









首先安装好pandas(pip命令安装)
本节案例数据表lesson4.xlsx
Section 1 导入数据
- 用的pandas的read_x()方法,x表示待导入文件的格式
- 导入.xlsx文件,使用read_excel()
# 文件路径
filePath = "../test1/lesson4.xlsx"
# 读入数据
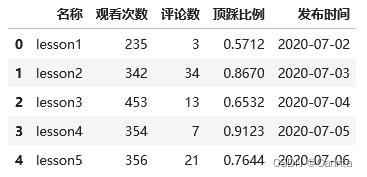
df = pd.read_excel(filePath)
# 指定sheet名称读入数据
df = pd.read_excel(filePath, sheet_name = "观看数据") # 读取名为“观看数据”的sheet
# 指定第几个sheet读取,从0开始
df = pd.read_excel(filePath, sheet_name = 0) # 读取第一个sheet
# 打印
# print(df)
df
运行结果:
# 指定哪一列为行索引
# 上一个案例没有指定行索引,默认加一列0-4
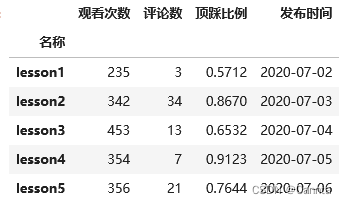
df = pd.read_excel(filePath, index_col = 0) # 第一列作为行索引
df
运行结果:
# 指定哪一行为列索引
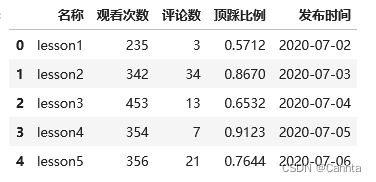
df = pd.read_excel(filePath, header = 0) # 第一列作为列索引,不指定也是默认第一行
df
运行结果:
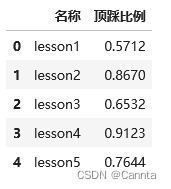
# 指定需要导入的列
df = pd.read_excel(filePath, usecols = [0,3]) # 只导入第一列和第四列
df
# 当数据很庞大时,只导入所需要的列可以提高数据处理速度
运行结果:
Section 2 了解数据内容
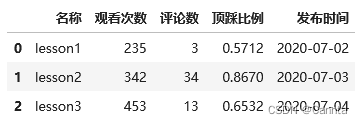
# head()方法控制显示前几行,默认5行数据
df = pd.read_excel(filePath, sheet_name = "观看数据")
# df.head() # 前5行(不包括title)
df.head(3) # 前3行(不包括title)
运行结果:
# shape属性获取数据表大小,返回元组
print(df.shape)
# 结果:(5, 5) 5行5列数据,不包括title
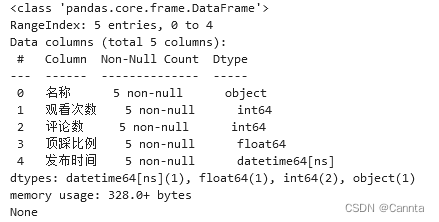
# infor()方法获取数据类型
print(df.info())
'''
结果解释:
该表格是DataFrame类型
共5条数据,索引0~4
共5列
下面列出了5列的名称、是否有空值、数据类型
'''
info()运行结果:
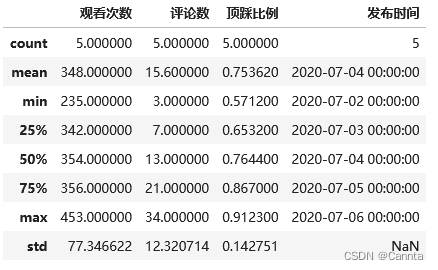
# describe()方法获取数据分布
print(df.describe())
运行结果:
Section 3 保存数据
- 数据经过自己的处理之后,需要保存成新的excel表
df = pd.read_excel(filePath, sheet_name = "观看数据")
# 将df保存为excel,文件名、sheet名称,index=False去掉行索引(不然自动生成的0-4会到新表,)
# na_rep = 0 如果某些单元格没有数值,填充为0
# inf_rep = 0 如果某些单元格时无穷之,填充为0
df.to_excel("new_sheet.xlsx", sheet_name = "new_sheet", index = False, na_rep = 0, inf_rep = 0)
上述代码完成后,生成new_sheet.xlsx















 357
357











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









