







一、摘要
本文介绍亚马逊牵头2025年3月发表的论文《Rec-R1: Bridging Generative Large Language Models and User-Centric Recommendation Systems via Reinforcement Learning》

译文:
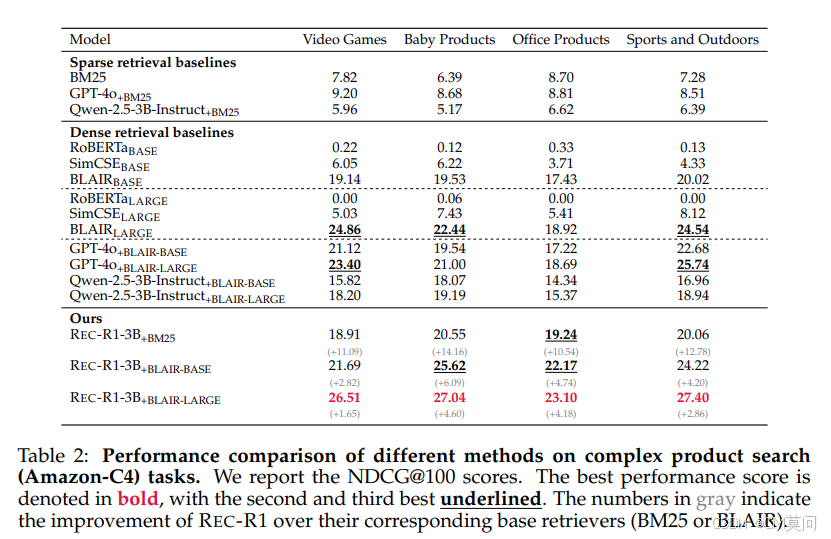
我们提出了Rec - R1,这是一个通用的强化学习框架,它通过闭环优化将大语言模型(LLMs)与推荐系统联系起来。与提示和监督微调(SFT)不同,Rec - R1直接利用来自固定黑盒推荐模型的反馈来优化大语言模型的生成,而不依赖于来自诸如GPT - 4o等专有模型的合成监督微调数据。这避免了数据提炼所需的大量成本和精力。为了验证Rec - R1的有效性,我们在两个具有代表性的任务上对其进行评估:产品搜索和序列推荐。实验结果表明,Rec - R1不仅始终优于基于提示和监督微调的方法,而且即使与诸如BM25这样简单的检索器一起使用,也能在强大的判别基线之上取得显著提升。此外,与监督微调不同,Rec - R1保留了大语言模型的通用能力,监督微调常常会损害模型的指令跟随和推理能力。这些发现表明,Rec - R1是一种有前途的基础,可用于持续的特定任务适配而不会发生灾难性遗忘。
二、核心创新点
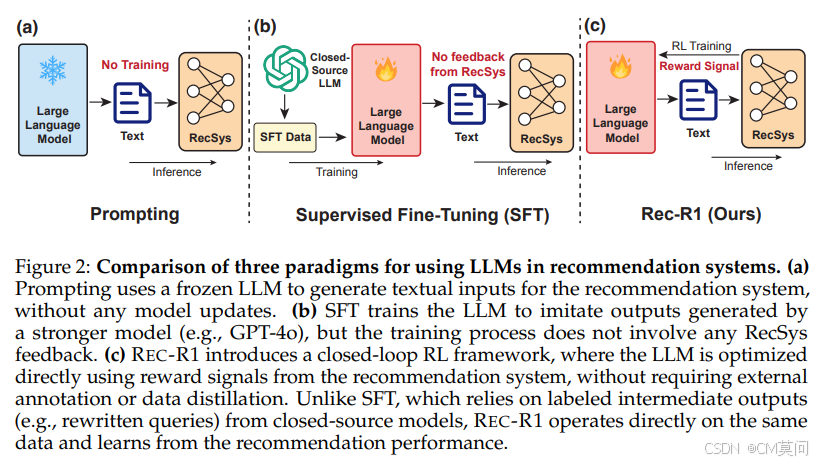
现在的推荐系统(如电商、视频平台的推荐)虽然很常用,但缺乏 “常识” 和对用户深层需求的理解。比如,用户搜索 “防水相机”,传统系统可能只匹配关键词,而无法理解用户可能是要 “户外徒步用的防水相机”,导致推荐结果不够精准。大语言模型(如 GPT-4、Qwen)有很强的语言理解和推理能力,能分析用户查询的隐含意图(比如从 “孩子生日礼物” 推断出需要适合年龄的玩具)。但传统方法只是用大模型生成固定提示或微调模型,没有形成 “反馈闭环”,浪费了模型的潜力。
1、问题陈述
作者首先对大语言模型如何集成到推荐系统中进行建模。在这个过程中,大模型接受一个输入,它可能代表用户查询、行为历史或者上下文信息。接着,大模型生成一个文本输出
,例如重写的查询、丰富的项目描述或者合成的用户画像。这个输出由下游推荐模型使用,该模型产生基于性能的评估
,如召回率等任务指标。
大模型的行为由条件生成策略控制,其中
表示生成式大模型的参数。目标是找到一种策略,使得预期推荐性能最大化:
这里,表示提供给大模型的与推荐相关的输入经验分布。
2、现有范式局限性分析
目前基于提示的方法,包括零样本和少样本提示,将大模型视为一个固定的生成器。这些方法依赖于手动构建的提示或少量示例来引出理想的输出。然而,由于模型参数不更新,策略
保持不变,无法适应特定任务的反馈,从而导致推荐性能欠佳。
有监督微调迫使大模型模仿由更强的模型生成的输出。形式上,这相当于在学习到的策略下,最大化从数据生成策略
中采样的动作的对数似然。这种最大似然估计目标促使学习到的策略
模仿
,但在优化过程中没有考虑下游性能
。作者证明了这种训练过程存在一个基本的性能上限——即经过监督微调训练的大模型的推荐性能充其量只能接近但永远无法超过用于生成训练数据的策略。
3、Rec-R1框架
为了克服提示和有监督微调的局限性,作者提出了Rec-R1通用框架,通过强化学习将生成式大模型与推荐系统直接联系起来。Rec-R1不是模仿静态的数据生成策略,而是基于来自下游推荐器的反馈直接优化大模型策略,从而使生成过程与真正的目标保持一致——最大化推荐性能。
本质上讲,Rec-R1将大模型和推荐系统之间的交互看作一个闭环优化过程,其中大模型生成文本(如改写后的查询、用户画像或者物品描述),而推荐模型则使用特定任务的指标来评估结果。然后,这些评估分数会通过强化学习转化为标量奖励信号,用于策略优化。
Rec-R1的一个关键优势在于,它能够利用来自推荐系统的直接反馈对大模型进行优化。这种反馈被形式化为一个标量奖励,该奖励量化了在给定输入 s 的情况下,大模型生成的输出 a 在下游任务中的表现。可以使用任何能反映推荐质量的可微或不可微指标来实例化该奖励,例如NDCG@K和Recall@K。形式上,优化目标是找到一个生成策略
,以最大化预期奖励:
与有监督微调不同,该目标不依赖手动标注的监督或者对固定策略的模仿。相反,它允许模型持续调整其行为,以在下游推荐任务中实现性能最大化。作者采用了GRPO方法来优化大模型的策略。与传统算法相比,GRPO能够在训练过程中显著降低内存消耗。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









