







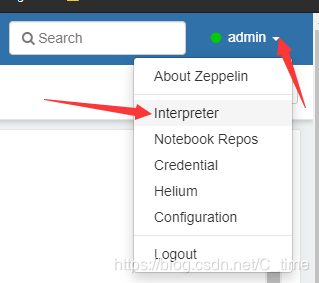
1.登陆后,点开如图interpret
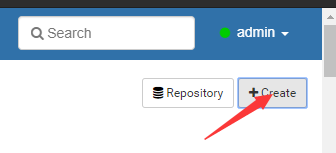
2.创建一个新的interpret解释器
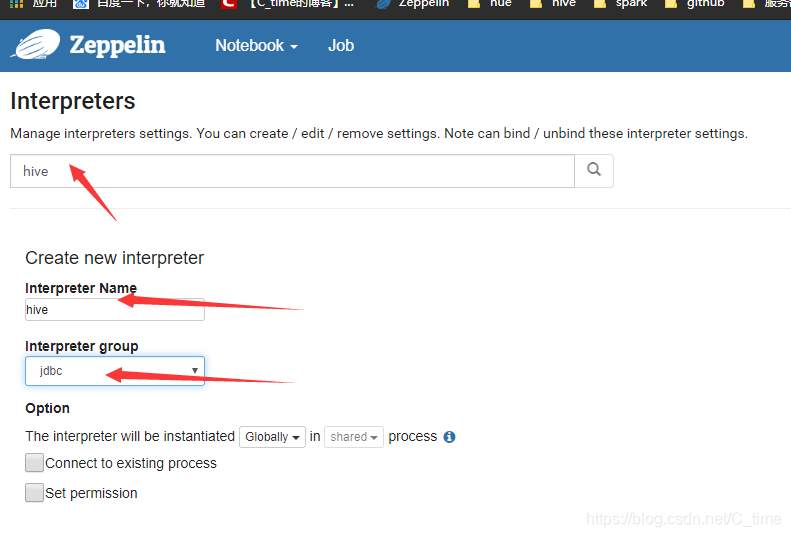
3.创建一个名为hive的interpret,依赖于jdbc连接
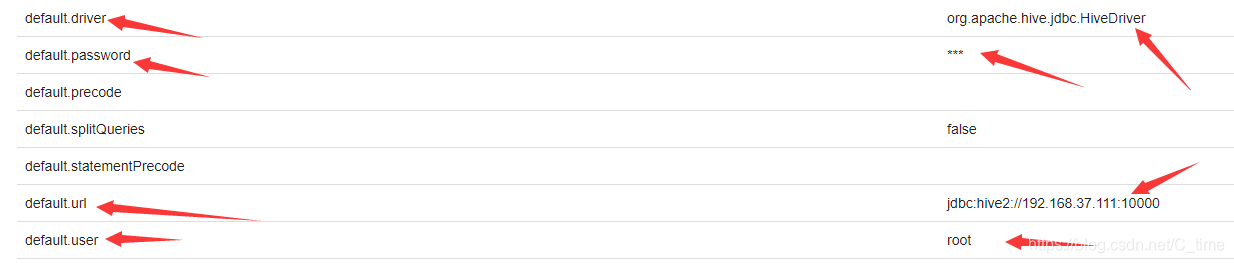
4.填写相关参数
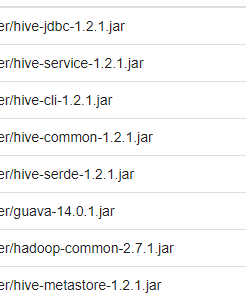
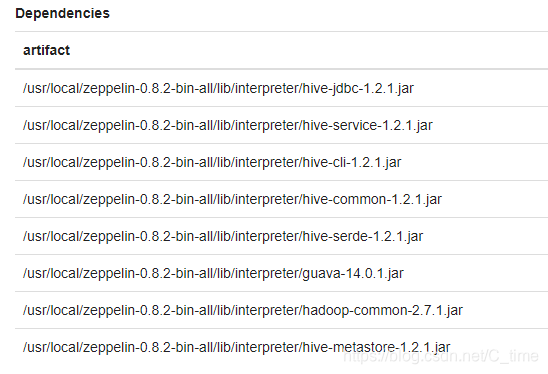
5.将相应jar包路径写上,在hive的lib下面能找到,还有一个hadoop的common在hadoop文件夹下找到的。
看其他博客配置都不一样,反正我这样是可以使用的。如果还有报错信息,看看缺少什么jar包,写入相应路径即可。
6.保存
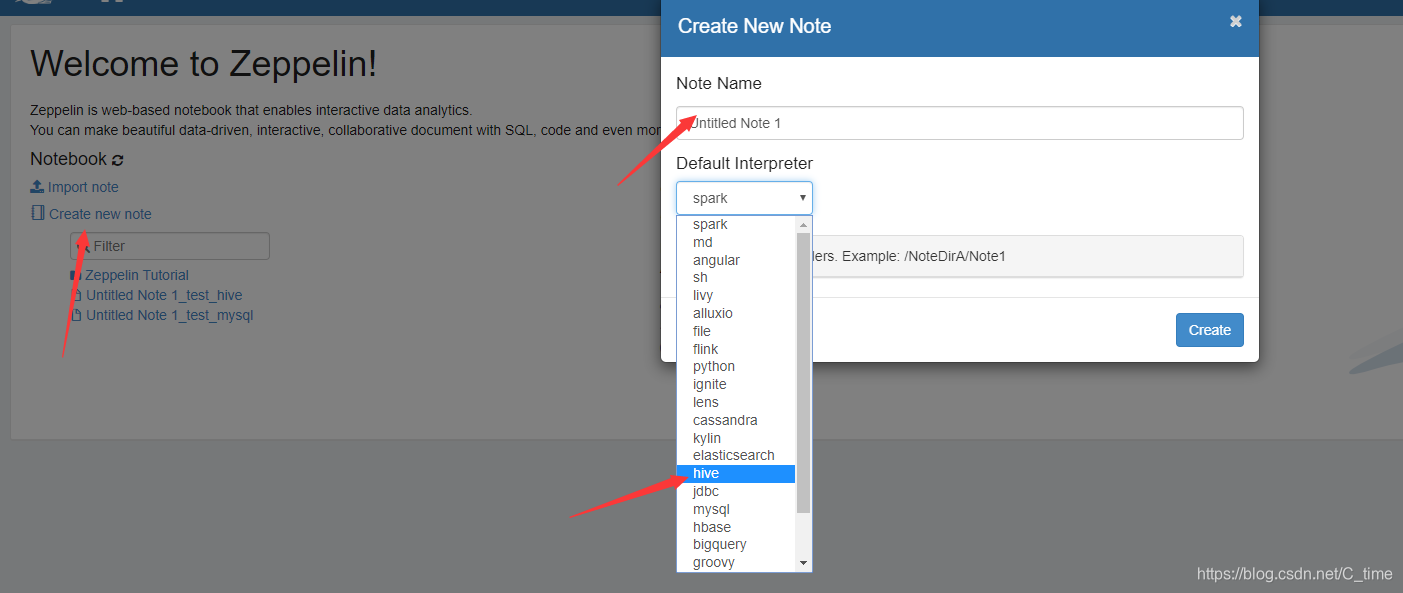
7.回到首页,创建new node 输入名称 选择hive
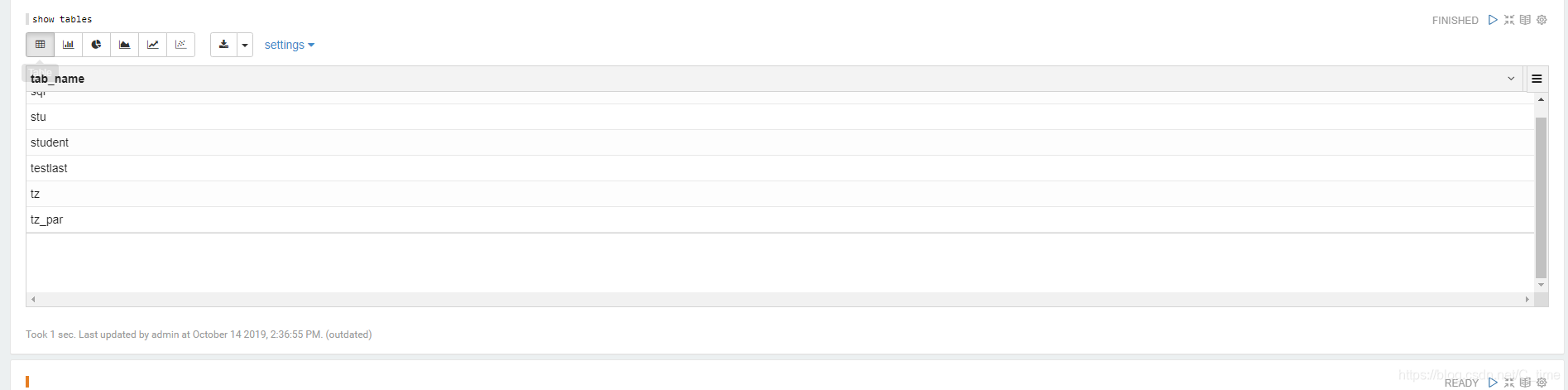
8.写个hql语句运行试试,没问题















 3406
3406











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









