







安装logstash
官网下载包,解压
mkdir -p /usr/local/logstash && cd /usr/local/logstash
tar -zxvf logstash-7.6.1.tar.gz
cd logstash-7.6.1
bin/logstash -e 'input { stdin {} } output { stdout {} }'
hello world
出现类似输出安装成功
{
"@version" => "1",
"@timestamp" => 2020-11-25T11:08:42.737Z,
"host" => "104",
"message" => "hello world"
}
安装filebeat
下载包解压即可
mkdir -p /usr/local/filebeat && cd /usr/local/filebeat
tar -zxvf filebeat-7.6.1-linux-x86_64.tar.gz
cd filebeat-7.6.1-linux-x86_64
Logstash配置并启动
在logstash安装目录下新建一个文件first-pipeline.conf
input {
beats {
port => "5044"
}
}
output {
elasticsearch {
# hosts => ["192.168.6.211:9200","192.168.6.212:9201","192.168.6.213:9202"]
hosts => ["192.168.6.210:9200"] #修改为自己的es地址和端口
index => "nginx"
}
}
启动Logstash有两个模式
–config.reload.automatic选项的意思是启用自动配置加载,以至于每次你修改完配置文件以后无需停止然后重启Logstash
cd /usr/local/logstash/logstash-7.6.1
bin/logstash -f first-pipeline.conf --config.reload.automatic
–config.test_and_exit选项的意思是解析配置文件并报告任何错误
cd /usr/local/logstash/logstash-7.6.1
bin/logstash -f first-pipeline.conf --config.test_and_exit
filebeat配置并启动
打开安装目录下 filebeat.yml
filebeat.inputs:
- type: log
enabled: true
paths:
- /var/log/nginx/*.log #修改为自己的文件
output.logstash:
hosts: ["192.168.6.210:5044"] # 修改为自己的logstash的ip和端口
启动filebeat
cd /usr/local/filebeat/filebeat-7.6.1-linux-x86_64
./filebeat -e -c filebeat.yml -d "publish"
kibana查询日志
1.创建一个索引管理
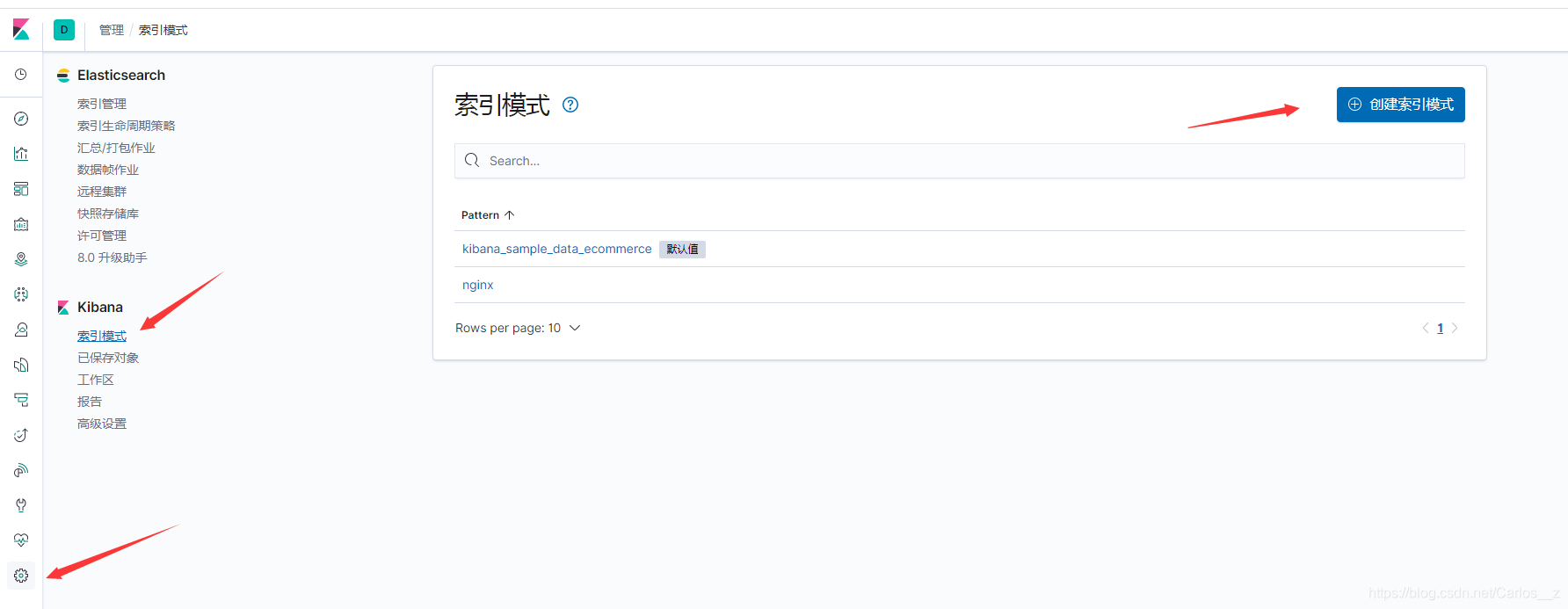
2.选择已有的索引或者配置通配符多个索引
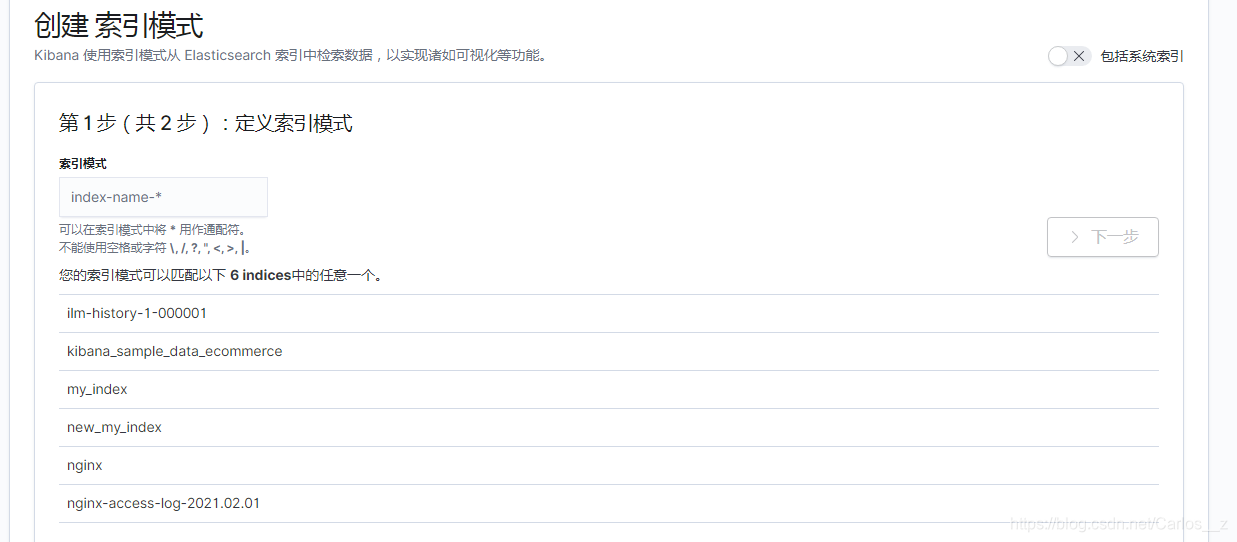
3.建议增加时间筛选的项

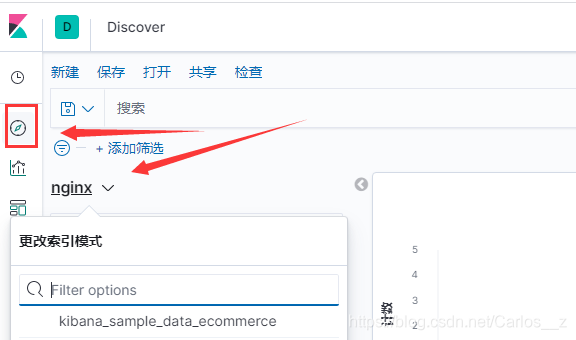
4.创建好索引管理回到表盘,选择刚才的索引
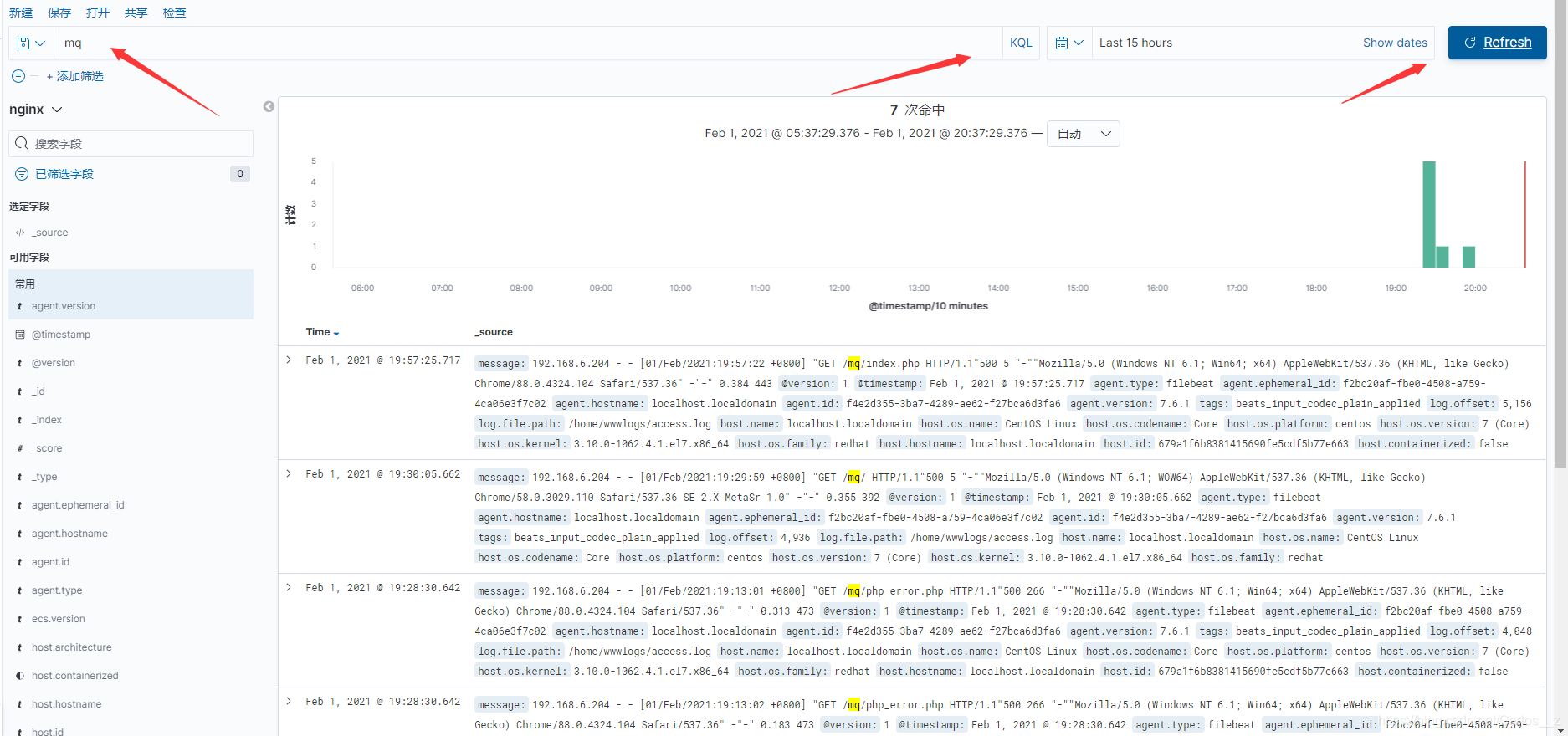
5.最简单的使用,直接搜索想要看的关键词,使用KQL模式
总结
为什么要是用filebeat:
Filebeat和Logstash
ELK架构中使用Logstash收集、解析日志,但是Logstash对内存、cpu、io等资源消耗比较高。相比 Logstash,
Beats所占系统的CPU和内存几乎可以忽略不计。
Filebeat工作原理
Filebeat是使用GO语言开发,工作原理如下:当Filebeat启动时,它会启动一个或者多个prospector监控日志路径或
日志文件,每个日志文件会有一个对应的harvester,harvester按行读取日志内容并转发至后台程序。Filebeat维护
一个记录文件读取信息的注册文件,记录每个harvester最后读取位置的偏移量。
示例中filebeat监听的目录是/var/log/nginx/*.log ,这里是我nginx日志目录,只要访问nginx则会记录一条日志,filebeat自动监听到并发送到logstash再发送到es处理
实际生成应用中,filebeat应在每个需要收集日志的服务器节点安装
在虚拟机操作过程中要注意内存分配,因为filebeat+elk需要大量内存,分配内存不足会出现很多错误。














 1892
1892











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









