




技术行业的基准测试颇为耐人寻味。某些测试似乎专为赢家向同行和媒体炫耀而设计——如同直线加速赛,胜负仅取决于400米直线冲刺的极速。这类测试固然精彩,却纸上谈兵,毕竟现实中没人会沿着一条笔直、平坦、空旷的道路,从家门口到便利店恰好只需冲刺400米。
对AI和基础设施架构师真正有价值的基准测试,是那些模拟真实工作负载的评估:既需高速公路巡航的稳定性,也要应对城区低速场景的灵活性,甚至涵盖拖挂重载的极端工况。正因如此,我们推崇MLCommons® MLPerf存储基准测试套件,并积极参与其扩展与优化工作。MLPerf存储基准通过模拟多样化的真实AI/ML工作负载,为企业在评估AI存储架构时提供关键数据参考点。
接下来我们将解析测试结果,并深入探讨其实现原理与技术价值。
本轮测试采用模拟H100 GPU环境运行了3D U-Net基准测试。
注:历史提交记录及其他测试配置详见此处文章。
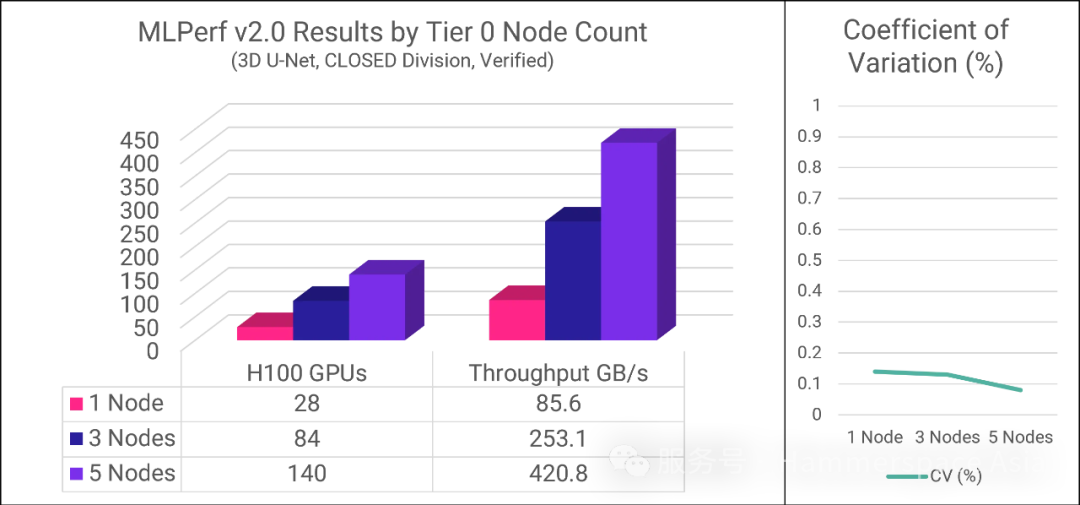
3D UNet模拟了医学图像分割的实际工作负载,是MLPerf存储基准测试中带宽密集度最高的用例,重点考核存储系统的并行I/O吞吐能力、内存及CPU效率。测试采用三种配置方案,分别部署1个、3个和5个Tier 0节点,核心结果详见下表及图示:
| Tier 0 节点数量 | 支持的H100 GPU数量 | 总吞吐量 | GPU的 平均利用率 | 变异系数 |
|---|---|---|---|---|
| 1 | 28 | 85.6 GB/s | 94.7% | 0.14% |
| 3 | 84 | 253.1 GB/s | 95.0% | 0.13% |
| 5 | 140 | 420.8 GB/s | 96.4% | 0.08% |
可扩展性验证
我们观察到,随着 Tier 0 节点数量的增加,系统支持的 GPU 数量和总吞吐量均呈线性增长。这充分证明了在最佳场景(主数据集可100% 驻留本地)下的架构潜力。随着集群规模扩大,峰值性能将取决于系统配置及本地驻留数据比例,但聚合性能将持续扩展——这将是性能测试团队后续重点探索的方向。
GPU 利用率的核心意义
平均 GPU 利用率(AU)反映 GPU 处于计算状态与等待状态的时间占比。为通过 MLPerf 存储基准测试,所有 GPU 的利用率必须≥90%。该数值越高越好,核心目标是最小化 GPU 闲置时间。
系统稳定性量化指标
系数变异(CV)用于衡量多次运行同一测试的结果离散度。MLPerf 存储基准要求每项测试必须重复执行,且结果需在极小范围内波动,以此确保结果的可复现性。Hammerspace 测试结果的极低 CV 值(≤0.14%)表明系统性能具备高度稳定性与可预测性。
竞品横向对比——简效性定成败
为确保对比的公平性与有效性,以下分析仅涵盖采用本地共享文件配置完成 3D U-Net H100 测试的厂商。下图展示各厂商提交的最高 GPU 支持量结果:
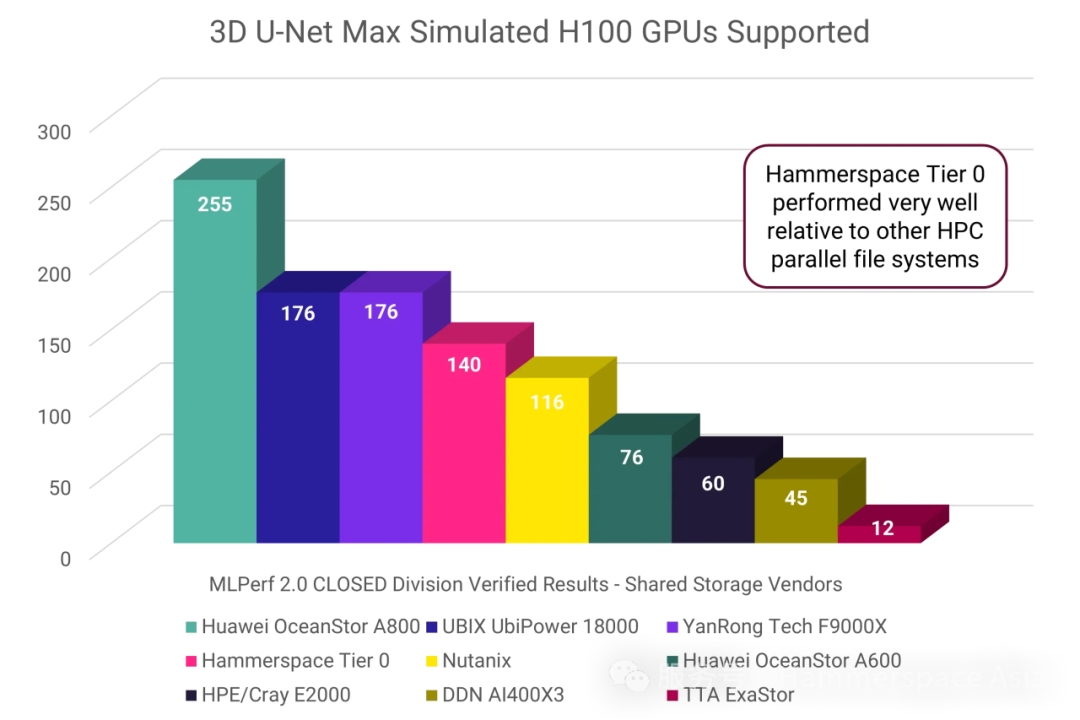
如数据所示,Hammerspace Tier 0 架构在此次测试中表现卓越,性能超越多数知名厂商。然而,若切换至能效视角分析,其技术价值将更具启示性——
当前全球数据中心普遍面临电力供给、散热能力与机柜空间的三重瓶颈。伴随高功耗 GPU 服务器在 AI 领域的规模化部署,此矛盾进一步激化。需明确:每瓦特电力若消耗于存储基础设施,即意味着 GPU 算力的等量削减。简言之,能效即核心竞争力。
尽管 MLPerf 存储测试未强制要求提交实际功耗数据,我们可引入 “机柜单元(U)” 作为间接能效指标——其核心假设为:解决方案占用的机柜空间(U)与功耗呈正相关。
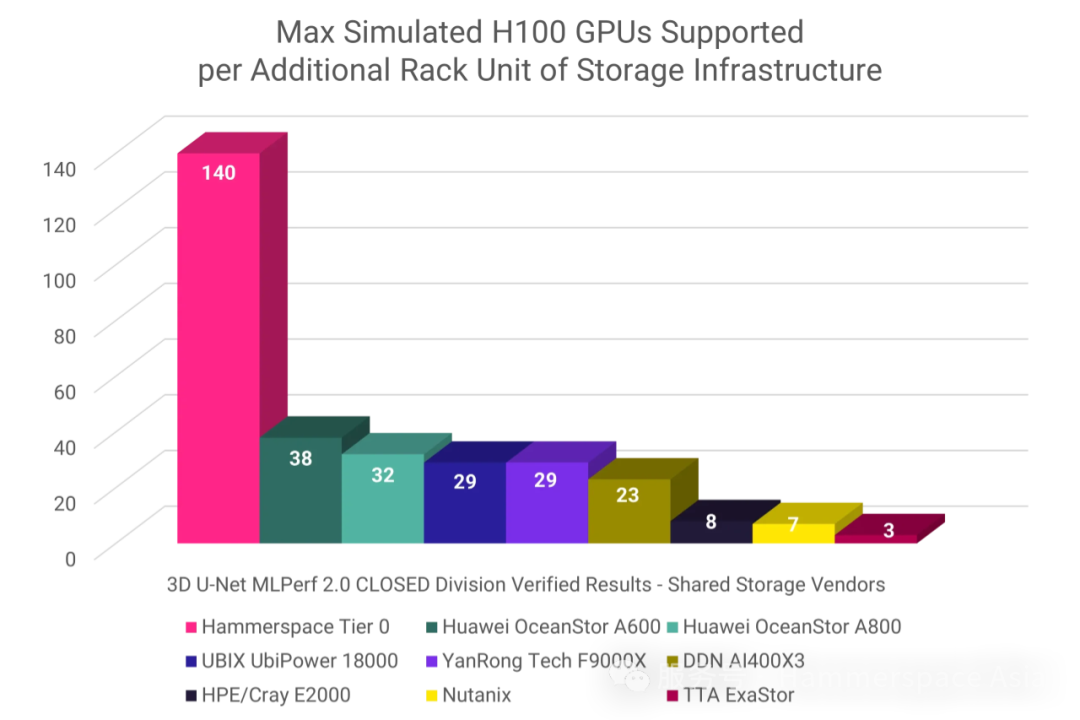
能效优势量化分析
以每机柜单元(U)存储基础设施支持的GPU数量为衡量标准,Hammerspace Tier 0 展现出绝对领先优势——其数值达次优方案的 3.7倍,真正实现了“一骑绝尘” 。
关键概念说明
GPU服务器角色:实际生产环境中运行AI工作负载的主体(基准测试中体现为客户端节点)
“额外机柜单元”定义:存储解决方案超出计算服务器/基准客户端本体所占用的物理空间(不含GPU服务器本身)
硬件精简的架构本质
Tier 0 通过聚合集群内GPU服务器的本地NVMe存储资源,仅需额外部署1台 1U元数据服务器(即Anvil) 即可构建完整存储架构。实际生产环境通常采用双Anvil高可用配置,即便如此,Hammerspace仍能保持 85%的能效优势(相较次优方案)
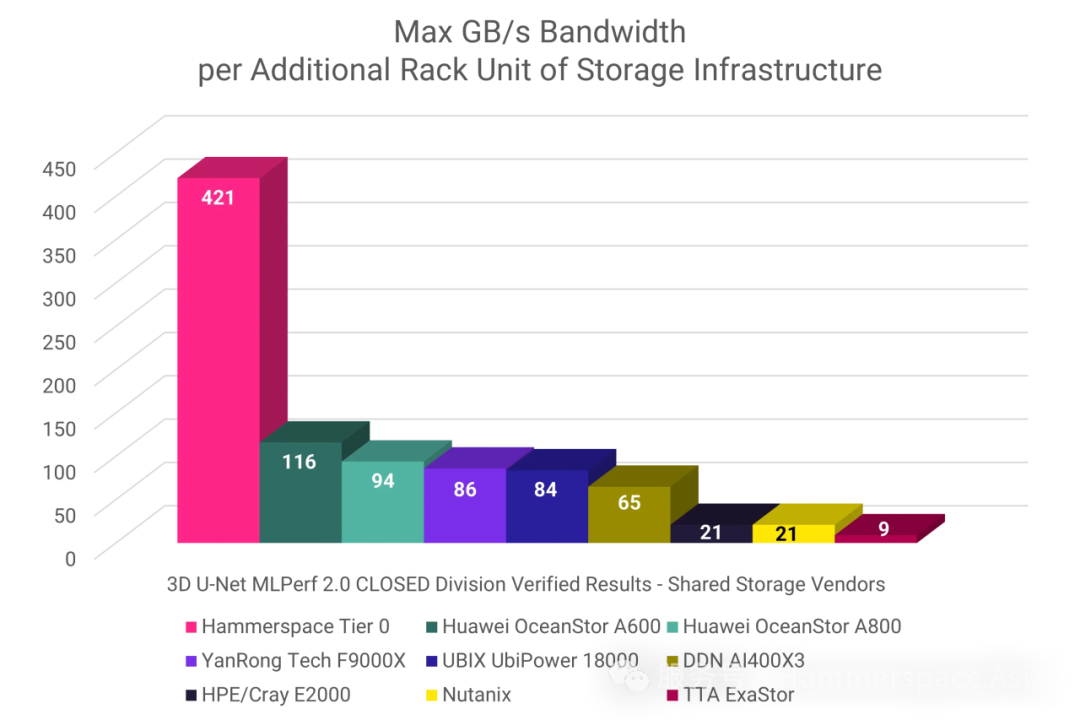
带宽能效的同等突破
在每U存储基础设施提供的最大GB/s带宽指标中,Hammerspace Tier 0 同样展现出 3.7倍于次优方案的统治级表现,印证其技术范式的全面领先。
架构配置与技术解析
测试架构示意图说明
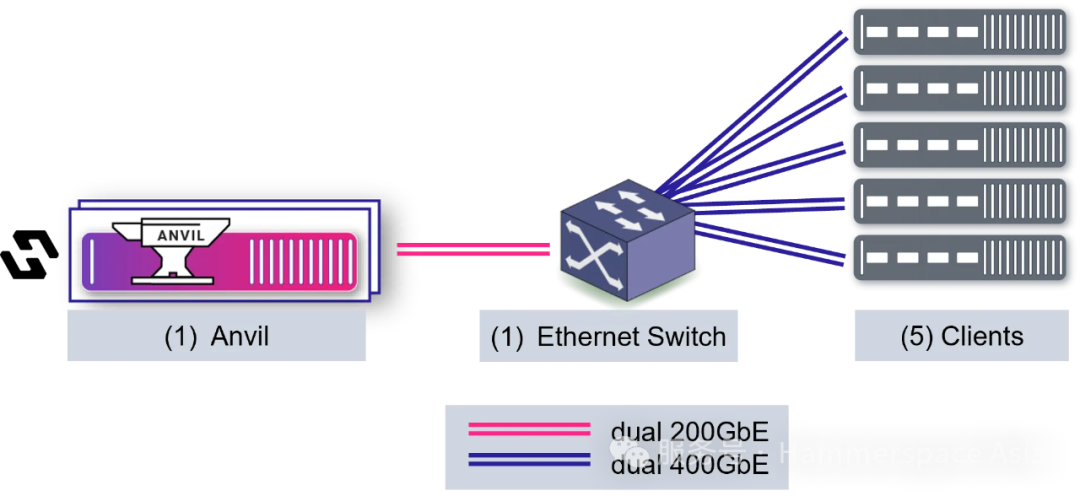
客户端运行基准测试代码。在 Tier 0 架构中,客户端同时承载 NVMe 存储设备——本次测试中每客户端配置 10 块 ScaleFlux CSD5000 硬盘。元数据服务器 Anvil 仅负责元数据操作与集群协调任务,数据流完全不流经该节点。客户端通过 并行 NFS (pNFS) v4.2 挂载共享文件系统,通过 Anvil 获取布局后直接访问存储设备。
基准测试的特殊性说明
当前测试范围具有限定性设计。实际生产环境中,Tier 0 仅是 Hammerspace 多层次持久化存储架构中的一环——该架构通常还包含网络直连的 Tier 1 NVMe 存储、对象存储层等,并支持跨多云站点部署。
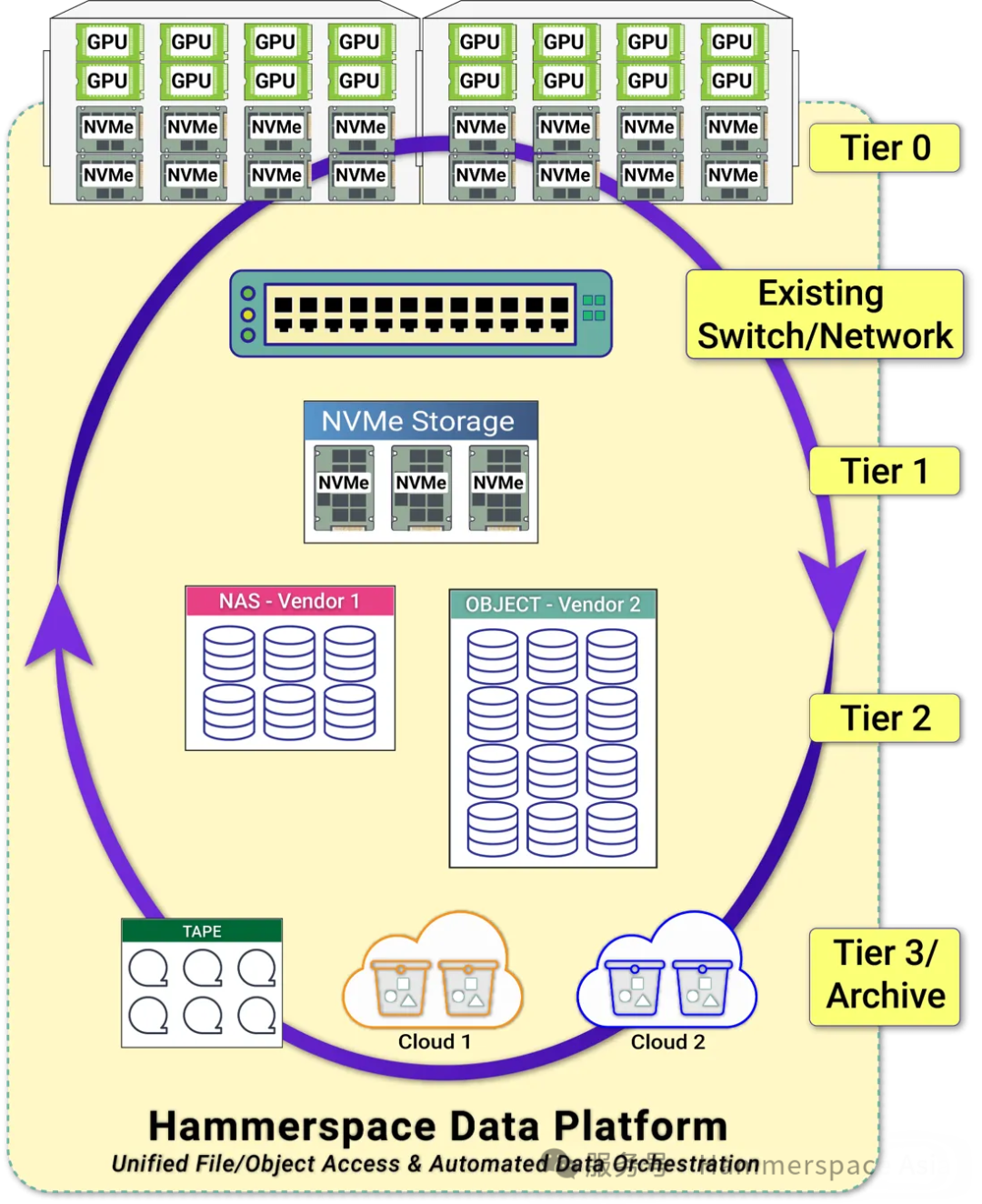
Tier 0 的企业级 AI 核心价值
当企业启动 AI 计划时,初始成本与数据治理构成双重挑战:需同时购置计算/存储资源,并对跨部门海量数据进行清洗与组织。任何能简化启动流程的技术都具有战略意义——正因如此,Hammerspace 在 MLPerf v2.0 中聚焦 Tier 0 方案的落地实现。
技术突破点
闲置资源激活:将 GPU 服务器集群中已有的 NVMe 存储纳入全局命名空间,构建高性能共享存储池
智能数据治理:通过 Hammerspace 数据编排引擎实现自动化数据放置与保护
混合云适配性:支持在云端以租赁模式替代硬件采购,优化 TCO(总拥有成本)
数据预处理革新
免迁移数据接入:通过元数据就地同化的能力,直接接入现有 NAS 卷而无需复制原始数据
动态资源调配:识别关键数据后,可将其即时编排至 Tier 0 高性能层进行处理
智能价值分层:处理结果自动归档至低成本存储层,实现全生命周期管理
Tier 0 的三大企业级收益
⚡️ 极简部署
零改造启动:直接复用现有存储与网络基础设施
无代理架构:无需安装客户端代理软件
协议普适性:标准以太网即可满足需求,无需专用网络
🚀 性能跃升
速度碾压:存储性能达传统网络存储方案的 10 倍速
全场景加速:本地与云端同步实现性能突破
GPU 效率革命:
训练场景:检查点时间缩短 → GPU 利用率提升 40%+
推理场景:毫秒级延迟归零 → 用户体验质变
🌱 能效重构
硬件精简:减少外部共享存储设备依赖
绿色计算:节省电力 35%+、机柜空间 50%+(相较传统 SAN)
敏捷上线:小时级激活 Tier 0 存储层,价值实现周期从周级压缩至天级
技术演进与生态参与
Hammerspace 深度参与 MLCommons® 组织的 MLPerf 存储基准测试项目,当前成果仅是起点。我们已实现进一步架构优化(后续将推出相关技术白皮书,敬请期待),持续推动存储性能边界。如您期望了解更多 Tier 0 的技术细节,请访问 Hammerspace.com。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









