







本篇日志记录于 2024.4.16
项目目标
通过网络爬虫,从公司官网、招聘平台、社交媒体、经验分享社群等多个媒介,收集求职相关数据,利用大模型将公司及岗位、面试题目及流程、经验分享等信息进行整合。
主要的内容包括:公司及岗位的关键信息,包括公司介绍、文化氛围、业务范围等详细描述;根据网络信息总结出来的面试题;面试者的经验分享及流程。
任务分析
任务的重点在于对多源信息进行集成,集成手段依赖于大语言模型的总结、推理能力。
学习数据信息的方式:
- 将数据作为prompt的上下文:我们的数据量会很大,而提示词对长度有限制
- 将数据作为训练数据来微调(使其学习到求职相关的语义):构建训练数据集以及微调参数需要很大的工作量与计算量,现有计算资源不支持
- 利用索引增强技术(RAG)将数据构建成知识库:目前最合理的方案
技术路线
阅读与RAG技术相关的文章,发现最基础的是要部署好大模型,所以当前首要目标是部署模型。
2024.4.28 日上传 阿里云部署教程。
LangChain
在Langchain中调用LLM接口的两种情况
- 官方提供的API调用接口:调用方便,但是只能免费调用一定额度,之后都要收费
- 自助托管开源模型:在本地或云端服务器上部署开源大模型,好处在于免费,但是部署起来相对麻烦、且对硬件资源有要求,通常可以在HuggingFace和魔搭中下载
Langchain-Chatchat
项目介绍
基于ChatGLM等大语言模型与Langchain等应用框架,所实现的开源、可离线部署的RAG项目
github:https://github.com/chatchat-space/Langchain-Chatchat
项目中默认使用大语言模型是 THUDM/ChatGLM3-6B ,Embedding模型是 BAAI/bge-large-zh
- 中文开源大语言模型chatglm
- 官方提供的技术文档:https://zhipu-ai.feishu.cn/wiki/WvQbwIJ9tiPAxGk8ywDck6yfnof
- github:https://github.com/THUDM/ChatGLM3
- HuggingFace:https://huggingface.co/THUDM/chatglm3-6b
- ModelScope:https://modelscope.cn/models/ZhipuAI/chatglm3-6b/summary
- bge提供RAG领域会用到的模型
使用步骤
- 部署此框架
- 下载llm和embedding模型到本地
- 初始化知识库
- 启动项目
使用分析
好处
- 现成的框架,较为成熟,已经经过一定的优化
- 功能齐全且提供对外调用的接口,我们在自己的项目中调用其api即可
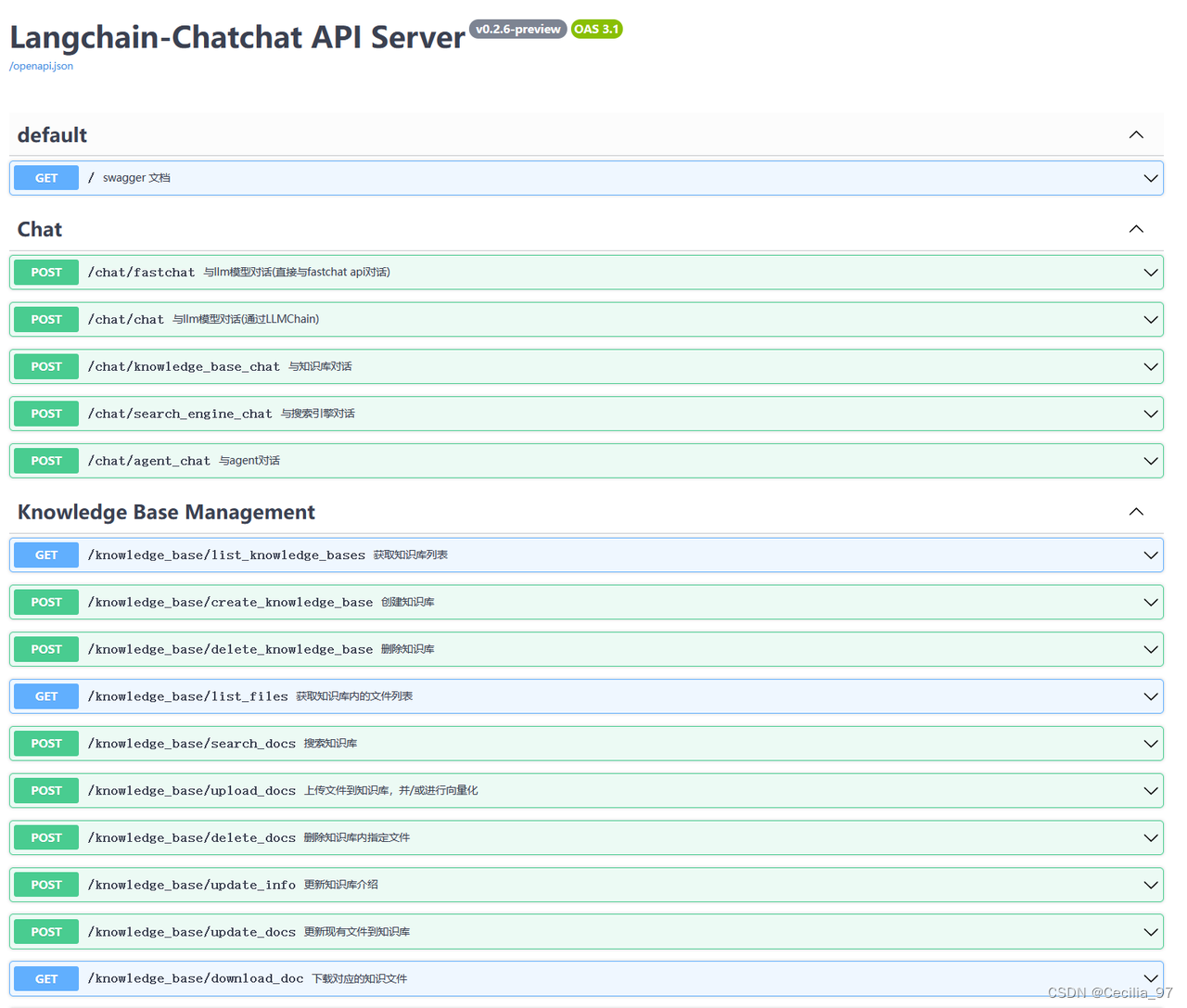
坏处 - 需要部署框架需要的环境
- 或许远超于我们的功能需求
选择策略:部署并使用好此框架的成本 (比较两者) 学习langchain自己写好完整代码的成本
Transformers
huggingface下的一个一个机器学习框架,可以进行nlp、cv、多模态等方向的任务,目前大部分的预训练模型都会上传到huggingface上,这个框架下也支持RAG
https://huggingface.co/docs/transformers/model_doc/rag


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









