







目录
3.7 过程(Procedures)
过程:软件的一种抽象。
提供了一种封装代码的方式,用一组指定的参数和一个可选的返回值实现了某种功能;
可以在程序的不同地方对其进行调用。
形式包括:函数(function)、方法(method)、子例程(subroutine)、处理(响应)函数(handler)等。
过程的机器级支持,需要包含以下机制:假设过程 P 调用过程 Q,Q 执行后返回到 P。
1、传递控制:在进入过程 Q 的时候,程序计数器必须被设置为 Q 的代码的起始地址;返回时,要把程序计数器设置为 P 中调用 Q 后面那条指令的地址。
2、传递数据:P 必须能够向 Q 提供一个或多个参数,Q 必须能够向 P 返回一个值。
3、分配和释放内存:在开始时,Q 需要为局部变量分配空间;返回前,又必须释放这些存储空间。
3.7.1 运行时的栈(The Run-Time Stack)(重要)
过程调用机制的一个关键特性:使用了栈数据结构提供的后进先出的内存管理原则。
1、分配和释放栈空间
- 分配空间
- 使用
pushq将数据存入栈中; - 操作栈指针:减小一个适当的量可以为没有指定初始值的数据在栈上分配空间。
- 使用
- 释放空间
- 使用
popq将数据弹出栈; - 操作栈指针:增加一个适当的量可以释放栈上已分配的空间。
(注意:操作的是指针,实际上并不会影响到栈空间所映射的内存位置的值)
- 使用
2、何时会用到栈?栈帧是啥?
(1)函数参数保存在哪里?
3.4 节给出的整数寄存器表格是 x86-64 的一组共计 16 个通用目的寄存器,每个 64 位。
其中有 6 个寄存器可以用于函数传参,按参数出现顺序分别是 %rdi、%rsi、%rdx、%rcx、%r8、%r9(64位时的名称)。——函数参数就临时保存在这些寄存器里
【问题】函数参数超过 6 个怎么办?有些 CPU 甚至只提供 4 个可用于函数传参的寄存器
【方法】在调用函数传参之前,把寄存器无法存下的参数存储在自己(当前执行的过程)的栈帧中。
【扩展】这也是为什么不建议函数参数过多的原因。多了需要使用栈空间,增加了存取释放的时间,降低了函数调用的速度。
(2)栈帧
当过程需要的存储空间超出寄存器能够提供的大小时,就会在栈上分配空间,该空间被称为: 栈帧(stack frame)。
- 栈帧的边界默认以 16 个字节进行对齐,栈帧内部则按正常规则对齐。(——主要是为了支持 SSE(Streaming SIMD Extensions)浮点运算扩展指令集与16字节的 XMM 浮点寄存器)
- 栈帧的大小
- 定长栈帧:编译器在编译时根据一些机制确定一个固定长度的空间;
- 变长栈帧:有些函数需要的局部存储空间是变长的。
🌰 当函数调用 alloca 时就会发生这种情况,alloca 是一个标准库函数,可以栈上分配任意字节数量的存储。
🌰 当代码声明一个局部变长数组时,也会发生这种情况。
举个🌰:
/* 一个包含变长数组的🌰 */
long vframe(long n, long idx, long *q) {
long i;
long *p[n];
p[0] = &i;
for (i = 1; i < n; i++)
p[i] = q;
return *p[idx];
}
# long vframe(long n, long idx, long *q)
# n in %rdi, idx in %rsi, q in %rdx
# Only portions of code shown
vframe:
## 把%rbp的当前值压入栈中,再将%rbp设置为指向当前的栈位置。
pushq %rbp # Save old %rbp
movq %rsp, %rbp # Set frame pointer
## 在栈上分配16个字节,其中前8个字节用于存储局部变量i,后8个字节是编译器机制决要分配的预留空间(这里不用管)。
subq $16, %rsp # Allocate space for i (%rsp = s1,结合下图看)
## 为数组p分配空间,怎么分配的详看后续单独分析。
leaq 22(,%rdi,8), %rax
andq $-16, %rax
subq %rax, %rsp # Allocate space for array p(%rsp = s2,结合下图看)
## 找到数组p的初始地址
leaq 7(%rsp), %rax
shrq $3, %rax
leaq 0(,%rax,8), %r8 # Set %r8 to &p[0]
movq %r8, %rcx # Set %rcx to &p[0] (%rcx = p)
...
# Code for initialization loop
# i in %rax and on stack, n in %rdi, p in %rcx, q in %rdx
.L3: loop:
movq %rdx, (%rcx,%rax,8) Set p[i] to q
addq $1, %rax # Increment i
movq %rax, -8(%rbp) # Store on stack
.L2:
movq -8(%rbp), %rax # Retrieve i from stack
cmpq %rdi, %rax # Compare i:n
jl .L3 # If <, goto loop
...
# Code for function exit
## 释放栈空间
leave # Restore %rbp and %rsp
ret # Return
为了管理变长栈帧,x86-64使用寄存器 %rbp 作为帧指针(frame pointer)(也称基指针)。
1、因为 %rbp 本身是一个被调用者保存的寄存器,因此先把原存在 %rbp 的值保存到栈中;
2、在函数的整个执行过程中,都使得 %rbp 指向那个时刻的栈的位置,然后通过 %rbp 进行偏移实现对已分配栈空间的引用。
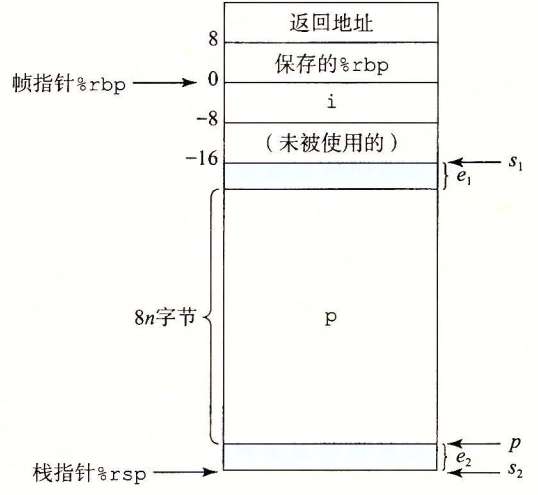
(3)探讨
这里分配了多少空间?数组 p 被放在这段空间的什么位置?
【分析】
s1 表示执行 subq $16, %rsp 后栈顶指针的位置,这条指令实现了为局部变量 i 分配空间;
s2 表示执行 subq %rax, %rsp 后栈顶指针的位置,这条指令实现了为数组 p 分配空间;
s2 的计算逻辑如下:
s
1
−
s
2
=
(
22
+
8
n
)
&
(
−
16
)
d
=
(
22
+
8
n
)
&
(
11110000
)
2
=
{
8
n
+
8
,
if
n
is even
8
n
+
16
,
if
n
is odd
s1-s2=(22+8n){\&}(-16)_d=(22+8n){\&}(11110000)_2=\begin{cases}8n+8, & \text{if }n\text{ is even}\\ 8n+16,& \text{if }n\text{ is odd} \end{cases}
s1−s2=(22+8n)&(−16)d=(22+8n)&(11110000)2={8n+8,8n+16,if n is evenif n is odd
——实现了向下舍入到最近的 16 的倍数
为什么是 16 的倍数?
因为栈帧边界默认是以 16 字节进行对齐的。【字节对齐是为了尽可能的提高CPU读取内存数据的速度】
【回答】
没有深入理解编译原理,而且不同编译器采取的机制也不尽相同。
所以到底分配了多少字节空间,我还是不知道。
数组 p 被放在这段空间的什么位置,我也还是不知道。
但是,仅就 CSPP 提供的🌰,可以确定答案(但目前仍是知其然,不知其所以然)
答案:
(1)为数组 p 分配的空间大小
根据 n 的值计算编译器为了至少能够存放数组 p 而分配的空间大小(就是肯定是可以放得下数组 p 的);
(2)数组 p 在这个空间的什么位置
首先,跟踪代码的执行,先确定 s1 的值,然后 s1 减去分配的空间大小标量值,得到 s2;
然后,还是根据字节对齐的思想,数组 p 是以指针为元素的数组,8字节对齐,指令 leaq 7(%rsp), %rax、shrq $3, %rax 和 leaq 0(,%rax,8), %r8 找到了距离 s2 最近的 8 的倍数的栈内地址,由此确定了数组的位置。
举例说明:已知 n 和 s1,跟踪代码执行,确定其余的参数值。
| n | s1 | s2 | p | e1 | e2 |
|---|---|---|---|---|---|
| 5 | 2065 | =2065-(8*5+8)=2017 | 2024,离2017最近的8的倍数 | =2065-2024-48=1 | =2024-2017=7 |
| 6 | 2064 | =2064-(8*6+16)=2000 | 2000 | =2064-2000-48=16 | =2000-2000=0 |
(4)leave 指令
leave 指令将帧指针恢复到它之前的值,没有操作数。
等价于:movq %rbp,%rsp、popq %rbp。
3.7.2 控制转移(Control Transfer)
——转移前后的指令地址处理
将控制从函数 P 转移到函数 Q 只需要将程序计数器(PC)设置为 Q 的代码的起始位置。在此之前,处理器必须记录好它需要继续 P 的执行的代码位置。
x86-64 中使用指令 call Q 调用过程 Q 来记录的:
把地址 A 压入栈中,并将 PC 设置为 Q 的起始地址;
压入的地址 A 被称为返回地址,是紧跟在 call 指令后的那条指令的地址;
对应 Q 的指令 ret 会从栈中弹出地址 A ,并把 PC 设置为 A 。
| 指令 | 描述 | |
|---|---|---|
call Label | 过程调用 | 直接调用 |
call *Operand | 过程调用 | 间接调用 |
ret | 从过程调用中返回 |
【举个🌰】
# 过程间传递控制的🌰,给出了两个函数top和leaf的反汇编代码
# Disassembly of leaf(long y)
# y in %rdi
0000000000400540 <leaf>:
400540: 48 8d 47 02 lea 0x2(%rdi),%rax # L1: z+2
400544: c3 retq # L2: Return
0000000000400545 <top>:
# Disassembly of top(long x)
# x in %rdi
400545: 48 83 ef 05 sub $0x5,%rdi # T1: x-5
400549: e8 f2 ff ff ff callq 400540 <leaf> # T2: Call leaf(x-5)
40054e: 4801c0 add %rax,%rax # T3: Double result
400551: c3 retq # T4: Return
# ...
# Call to top from function main
40055b: e8 e5 ff ff ff callq 400545 <top> # M1: Call top(100)
400560: 4889c2 mov %rax,%rdx # M2: Resume
| 指令 | 状态值 | (指令 | 执行前) | 描述 | |||
|---|---|---|---|---|---|---|---|
| 标号 | PC | 指令 | %rdi | %rax | %rsp | *%rsp | |
| M1 | 0x40055b | callq | 100 | — | 0x7fffffffe820 | — | Call top(100) |
| T1 | 0x400545 | sub | 100 | — | 0x7fffffffe818 | 0x400560 | 进入 top |
| T2 | 0x400549 | callq | 95 | — | 0x7fffffffe818 | 0x400560 | Call leaf(95) |
| L1 | 0x400540 | lea | 95 | — | 0x7fffffffe810 | 0x40054e | 进入 leaf |
| L2 | 0x400544 | retq | 95 | 97 | 0x7fffffffe810 | 0x40054e | 从 leaf 返回 97 |
| T3 | 0x40054e | add | 95 | 97 | 0x7fffffffe818 | 0x400560 | 继续 top |
| T4 | 0x400551 | retq | 95 | 194 | 0x7fffffffe818 | 0x400560 | 从 top 返回 194 |
| M2 | 0x400560 | mov | 95 | 194 | 0x7fffffffe820 | — | 继续 main |
3.7.3 数据传送(Data Transfer)
——转移前后的参数存储
call 指令执行前,将被调用的函数的参数必须已经存储在寄存器和栈空间。
在 x86-64 中:
△ 可以通过寄存器最多传递 6 个整型(整数和指针)参数( %rdi、%rsi、%rdx、%rcx、%r8、%r9);
△ 可以通过寄存器最多传递 8 个浮点参数(%xmm0 ~ %xmm7)。
△ 超过相应的寄存器个数,就需要使用栈空间来传递了。
寄存器的使用是有顺序的,寄存器使用的名字取决于要传递的数据类型的大小。
通过栈传递参数时,所有的数据大小都以 8 字节对齐。
【整型寄存器顺序、名字表】
| 操作数大小 | 第1参数 | 第2参数 | 第3参数 | 第4参数 | 第5参数 | 第6参数 |
|---|---|---|---|---|---|---|
| 64 位 | %rdi | %rsi | %rdx | %rcx | %r8 | %r9 |
| 32 位 | %edi | %esi | %edx | %ecx | %r8d | %r9d |
| 16 位 | %di | %si | %dx | %cx | %r8w | %r9w |
| 8 位 | %dil | %sil | %dl | %cl | %r8b | %r9b |
【浮点数寄存器顺序、名字表】
| 操作数 | 第1参数 | 第2参~ | 第3参~ | 第4参~ | 第5参~ | 第6参~ | 第7参~ | 第8参~ |
|---|---|---|---|---|---|---|---|---|
| float→32位 double→64位 | %xmm0 | %xmm1 | %xmm2 | %xmm3 | %xmm4 | %xmm5 | %xmm6 | %xmm7 |
【举个🌰】
假设过程 P 调用过程 Q ,Q 有 n 个整型参数,且 n>6。那么 P 代码分配的栈帧必须要能容纳 7 到 n 号参数的存储空间。
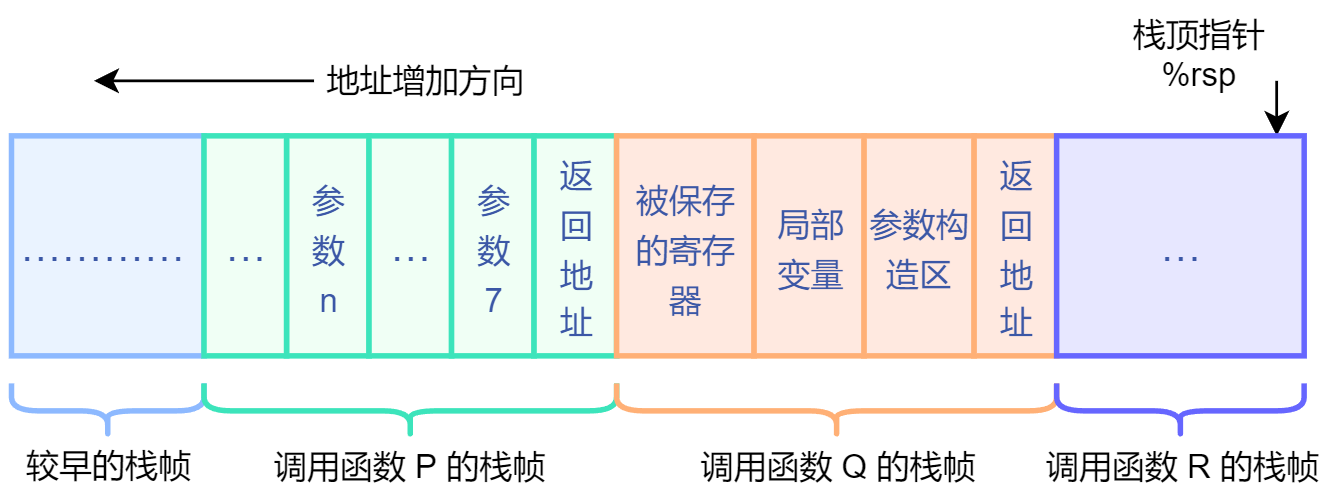
进一步地,假设过程 Q 也调用了某个有超过 6 个参数的函数 R,它也需要在自己的栈帧中为超出 6 个的参数分配空间,如下图的“参数构造区”。
栈的空间结构图如下:
/* 参数传递的示例 */
void proc(long a1, long *a1p,
int a2, int *a2p,
short a3, short *a3p,
char a4, char *a4p)
{
*a1p += a1;
*a2p += a2;
*a3p += a3;
*a4p += a4;
}
# void proc(a1, a1p, a2, a2p, a3, a3p, a4, a4p)
# Arguments passed as follows:
# a1 in %rdi (64 bits)
# a1p in %rsi (64 bits)
# a2 in %edx (32 bits)
# a2p in %rcx (64 bits)
# a3 in %r8w (16 bits)
# a3p in %r9 (64 bits)
# a4 at %rsp+8 (8 bits)
# a4p at %rsp+16 (64 bits)
proc:
movq 16(%rsp), %rax # Fetch a4p (64 bits)
addq %rdi, (%rsi) # *a1p += a1 (64 bits)
addl %edx, (%rcx) # *a2p += a2 (32 bits)
addw %r8w, (%r9) # *a3p += a3 (16 bits)
movl 8(%rsp), %edx # Fetch a4 (8 bits)
addb %dl, (%rax) # *a4p += a4 (8 bits)
ret # Return
👆函数 proc 的参数 a4 和 a4p 通过栈传递。(8 字节对齐)
3.7.4 栈上的局部存储(Local Storage on the Stack)
在 3.7.3 小节中的栈内存结构图中的“局部变量”就属于“栈上的局部存储”。
【什么时候需要在栈上分配空间存储这些局部变量数据?】
常见情况包括:
(1)寄存器不足够存放所有的本地数据时;
(2)对一个局部变量使用地址运算符‘&’时,因为必须能够为其产生一个地址(这个地址当然是指内存地址。寄存器从存储角度来讲,和内存是一个级别的);
(3)局部变量是数组或结构时,因为数组和结构可以通过引用被访问,既需引用,则需要为其产生内存地址。
一般而言,过程通过减小栈顶指针在栈上获得空间,这个空间也是栈帧的一部分。
【举个🌰】
/* 该函数必须在栈上分配局部变量存储空间的函数
还要向有8个参数的函数proc传递值 */
long call_proc()
{
long x1 = 1;
int x2 = 2;
short x3 = 3;
char x4 = 4;
proc(x1, &x1, x2, &x2, x3, &x3, x4, &x4);
return (x1+x2)*(x3-x4);
}
# long call_proc()
call_proc:
# Set up arguments to proc
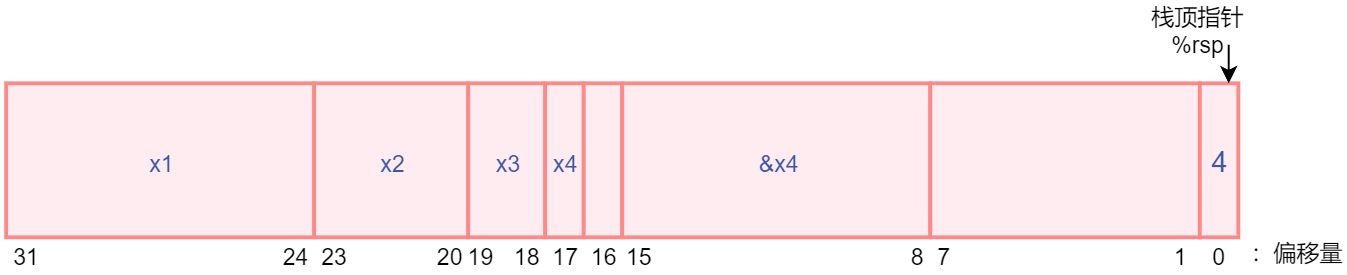
subq $32, %rsp # Allocate 32-byte stack frame
movq $1, 24(%rsp) # Store 1 in &x1
movl $2, 20(%rsp) # Store 2 in &x2
movw $3, 18(%rsp) # Store 3 in &x3
movb $4, 17(%rsp) # Store 4 in &x4
leaq 17(%rsp), %rax # Create &x4
movq %rax, 8(%rsp) # Store &x4 as argument 8
movl $4, (%rsp) # Store 4 as argument 7
leaq 18(%rsp), %r9 # Pass &x3 as argument 6
movl $3, %r8d # Pass 3 as argument 5
leaq 20(%rsp), %rcx # Pass &x2 as argument 4
movl $2, %edx # Pass 2 as argument 314
leaq 24(%rsp), %rsi # Pass &x1 as argument 2
movl $1, %edi # Pass 1 as argument 1
# Call proc
call proc
# Retrieve changes to memory
movslq 20(%rsp), %rdx # Get x2 and convert to long
addq 24(%rsp), %rdx # Compute x1+x2
movswl 18(%rsp), %eax # Get x3 and convert to int
movsbl 17(%rsp), %ecx # Get x4 and convert to int
subl %ecx, %eax # Compute x3-x4
cltq # Convert to long
imulq %rdx, %rax # Compute (x1+x2) * (x3-x4)
addq $32, %rsp # Deallocate stack frame
ret # Return
👆可以看到汇编代码中开始的一大部分,都是为调用函数 proc 做准备,其中包括为局部变量和函数参数建立栈帧,加载函数参数到寄存器中。
下图为函数 call_proc 的栈帧中用于局部存储的空间。
3.7.5 需要在栈上保存的寄存器
一个过程中可能存在多个嵌套的过程,同一时刻,只有一个过程是活跃的。
然而寄存器组是唯一被所有过程共享的资源。
根据设计要求:
寄存器 %rbx、%rbp、%r12、%r13、%r14、%r15 被划分为被调用者保存寄存器;
剩余的整型寄存器、全部的 XMM 浮点数寄存器都是调用者保存寄存器。
这就必须确保过程 P 调用过程 Q 时:
过程 P 必须先把调用者保存寄存器的值保存起来,就是压入过程 P 的栈帧中;
过程 Q 必须先把被调用者保存寄存器的值保存起来,就是压入过程 Q 的栈帧中,即下图中的“被保存的寄存器”部分。
(实际上,未被使用的,编译器压根不去理会)
当函数包含指针、整数和浮点数混合的参数时,指针和整数通过通用寄存器传递,而浮点值通过 XMM 寄存器传递——参数到寄存器的映射取决于它们的类型和排列的顺序。
double f1(int x, double y, long z),x 存放在 %edi 中,y 放在 %xmm0 中,z 放在 %rsi 中;
3.7.6 递归过程(Recursive Procedures)
栈规则提供了一种机制:
每次函数调用都有其自己私有的状态信息(保存的返回值、被调用者保存寄存器的值、局部变量、调用者保存寄存器的值)。
在栈空间的分配上,递归调用、相互递归调用与调用其他函数是一样的。
🌰
/* 阶乘函数的递归实现 */
long rfact(long n)
{
long result;
if (n <= 1)
result = 1;
else
result = n*rfact(n-1);
return result;
}
# long rfact(long n)
# n in %rdi
rfact:
pushq %rbx # Save %rbx
movq %rdi, %rbx # Store n in callee-saved register4
movl $1, %eax # Set return value = 1
cmpq $1, %rdi # Compare n:1
jle .L35 # If <=, goto done
leaq -1(%rdi), %rdi # Compute n-1
call rfact # Call rfact(n-1)
imulq %rbx, %rax # Multiply result by n
.L35: # done:
popq %rbx # Restore %rbx
ret # Return















 1624
1624











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









