






这里以大学为例,使用Python:
首先,导入数据,导入大众点评中爬取到的汉堡店数据,为了节省时间,选择前200个店铺:
df = pd.read_excel('df_new1.xlsx')
df_200 = df.iloc[:200, :]
df_200.head()数据长这个样子:
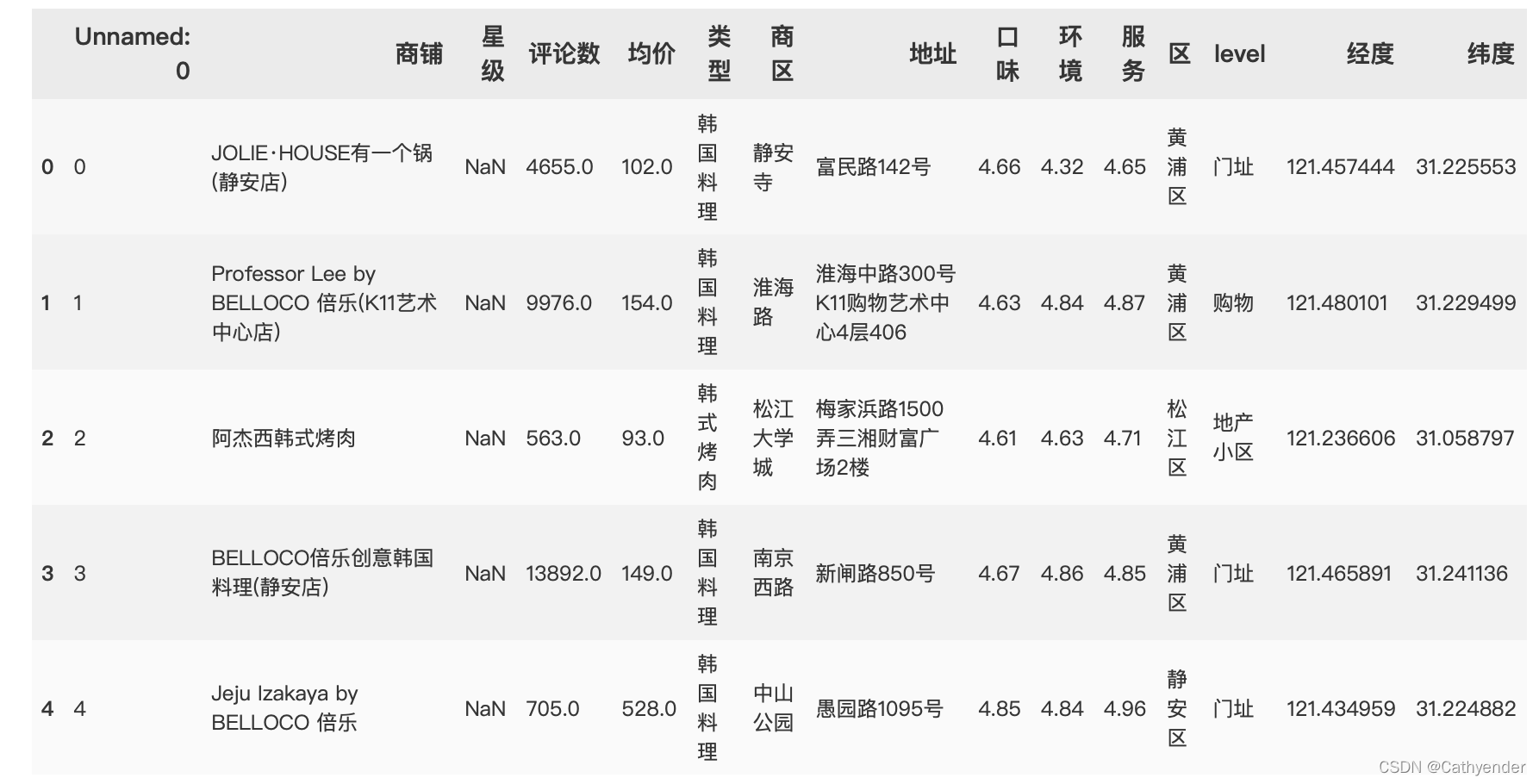
接着,利用百度api爬取周边5km以内的大学信息:
lat_partion=df_200["纬度"] #纬度
lng_partion=df_200["经度"] #经度
store=df_200["商铺"] #门店
targets=[] #用来存要查找的名称
addresss=[] #用来存放地址
stores=[] #用来存放项目名称
distances=[] #用来存放距离
def get_directory(keyword,radius): #定义圆形区域检索函数
for i in range(len(lat_partion)):
location=str(lat_partion[i])+","+ str(lng_partion[i]) #构造圆中心点的经纬度
#print(location) #测试
for j in range(5):
try:
url="http://api.map.baidu.com/place/v2/search?query="+keyword+"&page_size=20&page_num="+str(j)+"&location="+location+"&radius="+str(radius)+"&output=json&ak=KhqCA5dKbqViVotuUFlDDbzxtuMPXnE3&scope=2"#构造请求网址
print(url) #测试请求接口拼接是否正确,此url可以直接复制到浏览器查看返回结果
response=requests.get(url) #发出请求
answer=response.json() #返回结果json化
#print(answer) #测试
print("一共%s条数据"%len(answer['results']))
for k in range(len(answer['results'])):
target=answer['results'][k]['name'] #标的物名称
address=answer['results'][k]['address'] #地址
distance=answer['results'][k]['detail_info']['distance'] #距离
targets.append(target)
addresss.append(address)
stores.append(store[i])
distances.append(distance)
print(target,distance,address)
except:
print("the circle contains no message")
stores.append(store[i])
targets.append("")
distances.append("")
addresss.append("")
if __name__=='__main__':
keyword=input("please input the keywords:") #输入poi的关键词
radius=input("please input the radius:") #输入半径
get_directory(keyword,radius) #调用函数get_directory
dict={"商铺":stores,"标的物":targets,"距离":distances,"地址":addresss} #构造字典
res=pd.DataFrame(dict)
res.head()其中,input输入的keyword为大学,radius为5000(注意:单位是米!!!),j代表所翻的页数,由于发现所有汉堡店附近的大学信息没有超过5页的,这里取0-4页。注意:url中的j一定要是str的格式,不然不显示信息噢~(别问我是怎么知道的)
接着查看数据:
res.head(50)那么我们就可以得到(截取部分):
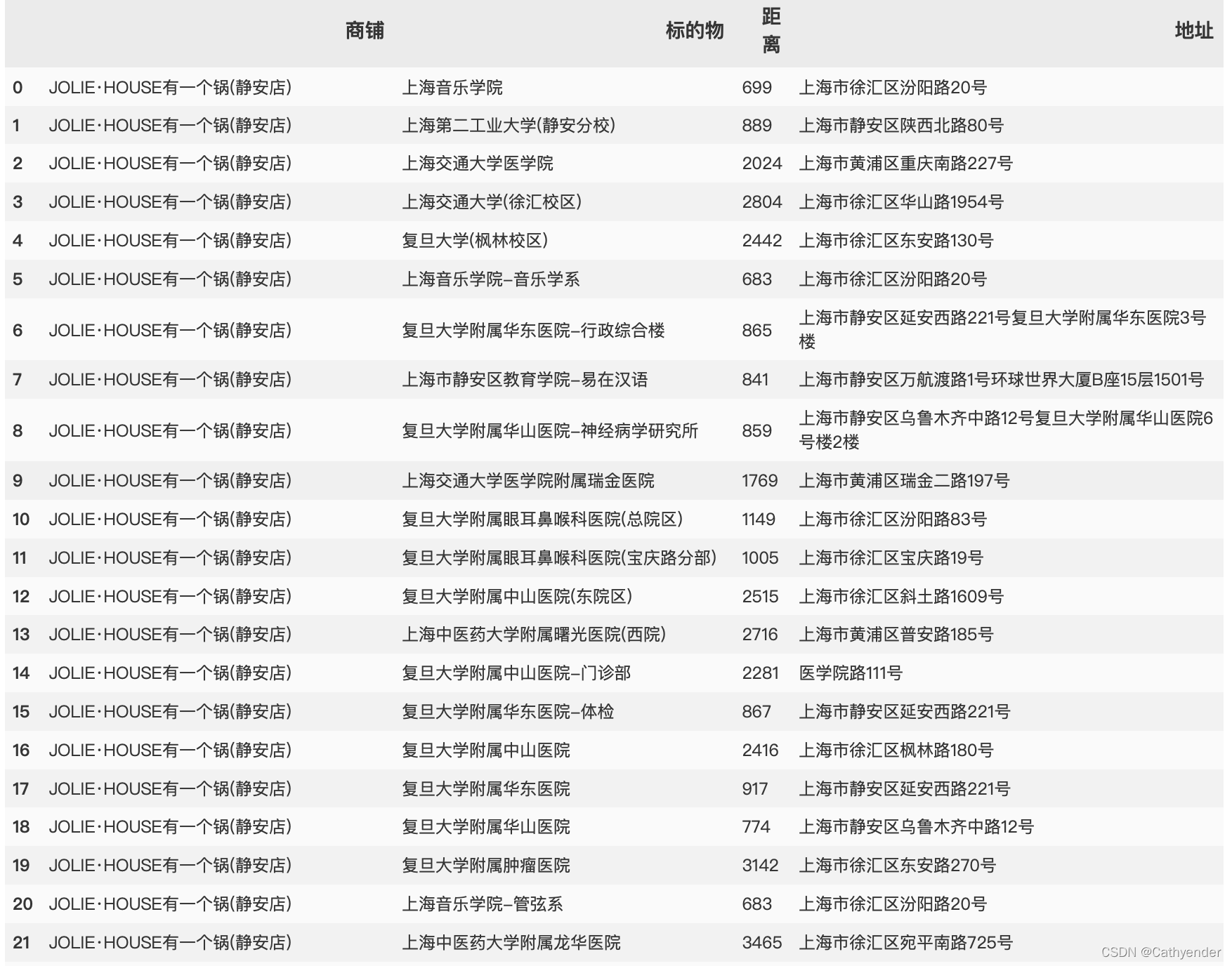
发现很多标的物其实不是大学或者是冗余信息,因此考虑将带有“系”和“医院”的数据条删除:
extra1 = res[res['标的物'].str.contains('系')]
extra2 = res[res['标的物'].str.contains('医院')]
res = res.drop(extra1.index)
res = res.drop(extra2.index)接着,我们进行groupby,计算周围5km的学校个数:
group = (res.groupby(['商铺'])['标的物']
.nunique()
.reset_index())
group = group.rename(columns = {'标的物':'周围5km大学数'})
df_200_new = pd.merge(df_200, group, on=['商铺'], how = 'left')
df_200_new['周围5km大学数'].fillna(0, inplace = True)
df_200_new.head()就可以得到结果啦~



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









