







下面为我绘制的知识库数据处理流程
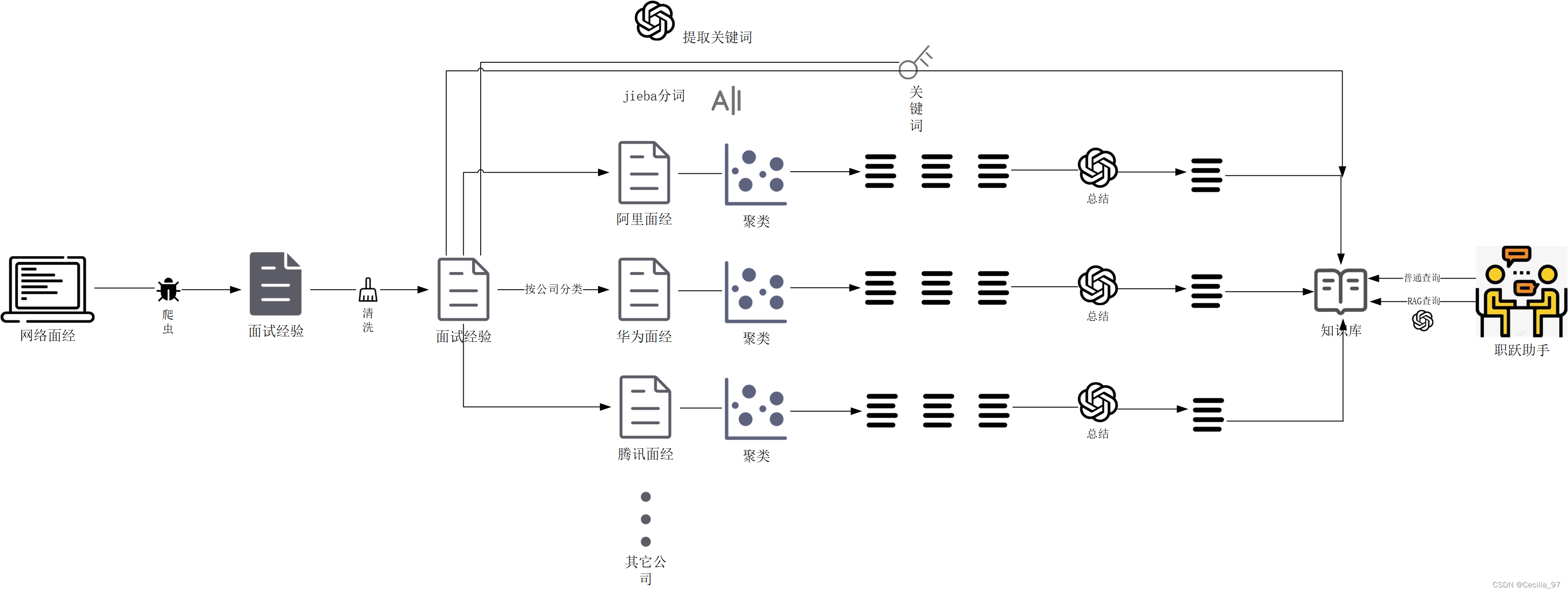
- 通过爬虫,获取网络上的由网友提供的各大公司面试经验信息以及各大公司对于岗位的介绍与要求
- 对网络上充满噪音的数据进行清洗
- 包括:删去非法符号、广告内容、重复内容、过短内容
- 清洗后按照公司进行数据的分类
- 对每个公司下的数据以句子为单位,使用bge-large模型嵌入,对文本向量进行聚类
- 在聚类后的文本上,以簇为单位使用glm3-6b大模型润色、修改、总结,生成面试经验的总结与面试问题库
- 讲收集到的面试问题注入到知识库中,供平台的AI模拟面试与AI对话进行RAG检索使用
- 面试经验与面试问题可以在平台前端得到展示和查询


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









