







Hive的基础数据类型和复杂数据类型


Array
create table if not exists arr1(
name String,
score Array<double>
)
row format delimited fields terminated by '\t'
collection items terminated by ','
;
load data local inpath '/home/olddata/arr1' into table arr1;



select a.name, a.score[0], a.score[2]
from arr1 a
where a.score[1] > 81;

数组越界不报错
因为hive是严格的读时模式
如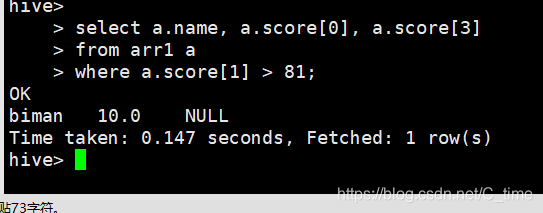
Map
集合map:
lucey Chinese:90,Math:80,English:99
biman Chinese:10,Math:100,English:99
create table if not exists map1(
name String,
score map<String, double>
)
row format delimited fields terminated by '\t'
collection items terminated by ','
map keys terminated by ':'
;
load data local inpath '/home/olddata/map1' into table map1;


查询
select m.name, m.score["Chinese"], m.score["Math"]
from map1 m
where m.score["Math"] > 60;

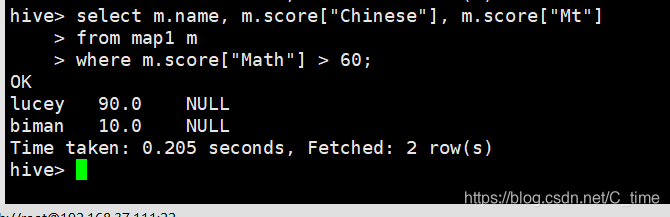
写错的话不会报错
结构体struct
create table if not exists struct1(
name String,
score struct<chinese:double,math:double,english:double>
)
row format delimited fields terminated by '\t'
collection items terminated by ','
;
load data local inpath '/home/olddata/str1' into table struct1;



select str.name, str.score,str.score.chinese, str.score.math
from struct1 str
where str.score.math > 80
;

map
create table if not exists map1(
name String,
score map<String, double>
)
select m.name, m.score["Chinese"], m.score["Mt"]
from map1 m
where m.score["Math"] > 60;
结构体
create table if not exists struct1(
name String,
score struct<chinese:double,math:double,english:double>
)
select str.name, str.score,str.score.chinese, str.score.math
from struct1 str
where str.score.math > 80
;
注意map和struct的写法差不多
但注意map的第一个值是string类型 所以查询时使用括号和引号引起来
struct的属性 不需要使用引号和括号 是用的点 请注意
Hive常用的内部函数和排名函数

- select rand(); 取随机数
- select rand(10); 想让随机数维持到某一个值

取随机数的整数
先乘100 得到整数

取到整数后 可以分割 split
select split(rand()*100, “\.”)[0]; 用点分割取第一个值
注意点需要转义 不然取不到值

或者采用四舍五入的方式
select round(rand()*100, 2);保留2位小数
select round(rand()*100);

直接四舍五入 还有点零
这个函数可以写明保留几位小数
或者截去
select substring(rand()*100, 0, 2);
但是如果取到9.215…这样的
就会有9.
所以不一定对 例如


substring
substr
两者是一样的功效

emmm 下面这两句都不能用…
select indexof(rand()*100, ".");
select locate(rand()*100, ".");
正则替代
select regexp_replace(“a.jpg”, “jpg”, “png”);

类型转换select cast(1 as double);

case when
casewhen 相当于java中的ifelse
这个答案永远是男 哈哈

两种case的写法
select
u.name,
case
when u.sex = 1 then "男"
when u.sex = 2 then "女"
else "unkown"
end
from u3 u
;


select
u.name,
case u.sex
when 1 then "男"
when 2 then "女"
else "unkown"
end
from u3 u
;

select if(1=1, “男”, “女”);

select if(1=1, “男”, if(2=2, “女”, “不知道”));


select
u.name,
if(u.sex=1, "男", if(u.sex=2, "女", "不知道"))
from u3 u
;

select concat(“1”, “2”, “3”);连接函数

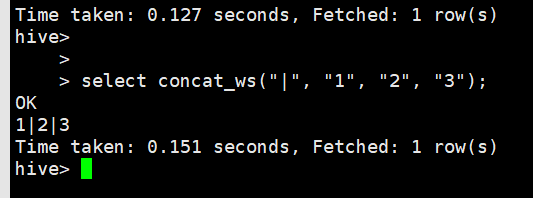
select concat_ws("|", “1”, “2”, “3”);加分隔符
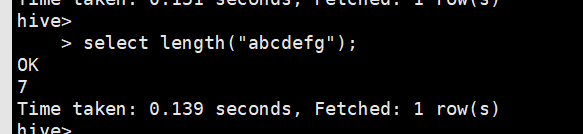
select length(“abcdefg”);长度
select size(array(1, 2, 3));数组大小

====================================
排名函数
- row_number():没有相同名次,名次不空位
- rank():有并列名次,并列名次后将空位
- desen_rank():有并列名次,并列名次后不空位
sno score sclass
1 88 1701
2 98 1701
3 86 1701
4 85 1701
5 88 1701
6 83 1702
7 78 1702
8 58 1702
9 68 1702
create table if not exists rn(
sno int,
score int,
sclass int
)
row format delimited fields terminated by '\t'
;
load data local inpath '/home/olddata/rn' into table rn;


select tmp.sclass, tmp.score
from (
select
r.sclass,
r.score,
row_number() over (distribute by r.sclass sort by r.score desc) rr
from rn r
) as tmp
where tmp.rr < 4
;


select
r.sclass,
r.score,
rank() over (partition by r.sclass order by r.score desc) ra,
dense_rank() over (partition by r.sclass order by r.score desc) dr,
row_number() over (distribute by r.sclass sort by r.score desc) rr
from rn r
;
看 rank dense_rank row_number 三列排名

row_number():没有相同名次,名次不空位
rank():有并列名次,并列名次后将空位
desen_rank():有并列名次,并列名次后不空位
================
sum()
count(*):整行有任意一个值不为null就累加
count(1):只要有记录就会累加
count(col):对col列进行累加
count(distinct col):对col列去重累加
avg()
max()
min()
















 768
768

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









