






-
下载Anaconda3-5.3.0-Linux-x86_64.sh

-
安装Anaconda

-
编辑~/.bashrc加入模块路径

-
使~/.bashrc生效

-
查看Python版本

-
在IPython Notebook使用Spark
创建ipynotebook工作目录

-
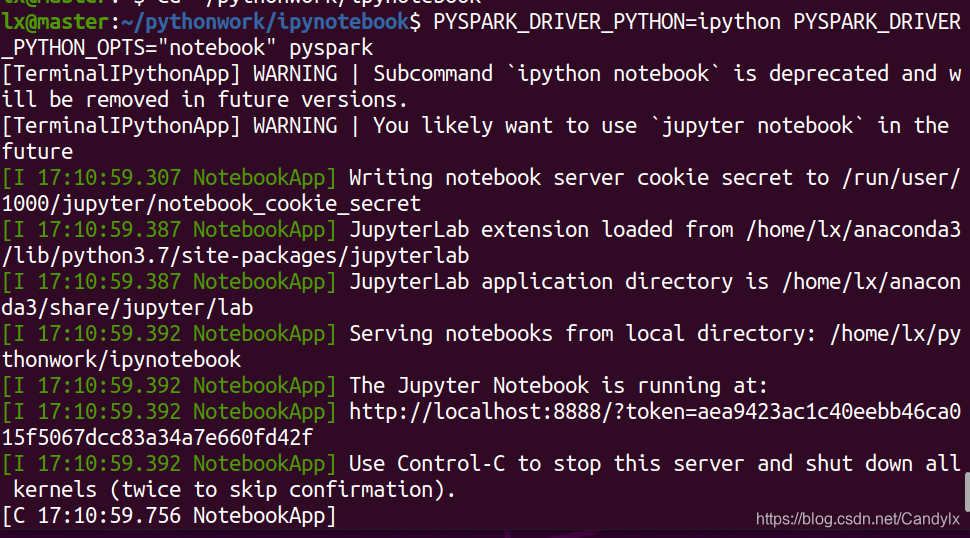
在IPython Nodebook界面运行pyspark

-
在IPython Notebook运行程序代码

-
读取本地文件程序代码

-
读取HDFS文件程序代码
需要先启动Hadoop
start-all.sh


-
输入读取HDFS文件程序代码

保存Nodebook -
使用IPython Notebook在Hadoop YARN-client模式运行
(作业)
使用IPython Notebook在Spark Stand Alone模式运行
启动Spark Stand Alone

-
启动IPython Notebook运行在Spark Stand Alone模式

-
全部重新执行Notebook程序代码

















 228
228

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









