






目录
定义:MapReduce是一个分布式运算程序的编程框架,其核心功能是将用户编写的业务逻辑代码和自带的默认组件整合成一个完整的分布式运算程序,并发运行在一个Hadoop集群上。
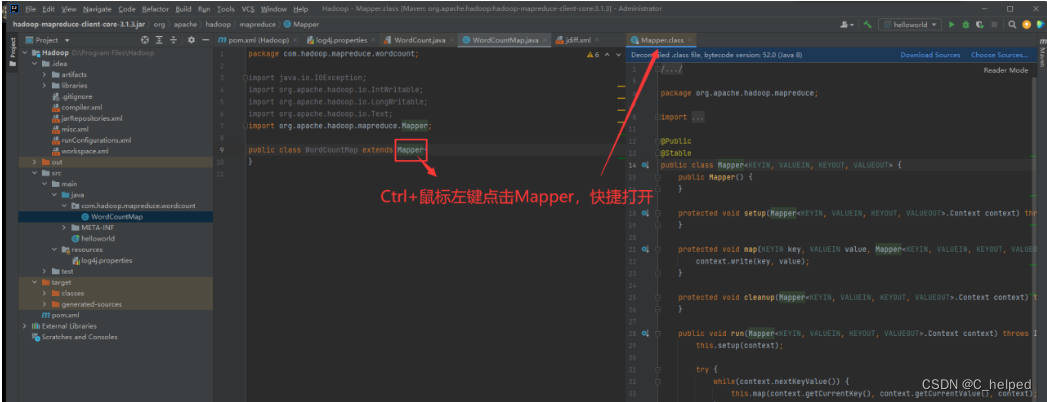
(2)解读部分源码,使用Ctrl+鼠标左键进入定义位置,以Mapper为例
一、MapReduce概述
-
定义:MapReduce是一个分布式运算程序的编程框架,其核心功能是将用户编写的业务逻辑代码和自带的默认组件整合成一个完整的分布式运算程序,并发运行在一个Hadoop集群上。
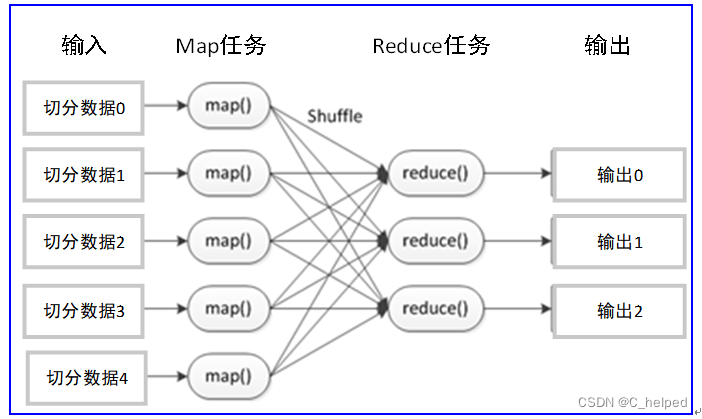
- 一个基本完整的MapReduce程序流程,包括:数据分片-数据映射-数据混洗-数据归约-数据输出
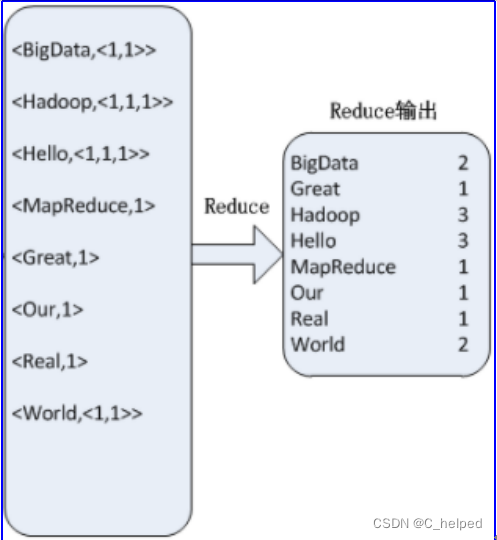
3.一个MapReduce例子:对以下左侧“输入”数据进行词频统计,输出结果如右侧“输出”所示:
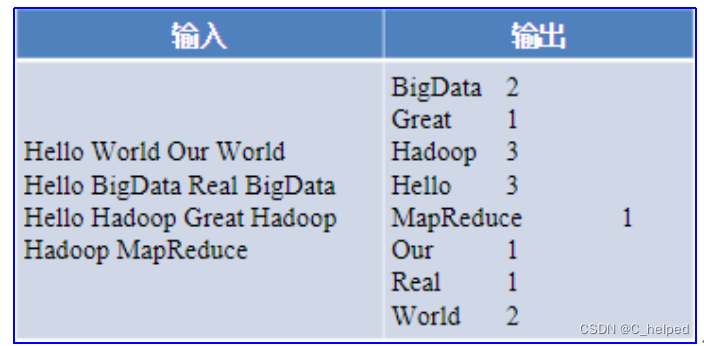
1)Map阶段处理过程
a.对于输入文件进行键值对组合,即切割出每个单词,并发配初始频数1。
b.如,Hello组成<Hello , 1>,其中,Hello是键;1是键值
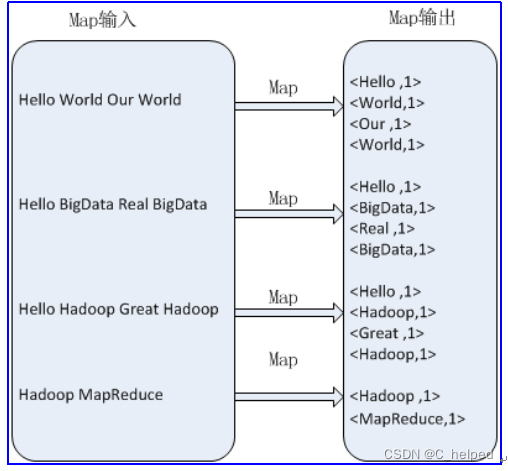
2)Shuffle
a.将键相同的键值进行汇集
b.如,3个<Hello,1>组成了<Hello,<1,1,1>>
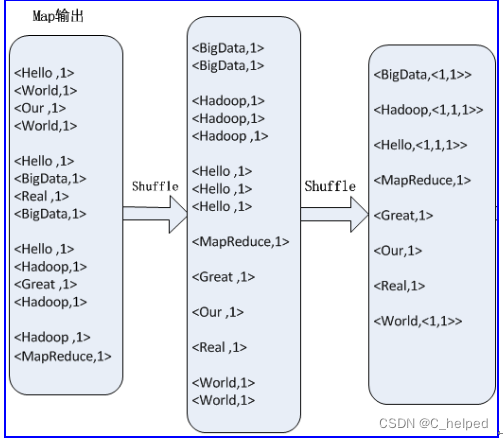
3)Reduce阶段过程
a.根据实际应用进行结果计算
b.如,对<Hello,<1,1,1>>的键值进行汇总计算,1+1+1=3,的到结果Hello 3
二、环境配置
(1)在Windows系统里安装并配置JDK
①安装一直下一步,复制好安装路径后面配置环境变量使用
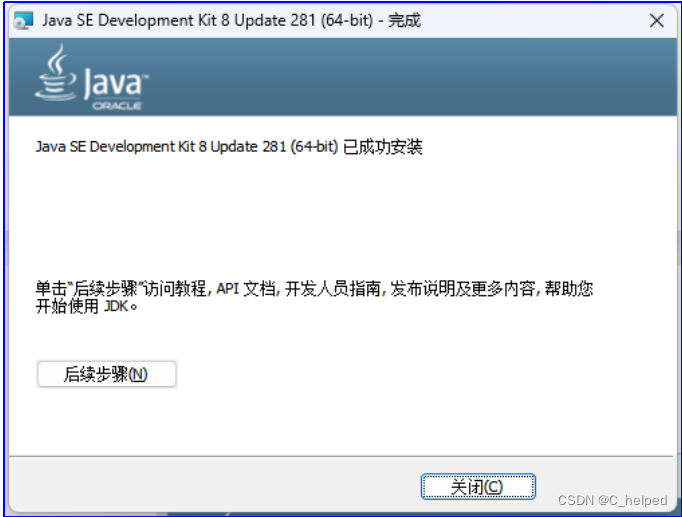
②配置环境变量
1)JAVA_HOME
a.变量名写入JAVA_HOME
b.变量值写入C:\Program Files\Java\jdk1.8.0_281
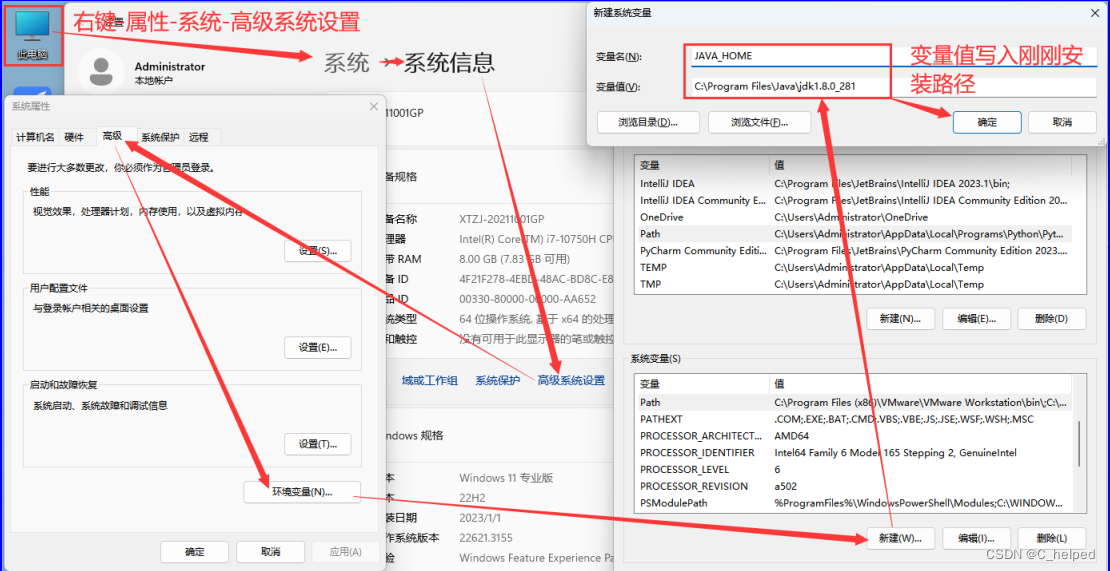
2)Path
a.%JAVA_HOME%\bin
b.%JAVA_HOME%\jre\bin
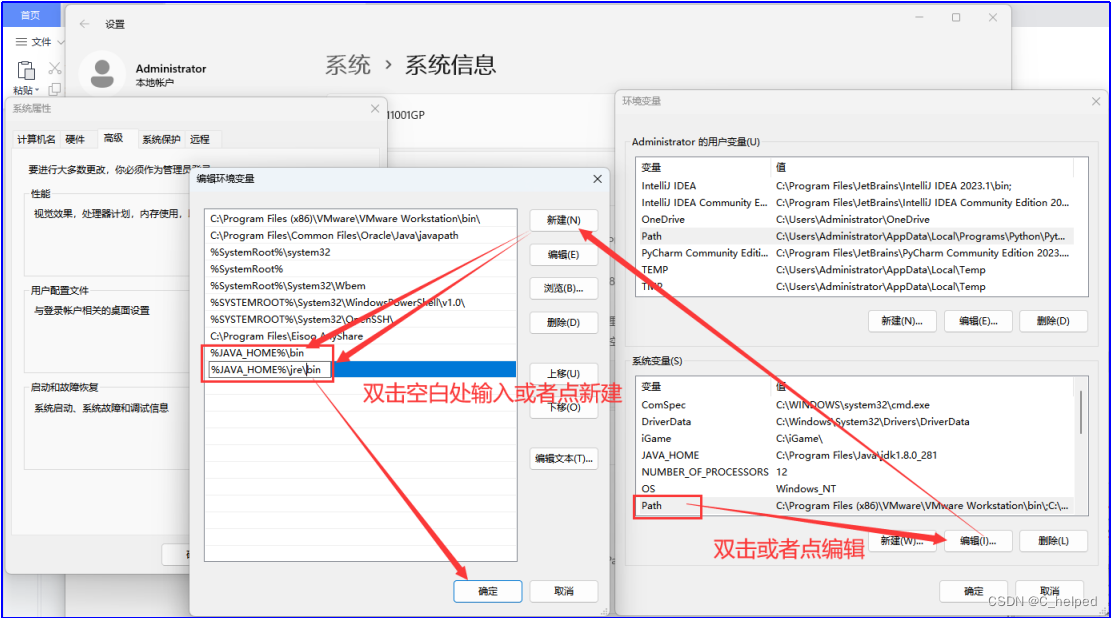
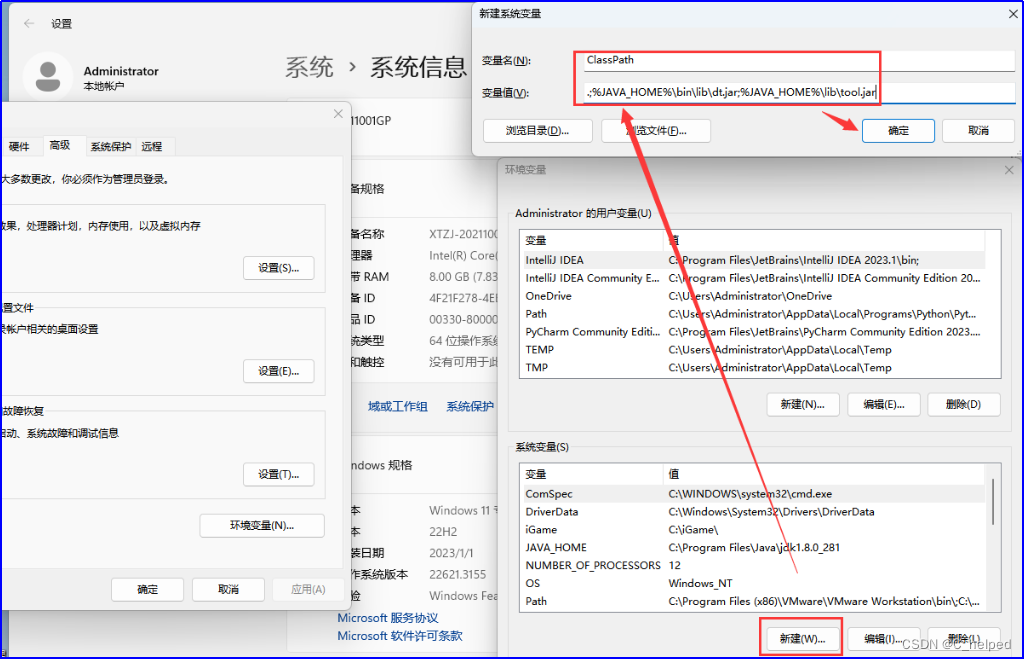
3)ClassPath
a.变量名写入ClassPath
b.变量值写入.;%JAVA_HOME%\bin\lib\dt.jar;%JAVA_HOME%\lib\tool.jar
③CMD验证:java -version

(2)安装IntelliJ IDEA社区版,略
(3)配置Hadoop在Windows系统下的环境
①把hadoop-3.1.0.rar解压并放到一个非中文路径里,并复制它的路径(后面要用)
②配置HADOOP_HOME:右键我的电脑---属性---系统信息---高级系统设置---高级---环境变量---系统变量(S)---新建---新建系统变量
1)变量名:HADOOP_HOME
2)变量值:C:\Program Files\Java\hadoop-3.1.0
3)注意,变量值写入你自己存放的路径
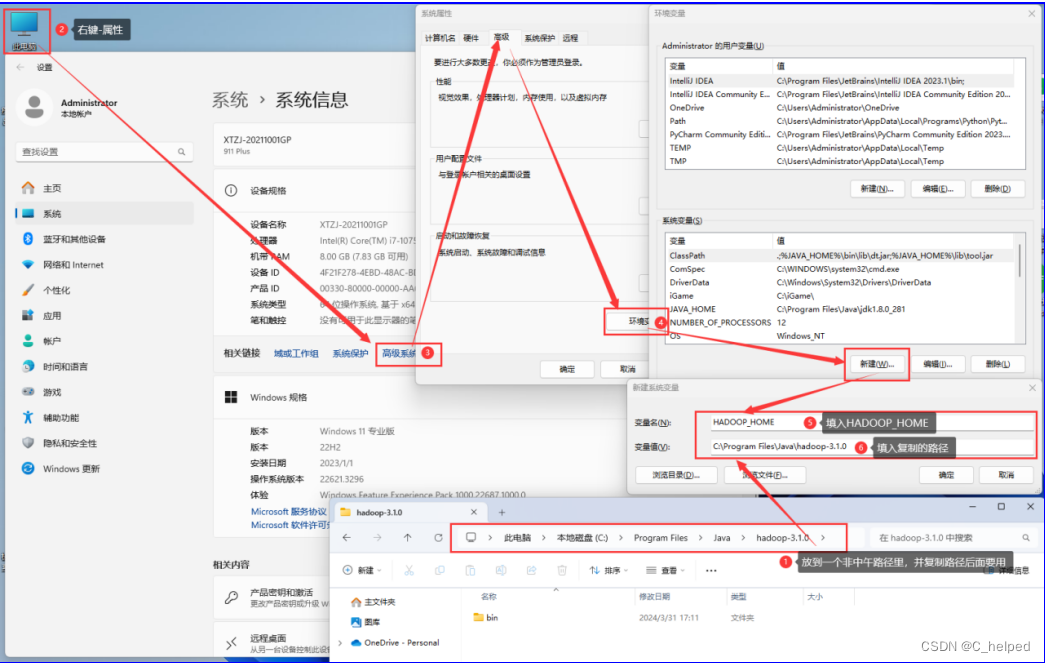
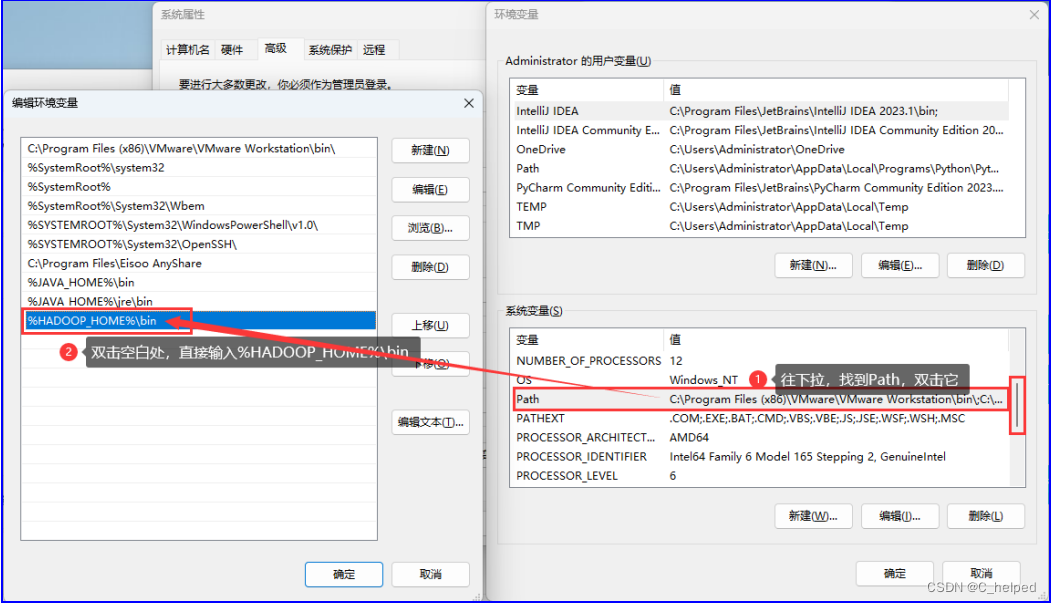
③配置PATH:%HADOOP_HOME%\bin
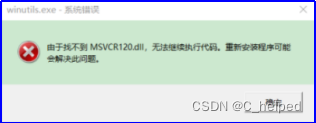
④进入bin目录下C:\Program Files\Java\hadoop-3.1.0\bin,双击winutils.exe文件,正常的话闪一个cmd命令窗口,否则如果弹出以下报错,需要安装微软运行库安装包
(4)使用In2telliJ IDEA创建MapReduce工程
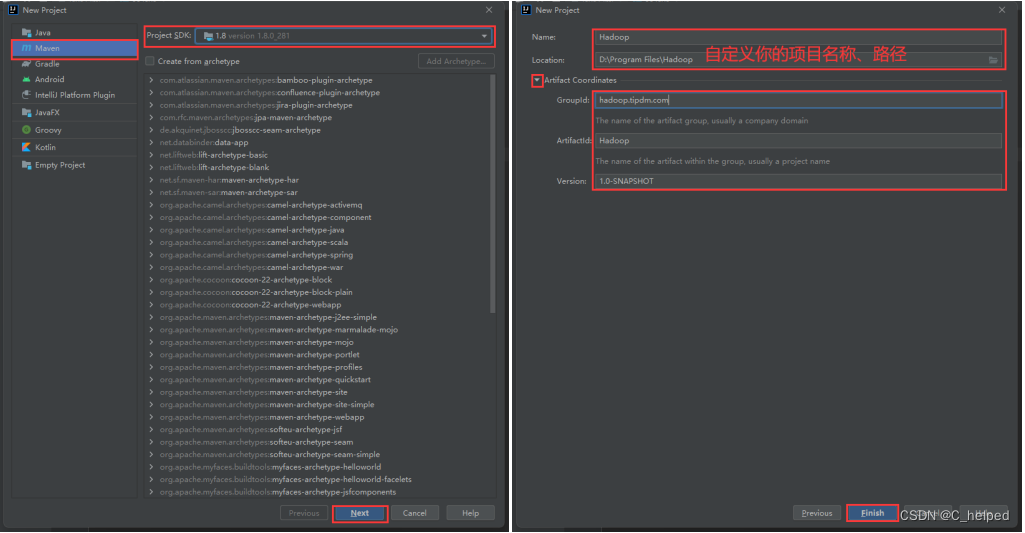
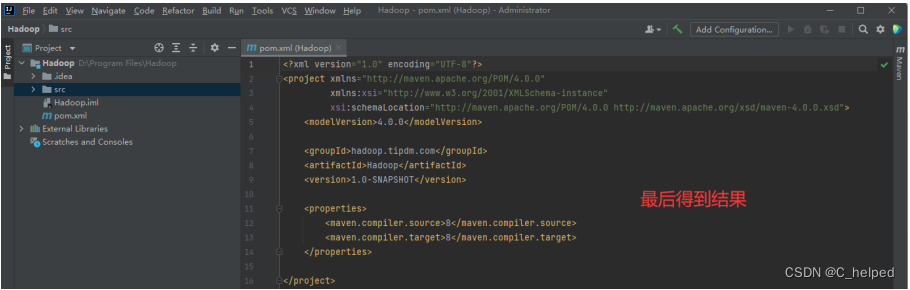
(5)配置maven项目
- 在项目名称\src\main\resources路径下添加一个文件,命名为log4j.properties,并添加以下代码:
log4j.rootLogger=INFO, stdout
log4j.appender.stdout=org.apache.log4j.ConsoleAppender
log4j.appender.stdout.layout=org.apache.log4j.PatternLayout
log4j.appender.stdout.layout.ConversionPattern=%d %p [%c] - %m%n
log4j.appender.logfile=org.apache.log4j.FileAppender
log4j.appender.logfile.File=target/spring.log
log4j.appender.logfile.layout=org.apache.log4j.PatternLayout
log4j.appender.logfile.layout.ConversionPattern=%d %p [%c] - %m%n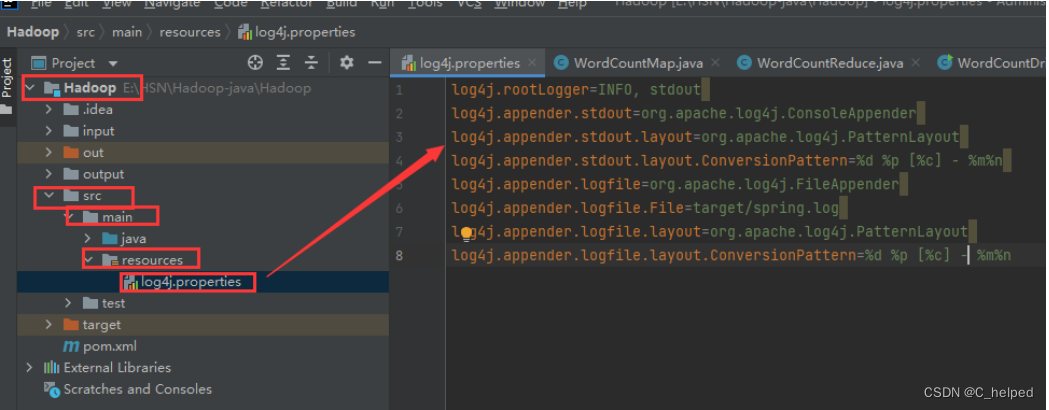
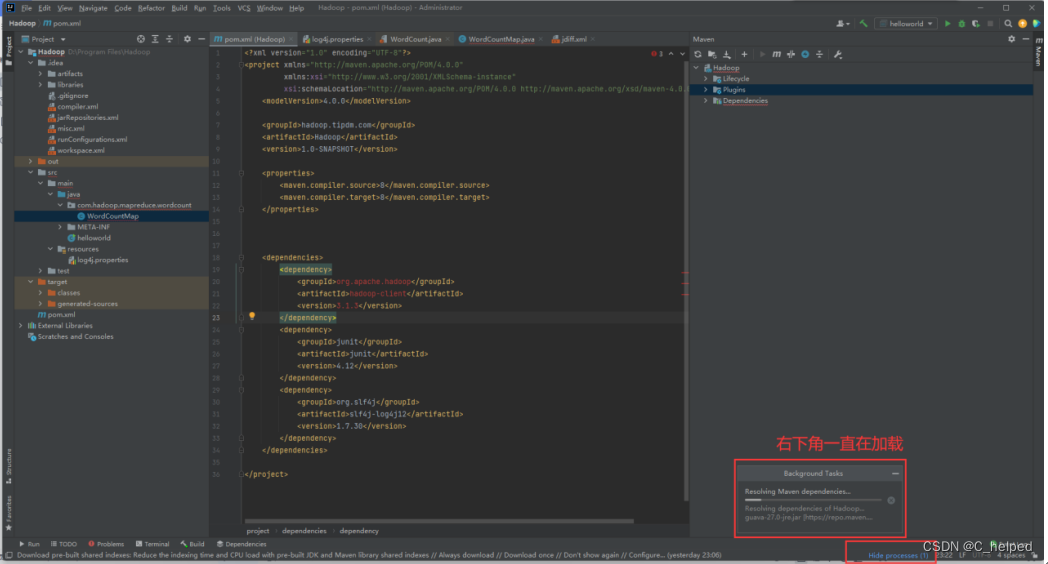
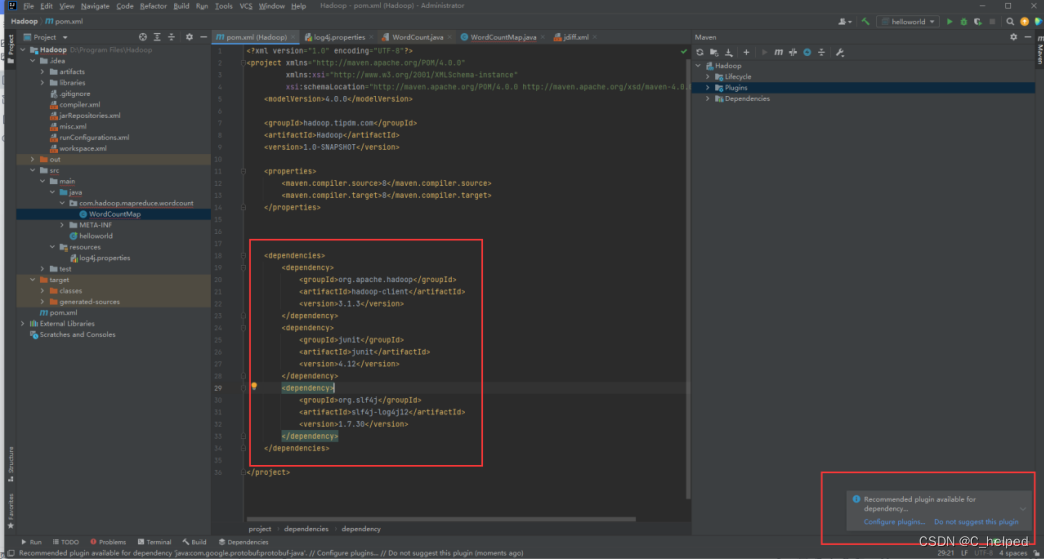
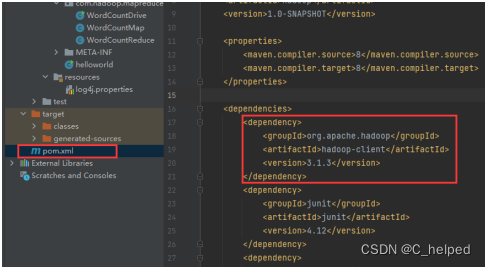
②修改pom.xml文件,添加以下部分代码;如果报红,则如下图设置
<dependencies>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>3.1.3</version>
</dependency>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.12</version>
</dependency>
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-log4j12</artifactId>
<version>1.7.30</version>
</dependency>
</dependencies>
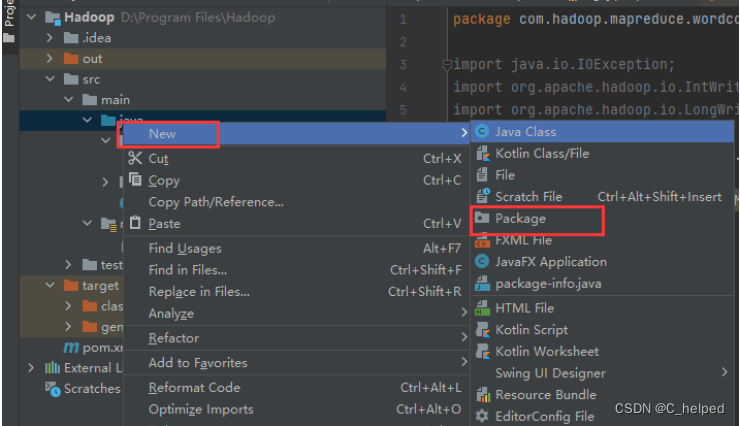
③趁着下载的时间,在IDEA左侧的project栏下的Hadoop-src-main-java路径右键创建一个包,命名为com.hadoop.mapreduce.wordcount
④在包里,右键创建一个WordCountMap类
⑤等待加载前面步骤的,最后成功标志:
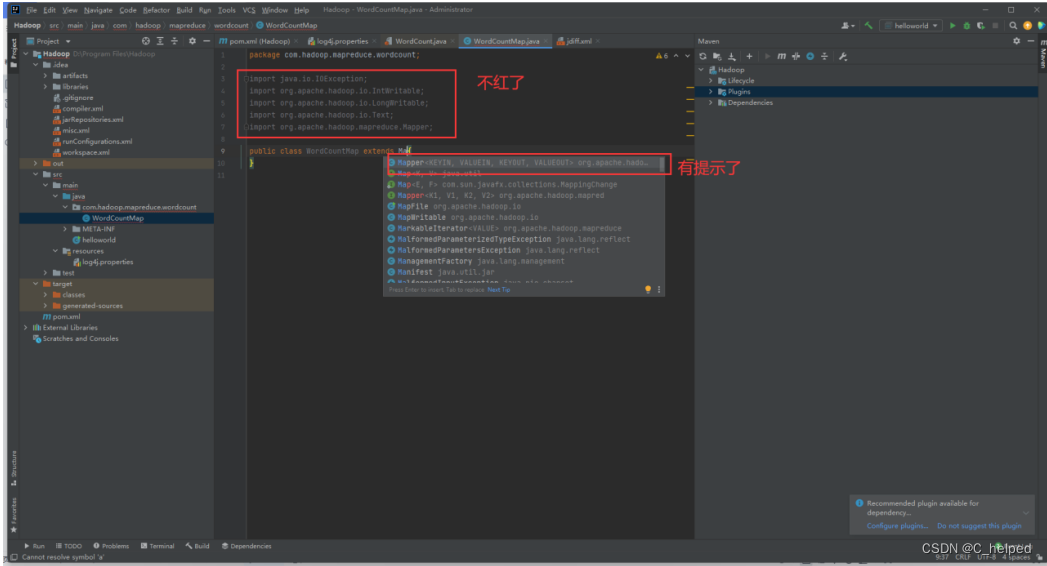
⑥成功后,发现引用包、扩展的Mapper也不报红了
三、理解官方WordCount源码
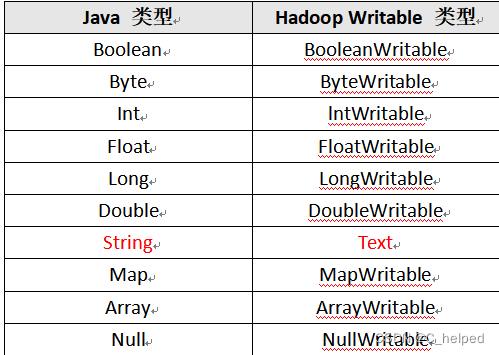
(1)常用的数据类型
(2)解读部分源码,使用Ctrl+鼠标左键进入定义位置,以Mapper为例
①Mapper的参数
1)KEYIN:map阶段输入的key的类型--LongWritable类型
2)VALUEIN:map阶段输入的value的类型--Text类型
3)KEYOUT:map阶段输出的key的类型--Text类型
4)VALUEOUT:map阶段输出的value的类型--IntWritable类型
②map函数:重写关键所在
1)重写,写入具体的业务逻辑
2)使用context.write(key, value)完成数据传递
③Context:当前环境的一种抽象概念,它提供了对环境相关信息的访问和管理能力
1)如,读取输入数据、输出数据、报告进度、获取配置信息等
2)具体如,context.write将键值对输出到下一个阶段(reduce阶段)
④run:
1)先执行setup,再循环(每次执行一遍map),最后cleanup
2)setup:在每个Map任务开始时执行一次的方法,用于进行一些初始化工作,比如打开文件、建立数据库连接等
3)cleanup:当所有输入数据都处理完毕后,run方法会退出循环,并调用cleanup方法。cleanup方法用于执行一些清理工作,比如关闭文件、断开数据库连接等。与setup方法类似,cleanup方法在每个Map任务结束时执行一次。
(3)map阶段编码:
①用户自定义的Mapper要继承自己的父类
②Mapper的输入数据是key-value(KV)对的形式(KV的类型可自定义)
③Mapper中的业务逻辑写在map()方法中
④Mapper的输出数据是KV对的形式(KV的类型可自定义)
⑤map()方法(MapTask进程)对每一个<K,V>调用一次
package com.hadoop.mapreduce.wordcount;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.io.Text;
import java.io.IOException;
public class WordCountReduce extends Reducer<Text, IntWritable,Text,IntWritable> {
private IntWritable outvalue = new IntWritable();
@Override
protected void reduce(Text key, Iterable<IntWritable> values, Reducer<Text, IntWritable, Text, IntWritable>.Context context)
throws IOException, InterruptedException {
// super.reduce(key, values, context);
int sum = 0;
for (IntWritable value : values){
sum += value.get();
}
outvalue.set(sum);
context.write(key,outvalue);
}
}
(4)reduce阶段编码:
①用户自定义的Reducer要继承自己的父类
②Reducer的输入数据类型对应Mapper的输出数据类型,也是KV
③Reducer的业务逻辑写在reduce()方法中
④ReduceTask进程对每一组相同k的<k,v>组调用一次reduce()方法
package com.hadoop.mapreduce.wordcount;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.io.Text;
import java.io.IOException;
public class WordCountDrive {
public static void main(String[] args) throws IOException, InterruptedException, ClassNotFoundException {
Configuration conf = new Configuration();
Job job = Job.getInstance(conf);
job.setJarByClass(WordCountDrive.class);
job.setMapperClass(WordCountMap.class);
job.setReducerClass(WordCountReduce.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(IntWritable.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
FileInputFormat.setInputPaths(job, new Path("输入文件路径"));
FileOutputFormat.setOutputPath(job, new Path("输出文件路径"));
boolean result = job.waitForCompletion(true);
System.exit(result ? 0 : 1);
}
}(5)driver阶段编码:
①配置作业:设置作业的各种参数,如输入和输出的路径、使用的Mapper和Reducer类等。
②提交作业:将配置好的作业提交给ResourceManager。
package com.hadoop.mapreduce.wordcount;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.io.Text;
import java.io.IOException;
public class WordCountDrive {
public static void main(String[] args) throws IOException, InterruptedException, ClassNotFoundException {
Configuration conf = new Configuration();
Job job = Job.getInstance(conf);
job.setJarByClass(WordCountDrive.class);
job.setMapperClass(WordCountMap.class);
job.setReducerClass(WordCountReduce.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(IntWritable.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
FileInputFormat.setInputPaths(job, new Path("输入文件路径"));
FileOutputFormat.setOutputPath(job, new Path("输出文件路径"));
boolean result = job.waitForCompletion(true);
System.exit(result ? 0 : 1);
}
}③执行WordCountDriver
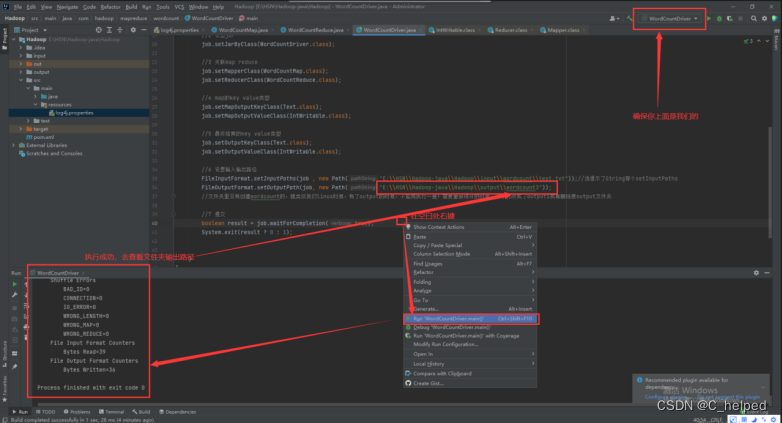 (6)查看结果
(6)查看结果
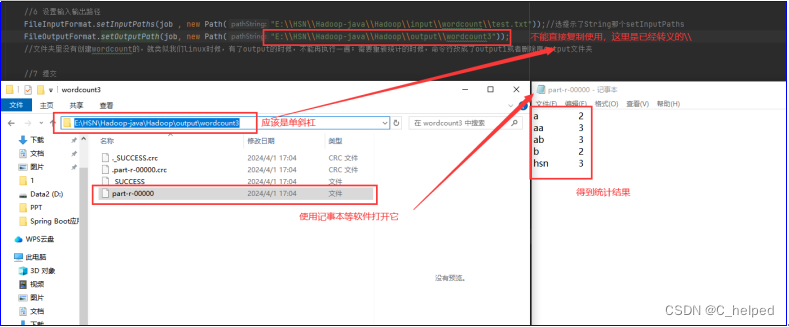
但是,目前启动程序执行过程是由本地运行,没有使用到集群,而下一步,即将打包到集群运行程序。
四、提交到集群运
(1)添加的打包插件依赖,如果报红,又需要右键---maven---reload projec
这里并不会打包上面的本地hadoop依赖,需要用到集群上布置好的hadoop运行
<build>
<plugins>
<plugin>
<artifactId>maven-compiler-plugin</artifactId>
<version>3.6.1</version>
<configuration>
<source>1.8</source>
<target>1.8</target>
</configuration>
</plugin>
</plugins>
</build>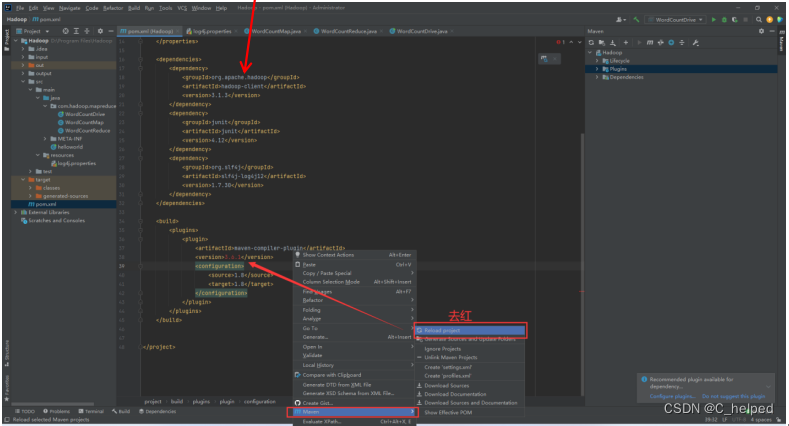
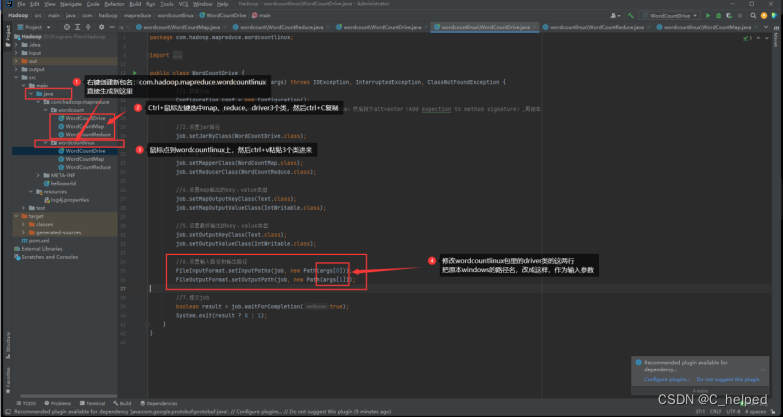
(2)新增包,复制类,对粘贴后新的WordCountDriver做修改,详细看下图:
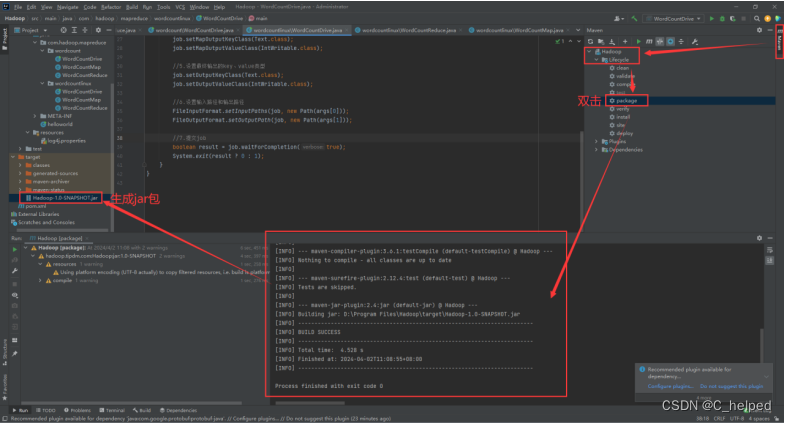
 (3)打包成jar,详细看下图:
(3)打包成jar,详细看下图:
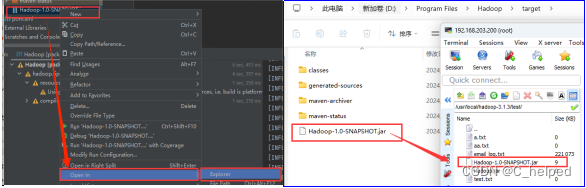
(4)右键所在打开Windows下的路径,并拖拽上传到虚拟机master的/usr/local/hadoop-3.1.3/test/里
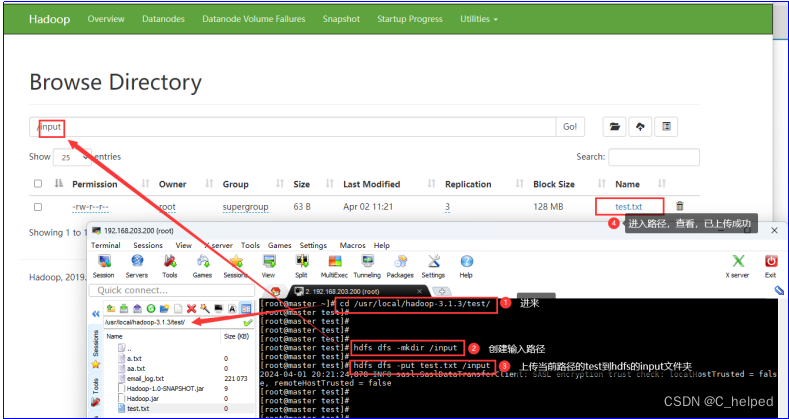
(5)在HDFS创建/input文件夹,并把/usr/local/hadoop-3.1.3/test/里的测试文件test.txt上传到HDFS的/input里,详情看下图:
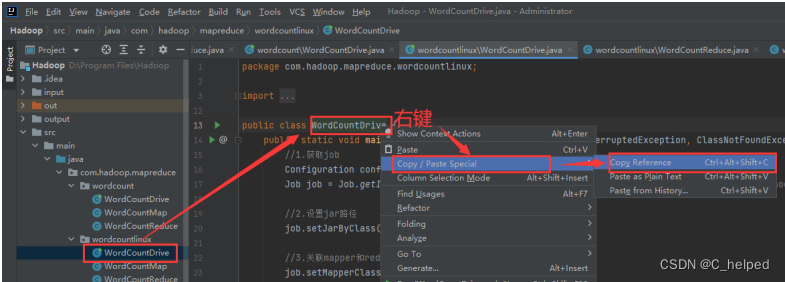
(6)复制全类名(即包名+类名),得到结果:com.hadoop.mapreduce.wordcountlinux.WordCountDrive,后面要用到
(7)使用cd ..命令回到/usr/local/hadoop-3.1.3/路径里,输入以下命令:
hadoop jar ./test/Hadoop-1.0-SNAPSHOT.jar com.hadoop.mapreduce.wordcountlinux.WordCountDrive /input /output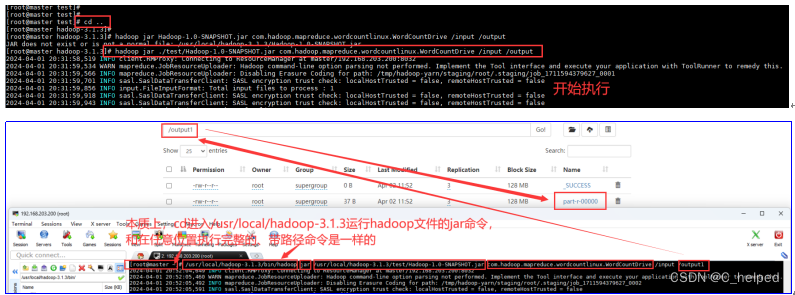
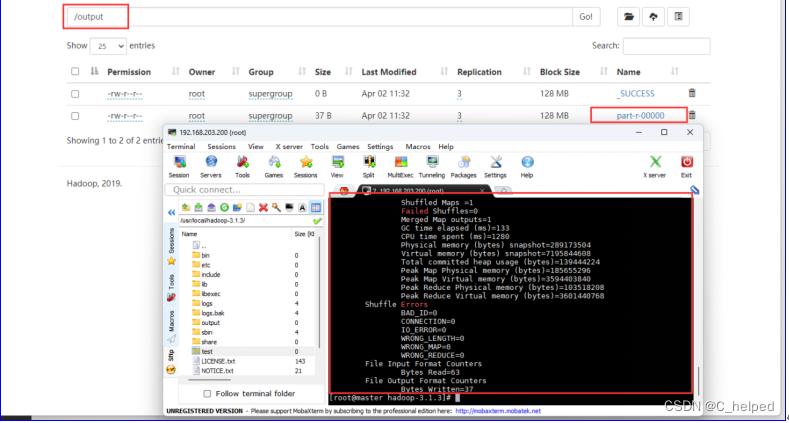
(8)执行成功标志,如下图:
①命令行已经完成输出
②Web端/output有输出文件
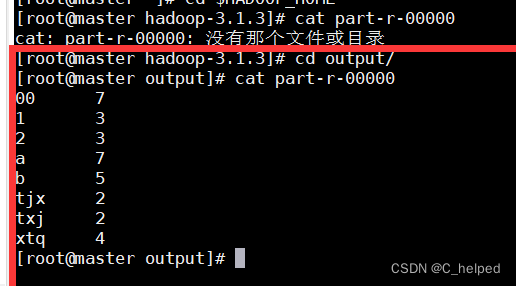
(9)使用命令hdfs dfs -cat /output查看结果:
小结
首先介绍了在Windows下Java和IntelliJ IDEA开发工具的安装过程,并介绍了在IDEA中新建MapReduce工程及配置MapReduce环境的过程。 接着介绍了MapReduce编程的基础知识,对Hadoop官方的示例WordCount源码的分析解读。 结合竞赛网站每日访问次数的统计任务,分析MapReduce编程的基本思路和处理逻辑,实现核心代码的编写。















 2645
2645

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









