







聚类
使用先前文章中提到的层次聚类算法,以句子问单位进行分类,得到聚类结果。
- 在聚类之前先分句,做初步清理
company_list = ['华为','美团','腾讯','小米','字节']
for company in company_list:
with open (f"data_experience/{company}_interview.json", 'r',
encoding='utf-8') as f:
interviews = json.load(f)
ques = []
for blog in interviews:
sen = blog['content'].strip().split('\n')
for s in sen:
s = s.replace("'", "")
sen = re.sub(r'\d+[\.\,:\;\!?\s\、\。\:]*', '', s)
sen = sen.strip()
if str_count(sen) > 20 or sen == "" or str_count(sen) < 5:
continue
else:
ques.append(sen)
依据\n和.进行分局,过滤无关信息,例如特殊字符和开头的数字,过滤长度过长或过短的句子
- 针对清理结果,使用上一文章中提到的层次聚类进行聚类。
聚类结果比较精确,一个簇中的句子都比较相似

- 遍历所有公司,得到我们以公司为单位的,面试中的问题集合

问题总结
在前一个步骤的基础上,依据面试问题的知识点进行润色与总结
提示词如下
下面是一个由句子组成的数组,用双引号围住,句子来源于一些面试者提供的面试信息。
请你根据其内容去掉与面问题无关内容,总结出面试中可以提出的问题。具体满足的要求如下:
1. 问题必须是问句,
2. 问题内容简洁、易于理解
3. 问题内容符合你的面试官身份
4. 不可以原文输出
请你以json格式进行输出,key为"问题",value为你总结问题所组成的list
"
{cluster}
"
system = {
“role”: “system”,
“content”: “你是一名计算机岗位的面试官”,
}
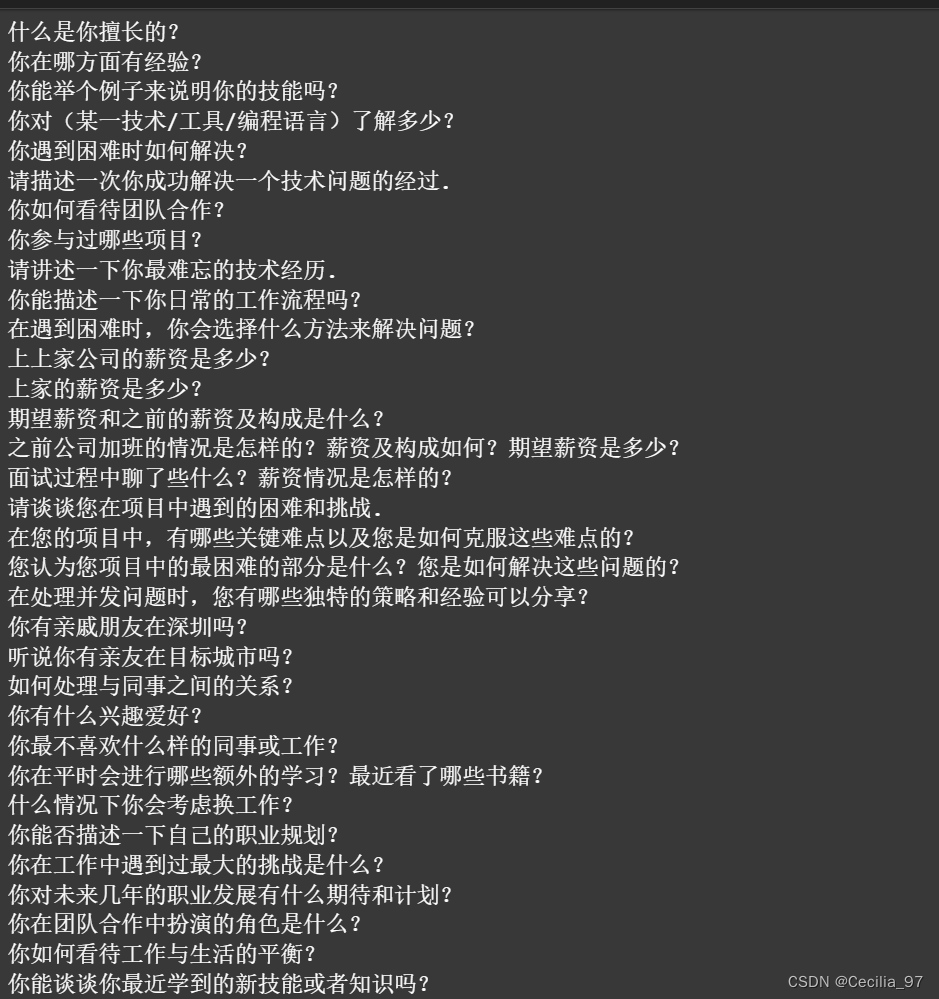
结果:总结到了很多与技术无关的面试问题

















 2996
2996

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









