






假设训练的样本集包含m个样例,因为此时对于单个样本我们将神经网络的代价函数定义为:
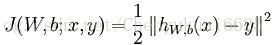
其中hW,b(x)为输入数据x经过神经网络前向传播得到的输出结果,y为期望值。
所以对于这个包含m个样本集的数据集而言,整体的代价函数应为:
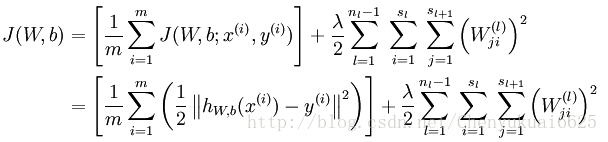
上式关于J(W,b)定义中的第一项是一个均方差项。第二项是一个权重衰减项,其目的是减小权重的幅度,防止过度拟合。nl 表示神经网络的层数。sl表示第 l 层神经元个数,不包含偏置单元。
在实际应用当中,我们使用批量梯度下降算法按照下面的公式来对神经网络的参数(权重W和偏置b)进行优化:
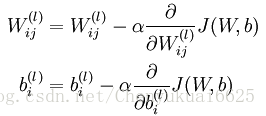
这里的 α 是学习速率,由上式可以发现问题的关键在于如何求解J(W,b)关于W和b的偏导数。这也就引出了本文所说的反向传播算法,它是计算偏导数的很有效的方法。
我们知道整体代价函数J(W,b)跟单个样本代价函数的关系,所以可得:
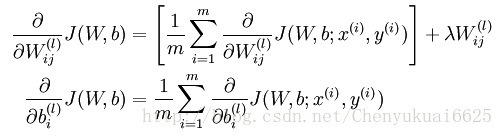
需要说明一点,第一行比第二行多出一项的原因在于权重衰减是作用于 W 而不作用于b上。
现在把原问题转换成对下面两个式子进行偏导求解:
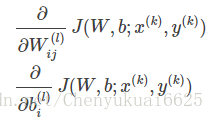
因为第 l+1 层第 i 个神经元的输出 zi(l+1) 由下面的式子计算出:
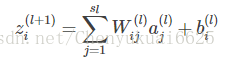
所以可以再进一步的将单个样本的代价函数J(W,b;x,y)对W求导化简为:
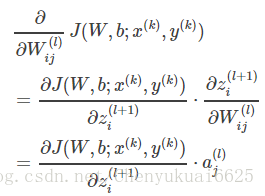
同理,单个样本的代价函数J(W,b;x,y)对b求导可化简为:
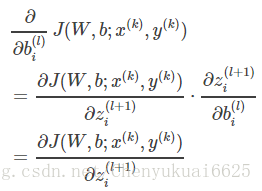
因此问题就被转化为求解每一层每一个神经元所对应的残差。定义第k个样本在第l层第i个神经元上产生的残差如下:
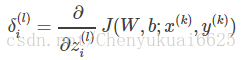
所以此时权值Wij(l)的更新公式为:
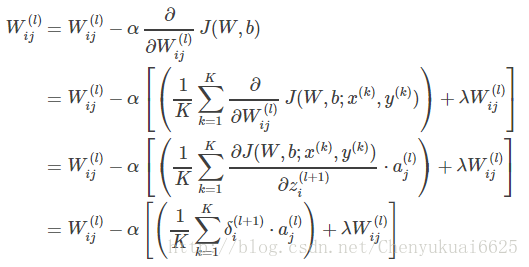
偏置bi(l)的更新公式为:
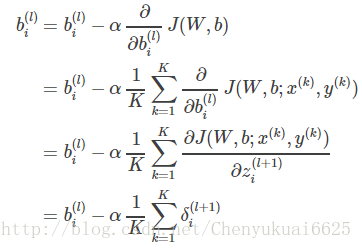
所以现在的核心问题只剩下一个了,就是残差该如何进行求解? 对于第nl层(输出层)的第 i 个神经元,利用下式来求解其对应的残差:
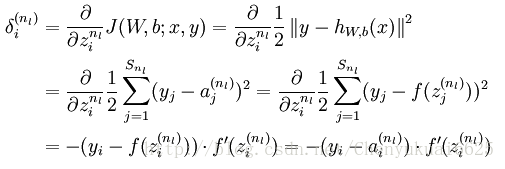
然后计算倒数第二层即第 nl −1层第 i 个神经元的残差:
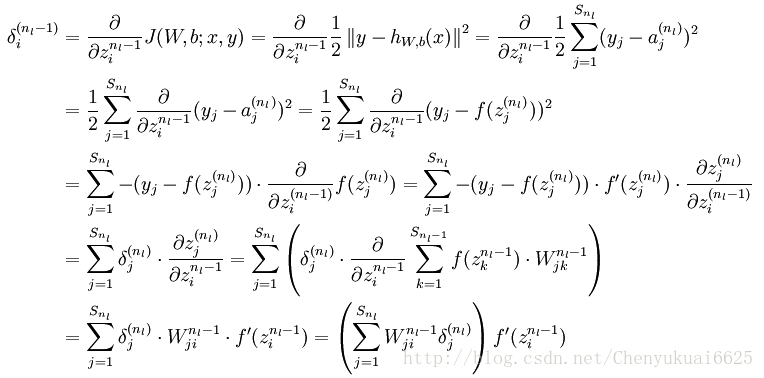
将上式中的 nl −1与 nl的关系替换为l与l+1的关系,就可以得到:
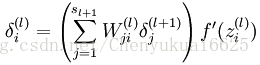
所以单个样本代价函数的偏导数的结果为:
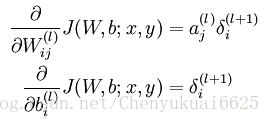
最后将求解得到的偏导数带入权值W和偏置b更新公式中去得到:
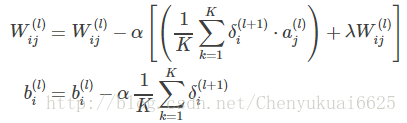
因此,概括下来反向传播算法主要包括以下几个步骤:
(1)进行前馈传导计算,利用前向传导公式,得到L2、L3直到输出层Ln的激活值。
(2)对输出层(第nl层),计算其残差:
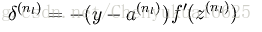
(3)对于l=nl-1,nl-2,…,2的各层,计算其对应的残差:
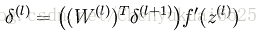
(4)计算出每个神经元对应的偏导数值:
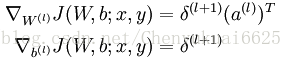
(5)将计算得到的偏导数值带入到权重W和偏置b对应的更新公式中去:
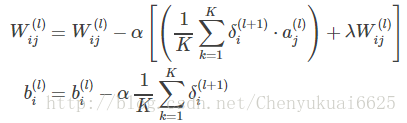















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









