






QSplat: 基于多分辨率处理大规模网格的点绘制系统(完整版翻译)
Szymon Rusinkiewicz
Mark Levoy
斯坦福大学计算机图形学实验室
Rusinkiewicz,S. and Levoy,M. “QSplat: AMultiresolution Point Rendering System for Large Meshes,”Stanford University Computer Graphics Lab,pp.343-352,2000
资源下载:http://download.csdn.net/detail/calvinshi/9687606 包含如下文件: QSplat程序,以及把ply程序转化为QSplat能够读取的qs文件的QSplatMake程序,以及以上两程序的完整C++代码; QSplat经典论文,以及完整版中文翻译; 关于QSplat的斯坦福原版PPT
摘要
随着3D扫描技术的进步,在实践中,有着数以百万计的网格的多边形如雨后春笋般涌现,意图使用传统的显示、简化和渐进传输算法处理如此数据规模的网格是不切实际的。我们描述的这一系统将表示并逐步显示这些网格——它们结合了基于边界球的多分辨率层次结构和基于点的渲染系统。我们将专门使用一个数据结构进行视域剔除,背面剔除,多细节层次选择以及绘图。这一表示是紧凑且可以被迅速计算的,因此适合大型数据集。这一实现将用于大规模3D数字化项目,它能够迅速启动,维护用户设置的交互式帧频,而无关乎对象的复杂性或相机位置,即使对于运动的物体运动,也能产生高质量图像。我们演示了该系统扫描模型——包含数以百万计的采样点。
分类和主题描述:I.3.3[计算机图形学]:图片/图像生成——显示算法;
I.3.5[计算机图形学]:计算几何和对象建模——曲线,表面,固体和对象表示;
I.3.6[计算机图形学]:方法与技巧——图形数据结构和数据的方法和技术类型。
关键词:渲染系统,空间数据结构,多细节层次算法,压缩算法
1介绍
近期的计算机图形学研究中的一个热点是,使用采样点渲染真实对象。这一趋势的一个例子是,增加对3D扫描系统的使用,产生实物三维采样模型。然而问题在于,3D扫描仪依然难以处理自身产生的大量数据。在过去的几年中,通过改善三维扫描系统的硬件和软件组件,3D扫描仪业已增加了实现扫描百万量级网格的可能性。
然而,当前工作站还不能实时地显示这样数量级的网格,并且传统的网格的简化和渐进的显示算法——其高企的时间和空间复杂度——使得这些扫描百万量级网格样本的途径变得不切实际。此外,许多传统技术专注于优化单个边缘和顶点的位置,在各个顶点上消耗大量精力。尽管如此,由于噪声的缘故,仍有许多顶点及其位置数据是失真的。这表明,存在一个替代的方法,一个把个别点视为相对不重要、把更少的精力花费在每个原始点上的方法。目前研究这个范例的包括Krishnamurthy和Levoy的Spline-fitting系统[Krishnamurthy 96],Curless和Levoy的Range Image Merging系统[Curless 96]以及Yemez和Schmitt的基于Octree Particles的绘制系统[Yemez 99]。这些算法都不能使得数据范围达到精确,并且事实上不能保护任何一个样本的原始网格的3D位置。
随着算法对每个原始点的低消耗这一趋势,我们已经开发出一种新的交互显示的大规模网格算法——QSplat,并业已在大型3D数字化项目课题中给出[Levoy 00]。它使用一个基于穿越边界球层次结构的简单的渲染算法,适用于浏览生成的模型包含了1亿到10亿个样本。此外,QSplat不保持输入网格的连通性(本质上,这些扫描数据几乎唯一的用途是,解决不连通性的深度问题),取而代之的是,依靠点表示和Splat渲染。因此, 比起以多边形为基石的系统,我们的系统已经降低预处理和渲染成本。QSplat可以迅速启动,维护一个可调整的多细节层次交互式帧频,采用在内存和磁盘使用方面紧凑的表示方法。
在本文中,我们提出了QSplat的数据结构和算法实现,讨论了关于使它能在处理大规模网格上有实际使用价值方面的设计决定和一些权衡。我们还描述了系统的渲染性能,并讨论其预处理成本。最后,我们认为它关系到了先前显示大规模网格的算法,同时我们也描述了一些将来对于绘制其他种类大规模几何数据集的扩展。
2 QSplat数据结构和算法
QSplat使用层次结构的边界球体[Rubin80,Arvo 89],进行可见性剔除的多细节层次控制和渲染。每个节点的树包含球面中心、半径、法向量和法锥面[Shirman93],以及可选的颜色。尽管对我们的程序来说,我们仅需要一种算法从三角网格中生成这种边界球的层次结构,但是QSplat还能从多边形、体素或者点云模型生成这样的层次结构。这种层次结构作为一种预处理被构造,并被写入到磁盘上。
2.1渲染算法
构造层次结构之后,下面的算法用于显示:
TraverseHierarchy(node)
{
if(node not visible)
skip this branch of the tree
else if(node is a leaf node)
draw a splat
else if(benefit of recursing further is too low)
draw a splat
else
for eachchildinchildren(node)
TraverseHierarchy(child)
}
现在我们来详细讨论这个基本算法的几个阶段。
可视性剔除: 在边界球的层次上做递归,剔除那些不可见的节点。视域剔除是由测试每个球体对着视域的位面完成的。如果球位于平截头体(视域平头四棱锥)的外面,那么它和它子树的节点都会被丢弃,而非做进一步的处理。如果球位于平截头体(视域平头四棱锥)的内部,就不必剔除这些节点的孩子节点。通过使用法向量和法锥面也可进行背面剔除。如果锥面完全背离视点,那么这些节点和它的子树节点都会被丢弃。若锥面完全指向视点,则组成这些面的节点的孩子节点就不作为背面剔除的候选节点。
确定递归时机:QSplat所使用的启发式决策意味着其递归基于在屏幕上投影的大小,这就是说,如果球投影到观察面上的区域超过一个阈值,就得对这个节点做细分。递归的中止为了维护用户选择的帧频,从而做从一帧到另一帧地调整。我们目前使用的是简单的反馈方案,在先前帧的基础上,通过实际的比率获得绘制时间,调整阈值面积的比率。Funkhouser和Sequin展示了LOD控制预测算法, 在多细节层次控制理论中,这种带有预测性的算法使得帧到帧的绘制时间变小[Funkhouser93] 。但是我们没有实现——如Hoppe的渐进网格系统[Hoppe98]中GeoMorphs算法那样——通过任何平滑过渡的算法,作为从一个多细节层次到另一个多细节层次的模型变化的片段。假如我们的程序在求精时对外观做适当改变,或者在典型观察点上突变时,我们将不能发现缺乏滤波的实然的重要意义。但是其他应用程序,可能从这样的平滑转变中受益。最受欢迎的LOD对度量进行控制,其他启发方案来决定递归的量[Duchaineau 97,Hoppe 97]。我们的框架可以将递归规则推广到以下情形:轮廓边缘(使用每个节点的法向量),高曲率区(使用法锥面宽度),或在中心凹陷区域 (只使用投影位置)。上述使用的帧频控制是实现模型的交互操作。一旦用户停止移动鼠标,我们就会重新绘制现场,即令阈值不断缩小,直至只有一个像素。图1渲染通过了QSplat的几个层次的细化的一个示例场景。


图1:一个模型——圣马太雕像,米开朗琪罗作品——渲染QSplat在几个层次的细化。渲染的SGI Onyx2完成超然的现实图形,在1280×1024的屏幕分辨率下从网格模型生成1.27亿个样本,代表一个2.7米高的雕像,有着0.25毫米的分辨率。右边的图片是左边的放大。
画一个Splat:一旦我们到达一个叶子节点或决定停止递归,我们画一个Splat代表当前的球体[Westover89]。Splat的大小是基于当前球体的投影直径,它的颜色是基于当前每个球的法向量和颜色而从照明角度考虑获得的,并启用了z缓冲解决阻尼。我们将在3.3节中讨论每一个Splat的形状。
2.2预处理算法
我们的预处理算法首先表示模型的三角网格编码。虽然可以直接从点云建立一个QSplat层次结构,然而从一个网格入手更容易计算每个节点的法向量。如果没有网格,我们就不得不设法拟合平面法向量的顶点——以计算其邻域点集的方式。一个网格也可以指定输入顶点(球体大小成为我们边界球的叶节点层次结构)。为了使得绘制的点紧密,我们目前的算法是,如果两个顶点由原始网格的一条边相连,所生成的球就必须足够大,使得每两个球在顶点相接。这是一个“宁停三分不抢一秒”式的保守方法。
一旦我们分配叶球体大小,我们使用以下算法建立树的其余部分:
BuildTree(vertices[begin..end])
{
if (begin == end)
return Sphere(vertices[begin])
else
midpoint = PartitionAlongLongestAxis(vertices[begin..end])
leftsubtree = BuildTree(vertices[begin..midpoint])
rightsubtree = BuildTree(vertices[midpoint+1..end])
return BoundingSphere(leftsubtree, rightsubtree)
}
这一算法沿着最长轴的边界框建立树的顶点,递归地计算两个子树,寻找边界球的两个孩子球体。一旦树被建立, 内部节点上的每个顶点的公共属性(如法向量和颜色)均被置为平均值。当递归达到一个顶点,我们简单地创建一个中心是顶点的球体,因为整个树的大小依赖每一个节点的分支因素,我们把这些节点都结合到树中去,使得树的平均分支大约有4个。这样将减少内部节点的数目,从而减少了树的存储量。预处理的最后一步就象3.1节描述的那样去量化每个节点的属性。
3设计决策和权衡
现在让我们考虑如何使QSplat适合于可视化大型数据集的扫描。我们在量化描述如何权衡, 我们描述了在量化、存储形式和描述Splat形状时的权衡,这一权衡是基于我们意图进行快速绘制并压缩表示的目标的。

图2:QSplat文件和节点布局。(a)树存储按广度优先方式(即红色箭头给出的顺序)。(b)从父节点到孩子节点的联系——建立一组从父节点到第一个孩子节点的指针。如果所有的“父”的兄弟姐妹都是叶节点,则指针不出现。所有的指针都是32位。(c)一个量化节点占48位(不带颜色的占32位)。
3.1节点布局和量化
边界球层次结构中的每个节点的布局如图2(c)所示,一个节点包含相对于它父节点的位置和球的尺寸、法向量、法锥面的宽度、可选的颜色、以位表示的用来存储表示树的数据结构的空间(比特表示)。我们将在3.2节中讨论树的数据结构和存储节点的设计。
球心位置和半径:每个球的球心位置和半径在边界球层次结构上相对于它们的父节点被编码。为了节约空间,这些度量的值定在了13比特。也就是说,球的半径数值范围相对其父节点是1/13到13/13,球心相对于它父节点(每一个X,Y,Z)的中心的偏移量是它父节点直径的1/13的倍数。量化自顶向下进行,然则孩子节点球的位置和范围相对其父节点的量化的位置被输入,是故量化错误不向网格传播。为了保证量化过程紧密且拟合良好,量化的半径总是收敛于代表最近点的值。
需要注意的是,不是所有可能组合的中心偏移量和半径比都是有效的,因为,许多孩子节点的结果是不依赖于其父节点的。事实上,只有7621种可能的组合是有效的,这就意味着我们对球心位置和半径所使用的空间只能是13比特。假设父球的半径是1的话,这个编码的方案给出了对于孩子球的X、Y、Z的一个平均量化误差是0.04,对于孩子球半径而言,误差的均值为0.15。半径误差远大于位置误差的原因是,为了保证量化球能够接近实际球,半径被球位置量化的误差不断累加,于是半径总是收敛于代表最近点的值。我们只要不坚持量化球完整拟合原始球,就能够获得比较低的量化半径误差。但是,这样就会引起球之间不紧密地接触,在绘制时制造出空隙。
通过渐进式的编码来表示像球位置这样的几何量,因此实质上在层次结构的层次上按比特输出这些几何量。这种方案在网格压缩方面是违背传统方案的[Taubin 98]。传统方案依赖对于沿着一些路径和沿着网格边的顶点位置的不同的编码。实际上这种层次三角编码和Eck的多分辨率分析中小波表示几何体比较接近[Eck 95]。我们每个节点只需要13比特空间的方案比state-of-the-art几何压缩方法更有竞争力,后者是依靠最初量化的顶点位置,使得顶点平均占用9-15个比特。然而这不是完全有效的比较,因为被我们抛弃的传统几何压缩方案同样也表示出了网格的连通性,而我们用这13比特创造的一个节点还存储了球的半径。
每个节点的位置和半径都被迅速解码以渲染。正因如此,我们的数据结构不仅在磁盘上表现得紧凑,而且在绘制的时候比在绘制前解压数据的方案需要更少的内存空间。
法向量: 每个节点的法向量存储时占用14比特,可表示的法向量对应的点落在正方体每个面的52×52的格子上,向样本的法平面上作不一致的弯曲。在绘制时,我们使用一种查找表来对可表示的法向量进行解码。在实践中我们仅仅使用了52×52×6 = 16224个不同的法向量生成灰部,但是,一些条状产物在低曲率的广阔区域里的强镜面反射周围却是可见的。我们可以通过平移每个法向量做其相对父球的法向量,这样利用渐进式的编码消除这些产物,并达到比较好的压缩,但是,这样会增加内部算法循环的时间复杂度——又一个空间和时间的权衡。不似节点位置的无疆,法向量的空间是有界的,所以,一个固定的量化表能满足任意场景下法向量的编码。因此在这样的情况下,我们选择了一个对法向量固定的量化,这种量化在运行时只需要一个查找表。当处理器的处理速度增加时,我们预测,渐进量化方案将变得更加有前景。
颜色:颜色目前存储时占用5+6+5=16位。在做法矢运算的时候,颜色增加式的编码能够节约存储空间,但是在运行的时候耗费比较多的内存。
法锥面:经过实验,我们决定给每个节点法锥面宽度2比特的空间。四个有代表性的数值对应着角度为arcsin(1/16),arcsin(4/16),arcsin(9/16),arcsin(16/16)的四个锥面。在典型数据集上,使用准确量化的法锥面做背面剔除,可以砍掉超过90%的节点。值得注意的是,我们总是保守地去表示法锥面的宽度,“宁停三分不抢一秒”。和法向量以及颜色一样,这意味着,法锥面的宽度能相对于其父节点的宽度被表示,但是这将减慢绘制速度。
3.2文件布局和指针
边界球的节点层次结构在内存和磁盘上以广度优先顺序存储。一个主要的结果是,第一部分的文件——内存中的文件——包含了整个低分辨率的网格。因此,我们只需要读这第一部分文件来将低分辨率模型可视化;若欲明察秋毫,则更多的文件可从磁盘读取。我们目前使用OS-provided内存映射作为工作集管理的基石,这种渐进加载对于将QSplat推广到大型模型的努力是重要的。从磁盘加载整个数据集的时间可能要几分钟。因为数据需要加载,渲染性能在用户首次放大时会降低,因为在某些区域的模型是基于反馈的方法建立的,这样帧频控制就会产生时滞。然而,后续帧将全速渲染,解决这个问题,同时人们也一直在探索一种方法,减少这种性能变化[Funkhouser 92, Funkhouser 96,Aliaga 99],但目前尚无有效进展。
几个无指针的方案业已提出了树编码设想,包括线性八叉树方法和基于完全树的方法[Samet 90]。然而,这些数据结构是不适合我们的应用程序的。线性八叉树和相关想法需要整个树被遍历以恢复它的结构,这在我们的系统里是不切实际的。基于完全树的数据结构可用于部分遍历,但这样我们不能保证产生的树是完整和均衡的,这是因为,我们用以生成树的算法本身基于二分法。此外,要用修改预处理算法的方式生成完全树是我们不希望看到的,因为在每个子树加以同等数量的顶点,可能明显地打破平面的均衡。考虑到我们在孩子球体的中心执行量化,这可能导致压缩树时的明显错误。
尽管我们不能为我们的树使用无指针编码,我们至少应该尝试最小化所需的指针。鉴于我们按广度优先顺序存储树,只要有一个指针将每个组的兄弟树指向这些节点的孩子节点就足够了。此外,如果这些节点没有孩子节点(即他们都是叶节点),那么就不需要指针。如果使用这一方案,只有大约8%到10%的总存储成本——我们认为是足够小以至于不需追求更复杂的方案做进一步压缩的——花在了指针上。为了使树能够遍历,我们在每个节点存储两位编码数量的孩子节点(0、2、3或4个孩子节点,一个孩子节点是不允许的),加上一个比特的空间——指示是否该节点的所有孩子节点是叶节点。
可以做个这样的估计:树的总存储需求=树中的节点数量×每个节点的成本+开销指针。例如,若树的平均分支系数为3.5,节点总数将是叶节点数的1.4倍,整个树的存储空间=9×叶节点的数量,如果颜色不存储,那么整个树的存储空间=6×叶节点的数量。
3.3 Splat形状
内核的选择对于渲染点采样有重大影响,直接决定了最终的图像质量。最简单的,最快的选择是一个OpenGL点,渲染为一个正方形。第二个选择是一个不透明的圆,这可能渲染为一群小三角形,或以更低成本在OpenGL实现为一群多边形。另一种可能是模糊点,利用正态分布来拟合。我们使用的拟合方法是,定义半径的标准差为1/2的Splat。后面这两个选项的绘制速度将减缓,因为需要发送更多的数据。此外,由于混合和z缓冲的互作,画一个正态分布的Splat需要特殊处理。Levoy和Whitted就纯软件渲染讨论过这个问题[Levoy 85],他们提出的基于容器的方法确保了图像在阻尼和混合下的准确性。在OpenGL中,我们可以用多通道渲染增强准确性。在第一通道,深度偏移远离观测者一些,我们就只渲染深度缓冲。在第二通道,我们通过增加对颜色缓冲区的渲染抵消深度偏移,却不更新深度。这就把一定深度范围内的所有Splat混合在一起,同时保持正确的阻尼。图3比较了这三种选择的Splat内核。因为每个内核、每个splat绘制时间在当前硬件都是不同的,我们现在在恒定的Splat尺寸和恒定的运行时间下进行比较。

图3:选择Splat形状。我们展示一个场景渲染使用正方形、圆和正态分布作为Splat内核。在最上面一行,每个图像使用相同的递归,即20像素的阈值。相对于正方形,圆花大约两倍的时间来渲染,正态分布需要大约四倍的时间。然而,正态分布显著减少了混叠。在最后一行,每个图像的阈值调整在每种情况下产生相同的渲染时间。根据这一标准,正方形内核提供最高质量的显示。
另一个选择基于Splat是圆(或由OpenGL点渲染的正方形)还是椭圆。在后一种情况下,每个节点的法向量还用来确定椭圆的离心率和方向。当法向量指向观测者,Splat将是圆形的。否则,每一个椭圆的短轴将法向量n的投影指向观测平面上,短轴与长轴的比值k=n·v ,其中v是指向观测者的向量。这提高了轮廓的质量,是相对于圆形Splat的锐化。比较使用圆形和椭圆形的Splat如图4所示。

图4:圆形和椭圆Splat。在左边的图片,所有的Splat都是直径20像素的圆。在正确的图像中,我们根据每个节点的法向量画出旋转椭圆的Splat。这样就对图像进行了锐化。递归深度被限制以便看清单个Splat。
因为我们在一个连续的表面构造边界球层次结构不会留下空隙,我们可以保证,方形和圆形内核总是紧密地进行重建。正态分布内核同样保证了表面的连续性。对于椭圆内核,我们不能再保证这一点了,也不必要再保证这一点了,因为此时法向量不需要沿着连续表面重建。在使用椭圆内核时,我们偶尔会看到孔隙,尤其是在轮廓的边缘。我们不妨通过限制k的最小值来限制椭圆的离心率的最小值,具体地说,如限制k>1/10,这样就能填充几乎所有的空隙。
3.4 基于点的绘制系统的结果
QSplat使用点作为渲染的原始对象,适合各种特定的场景,特别是显示标准大小的几何细节,和没有必要采取很高的分辨率的情形下。如果模型如一马平川,或是某些特殊的曲面,多边形模型画得更快也更紧密。同样地,如果放大到像素级别,多边形模型也提供了更高的画面质量,尤其是对于那些锋利的棱角。图5显示了一个比较点绘制和多边形绘制的效果图。

图5:使用点和多边形渲染的比较。
QSplat开发了可视化的目的扫描模型,包含了在分辨率附近尺度的大量数据。我们使用了容积图像处理(VRIP)系统[Curless 96]合并原始扫描数据到我们最后的模型,利用立方体匹配算法[Cline 88]提取多边形网格。因为后者产生等距样品,因此渲染的渲染情形是适合我们的应用程序的。我们希望QSplat在那些多边形绘制擅长的领域更加高效,同时我们也指出,对于那些大多边形相对破碎的实物——例如建筑物REYES [Cook 87]——兼采点与多边形绘制的计划将相得益彰。
4性能
如第3节所述,交互性的目标决定了许多对我们的系统的设计决策。此外,我们已经在几个方面优化我们的程序,以期增加可以进行可视化的模型。
4.1渲染性能
我们的系统把大多数的渲染时间用来在一个内部循环遍历层次结构,计算各自的位置和半径节点,执行可视性剔除,并决定是画一个点还是进一步递归。这个内部循环代价高昂,特别是在树的层次较低时。例如, 当一个节点的空间大小达到几个像素时,我们就要将树的低层次的角度划分由精确切换到近似。因此, 在SGI Onyx2上,一旦数据被从磁盘读取,我们的算法平均每秒可以渲染150万至250万个点。准确的速度因缓存的影响(例如,我们观察到,加速适合在L2缓存)、剔除数据的量和树的层次而异。
我们的显示率可能可以与每秒48万个多边形 (在相同的硬件上)——这一数据由Hoppe的累进网格算法给出[Hoppe 98]——或在ROAM系统上的每秒18万个多边形 [Duchaineau 97]——进行比较。在我们的应用程序中,我们通常使用5 到10赫兹的帧频,这意味着每帧的交互式渲染吸引20万到30万点。注意,与上述两个系统相比,QSplat没有显式使用帧间一致性,例如缓存列表的原始数据可能是可见的。QSplat的渲染性能总结如图6。
我们的算法的简单性使其非常适合在低端机器上实现。作为一个极端的例子,我们在没有3D图形硬件的笔记本电脑上实现了QSplat(366 MHz英特尔奔腾II处理器,128 MB内存)。因为在渲染软件中,系统填充是有限的,对于一个500×500和帧率5赫兹的典型窗口,可以实现每秒25万到40万点的遍历,每秒4000万像素填充率,每帧通常吸引5万到7万Splat。在这个分辨率实现仍堪舒适的用户体验。虽然目前大多数台式机有3D图形硬件,便携和手持设备却并非如此,甚至对于数字电视机顶盒,我们也相信QSplat是适合的。
4.2预处理性能
虽然预处理时间不如渲染时间那样重要,它在实际的可视化操作中对于巨大网格仍系关键。Hoppe给出10小时预处理20万网格顶点数据[Hoppe 97]。Luebke和Erikson给出基于他们的分层动态简化模型的121秒预处理28.1万点的数据[Luebke97]。相比之下,我们的预处理时间为5秒20万顶点 (在相同的硬件上)。
另一类可资比较的算法是网格简化算法。虽然这些算法和QSplat有不同的目标,它们也通常用于生成多分辨率显示或简化网格显示。Lindstrom和Turk发表了一篇比较几种最近的网格简化方法的论文[Lindstrom 98],给出的对兔子网格的35000个顶点进行简化的时间介于30秒到45分钟之间,那篇论文没有考虑到Rossignac和Borrel[Rossignac 93]的简化算法,其在与Lindstrom和Turk所采用的相同硬件上使用1秒钟完成任务,而我们的预处理时间未0.6秒。因此,我们的算法明显快于上述大多数方法。
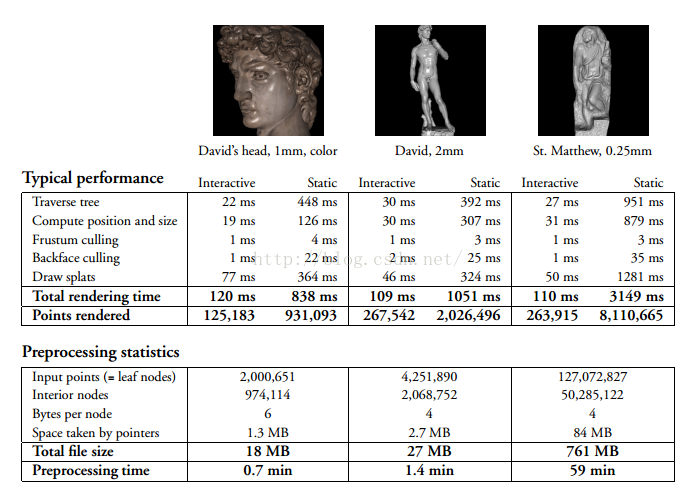
图6:渲染性能总结,一些统计数据的预处理时间和空间需求,以及本文使用的模型的数据。
5以前的工作
以前显示大型模型的方法可分为点渲染、可见性剔除的多细节层次控制和几何压缩三类。
5.1点渲染
计算机图形学系统传统上用三角形作为渲染的原始对象。为了在宏大场景中减少三角形的设置和光栅化的成本,一系列更简单的原始对象被提出来了。Levoy和Whitted使用点来显示原始连续表面[Levoy 85],最近的焦点则是Grossman和Dally[Grossman 98]把点渲染纳入商业产品——Animatek Cavier系统,例如使用点渲染游戏Animatek中的角色。这一方法也被使用于更专业的领域,如渲染火,烟,和树木[Csuri 79,Reeves79, Max 95]。
在体绘制的渲染中[Westover 89],对于巨大物体进行分层是很自然的事情,Laur和Hanrahan使用八叉树数据结构来实现对区域的闲置空间的压缩 [Laur 91]。虽然目前这是最好的方法,我们也有必要关注其他方案,Cline等人提出的方案是使用像素压缩方法进行立方体分割[Cline 88]。对于微小体元,Swan等人提出了正确的算法,得到了平滑的结果[Swan 97]。
5.2可视性剔除
平视算法和隐面消除算法——例如那些QSplat业已使用的——亦出现在大量的计算机图形系统中。分层视域剔除[Samet 90]基于八叉树等数据结构,其对宏大场景的渲染功能可堪标杆。隐面消除原始对象的方法如同“旧时王谢堂前燕,飞入寻常百姓家”,此外,Kumar和Manocha还提出了基于法锥面的分层隐面消除算法[Kumar 96]。
另一类的可视化剔除算法包括阻尼剔除方法。Greene等人使用Z缓冲描述了一个通用算法,通过抛出原始对象来不断拟合[Greene 93]。如果现场是高度结构化的,其他更专业阻尼算法也可资运用。那些用于建筑领域的计算机图形系统,例如经常使用的cells-and-portals方案——剔除掉整个非可视化的空间[Tellor 91]。QSplat目前不执行任何形式的阻尼剔除,这将为我们探幽入微提供方便。然而,阻尼剔除,仍是对曲径通幽处的有用补充。
5.3多细节层次控制
渲染一个大数据集通常会导致原始对象小于输出设备像素。为了减少渲染时间,在这些情况下,需要切换到低分辨率数据集,并与原始对象更紧密地匹配输出。LOD算法可以区分那些存储整个对象的离散程度的细节,执行细粒度的LOD控制算法,即通过控制连续的原始对象的数量,减少“弹出”构件,灵活地调整现场的多细节层次,弥补不同放大倍数的透视投影。
多分辨率分析对象作为基础网格的一部分,其一系列的修正存储为小波系数[Eck 95]。目前业已实现基于多分辨率的实时网格系统,可以选择使用任意数量的小波系数——因此画一个任意数量的多边形网格[Certain 96]。他们的观测对象还包括诸如渐进特性传输、独立集的几何性质、小波系数和对象颜色。
渐进网格使用基础网格顶点[Hoppe 96]进行分割操作,实时查看细化数百万多边形的情形[Hoppe 97,Hoppe98]。观测者不仅可以选择任意绘制的多边形数量,而且可以改进对象的不同部分形成不同的结果。其他系统还允许在整个场景采用不同的分辨率——包括ROAM渲染系统[Duchaineau 97]和LDI树[Zhang 99]。QSplat基于LOD控制实现了同样的目标,并允许在现场根据投影屏幕大小调整多细节层次。
5.4几何压缩
几何压缩的目标是减少内存需求和传输成本。Deering提出了一个压缩网格连接系统,考虑到了顶点位置、颜色和法向量,目前在硬件中得以应用[Deering 95]。最近的研究,如Taubin和Rossignac提出的拓扑操作方案,都聚焦于减少网格连接的成本和改善压缩顶点的位置[Taubin98]。Pajarola和Rossignac对渐进网格进行压缩,产生一个结合多细节层次控制和渐进细化的紧凑表示[Pajarola 99]。然而,他们的算法比QSplat预处理和解码成本都更高。
6 结论和未来的工作
QSplat系统能渐进显示实时渲染的大型模型,其结构匹配的渲染速度最快,预处理和压缩接近最佳,同时由于QSplat软件是轻量级的,是可以在低端机实现的,我们相信它将打破那些认为3D渲染不切实际的担忧。
我们可以将更多技术引入目前的QSplat框架,使其在时间和空间上更高效:
Huffman编码[Huffman 52]或另一个无损压缩方案可以使得实时显示更加紧凑。这将可以用于离线存储,或在低带宽情形下传输,但需要模型在渲染之前被解压。
当渲染速度比紧密度更要紧时,该算法可以通过加快消除球体位置和大小的压缩和增量编码(如3.1节所述),并简单地将这些数量存为浮点型。此外,法锥面和可视化锥面,如Grossman和Dally使用的,即使在高阻尼情形也能实现快速渲染[Zhang 97,Grossman98]。通过并行渲染算法——分配树的不同部分到不同的处理器——可以进一步加速。我们已经可以并行运行我们的预处理算法,尽管我们给出的是单处理器的结果。
进一步分析有赖于理解QSplat的缓存情形。在帧频控制、渲染、架构和工作集管理方面,业已涌现出大量研究[Funkhouser96],这些算法将提升用户的体验。
以下是QSplat可资结合的潜在的研究领域:
QSplat适合使用边界球层次结构和射线追踪的增量数据结构,使得高质量渲染效果的模型能以QSplat格式存储。
基于树的数据结构和渲染算法易于实例化,大大减少了内存,跳过了要求大量类定义的程式性的场景,这可以被认为是一种新形式的视觉实现,那就是允许在同一场景中有效地包含多个视点。
除了法向量和颜色可以存储在每个节点外,透明度、BRDFs和BTDFs这些数据也将增加QSplat可表示的视觉复杂性,使其功能类似于现代体积渲染器[Kajiya 89]。更复杂的对象,如光场、观测者独立视点以及不同空间的BRDFs以及分层图像处理,也可以在每个节点存储,创建混合渲染系统和现代化的基于图像的渲染器。
Acknowledgement
Thanksto Dave Koller, Jonathan Shade, Matt Ginzton, Kari Pulli,LucasPereira, James Davis, and the whole DMich gang. The Digital Michelangelo Project was sponsored by Stanford University, Interval ResearchCorporation, and the Paul Allen Foundation for the Arts.
Reference
[Aliaga 99] Aliaga, D., Cohen, J., Wilson, A.,Baker, E., Zhang, H., Erikson, C., Hoff, K., Hudson, T., Stuerzlinger, W.,Bastos, R., Whitton, M., Brooks, F., and Manocha, D. “MMR: An InteractiveMassive
ModelRendering System Using Geometric and Image-Based Acceleration,”Proc. Symposiumon Interactive 3D Graphics, 1999.
[Animatek]AnimaTek International, Inc., “Caviar Technology,” Web page: http://www.animatek.com/products_caviar.htm
[Arvo89] Arvo, J. and Kirk, D. “A Survey of Ray Tracing Acceleration Techniques,”AnIntroduction to Ray Tracing, Glassner, A. S. ed., Academic Press, 1989.
[Certain96] Certain, A., Popovi´ c, J, DeRose, T., Duchamp, T., Salesin, D.,andStuetzle, W. “Interactive Multiresolution Surface Viewing,” Proc.SIGGRAPH,1996.
[Chang99] Chang, C., Bishop, G., and Lastra, A. “LDI Tree: A Hierarchical Representationfor Image-Based Rendering,”Proc. SIGGRAPH, 1999.
[Cline88] Cline, H. E., Lorensen, W. E., Ludke, S., Crawford, C. R., and Teeter, B.C. “Two Algorithms for the Three-Dimensional Reconstruction ofTomograms,”Medical Physics, Vol. 15, No. 3, 1988.
[Cook87] Cook, R., Carpenter, L., and Catmull, E. “The Reyes Image RenderingArchitecture,”Proc. SIGGRAPH, 1987.
[Csuri79] Csuri, C., Hackathorn, R., Parent, R., Carlson, W., and Howard, M. “Towardsan Interactive High Visual Complexity Animation System,”Proc. SIGGRAPH, 1979.
[Curless96] Curless, B. and Levoy, M. “A Volumetric Method for Building Complex Modelsfrom Range Images,”Proc. SIGGRAPH, 1996.
[Deering95] Deering, M. “Geometry Compression,” Proc. SIGGRAPH,1995.
[Duchaineau97] Duchaineau, M., Wolinsky, M., Sigeti, D,. Miller, M., Aldrich, C., andMineev-Weinstein, M. “ROAMing Terrain: Real-time Optimally AdaptingMeshes,”Proc. Visualization, 1997.
[Eck95] Eck, M., DeRose, T., Duchamp, T., Hoppe, H., Lounsbery, M., and Stuetzle,W. “Multiresolution Analysis of Arbitrary Meshes,”Proc.SIGGRAPH, 1995.
[Funkhouser92] Funkhouser, T., Séquin, C., and Teller, S. “Management of Large Amounts ofData in Interactive Building Walkthroughs,”Proc.Symposium on Interactive 3DGraphics, 1992.
[Funkhouser93] Funkhouser, T. and Séquin, C. “Adaptive Display Algorithm for InteractiveFrame Rates During Visualization of Complex Virtual Environments,”Proc.SIGGRAPH, 1993.
[Funkhouser96] Funkhouser, T. “Database Management for Interactive Display of LargeArchitectural Models,”Graphics Interface, 1996.
[Greene93] Greene, N., Kass, M., and Miller, G. “Hierarchical Z-buffer Visibility,”Proc. SIGGRAPH, 1993.
[Grossman98] Grossman, J. and Dally, W. “Point Sample Rendering,”Proc.EurographicsRendering Workshop, 1998.
[Hoppe96] Hoppe, H. “Progressive Meshes,”Proc. SIGGRAPH, 1996.
[Hoppe97] Hoppe, H. “View-Dependent Refinement of Progressive Meshes,”Proc. SIGGRAPH,1997.
[Hoppe98] Hoppe, H. “Smooth View-Dependent Level-of-Detail Control and itsApplication to Terrain Rendering,”Proc. Visualization, 1998.
[Huffman52]Huffman, D. “A Method for the Construction of Minimum RedundancyCodes,”Proc. IRE, Vol. 40, No. 9, 1952.
[Kajiya89] Kajiya, J. and Kay, T. “Rendering Fur with Three Dimensional Te x t u r e s, ”Proc. SIGGRAPH, 1989.
[Krishnamurthy96] Krishnamurthy, V. and Levoy, M. “Fitting Smooth Surfaces to Dense PolygonMeshes,”Proc. SIGGRAPH, 1986.
[Kumar96] Kumar, S., Manocha, D., Garrett, W., and Lin, M. “Hierarchical Back-FaceComputation,”Proc. Eurographics Rendering Workshop, 1996.
[Laur91] Laur, D. and Hanrahan, P. “Hierarchical Splatting: A Progressive RefinementAlgorithm for Volume Rendering,”Proc. SIGGRAPH,1991.
[Levoy85] Levoy, M. and Whitted, T. “The Use of Points as a Display Primitive,”Technical Report TR 85-022, University of North Carolina at Chapel Hill, 1985.
[Levoy00] Levoy, M., Pulli, K., Curless, B., Rusinkiewicz, S., Koller, D., Pereira,L., Ginzton, M., Anderson, S., Davis, J., Ginsberg, J., Shade, J., and Fulk, D.“The Digital Michelangelo Project: 3D Scanning of Large Statues,”Proc.SIGGRAPH, 2000.
[Lindstrom98] Lindstrom, P. and Turk, G. “Fast and Memory Efficient PolygonalSimplification,”Proc. Visualization, 1998.
[Luebke97] Luebke, D., and Erikson, C. “View-Dependent Simplification of ArbitraryPolygonal Environments,”Proc. SIGGRAPH, 1997.
[Max95] Max, N. and Ohsaki, K. “Rendering Trees from Precomputed ZbufferViews,”Proc. Eurographics Rendering Workshop, 1995.
[Pajarola99] Pajarola, R. and Rossignac, J. “Compressed Progressive Meshes,”TechnicalReport GIT-GVU-99-05, Georgia Institute of Technology, 1999.
[Reeves83] Reeves, W. “Particle Systems – A Technique for Modeling a Class of FuzzyObjects,”Proc. SIGGRAPH, 1983.
[Rossignac93] Rossignac, J. and Borrel, P. “Multi-Resolution 3D Approximations forRendering Complex Scenes,”Geometric Modeling in Computer Graphics, 1993.
[Rubin80] Rubin, S. M. and Whitted, T. “A 3-Dimensional Representation for FastRendering of Complex Scenes,”Proc. SIGGRAPH, 1980.
[Samet90]Samet,H.Applications of Spatial Data Structures, Addison-Wesley,1990.
[Shirman93] Shirman, L. and Abi-Ezzi, S. “The Cone of Normals Technique for FastProcessing of Curved Patches,”Proc. Eurographics, 1993.
[Swan97] Swan, J., Mueller, K., Möller, T., Shareef, N., Crawfis, R., and Yagel, R.“An Anti-Aliasing Technique for Splatting,”Proc. Visualization,1997.
[Tau b in 9 8] Taubin, G. and Rossignac, J. “Geometric Compression Through TopologicalSurgery,”ACM Trans. on Graphics, Vol. 17, No. 2, 1998.
[Teller91] Teller, S. and Séquin, C. “Visibility Preprocessing for Interactive Walkthroughs,”Proc.SIGGRAPH, 1991.
[West over 89] Westover, L. “Interactive Volume Rendering,”Proc. VolumeVisualization Workshop, University of North Carolina at Chapel Hill, 1989.
[Yemez99] Yemez, Y. and Schmitt, F. “Progressive Multilevel Meshes from OctreeParticles,”Proc. 3D Digital Imaging and Modeling, 1999.
[Zhang97] Zhang, H. and Hoff, K. “Fast Backface Culling Using Normal Masks,”Proc.Symposium on Interactive 3D Graphics, 1997.















 2710
2710











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









