







爬取目标
网站:绝对领域
主要运用到以下知识点:
1、 requests请求三大要素
2、功能函数的封装.
3、os对文件路径处理
4、图集分类保存
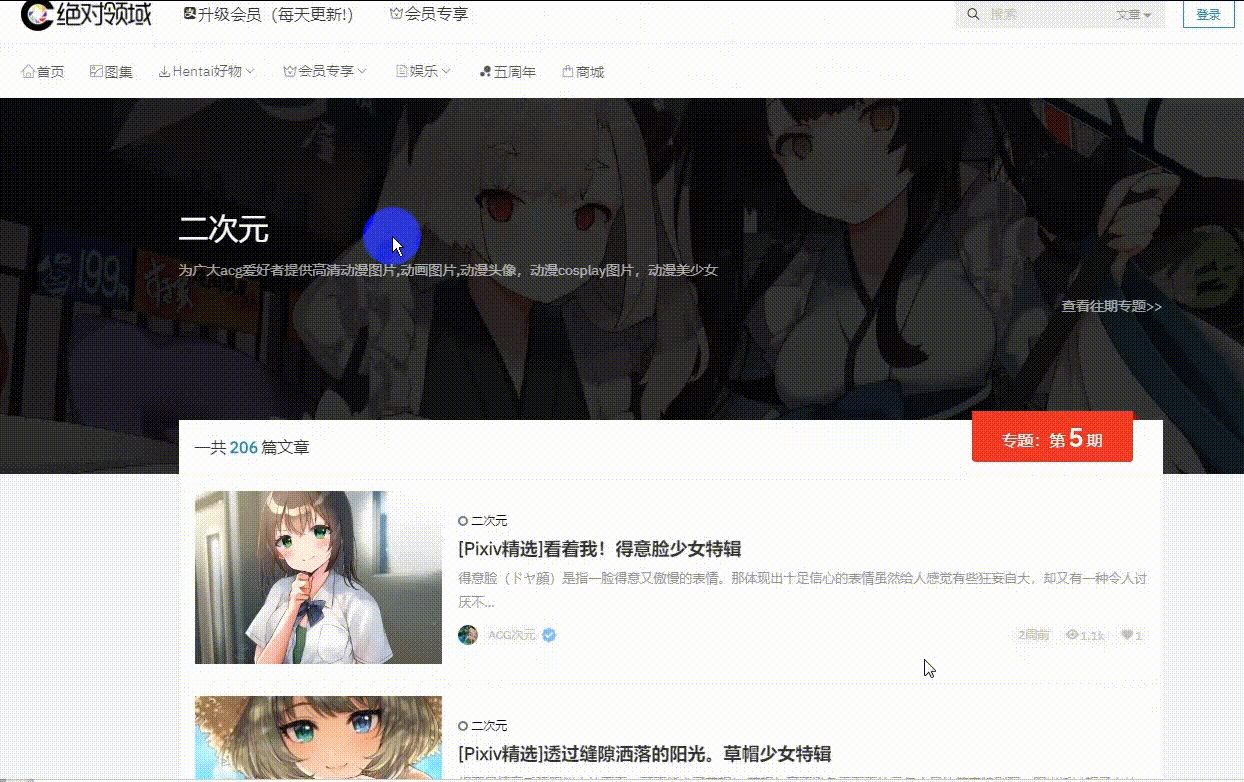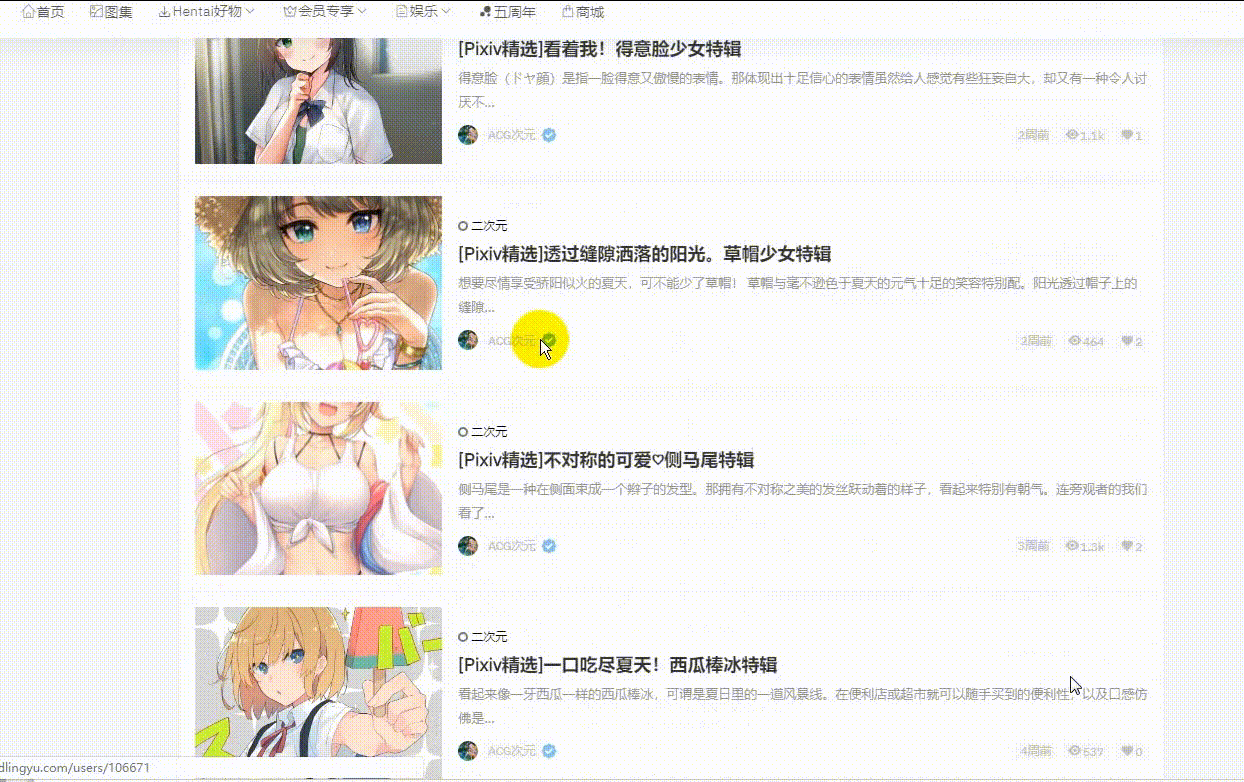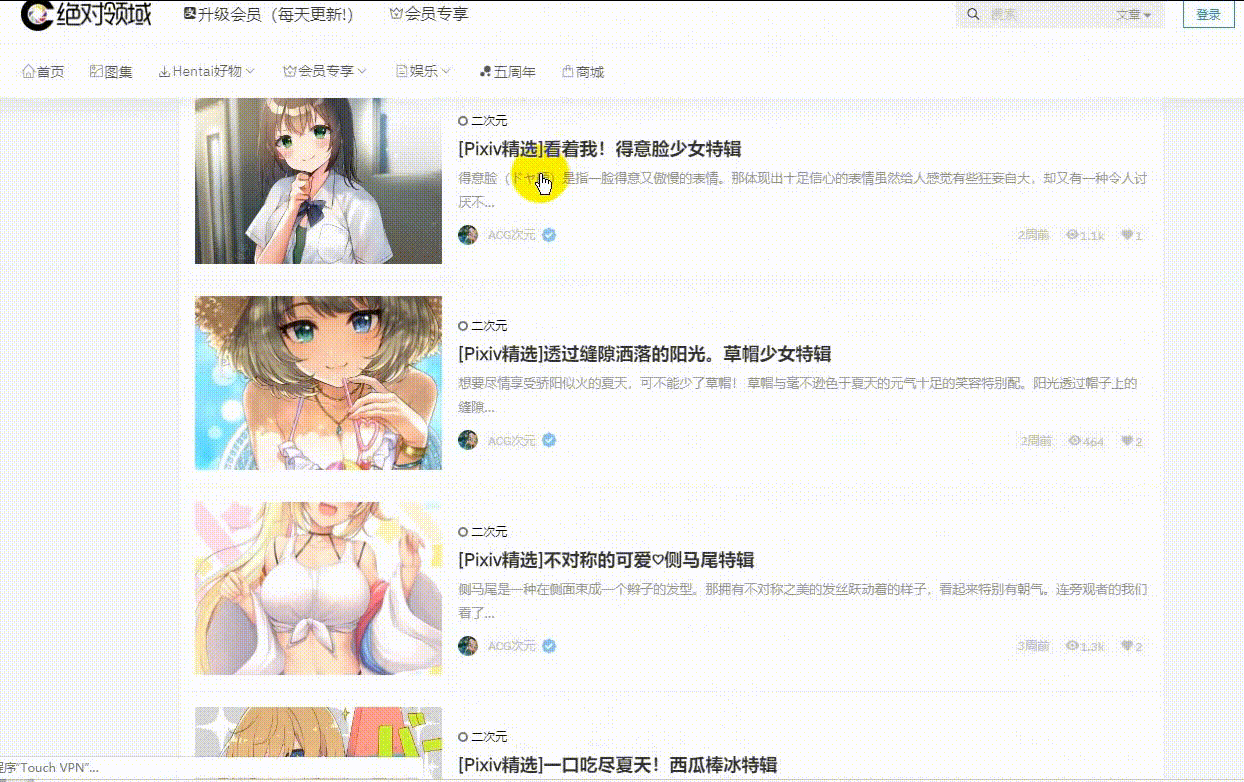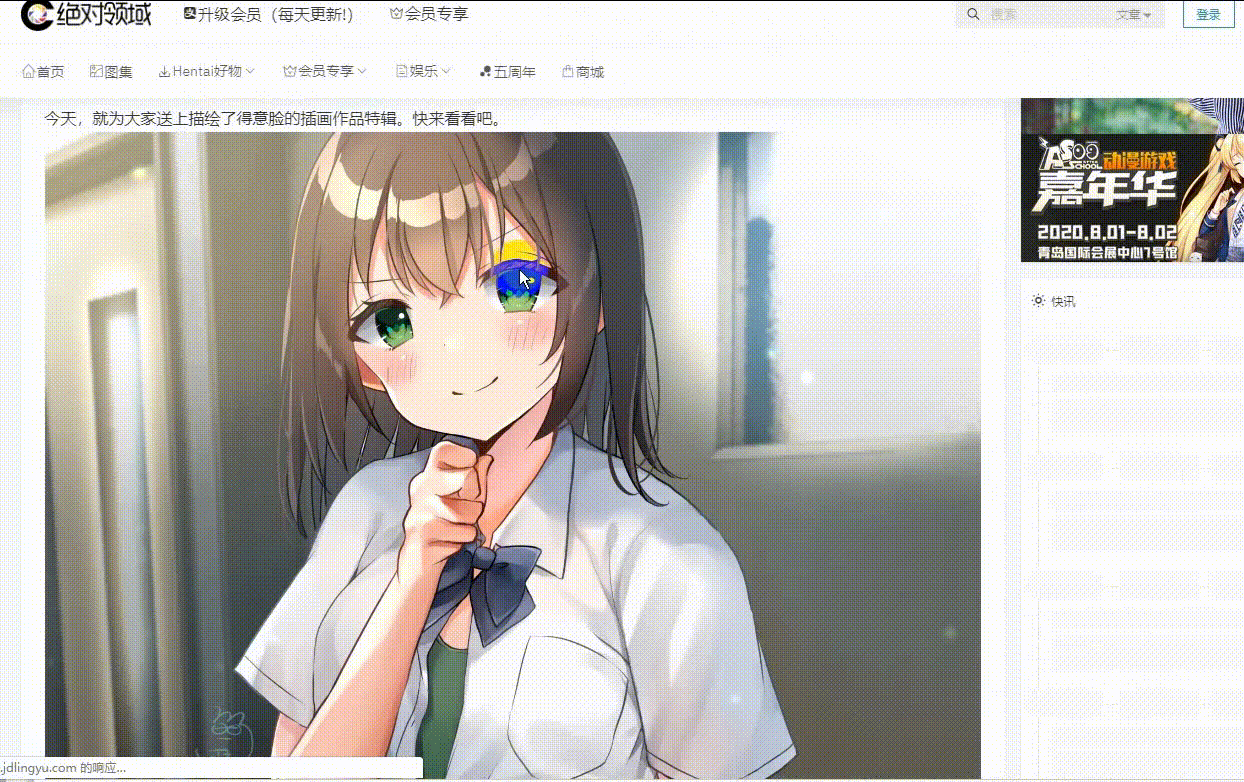
效果动图展示:
工具使用
开发环境:win10、python3.7
开发工具:pycharm、Chrome
工具包:requests,lxml
项目思路解析
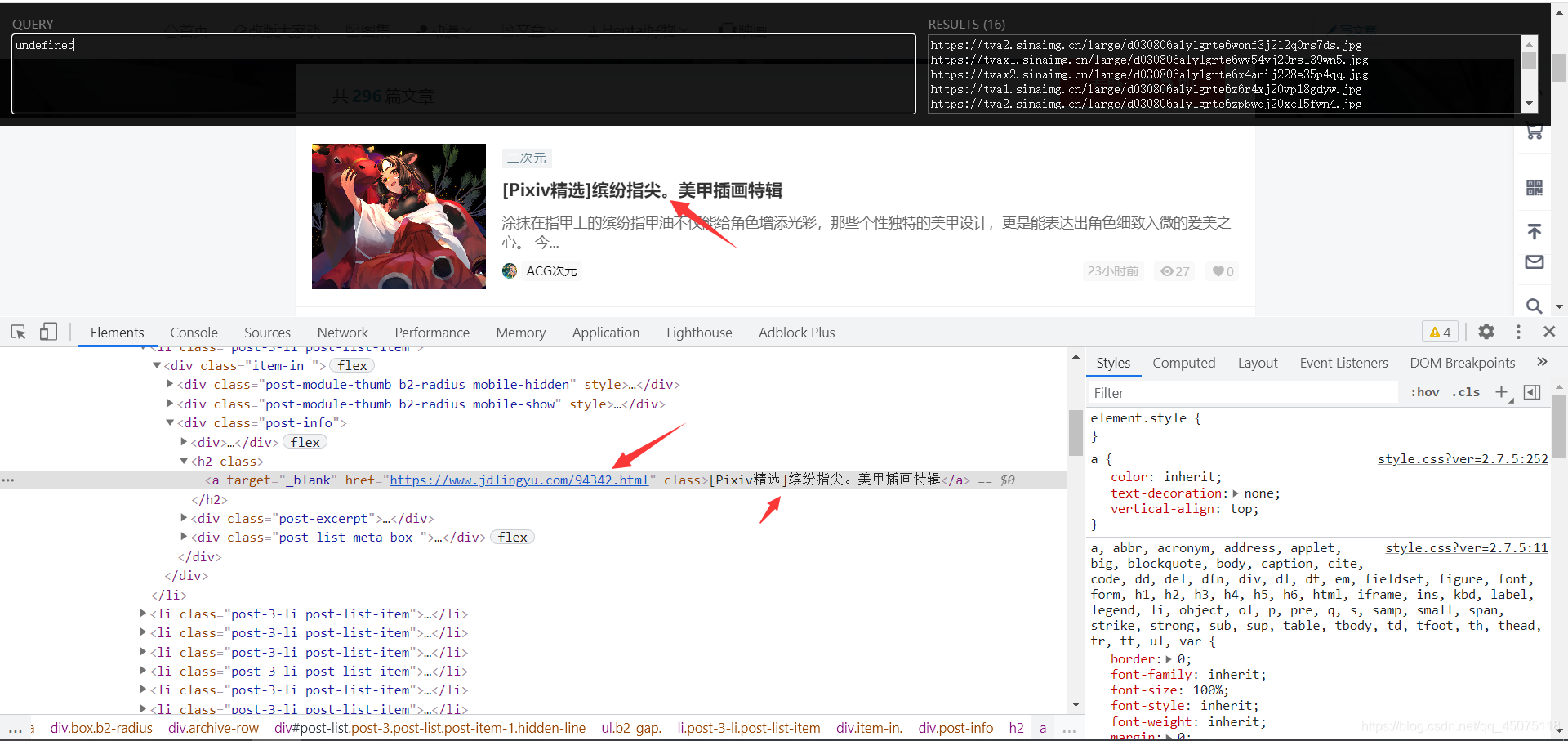
首页获取到当前网页所有的A标签
提取出href以及标题
url = 'https://www.jdlingyu.com/collection/acg/page/' + str(page)
response = requests.get(url)
# print(response.text)
html_data = etree.HTML(response.text)
href_list = html_data.xpath('//h2/a/@href')
name_list = html_data.xpath('//h2/a/text()')
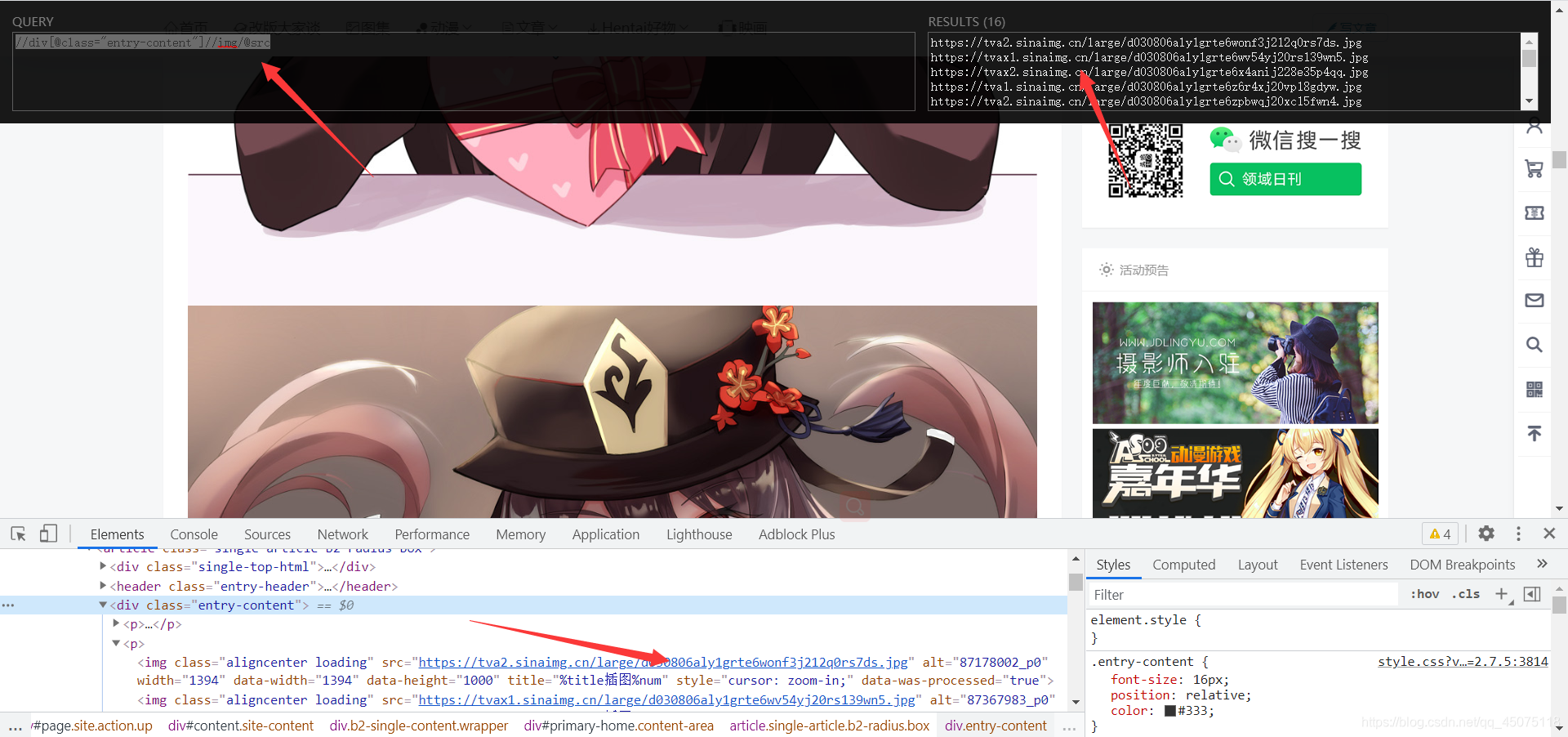
进入详情页面提取出详情页面图片数据
for name, href in zip(name_list, href_list):
res = requests.get(href).text
html = etree.HTML(res)
img_url_list = html.xpath('//div[@class="entry-content"]//img/@src')
保存图片数据信息
简易源码分享
import os
import requests
from lxml import etree
for page in range(1, 2):
url = 'https://www.jdlingyu.com/collection/acg/page/' + str(page)
response = requests.get(url)
# print(response.text)
html_data = etree.HTML(response.text)
href_list = html_data.xpath('//h2/a/@href')
name_list = html_data.xpath('//h2/a/text()')
# print(href_list)
# print(name_list)
for name, href in zip(name_list, href_list):
res = requests.get(href).text
html = etree.HTML(res)
img_url_list = html.xpath('//div[@class="entry-content"]//img/@src')
num = 0
for img_url in img_url_list:
result = requests.get(img_url).content
path = "图片/" + name
if not os.path.exists(path):
os.mkdir(path)
f = open(path + "/" + str(num) + ".jpg", "wb")
f.write(result)
num += 1
print('正在下载{}第{}张'.format(name, num))
❀微信扫一扫关注公众号或加入学习交流技术解答小天地+q裙:881744585❀
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









