






2022年1月2日更新:
# 绘制棘状图的函数
def jizhuangtu(b, colors=['#1f77b4','lightseagreen'], labels=None, title=None, text_on=True): # 绘制棘状图的函数
'''
b:Serie, 由groupby(x).y.values()得到
colors:list, 分类的颜色(y轴分类)
labels:list, 分类的标签(y轴分类)
title:标签的名称/plt.legend的参数
text_on:是否添加文字标签
'''
fig, ax = plt.subplots()
for n, value in enumerate(b.index.levels[0]):
c = b[value].sort_index()
c = c/c.sum()
globals()['width%s'%(n+1)] = b[value].sum()/b.sum() # 计算样本量占比 width1:男 width2:女
globals()['x%s'%(n+1)] = 0 if n==0 else globals()['x%s'%n]+globals()['width%s'%(n)]/2+0.02+globals()['width%s'%(n+1)]/2 # 两个柱状图保留0.1的间隙
plt.bar(globals()['x%s'%(n+1)], c.cumsum()[::-1], color=colors, width=globals()['width%s'%(n+1)])
if text_on: # 如果text_on=True, 那么添加文字标签
for h, s in zip(c[::-1], c):
plt.text(globals()['x%s'%(n+1)], h, format(s, '.2%') ,horizontalalignment='center', verticalalignment='bottom')
plt.ylim(0,1)
plt.xlim(0-width1/2, globals()['x%s'%(n+1)]+globals()['width%s'%(n+1)]/2) # xn+widthn/2
# xticks = [i +'({:.2%})'.format(globals()['width%s'%(n+1)]) for n, i in enumerate(b.index.levels[0])] # 给x标签添加样本占比,添加占比太占位置了,且观看者可能难以理解
plt.xticks([globals()['x%s'%(i)] for i in range(1, n+2)], b.index.levels[0])
# 添加图例
labels = b.index.levels[1] if labels==None else labels
[plt.bar(0,0,color=colors[n], label=lab) for n,lab in enumerate(labels)]
num1 = 1.01; num2 = 0.5; num3 = 3; num4 = 0
plt.legend(bbox_to_anchor=(num1, num2), title=title, loc=num3, borderaxespad=num4)
# 去掉边框
for loc in ['top', 'left', 'bottom', 'right']:
ax.spines[loc].set_visible(False)
jizhuang_data

jizhuangtu(jizhuang_data, labels=['逾期', '未逾期'])

之前的版本:
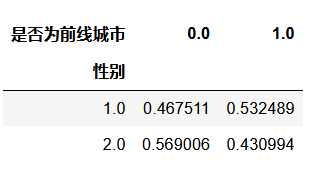
bar_data = pht.groupby('性别').是否为前线城市.value_counts().unstack().apply(lambda x: x/x.sum(), axis=1)
bar_data.plot(kind='bar', stacked=True)

bar_data
以前的版本:
写了一个可以画棘状图的函数
def jizhuangtu(b, colors=['#bebebe','#ffd700'], labels=None): # 绘制棘状图的函数
fig, ax = plt.subplots()
for n, value in enumerate(b.index.levels[0]):
c = b[value].sort_index()
c = c/c.sum()
globals()['width%s'%(n+1)] = b[value].sum()/b.sum() # 计算样本量占比 width1:男 width2:女
globals()['x%s'%(n+1)] = 0 if n==0 else globals()['x%s'%n]+globals()['width%s'%(n)]/2+0.02+globals()['width%s'%(n+1)]/2 # 两个柱状图保留0.1的间隙
plt.bar(globals()['x%s'%(n+1)], c.cumsum()[::-1], color=colors, width=globals()['width%s'%(n+1)])
plt.ylim(0,1)
plt.xlim(0-width1/2, globals()['x%s'%(n+1)]+globals()['width%s'%(n+1)]/2) # xn+widthn/2
plt.xticks([globals()['x%s'%(i)] for i in range(1, n+2)], b.index.levels[0])
# 添加图例
labels = b.index.levels[1] if labels==None else labels
[plt.bar(0,0,color=colors[n],label=lab) for n,lab in enumerate(labels)]
num1 = 1.01; num2 = 0.5; num3 = 3; num4 = 0
plt.legend(bbox_to_anchor=(num1, num2), loc=num3, borderaxespad=num4)
# 去掉边框
for loc in ['top', 'left', 'bottom', 'right']:
ax.spines[loc].set_visible(False)
# 生成数据
by = 20; bn = 80
gy = 2; gn = 18
a = pd.DataFrame(columns=['性别','是否出险'])
a = a.append([dict(性别='男',是否出险=1)]*by, ignore_index=True)
a = a.append([dict(性别='男',是否出险=0)]*bn, ignore_index=True)
a = a.append([dict(性别='女',是否出险=1)]*gy, ignore_index=True)
a = a.append([dict(性别='女',是否出险=0)]*gn, ignore_index=True)
a = a.append([dict(性别='未知',是否出险=0)]*20, ignore_index=True)
b = a.groupby('性别').是否出险.value_counts()
b

jizhuangtu(b)

修改图例
jizhuangtu(b, labels=['a','b'])

注:记得将索引补全
b
>>> 性别 是否出险 a
女 0 18
女 1 2
未知 0 20
男 0 80
男 1 20
想要补全 (未知,1)
full_index = pd.MultiIndex.from_product([['男','女','未知'],[0,1]])
b = b.reindex(full_index)
b
>>>
男 0 80.0
1 20.0
女 0 18.0
1 2.0
未知 0 20.0
1 NaN
画累积/叠加柱状图 https://zhuanlan.zhihu.com/p/71840687
Survived_m = train.Survived[train.Sex =='male'].value_counts()
Survived_f = train.Survived[train.Sex =='female'].value_counts()
df = pd.DataFrame({u'男性':Survived_m,u'女性':Survived_f})
df.plot(kind='bar',stacked =True)
plt.title(u'按性别看获救情况')
plt.xlabel(u'性别')
plt.ylabel(u'人数')

优化上述代码(一行解决)
trainData.groupby('p1_gender').y1_is_purchase.value_counts().unstack().plot(kind='bar', stacked=True)
















 455
455











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









