



kafka分享
1.初识kafka
1.1 kafka是什么
kafka是 由linkedin公司采用scala开发的多分区多副本基于ZooKeeper协调的分布式消息系统,现已经捐献给Apache基金会
1.2 kafka基本概念
1.2.1 概念解释
一个典型的kafka体系架构包含若干生产者(Producer),若干Broker(kafka实例,一般一台机器只存在一个实例,又可以指代单台服务器),若干消费者(Consumer),以及一个Zookeeper集群
如下图
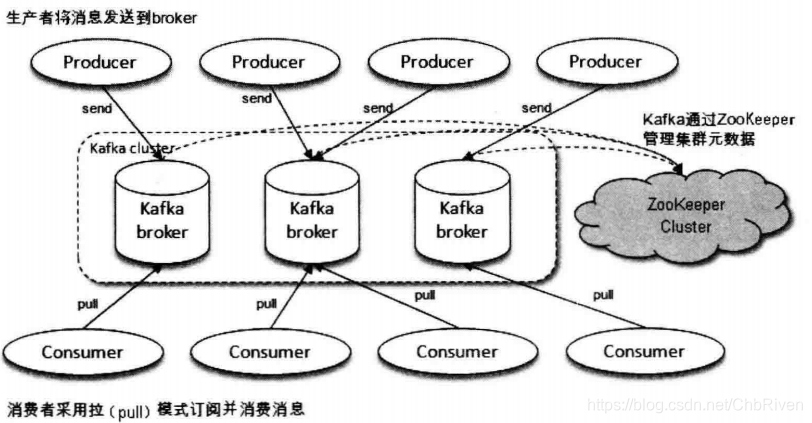
其中Producer用来生产数据 ,Broker用来存储数据,Consumer用来消费数据,Zookeeper则用来管理集群的元数据(集群节点信息,选举,故障切换)
在kafka中还有两个特别重要的概念
主题(Topic):
主题是一个逻辑上的概念,kafka中的消息以主题为单位进行归类,生产者发送消息到相应的主题,消费者监听相应的主题进行消费
创建主题
可以设置 broker端配置参数 auto.create.topics.enable 配置为true 当生产者向broker发未知主题消息或消费者开始从未知主题读消息时都会自动创建一个分区数为num.partitions(默认为1) ,副本因子为default.replication.factor(默认为1)的主题
但是并不推荐以上做法,会导致主题管理与维护难度增加
一般建议通过
bin/kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 3 --partitions 3 --topic test
并且在主题创建的时候可以指定分区副本的分配方案 replica-assignment参数
主题创建时 所有的.都会转化为_ 并且并不推荐用__(双下划线)开头 一般以双下划线开头的都是kafka内部主题 且长度不能超过249
分区(Partition):
一个主题可以分为多个分区,每个分区只属于一个主题,很多时候可以把分区称之为主题分区(Topic-Partition)
同一主题下,不同分区所保存的数据是不一样的,每个分区在存储层面都有对应的文件夹 每个文件夹里面有多个segmentLog
segmentLog的文件名上带有此分段日志的第一条消息的offset,用户可以选择按时间,大小,位移量切分
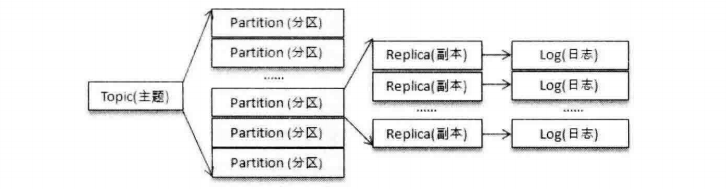
kafka不同分区可以分布在不同的Broker上,也就是说同一个Topic的分区可以跨越多个Broker,可以突破单个Broker的性能限制来提供更高的读写能力
分区的数据在存储的时候可以看做一个可以追加的Log文件,消息被追加到日志文件尾部的时候消息会分配一个特定的偏移量offset
offset是消息在分区的唯一标识,offset在单个分区内有序,但是并不保证跨分区顺序,因此kafka是保证分区有序的而不是主题有序
其中每个partition对应多个副本Replica kafka通过副本机制来提升容灾能力
kafka从 1.10.x版本开始 支持broker指定机架信息
分区副本分配时 会尽量将分区副本分配到不同的机架上
如果集群中有部分broker指定了机架信息,其余的部分broker未指定 创建主题时会异常
可以用disable-rack-aware来忽略机架信息
或者补全机架信息
需要注意 分区数可以更改 但是 分区数只能改大不能改小
请注意 分区数改大之后 如果之前topic指定过key 是会有消息顺序的问题的
添加分区操作会有如下提示
if partitions are increased for a topic that has a key,the partition logic or ordering of the message will be affected
所以建议在最初时就设计好分区数
1.2.2 副本机制
kafka在创建Topic时就可以指定分区数和副本数
bin/kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 3 --partitions 3 --topic test
也可以在创建之后更改Topic的属性
/kafka-topics.sh --zookeeper 127.0.0.1:2181 -alter --partitions 4 --replication-factor 5 --topic test
一个分区的所有副本统称为AR(Assigned Replicas)
而副本分为 leader 和follower 只有leader负责数据的读写 ,kafka并不支持读写分离 (leader也是于副本中的一员)
而主从之间 一定会有同步的滞后问题,所以AR又分为 ISR(in-sync)一定程度的同步副本和OSR(Out-of-Sync)超出一定程度同步的副本
而ISR与OSR的区别就是滞后量的大小 而这个大小是可以设置的
replica.lag.time.max.ms(有多久没同步低水位的值)
0.9.0之前有一个消息数量的设置 之后废除
取并集 加入OSR
而这两个集合的迁入迁出是由kafka内部定时任务完成的
在分区leader挂掉之后 会在ISR中选一个Offset最大的follower推举为Leader
需要注意的是 kafka并不会生成生成新副本来补充副本数
而是要通过脚本
kafka-reasign-partition.sh
对partition进行重新均衡
2. 生产者介绍
生产者是负责向Kafka发送消息的应用程序
2.1 生产者客户端开发
这里演示向本地kafka的主题topic_a发送了一条内容为aaa的消息
public static void sendMessage(String url, String topic, String message) {
Properties props = new Properties();
props.put("bootstrap.servers", url);
props.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer");
props.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer");
Producer<String, String> producer = new KafkaProducer<>(props);
//这里的send方法本身就是异步的,如果需要同步,则可以在后方加上.get() 等待返回可以获取一个RecordMetadata对象,包含当前消息的主题,分区号,偏移量,时间戳等
producer.send(new ProducerRecord<>(topic, message));
producer.close();
}
public static void main(String[] args) {
KafkaUtil.sendMessage("127.0.0.1:9092", "topic_a", "aaa");
}
需要说明的是构建的消息对象ProducerRecord 并不仅仅是单纯意义上的消息
public class ProducerRecord<K, V> {
//主题
private final String topic;
//分区号
private final Integer partition;
//消息头部,一般用来设定一些与应用相关的信息,无需要可以不设置
private final Headers headers;
//键 不仅是消息的附加信息,而且可以让消息二次归内,同一个key的消息会分在同一个分区
private final K key;
//消息值
private final V value;
//消息的时间戳
private final Long timestamp;
}
2.2 生产者必要配置
bootstrap.servers: 用来指定生产者客户端连接kafka集群的地址,用逗号隔开,不需要将所有的broker地址写上,生产者会从给定的broker中找其他的broker信息,
一般建议填两个以上的broker地址,这样在其中一个宕机时,生产者仍然可以连接上集群.
**key.serializer 和 value.serializer:**broker接受的消息必须以字节数组的形式存在,这里需要填写序列化工具的全限定类名
例如 org.apache.kafka.common.serialization.StringSerializer
2.3 消息的发送
创建完生产者,就要构建消息,即创建ProducerRecord对象

这里是ProducerRecord对象的构造方法
在构造完ProducerRecord对象完成之后,就可以开始发送消息,发送消息有三种模式
发后即忘;同步;异步
在上方代码处有同步与发后即忘的模式,这里主要讲异步
send()有两个重载方法:
写 senddeCallback参数 异步发送方法参数有一个callback接口 可以直接 new Callback(){}创建一个匿名内部类然后重写onComption方法
public static void sendMessage(String url, String topic, String message) {
log.info("send to kafka topic :{} message :{} ", topic, message);
Properties props = new Properties();
props.put("bootstrap.servers", url);
props.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer");
props.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer");
Producer<String, String> producer = new KafkaProducer<>(props);
producer.send(new ProducerRecord<>(topic, message), new Callback() {
@Override
public void onCompletion(RecordMetadata metadata, Exception exception) {
if (exception!=null){
exception.printStackTrace();
}else {
System.out.println(metadata);
}
}
});
producer.close();
}
2.4 分区器
消息在send()方法发往Broker的过程中 先经过拦截器,然后再经过序列化器和分区器,其中分区器会给消息进行分区
默认分区器 有partition参数就按partition算 不然有key参数 就 对key进行hash 然后根据得到的hash值来计算分区号
如果key也为null 那么就轮询发往主题的各个可用分区
可以自己重写分区器
实现Partitioner接口即可
2.5 整体架构
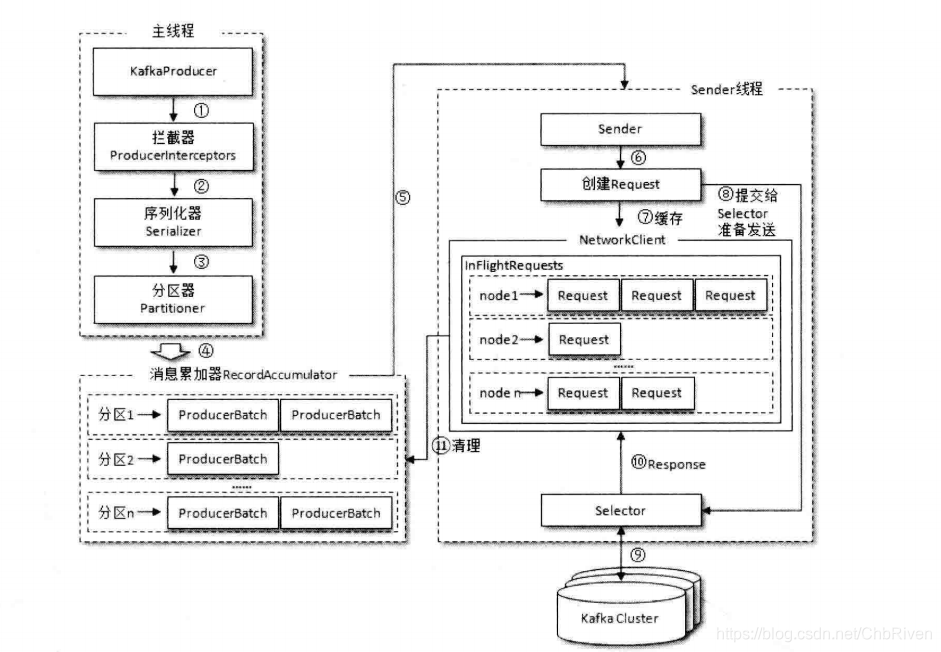
生产者一般是由两个线程组成的,主线程 以及sender线程
在主线程中由KafkaProducer创建消息,然后通过可能的拦截器,序列化器,分区器之后添加到消息累加器,sender线程负责从RecordAccumulator中获取消息并将其发送到kafka
RecordAccumulator主要用来缓存消息以便Sender线程可以批量发送,大小可以通过buffer.memory配置 默认为32MB
如果生产者发送消息到缓存的速度大于sender线程发送到服务器的速度,那么会导致生产者空间不足,这个取决于参数.max.block.ms的配置,此参数默认为60000ms
RecordAccumulator的内部有一个bufpool,主要用来实现ByteBuffer的复用只针对特定大小的ByteBuffer进行管理,其他大小的不会缓存进去,这个特定的大小与batch.size参数来进行指定默认为16kb
acks 1,0,-1 all
buffer.memory配置 默认为32MB
如果生产者发送消息到缓存的速度大于sender线程发送到服务器的速度,那么会导致生产者空间不足,这个取决于参数.max.block.ms的配置,此参数默认为60000ms
RecordAccumulator的内部有一个bufpool,主要用来实现ByteBuffer的复用只针对特定大小的ByteBuffer进行管理,其他大小的不会缓存进去,这个特定的大小与batch.size参数来进行指定默认为16kb
acks 1,0,-1 all

















 2706
2706

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









