







概念
ZooKeeper 是一个开源的分布式协调服务。它是一个为分布式应用提供一致性服务的软件,用于维护配置信息,命名,提供分布式同步以及提供组服务的集中式服务。
参考文档:https://zookeeper.apache.org/doc/current/zookeeperOver.html
下载安装
略;
可视化工具:zkui、ZooInspector
应用场景
Zookeeper主要包括四种节点类型,通过对 Zookeeper 中丰富的数据节点进行交叉使用,配合 Watcher 事件通知机制,主要能实现以下应用场景:
(1)数据发布/订阅
(2)负载均衡(通过节点管理服务列表,具体负载算法需要程序进行实现)
(3)命名服务
(4)分布式协调/通知
(5)集群管理
(6)Master 选举
(7)分布式锁
(8)分布式队列
数据结构
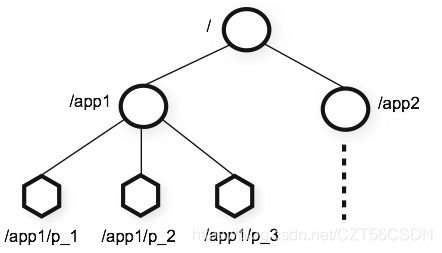
学习zookeeper首先要了解其数据结构, Zookeeper 的视图结构跟标准的 Unix 文件系统很像,都有一个根节点 / 。在根节点下面就是一个个的子节点,我们称为 ZNode。这个存储结构是一个树形结构。
可以使用zkCli命令,登录到zookeeper上,并通过ls、create、delete、sync等命令操作这些znode节点
这些应用场景主要依赖于zk的节点,
四种类型的数据节点 Znode
(1)PERSISTENT-持久节点
除非手动删除,否则节点一直存在于 Zookeeper 上
(2)EPHEMERAL-临时节点
临时节点的生命周期与客户端会话绑定,一旦客户端会话失效(客户端与zookeeper 连接断开不一定会话失效),那么这个客户端创建的所有临时节点都会被移除。
(3)PERSISTENT_SEQUENTIAL-持久顺序节点
基本特性同持久节点,只是增加了顺序属性,节点名后边会追加一个由父节点维护的自增整型数字。
(4)EPHEMERAL_SEQUENTIAL-临时顺序节点
基本特性同临时节点,增加了顺序属性,节点名后边会追加一个由父节点维护的自增整型数字。
基础操作
(增 删 改 查;注册,监听)
Java绑定
ZooKeeper Java绑定有两个软件包:org.apache.zookeeper和org.apache.zookeeper.data。构成ZooKeeper的其余软件包在内部使用或作为服务器实现的一部分。所述org.apache.zookeeper.data包装由被简单地用作容器生成的类组成。
ZooKeeper Java客户端使用的主要类是ZooKeeper类。它的两个构造函数的区别仅在于可选的会话ID和密码。ZooKeeper支持跨流程实例的会话恢复。Java程序可以将其会话ID和密码保存到稳定的存储中,然后重新启动并恢复该程序的较早实例所使用的会话。
Watcher 机制
Watcher 机制是 ZooKeeper 实现分布式协调服务的重要特性。
首先,我们要知道为什么需要watcher机制,什么场景需要用到,其作用什么?
问题:
在分布式集群中,当某个通用的配置发生变化后,怎么让自动的让所有服务器的配置统一生效?
当集群中某个节点宕机,如何让集群中的其他节点知道?
在 ZooKeeper 中,引入了 Watcher 机制来实现这种分布式的通知功能。ZooKeeper 允许客户端向服务端注册一个 Watcher 监听,当服务器的一些特定事件触发了这个 Watcher,那么就会向指定客户端发送一个事件通知来实现分布式的通知功能
ZooKeeper 的 Watcher 机制主要包括客户端线程、客户端 WatchManager 和 ZooKeeper 服务器三部分。
参考:https://blog.csdn.net/hohoo1990/article/details/78617336
一致性保证
客户端的读请求可以被集群中的任意一台机器处理,如果读请求在节点上注册了监听器,这个监听器也是由所连接的 zookeeper 机器来处理。对于写请求,这些请求会同时发给其他 zookeeper 机器并且达成一致后,请求才会返回成功。因此,随着 zookeeper 的集群机器增多,读请求的吞吐会提高但是写请求的吞吐会下降。
有序性是 zookeeper 中非常重要的一个特性,所有的更新都是全局有序的,每个更新都有一个唯一的时间戳,这个时间戳称为 zxid(Zookeeper Transaction Id)。而读请求只会相对于更新有序,也就是读请求的返回结果中会带有这个zookeeper 最新的 zxid。
HA集群
高可用集群
leader 选举
选举算法:LeaderElection、FastLeaderElection
宕机处理方案
Zookeeper 本身也是集群,推荐配置不少于 3 个服务器。Zookeeper 自身也要保证当一个节点宕机时,其他节点会继续提供服务。
ZK 集群的机制是只要超过半数的节点正常,集群就能正常提供服务。只有在 ZK节点挂得太多,只剩一半或不到一半节点能工作,集群才失效。
分布式一致性
数据同步
Zookeeper 的核心是原子广播机制,这个机制保证了各个 server 之间的同步。实现这个机制的协议叫做 Zab 协议。Zab 协议有两种模式,它们分别是恢复模式和广播模式。
工作状态
Zookeeper 下 Server 工作状态:
分别是 LOOKING、FOLLOWING、LEADING、OBSERVING。
常见问题及解决方案
脑裂和假死
假死:由于心跳超时(网络原因导致的)认为leader死了,但其实leader还存活着。
脑裂:由于假死会发起新的leader选举,选举出一个新的master,简单来说就是存在多个leader,相1当多个集群
解决方案:
要解决Split-Brain的问题,一般有3种方式:
Quorums(ˈkwôrəm 法定人数) :比如3个节点的集群,Quorums = 2, 也就是说集群可以容忍1个节点失效,这时候还能选举出1个lead,集群还可用。比如4个节点的集群,它的Quorums = 3,Quorums要超过3,相当于集群的容忍度还是1,如果2个节点失效,那么整个集群还是无效的
Redundant communications:冗余通信的方式,集群中采用多种通信方式,防止一种通信方式失效导致集群中的节点无法通信。
Fencing, 共享资源的方式:比如能看到共享资源就表示在集群中,能够获得共享资源的锁的就是Leader,看不到共享资源的,就不在集群中。
ZooKeeper默认采用了Quorums这种方式
这里参考:https://blog.csdn.net/u013374645/article/details/93140148
本文仅供个人学习记录(待完善)!














 264
264











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









