







目录
一、什么是范式
范式来自英文Normal Form,简称NF。
实际上你可以把它粗略地理解为 一张数据表的表结构所符合的某种设计标准的级别 。就像家里装修买建材,最环保的是E0级,其次是E1级,还有E2级等等
目前关系数据库有六种范式:第一范式(1NF)、第二范式(2NF)、第三范式(3NF)、巴斯-科德范式(BCNF)、第四范式(4NF)和第五范式5NF,又称完美范式)。
满足最低要求的范式是第一范式(1NF),在第一范式的基础上进一步满足更多规范要求的称为第二范式(2NF),其余范式以次类推。一般来说,数据库只需满足第三范式(3NF)就行了。
二、第一范式
定义: 表中所有属性都不可再分,即数据项不可分。
比如一张表有一个name-age列,这个列具有两个属性,一个name,一个 age,两个属性在一个字段中,所以不符合第一范式。
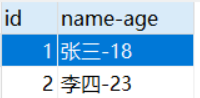
我们把它拆分成两列name和age,这张表就符合第一范式关系。
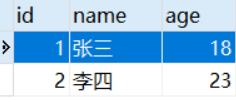
关系型数据库中,例如SQL Server,Oracle,MySQL中创建数据表的时候,1NF是所有关系型数据库设计的最基本要求。
第一范式详细的要求如下:
1、每一列属性都是不可再分的属性值,确保每一列的原子性;
2、两列的属性相近或相似或一样,尽量合并属性一样的列,确保不产生冗余数据;
3、单一属性的列为基本数据类型构成;
4、设计出来的表都是简单的二维表。
三、第二范式
第二范式(2NF)是在第一范式(1NF)的基础上建立起来的,即满足第二范式(2NF)必须先满足第一范式(1NF)。
定义:第二范式(2NF)要求实体的属性完全依赖于主关键字。
现在有一张订单表如下:
| ID(主键) | 订单时间 | 产品ID |
| 1 | 2023-09-25 | 2 |
| 2 | 2023-09-25 | 3 |
这个订单表就不满足第二范式。因为产品ID属性不完全依赖于订单ID主键。,如果存在不完全依赖主键的属性,那么这个属性和主关键字的这一部分应该分离出来形成一个新的实体,新实体与原实体之间是一对多的关系。 我们现在把订单表改成如下:
| ID(主键) | 订单时间 |
| 1 | 2023-09-25 |
| 2 | 2023-09-25 |
| 订单-产品关联ID(主键) | 订单ID | 产品ID |
| 1 | 1 | 1 |
| 2 | 2 | 2 |
四、第三范式
定义:满足第三范式(3NF)前提必须先满足第二范式(2NF)
第三范式(3NF)要求一个数据库表中不包含已在其它表中包含的非主关键字信息,即数据不能存在传递关系,即每个属性都跟主键有直接关系而不是间接关系。
现在有如下订单表,不满足第三范式设计:
| ID(主键) | 订单时间 | 产品ID | 产品名称 |
| 1 | 2023-09-25 | 2 | 镜头 |
| 2 | 2023-09-25 | 3 | 相机 |
因为产品名称已经是产品表的非主键属性了,所以不满足第三范式设计。修改订单表结构如下,满足第三范式:
| ID(主键) | 订单时间 | 产品ID |
| 1 | 2023-09-25 | 2 |
| 2 | 2023-09-25 | 3 |
五、反范式设计及对比
其实反范式设计并不一定不好。为了查询的性能,允许存在部分(少量)冗余数据 。其实反范式设计基本上就是利用空间换时间。
范式与反范式设计的比较如下:
| 操作 | 范式设计 | 反范式设计 |
| 更新操作 | 快 | 慢 |
| 数据冗余 | 低 | 高 |
| 内存占用 | 小 | 大 |
| 查询表关联 | 多 | 少 |
| 查询索引命中 | 较少命中 | 更多命中 |














 302
302











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









