






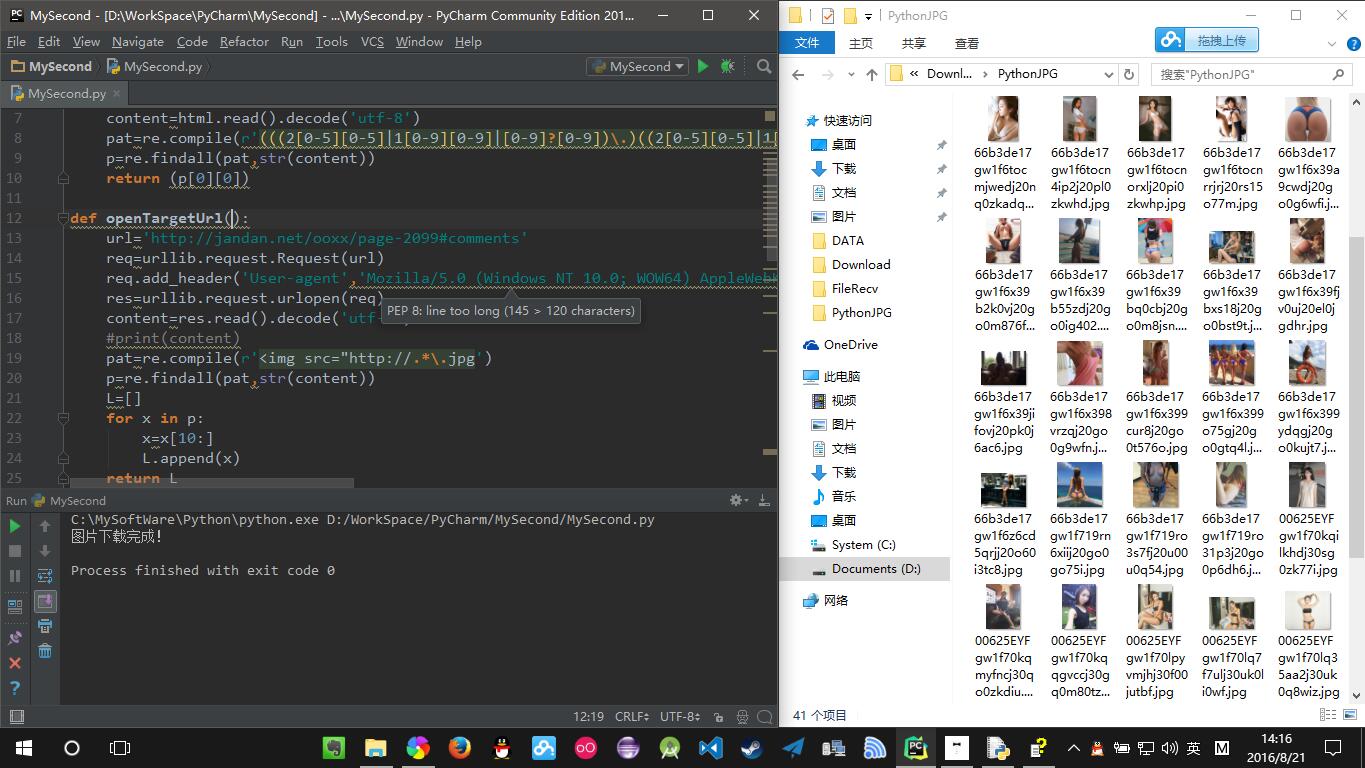
import urllib.request
import re
def agentIp():
url='http://www.kuaidaili.com/'
html=urllib.request.urlopen(url)
content=html.read().decode('utf-8')
pat=re.compile(r'(((2[0-5][0-5]|1[0-9][0-9]|[0-9]?[0-9])\.)((2[0-5][0-5]|1[0-9][0-9]|[0-9]?[0-9])\.)((2[0-5][0-5]|1[0-9][0-9]|[0-9]?[0-9])\.)(2[0-5][0-5]|1[0-9][0-9]|[0-9]?[0-9]))')
p=re.findall(pat,str(content))
return (p[0][0])
def openTargetUrl():
url='http://jandan.net/ooxx/page-2099#comments'
req=urllib.request.Request(url)
req.add_header('User-agent','Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/50.0.2661.102 Safari/537.36')
res=urllib.request.urlopen(req)
content=res.read().decode('utf-8')
#print(content)
pat=re.compile(r'<img src="http://.*\.jpg')
p=re.findall(pat,str(content))
L=[]
for x in p:
x=x[10:]
L.append(x)
return L
def download(L):
for url in L:
name=url.split("/")[-1]
req = urllib.request.Request(url)
req.add_header('User-agent',
'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/50.0.2661.102 Safari/537.36')
res = urllib.request.urlopen(req)
content = res.read()
with open("D:\Download\PythonJPG\\"+name,'wb') as f:
f.write(content)
def main():
download(openTargetUrl())
print("图片下载完成!")
#agentIp()
if __name__ == '__main__':
main()Python——用爬虫下载妹子图
最新推荐文章于 2020-12-10 22:03:43 发布
















 307
307











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









