前一周,连一场半马都跑不下来,还谈论什么首马破三?
周六中午出发前,我临时把所有跑步装备(XTEP跑鞋、墨镜、鸭舌帽、肌贴)从行李中撤走,随身只带上换洗的两三件内衣物,毛巾、拖鞋,云南白药和两瓶水。我确信自己用不到那些东西,跑鞋用脚上这双NIKE绰绰有余,墨镜、鸭舌帽不过身外之物,肌贴也改变不了现状。
我很难描述这两日的心境。先是图省钱乘坐的绿皮车(其实绿皮车也没比高铁慢多少,但确实便宜太多),绿皮车果然是很难熬,所幸同行的人还不错。邻座是一位80多岁的沪上老阿姨,她正要独自前往南京游玩,手拿一把自拍杆,是个很有活力的人,听说阿姨九岁丧父,早早就独立地成为中学教师,凭借自己数十年的奋斗打下一片天地,如今已是儿孙满堂,谈论起自己的女儿女婿如数家珍,子辈孙辈个个都是高知精英,令人艳羡;对面是一对长我一两岁的情侣,男方湖南大学硕士毕业,刚刚入职张江一家芯片公司,待遇还不错,周末一同前往苏州游玩,女方在盘算着两日的行程安排,听起来很是幸福。
抵达江阴时,我忽然感到失望。江阴好歹也是百强县,不说有上海的管理水平,但至少也不能跟老家江都区这种二流县城相提并论吧。然而,这里的城市面貌和江都并无二致。街道两旁是杂乱无章的杂货小铺,老旧的住宅楼外壁上笼罩着黑灰色的烟渍,方圆两三公里找不到一家能吃饭的商场,穿梭于小巷中才终于能找到几家吃饭的小店,可是到了饭点连着几家都见不到一位顾客,最后在一家看起来还算有点生意的清真面馆解决晚饭。本还指望有些人文风光,领完比赛物资后,走了十几公里的路(走的我脚都疼了),试着熟悉一下周边环境,到头来根本没有熟悉的必要,全跟老家一样的小市民风气。如果将这里所有的“江阴”替换成“江都”,说实话也没啥违和感。
一切都是那么平淡。领物的地方也很平淡,没有扬马时热情的志愿者,也没有乱七八糟的路演摊,用了不到五分钟就走完了全部流程。心态也很平淡,提不起什么兴致,走了一天路,身体疲劳,右脚愈发疼痛,只想早早休息,11点熄灯,不到6点自然醒,中途一点没醒,睡得特别踏实。今早出门前,我在想参赛包里要带些什么好,想了好一会儿,发现除了手机和房卡好像什么也不用带,索性连包都没带,穿上件外套,手机房卡揣兜里就完事了。
七点四十多到场,距离发枪只有不到二十分钟。A区检录,第一次距离起点那么近,挤一挤甚至能跟在黑人选手后面一起出发,天气也是绝好,如果还是健康状态,我很愿意今天全力跑一回,然而现实是我连热身都懒得做,还穿着笨重的外套,里头的号码布都看不到,站在一堆身着背心短裤的A区大佬中,显得是如此格格不入。
现场气氛很热烈,然而我的内心毫无波澜。双金扬马的PB(1:24:05),足以让我接下来两年去任何想去的地方参赛,江阴这场我绝无可能再次PB,跑多快都是没有意义的。
- 没有意义也不是什么坏事。这不是在说什么漂亮话。跑步的目的,当然是要取得胜利,但胜利其实有许多种形式。所谓的胜利,不单是指在所有参赛者中跑出最好的成绩。 就像人活在这世上,怎样才算人生胜利组,也没有明确的定义。——《强风吹拂》
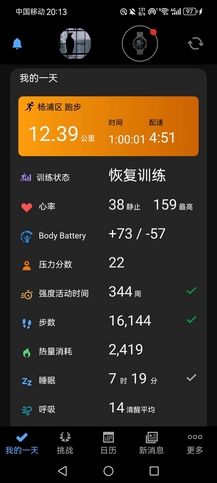
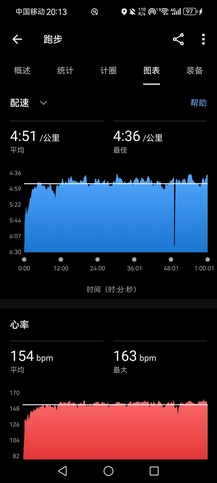
或许还是想表现得开心些,我一直暗示自己要振作些。跑步嘛,别忘了初衷,跑步应该是件快乐的事。发枪后,跟着身着上海交大队服的女生跑了好久,我发现自己还是能用后跟跑法勉强跑起来,前10km用时刚好53分钟,我算了算,好像可以凑个520配速。
11km时,我看到嘉伟已经完赛黄浦四分马,完成了10km分段PB(36分34秒,PB1秒钟),我感觉不可思议,因为嘉伟近期也受跟腱伤痛的困扰,而且他应该比我伤得更重,他是在锡马比赛中途受伤,坚持走了14km才抵达终点,我的扬马赛程极其顺利,赛后才发现受伤。我后来仔细回顾,还是自己托大,扬马之后没有好好休息,先是赛后马不停蹄地走路,直到晚上才回家,而且这两周恢复期,我太低估伤痛,以为只是单纯的肌肉疲劳,休息好就完事了,4.5,4.8,4.10三天晚上都进行大强度的间歇和体能训练,直到4.11晚上例训后才发现自己真的已经完全跑不起来,追悔莫及。我不由得感慨天赋的差异,嘉伟短时间内即从低谷恢复到全盛状态,我却在一次绽放之后迅速衰败。
15km后,状态急转直下,右脚已经有些肿痛,我不想再勉强,走走停停,在补给点自助,一路上恰了五包法式小面包,若干圣女果,六袋葡萄干(葡萄干真好吃呀,有一个补给站我都走过去了,还是回头拿了几包带身上吃),我跑不了,又不是吃不下了xs。
- 就算不受神的眷顾,还是可以选择热爱。
- 轮流迈出左右脚,这样一来,就能到达终点。——《强风吹拂》
毫无波澜地,走完全程,由于过于轻松(即便是前15km,我的心率也没有超过150bpm,平均心率在140bpm左右,后面走了一大段早已休息好了),大腿小腿都没啥感觉,拉伸也没做。主办方提供了冰水池用于泡脚,这对我确是很有用,我赶紧给右脚消了消肿,完赛包的物资很丰富,不枉走这一遭,只是可惜了那条破九鲥鱼,我是拿不到了。
没有过多留恋,一完赛我就踏上了归途。我发现从宾馆到地铁站的2km路变长了许多,颤颤巍巍的右脚,迈起步来,愈发得艰难,我想,已经知道是什么样子了。该把南通的高铁和酒店都退了罢,cy,今天已经耗费了我最后的精血,我已经,无论如何,都不可能在一周内,恢复到跑全马的状态了。
突然就很难受。我从五个月前决定备战首马,三个月前决定备战首马破三,如今我已经拥有半马124的硬实力,全马破三近在咫尺,却在短短几天内,如泡影般幻灭。为什么?为什么!为什么不能让我再赢一次,难道我的人生,连一个月的绽放都不值得吗?
“是的,你的努力只够在3月31日绽放这仅有的一回了。”
我终究还是那个常败将军。与自己,也与跑步一起和解。总要接受人生的不完满。路或许真的很长,破三终有时,何须当下。
- 只要努力就一定能成功,其实是一种傲慢。
- 明天、后天、大后天,该做什么就还得做什么。现实永远都在眼前,那就不要逃避,干脆与现实一起跑吧。——《强风吹拂》

一些后记:
- 新逮到的李雨,今天首马——苏州马拉松顺利完赛,4小时21分,虽然不是很惊艳的成绩,但是作为现役,可能是整个上财在校生里唯一一个完赛全马的女生。
- 宋某四分马的战果未知,他日常不想让我知道他的真实水平。小崔倒是拉胯不少,跑了44分43秒,算下来至少也是4分10秒开外的配速了,对于去年校运会第一的他来说,这无疑不是个理想的成绩。
- 另一个宋某大概四分马是顺利完赛了吧。
- 希望嘉伟下周上半马能打破我的PB,破开120,我更希望他能健康地一路跑下去,他比我年轻,他的路会更长些。
20240415(首马6日)
- 右脚伤痛有些不可名状,最一开始是在脚踝,然后在跟腱一圈,现在感觉似乎并不疼,但到处又都有点疼,那种麻木的疼,像是扭伤,但不见淤血凝肿的地方,两只脚的形态一模一样。唯一确定的是,现在是真的一步都跑不起来了。
- 这两年我已经看得很开,对这个年纪的我来说,任何经历都是有价值的,无论好坏,这就是生活给你上的课,尽管这次的打击真的很大。
- 在此之前,我自以为已经很懂了,也对自己的身体足够了解。有些事,确实是要学一辈子,要有敬畏之心。
- 再多慰藉,在现实面前都显得无力,唯有接受,好好养伤。
- 我不会,也不想,就此倒下!(^_^)
pip install llama-index
默认情况下,LlamaIndex使用OpenAI的gpt-3.5 turbo来创建文本,并使用text- embedting -ada-002来获取和嵌入文本。所以这里需要一个OpenAI API Key来使用这些。在OpenAI的网站上注册即可免费获得API密钥。然后在python文件中以OPENAI_API_KEY的名称设置环境变量。
import os
os.environ["OPENAI_API_KEY"] = "your_api_key"
如果你不想使用OpenAI,也可以使用LlamaCPP和llama2-chat-13B来创建文本,使用BAAI/ big -small-en来获取和嵌入。这些模型都可以离线工作。要设置LlamaCPP,请按照Llamaindex的官方文档进行设置。这将需要大约11.5GB的CPU和GPU内存。要使用本地嵌入,需要安装这个库:
pip install sentence-transformers
创建Llamaindex文档
数据连接器(也称为reader)是LlamaIndex中的重要组件,它有助于从各种来源和格式摄取数据,并将其转换为由文本和基本元数据组成的简化文档表示形式。
from llama_index import download_loader
GoogleDocsReader = download_loader('GoogleDocsReader')
loader = GoogleDocsReader()
documents = loader.load_data(document_ids=[...])
LlamaIndex提供了的各种数据连接器包括:
SimpleDirectoryReader:支持本地文件目录中的多种文件类型(.pdf, .jpg, .png, .docx等)。
NotionPageReader:从Notion获取数据。
lackReader:从Slack导入数据。
ApifyActor:能够抓取网页,抓取,文本提取和文件下载。
创建LlamaIndex节点
在LlamaIndex中,一旦数据被摄取并表示为文档,就可以选择将这些文档进一步处理为节点。节点是更细粒度的数据实体,表示源文档的“块”,可以是文本块、图像或其他类型的数据。它们还携带元数据和与其他节点的关系信息,这有助于构建更加结构化和关系型的索引。
为了将文档解析为节点,LlamaIndex提供了NodeParser类。这些类有助于自动地将文档的内容转换为节点,遵循一个特定的结构,可以在索引构造和查询中进一步利用。
下面是如何使用SimpleNodeParser将文档解析为节点:
from llama_index.node_parser import SimpleNodeParser
# Assuming documents have already been loaded
# Initialize the parser
parser = SimpleNodeParser.from_defaults(chunk_size=1024, chunk_overlap=20)
# Parse documents into nodes
nodes = parser.get_nodes_from_documents(documents)
在这个代码片段中,SimpleNodeParser.from_defaults()用默认设置初始化一个解析器,get_nodes_from_documents(documents)用于将加载的文档解析为节点。
参数选项包括:
-
`text_splitter·(默认:TokenTextSplitter)
-
include_metadata(默认值:True) -
include_prev_next_rel(默认值:True) -
metadata_extractor(默认值:无)
在定义好节点后,会根据需要将节点的文本通过文本分割器拆分成token,这里可以使用llama_index.text_splitter中的senencesplitter、TokenTextSplitter或CodeSplitter。例子:
SentenceSplitter:
import tiktoken
from llama_index.text_splitter import SentenceSplitter
text_splitter = SentenceSplitter(
separator=" ", chunk_size=1024, chunk_overlap=20,
paragraph_separator="\n\n\n", secondary_chunking_regex="[^,.;。]+[,.;。]?",
tokenizer=tiktoken.encoding_for_model("gpt-3.5-turbo").encode
)
node_parser = SimpleNodeParser.from_defaults(text_splitter=text_splitter)
TokenTextSplitter:
import tiktoken
from llama_index.text_splitter import TokenTextSplitter
text_splitter = TokenTextSplitter(
separator=" ", chunk_size=1024, chunk_overlap=20,
backup_separators=["\n"],
tokenizer=tiktoken.encoding_for_model("gpt-3.5-turbo").encode
)
node_parser = SimpleNodeParser.from_defaults(text_splitter=text_splitter)
CodeSplitter:
from llama_index.text_splitter import CodeSplitter
text_splitter = CodeSplitter(
language="python", chunk_lines=40, chunk_lines_overlap=15, max_chars=1500,
)
node_parser = SimpleNodeParser.from_defaults(text_splitter=text_splitter)
对于特定的范围嵌入,还需要使用SentenceWindowNodeParser将文档拆分为单独的句子,同时捕获周围的句子窗口。
import nltk
from llama_index.node_parser import SentenceWindowNodeParser
node_parser = SentenceWindowNodeParser.from_defaults(
window_size=3, window_metadata_key="window", original_text_metadata_key="original_sentence"
)
为了获得更多控制,也可以使用手动创建Node对象并定义属性和关系:
from llama_index.schema import TextNode, NodeRelationship, RelatedNodeInfo
# Create TextNode objects
node1 = TextNode(text="<text_chunk>", id_="<node_id>")
node2 = TextNode(text="<text_chunk>", id_="<node_id>")
# Define node relationships
node1.relationships[NodeRelationship.NEXT] = RelatedNodeInfo(node_id=node2.node_id)
node2.relationships[NodeRelationship.PREVIOUS] = RelatedNodeInfo(node_id=node1.node_id)
# Gather nodes
nodes = [node1, node2]
上面的代码中,TextNode创建带有文本内容的节点,而noderrelationship和RelatedNodeInfo定义节点关系。
20240416(首马5日)
- 停训第二日,不训练的日子里,似乎也没啥改变。最近五天LXY在香港交流,下午队里都没人去训练了,东哥直呼要解散田径队,我觉得不如直接改篮球队,大家一定积极很多。
- 这次可能会是一周,一个月,三个月,半年?我不知道,右脚依然抽的很紧,就感觉整个脚踝连着跟腱这一大圈的肌肉紧绷着,像是随时会抽的样子。真得跟宋某学学,他从去年12月到现在也是伤痛不断,但依然很乐观,每次我觉得他已经拉胯了,他都会给我一记狠狠的巴掌,生活态度真的很重要。
- 晚上下会路过操场还是想去走会儿,偶遇DGL,遇见认识的人还是上去一起跑会儿,最近DGL每天坚持5km,已经能跑到接近23分的水平,恐怖如斯。跑了6圈,感觉右脚就快要疼起来了,放弃了。
- 时间已晚,不好意思叫师傅帮我开门拿铃片做力量,明天再做。补了三组单杠卷腹和引体就离开了。刚走,就LXY一路跑来,估计是刚下飞机就来训练,好积极,好积极。
目前图像这块的AIGC的解释性有些令人感觉诡异,就是从人类的视角来看,各种prompt替换的操作实现的迁移,似乎是有解释性的,但是我觉得理论突破的关键在于如何做语义的解耦。从结果来看,至少在表征上已经几乎做到了充分的程度(尽管在细节上),但是没有人知道各个维度语义上到底代表着些什么?比如难以做到精确位置的颜色替换,颜色的语义到底被包含在哪些维度中,是否有办法将对应位置的颜色语义解耦出来。
所以愈是研究,越是觉得人脑是个很神奇的东西,人可以学会察言观色,读取唇语,揣摩文字背后作者的心境,尽管LLM也能模仿着人类写出一些话,但它终究差人类还是太遥远,或者说我们并不是那么懂他
LlamaIndex用节点和文档创建索引
LlamaIndex的核心本质在于它能够在被摄取的数据上构建结构化索引,这些数据表示为文档或节点。这种索引有助于对数据进行有效的查询。让我们深入研究如何使用Document和Node对象构建索引,以及在此过程中会发生什么。
下面是如何使用VectorStoreIndex从文档中直接创建索引:
from llama_index import VectorStoreIndex
# Assuming docs is your list of Document objects
index = VectorStoreIndex.from_documents(docs)
LlamaIndex中不同类型的索引以不同的方式处理数据:
Summary Index :将节点存储为一个顺序链,在查询期间,如果没有指定其他查询参数,则将所有节点加载到Response Synthesis模块中。
Vector Store Index:将每个节点和相应的嵌入存储在Vector Store中,查询涉及获取top-k最相似的节点。
Tree Index:从一组节点构建层次树,查询涉及从根节点向下遍历到叶节点。
Keyword Table Index:从每个Node中提取关键字构建映射,查询提取相关关键字获取对应的Node。
具体使用索引,请详细查看官方文芳并根据用例做出选择。
使用下面代码为PDF文件创建一个索引。
我们也可以直接从Node对象中创建索引,然后将文档解析为Node或手动创建Node:
from llama_index import VectorStoreIndex
# Assuming nodes is your list of Node objects
index = VectorStoreIndex(nodes)
存储索引
LlamaIndex可以为所以提供多种存储方式,可以根据不同的需要进行选择。
1、基本方法
LlamaIndex使用persist()方法可以存储数据,使用load_index_from_storage()方法可以毫不费力地检索数据。
# Persisting to disk
index.storage_context.persist(persist_dir="<persist_dir>")
# Loading from disk
from llama_index import StorageContext, load_index_from_storage
storage_context = StorageContext.from_defaults(persist_dir="<persist_dir>")
index = load_index_from_storage(storage_context)
2、存储组件(高级)
LlamaIndex提供了可定制的存储组件,允许用户指定存储各种数据元素的位置。这些组成部分包括:
Document Stores:用于存储表示为Node对象的摄取文档的存储库。
Index Stores:保存索引元数据的地方。
Vector Stores:用于存放嵌入向量的存储器。
LlamaIndex在存储后端支持方面是通用的,已确认支持:
本地文件系统、AWS S3、Cloudflare R2等
这些后端通过使用fsspec库得就进行访问,因为该库支持各种存储后端。
创建或重新加载索引的示例如下:
# build a new index
from llama_index import VectorStoreIndex, StorageContext
from llama_index.vector_stores import DeepLakeVectorStore
vector_store = DeepLakeVectorStore(dataset_path="<dataset_path>")
storage_context = StorageContext.from_defaults(vector_store=vector_store)
index = VectorStoreIndex.from_documents(documents, storage_context=storage_context)
# reload an existing index
index = VectorStoreIndex.from_vector_store(vector_store=vector_store)
为了利用存储抽象,需要定义一个StorageContext对象:
from llama_index.storage.docstore import SimpleDocumentStore
from llama_index.storage.index_store import SimpleIndexStore
from llama_index.vector_stores import SimpleVectorStore
from llama_index.storage import StorageContext
storage_context = StorageContext.from_defaults(
docstore=SimpleDocumentStore(),
vector_store=SimpleVectorStore(),
index_store=SimpleIndexStore(),
)
20240417(首马4日)
- 晚上十点,去B1试着跳会儿绳,只不到200个单摇,右脚就疼得受不了。我下定决心退掉高铁和酒店。理智,抑或懦夫?或是该去放手一搏,豪赌奇迹的发生?
- 一日大雨,上午仍觉得右脚不行,但傍晚下楼吃晚饭时突然觉得身体好轻,真的好轻好轻,试着用前掌跑了一段,感觉很好,我似乎又行了。临时决定给自己最后一次机会,我先去21号楼称了下体重,想着此时体重若是超过70kg,我就直接放弃。因为最近三四天有点不太节制,非饭点吃一堆碳水,训练量又低,估计是要长胖,但称下来只有67kg,而且是饭后,净重可能都不如扬马赛前的水平。
- 于是,晚饭后,决定冒雨再试一次,如果能以5分以内的配速,坚持到20km以上,我就去南通赌一回奇迹发生。
- 然而,奇迹从未发生。环校一圈2.5km,第一圈到2.15km,右脚就坚持不住了。我觉得或许是因为跑得太快的缘故,试着慢一点再来一次,这次我只坚持到1km出头,就再也无法跑下去。
- 去年4月25日,同样的伤痛,那次我坚持上场,结果又如何?这次提前放弃,解脱,我不想再挣扎了。
- 真的结束了呀。又是还没开始就结束,一如既往地,搞砸了。

使用索引查询数据
在使用LlamaIndex建立了结构良好的索引之后,下一个关键步骤是查询该索引,本文的这一部分将说明查询LlamaIndex中索引的数据的过程和方法。
1、高级查询API
LlamaIndex提供了一个高级API,可以简化简单的查询,非常适合常见的用例。
# Assuming 'index' is your constructed index object
query_engine = index.as_query_engine()
response = query_engine.query("your_query")
print(response)
默认情况下,index.as_query_engine()使用LlamaIndex中指定的默认设置创建查询引擎。
如果我们使用子问题查询引擎来解决多个数据源回答复杂查询的问题。它首先将复杂的查询分解为每个相关数据源的子问题,然后收集所有中间响应并合成最终响应。我们以Wikipedia为例:
import nest_asyncio
from llama_index import VectorStoreIndex, SimpleDirectoryReader
from llama_index.tools import QueryEngineTool, ToolMetadata
from llama_index.query_engine import SubQuestionQueryEngine
from llama_index.callbacks import CallbackManager, LlamaDebugHandler
from llama_index import ServiceContext
nest_asyncio.apply()
# We are using the LlamaDebugHandler to print the trace of the sub questions captured by the SUB_QUESTION callback event type
llama_debug = LlamaDebugHandler(print_trace_on_end=True)
callback_manager = CallbackManager([llama_debug])
service_context = ServiceContext.from_defaults(
callback_manager=callback_manager
)
节点后处理程序
在查询输出后,可以通过后处理程序转换、过滤或重新排序来细化节点集。LlamaIndex后置处理器包括:
SimilarityPostprocessor:使用similarity_cutoff设置阈值。移除低于某个相似度分数的节点。
KeywordNodePostprocessor:使用required_keywords和exclude_keywords。根据关键字包含或排除过滤节点。
MetadataReplacementPostProcessor:用其元数据中的数据替换节点内容。
LongContextReorder:重新排序节点,这有利于需要大量顶级结果的情况,可以解决模型在扩展上下文中的困难
SentenceEmbeddingOptimizer:选择percentile_cutoff或threshold_cutoff作为相关性。基于嵌入删除不相关的句子。
CohereRerank:使用coherence ReRank对节点重新排序,返回前N个结果。
SentenceTransformerRerank:使用SentenceTransformer交叉编码器对节点重新排序,产生前N个节点
LLMRerank:使用LLM对节点重新排序,为每个节点提供相关性评分。
FixedRecencyPostprocessor:返回按日期排序的节点。
EmbeddingRecencyPostprocessor:按日期对节点进行排序,但也会根据嵌入相似度删除较旧的相似节点。
TimeWeightedPostprocessor:对节点重新排序,偏向于最近未返回的信息。
PIINodePostprocessor(β):可以利用本地LLM或NER模型删除个人身份信息。
PrevNextNodePostprocessor(β):根据节点关系,按顺序检索在节点之前、之后或两者同时出现的节点。
以上是一些常用的后处理程序,官网还有很多其他的模块。
20240418(首马3日)
- 晚上例训。45分钟出头跑了10km,补30箭步×8组(+20kg)(跑完忘记掐表,走了两分多钟才发现,但也没啥区别了,爱咋咋地)。其实我真的只想慢跑,但是中途不断有人跟过来:
- 先是一个博一金融的男生,看起来水平还不错,也是个经常跑步的;
- 接着是GZJ,真的好久好久没见了,他还有两个月就毕业了,一战考本院没能上岸,决定还是要进行二战,唉,现在本科生真的是太卷了,今年本院初试378分都没过,只招5个人。
- 后来ZYY也跟着我跑了一段,我稍微提了些到4分配;
- 最后宋某也来了,我跟着350以内的配速冲了一段,把后面跟着的XR给拉爆了。很神奇,居然越快脚越觉得不疼,前3km我已经觉得右脚疼得快要支撑不住了,但是跑到后面反而没有感觉了,可能是因为有人一起跑显得会轻松一些罢。
- 宋某今晚大爆发,场地5000米跑出18分22秒,虽然我自信在上个月的巅峰期也能轻松跑出这个成绩(我上个月场地5000米应该能开18分,但是很可惜,上个月没有正式测一回5000米),但是接下来还想跑出这个成绩真的已经很难了。他也算是拨云见日,从去年12月底开始伤痛,破而后立,终于重回巅峰。
- 伤痛对我来说并非坏事,也不是什么大事,我早就习惯了。一路都是在这样起起落落中慢慢恢复,寻找正确的训练方法。其实如果真的想跑,我依然可以用4分以内的配速坚持10km以上,但是我不想再透支身体,我想认真地慢跑一段时间,好好堆一堆有氧(目前绝对速度已经绰绰有余,主要是心率要能控住,445左右的配速,心率能降到140bpm以下,就是最好的有氧积累,一切都会水到渠成的)。
- 整个三月,256km的月跑量,平均配速4分09秒,完全没有慢跑的有氧积累,几乎全都是大强度训练,终于在扬马,我透支了所有精力,跑出了本还不属于我的成绩。而回来之后又不自知,以为已经恢复,就开始上强度。其实并没有后悔什么,有得必有失,但有失,也必有得,伤痛就像一记刹车,让我能慢慢停下做些思考,一味盲目地在冲,或许真的是迷失了方向,初心本非如此。
另一个llamaIndex案例:
依赖:
pip install -U llama_hub llama_index braintrust autoevals pypdf pillow transformers torch torchvision
初始化:
import os
from dotenv import load_dotenv, find_dotenv
#加载本地 .env 配置文件
_ = load_dotenv(find_dotenv())
加载数据
from llama_index.readers.web import TrafilaturaWebReader
docs = TrafilaturaWebReader().load_data(
["https://baike.baidu.com/item/ChatGPT/62446358",
"https://baike.baidu.com/item/恐龙/139019"]
)
len(docs) # 文档数
print(docs[0].text[:1000]) # 文档内容
接下来我们要实现文档的切割工作,这也是文档检索的必要步骤之一,和Langchain相似的是LlamaIndex也需要创建文档的切割器:
from llama_index.node_parser import SimpleNodeParser
from llama_index.schema import IndexNode
#创建文档切割器
node_parser = SimpleNodeParser.from_defaults(chunk_size=1024)
node_parser
这里需要说明一下的是在LIamaIndex中我们把文档块称为“节点(node)”,文档切割器称为“解析器(parser)”,和Langchain一样的是在创建文档切割器时我们也需要设置文档块大小(chunk_size),另外还有一些可选参数如重叠字符串长度(chunk_overlap)等,这里我们看到文档切割器node_parser 它有着自己的文档切割规则,比如:
separator=' ', paragraph_separator='\n\n\n',secondary_chunking_regex='[^,.;。?!]+[,.;。?!]?'。
这些和Langchain的文档切割规则也有所差异。下面我们要用文档切割器node_parser来切割文档:
base_nodes = node_parser.get_nodes_from_documents(docs)
len(base_nodes)
base_nodes[10] # 节点内容
这里我们需要特别说明的是在被切割出来的每一个节点中都包含了:本节点自身Id(id_)、父节点Id(SOURCE)、上级节点Id(PREVIOUS)、下级节点Id(NEXT),这里的父节点Id指的是原始文档Id即docs里面的文档Id,而上/下级节点指的是当前节点的上一个和下一个节点。从这里我们可以看出LIamaIndex的文档块信息中包含了较为完整的上下文索引信息。
20240419(首马2日)
- 起了个大早,提振了一下连日萎靡的精神。白天天气很好,下午却又变天,四点多冒雨跑了10圈,本想只是慢跑(目前右脚的伤痛基本都消失了,疼痛的位置在右脚内侧脚踝上方5cm的地方,就是寒假一直觉得的小腿和脚的连接处阵痛,这个确实是旧伤,年前经常会跑到15km以上时开始疼,年后回来后基本不疼,现在只要开始跑就会疼,但是勉强可以忍受),心率压在140bpm上下,但雨越下越大,敦促着步伐也越来越快,那就去TND心率呗,久违的雨中狂奔。
- 后天的上半马,嘉伟、小崔和LZR都将参加,我将到现场为嘉伟加油。一方面,他刚刚被我超越半马PB,必定这次全力以赴,不出意外这次会比我更快,我更希望他能成功破开1小时20分。另一方面,作为本篇的完结,尽管序言立下的FLAG终究倒下,有些无可奈何,但总归还是有始有终吧。
- 现实总不如小说桥段的精彩,奇迹从来不会毫无逻辑地发生。
- 然,坚持,奇迹总会发生。跑者永不言弃,无论如何,我终将破三,一定。
In this section, we start with the code you wrote for the starter example and show you the most common ways you might want to customize it for your use case:
from llama_index.core import VectorStoreIndex, SimpleDirectoryReader
documents = SimpleDirectoryReader("data").load_data()
index = VectorStoreIndex.from_documents(documents)
query_engine = index.as_query_engine()
response = query_engine.query("What did the author do growing up?")
print(response)
“I want to parse my documents into smaller chunks”#
Global settings
from llama_index.core import Settings
Settings.chunk_size = 512
# Local settings
from llama_index.core.node_parser import SentenceSplitter
index = VectorStoreIndex.from_documents(
documents, transformations=[SentenceSplitter(chunk_size=512)]
)
“I want to use a different vector store”#
First, you can install the vector store you want to use. For example, to use Chroma as the vector store, you can install it using pip:
pip install llama-index-vector-stores-chroma
To learn more about all integrations available, check out LlamaHub.
Then, you can use it in your code:
import chromadb
from llama_index.vector_stores.chroma import ChromaVectorStore
from llama_index.core import StorageContext
chroma_client = chromadb.PersistentClient()
chroma_collection = chroma_client.create_collection("quickstart")
vector_store = ChromaVectorStore(chroma_collection=chroma_collection)
storage_context = StorageContext.from_defaults(vector_store=vector_store)
StorageContext defines the storage backend for where the documents, embeddings, and indexes are stored. You can learn more about storage and how to customize it.
from llama_index.core import VectorStoreIndex, SimpleDirectoryReader
documents = SimpleDirectoryReader("data").load_data()
index = VectorStoreIndex.from_documents(
documents, storage_context=storage_context
)
query_engine = index.as_query_engine()
response = query_engine.query("What did the author do growing up?")
print(response)
“I want to retrieve more context when I query”#
from llama_index.core import VectorStoreIndex, SimpleDirectoryReader
documents = SimpleDirectoryReader("data").load_data()
index = VectorStoreIndex.from_documents(documents)
query_engine = index.as_query_engine(similarity_top_k=5)
response = query_engine.query("What did the author do growing up?")
print(response)
as_query_engine builds a default retriever and query engine on top of the index. You can configure the retriever and query engine by passing in keyword arguments. Here, we configure the retriever to return the top 5 most similar documents (instead of the default of 2). You can learn more about retrievers and query engines.
“I want to use a different LLM”#
# Global settings
from llama_index.core import Settings
from llama_index.llms.ollama import Ollama
Settings.llm = Ollama(model="mistral", request_timeout=60.0)
# Local settings
index.as_query_engine(llm=Ollama(model="mistral", request_timeout=60.0))
You can learn more about customizing LLMs.
“I want to use a different response mode”#
from llama_index.core import VectorStoreIndex, SimpleDirectoryReader
documents = SimpleDirectoryReader("data").load_data()
index = VectorStoreIndex.from_documents(documents)
query_engine = index.as_query_engine(response_mode="tree_summarize")
response = query_engine.query("What did the author do growing up?")
print(response)
You can learn more about query engines and response modes.
“I want to stream the response back”#
from llama_index.core import VectorStoreIndex, SimpleDirectoryReader
documents = SimpleDirectoryReader("data").load_data()
index = VectorStoreIndex.from_documents(documents)
query_engine = index.as_query_engine(streaming=True)
response = query_engine.query("What did the author do growing up?")
response.print_response_stream()
You can learn more about streaming responses.
“I want a chatbot instead of Q&A”#
from llama_index.core import VectorStoreIndex, SimpleDirectoryReader
documents = SimpleDirectoryReader("data").load_data()
index = VectorStoreIndex.from_documents(documents)
query_engine = index.as_chat_engine()
response = query_engine.chat("What did the author do growing up?")
print(response)
response = query_engine.chat("Oh interesting, tell me more.")
print(response)
20240420(首马1日)
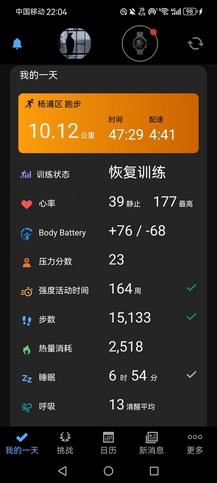
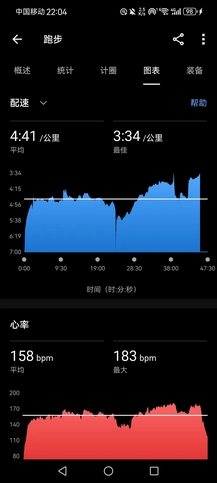
- 下午慢跑1小时,配速4’51"。原计划就这样摇到20km,还是高估了自己,右脚真的坚持不下来,全程都是后跟跑,前掌完全踮不起来。旨在控制心率,配速起伏得厉害。之前这个心率,至少能顶到4’25"以内的配速,但下午很热,心率高一些问题也不是很大,而且如今确是落魄了,比不了从前。
- 完事跟宋某做力量。宋某现在经常做空杆深蹲(他是真的空杆,连杆都没有,举着个皇帝的新杆做深蹲跳,一组还就做12个,我真想给他一脚),我用弹力带拉引体,现在可以一口气拉上去6个,一共做了20多个,真的累。恢复期,把背部力量好好练一下,以前也不重视背部训练,虽然感觉背部力量对跑步用处不是很大,但是AK说有用那就练吧。
- 之后带宋某做核心:
- 平板支撑:低位平板,抬脚×2,抬手×2,抬对侧手脚×2,抬同侧手脚×2,一个动作保持静态30秒。我可以一口气把8个动作全部做下来,宋某连3分钟普通的低位平板都费事,但是他的上半身确实很稳定,应该是比我还要稳,跑起来完全不动的那种,令人费解。
- 仰卧两头起:宋某做3个就不行了,我一口气能做100个,狠狠地嘲讽了一下他。
- 再一些侧腹的动作,俄罗斯转体,仰卧摸脚,俯卧两头起,我说俄罗斯转体应该搞点负重,不然没效果,拿了个哑铃给他,一下子就萎了。现在是跑不过他,但我是不会放过任何一个能嘲讽他的机会滴。
- 其实我跟宋某的分水岭就是10km,以内我跑不赢他,以外他跑不赢我。他黄浦四分马成绩40’55",10km分段推算在38分50秒左右,常规发挥,不算很惊艳。
- 明日嘉伟、小崔、LZR上海半马,ZJC和XR安阳半马,胡哥在淮安全马(首马),目前看来,胡哥和嘉伟的状态都比较稳,胡哥首马有望开315,从四分马的情况来看,嘉伟已经恢复到全盛,希望能PB到120。若是无能为力,那就为别人喝彩。
图像分类是基于深度学习的计算机视觉任务中最简单、也是最基础的一类,它其中用到的CNN特征提取技术也是目标检测、目标分割等视觉任务的基础。
具体到图像分类任务而言,其具体流程如下:
- 输入指定大小RGB图像,1/3通道,宽高一般相等
- 通过卷积神经网络进行多尺度特征提取,生成高维特征值
- 利用全连接网络、或其他结构对高维特征进行分类,输出各目标分类的概率值(概率和为1)
- 选择概率值最高的作为图像分类结果
代码中LABEL_MAP是图像分类名称字典,给定索引得到具体分类名称(string)。
import cv2
import numpy as np
from labels import LABEL_MAP # 1000 labels in imagenet dataset
if __name__=='__main__':
# caffe model, googlenet aglo
weights = "bvlc_googlenet.caffemodel"
protxt = "bvlc_googlenet.prototxt"
# read caffe model from disk
net = cv2.dnn.readNetFromCaffe(protxt, weights)
# create input
image = cv2.imread("ocean-liner.jpg")
blob = cv2.dnn.blobFromImage(image, 1.0, (224, 224), (104, 117, 123), False, crop=False)
result = np.copy(image)
# run!
net.setInput(blob)
out = net.forward()
# TODO(You): 请在此实现代码
# output probability, find the right index
out = out.flatten()
classId = np.argmax(out)
confidence = out[classId]
# time cost
t, _ = net.getPerfProfile()
label = 'cost time: %.2f ms' % (t * 1000.0 / cv2.getTickFrequency())
cv2.putText(result, label, (0, 20), cv2.FONT_HERSHEY_SIMPLEX, 0.8, (255, 255, 0), 2)
# render on image
label = '%s: %.4f' % (LABEL_MAP[classId] if LABEL_MAP else 'Class #%d' % classId, confidence)
cv2.putText(result, label, (0, 60), cv2.FONT_HERSHEY_SIMPLEX, 1, (0, 0, 255), 2)
show_img = np.hstack((image, result))
# normal codes in opencv
cv2.imshow("Image", show_img)
cv2.waitKey(0)
20240421(完篇)
峰谷有时,胜败常事。
若是无能为力,便为他人喝彩。
七点二十抵达东方体育中心(泳耀路与耀龙路交叉口),这里是上半马14km和21km的里程点,也是最佳观赛点。
今年上半马邀请青山学院和国学院大学的箱根选手前来参赛,不少霓虹桑也在此处为他们加油,尽管最终云南的贾俄仁加取得了国内冠军,但是国际排名仅为第9,在他前面还有两位日本大学生(国学院大学的平林清澄第5,青山学院的太田苍生第8),中日马拉松水平的差距可见一斑。
近距离看到这些顶级跑者,尤其是太田苍生——今年第一百回箱根拿下三区区间赏、在起跑落后22秒情况下强势反杀驹泽大的佐藤圭汰(号称最强大学生,场地万米最好成绩27分28秒,比太田快整整一分钟,要知道我们国家记录才28分8秒)4秒的传奇人物,用跑步来形容他们是不准确的,应该说是在起舞,是华丽的舞动,平林在14km处依然紧跟第一集团的4名黑人选手,太田在前半程也是紧跟追逐集团的2位黑人,直到18km之后才被甩开,冲线时他就在我身前掠过,一眼就能认出那张俊秀的脸,兼具力量与轻盈的跑姿,身边的霓虹桑喊着Aoi がんばって,引得我也不禁学着喊了两声(工地日语:阿噢一,刚巴爹!)。
在第一百回箱根的纪录片里,太田的教练说,他是一个懂得如何赢得比赛的人,就像一只狼,你一旦被太田盯上,他就会一直咬着你直到终点。凭借骇人的意志,太田跑出箱根三区的区间赏(同时也是箱根三区历史第二的成绩,第一是外籍黑人留学生创造的)。
- 哔哩哔哩·半马58分56秒! 连日本史上最强大学生也被他拉爆——太田苍生是谁?
- 有人要说,那为什么这次太田苍生都没跑赢平林清澄,后者那更是个怪物,首马即跑出206,比今年3月24日何杰在无锡马拉松创造的国家纪录还要快。而且太田要更帅一些,有种当年白衣修士设乐悠太的风范。
太田生吃佐藤名场面👇

校内战况:实力最强的嘉伟和小崔都发挥失常,嘉伟前10km跑出37分半,明显奔着120去跑,但是中途肠胃不适,3km多跑去上了个厕所,节奏大乱,后半程跑崩,配速掉到4分20秒开外,最终仅128完赛,大大低于预期;小崔中途岔气,净成绩145,甚至比去年上马的前半程都要慢。不过,新人LZR和XR都跑出了很惊艳的成绩,LZR139(PB8分钟),XR132(PB10分钟,非常好的成绩,跑到脚上都出血),ZJC依然是预料之中的138,他太缺力量训练,提升始终不明显;胡哥则是极其稳定的发挥,首马即跑出324,30km后没有大崩,是相当惊艳的成绩了。
我,嘉伟,AK,胡哥这些老人,对成绩的执着已经远远不如这些年轻一辈了,我一直跟队里几位新生强调注重力量训练,跑前跑后的热身和拉伸,以前我也不注重这些,很多事情,不去经历和痛过,就很难学会珍惜。但是对我来说,首马破三始终是个心结,我还是不愿意那么轻易地放下。
前两天SXY很唐突地问我怎么才能跑得快,我大概能猜到她的心思,说慢慢跑就能变快,但是不如逆向思考,与其追上别人,不如让别人停下来等你。虽然很多时候让别人停下并不是很现实的事情,但是相信我,慢慢跑真的有用。从科学角度来说,慢跑的有氧堆积是可以使得有氧配速逐渐逼近绝对速度,许多业余马拉松跑者平时只进行有氧慢跑训练,也能达到破三水平;从哲学角度来说,越慢就会越快,而越快也会越慢,其实很少有很纯粹的跑者,我们执着的并非跑步本身,都是一些外物罢了。
但是,今天我真的很希望嘉伟能跑出好成绩,因为缺席首马,4月21日对我来说是很遗憾的一天,我为了首马准备了许久,最终却不得不放弃。我不希望嘉伟会跟我承受同样的遗憾(他刚刚崩了一次锡马,又被我超越了半马PB,当然很想在上半马扳回一城),我知道嘉伟跑完也很痛苦,如果嘉伟能跑出120以内的成绩,也算是我今天不枉此行,但是我在14km处等到嘉伟跑来时,已经是7:56,说明此时平均配速已经掉出4分配,我猜到他应该是崩了,等到折返20km时,我看到嘉伟已经是一脸无奈,完全提不起精神,我扯着嗓子大喊着加油,说没事没事,跑完就好,跑完就好,下次再来就是了。一路陪着他跑到终点。
至少,赛前我觉得嘉伟想PB应该是很轻松的事,我并不觉得自己的1:24:05会对嘉伟产生什么威胁,这个成绩他想跑出来难度并不算太大,但很多事情就是如此滑稽,越是想做成,就越是难以达到。
如今,物欲横流,成败论英雄,各种变数交错,蝴蝶效应愈发明显,各种随机事件的方差越来越大,传统意义上事物相关性愈渐衰弱,纯粹的事情越来越少。诚然,我们并非那些受害最深的人,但总有人在负重前行。因此,平等和尊重,是最重要的事情。你所拥有的一切,真的都本该属于你吗?我觉得绝大多数源于外物,而非本身。
但是,有些东西真的本该属于我,就算我今天放弃了,也终究会属于我。没有人会一直输,没有人是永远的赢家。
任千帆竞发,吾自悠然拨桨,直至彼岸。
END


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









