







遗传算法(GA)与图同构中的应用
【文中第二部分(2.手工模拟计算)部分转自b2b160的博客,不过b2b160也是转载的,抱歉没有找到原文出处,先谢原作。】b2b160遗产算法
1.发展沿革:
产生
遗传算法(Genetic Algorithms,基因算法,简称GA)的产生和发展是生物学、遗传学、系统科学、计算机科学与技术等科技革命的结果。
提出背景
GA是一种建立在Darwin生物进化论和Mendel群体遗传学基础上的一种算法。自然界中生物体的结构体现了生物对其环境的生存与繁殖能力。自然界总是延续适应性强的物种,淘汰不适应的物种。“适应性”驱使遗传操作,异性结合和变异创造出新的和适应性更强的生物结构。
研究历程
1975年Holland教授发表了标志GA诞生的代表作,但没有受到足够的重视。80年代后,随着计算机技术的进步和人工神经网络、人工生命及机器学习理论的发展,GA在理论和应用方面都得到了较大的发展。
应用
GA的初期应用研究主要围绕组合优化问题求解,近些年来它已迅速地扩展到机器学习、设计规划、系统控制、模式识别、人工生命等众多科学技术领域。
自然界的遗传现象
可以简单看下,观其大略即可。
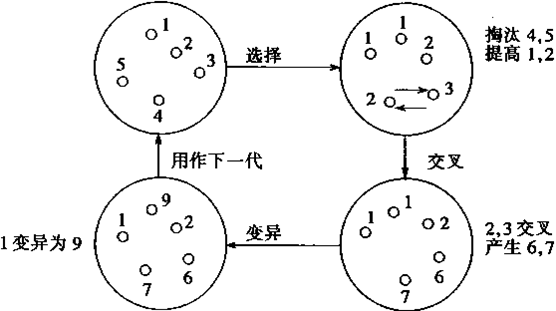
2.遗传算法的手工模拟计算示例
再谢网友。这一部分基于网友博客修订的。
为更好地理解遗传算法的运算过程,下面用手工计算来简单地模拟遗传算法的各个主要执行步骤。可以分为6个步骤,以下(1)-(6)分别说明。
目标问题
求下述二元函数的最大值:
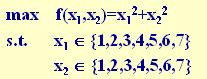
执行步骤
(1) 个体编码
遗传算法的运算对象是表示个体的符号串,所以必须把变量 x1, x2 编码为一种符号串。本题中,用无符号二进制整数来表示。
因 x1, x2 为 0 ~ 7之间的整数,所以分别用3位无符号二进制整数来表示,将它们连接在一起所组成的6位无符号二进制数就形成了个体的基因型,表示一个可行解。
例如,基因型 X=101110 所对应的表现型是:x=[ 5,6 ]。
5=1*2^2+0*2^1+1*2^0=4+0+1=5;
个体的表现型x和基因型X之间可通过编码和解码程序相互转换。
(2) 初始群体的产生
遗传算法是对群体进行的进化操作,需要给其淮备一些表示起始搜索点的初始
群体数据。
本例中,群体规模的大小取为4,即群体由4个个体组成,每个个体可通过随机
方法产生。
如:011101,101011,011100,111001
(3) 适应度汁算
遗传算法中以个体适应度的大小来评定各个个体的优劣程度,从而决定其遗传
机会的大小。
本例中,目标函数总取非负值,并且是以求函数最大值为优化目标,故可直接
利用目标函数值作为个体的适应度。
例如,基因型 X=101110 所对于的适应度是25+36=61。
(4) 选择运算
选择运算(或称为复制运算)把当前群体中适应度较高的个体按某种规则或模型遗传到下一代群体中。一般要求适应度较高的个体将有更多的机会遗传到下一代群体中。
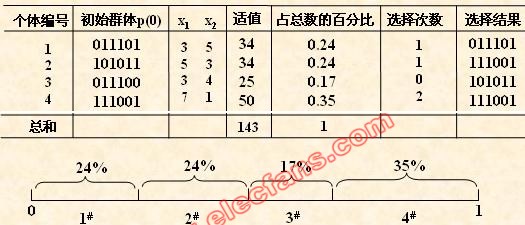
本例中,我们采用与适应度成正比的概率来确定各个个体复制到下一代群体中的数量。其具体操作过程是:
• 先计算出群体中所有个体的适应度的总和 ∑fi ( i=1.2,…,M );
• 其次计算出每个个体的相对适应度的大小 fi / ∑fi ,它即为每个个体被遗传
到下一代群体中的概率,
• 每个概率值组成一个区域,全部概率值之和为1;
• 最后再产生一个0到1之间的随机数,依据该随机数出现在上述哪一个概率区
域内来确定各个个体被选中的次数。
(5) 交叉运算
交叉运算是遗传算法中产生新个体的主要操作过程,它以某一概率相互交换某
两个个体之间的部分染色体。
本例采用单点交叉的方法,其具体操作过程是:
• 先对群体进行随机配对;
• 其次随机设置交叉点位置;
• 最后再相互交换配对染色体之间的部分基因。
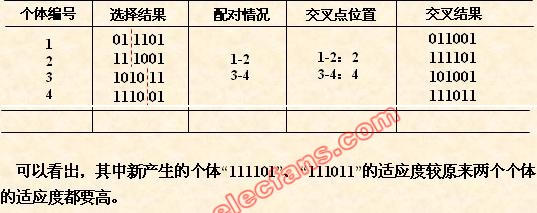
如图,第一步。编号为1和编号2的两个个体被随机配对,分别是011101和111001交叉运算在配对的个体之间发生。
第二步。随机选择一个交叉点位置,假设选择第二个基因位置。那么我就得到了四个基因片段。片段1:01,片段2:1101;片段3:11;片段4:1001。现在片段1和片段2是一个个体;片段3和片段4是一个个体。
第三步。我们回想一下高中生物课程精卵细胞染色体交叉的过程。这四个基因片段类似地进行交叉互换,重新组合为011001(片段1+片段4),111101(片段3+片段2).
经过以上三步,新的个体生成了。相当于产生了新的解,再次强调交叉运算是遗传算法中产生新个体的主要操作过程。
(6) 变异运算
变异运算是对个体的某一个或某一些基因座上的基因值按某一较小的概率进
行改变,它也是产生新个体的一种操作方法。作用1:丰富基因;作用2:跳出当前搜索区域。
本例中,我们采用基本位变异的方法来进行变异运算,其具体操作过程是:
• 首先确定出各个个体的基因变异位置,下表所示为随机产生的变异点位置,
其中的数字表示变异点设置在该基因座处;
• 然后依照某一概率将变异点的原有基因值取反。
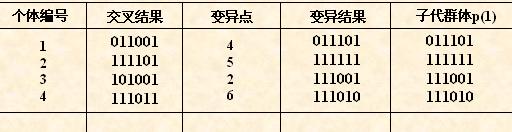
以个体编号1的基因011101为例,随机选择变异位置为4,那么011 1 01变为011 0 01。
对群体P(t)进行一轮选择、交叉、变异运算之后可得到新一代的群体p(t+1)。
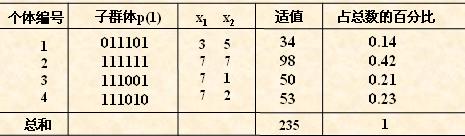
从上表中可以看出,群体经过一代进化之后,其适应度的最大值、平均值都得
到了明显的改进。事实上,这里已经找到了最佳个体“111111”。
[说明]
需要说明的是,表中有些栏的数据是随机产生的。这里为了更好地说明问题,
我们特意选择了一些较好的数值以便能够得到较好的结果,而在实际运算过程中
有可能需要一定的循环次数才能达到这个最优结果。
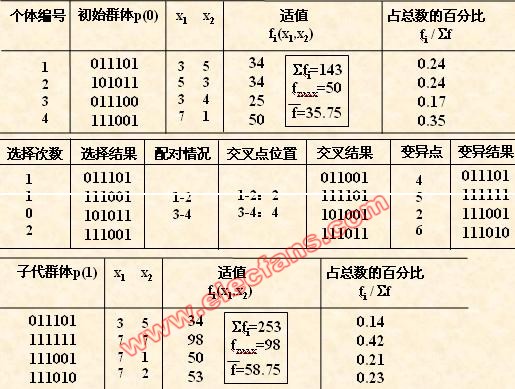
小结: 算法流程
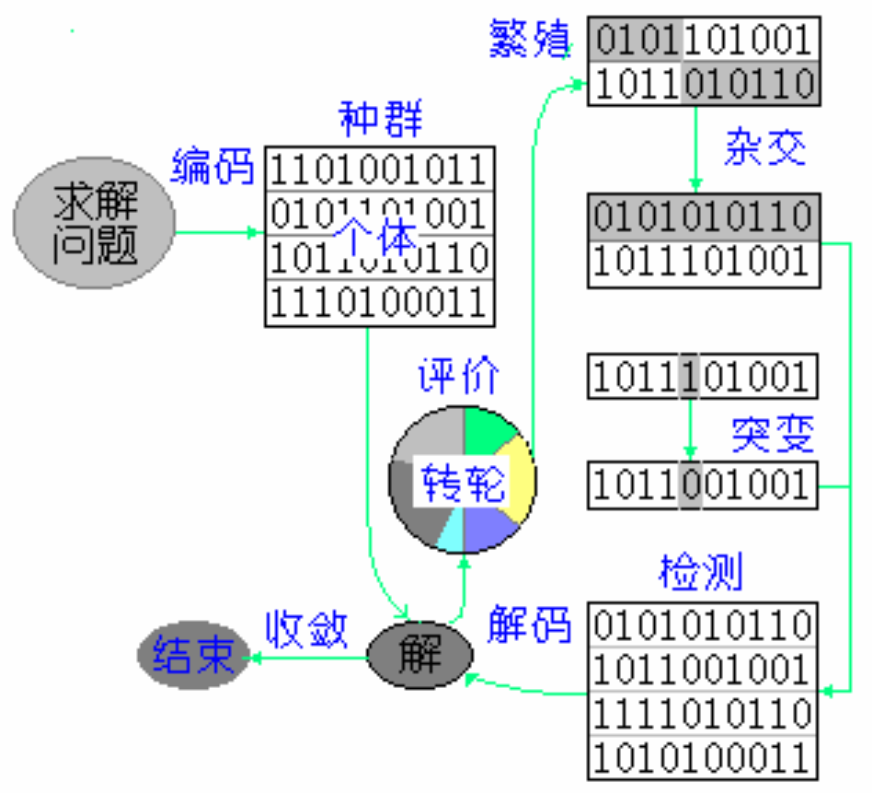
3.图同构问题中的应用
如何实现从数学工具模型到具体科研问题的飞跃是十分重要的。这一部分抛砖引玉,举例说明GA算法的应用方法。
参考论文:A Genetic and Iterative Local Search Algorithm forsolving Subgraph Isomorphism Problem
图是表达数据类型最有效的方式之一,如虚拟网络映射(Virtual Network Embedding)问题可以转化为图论中图嵌入的问题。
思路
愚以为:GA算法建模关键步骤在于编码和 适应度计算 。
交叉、变异、选择等步骤是优化步骤。建模和优化都很重要,但是建模是研究的基础。
邻接矩阵是图表征的常用方法。如果我们将矩阵的每一行作为一个基因,然后拼接起来就组成染色体。邻接矩阵的权值如果设为链路带宽(边的大小),那么对其进行二进制编码,就得到了遗传算法的运算对象:表示个体的符号串。
参考论文就是提出一种用改进的遗传算法解决图论中的子图同构问题。
具体来说:
编码:用一个N维的向量表示图G的一个子图{V1,V2,…,Vn}。目标子图也可用一个N维向量表示。
适应度计算 :可以根据目标子图构造一个适应度函数。序列相似度越高,适应度越大。当这个适应度函数达到1时同构子图被找到,否则继续迭带。
优化:论文中引入了本地迭带搜索ILS,来辅助优化。
小结:虚拟网络映射问题可以建模为一个子图同构问题,子图同构问题可以采用GA算法来解决。
4.matlab仿真
由于GA研究成熟,可直接借助谢菲尔德Matlab遗传工具箱,下载安装即可。是用M文件编写的,可以看到源码,提供了多样的使用函数。
安装成功提示:
举例:
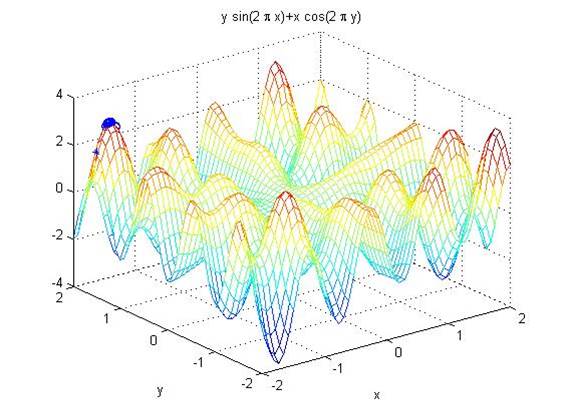
Z=F(x,y)=xcos(2*pi*y)+ysin(2*pi*x) x,y属于[-2,2]
最优解:
X=-1.7666
Y=1.5142
Z=3.2655
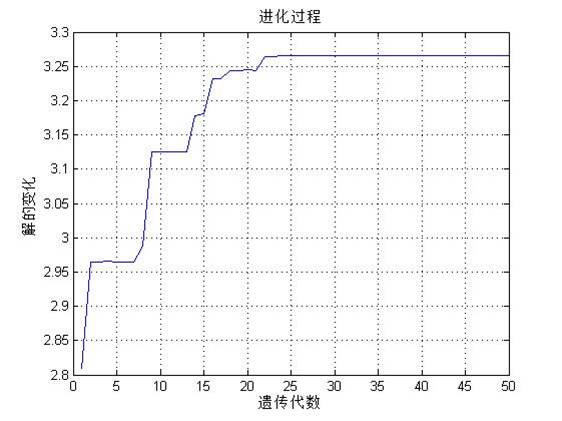
可以看到,这种遗传策略下,子代最优个体强于上一代,这也是遗产的思想,优势基因留存和发展,Z值不断逼近最优值。















 4083
4083











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









