






写复杂的sql语句时,尽量别用分页 count(0)出现可能使用分页
1、统计本级单位以及下级数据
方法一:先子表用count函数统计数据 再配合find_in_set函数 、sum函数统计全部数据。count统计本级数据,sum配合find_in_set是同统计本级以及子级的数据
方法二:直接使用count配合find_in_set再加上判断FIND_IN_SET( dept.id, t.parent_path )来统计本级和本级及其下级数据
SELECT
dept.id,
//本级数据
count( CASE WHEN FIND_IN_SET( dept.id, t.parent_path )= 1 THEN 1 END ) bdw,
//本级数据及下级数据
count( CASE WHEN FIND_IN_SET( dept.id, t.parent_path )> 0 THEN 1 END ) lj
FROM
sys_department dept
LEFT JOIN (
SELECT
tq.org_Id,
sd.parent_path,
sd.id deptId
FROM
`tq_meet` tq
LEFT JOIN sys_department sd ON tq.org_id = sd.id
) t ON FIND_IN_SET( dept.id, t.parent_path )> 0
GROUP BY
dept.id先用count统计数量再用sum计算和
select fresult.*
from (
select sd.id ,sd.`name` deptName,
IFNULL(sum(result.PersuasiveNum),0) PersuasiveNum,
IFNULL(sum(result.DsrgzdwNum),0) DsrgzdwNum
from
sys_department sd
left join (
select dTable.create_dept_id,dept.parent_path,dTable.PersuasiveNum PersuasiveNum,dTable.DsrgzdwNum DsrgzdwNum
from (
SELECT
td.create_dept_id,
count( td.create_dept_id ) PersuasiveNum,
count(case when td.dsr_gzdw IS NOT NULL
and td.dsr_gzdw != '' then 1 end) DsrgzdwNum
FROM
tq_ddcwf td
GROUP BY
td.create_dept_id
)dTable
left join sys_department dept on dTable.create_dept_id =dept.id
) result on FIND_IN_SET(sd.id,result.parent_path)>0
where sd.id is not null and sd.status=1
GROUP BY sd.id
) fresult
order by fresult.PersuasiveNum desc3、传入部门id查出本级及其所以下级的部门id 用来实现统计数据 最好添加上
GROUP BY td.create_dept_id来分类
<if test="deptId !=null and deptId!= ''">
and td.create_dept_id in
(select id from
(
with recursive departments as
(
select a.id,a.name,a.parent_id,b.name as parent_name
from sys_department a
left join sys_department b on a.parent_id=b.id
where a.id in (${deptId})
union all
select bb.id,bb.name,bb.parent_id,bb.parent_name from
(
select a.id,a.name,a.parent_id,b.name as parent_name
from sys_department a
left join sys_department b on a.parent_id=b.id
) as bb,departments as h where h.id=bb.parent_id
)
select dep.id,dep.name,dep.parent_id,dep.parent_name from departments as dep
) xx
)
</if>此方法的前提是表有parent_path这个字段,以下为生成此字段
//更新所有单位的上级路径
sysDepartmentMapper.updataParentPath(new HashMap<>());
//mapper文件
int updataParentPath(HashMap<String, Object> map);
//xml代码
<update id="updataParentPath" parameterType="hashmap">
update sys_department sd
set sd.parent_path =getParentList('sys_department', sd.id)
</update>
getParentList为数据库中的函数。
CREATE DEFINER=`root`@`%` FUNCTION `getParentList`(tableName varchar(64),rootId varchar(100)) RETURNS varchar(1000) CHARSET utf8
BEGIN
DECLARE fid varchar(100) default '';
DECLARE str varchar(4000) default rootId;
IF tableName = 'sys_department' THEN
WHILE rootId is not null do
SET fid =(SELECT parent_id FROM sys_department WHERE id = rootId);
IF fid is not null THEN
SET str = concat(str, ',', fid);
SET rootId = fid;
ELSE
SET rootId = fid;
END IF;
END WHILE;
END IF;
return str;
END update sys_department sd
set sd.parent_path =getParentList('sys_department', sd.id)
com.mysql.cj.jdbc.exceptions.MysqlDataTruncation: Data truncation: Data too long for column 'str' at row 1
当数据库中数据父子结构乱的时候可用以下查出结构混乱的数据并删除
SELECT * FROM sys_department depart
LEFT JOIN sys_department sd2 on depart.parent_id=sd2.id
LEFT JOIN sys_department sd3 on sd2.parent_id=sd3.id
LEFT JOIN sys_department sd4 on sd3.parent_id=sd4.id
LEFT JOIN sys_department sd5 on sd4.parent_id=sd5.id
LEFT JOIN sys_department sd6 on sd5.parent_id=sd6.id
WHERE depart.id=sd2.id or depart.id=sd3.id or depart.id=sd4.id or depart.id=sd5.id or depart.id=sd6.id 统计还有生成临时表在统计
CREATE TEMPORARY TABLE IF NOT EXISTS tempresult AS (
select count(CASE WHEN YEARWEEK(td.create_time,1) = YEARWEEK(now(),1)-1 THEN 0 END) lastWeekSum,
count(CASE WHEN YEARWEEK(td.create_time,1) = YEARWEEK(now(),1) THEN 0 END) thisWeekSum,
count(CASE WHEN MONTH(td.create_time) = MONTH(now()) THEN 0 END) thisMonthSum,
td.create_dept_name createDeptName,
td.create_dept_id createDeptId
FROM tq_ddcwf td
<where>
td.cllx='面包车'
and (MONTH(td.create_time) = MONTH(now()) or YEARWEEK(td.create_time,1) = YEARWEEK(now(),1)-1 or YEARWEEK(td.create_time,1) = YEARWEEK(now(),1))
and td.hzrs>4
<if test="deptId !=null and deptId!= ''">
and td.create_dept_id in
(select id from
(
with recursive departments as
(
select a.id,a.name,a.parent_id,b.name as parent_name
from sys_department a
left join sys_department b on a.parent_id=b.id
where a.id in (${deptId})
union all
select bb.id,bb.name,bb.parent_id,bb.parent_name from
(
select a.id,a.name,a.parent_id,b.name as parent_name
from sys_department a
left join sys_department b on a.parent_id=b.id
) as bb,departments as h where h.id=bb.parent_id
)
select dep.id,dep.name,dep.parent_id,dep.parent_name from departments as dep
) xx
)
GROUP BY td.create_dept_id
</if>
</where>
);
SELECT
IFNULL( SUM( t.lastWeekSum ), 0 ) AS lastWeekSum,
IFNULL( SUM( t.thisWeekSum ), 0 ) AS thisWeekSum,
IFNULL( SUM( t.thisMonthSum ), 0 ) AS thisMonthSum,
sys.NAME AS createDeptName
FROM
sys_department sys
RIGHT JOIN (
SELECT
temp1.lastWeekSum,
temp1.thisWeekSum,
temp1.thisMonthSum,
temp1.createDeptName,
temp1.createDeptId,
sd.parent_path,
sd.parent_id
FROM
tempresult temp1
LEFT JOIN sys_department sd ON sd.id = temp1.createDeptId
) t ON FIND_IN_SET( sys.id, t.parent_path )> 0
<where>
<if test="nullDeptId !=null and nullDeptId!= ''">
sys.parent_id is null or sys.parent_id =''
</if>
</where>
GROUP BY
sys.id;2、根据日期统计统计多张表
WITH recursive dates AS (
SELECT DATE('开始时间') AS date
UNION ALL
SELECT date + INTERVAL 1 DAY
FROM dates
WHERE date < DATE('结束时间')
), table1_data AS (
SELECT DATE(create_time) AS date, SUM(value) AS total_value
FROM table1
WHERE DATE(create_time) BETWEEN DATE('开始时间') AND DATE('结束时间')
GROUP BY DATE(create_time)
), table2_data AS (
SELECT DATE(create_time) AS date, COUNT(*) AS total_count
FROM table2
WHERE DATE(create_time) BETWEEN DATE('开始时间') AND DATE('结束时间')
GROUP BY DATE(create_time)
), table3_data AS (
SELECT DATE(create_time) AS date, AVG(price) AS average_price
FROM table3
WHERE DATE(create_time) BETWEEN DATE('开始时间') AND DATE('结束时间')
GROUP BY DATE(create_time)
)
SELECT dates.date,
COALESCE(t1.total_value, 0) AS table1_total_value,
COALESCE(t2.total_count, 0) AS table2_total_count,
COALESCE(t3.average_price, 0) AS table3_average_price
FROM dates
LEFT JOIN table1_data t1 ON dates.date = t1.date
LEFT JOIN table2_data t2 ON dates.date = t2.date
LEFT JOIN table3_data t3 ON dates.date = t3.date
ORDER BY dates.date;
实战
WITH recursive dates AS (
SELECT DATE('2023-08-15') AS date
UNION ALL
SELECT date + INTERVAL 1 DAY
FROM dates
WHERE date < DATE('2023-08-18')
), table1_data AS (
SELECT
DATE( create_time ) AS date,
count( CASE WHEN cllx = '行人' OR cllx = '电动二轮车' THEN 1 END ) AS 'xingrenOrdderlun',
count( CASE WHEN cllx = '三轮' OR cllx = '四轮' THEN 1 END ) AS 'sanlunOrsilun',
count( CASE WHEN cllx = '面包车' THEN 1 END ) AS 'mianbaoche',
count( CASE WHEN cllx = '电动车临牌' THEN 1 END ) AS 'ddclinpai'
FROM
tq_ddcwf
WHERE DATE(create_time) BETWEEN DATE('2023-08-15') AND DATE('2023-08-18')
GROUP BY DATE(create_time)
), table2_data AS (
SELECT
DATE( create_time ) AS date,
IFNULL( COUNT( 1 ), 0 ) AS 'sjmyjd'
FROM
tq_sjmyjd_table
WHERE DATE(create_time) BETWEEN DATE('2023-08-15') AND DATE('2023-08-18')
GROUP BY DATE(create_time)
), table3_data AS (
SELECT
DATE( create_time ) AS date,
IFNULL( COUNT(*), 0 ) AS 'wjaqd'
FROM
tq_wjaqd
WHERE DATE(create_time) BETWEEN DATE('2023-08-15') AND DATE('2023-08-18')
GROUP BY DATE(create_time)
)
SELECT dates.date,
COALESCE(t1.xingrenOrdderlun, 0) AS xingrenOrdderlun,
COALESCE(t1.sanlunOrsilun, 0) AS sanlunOrsilun,
COALESCE(t1.mianbaoche, 0) AS mianbaoche,
COALESCE(t1.ddclinpai, 0) AS ddclinpai,
COALESCE(t2.sjmyjd, 0) AS sjmyjd,
COALESCE(t3.wjaqd, 0) AS wjaqd
FROM dates
LEFT JOIN table1_data t1 ON dates.date = t1.date
LEFT JOIN table2_data t2 ON dates.date = t2.date
LEFT JOIN table3_data t3 ON dates.date = t3.date
ORDER BY dates.date;
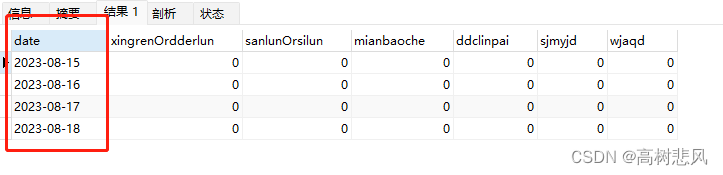
日期中没有的数据也会实现为0
3、通过构造mybatis返回类型结构来实现多表查询一条数据中带一个list数据
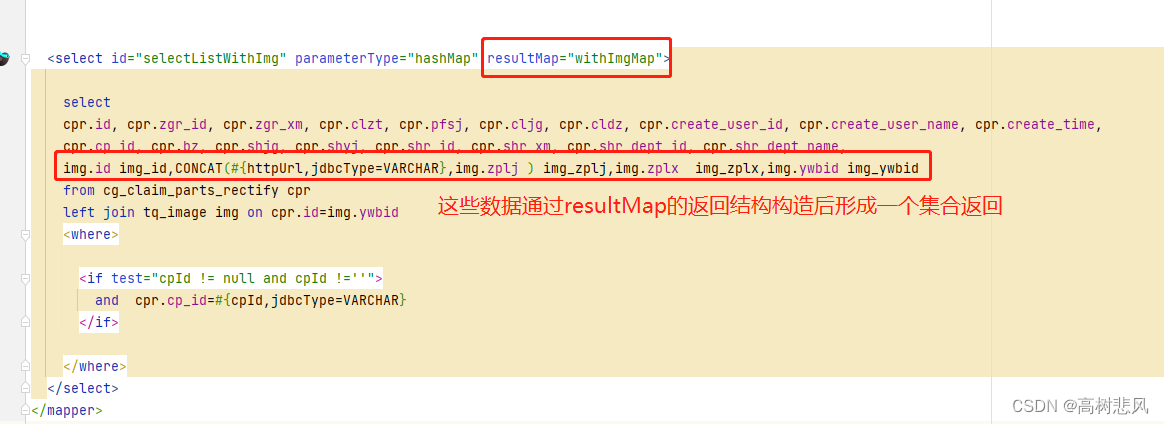
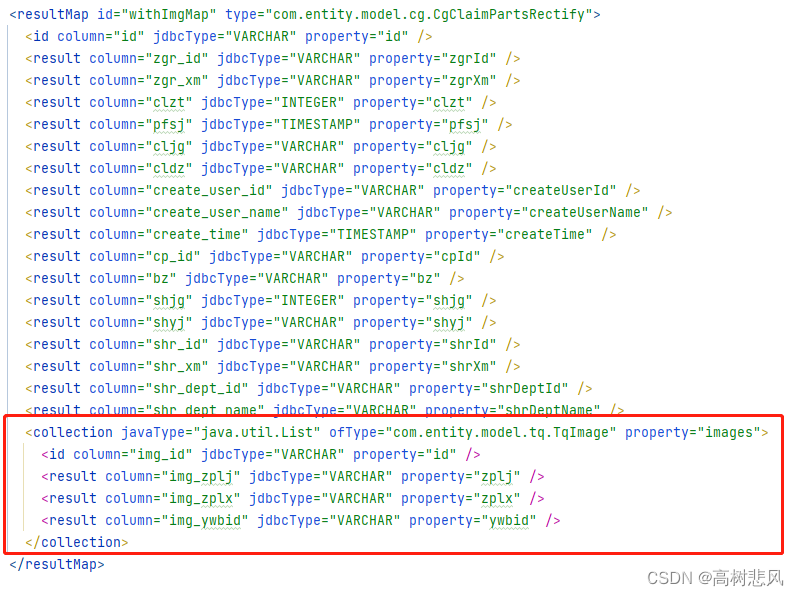
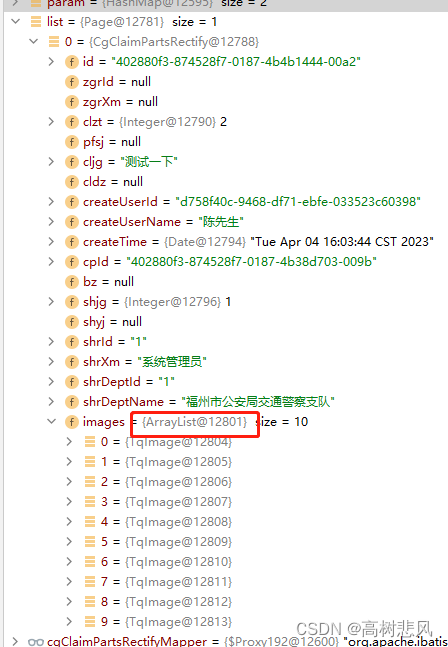
<resultMap id="withImgMap" type="com.entity.model.cg.CgClaimPartsRectify">
<id column="id" jdbcType="VARCHAR" property="id" />
<result column="zgr_id" jdbcType="VARCHAR" property="zgrId" />
<result column="zgr_xm" jdbcType="VARCHAR" property="zgrXm" />
<result column="clzt" jdbcType="INTEGER" property="clzt" />
<result column="pfsj" jdbcType="TIMESTAMP" property="pfsj" />
<result column="cljg" jdbcType="VARCHAR" property="cljg" />
<result column="cldz" jdbcType="VARCHAR" property="cldz" />
<result column="create_user_id" jdbcType="VARCHAR" property="createUserId" />
<result column="create_user_name" jdbcType="VARCHAR" property="createUserName" />
<result column="create_time" jdbcType="TIMESTAMP" property="createTime" />
<result column="cp_id" jdbcType="VARCHAR" property="cpId" />
<result column="bz" jdbcType="VARCHAR" property="bz" />
<result column="shjg" jdbcType="INTEGER" property="shjg" />
<result column="shyj" jdbcType="VARCHAR" property="shyj" />
<result column="shr_id" jdbcType="VARCHAR" property="shrId" />
<result column="shr_xm" jdbcType="VARCHAR" property="shrXm" />
<result column="shr_dept_id" jdbcType="VARCHAR" property="shrDeptId" />
<result column="shr_dept_name" jdbcType="VARCHAR" property="shrDeptName" />
<collection javaType="java.util.List" ofType="com.entity.model.tq.TqImage" property="images">
<id column="img_id" jdbcType="VARCHAR" property="id" />
<result column="img_zplj" jdbcType="VARCHAR" property="zplj" />
<result column="img_zplx" jdbcType="VARCHAR" property="zplx" />
<result column="img_ywbid" jdbcType="VARCHAR" property="ywbid" />
</collection>
</resultMap>
<select id="selectListWithImg" parameterType="hashMap" resultMap="withImgMap">
select
cpr.id, cpr.zgr_id, cpr.zgr_xm, cpr.clzt, cpr.pfsj, cpr.cljg, cpr.cldz, cpr.create_user_id, cpr.create_user_name, cpr.create_time,
cpr.cp_id, cpr.bz, cpr.shjg, cpr.shyj, cpr.shr_id, cpr.shr_xm, cpr.shr_dept_id, cpr.shr_dept_name,
img.id img_id,CONCAT(#{httpUrl,jdbcType=VARCHAR},img.zplj ) img_zplj,img.zplx img_zplx,img.ywbid img_ywbid
from cg_claim_parts_rectify cpr
left join tq_image img on cpr.id=img.ywbid
<where>
<if test="cpId != null and cpId !=''">
and cpr.cp_id=#{cpId,jdbcType=VARCHAR}
</if>
</where>
</select>上面使用嵌套结果映射 但分页不支持嵌套结果映射可以修改为嵌套select可参考
分页导致Mybatis数据不一致(使用了关联查询collection)_高树悲风的博客-CSDN博客
4、CREATE TEMPORARY TABLE与with as 提取临时表别名
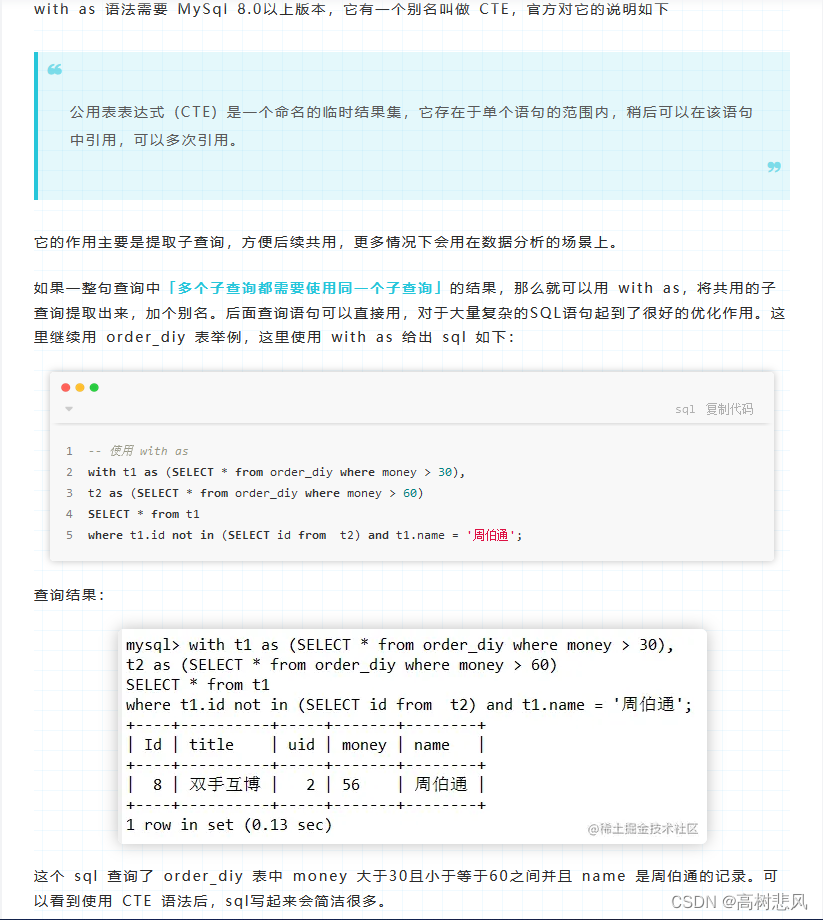
CREATE TEMPORARY TABLE 创建的临时表是一个独立的表对象,会在当前会话结束或显式删除表时被销毁。这意味着,临时表只在当前会话中可见,并且不能被其他会话访问。因此,您可以使用相同的表名创建临时表,在不同的会话中保证不会发生冲突。
另一方面,WITH 子句生成的临时表仅在查询语句的上下文中存在,也称为 "公用表表达式" (Common Table Expression, CTE)。这意味着,虽然临时表在查询中被引用了多次,但它只是查询中的一个临时结果集,并没有被创建为一个独立的表对象。因此,它不能在查询之外的上下文中被引用或操作。
因此,如果您需要在当前会话中创建一个独立的临时表,以供多个查询或操作使用,那么 CREATE TEMPORARY TABLE 将是更适合的选择。如果您只需要在一个查询中使用临时表,那么 WITH 子句创建的临时表将更加方便。
CREATE TEMPORARY TABLE a1 AS (
SELECT zh.*
FROM `user2023` zh
LEFT JOIN sys_user suer ON zh.accounts = suer.user_name
WHERE suer.id IS NULL
);
INSERT INTO user_copy (id, user_name, name, status, user_type, platform, password)
SELECT UUID(), accounts, name, 1, '1', '1', 'dezhoujiaojing@123'
FROM a1;
INSERT INTO user_role (id, user_id, role_id, role_name)
SELECT UUID(), c.id, '1', '1'
FROM ( SELECT b.id FROM a1 a LEFT JOIN user_copy b on a.accounts = b.user_name) c;
-- DROP TEMPORARY TABLE IF EXISTS a1;
5、详细地址如何在表中查出所在乡镇(匹配查询)
WITH town AS (
SELECT *FROM sys_department WHERE unit_type = 1 AND xz_level = 4 and xzqh=#{xzqh}
)
SELECT * FROM town WHERE #{djzs} LIKE CONCAT('%', town.name, '%');6、在使用不能分组情况需要去重统计数据
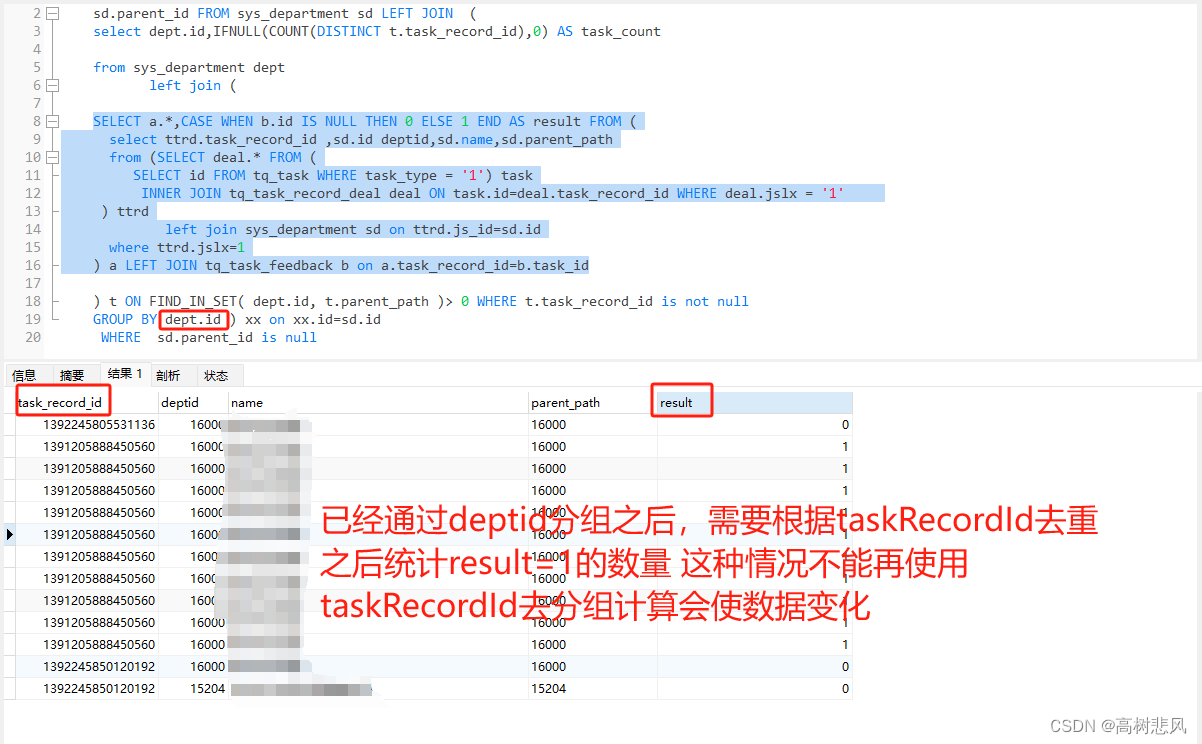
COUNT 函数在默认情况下不统计 NULL 值。如果你想统计包括 NULL 值在内的记录数量,可以使用 COUNT(*) 或 COUNT(字段名)。 所以可以设置为null排除
count(DISTINCT case when (t.task_record_id and t.result =1) then t.task_record_id else NULL end ) as feedbackSummysql sum函数配合 case when distinct 去重复求和_sum case when 去掉重复值-CSDN博客
7、使用索引的经验
a、子查询使索引失效
b、表连接时使用where才能使用索引

















 3872
3872

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









