







一、概述
public class LinkedHashMap<K,V>
extends HashMap<K,V>
implements Map<K,V>
它是一个将所有Entry节点链入一个双向链表的HashMap。
HashMap是无序的,也就是说,迭代HashMap所得到的元素顺序并不是它们最初放置到HashMap的顺序。HashMap的这一缺点往往会造成诸多不便,因为在有些场景中,我们确需要用到一个可以保持插入顺序的Map。
与HashMap基本类似,只是在细节实现上稍有不同。因为它额外维护了一个双向链表用于保持迭代顺序。所以,LinkedHashMap可以很好的支持LRU算法。
特别地,该迭代顺序可以是插入顺序,也可以是访问顺序。因此,根据链表中元素的顺序可以将LinkedHashMap分为:保持插入顺序的LinkedHashMap 和 保持访问顺序的LinkedHashMap,其中LinkedHashMap的默认实现是按插入顺序排序的。
HashMap:
双向链表:

结合:
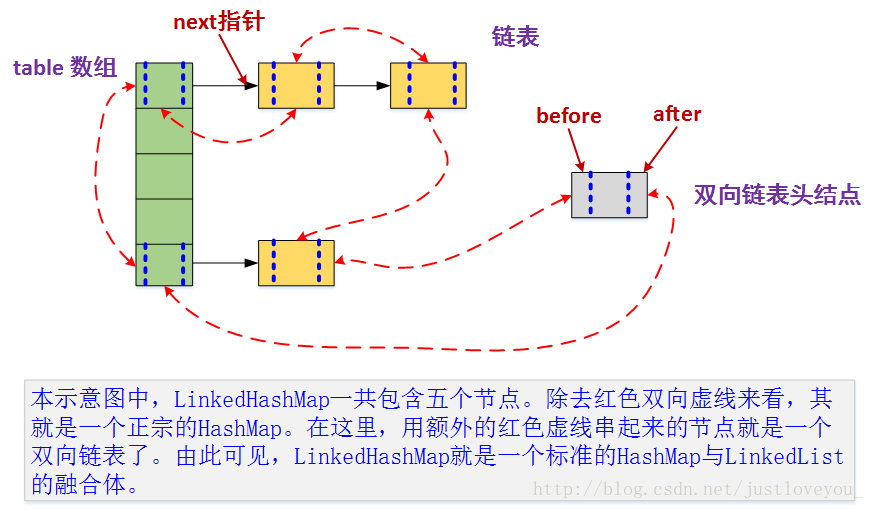
HashMap与LinkedHashMap的Entry结构示意图如下图所示:
由于LinkedHashMap是HashMap的子类,所以LinkedHashMap自然会拥有HashMap的所有特性。比如,LinkedHashMap也最多只允许一条Entry的键为Null(多条会覆盖),但允许多条Entry的值为Null。此外,LinkedHashMap 也是 Map 的一个非同步的实现。
二、JDK 中的定义
public class LinkedHashMap<K,V>
extends HashMap<K,V>
implements Map<K,V>
{......}
1、成员变量定义
与HashMap相比,LinkedHashMap增加了两个属性用于保证迭代顺序,分别是 双向链表头结点header 和 标志位accessOrder (值为true时,表示按照访问顺序迭代;值为false时,表示按照插入顺序迭代)。默认插入顺序

/**
* The head of the doubly linked list.
*/
private transient Entry<K,V> header; // 双向链表的表头元素
/**
* The iteration ordering method for this linked hash map: <tt>true</tt>
* for access-order, <tt>false</tt> for insertion-order.
*
* @serial
*/
private final boolean accessOrder; //true表示按照访问顺序迭代,false时表示按照插入顺序
2、方法成员的定义
从下图我们可以看出,LinkedHashMap中并增加没有额外方法。也就是说,LinkedHashMap与HashMap在操作上大致相同,只是在实现细节上略有不同罢了。

3、LinkedHashMapEntry
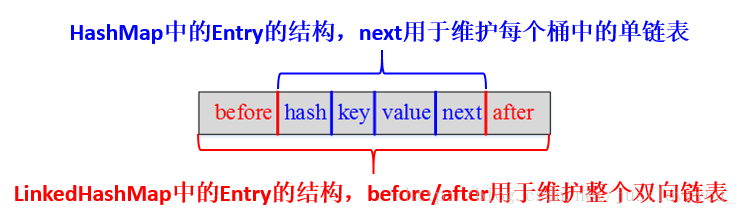
LinkedHashMap中的Entry增加了两个指针 before 和 after,它们分别用于维护双向链接列表。特别需要注意的是,next用于维护HashMap各个桶中Entry的连接顺序,before、after用于维护Entry插入的先后顺序的.
/**
* LinkedHashMap entry.
*/
private static class LinkedHashMapEntry<K,V> extends HashMapEntry<K,V> {
// These fields comprise the doubly linked list used for iteration.
LinkedHashMapEntry<K,V> before, after;
LinkedHashMapEntry(int hash, K key, V value, HashMapEntry<K,V> next) {
super(hash, key, value, next);
}
...}三、LinkedHashMap 与 LRU(Least recently used,最近最少使用)算法
1、LinkedHashMap区别于HashMap最大的一个不同点是,前者是有序的,而后者是无序的。为此,LinkedHashMap增加了两个属性用于保证顺序,分别是双向链表头结点header和标志位accessOrder。
header是LinkedHashMap所维护的双向链表的头结点,而accessOrder用于决定具体的迭代顺序。
2、put操作与标志位accessOrder
当要put进来的Entry的key在哈希表中已经在存在时,会调用Entry的recordAccess方法;当该key不存在时,则会调用addEntry方法将新的Entry插入到对应桶的单链表的头部
/**
* This method is invoked by the superclass whenever the value
* of a pre-existing entry is read by Map.get or modified by Map.set.
* If the enclosing Map is access-ordered, it moves the entry
* to the end of the list; otherwise, it does nothing.
*/
void recordAccess(HashMap<K,V> m) {
LinkedHashMap<K,V> lm = (LinkedHashMap<K,V>)m;
//如果链表中元素按照访问顺序排序,则将当前访问的Entry移到双向循环链表的尾部,
//如果是按照插入的先后顺序排序,则不做任何事情。
if (lm.accessOrder) {
lm.modCount++;
//移除当前访问的Entry
remove();
//将当前访问的Entry插入到链表的尾部
addBefore(lm.header);
}
}
当accessOrder为true时,get方法和put方法都会调用recordAccess方法使得最近使用的Entry移到双向链表的末尾。
3、get操作与标志位accessOrder
在LinkedHashMap中进行读取操作时,一样也会调用recordAccess方法。
public V get(Object key) {
// 根据key获取对应的Entry,若没有这样的Entry,则返回null
Entry<K,V> e = (Entry<K,V>)getEntry(key);
if (e == null) // 若不存在这样的Entry,直接返回
return null;
e.recordAccess(this);
return e.value;
}
LinkedListMap与LRU小结:
使用LinkedHashMap实现LRU的必要前提是将accessOrder标志位设为true以便开启按访问顺序排序的模式。我们可以看到,无论是put方法还是get方法,都会导致目标Entry成为最近访问的Entry,因此就把该Entry加入到了双向链表的末尾:get方法通过调用recordAccess方法来实现;put方法在覆盖已有key的情况下,也是通过调用recordAccess方法来实现,在插入新的Entry时,则是通过createEntry中的addBefore方法来实现。这样,我们便把最近使用的Entry放入到了双向链表的后面。多次操作后,双向链表前面的Entry便是最近没有使用的,这样当节点个数满的时候,删除最前面的Entry(head后面的那个Entry)即可,因为它就是最近最少使用的Entry。
---------------------
四、 使用LinkedHashMap实现LRU算法
如下所示,笔者使用LinkedHashMap实现一个符合LRU算法的数据结构,该结构最多可以缓存6个元素,但元素多余六个时,会自动删除最近最久没有被使用的元素,如下所示:
public class LRU<K,V> extends LinkedHashMap<K, V> implements Map<K, V>{
private static final long serialVersionUID = 1L;
public LRU(int initialCapacity,
float loadFactor,
boolean accessOrder) {
super(initialCapacity, loadFactor, accessOrder);
}
/**
* @description 重写LinkedHashMap中的removeEldestEntry方法,当LRU中元素多余6个时,
* 删除最不经常使用的元素
* @author rico
* @created 2017年5月12日 上午11:32:51
* @param eldest
* @return
* @see java.util.LinkedHashMap#removeEldestEntry(java.util.Map.Entry)
*/
@Override
protected boolean removeEldestEntry(java.util.Map.Entry<K, V> eldest) {
// TODO Auto-generated method stub
if(size() > 6){
return true;
}
return false;
}
public static void main(String[] args) {
LRU<Character, Integer> lru = new LRU<Character, Integer>(
16, 0.75f, true);
String s = "abcdefghijkl";
for (int i = 0; i < s.length(); i++) {
lru.put(s.charAt(i), i);
}
System.out.println("LRU中key为h的Entry的值为: " + lru.get('h'));
System.out.println("LRU的大小 :" + lru.size());
System.out.println("LRU :" + lru);
}
}
下图是程序的运行结果:

五、有序性原理分析
LinkedHashMap 增加了双向链表头结点header 和 标志位accessOrder两个属性用于保证迭代顺序。但是要想真正实现其有序性,还差临门一脚,那就是重写HashMap 的迭代器,其源码实现如下:
private abstract class LinkedHashIterator<T> implements Iterator<T> {
Entry<K,V> nextEntry = header.after;
Entry<K,V> lastReturned = null;
/**
* The modCount value that the iterator believes that the backing
* List should have. If this expectation is violated, the iterator
* has detected concurrent modification.
*/
int expectedModCount = modCount;
public boolean hasNext() { // 根据双向列表判断
return nextEntry != header;
}
public void remove() {
if (lastReturned == null)
throw new IllegalStateException();
if (modCount != expectedModCount)
throw new ConcurrentModificationException();
LinkedHashMap.this.remove(lastReturned.key);
lastReturned = null;
expectedModCount = modCount;
}
Entry<K,V> nextEntry() { // 迭代输出双向链表各节点
if (modCount != expectedModCount)
throw new ConcurrentModificationException();
if (nextEntry == header)
throw new NoSuchElementException();
Entry<K,V> e = lastReturned = nextEntry;
nextEntry = e.after;
return e;
}
}
// Key 迭代器,KeySet
private class KeyIterator extends LinkedHashIterator<K> {
public K next() { return nextEntry().getKey(); }
}
// Value 迭代器,Values(Collection)
private class ValueIterator extends LinkedHashIterator<V> {
public V next() { return nextEntry().value; }
}
// Entry 迭代器,EntrySet
private class EntryIterator extends LinkedHashIterator<Map.Entry<K,V>> {
public Map.Entry<K,V> next() { return nextEntry(); }
}从上述代码中我们可以知道,LinkedHashMap重写了HashMap 的迭代器,它使用其维护的双向链表进行迭代输出。
参考:https://blog.csdn.net/justloveyou_/article/details/71713781














 2186
2186











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









