







1.对象头
Java对象头里的Mark Word里默认存储对象的HashCode、分代年龄和锁标记位。




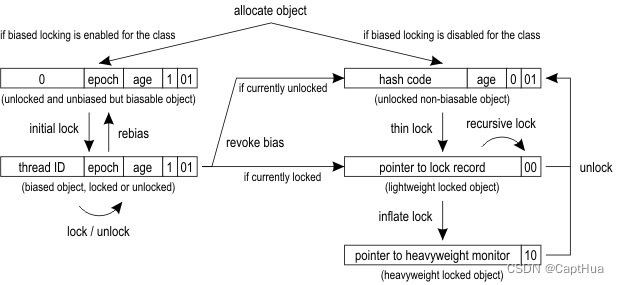
对象在不同状态下的markword布局
2.锁
无锁状态、偏向锁状态、轻量级锁状态和重量级锁状态,这几个状态会随着竞争情况逐渐升级。锁可以升级但不能降级,这种锁升级却不能降级的策略,目的是为了提高获得锁和释放锁的效率。
2.1.偏向锁
大多数情况下,锁不仅不存在多线程竞争,而且总是由同一线程多次获得,为了让线程获得锁的代价更低而引入了偏向锁。
当一个线程访问同步块并获取锁时,会在对象头和栈帧中的锁记录里存储锁偏向的线程ID。
偏向锁的获取
假设当前执行的线程为T1,步骤如下
1.检测锁对象的 MarkWord, 判断其偏向状态
(无锁)可偏向状态 的MarkWord为: 0 epoch age 1 01 ,线程id为0,偏向锁标志为1,锁标志位为01
已偏向状态: tId epoch age 1 01
2.1 如果为可偏向状态,则CAS 操作,将自己的线程 ID 写入MarkWord。
CAS成功进入步骤3。
CAS失败,说明有另外一个线程 T2 抢先获取了偏向锁。此时需要撤销 T2 获得的偏向锁,将其升级为轻量级锁,继续由 T2 持有。
2.2 如果为已偏向状态,检测Mark Word中tId是否指向当前线程,如果是当前线程,进入步骤3,如果不等,
则证明该对象目前偏向于其他线程, 需要撤销偏向锁。
3.执行同步代码。此时的markword为 tId epoch age 1 01 。同步代码块执行完后,不会尝试将 markword 中的 tId 赋回原值。
偏向锁的撤销
偏向锁使用了一种等到竞争出现才释放锁的机制,所以当其他线程尝试竞争偏向锁时,持有偏向锁的线程才会释放锁。
偏向锁的撤销,需要等待全局安全点(在这个时间点上没有正在执行的字节码)。
通过 MarkWord 中已经存在的 TId 找到成功获取了偏向锁的那个线程, 然后在该线程的栈帧中补充上轻量级加锁时会保存的锁记录(Lock Record),将MarkWord复制到锁记录中, 然后将对象的 MarkWord 更新为指向这条锁记录的指针。
锁撤销操作完成后,阻塞在安全点的线程继续执行。
偏向锁的批量重偏向(bulk rebiasing)机制
openjdk官网中的解释如下
A similar mechanism, called bulk rebiasing, optimizes situations in which objects of a class are locked and unlocked by different threads but never concurrently. It invalidates the bias of all instances of a class without disabling biased locking. An epoch value in the class acts as a timestamp that indicates the validity of the bias. This value is copied into the header word upon object allocation. Bulk rebiasing can then efficiently be implemented as an increment of the epoch in the appropriate class. The next time an instance of this class is going to be locked, the code detects a different value in the header word and rebiases the object towards the current thread.
一个相似的称为批量重偏向的机制,它优化了一个类的对象被不同线程加锁和解锁,但不是并发操作的场景。它会使这个类所有实例的偏向在不禁用偏向锁的情况下失效。类中的epoch值作为一个时间戳来表明偏向的有效性。在对象分配时,该值被赋值到markword中。批量重偏向可以通过增加类中的epoch被有效的实现。当下一次这个类的实例将要被加锁时,代码如果检测到markword中的epoch值和类中的不一样,同步对象就会重新偏向当前线程。
偏向锁不存在解锁的操作,只有撤销操作。
批量重偏向的过程如下:
如果一个对象先偏向于某个线程,执行完同步代码后,另一个线程就不能直接重新获得偏向锁吗?答案是可以的,JVM 提供了批量重偏向机制(bulk rebiasing)机制:
引入一个概念 epoch,其本质是一个时间戳 ,代表了偏向锁的有效性。
除了对象中的 epoch,对象所属的类class A 信息中, 也会保存一个 epoch 值。
每当遇到一个全局安全点时, 如果要对 class A 进行批量再偏向, 则首先对 class A 中保存的 epoch 进行增加操作,得到一个新的 epoch_new。
然后扫描所有持有 class A 实例的线程栈,根据线程栈的信息判断出该线程是否锁定了该对象,仅将epoch_new 的值赋给被锁定的对象。
退出安全点后,当有线程需要尝试获取偏向锁时,检查 class A 中存储的 epoch 值是否与同步对象(A实例)中存储的 epoch 值是否相等,如果不相等,则说明该对象的偏向锁已经无效了,可以尝试对该对象重新进行偏向操作。
偏向锁的关闭
偏向锁在Java 6和Java 7里是默认启用的,但是它在应用程序启动几秒钟之后才激活,如有必要可以使用JVM参数来关闭延迟:-XX:BiasedLockingStartupDelay=0。如果你确定应用程序里所有的锁通常情况下处于竞争状态,可以通过JVM参数关闭偏向锁:-XX:-UseBiasedLocking=false,那么程序默认会进入轻量级锁状态。
2.2.轻量级锁
偏向锁撤销后, 对象可能处于两种状态。
无锁不可偏向: hashcode age 0 01
轻量级锁: 指向锁记录的指针 00
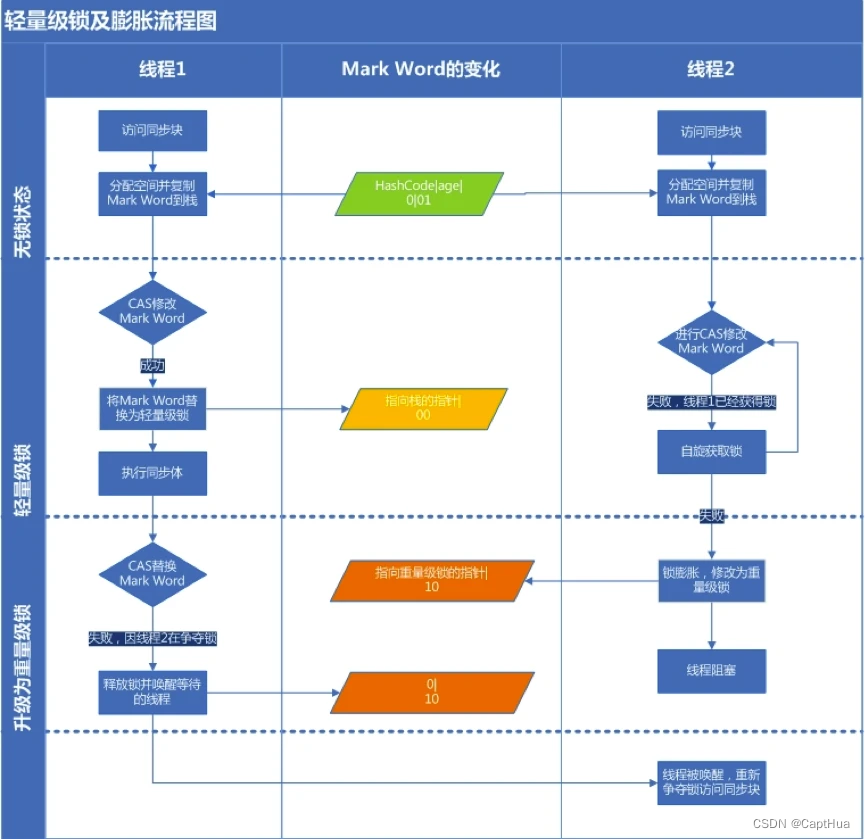
轻量级锁加锁
线程在执行同步块之前,根据标志位判断出对象状态处于不可偏向的无锁状态
在当前线程的栈桢中创建用于存储锁记录的空间,并将对象头中的Mark Word复制到锁记录中,官方称为Displaced Mark Word。然后线程尝试使用CAS将对象头中的Mark Word替换为指向锁记录的指针
成功:获得轻量级锁,执行同步块。
失败:如果失败,表示其他线程竞争锁,当前线程便尝试使用自旋来获取锁。自旋一定次数后,升级为重量级锁。
轻量级锁解锁
轻量级解锁时,会使用原子的CAS操作将Displaced Mark Word替换回到对象头,如果成功,则表示没有竞争发生。如果失败,表示当前锁存在竞争,锁就会膨胀成重量级锁。
下图是两个线程同时争夺锁,导致锁膨胀的流程图。未启用偏向锁。
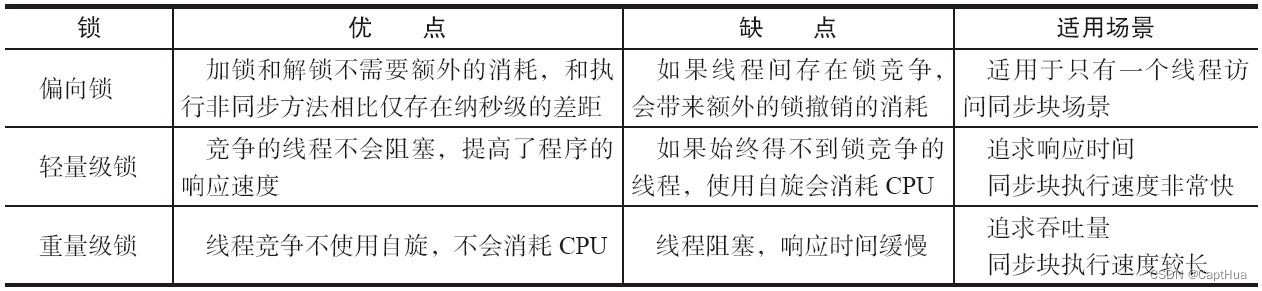
2.3.不同锁的优缺点对比
3.优化
3.1.适应性自旋(Adaptive Spinning)
当线程在获取轻量级锁的过程中执行CAS操作失败时,通过自旋来继续获取锁。自旋是需要消耗CPU的,如果一直获取不到锁的话,那该线程就一直处在自旋状态,白白浪费CPU资源。解决这个问题最简单的办法就是指定自旋的次数,例如让其循环10次,如果还没获取到锁就进入阻塞状态。JDK采用的方式是适应性自旋,简单来说就是线程如果自旋成功了,则下次自旋的次数会更多,如果自旋失败了,则自旋的次数就会减少。
3.2.锁粗化
将多次连接在一起的加锁、解锁操作合并为一次,将多个连续的锁扩展成一个范围更大的锁。append()方法是加锁的,如果连续执行3个append()方法,会将这三个加锁方法合并为只加一次锁。
public void append(){
stringBuffer.append("a");
stringBuffer.append("b");
stringBuffer.append("c");
}
@Override
synchronized StringBuffer append(AbstractStringBuilder asb) {
toStringCache = null;
super.append(asb);
return this;
}3.3.锁消除
去除不可能存在共享资源竞争的锁
根据代码逃逸技术,如果判断到一段代码中,堆上的数据不会逃逸出当前线程,那么可以认为这段代码是线程安全的,不必要加锁。
-XX:+DoEscapeAnalysis -XX:-EliminateLocks //+DoEscapeAnalysis:开启逃逸分析
-XX:+DoEscapeAnalysis -XX:+EliminateLocks //+EliminateLocks:开启锁消除

















 867
867

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









