







第1章 实验基本信息
1.1 实验目的
理解现代计算机系统存储器层级结构;
掌握Cache的功能结构与访问控制策略;
培养Linux下的性能测试方法与技巧;
深入理解Cache组成结构对C程序性能的影响。
1.2 实验环境与工具
1.2.1 硬件环境
x64 CPU;1.60GHz;8G RAM;256GHD Disk。
1.2.2 软件环境
Windows10 64位。
1.2.3 开发工具
VM VirtualBox 6.1;Ubuntu 20.04 LTS 64位;
Visual Studio 2019 64位;CodeBlocks 17.12 64位;vi/vim/gedit+gcc;
cpu-z;Gprof;Valgrind。
1.3 实验预习
见第二章
第2章 实验预习
2.1 画出存储器层级结构,标识容量价格速度等指标变化(5分)

2.2用CPUZ等查看你的计算机Cache各参数,写出各级Cache的C S E B s e b(5分)

| 高速缓存 | C | S | E | B | s | e | b |
| 一级数据缓存 | 32KB | 64 | 8 | 64Byte | 2 | 3 | 9 |
| 一级指令缓存 | 32KB | 64 | 8 | 64Byte | 2 | 3 | 9 |
| 二级缓存 | 256KB | 1024 | 4 | 64Byte | 2 | 2 | 9 |
| 三级缓存 | 6MB | 8192 | 12 | 64Byte | 0 | 非整数 | 9 |
注意CPU-Z图中"way" "line"对应的含义,考试可能会考
2.3写出各类Cache的读策略与写策略(5分)
1.读策略:在高速缓存中查找所需字w的副本。如果命中,立即返回字w给CPU。如果不命中,从存储器层次结构中较低层中取出包含字w的块,将这个块存储到某个高速缓存行中(可能会驱逐一个有效的行),然后返回字w。
2.写策略:写命中时:(1)直写:写命中后,在高速缓存中更新了它的w的副本之后,立即将w的高速缓存块写回到紧接着的低一层中。
(2)写回:写命中后,尽可能地推迟更新,只有当替换算法要驱逐这个更新过地块时,才把它写到紧接着的低一层中。
写不命中时:(1)写分配:加载相应的低一层中的块到高速缓存中,然后更新这个高速缓存块。
(2)非写分配:避开高速缓存,直接把这个字写到低一层中。
2.4 写出用gprof进行性能分析的方法(5分)
(1) 用gcc、g++、xlC编译程序时,使用-pg参数,如: g++ -pg -o test.exe test.cpp
编译器会自动在目标代码中插入用于性能测试的代码片断,这些代码在程序运行时采集并记录函数的调用关系和调用次数,并记录函数自身执行时间和被调用函数的执行时间。
(2) 执行编译后的可执行程序,如: ./test.exe。该步骤运行程序的时间会稍慢于正常编译的可执行程序的运行时间。程序运行结束后,会在程序所在路径下生成一个缺省文件名为gmon.out的文件,这个文件就是记录程序运行的性能、调用关系、调用次数等信息的数据文件。
(3) 使用gprof命令来分析记录程序运行信息的gmon.out文件,如:gprof test.exe gmon.out则可以在显示器上看到函数调用相关的统计、分析信息。上述信息也可以采用 gprof test.exe gmon.out> gprofresult.txt重定向到文本文件以便于后续分析。
2.5写出用Valgrind进行性能分析的方法(5分
Valgrind工具套件提供了许多调试和分析工具,可帮助你使程序更快,更正确。
Valgrind标准配置提供了许多有用的工具,其中包括:内存错误检测器MeMcheck,缓存和分支预测分析器Cachegrind,生成缓存分析器Callgrind,线程错误检测器Helgrind,线程错误检测器DRD,堆分析器Massif,堆分析器DHAT,实验工具SGcheck,示例工具Lackey,测试工具Nulgrind等。
用法: valgrind [options] prog-and-args
其中[options]: 常用选项,适用于所有Valgrind工具
最常用的命令格式:
valgrind --tool=memcheck --leak-check=full ./test
第3章 Cache模拟与测试
3.1 Cache模拟器设计
提交csim.c
程序设计思想:
对于Cache进行模拟,首先需要先构造出模拟器的数据结构,然后对内存访问过程进行模拟。
(1)首先构造模拟器的数据结构,在此之前,先使用左移操作根据输入的s、b算出相应的组数S和块大小B,便于以后想得到组索引和标记位时对位进行操作。

(2)构造模拟器的数据结构,观察定义的高速缓存行结构体、高速缓存组及高速缓存,发现cache_set_t指向cache_line_t,cache_t指向cache_set_t,于是我们可以令已经定义的高速缓存cache指向建立的cache_set_t数组,数组内为S个高速缓存组;然后令每个高速缓存组指向新建立的高速缓存行,数组内为E个高速缓存行。这样建立起高速缓存管理高速缓存组数组、高速缓存组管理高速缓存行数组的数据结构。
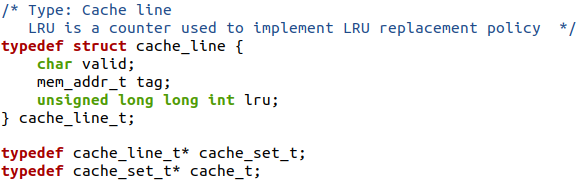

(3)紧接着编写释放malloc出来的cache内存的函数,由于在上一步我们建立了两层关系的数组,我们需要先将下一层的数组释放掉,再释放上一层数组;即先释放每个高速缓存组,再释放高速缓存。

(4)最后模拟高速缓存的访问。我们首先需要得到地址的标记以及组索引以去目标高速缓存组寻找对应的缓存。首先得到高速缓存组的mask,使其与输入的地址做位与操作,得到组索引。对于标记,由于其在地址高位,只需要令其左移(s+b)位即可。
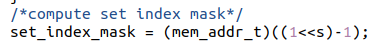

然后找到目标高速缓存组,对目标高速缓存组(即(2)中的下层数组)内的高速缓存行进行遍历寻找,判断是否存在有效位为1的标记位相同的目标缓存,若存在,则命中。

若不命中,则根据是否存在剩余缓存行,令其缓存在没有使用的高速缓存行,或替换掉已有的一个高速缓存行。
其中,若要使其缓存在没有的高速缓存行时,遍历数组查看是否存在有效值为0的高速缓存行。
涉及到替换时使用LRU淘汰策略,即淘汰最近最少使用的行。为了标记最近使用情况,使用结构体内的成员lru存储行被访问到的次数,行每次被访问则更新该值为lru_counter,并令lru_counter加1,以令lru_counter永远为数组中lru的最高值;当需要进行淘汰时,设置eviction_lru为足够大的数,从数组下标为0开始通过比较找到数组中第一个(即最近)lru_counter最小(即最少)的行所在的下标,淘汰该行,并重置改行lru为lru_counter,以标记其最近被访问过。

(5)完成后,进行make,运行test-csim,得到的结果与csim-ref相同,模拟成功。
测试用例1的输出截图(5分):

测试用例2的输出截图(5分):

测试用例3的输出截图(5分):

测试用例4的输出截图(5分):

测试用例5的输出截图(5分):

测试用例6的输出截图(5分):

测试用例7的输出截图(5分):

测试用例8的输出截图(10分):

注:每个用例的每一指标5分(最后一个用例10)——与参考csim-ref模拟器输出指标相同则判为正确

3.2 矩阵转置设计
提交trans.c
程序设计思想:
(1)32*32
由于模拟缓存器块大小32byte,则每块高速缓存可以缓存8个int变量。
于是测试使用的模拟器为32组每组1行,每行8个变量;数组每行有32个int变量;则缓存器最多可以存储数组中的8行。
首先观察程序中给的trans函数,该函数简单按行优先顺序进行读取,按列优先顺序进行存储。由于缓存器最多可以缓存8行,该函数在存储数组B时一直在增加行下标,而每次访问新B的行都会有冷不命中,没有利用到缓存中的数据,于是B数组中的全部没有命中;A数组每8个数据有一次命中。理论上不命中次数为32*32+32*32/8=1152(这里为大约计算,没有计算AB数组冲突时的不命中数量),进行测试,得到验证。

为了解决这种情况,我们需要增加B数组的命中率,即改善B数组缓存后的利用情况。为了让B也能利用缓存,我们不让B的列下标一直增大,而将其限制在缓存器最大的缓存行数内(8),即将数组分为8*8的块;这样B的下标范围在超过8之前行下标会增加,进行下一列的存储,于是他会利用到原来缓存在缓存器中的数据。理论上大致的不命中数为4*4*8+4*4*8=256,我们进行测试发现很接近预测数,但有很大误差。

于是我们需要更细节地寻找发生不命中的情况。经过手动模拟,我们发现进行 读取和存储 时会发生冲突,即A访问后对B进行存储时,B的缓存会覆盖A的 行。这时会发生更多的不命中。为了减少冲突,我们一次性读取8个A的变量, 这样后面就不用再去读取A的行,于是就减少了冲突。
进行测试发现如我们所料,虽然仍然有一些误差,但已经减到300以内。

(2)64*64
由于数组的列元素数量提高了一倍,缓存器最多只能存储4数组中的行,若我们继续进8*8分块,每当B的行下标范围超过4,会出现冷不命中,仍然会出现我们在32*32中说的B没有利用缓存好的情况。
于是我们借鉴32*32,我们选择4*4分块。进行测试,我们发现不命中数还没 有达到1300。

这是由于我们分为4*4块时数组中有16*16个块,数量过多,理论上有16*16*4*2即2048个不命中。想要改善情况,我们仍然不能增大数组分块,于是我们着手于加大利用缓存,因为每个缓存块我们只用到了4个int,而有4个位置我们没有利用到。我们需要减少冲突不命中率,受32*32最后的优化的启发,我们应多利用局部变量一次性读取或存储大量的数,防止后续冲突的出现。于是我们为了利用到缓存块中的8个位置,将数组分为8*8块,8*8块内再分为4*4块,这样首先我们将块内左上角的块转置到B的左上角(此时B的下半部分存入缓存,后续下半部分缓存除个别行与A冲突全命中),然后将A的右上角的块转置放在B的右上角(本应放在左下角);然后我们试图将A的整个下半部分存入缓存器,而每次后续读取A或存储B时最多有一行发生冲突,即先将B的右上角的一行通过变量存储,放置在B的左下角的一行,然后令A的左下角的一列放到B的左上角的一行(此时A的下半部分存入缓存,后续下半部分缓存除个别行与B冲突全命中),按照这个步骤将B的右上部分平移到B的右下部分,将A的左下部分转置到B的右上部分,最后将A的右下部分转置到B的右下部分;这样做每4个4*4块中会减少几乎一半的冷不命中。即16*16*4=1024个不命中。
测试结果低于1300:

(3)61*67
这种情况数组行列数量不是2的幂,我们可以将数组分为2幂区域和非2的幂区域(简称为幂区域和非幂区域)。针对非幂区域,我们没有统一的处理方式,于是我们只要将幂区域的不命中数降低到加上非幂区域的不命中也可以接受的程度。
而61*67的幂区域为56*64,我们测试上面两种方式,发现分为8*8的块足够降低到2000以下,而4*4因为缓存利用率不够的原因仍然高于2000。
于是我们选用8*8分块,其余部分按行或列优先进行读取和存储即可。

32×32(10分):运行结果截图

64×64(10分):运行结果截图

61×67(20分):运行结果截图

代码、附件github地址
https://github.com/ChenDolph7in/HITICS-LABS-in-21-Spring/tree/master/Lab6















 7400
7400











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









