







Redis目录
安装Redis
yum 安装 redis
yum -y install redis
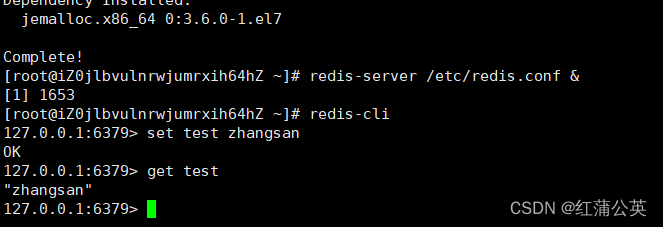
启动 redis
redis-server /etc/redis.conf &
操作 redis
redis-cli
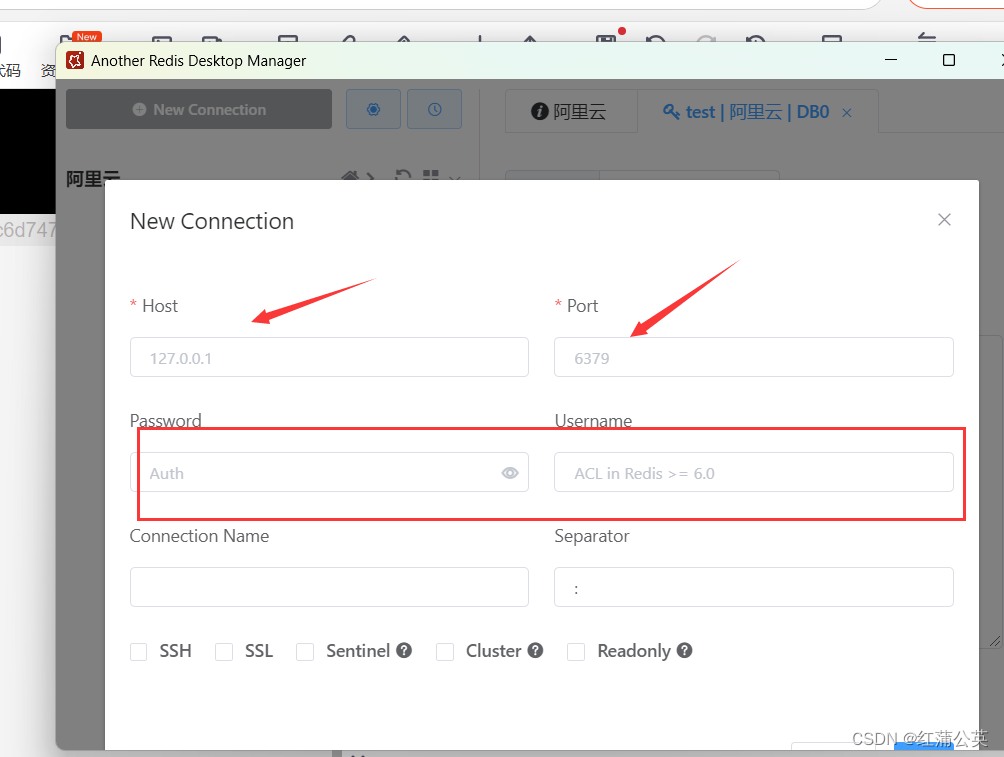
设置远程连接
-
将 redis 配置文件下载到本地:redis 配置文件是 linux 下的 /etc/redis.conf ;

点击取消下载

此时下载完成
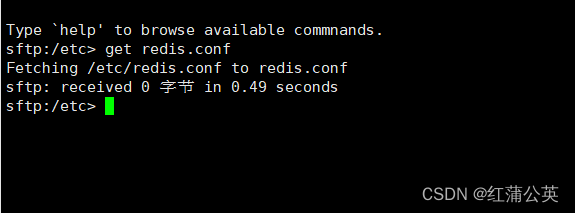

-
将 redis.conf 中的 “bind 127.0.0.1”注释掉;
-
将 redis.conf 中的“protected-mode yes” 改为“protected-mode no”;
-
将修改后的 redis.conf 上传至 liunx 下的 /etc 目录;
-
使用命令“redis-cli shutdown”先关闭 redis 服务,再使用“redis-server /etc/redis.conf &”启动 redis 服务。
-
开放6379端,云服务在安全策略里打开。
https://redis.io/commands/使用文档
使用场景
1.会话存储:保存用户的登录信息,原本的session里存储会话,只支持一次,诺是在分布式下,会使得,用户登录需要将这些分布式服务器都登录才可以,而redis就能很好的解决这个问题。
2.存储普通缓存:列如详情页等数据的缓存信息存储。
3.实现分布式锁:redis 可以非常方便的实现微服务选的分布式锁,redis 天然支持分布式服务。也可以使用zookeeper实现分布式锁。
4.简单的消息队列:redis 自身提供的发布订阅模式,可以用来实现简单的消息队列
redis常用的数据类型
- String:(字符串):
常见的使用场景是存储session信息,存储缓存信息如详情页缓存,存储整数信息可使用incr实现整数 + 1和使用decr实现整数 - 1。 - list:(列表类型):
常见使用场景式简单的消息队列,存储某项列表数据。 - Hash:(哈希表):
常见使用场景是存储session信息存储商品的购物车,购物车非常适合用哈希字典表示,使用人员唯一编号作为字典的key value值,可以存储商品的ID和数量等信息,存储详情页信息。 - Set:(集合):
一个无序并唯一的兼职集合,它的常见使用场景是实现关注功能,比如关注我的人,我关注的人使用集合存储可以保证人员不重复。 - Sorted Set :(有序集合):
相比于set集合类型多了一个排序属性的 score (分值),它的常见使用场景是可以用来存储排名信息,关注列表功能,这样就可以根据关注实现排序展示了。
有序列表的底层是如何实现的?
当数据比较少时,有序集合是压缩列表(字节数组) ziplist 实现的,反之作为跳跃表 skiplist 实现的。
使用压缩列表要满足两个条件:
- 有序集合保存的元素个数要小于128个。
- 有序集合保存的所有元素成员的长度必须小于64个字节。
如果任意一个条件不满足,就会使用跳跃表结构进行存储。
跳跃表
它的本质是由多层链表来进行实现的。

跳跃表
节点随机层数。意思是每次新增的一层,单独放一个节点,随着基数越大,层数越高,但是,最高层数32层
Redis 以及缓存的作用
缓存是⼀个⾼速数据交换的存储器,使⽤它可以快速的访问和操作数据。
Redis是文档型数据库(非关系型数据库)
缓存优点
相⽐于数据库⽽⾔,缓存的操作性能更⾼,缓存性能⾼的主要原因有以下⼏个:
- 缓存⼀般都是 key-value 查询数据的,因为不像数据库⼀样还有查询的条件等因素,所以查询的性能⼀般会⽐数据库⾼;
- 缓存的数据是存储在内存中的,⽽数据库的数据是存储在磁盘中的,因为内存的操作性能远远⼤于磁盘,因此缓存的查询效率会⾼很多;
- 缓存更容易做分布式部署(当⼀台服务器变成多台相连的服务器集群),⽽数据库⼀般⽐较难实现分布式部署,因此缓存的负载和性能更容易平⾏扩展和增加。

本地缓存也叫单机缓存,也就是说可以应⽤在单机环境下的缓存。所谓的单机环境是指,将服务部署到⼀台服务器上,本地缓存的特征是只适⽤于当前系统。
分布式缓存是指可以应⽤在分布式系统中的缓存。所谓的分布式系统是指将⼀套服务器部署到多台服务器,并且通过负载分发将⽤户的请求按照⼀定的规则分发到不同服务器,
- 本地缓存的常⻅使⽤:Spring Cache、MyBatis 的缓存等。
- 分布式缓存的常⻅使⽤:Redis 和 Memcached。
使用redis
Spring/Spring Boot 操作redis java客户端
Spring Redis lettuce
添加Redis依赖。

设置Redis远程连接
在配置文件中写入
#设置Redis连接信息
spring.redis.host=127.0.0.1
spring.redis.port=6379
spring.redis.password=
spring.redis.database=1
因为我没有设置密码,所以无需填入。

通过RedisAPI调用。
@RestController
public class TestController {
private static final String _REDIS_KEY="myapplication_test";
@Resource
private RedisTemplate redisTemplate;
@RequestMapping("/setval")
public void setVal(String val){
//得到操作redis的String类型
redisTemplate.opsForValue()
.set(_REDIS_KEY,val,1000, TimeUnit.SECONDS);
}
@RequestMapping("/getval")
public String getValue(){
return (String) redisTemplate.opsForValue()
.get(_REDIS_KEY);
}
}
session升级到Redis中
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-redis</artifactId>
<version>2.7.14</version>
</dependency>
<!-- https://mvnrepository.com/artifact/org.springframework.session/spring-session-data-redis -->
<dependency>
<groupId>org.springframework.session</groupId>
<artifactId>spring-session-data-redis</artifactId>
<version>2.7.0</version>
</dependency>
spring.session.store-type=redis
#过期时间
server.servlet.session.timeout=1800
spring.session.redis.flush-mode=on_save
#用户登录的session存在这个目录下
spring.session.redis.namespace=spring:session

Redis如何实现分布式锁
在分布式存储的服务器中一个应用在一台服务器上进行实现,运行,并且加锁的话,那么相应的对于其他服务器而言,他们也有相同的应用也需要进行加锁,而此时我们平常的加锁是对于一个服务器来说进行加锁,所以此时的需求就需要我们进行对同时多个服务器进行加锁。
分布式加锁是一个-----》逻辑概念
Redis 是单线程的模型。它的速度为什么会比较快,并且没有用到多线程度?其原因就在于:
- 它的内部结构是通过 key value 对进行存储数据的。可以通过某种算法快速定位到相应的值。就是他在查找的过程中他的时间复杂度为O(1)。这种设计有效的避免了多线程的锁竞争和锁开销。所以在这种模式下,可以处理大量的并发请求。
- Redis 是一种基于内存的数据存储系统,所有的数据都存储在内存中。内存的访问速度明显高于磁盘存储系统的速度。
- Redis 提供了高效的数据结构。这些数据结构都进行了优化。
- Redis 使用了 非 I/O 模型 就意味着,当进行磁盘读写或者网络通信时,Redis 不会等待数据的返回,而是继续处理其他请求。
如何实现分布式加锁操作 Redis 给出了他的解决方案。因为Redis 本身可以实现分布式,所以通过 setnx(set it not exists)命令实现。del 释放锁
setnx lock true;创建锁成功
del lock;释放锁
分布式加锁,产生死锁:
获取锁的线程下线了或者是崩溃,线程不会继续执行看,那么就会发生死锁。
如何解决:添加超时时间。
set (锁名字)true ex (设置的时间) nx
定期删除,不是超时删除。
锁误删
线程的锁在删除的过程中,删除了其他的线程。
如何解决误删,在锁中添加标识符。判断锁的归属。
非原子性
此时又出现一个问题,因为出现了判断结果,并修改,有读和写操作,此时是非原子性操作。
为了解决这种状况。有两种方案:
1.使用lua脚本(Redis 可使用可保证原子性的脚本)
2.Redisson框架
数据不丢失(持久化)
所谓的持久化就是将数据从内存保存到磁盘的过程,它的⽬的就是为了防⽌数据丢失。因为服务器重启之后数据会丢失,但是如果存储到磁盘中,此时就永久保存了下来。Memcached与Redis最本质的区别就是这个。
三种方式:
- 快照⽅式(RDB, Redis DataBase)将某⼀个时刻的内存数据,以⼆进制的⽅式写⼊磁盘;
- ⽂件追加⽅式(AOF, Append Only File),记录所有的操作,非查询命令,并以⽂本的形式追加到⽂件中;
- 混合持久化⽅式,混合持久化是结合了 RDB 和 AOF 的优点,在写⼊的时候,先把当前的数据以 RDB 的形式写⼊⽂件的开头,再将后续的操作命令以 AOF 的格式存⼊⽂件,这样既能保证 Redis 重启时的速度,⼜能减低数据丢失的⻛险。
RDB
RDB工作原理:
RDB持久化是通过快照的方式,将当前release内存中的数据二进制格式保存到硬盘上的一个文件中,快照文件是一个经过二压缩的二进制文件,代表了某个时间点上的数据库状态。
RDB 优点:
- 效率高:RDB持久化是将整个数据集与二进制格式保存到磁盘上,因此在数据恢复时速度较快。
- 文件较小:相比于AOF,RDB生成的快照文件通常较小,占用较小的磁盘空间
缺点:
- 数据丢失:由于 RDB 是定期保存快照,如果reduce在快照之间发生故障,可能导致部分数据丢失。
AOF
AOF的工作原理:
AOF持久化是将 Redis 的写操作与日志的形式,追加到一个文件中,类似于数据库中的日志,当Redis需要重启时,可以通过回放 AOF 文件中的写操作来恢复数据。
AOF优点:
- 数据完整性较好:AOF 持久化是通过追加,写操作来记录数据变化的,因此通常比 RDB 更可靠,数据丢失的可能性比较低。
- 可读性高 :AOF文件是一个文本文件,可以方便的查看和分析,其中的内容也更容易进行手动修复。
- 多种持久化策略,为Redis提供了不同的AOF持久化策略,可以根据需要,选择不同级别的数据安全性和性能。
缺点:
- 文件比较大:由于追加写,AOF文件会随着时间比较长,可能会变得很大,而较大的AOF文件可能影响重启和恢复的速度。
- 对磁盘的写入频繁:AOF持久化需要平凡写入日志文件,可能会对磁盘造成一定的写入压力
AOF持久化策略有3中:
- always:每天Redis操作命令都会写入磁盘,最多丢失一条数据。
- everysec:每秒钟写一次磁盘,最多丢失一秒的数据
- no:不设置写入磁盘的规则,根据当前操作系统来决定何时写入磁盘,Linux默认30秒写一次。
这三种配置在Redis的文件Redis.conf中,通过 “appendfsync everysec”来设置。
redis的键值过期后就会删除吗?
不会的。redis并不会在过期后,立即删除过期数据,而是等待多个过期数据,然后一起删除。降低开销。
数据淘汰
如何删除过期数据:
- 定时删除,在设置 键值 过期时,创建一个时间事件,当过期时间达到时,由事件处理器自动执行删除操作。
- 惰性删除,不主动删除过期键,每次从数据库获取键值时,判断是否过期,如果过期则删除键值,并返回null。
- 定期删除,每隔一段时间检查一次数据库,随机删除一些过期键。
定期删除的流程:
- 从过期字典中随机取出20个键
- 删除这20个键中过期的键
- 如果过期key的比例超过25%,则重复步骤1.
redis内存会用完吗?
会的。也就是当Redis的运行内训,超过Redis设置的对大内存后,将会采取内存淘汰机制来删除符合条件的键值对,一次来保证Redis的正常运行。
那么内存淘汰机制有哪些:
- noeviction:不淘汰任何数据。
- allkeys-lru:淘汰最久未使用的键值
- allkeys-random:淘汰时间最久的。
。
。
。
其实主要四种。一种是不淘汰,只报错,一种是设置淘汰时间的。一种随机淘汰,一种淘汰时间最长的。
LRU 和 LFU 的区别
LRU(最近最少使用)和 LFU(最不常用使用)都是常见的缓存淘汰策略,他们在淘汰缓存中的键有不同的侧重点。
- LRU(最近最少使用)(基于时间的概念):淘汰时会优先淘汰最久未被访问的键
- LFU(最不常用使用)(基于访问次数的概念):会优先选择访问字数最少的键
- LRU基于时间,LFU基于访问频率
- LRU策略假设最近被访问的键可能再次访问,LFU假设访问次数最少的键是最不常使用的。
- LRU维护一个访问顺序表,LFU维护一个计数器
- LRU只关注的访问顺序,而LFU关注键的访问频率
过期淘汰策略和内存淘汰策略有什么区别
- 内存淘汰机制:解决Redis运行内存过大的问题(节约内存空间)
- 过期删除策略:主要是为了删除过期数据
Redis事务
Redis和Mysql事务最大的区别是Redis事务本质是一组命令加入到一次性执行,并没有提供向Mysql那样的事务隔离性。Redis没有隔离性。
Redis中,单条命令是原子性执行的,但事务不保证原子性,且没有回滚。事务中任意命令执行失败,其余的命令仍会被执行。
在事务执行过程,会按照顺序串行化执行队列中的命令,其他客户端提交的命令请求不会插入到事务执行命令序列中。
redis事务就是一次性、顺序性、排他性的执行一个队列中的一系列命令
Redis事务相关命令:
开始事务
命令入队
执行事务
-
watch key1 key2 … : 监视一或多个key,如果在事务执行之前,被监视的key被其他命令改动,则事务被打断 ( 类似乐观锁 )
-
multi : 标记一个事务块的开始( queued )
-
exec : 执行所有事务块的命令 ( 一旦执行exec后,之前加的监控锁都会被取消掉 )
-
discard : 取消事务,放弃事务块中的所有命令
-
unwatch : 取消watch对所有key的监控
雪崩
缓存雪崩是指在短时间内,有⼤量缓存同时过期,导致⼤量的请求直接查询数据库,从⽽对数据库造成了巨⼤的压⼒,严重情况下可能会导致数据库宕机的情况叫做缓存雪崩。
如何解决:
- 加锁排队:可以起到缓冲的作⽤,防⽌⼤量的请求同时操作数据库,但它的缺点是增加了系统的响应时间,降低了系统的吞吐量,牺牲了⼀部分⽤户体验。
- 随机化过期时间:为了避免缓存同时过期,可在设置缓存时添加随机时间,这样就可以极⼤的避免⼤量的缓存同时失效。
// 缓存原本的失效时间
int exTime = 10 * 60;
// 随机数⽣成类
Random random = new Random();
// 缓存设置
jedis.setex(cacheKey, exTime+random.nextInt(1000) , value);
- 设置⼆级缓存:⼆级缓存指的是除了 Redis 本身的缓存,再设置⼀层缓存,当 Redis 失效之后,先去查询⼆级缓存。

缓存穿透
缓存中没有没有数据。每次访问就穿过缓存进入数据库查询
缓存穿透是指查询数据库和缓存都⽆数据,因为数据库查询⽆数据,出于容错考虑,不会将结果保存到缓存中,因此每次请求都会去查询数据库,这种情况就叫做缓存穿透。
缓存击穿
缓存失效(使得程序直接访问数据库,滤过了Redis)
缓存击穿指的是某个热点缓存,在某⼀时刻恰好失效了,然后此时刚好有⼤量的并发请求,此时这些请求将会给数据库造成巨⼤的压⼒,这种情况就叫做缓存击穿。
解决方式:
- 加锁排队:缓冲操作请求以此来减少服务器的运⾏压⼒
- 设置永不过期:对于某些热点缓存,我们可以设置永不过期,这样就能保证缓存的稳定性,但需要注意在数据更改之后,要及时更新此热点缓存,不然就会造成查询结果的误差
缓存预热
缓存预热指的是在系统启动的时候,先把查询结果预存到缓存中,以便⽤户后⾯查询时可以直接从缓存中读取,以节约⽤户的等待时间。
缓存预热的实现思路有以下三种:
-
把需要缓存的⽅法写在系统初始化的⽅法中,这样系统在启动的时候就会⾃动的加载数据并缓存数据
-
把需要缓存的⽅法挂载到某个⻚⾯或后端接⼝上,⼿动触发缓存预热;
-
设置定时任务,定时⾃动进⾏缓存预热。
Redi多机部署
Redis 主从同步
把主要存储数据的节点叫做主节点 (master),把其他通过复制主节点数据的副本节点叫做从节点 (slave)。
在 Redis 中⼀个主节点可以拥有多个从节点,⼀个从节点也可以是其他服务器的主节点。

我们可以使⽤ replicaof host port 命令,把⾃⼰设置为⽬标 IP 的从服务器。
replicaof host port
如果主服务设置了密码,需要在从服务器输⼊主服务器的密码,使⽤ config set masterauth 主服务密码
config set masterauth 主服务密码
主从同步的缺点:这种模式本身存在⼀个致命的问题,当主节点奔溃之后,需要⼈⼯将从节点中设置一个主节点才能恢复 Redis 的正常使⽤。
Redis 哨兵模式
假如晚上发⽣了主从服务器宕机的情况,尤其是在主从服务器节点⽐较多的情况下。Redis Sentinel (哨兵模式) 来把⼿动的过程变成⾃动的,让 Redis 拥有⾃动容灾恢复 (failover) 的能⼒。
但是读写能力相对于主从结构,没有改变,还是以一个服务器为主节点交互。

哨兵的⼯作原理是,
-
⾸先每个 Sentinel(哨兵) 会以每秒钟 1 次的频率,向已知的主服务器、从服务器和以及其他 Sentinel (哨兵)实例,发送⼀个 PING 命令。
-
如果超越了所定的时间,就认为主服务器下线并做好标记。
-
之后正在监视这个主服务器的所有 Sentinel 节点,要以每秒 1 次的频率确认主服务器是否确实确进⼊了主观下线状态
-
如果有⾜够数量 (quorum 配置值) 的 Sentinel 在指定的时间范围内同意这⼀判断,那么这个主服务器
被标记为客观下线。此时所有的 Sentinel 会按照规则协商⾃动选出新的主节点
Redis 集群服务
Redis 集群(Redis Cluster)是 Redis 多机运⾏最完美的终极⽅案。Redis Cluster 是⽆代理模式去中⼼化的运⾏模式。
主从节点还是遵循哨兵模式。
⽔平扩展⼀倍的主节点就相当于请求处理的性能也提⾼了⼀倍,所以 Redis Cluster 的性能是⾮常⾼的。
Redis Cluster 可以拥有⽆数个主从节点,因此 Redis Cluster 拥有更强⼤的平⾏扩展能⼒,也就是说当 Redis Cluster 拥有两个主从节点时,从理论上来讲 Redis 的性能相⽐于单机服务来说性能提升了 2 倍。
















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









