







一、hashCode和hashCode()
hashCode 是 jdk 根据对象的地址或者字符串或者数字算出来的 int 类型的数值。public int hashCode()返回该对象的哈希码值。支持此方法是为了提高哈希表(如java.util.Hashtable提供的哈希表)的性能。
1️⃣理解
虽然 Set 同 List 都实现了 Collection 接口,但是二者实现方式却大不一样。List 基本上是以 Array 为基础。而 Set 则是在 HashMap 的基础上实现的,这是二者的根本区别。HashSet 的存储方式是把 HashMap 中的 Key 作为 set 的对应存储项。看看 HashSet 的 add(Object obj) 实现就可以知晓。
hashCode() 是 Java 所有对象的固有方法,如果不重写,返回的实际上是该对象在JVM的堆上的内存地址。不同对象的内存地址肯定不同,所以 hashCode 值必然不同。如果重写了,由于采用的算法的不同,有可能导致两个不同对象的 hashCode 相同。而且,还需要注意以下几点:
- hashCode 和 equals 两个方法是有语义关联的,它们需要满足:
a.equals(b)==true ---> a.hashCode()==b.hashCode()
因此重写其中一个方法时必须将另一个也重写。
-
hashCode 的重写需要满足不变性,即一个 object 的 hashCode 不能一会是 1,一会是 2。hashCode 的重写最好依赖于对象中的final属性,从而在对象初始化构造后就不再变化。一方面是JVM便于代码优化,可以缓存这个 hashCode;另一方面,在使用 HashMap 或 HashSet 的场景中,如果使用的 key 的 hashCode 会变,将会导致 bug,比如 put 时 key.hashCode()=1,get 时 key.hashCode()=2 了,就会获取不到原先的数据。
-
哈希表结合了直接寻址和链式寻址两种方式。所需要的就是将需要加入哈希表的数据首先计算哈希值,其实就是预先分个组,然后再将数据挂到分组后的链表后面,随着添加的数据越来越多,分组链上会挂接更多的数据,同一个分组链上的数据必定具有相同的哈希值,Java 中的 hashCode() 返回的是 int 类型的,也就是说,最多允许存在 2^32 个分组,也是有限的,所以出现相同的哈希码就不稀奇。
二、散列表数据结构(哈希表)
1️⃣含义
散列表(Hashtable,也叫哈希表),是根据关键码值(Key value)而直接进行访问的数据结构。也就是说,它通过把关键码值映射到表中一个位置来访问记录,以加快查找的速度。这个映射函数叫做散列函数,存放记录的数组叫做散列表。给定表 M,存在方法 f(key),对任意给定的关键字值 key,代入方法后若能得到包含该关键字的记录在表中的地址,则称表 M 为哈希(Hash)表,方法 f(key) 为哈希(Hash)方法。
2️⃣HashMap 底层就是散列表数据结构,即数组和链表的结合体,底层是一个数组结构,数组中存储的值又是一个链表。这样做有什么好处呢?数组能够提供对元素的快速访问但不易于扩展(如果不知道元素下标,还得进行遍历查找),链表易于扩展但不能对其元素进行快速访问。怎样做到两全其美,就是散列表数据结构。
3️⃣HashMap 中元素存跟取的实现方式。HashMap 根据 key 的 hashCode 计算出元素在 Entry 数组中的位置,然后在 Entry 内部链表中存放 key,value。
4️⃣性能分析
因为元素的存取是通过 hash 算法进行的,所以速度都很快。在查找操作中,唯一影响性能的是在链表中,但实际只要优化好了 key 对象 hashCode 方法跟 equals 方法,就会避免链表中的数据过多而导致查找性能变慢。
再一个非常影响性能的是数组扩容操作,当使用默认的DEFAULT_INITIAL_CAPACITY对 HashMap 进行初始化的时候,如果元素个数非常多,会导致扩容次数增加,每次扩容都会进行元素位置的重新分配,这是相当耗费性能的。如果能预算好元素个数,就应该避免使用默认的DEFAULT_INITIAL_CAPACITY,可在 HashMap 的构造函数中为其指定一个初始值。
5️⃣问题解决
hashCode 必须和 equals 保持兼容(equals() 的判断依据和计算 hashCode 的依据相同),这样做是为了避免链表中的数据过多。
三、为何不同对象的hashCode有可能相同
定义一个类,重写 hashCode() 和 equals(Object obj):
public class A {
@Override
public boolean equals(Object obj) {
System.out.println("判断equals:" + obj.getClass());
return false;
}
@Override
public int hashCode() {
System.out.println("判断hashcode");
return 1;
}
}
测试类如下:
public class test {
public static void main(String[] args) {
Map<A, Object> map = new HashMap<>();
map.put(new A(), new Object());
map.put(new A(), new Object());
System.out.println(map.size());
}
}
执行结果:
判断hashcode
判断hashcode
判断equals:class com.xxp.mchopin.A
2
可以看出,Java 运行时环境会调用new A()这个对象的 hashcode()。其中:输出的第一行“判断hashcode”是第一次map.put(new A(), new Object())执行的。接下来的“判断hashcode”和“判断equals”是第二次map.put(new A(), new Object())执行的。
为什么是这种情况呢?
- 当第一次
map.put(new A(), new Object())的时候,Java 运行时环境就会判断这个 map 里面有没有和现在添加的 new A() 相同的键,判断逻辑:调用 new A() 的 hashcode(),判断 map 中当前是不是存在和 new A() 对象相同的 hashCode。显然没有,因为这个 map 中还没有东西。所以这时候 hashcode 不相等,则没有必要再调用 equals(Object obj) 了。如果两个对象hashcode不相等,它们一定不equals。 - 当第二次
map.put(new A(), new Object())的时候,Java 运行时环境再次判断,这时候发现 map 中有两个相同的 hashcode (因为重写了 A 类的 hashcode() 永远都返回1),所以有必要调用 equals(Object obj) 进行判断。如果两个对象hashcode相等,它们不一定equals然后发现两个对象不 equals (因为重写了 equals(Object obj),永远都返回 false)。 - 判断结束。结果:两次存入的对象不是相同的对象。所以最后输出 map 的长度为 2。
改写程序如下:
class A {
@Override
public boolean equals(Object obj) {
System.out.println("判断equals:" + obj.getClass());
return true;
}
@Override
public int hashCode() {
System.out.println("判断hashcode");
return 1;
}
}
public class Test {
public static void main(String[] args) {
Map<A,Object> map = new HashMap<A, Object>();
map.put(new A(), new Object());
map.put(new A(), new Object());
system.out.println(map.size());
}
}
运行之后打印结果是:
判断hashcode
判断hashcode
判断equals:class com.xxp.mchopin.A
1
这时候 map 的长度为 1,因为 Java 运行时环境认为存入了两个相同的对象。HashSet 的底层是通过 HashMap 实现的,所以它的判断原理和 HashMap 一样,也是先判断 hashcode 再判断 equals。
四、重写 equals 时必须重写 hashcode
HashMap 存储数据的时候,是取的 key 的哈希值,然后计算数组下标,采用链地址法解决冲突,然后进行存储。取数据的时候,依然是先要获取到哈希值,找到数组下标,然后 for 遍历链表集合,进行比较是否有对应的 key。比较关心的有两点:
- 无论是 put 还是 get 的时候,都需要得到 key 的哈希值,去定位 key 的数组下标;
- 在 set 的时候,需要调用 equals() 比较是否有相等的 key 存储过。

上面代码,Map 的 key 是自定义的一个类。这里没有重写 equal 方法,更没重写 hashCode 方法,意思是 map 在进行存储的时候是调用的 Object 类中 equals 方法和 hashCode 方法。为此,输出 hashCode 码:
hashCode 不一致,因此拿不到数据。这两个 key,在 Map 计算的时候,数组下标可能就不一致,就算数据下标碰巧一致,根据前面,最后 equals 比较的时候也不可能相等(两个对象,在堆上的地址必定不一样)。假如重写了 equals,将这两个对象都 put 进去,根据 map 的原理,只要是 key 一样,后面的值会替换前面的值,测试如下:
输出结果:
instance value:1
newInstance value:2
同样的一个对象,为什么在 map 中存了两份,map 的 key 值不是不能重复吗?
没错,它就是存的两份。只不过在它看来,这两个key是不一样的,因为它们的哈希码就是不一样的,可以看下输出的 hash 码确实不一样。那怎么办?只有重写 hashCode(),代码更改如下: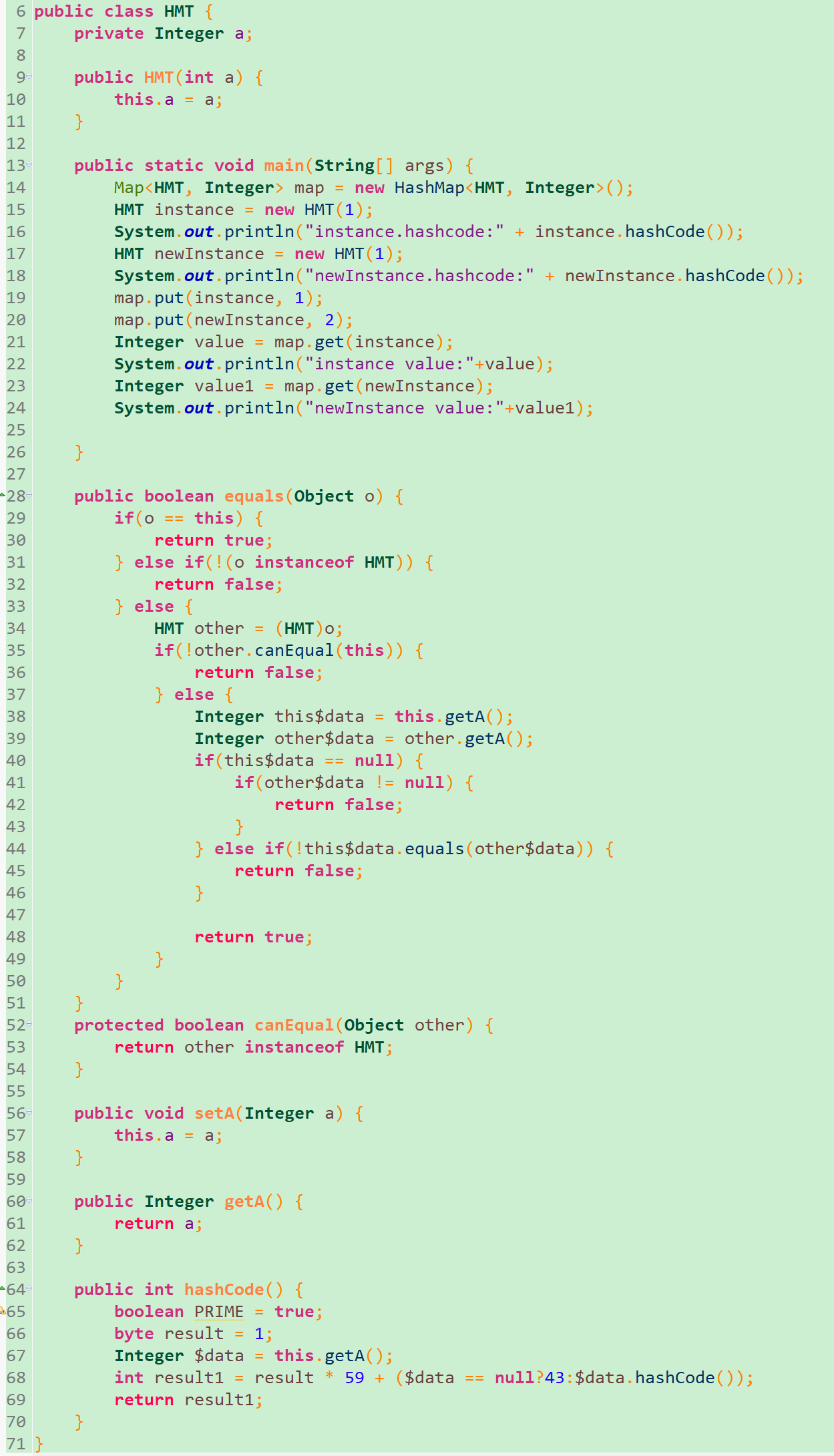
它们的 hash 码是一致的,最后的结果符合预期。
五、总结
Map 中存了两个数值一样的 key,这个问题很严重。所以在重写 equals() 的时候,一定要重写 hashCode()。类似 HashMap、HashTable、HashSet 这种的都要考虑到散列的数据类型的运用。
- 重写 equals(),就必须重写 hashCode()。
- equals() 默认比较对象的地址,使用的是
==等值运算符。 - hashCode() 对底层是散列表的对象有提升性能的功能。
- 同一个对象(如果该对象没有被修改):那么重复调用 hashCode() 返回的 int 值是相同的。
- hashCode() 默认是由对象的地址转换而来的。
- 传入的参数为 null,返回的是 false。















 4万+
4万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











