







- 程序运行时需要从本地磁盘加载到内存中。
- 每次从磁盘加载到内存都可以看做是一次I/O操作,而这种I/O操作是很耗费时间和性能的。
- 因此MySQL在设计索引时考量的重点是哪种数据结构查找快并且I/O读写次数尽可能少。
答案是树,一个典型的查找树就是平衡二叉树!
平衡二叉树
特点:
- 必须是“二叉的排序树”
- 其次每个节点的左子树和右子树高度差最多为1

B树
上面使用的二叉平衡树的确大大减少了查找次数,但生活中“秒”级别的查找是不够的,让用户等20-30s很可能用户会“裂开”。要想提高检索的速度不光要“缩小查找的范围”,还要“减少I/O读写”。
所以出现了B树这个多叉查找树!多叉也叫多“阶”,指的是一个树能拥有的最大节点树。
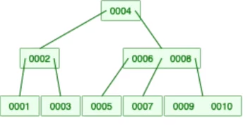
特点:
- 根节点至少有2个叶子节点
- 每个节点可以包含多个元素,根节点最多可以有“阶数-1”个元素
- 其他节点最少有“阶数/2(向上取整)再减去1”个元素,最多有“阶树/2(向上取整)”个元素
B+树
二叉就表示最多只能把I/O读写次数减半,既然二叉解决不了问题,多叉、每个叶子节点可以存多个数据不就好了?这样是不是让I/O读写次数在减半的基础上又减少了呢?
但当数据量非常大的时候,B树的性能还可以提的更高,因此B+树出现了,B+树也正是MySQL所使用的索引结构
B+树在B树的基础上,提高了查找性能,

特点:
- B+树的所有非叶子节点只存索引
- B+树的叶子节点包含所有的索引值,并且指向数据
- B+树的所有叶子节点相连
在数据量小的时候,B+树的I/O次数并不一定比B树少。但是由于B+树把所有数据都放到了一排并增加了指针,实现了顺序查找,因此效率比B树更高。
B树和B+树的区别就在于:
B+树的叶子节点增加了索引值,提高了查找效率















 3470
3470











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









