






一、Es的用途
1. 分布式的搜索、存储和分析引擎
2. 搜索引擎类的数据库
3. 应用范围广泛
垂直搜索引擎
4. 上手简单
相对于Lucene, es上手很简单
二、节点
每个节点就是一个java进程,就是一个elasticsearch的实例
一个节点不等于一个服务器
1. 节点的角色

master节点可以有多个,其中有一个是主节点,主节点挂了以后,会从其他的master节点中选举一个主节点
master节点默认为投票节点,但是有的节点是仅投票节点
三、分片

主分片:可以进行数据的读和写
副本分片:作为主分片的备份,不可以直接进行写数据,只可以对主分片进行数据同步。增加数据的安全性,提高集群的可用性
索引创建以后,主分片数量不可以进行修改(除非重新创建索引),副本分片数量可以修改
每个节点是一个es的实例,每个节点可以包含多个分片,每个分片是一个Lucene的实例
当节点数发生变化时,es会自动进行分片均衡
四、集群
由多个节点组成的高可用的、分布式的系统叫做集群
es原生就是分布式的
五、Type
es7.0以前,索引是由很多个type组成的;
7.x弱化了type的概念,用_doc
8.x完全删除type
** 所有索引的名称都是小写,如果涉及多个单词,用下划线_隔开
六、mapping

mapping类似于关系型数据库中的表结构。在mapping中包含了一些属性,比如:字段名称、类型、字段使用的分词器、是否评分、是否创建索引等属性。
1. 查看mapping
下划线_开头,表示使用的是一个api
# 查看mapping
GET /test_index/_mapping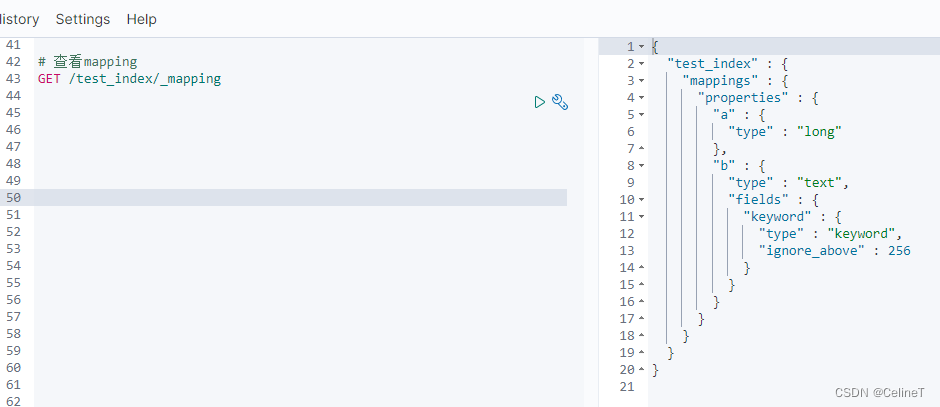
其中,type是字段类型
2. es支持的数据类型

正排索引用于排序和聚合
倒排索引用于文本检索
text类型默认会创建倒排索引,不创建正排索引
其他类型:

3. dynamic mapping 自动映射
创建索引时,不指定每个字段的类型,就叫做dynamic mapping
映射规则:

所有text类型的字段,会默认添加一个fileds属性
b会被分词,b.keyword不会被分词

4. explicit mapping 手动映射
手动创建mapping

mapping创建以后,不能修改type属性了
# 手动创建索引
PUT /test_index2
{
"mappings": {
"properties": {
"a":{
"type":"text",
"analyzer": "standard"
},
"b":{
"type":"long"
}
}
}
}
GET /test_index2/_mapping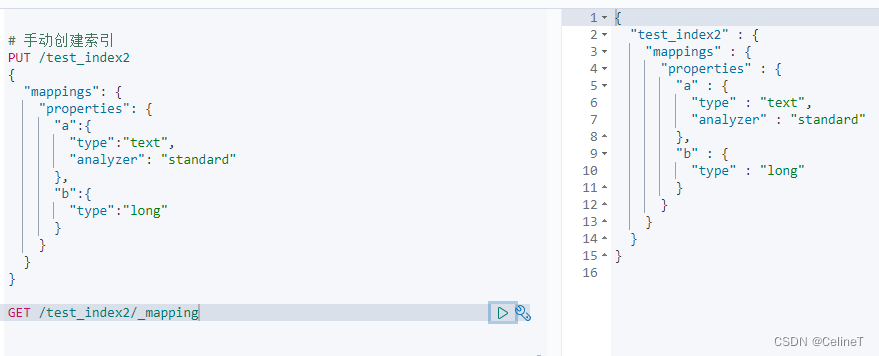
5. 手动映射的参数
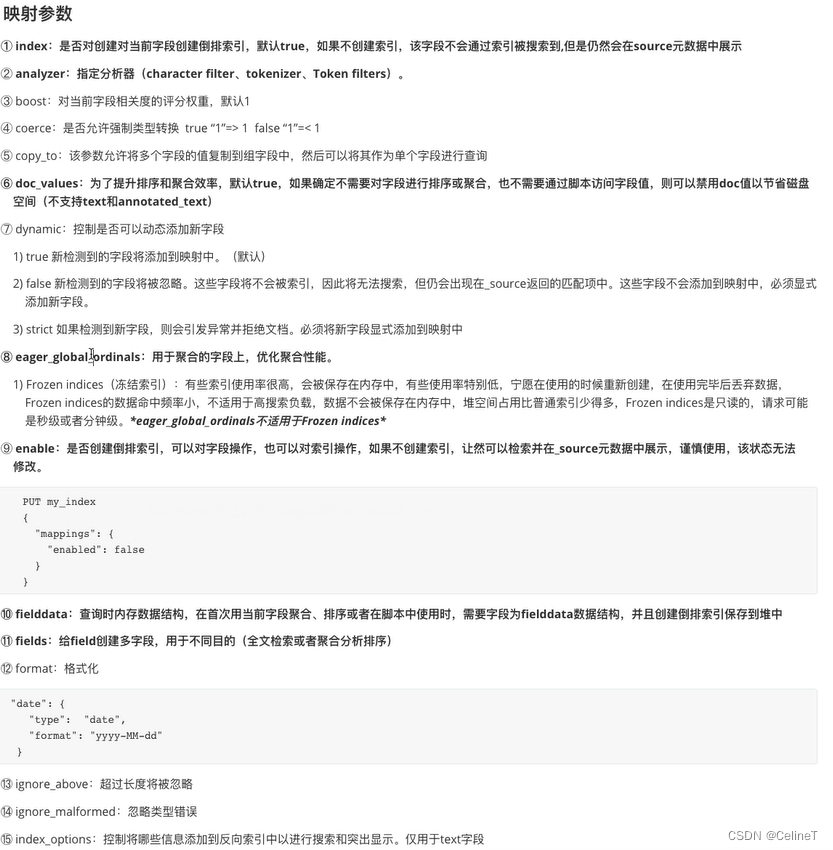

10.fileddata:创建正排索引,doc_value是在磁盘中进行正排索引,fileddata在内存中进行正排索引
14. ignore_malformed: 忽略类型错误,常用于数据同步















 3531
3531











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









