







0.前言
本文主要记录自己在使用TensorFlow版SSD算法训练自己的数据集时的步骤。
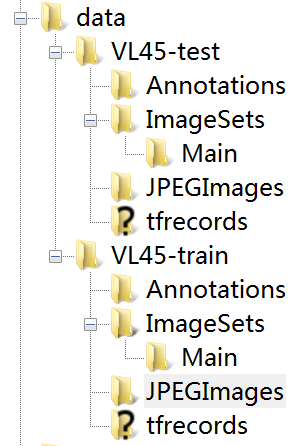
我的文件夹具体内容如下图所示。这里只能显示文件夹,单独的文件无法显示。

1.数据集准备
数据集按照VOC的格式进行制作,图片标注的工具使用的是labelImg。数据集文件夹存放的方式需要稍作改变。具体格式如图片所示,文件夹分为test和train两个文件夹,Annotations文件夹放置的是对应的图片的标注信息,JPEGImages文件夹放置的是对应的图片。ImageSets文件夹中包含Main文件夹,test下的Main文件夹包括text.txt文件,train下的文件夹包括train.txt,val.txt,trainval.txt三个文件,但文件中的内容是一致的。同时还要在test和train文件夹下分别新建tfrecords文件夹,留作数据转换后存放文件使用。
2.数据格式转换
SSD算法在训练之前需要对数据格式进行转换。
- 首先要修改datdsets文件夹中pascalvoc_common.py文件,将其中的类别修改成自己数据集的类别。我的数据集是一个包括45类的车标数据集。
VOC_LABELS = {
'none': (0, 'Background'),
'BAIC GROUP': (1, 'BAIC GROUP'),
'Ford': (2, 'Ford'),
'SKODA': (3, 'SKODA'),
'Venucia': (4, 'Venucia'),
'HONDA': (5, 'HONDA'),
'NISSAN': (6, 'NISSAN'),
'Cadillac': (7, 'Cadillac'),
'SUZUKI': (8, 'SUZUKI'),
'GEELY': (9, 'GEELY'),
'Porsche': (10, 'Porsche'),
'Jeep': (11, 'Jeep'),
'BAOJUN': (12, 'BAOJUN'),
'ROEWE': (13, 'ROEWE'),
'LINCOLN': (14, 'LINCOLN'),
'TOYOTA': (15, 'TOYOTA'),
'Buick': (16, 'Buick'),
'Chery': (17, 'Chery'),
'KIA': (18, 'KIA'),
'HAVAL': (19, 'HAVAL'),
'Audi': (20, 'Audi'),
'LAND ROVER': (21, 'LAND ROVER'),
'Volkswagen': (22, 'Volkswagen'),
'Trumpchi': (23, 'Trumpchi'),
'CHANGAN': (24, 'CHANGAN'),
'Morris Garages': (25, 'Morris Garages'),
'Renault': (26, 'Renault'),
'LEXUS': (27, 'LEXUS'),
'BMW': (28, 'BMW'),
'MAZDA': (29, 'MAZDA'),
'Mercedes-Benz': (30, 'Mercedes-Benz'),
'HYUNDAI': (31, 'HYUNDAI'),
'Chevrolet': (32, 'Chevrolet'),
'BYD': (33, 'BYD'),
'PEUGEOT': (34, 'PEUGEOT'),
'Citroen': (35, 'Citroen'),
'Huachen Auto Group': (36, 'Huachen Auto Group'),
'Volvo': (37, 'Volvo'),
'Mitsubishi': (38, 'Mitsubishi'),
'Subaru': (39, 'Subaru'),
'GMC': (40, 'GMC'),
'Infiniti': (41, 'Infiniti'),
'FAW Haima': (42, 'FAW Haima'),
'SGMW': (43, 'SGMW'),
'Soueast Motor': (44, 'Soueast Motor'),
'QOROS': (45, 'QOROS'),
}
- 修改datasets文件夹下的pascalvoc_to_records.py文件,更改83行的读取方式为‘rb’,同时检查图片类型是否与你自己的数据集的格式一致。还有第67行,可以修改几张图片转为一个tfrecords,我的数据集比较大,选择了200张转为一个,这个具体视自己的数据集而定。
# Read the image file.
filename = directory + DIRECTORY_IMAGES + name + '.jpg'
image_data = tf.gfile.FastGFile(filename, 'rb').read()
# TFRecords convertion parameters.
RANDOM_SEED = 4242
SAMPLES_PER_FILES = 200
- 接下来就可以进行数据转换了。在SSD_test_VL45文件夹下新建tf_convert_data.sh文件。复制如下第一段代码,运行tf_convert_data.sh文件,完成训练数据的转换。修改代码成第二段,再运行tf_convert_data.sh文件,完成测试数据的转换。其中具体的路径和文件夹的名称根据自己的来。转换完成后将会在前文提到的两个tfrecords文件夹中看到相应的文件。
python tf_convert_data.py \
--dataset_name=pascalvoc \
--dataset_dir=./data/VL45-train/ \
--output_name=voc_2007_train \
--output_dir=./data/VL45-train/tfrecords
python tf_convert_data.py \
--dataset_name=pascalvoc \
--dataset_dir=./data/VL45-test/ \
--output_name=voc_2007_test \
--output_dir=./data/VL45-test/tfrecords
3.配置300x300的网络
接下来就到了配置网络部分了,首先要对一些文件进行修改。
- train_ssd_network.py文件中修改:
(1)多少次显示一下结果(100),多少次保存一下模型(1000)。
(2)开始学习率(0.001),最终学习率(0.000001)。
(3)训练类别(45+1)
(4)batch size大小(4)
(5)最大训练步骤(800000)
还有其他的参数也可以进行更改。
tf.app.flags.DEFINE_integer(
'log_every_n_steps', 100,
'The frequency with which logs are print.')
tf.app.flags.DEFINE_integer(
'save_summaries_secs', 1000,
'The frequency with which summaries are saved, in seconds.')
tf.app.flags.DEFINE_integer(
'save_interval_secs', 1000,
'The frequency with which the model is saved, in seconds.')
tf.app.flags.DEFINE_float('learning_rate', 0.001, 'Initial learning rate.')
tf.app.flags.DEFINE_float(
'end_learning_rate', 0.000001,
'The minimal end learning rate used by a polynomial decay learning rate.')
tf.app.flags.DEFINE_integer(
'num_classes', 46, 'Number of classes to use in the dataset.')
tf.app.flags.DEFINE_integer(
'batch_size', 4, 'The number of samples in each batch.')
tf.app.flags.DEFINE_integer('max_number_of_steps', 800000,
'The maximum number of training steps.')
- eval_ssd_network.py修改:
(1)类别
(2)batch size 大小
tf.app.flags.DEFINE_integer(
'num_classes', 46, 'Number of classes to use in the dataset.')
tf.app.flags.DEFINE_integer(
'batch_size', 4, 'The number of samples in each batch.')
- nets/ssd_vgg_300.py文件修改类别:
num_classes=46,
no_annotation_label=46,
- datasets/pascalvoc_2007.py文件修改:
类别后面的数字是该类别包含的图片数量和出现的次数,这个数字没有实际作用,不影响训练,所以如果你进行统计了可以如实填写,我没有统计所以统一写了1。
SPLITS_TO_SIZES是训练集(35010)和测试集(9990)包含的图片数量,还有NUM_CLASSES(45)是类别数量也要如实填写。
TRAIN_STATISTICS = {
'none': (0, 0),
'BAIC GROUP': (1, 1),
'Ford': (1, 1),
'SKODA': (1, 1),
'Venucia': (1, 1),
'HONDA': (1, 1),
'NISSAN': (1, 1),
'Cadillac': (1, 1),
'SUZUKI': (1, 1),
'GEELY': (1, 1),
'Porsche': (1, 1),
'Jeep': (1, 1),
'BAOJUN': (1, 1),
'ROEWE': (1, 1),
'LINCOLN': (1, 1),
'TOYOTA': (1, 1),
'Buick': (1, 1),
'Chery': (1, 1),
'KIA': (1, 1),
'HAVAL': (1, 1),
'Audi': (1, 1),
'LAND ROVER': (1, 1),
'Volkswagen': (1, 1),
'Trumpchi': (1, 1),
'CHANGAN': (1, 1),
'Morris Garages': (1, 1),
'Renault': (1, 1),
'LEXUS': (1, 1),
'BMW': (1, 1),
'MAZDA': (1, 1),
'Mercedes-Benz': (1, 1),
'HYUNDAI': (1, 1),
'Chevrolet': (1, 1),
'BYD': (1, 1),
'PEUGEOT': (1, 1),
'Citroen': (1, 1),
'Huachen Auto Group': (1, 1),
'Volvo': (1, 1),
'Mitsubishi': (1, 1),
'Subaru': (1, 1),
'GMC': (1, 1),
'Infiniti': (1, 1),
'FAW Haima': (1, 1),
'SGMW': (1, 1),
'Soueast Motor': (1, 1),
'QOROS': (1, 1),
'total': (35010, 35010),
}
TEST_STATISTICS = {
'none': (0, 0),
'BAIC GROUP': (1, 1),
'Ford': (1, 1),
'SKODA': (1, 1),
'Venucia': (1, 1),
'HONDA': (1, 1),
'NISSAN': (1, 1),
'Cadillac': (1, 1),
'SUZUKI': (1, 1),
'GEELY': (1, 1),
'Porsche': (1, 1),
'Jeep': (1, 1),
'BAOJUN': (1, 1),
'ROEWE': (1, 1),
'LINCOLN': (1, 1),
'TOYOTA': (1, 1),
'Buick': (1, 1),
'Chery': (1, 1),
'KIA': (1, 1),
'HAVAL': (1, 1),
'Audi': (1, 1),
'LAND ROVER': (1, 1),
'Volkswagen': (1, 1),
'Trumpchi': (1, 1),
'CHANGAN': (1, 1),
'Morris Garages': (1, 1),
'Renault': (1, 1),
'LEXUS': (1, 1),
'BMW': (1, 1),
'MAZDA': (1, 1),
'Mercedes-Benz': (1, 1),
'HYUNDAI': (1, 1),
'Chevrolet': (1, 1),
'BYD': (1, 1),
'PEUGEOT': (1, 1),
'Citroen': (1, 1),
'Huachen Auto Group': (1, 1),
'Volvo': (1, 1),
'Mitsubishi': (1, 1),
'Subaru': (1, 1),
'GMC': (1, 1),
'Infiniti': (1, 1),
'FAW Haima': (1, 1),
'SGMW': (1, 1),
'Soueast Motor': (1, 1),
'QOROS': (1, 1),
'total': (9990, 9990),
}
SPLITS_TO_SIZES = {
'train': 35010,
'test': 9990,
}
SPLITS_TO_STATISTICS = {
'train': TRAIN_STATISTICS,
'test': TEST_STATISTICS,
}
NUM_CLASSES = 45
4.训练300x300的网络
以上就完成了训练前的配置工作,接下来就可以进行训练了。
- 在SSD_test_VL54文件夹下新建train_model_300文件夹留作存放训练模型。
- 在SSD_test_VL54文件夹下新建train_VOC2007_300.sh文件,复制以下代码:
对应参数和路径有不同的自行修改,其他博客会有加载VGG16的部分模型参数的代码,但是我训练以后发现效果特别差,所以这里就没有加载参数,而是直接进行训练。
DATASET_DIR=./data/tfrecordsdata/
TRAIN_DIR=./train_model/
CHECKPOINT_PATH=./checkpoints/vgg_16.ckpt
python train_ssd_network.py \
--train_dir=./train_model_300/ \
--dataset_dir=./data/VL45-train/tfrecords/ \
--dataset_name=pascalvoc_2007 \
--dataset_split_name=train \
--model_name=ssd_300_vgg \
--save_summaries_secs=100 \
--save_interval_secs=1000 \
--weight_decay=0.0005 \
--optimizer=adam \
--learning_rate=0.0001 \
--learning_rate_decay_factor=0.94 \
--batch_size=4 \
- 完成以上操作以后,终端输入 bash train_VOC2007_300.sh 命令即可开始训练。
5.测试300x300的网络
- 在SSD_test_VL45文件夹下新建result_300文件夹用以存放测试结果。
- 在SSD_test_VL45文件夹下新建一个test_VOC2007.sh文件,复制下列代码,相应路径根据自己的进行修改,然后运行即可得到检测结果。
python eval_ssd_network.py \
--eval_dir=./result_300/ \
--dataset_dir=./data/VL45-test/tfrecords/ \
--dataset_name=pascalvoc_2007 \
--dataset_split_name=test \
--model_name=ssd_300_vgg \
--checkpoint_path=./train_model_300/model.ckpt-800000 \
--batch_size=1
- 原程序中默认的是输出VOC2007和VOC2012的mAP值,只看07的结果就可以了 ,如果想得到每一类的AP值,可以更改 eval_ssd_network.py中的代码,将对应位置的#做添加或去除处理就可以。
# Average precision VOC07.
v = tfe.average_precision_voc07(prec, rec)
summary_name = 'AP_VOC07/%s' % c
op = tf.summary.scalar(summary_name, v, collections=[])
op = tf.Print(op, [v], summary_name)
tf.add_to_collection(tf.GraphKeys.SUMMARIES, op)
aps_voc07[c] = v
# Average precision VOC12.
v = tfe.average_precision_voc12(prec, rec)
summary_name = 'AP_VOC12/%s' % c
op = tf.summary.scalar(summary_name, v, collections=[])
# op = tf.Print(op, [v], summary_name)
tf.add_to_collection(tf.GraphKeys.SUMMARIES, op)
aps_voc12[c] = v
# Mean average precision VOC07.
summary_name = 'AP_VOC07/mAP'
mAP = tf.add_n(list(aps_voc07.values())) / len(aps_voc07)
op = tf.summary.scalar(summary_name, mAP, collections=[])
op = tf.Print(op, [mAP], summary_name)
tf.add_to_collection(tf.GraphKeys.SUMMARIES, op)
# Mean average precision VOC12.
summary_name = 'AP_VOC12/mAP'
mAP = tf.add_n(list(aps_voc12.values())) / len(aps_voc12)
op = tf.summary.scalar(summary_name, mAP, collections=[])
# op = tf.Print(op, [mAP], summary_name)
tf.add_to_collection(tf.GraphKeys.SUMMARIES, op)
6.配置512x512的模型
- 修改nets/ssd_vgg_512.py的类别:
num_classes=46,
no_annotation_label=46,
- 修改nets/np_methods.py文件中的尺寸和类别(注意有两处):
img_shape=(512, 512),
num_classes=46,
- 修改preprocessing/ssd_vgg_preprocessing.py,文件中300改成512:
EVAL_SIZE = (512, 512)
- 修改train_ssd_network.py文件,
tf.app.flags.DEFINE_string(
'model_name', 'ssd_512_vgg', 'The name of the architecture to train.')
7.在300x300的基础上训练512x512的模型
- 在SSD_test_VL54文件夹下新建train_model_512文件夹留作存放训练模型。
- 在SSD_test_VL54文件夹下新建train_VOC2007_512.sh文件,复制以下代码:
python train_ssd_network.py \
--train_dir=./train_model_512/ \
--dataset_dir=./data/VL45-train/tfrecords/ \
--dataset_name=pascalvoc_2007 \
--dataset_split_name=train \
--model_name=ssd_512_vgg \
--checkpoint_path=./train_model_300/model.ckpt-800000 \
--checkpoint_model_scope=ssd_300_vgg \
--checkpoint_exclude_scopes=ssd_512_vgg/block7,ssd_512_vgg/block7_box,ssd_512_vgg/block8,ssd_512_vgg/block8_box,ssd_512_vgg/block9,ssd_512_vgg/block9_box,ssd_512_vgg/block10,ssd_512_vgg/block10_box,ssd_512_vgg/block11,ssd_512_vgg/block11_box,ssd_512_vgg/block12,ssd_512_vgg/block12_box \
--save_summaries_secs=100 \
--save_interval_secs=1000 \
--weight_decay=0.0005 \
--optimizer=adam \
--learning_rate=0.001 \
--learning_rate_decay_factor=0.94 \
--batch_size=4 \
- 运行train_VOC2007_512.sh文件即可进行训练。
8.测试512x512的网络
- 在SSD_test_VL45文件夹下新建result_512文件夹用以存放测试结果。
- 修改test_VOC2007.sh文件:
python eval_ssd_network.py \
--eval_dir=./result_512/ \
--dataset_dir=./data/VL45-test/tfrecords/ \
--dataset_name=pascalvoc_2007 \
--dataset_split_name=test \
--model_name=ssd_512_vgg \
--checkpoint_path=./train_model_512/model.ckpt-800000 \
--batch_size=1
- 运行test_VOC2007.sh文件即可进行测试。
9.查看检测结果
我的数据集用512的网络得到的mAP更好一些,所以我就使用训练好的512的模型来测试一下检测效果。
- 更改notebooks/ssd_notebook.ipynb文件,300均改成512,如果你要测试300的模型就不用改。
- 在SSD_test_VL45文件夹下新建test.py文件,复制notebooks/ssd_notebook.ipynb中的代码过去。修改模型路径和测试文件夹。
# Restore SSD model.
ckpt_filename = '/home/clj/SSD_test_VL45/train_model_512/model.ckpt-800000'
# Test on some demo image and visualize output.
path = '/home/clj/SSD_test_VL45/data/VL45-test/JPEGImages/'
image_names = sorted(os.listdir(path))
- i代表第几张图片,i=-1时表示最后一张
img = mpimg.imread(path + image_names[i])
- 我的linux系统没有图形界面,所以只能把测试结果保存为图片再下载到本地进行查看,而且为了一次测试多张,我使用了一个for循环。在SSD_test_VL45文件夹下新建了一个output文件夹留作存放测试结果图片。最终这一部分的具体代码改动如下:
# Test on some demo image and visualize output.
path = '/home/clj/SSD_test_VL45/data/VL45-test/JPEGImages/'
image_names = sorted(os.listdir(path))
#print(image_names)
for i in range(1,6):
img = mpimg.imread(path + image_names[i])
#print(img)
rclasses, rscores, rbboxes = process_image(img)
# visualization.bboxes_draw_on_img(img, rclasses, rscores, rbboxes, visualization.colors_plasma)
visualization.plt_bboxes(img, rclasses, rscores, rbboxes)
plt.savefig("output/"+image_names[i])
- 最终的测试结果图如下:

10.总结
训练和测试的过程大体就是这些,还有一些细节可能还没有想到,以后还会有补充。
当然训练过程中还遇到了很多的问题,一时也不好整理,不过也都解决了,所以有问题的可以下方留言一起探讨。
最后,以上的步骤也都参考了一些大神的博客,感谢各位大神。
1.https://blog.csdn.net/Angela_qin/article/details/80930267
2.https://blog.csdn.net/duanyajun987/article/details/81564081
3.https://blog.csdn.net/qq_36396104/article/details/84639904
4.https://blog.csdn.net/liuyan20062010/article/details/78905517















 4831
4831











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









