







以 JDK8 的 HashMap 为例。

1️⃣情况一:
线程甲和线程乙共同对 HashMap 进行 put 操作。假设甲乙插入的 Key-Value 中 key 的 hashcode 是相同的,这说明该键值对将会插入到 Table 的同一个下标的位置,会发生哈希碰撞,此时 HashMap 按照平时的做法是形成一个链表(若超过八个节点则是红黑树)。现在插入的下标为 null(Table[i]==null) 则进行正常的插入,此时线程甲进行到了这一步正准备插入,被堵塞,线程乙获得运行时间,进行同样操作,也是 Table[i]==null,此时它直接运行完整个 put 方法,成功将元素插入。随后线程甲获得运行时间接着上面的判断继续运行,进行了 Table[i]==null 的插入(此时实际是 Table[i]!=null 的操作,因为前面线程乙已经插入元素了),这样就会直接覆盖线程乙插入的数据,如此非线程安全。在 hashmap 做 put 操作的时候会调用到以下的方法:
void addEntry(int hash, K key, V value, int bucketIndex) {
Entry<K,V> e = table[bucketIndex];
table[bucketIndex] = new Entry<K,V>(hash, key, value, e);
if (size++ >= threshold)
resize(2 * table.length);
}
甲乙线程同时对同一个数组位置调用 addEntry,两个线程会同时得到现在的头结点,然后甲写入新的头结点之后,乙也写入新的头结点,那乙的写入操作就会覆盖甲的写入操作造成甲的写入操作丢失。
2️⃣情况二:
void transfer(Entry[] newTable, boolean rehash) {
int newCapacity = newTable.length;
for (Entry<K,V> e : table) {
while(null != e) {
Entry<K,V> next = e.next;
if (rehash) {
e.hash = null == e.key ? 0 : hash(e.key);
}
int i = indexFor(e.hash, newCapacity);
e.next = newTable[i];
newTable[i] = e;
e = next;
}
}
}
这种情况是 resize 的时候造成的。假设 HashMap 中的 Table 情况如下:
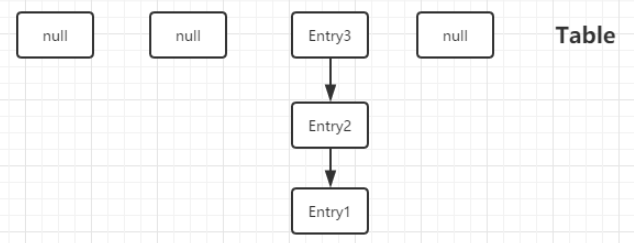
甲乙线程要对同一个 HashMap 进行 put 操作。插入后 Table 变为:
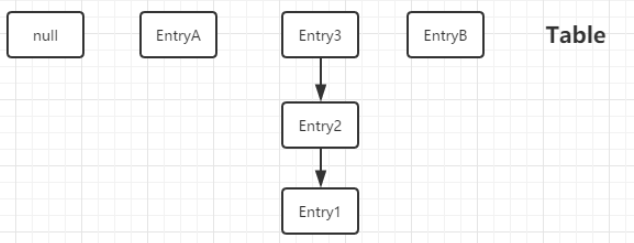
此时线程甲乙都需要对 HashMap 进行扩容。假设线程甲没有堵塞,顺利完成 resize 后 Table 如下(这里的元素位置都是假设的):
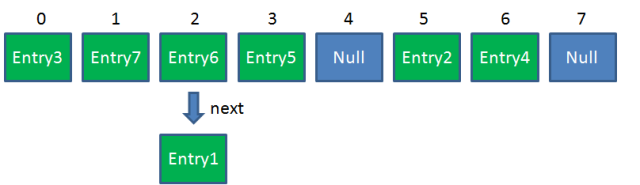
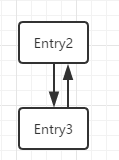
如果线程乙的 resize 是在 Entry3 的时候堵塞的,那么当它再次执行的时候就会造成如下图处形成一个循环链表,当进行 get 操作时候可能陷入死循环。

原因是:
线程乙获得 CPU 时e = Entry3,next = Entry2; 正常赋值,然后进行下一次循环遍历时要注意,此时 HashMap 已经是被线程甲 resize 过的了,那么就有 e = Entry2,next = Entry3;头插法插入此时:

接着循环,e = Entry3,next = Entry3.next = null(看图),此时再头插就会形成循环链表了。
头插法代码:

当多个线程同时检测到总数量超过门限值的时候就会同时调用 resize 操作,各自生成新的数组并 rehash 后赋给该 map 底层的数组 table,结果最终只有最后一个线程生成的新数组被赋给 table 变量,其他线程的均会丢失。而且当某些线程已经完成赋值而其他线程刚开始的时候,就会用已经被赋值的 table 作为原始数组,这样也会有问题。
















 660
660











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











