在上一遍《“Spark Streaming + Kafka direct + checkpoints + 代码改变” 引发的问题》中说到,当时是将 topic 的 partition 的 offset 保存到了 MySQL 数据库中,其存在一个问题,就是无法在现有的监控工具中进行体现(如:Kafka Manager)。那我们现在就来将此offset保存到zookeeper中,从而使用监控工具发挥其效果。
一、Kafka Zookeeper 结构
首先,我们来看一下,Kafka在Zookeeper中的结构树,如图(说明:图片来源于网络):
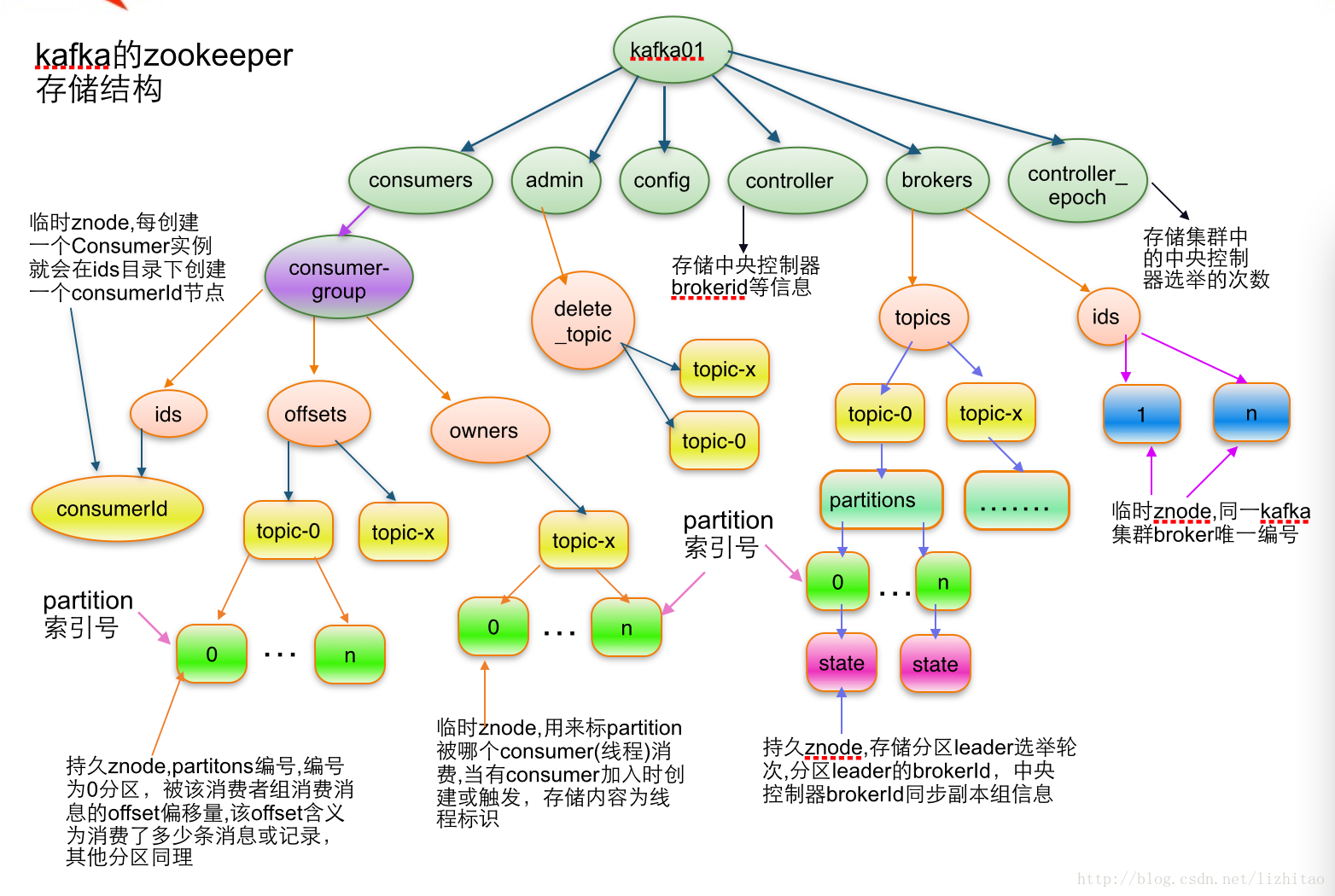
此处,我们主要关心的是 /consumers/[groupId]/offsets/[topic]/[partitionId] -> long (offset) 这个路径,具体含义请看图片上的说明。
由此可见,我们只需要在原来保存到数据库中的内容现在写入到如上路径中即可。
二、具体实现
1、程序实现,如下:
public class SparkStreamingOnKafkaDirect{
public static JavaStreamingContext createContext(){
SparkConf conf = new SparkConf().setMaster("local[4]").setAppName("SparkStreamingOnKafkaDirect");
JavaStreamingContext jsc = new JavaStreamingContext(conf, Durations.seconds(30));
jsc.checkpoint("/checkpoint");
Map<String, String> kafkaParams = new HashMap<String, String>();
kafkaParams.put("metadata.broker.list","192.168.1.151:1234,192.168.1.151:1235,192.168.1.151:1236");
Set<String> topics = new HashSet<String>();
topics.add("kafka_direct");
JavaPairInputDStream<String, String> lines = KafkaUtils.createDirectStream(jsc, String.class,
String.class, StringDecoder.class,
StringDecoder.class, kafkaParams,
topics);
final AtomicReference<OffsetRange[]> offsetRanges = new AtomicReference<>();
JavaDStream<String> words = lines.transformToPair(
new Function<JavaPairRDD<String, String>, JavaPairRDD<String, String>>() {
@Override
public JavaPairRDD<String, String> call(JavaPairRDD<String, String> rdd) throws Exception {
OffsetRange[] offsets = ((HasOffsetRanges) rdd.rdd()).offsetRanges();
offsetRanges.set(offsets);
return rdd;
}
}
).flatMap(new FlatMapFunction<Tuple2<String, String>, String>() {
public Iterable<String> call(
Tuple2<String, String> event)
throws Exception {
String line = event._2;
return Arrays.asList(line);
}
});
JavaPairDStream<String, Integer> pairs = words
.mapToPair(new PairFunction<String, String, Integer>() {
public Tuple2<String, Integer> call(
String word) throws Exception {
return new Tuple2<String, Integer>(
word, 1);
}
});
JavaPairDStream<String, Integer> wordsCount = pairs
.reduceByKey(new Function2<Integer, Integer, Integer>() {
public Integer call(Integer v1, Integer v2)
throws Exception {
return v1 + v2;
}
});
lines.foreachRDD(new VoidFunction<JavaPairRDD<String,String>>(){
@Override
public void call(JavaPairRDD<String, String> t) throws Exception {
ObjectMapper objectMapper = new ObjectMapper();
CuratorFramework curatorFramework = CuratorFrameworkFactory.builder()
.connectString("192.168.1.151:2181").connectionTimeoutMs(1000)
.sessionTimeoutMs(10000).retryPolicy(new RetryUntilElapsed(1000, 1000)).build();
curatorFramework.start();
for (OffsetRange offsetRange : offsetRanges.get()) {
final byte[] offsetBytes = objectMapper.writeValueAsBytes(offsetRange.untilOffset());
String nodePath = "/consumers/spark-group/offsets/" + offsetRange.topic()+ "/" + offsetRange.partition();
if(curatorFramework.checkExists().forPath(nodePath)!=null){
curatorFramework.setData().forPath(nodePath,offsetBytes);
}else{
curatorFramework.create().creatingParentsIfNeeded().forPath(nodePath, offsetBytes);
}
}
}
curatorFramework.close();
});
wordsCount.print();
return jsc;
}
public static void main(String[] args) {
JavaStreamingContextFactory factory = new JavaStreamingContextFactory() {
public JavaStreamingContext create() {
return createContext();
}
};
JavaStreamingContext jsc = JavaStreamingContext.getOrCreate("/checkpoint", factory);
jsc.start();
jsc.awaitTermination();
jsc.close();
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
2、准备测试环境,并记录目前consumer中的信息,如下图:
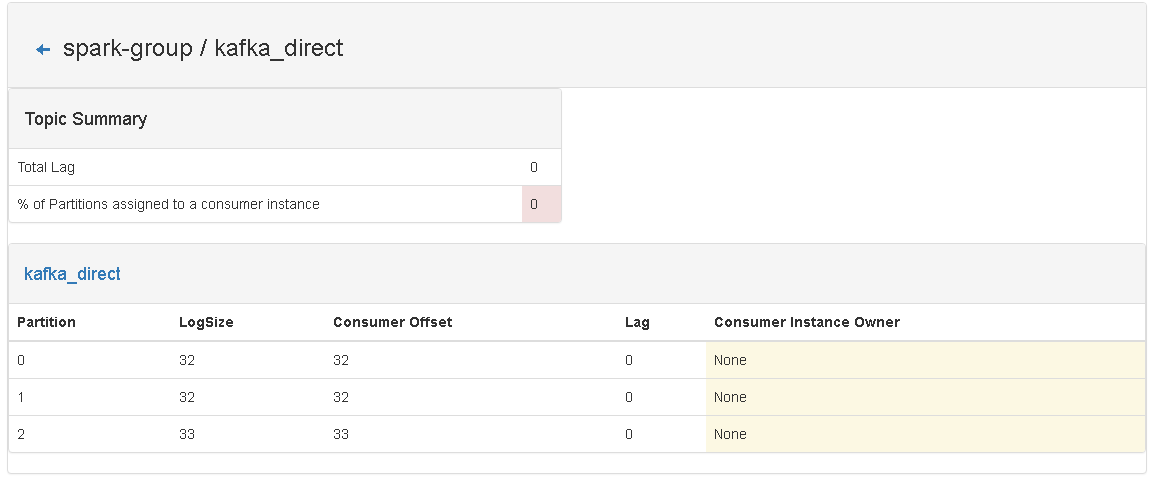
从截图中可以看出,目前 kafka_topic 这个 topic 中,所有的消息都已经被消息了。
说明:由于在写blog之前,我已经运行过代码了,所以可以直接看到数据,如果是第一次运行,则是看到不 spark-group 这个 group 的。
3、运行Spark Streaming 程序(注意:要先清空 checkpoint 目录下的内容),在程序运行的过程中查看 kafka monitor中关于 spark-group的变化情况:
第 n 次 Job 之后:
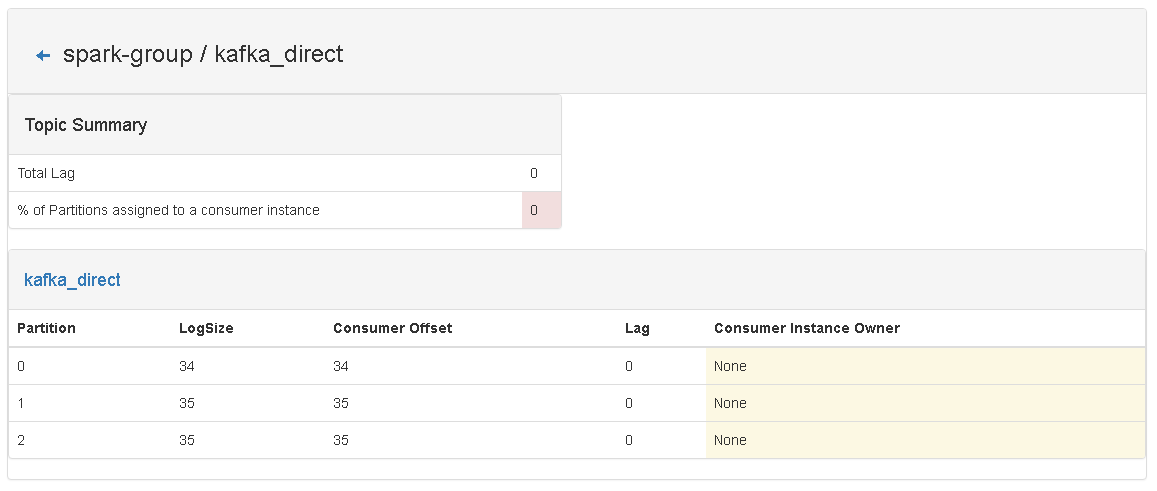
从图片上可以看出,已经起到作用了。
原文链接:http://blog.csdn.net/sun_qiangwei/article/details/52089795

























 3895
3895











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









