







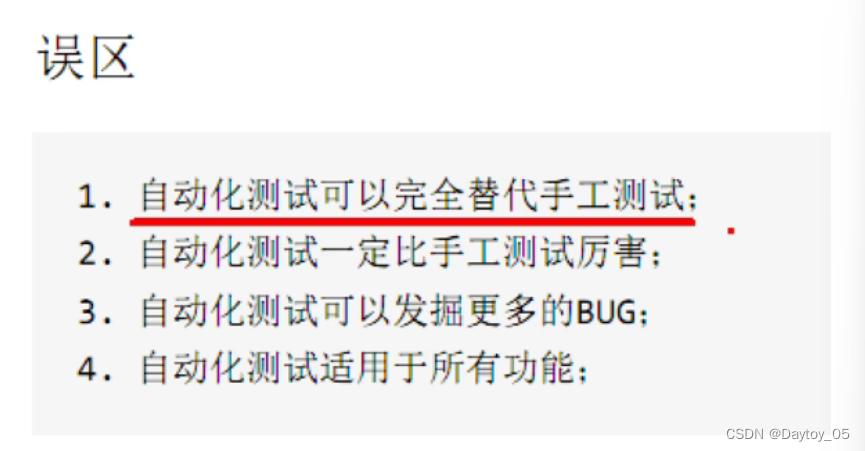
自动化理论

回归测试: 在进行软件升级、修改或修复bug后,对系统进行回归测试,以确保修改过的部分没有引入新的问题或破坏其他功能。回归测试通常是自动化执行的,并且可以通过比较测试前后的结果来确定系统的稳定性。
压力测试: 对软件系统进行在正常工作负载之外的高负载测试,以观察系统在极限情况下的表现。通过模拟多用户同时访问或大量数据输入等场景,来评估系统在压力下的性能表现和稳定性。
兼容性测试: 在各种不同的硬件、操作系统、浏览器等环境下测试软件系统的兼容性。通过模拟不同的用户设备和环境,来确保系统在各种情况下都能正常运行,并提供一致的用户体验。兼容性测试通常涵盖功能测试、UI测试、性能测试等方面。
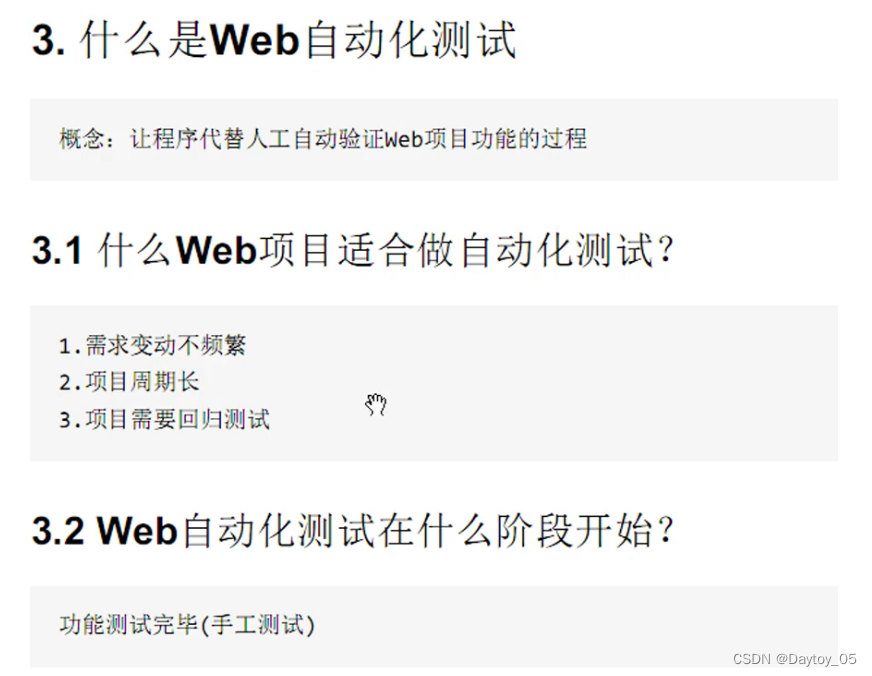
Web自动化测试:

Web:基于浏览器 基于HTTP/HTML
移动:App
接口:基于工具和代码
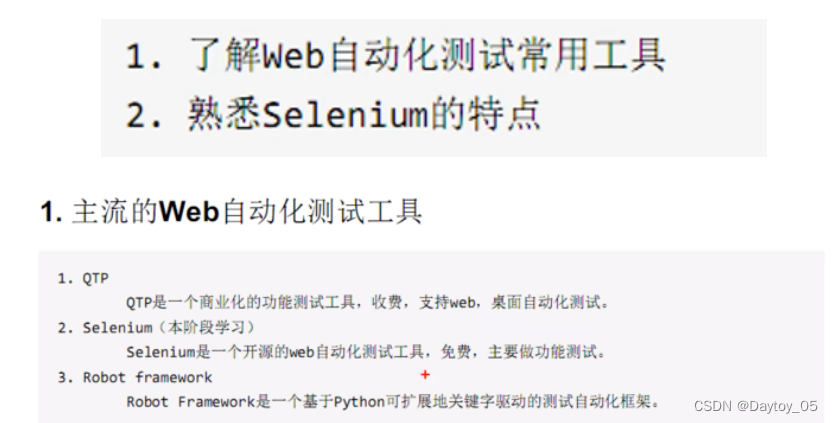
单元测试
黑盒测试:功能测试
白盒测试:单元测试 代码
灰盒测试:接口测试
Web自动化属于黑盒测试(功能测试)
selenium



from time import sleep
from selenium import webdriver
driver = webdriver.Edge()
driver.get('http://www.baidu.com')
sleep(3)
driver.quit()元素定位

元素定位方式:

id,name,class_name 基于元素属性
id定位:通过元素的id属性定位,id一般情况下在当前页面是唯一
class_name -> 使用元素的class属性定位
tag_name 基于元素的标签名称 <标签名称
link_text 定位a标签 超链接
partial_link_text 定位a标签 超链接 模糊
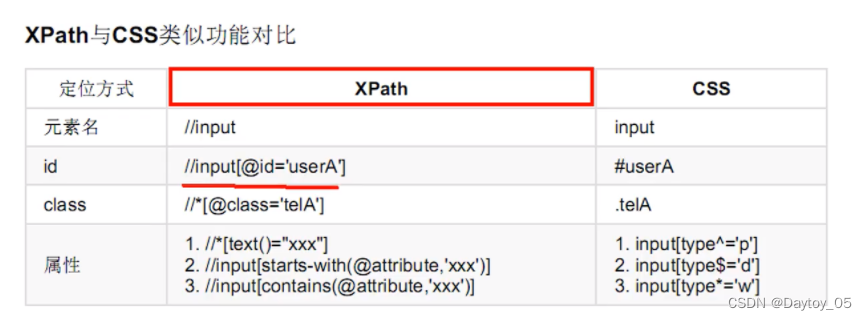
XPath (基于元素路径)
CSS (基于元素选择器)
id属性定位

# id 定位
# 导包
from selenium import webdriver
from time import sleep
# 获取浏览器对象
driver = webdriver.Edge()
# \反斜杠在python中是转义字符 r修饰的字符串 如果字符串中有转义字符 不进行转义
# 使用双反斜杠 \\ 进行转义操作
# 使用本地浏览模式 前缀加file:///
url = r"D:\WORK\ww\web自动化_day01_课件+笔记+资料+代码\web自动化_day01_课件+笔记+资料+代码\02_其他资料\注册A.html"
driver.get(url)
# 查找用户名元素
username = driver.find_element_by_id("userA")
# 查找密码元素
password = driver.find_element_by_id("passwordA")
username.send_keys("admin")
password.send_keys("123456")
sleep(3)
driver.quit()from selenium import webdriver
from time import sleep
driver = webdriver.Edge()
driver.get("file:///D:/WORK/ww/web%E8%87%AA%E5%8A%A8%E5%8C%96_day01_%E8%AF%BE%E4%BB%B6+%E7%AC%94%E8%AE%B0+%E8%B5%84%E6%96%99+%E4%BB%A3%E7%A0%81/web%E8%87%AA%E5%8A%A8%E5%8C%96_day01_%E8%AF%BE%E4%BB%B6+%E7%AC%94%E8%AE%B0+%E8%B5%84%E6%96%99+%E4%BB%A3%E7%A0%81/02_%E5%85%B6%E4%BB%96%E8%B5%84%E6%96%99/%E6%B3%A8%E5%86%8CA.html")# 直接复制的
driver.find_element_by_id("userA").send_keys("admin")
driver.find_element_by_id("passwordA").send_keys("123456")
sleep(3)
driver.quit()name属性定位
# name定位
from selenium import webdriver
from time import sleep
driver = webdriver.Edge()
driver.get(r"D:\WORK\ww\web自动化_day01_课件+笔记+资料+代码\web自动化_day01_课件+笔记+资料+代码\02_其他资料\注册A.html")
driver.find_element_by_name("userA").send_keys("admin")
driver.find_element_by_name("passwordA").send_keys("123456")
sleep(3)
driver.quit()
class name属性定位
from selenium import webdriver
from time import sleep
driver = webdriver.Edge()
driver.get(r"D:\WORK\ww\web自动化_day01_课件+笔记+资料+代码\web自动化_day01_课件+笔记+资料+代码\02_其他资料\注册A.html")
driver.find_element_by_class_name("telA").send_keys("152.....")
sleep(3)
driver.quit()id 一般情况下唯一
name最大特色可以重名 就一个name会定位到多个元素
就李四 李四 都是李四 都会找到
class多个命名 可以通过多个class名来找到元素 一个元素对应多个class名
就李四 小四 都是同一个人 都是他 我的理解就是 一个有对应有多个class(李四 小四)名
标签就是元素
标签名称 就是 元素名称
tag_name
a标签 超链接
input type不同


from selenium import webdriver
from time import sleep
driver = webdriver.Edge()
driver.get(r"D:\WORK\ww\web自动化_day01_课件+笔记+资料+代码\web自动化_day01_课件+笔记+资料+代码\02_其他资料\注册A.html")
driver.find_element_by_tag_name("input").send_keys("admin")
# 有多个相同的标签名 默认返回第一个
sleep(3)
driver.quit()link_text 只定位a标签 需要完全匹配 精准匹配

from selenium import webdriver
from time import sleep
driver = webdriver.Edge()
driver.get(r"D:\WORK\ww\web自动化_day01_课件+笔记+资料+代码\web自动化_day01_课件+笔记+资料+代码\02_其他资料\注册A.html")
driver.find_element_by_link_text("访问 新浪 网站").click()
sleep(3)
driver.quit()partial_link_text 只定位a标签 模糊匹配 但是要有唯一代表性
如果没有使用唯一代表词 就是说匹配到了多个 默认就返回第一个匹配到的
from selenium import webdriver
from time import sleep
driver = webdriver.Edge()
driver.get(r"D:\WORK\ww\web自动化_day01_课件+笔记+资料+代码\web自动化_day01_课件+笔记+资料+代码\02_其他资料\注册A.html")
driver.find_element_by_partial_link_text("访问").click()
sleep(3)
driver.quit()
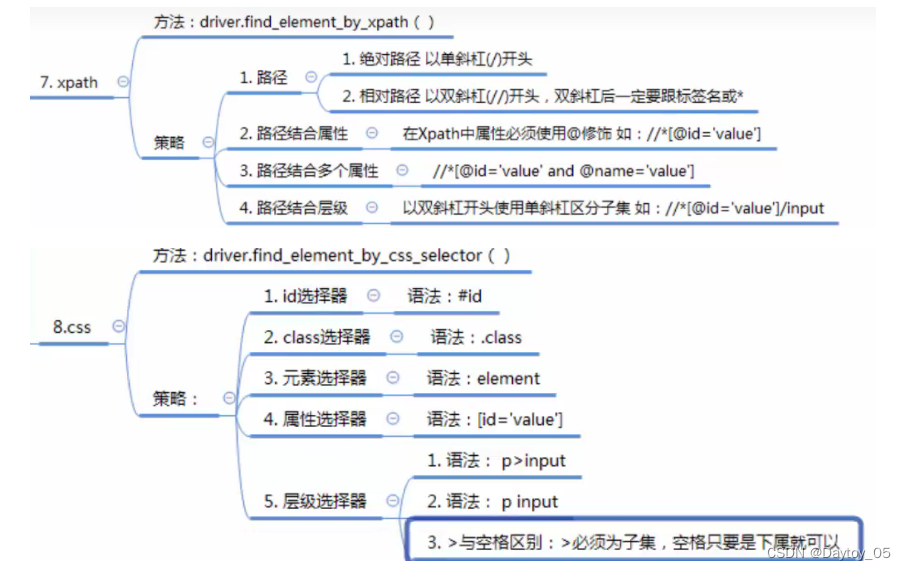
XPath
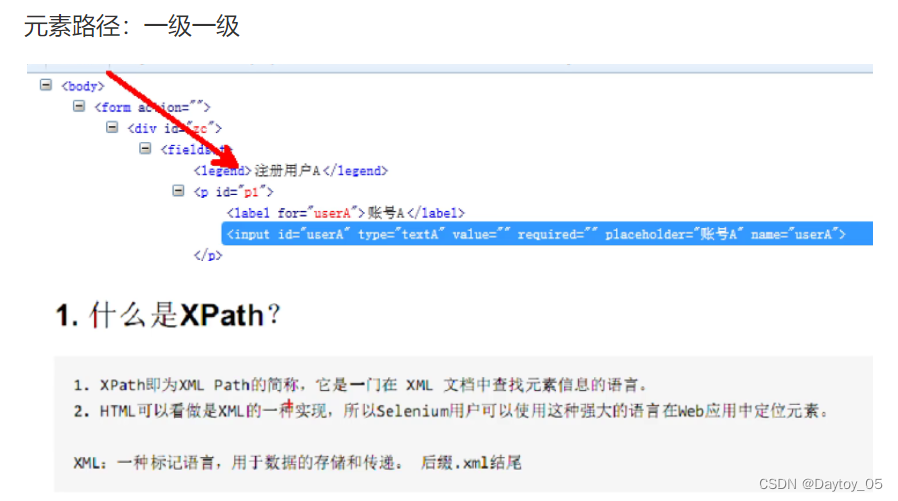

介绍这么多定位方法 就是为了找到我们想要定位的元素
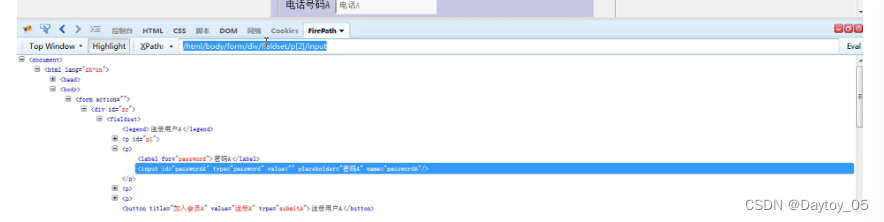
绝对路径:索引从1开始
 相对路径://开头
相对路径://开头
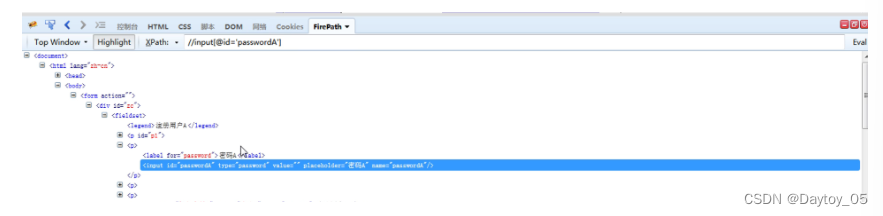 属性用@修饰
属性用@修饰
相对路径 加 属性
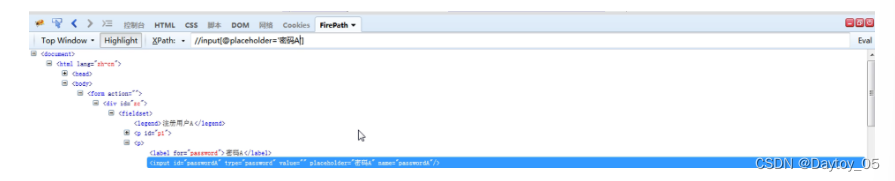
相对路径 加 属性 与 逻辑 结合

层级加属性:
 再往前加父级的 再定位
再往前加父级的 再定位
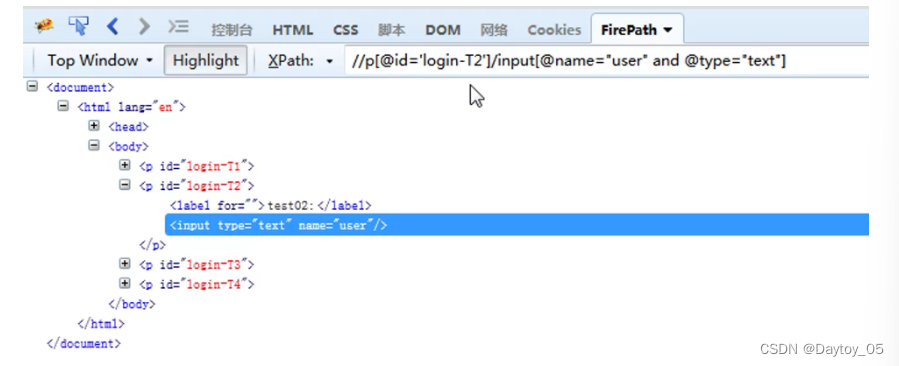 最后简化:
最后简化:
 不知道元素名的话 用*替代
不知道元素名的话 用*替代
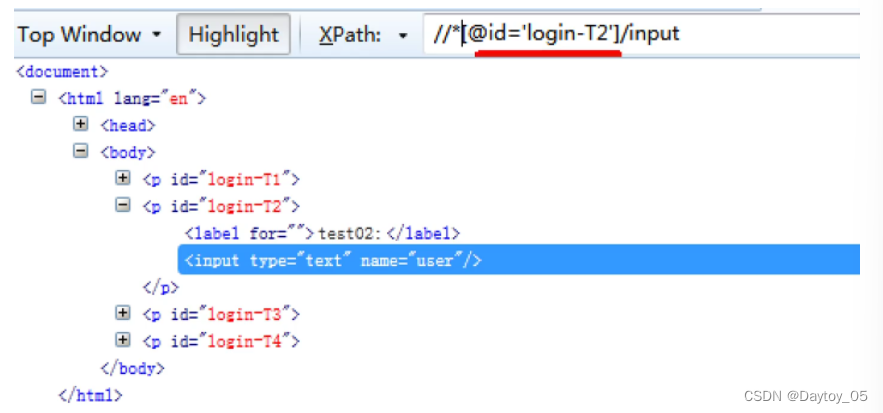


from selenium import webdriver
from time import sleep
driver = webdriver.Edge()
driver.get(r"D:\WORK\ww\web自动化_day01_课件+笔记+资料+代码\web自动化_day01_课件+笔记+资料+代码\02_其他资料\注册A.html")
# 绝对路径
driver.find_element_by_xpath("/html/body/form/div/fieldset/p[1]/input").send_keys("admin")
# 层级结合属性
driver.find_element_by_xpath(("//p[@id='p1']/input")).send_keys("admin")
sleep(2)
# 相对路径 属性
driver.find_element_by_xpath("//input[@id='passwordA']").send_keys("123")
# 属性与逻辑
driver.find_element_by_xpath("//input[@id='passwordA' and @placeholder='密码A']").send_keys("123")
sleep(3)
driver.quit()
<标签 属性> 文本文本文本</标签>
定位a标签 p标签 仅仅定位文本
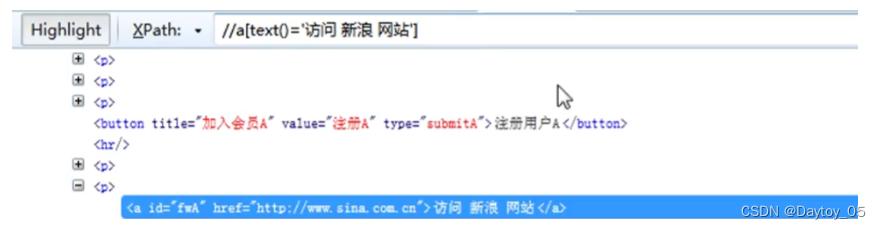
from selenium import webdriver
from time import sleep
driver = webdriver.Edge()
driver.get(r"D:\WORK\ww\web自动化_day01_课件+笔记+资料+代码\web自动化_day01_课件+笔记+资料+代码\02_其他资料\注册A.html")
driver.find_element_by_xpath("//*[contains(@type,'tA')]").send_keys("admin")
# //*[@id="userA"]
driver.find_element_by_xpath("//*[starts-with(@id,'pa')]").send_keys("123")
# //*[@id="passwordA"]
driver.find_element_by_xpath("//a[text()='访问 新浪 网站']").click()
# //*[@id="fwA"]
sleep(3)
driver.quit() CSS
CSS


层级选择器:
body>input 得是直属关系
body input 只要在其下面即可
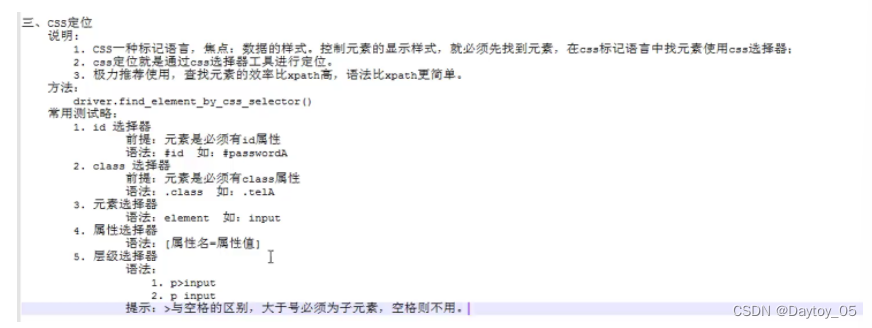
属性的话 任意属性


from selenium import webdriver
from time import sleep
driver = webdriver.Edge()
driver.get(r"D:\WORK\ww\web自动化_day01_课件+笔记+资料+代码\web自动化_day01_课件+笔记+资料+代码\02_其他资料\注册A.html")
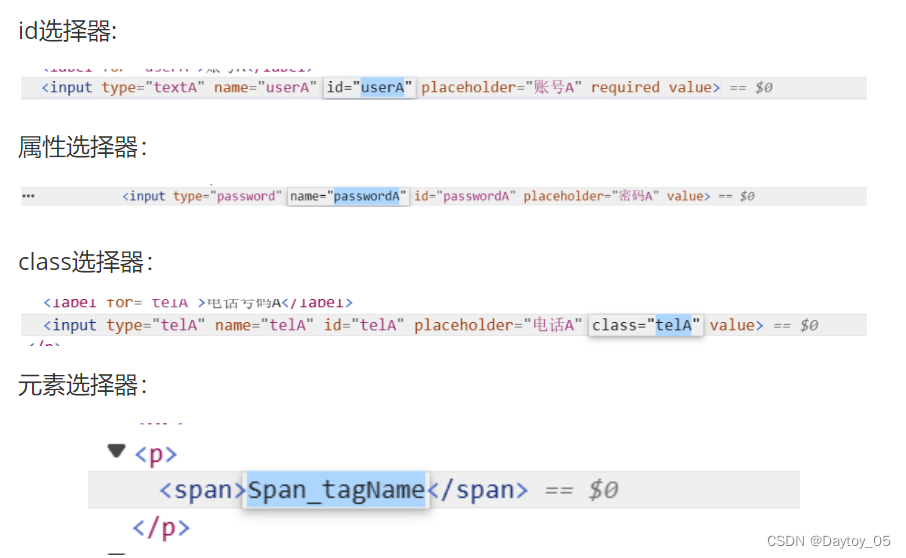
# id选择器
driver.find_element_by_css_selector("#userA").send_keys("admin")
# 属性选择器
driver.find_element_by_css_selector("[name = 'passwordA']").send_keys("123456")
# class选择器
driver.find_element_by_css_selector(".telA").send_keys("15237463726")
# 元素选择器
span = driver.find_element_by_css_selector("span").text
print("获取span的标签文本值", span)
# 层级选择器
driver.find_element_by_css_selector("p>input[placeholder='电子邮箱A']").send_keys("123@.com")
sleep(3)
driver.quit()
from selenium import webdriver
from time import sleep
driver = webdriver.Edge()
driver.get(r"D:\WORK\ww\web自动化_day01_课件+笔记+资料+代码\web自动化_day01_课件+笔记+资料+代码\02_其他资料\注册A.html")
# name=什么
# 属性以us开头
driver.find_element_by_css_selector("[name^='us']").send_keys("admin")
# 属性以dA结束
driver.find_element_by_css_selector("[name$= 'dA']").send_keys("123456")
# 属性包含el
driver.find_element_by_css_selector("[name*='el']").send_keys("15237463726")
sleep(3)
driver.quit()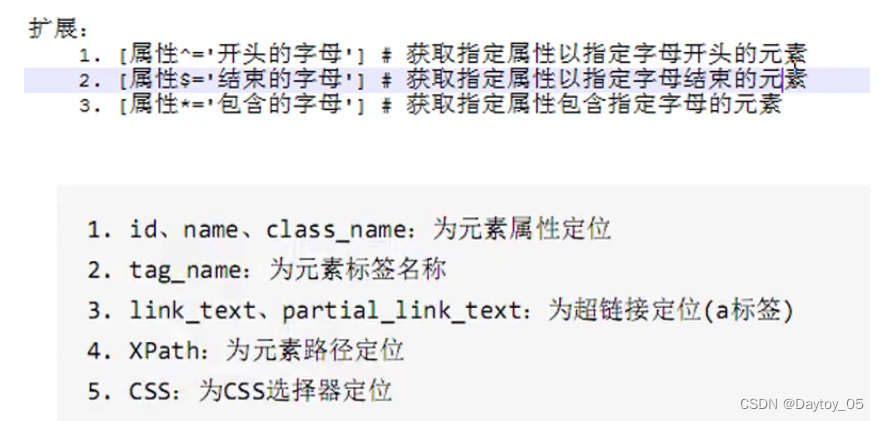
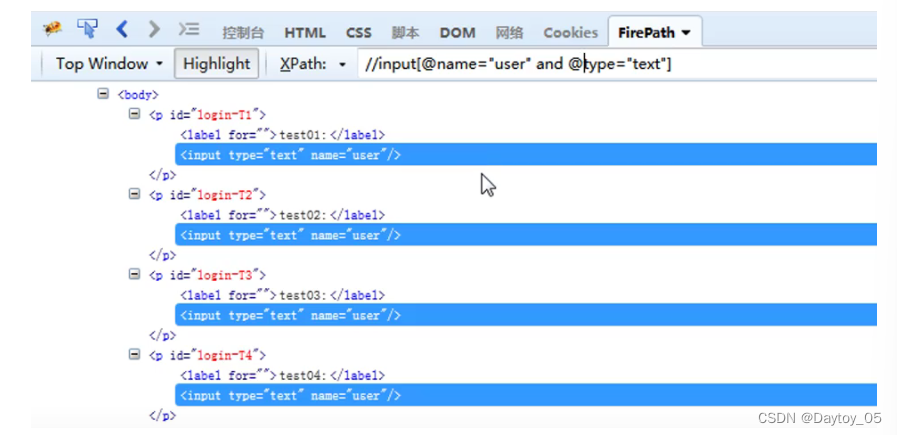
找到一组元素
from selenium import webdriver
from time import sleep
driver = webdriver.Edge()
driver.get(r"D:\WORK\ww\web自动化_day01_课件+笔记+资料+代码\web自动化_day01_课件+笔记+资料+代码\02_其他资料\注册A.html")
# 一组元素
# elements = driver.find_elements_by_tag_name("input")
elements = driver.find_elements_by_id("userA")
print(len(elements)) # elements是列表
# 对列表访问就是用下标遍历
# elements[0].send_keys("admin")
for el in elements:
el.send_keys("admin")
sleep(3)
driver.quit()类型:8种定位方法
简化定位方法
from selenium import webdriver
from selenium.webdriver.common.by import By
from time import sleep
driver = webdriver.Edge()
driver.get(r"D:\WORK\ww\web自动化_day01_课件+笔记+资料+代码\web自动化_day01_课件+笔记+资料+代码\02_其他资料\注册A.html")
driver.find_element(By.ID,"userA").send_keys("admin")
driver.find_element(By.CSS_SELECTOR,"#passwordA").send_keys("123456")
sleep(3)
driver.quit()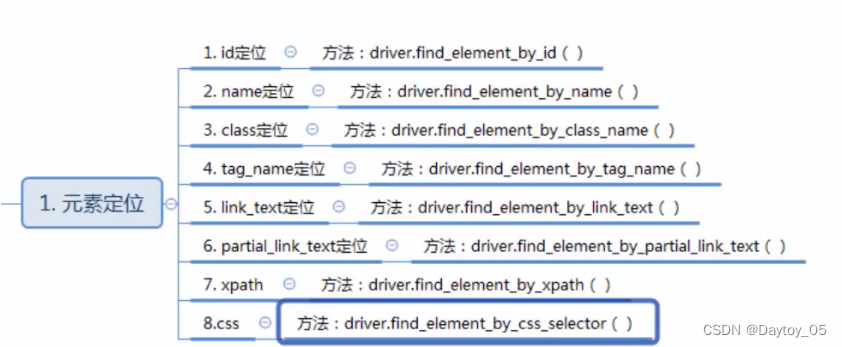
1,2,3 元素属性
4 标签属性
5,6 超链接















 221
221











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









